Události
Vytváření inteligentních aplikací
17. 3. 23 - 21. 3. 23
Připojte se k řadě meetupů a vytvořte škálovatelná řešení AI založená na skutečných případech použití s kolegy vývojáři a odborníky.
ZaregistrovatTento prohlížeč se už nepodporuje.
Upgradujte na Microsoft Edge, abyste mohli využívat nejnovější funkce, aktualizace zabezpečení a technickou podporu.
Tip
Tento obsah je výňatek z elektronické knihy, vzory podnikových aplikací pomocí .NET MAUI, dostupné na .NET Docs nebo jako zdarma ke stažení PDF, které lze číst offline.

Vývoj klientských serverových aplikací má za následek zaměření se na vytváření vrstvených aplikací, které používají konkrétní technologie v každé vrstvě. Takové aplikace se často označují jako monolitické a jsou zabalené do hardwaru předem škálované pro zatížení ve špičce. Hlavní nevýhodou tohoto vývojového přístupu je úzká spojka mezi komponentami v rámci každé úrovně, že jednotlivé komponenty nelze snadno škálovat a náklady na testování. Jednoduchá aktualizace může mít nepředvídatelné účinky na zbytek vrstvy, takže změna komponenty aplikace vyžaduje opětovné otestování a opětovné nasazení celé vrstvy.
Zejména pokud jde o to, že ve věku cloudu není možné snadno škálovat jednotlivé komponenty. Monolitická aplikace obsahuje funkce specifické pro doménu a obvykle se dělí podle funkčních vrstev, jako je front-end, obchodní logika a úložiště dat. Následující obrázek ukazuje, že monolitická aplikace se škáluje klonováním celé aplikace na více počítačů.

Mikroslužby nabízejí jiný přístup k vývoji a nasazení aplikací, přístup, který je vhodný pro požadavky na flexibilitu, škálování a spolehlivost moderních cloudových aplikací. Aplikace mikroslužeb je rozdělená na nezávislé komponenty, které spolupracují na poskytování celkové funkčnosti aplikace. Pojem mikroslužba zdůrazňuje, že aplikace by se měly skládat ze služeb dostatečně malé, aby odrážely konkrétní obavy, takže každá mikroslužba implementuje jednu funkci. Každá mikroslužba má navíc dobře definované kontrakty, se kterými ostatní mikroslužby komunikují a sdílejí data. Mezi typické příklady mikroslužeb patří nákupní košíky, zpracování zásob, nákupní subsystémy a zpracování plateb.
Mikroslužby se můžou nezávisle škálovat v porovnání s obřími monolitických aplikací, které se škálují společně. To znamená, že je možné škálovat konkrétní funkční oblast, která vyžaduje větší výpočetní výkon nebo šířku pásma sítě pro podporu poptávky, a ne zbytečně škálovat další aplikační oblasti. Následující obrázek znázorňuje tento přístup, kdy se mikroslužby nasazují a škálují nezávisle a vytvářejí instance služeb napříč počítači.

Škálování mikroslužeb může být téměř okamžité, což aplikaci umožňuje přizpůsobit se měnícím zatížením. Například jedna mikroslužba ve webové funkci aplikace může být jedinou mikroslužbou, která potřebuje horizontální navýšení kapacity pro zpracování dalšího příchozího provozu.
Klasickým modelem škálovatelnosti aplikací je mít vrstvu bezstavové vyrovnávání zatížení se sdíleným externím úložištěm dat pro ukládání trvalých dat. Stavové mikroslužby spravují svá vlastní trvalá data, obvykle je ukládají místně na servery, na kterých jsou umístěné, aby se zabránilo režii síťového přístupu a složitosti operací napříč službami. To umožňuje nejrychlejší zpracování dat a může eliminovat potřebu systémů ukládání do mezipaměti. Kromě toho škálovatelné stavové mikroslužby obvykle rozdělují data mezi své instance, aby bylo možné spravovat velikost dat a propustnost přenosu nad rámec toho, co může jeden server podporovat.
Mikroslužby také podporují nezávislé aktualizace. Toto volné spojení mezi mikroslužbami poskytuje rychlý a spolehlivý vývoj aplikací. Jejich nezávislá distribuovaná povaha pomáhá spouštět aktualizace, kdy se v daném okamžiku aktualizuje pouze podmnožina instancí jedné mikroslužby. Proto pokud se zjistí problém, je možné vrátit aktualizaci chyby zpět před aktualizací všech instancí s chybným kódem nebo konfigurací. Podobně mikroslužby obvykle používají správu verzí schématu, aby klienti viděli konzistentní verzi při použití aktualizací bez ohledu na to, s jakou instancí mikroslužby se komunikuje.
Proto mají aplikace mikroslužeb mnoho výhod oproti monolitických aplikacím:
Řešení založené na mikroslužbách má ale také potenciální nevýhody:
Kontejnerizace je přístup k vývoji softwaru, ve kterém se aplikace a jeho verze sady závislostí a navíc jeho konfigurace prostředí abstrahuje jako soubory manifestu nasazení, jsou zabaleny společně jako image kontejneru, testovány jako jednotka a nasazeny do hostitelského operačního systému.
Kontejner je izolované, řízené a přenosné provozní prostředí, ve kterém může aplikace běžet bez zásahu do prostředků jiných kontejnerů nebo hostitele. Kontejner proto vypadá a funguje jako nově nainstalovaný fyzický počítač nebo virtuální počítač.
Existuje mnoho podobností mezi kontejnery a virtuálními počítači, jak je znázorněno níže.

Kontejner spouští operační systém, má systém souborů a dá se k němu přistupovat přes síť, jako by šlo o fyzický nebo virtuální počítač. Technologie a koncepty používané kontejnery se ale velmi liší od virtuálních počítačů. Mezi virtuální počítače patří aplikace, požadované závislosti a úplný hostovaný operační systém. Kontejnery zahrnují aplikaci a její závislosti, ale sdílejí operační systém s jinými kontejnery, které běží jako izolované procesy v hostitelském operačním systému (kromě kontejnerů Hyper-V, které běží uvnitř speciálního virtuálního počítače na kontejner). Kontejnery proto sdílejí prostředky a obvykle vyžadují méně prostředků než virtuální počítače.
Výhodou přístupu zaměřeného na vývoj a nasazení kontejnerů je, že eliminuje většinu problémů, které vznikají z nekonzistentních nastavení prostředí a problémů, které s nimi přicházejí. Kontejnery navíc umožňují rychlé funkce vertikálního navýšení kapacity aplikací tak, že podle potřeby nastavují nové kontejnery.
Mezi klíčové koncepty při vytváření a práci s kontejnery patří:
| Koncept | Popis |
|---|---|
| Hostitel kontejneru | Fyzický nebo virtuální počítač nakonfigurovaný pro hostování kontejnerů. Hostitel kontejneru spustí jeden nebo více kontejnerů. |
| Image kontejneru | Obrázek se skládá ze sjednocení vrstvených systémů souborů skládaných nad sebou a je základem kontejneru. Image nemá stav a při nasazení do různých prostředí se nikdy nemění. |
| Kontejner | Kontejner je instance modulu runtime image. |
| Image kontejneru operačního systému | Kontejnery se nasazují z imagí. Image operačního systému kontejneru je první vrstvou v potenciálně mnoha vrstvách imagí, které tvoří kontejner. Operační systém kontejneru je neměnný a nelze ho upravovat. |
| Úložiště kontejnerů | Při každém vytvoření image kontejneru se image a její závislosti ukládají v místním úložišti. Tyto image je možné opakovaně používat na hostiteli kontejneru. Image kontejneru se dají uložit také do veřejného nebo privátního registru, jako je Docker Hub, aby je bylo možné použít napříč různými hostiteli kontejnerů. |
Podniky stále častěji přijímají kontejnery při implementaci aplikací založených na mikroslužbách a Docker se stal standardní implementací kontejnerů, kterou přijala většina softwarových platforem a dodavatelů cloudu.
Referenční aplikace eShop používá Docker k hostování čtyř kontejnerizovaných back-endových mikroslužeb, jak je znázorněno v následujícím diagramu.
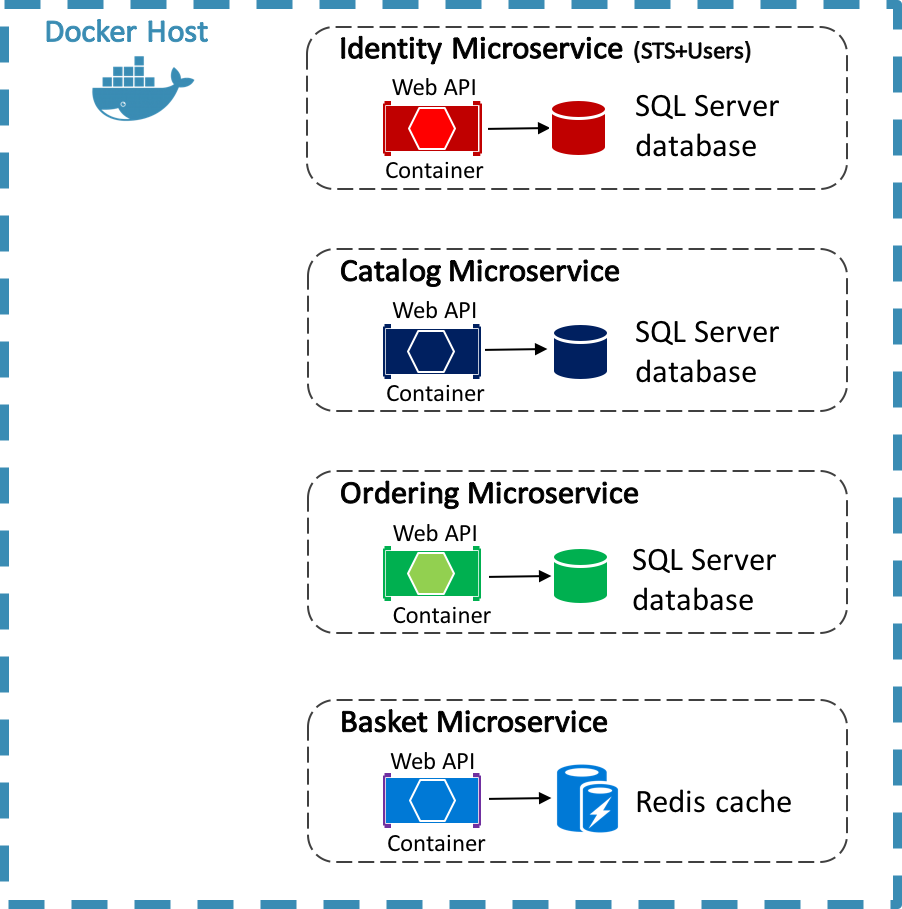
Architektura back-endových služeb v referenční aplikaci je rozdělena do několika autonomních dílčích systémů ve formě spolupráce mikroslužeb a kontejnerů. Každá mikroslužba poskytuje jednu oblast funkcí: službu identit, službu katalogu, službu objednávek a službu košíku.
Každá mikroslužba má svou vlastní databázi, která umožňuje úplné oddělení od ostatních mikroslužeb. V případě potřeby je dosaženo konzistence mezi databázemi z různých mikroslužeb pomocí událostí na úrovni aplikace. Další informace naleznete v tématu Komunikace mezi mikroslužbami.
Multiformní aplikace eShop komunikuje s kontejnerizovanými back-endovými mikroslužbami pomocí přímé komunikace mezi klientem a mikroslužbou , jak je znázorněno níže.

Díky přímé komunikaci mezi klientem a mikroslužbou aplikace pro více platforem provádí požadavky na každou mikroslužbu přímo prostřednictvím svého veřejného koncového bodu s jiným portem TCP na mikroslužbu. V produkčním prostředí by koncový bod obvykle mapoval na nástroj pro vyrovnávání zatížení mikroslužby, který distribuuje požadavky mezi dostupné instance.
Tip
Zvažte použití komunikace brány rozhraní API.
Přímá komunikace mezi klientem a mikroslužbou může mít nevýhody při vytváření rozsáhlé a složité aplikace založené na mikroslužbách, ale je pro malou aplikaci vhodnější. Při návrhu rozsáhlé aplikace založené na mikroslužbách s desítkami mikroslužeb zvažte použití komunikace brány rozhraní API.
Aplikace založená na mikroslužbách je distribuovaný systém, který může běžet na více počítačích. Každá instance služby je obvykle procesem. Služby proto musí komunikovat pomocí komunikačního protokolu mezi procesy, jako je HTTP, TCP, Advanced Message Queuing Protocol (AMQP) nebo binární protokoly v závislosti na povaze každé služby.
Mezi dva běžné přístupy pro komunikaci mikroslužeb mezi mikroslužbami patří komunikace REST založená na protokolu HTTP při dotazování na data a odlehčené asynchronní zasílání zpráv při komunikaci aktualizací mezi několika mikroslužbami.
Asynchronní komunikace založená na událostech založená na zasílání zpráv je důležitá při šíření změn napříč několika mikroslužbami. S tímto přístupem mikroslužba publikuje událost, když se stane něco, co se stane, například když aktualizuje obchodní entitu. Ostatní mikroslužby se k odběru těchto událostí přihlašují. Když pak mikroslužba obdrží událost, aktualizuje své vlastní obchodní entity, které pak můžou vést k publikování dalších událostí. Tato funkce publikování a odběru se obvykle dosahuje pomocí sběrnice událostí.
Sběrnice událostí umožňuje komunikaci s publikováním a odběrem mezi mikroslužbami, aniž by bylo nutné, aby si komponenty navzájem explicitně uvědomily, jak je znázorněno níže.

Z pohledu aplikace je sběrnice událostí jednoduše kanál publikování a odběru vystavený prostřednictvím rozhraní. Způsob implementace sběrnice událostí se ale může lišit. Implementace sběrnice událostí může například používat RabbitMQ, Azure Service Bus nebo jiné servisní autobusy, jako je NServiceBus a MassTransit. Následující diagram ukazuje, jak se v referenční aplikaci eShop používá sběrnice událostí.

Sběrnice událostí eShop implementovaná pomocí RabbitMQ poskytuje funkce asynchronního publikování a odběru 1:N. To znamená, že po publikování události může být několik odběratelů, kteří naslouchají stejné události. Tento vztah znázorňuje následující diagram.

Tento komunikační přístup 1:N používá události k implementaci obchodních transakcí, které zahrnují více služeb a zajišťují konečnou konzistenci mezi službami. Konečná transakce se skládá z řady distribuovaných kroků. Proto když mikroslužba profilu uživatele obdrží příkaz UpdateUser, aktualizuje podrobnosti uživatele v jeho databázi a publikuje událost UserUpdated do sběrnice událostí. Mikroslužba košíku i objednávková mikroslužba se přihlásily k odběru této události a v reakci na to aktualizují informace o kupujících v příslušných databázích.
Mikroslužby nabízejí přístup k vývoji a nasazení aplikací, který je vhodný pro požadavky na flexibilitu, škálování a spolehlivost moderních cloudových aplikací. Jednou z hlavních výhod mikroslužeb je, že je možné škálovat nezávisle na sobě, což znamená, že je možné škálovat konkrétní funkční oblast, která vyžaduje větší výpočetní výkon nebo šířku pásma sítě, aby podporovala poptávku bez zbytečného škálování oblastí aplikace, u kterých není zvýšená poptávka.
Kontejner je izolované, řízené prostředky a přenosné provozní prostředí, ve kterém může aplikace běžet bez zásahu do prostředků jiných kontejnerů nebo hostitele. Podniky stále častěji přijímají kontejnery při implementaci aplikací založených na mikroslužbách a Docker se stal standardní implementací kontejnerů, kterou přijala většina softwarových platforem a dodavatelů cloudu.
Zpětná vazba k produktu .NET
.NET je open source projekt. Vyberte odkaz pro poskytnutí zpětné vazby:
Události
Vytváření inteligentních aplikací
17. 3. 23 - 21. 3. 23
Připojte se k řadě meetupů a vytvořte škálovatelná řešení AI založená na skutečných případech použití s kolegy vývojáři a odborníky.
ZaregistrovatŠkolení
Modul
Sestavte si první mikroslužbu pomocí .NET - Training
Aplikace mikroslužeb se skládají z malých, nezávislých verzí a škálovatelných služeb zaměřených na zákazníky, které vzájemně komunikují pomocí standardních protokolů a dobře definovaných rozhraní. Každá mikroslužba obvykle zapouzdřuje jednoduchou obchodní logiku, kterou můžete škálovat na více instancí nebo do nich. Mikroslužbu testujete, nasazujete a spravujete nezávisle. Menší týmy vyvíjejí mikroslužbu na základě scénáře zákazníka a vyberou si technologie, které používají. V tomto modulu se naučíte, jak v
Certifikace
Microsoft Certifikát: Azure Vývojářský Asistent - Certifications
Vytvářejte ucelená řešení v Microsoft Azure pro vytváření funkcí Azure, implementaci a správu webových aplikací, vývoj řešení využívajících úložiště Azure a další.