Implementer medallion lakehouse-arkitektur i Microsoft Fabric
I denne artikel introduceres medallionsøarkitekturen og beskrives, hvordan du kan implementere et lakehouse i Microsoft Fabric. Den er målrettet mod flere målgrupper:
- Datateknikere: Tekniske medarbejdere, der designer, bygger og vedligeholder infrastrukturer og systemer, der gør det muligt for deres organisation at indsamle, gemme, behandle og analysere store datamængder.
- Center of Excellence, IT og BI-teamet: De teams, der er ansvarlige for at holde tilsyn med analyser i hele organisationen.
- Fabric-administratorer: De administratorer, der er ansvarlige for at lede Fabric i organisationen.
Medallion lakehouse-arkitekturen, der ofte kaldes medaljonsarkitektur, er et designmønster, der bruges af organisationer til logisk at organisere data i et lakehouse. Det er den anbefalede designtilgang til Fabric.
Medaljonsarkitekturen består af tre forskellige lag – eller zoner. Hvert lag angiver kvaliteten af data, der er gemt i lakehouse, med højere niveauer, der repræsenterer højere kvalitet. Denne tilgang med flere lag hjælper dig med at opbygge en enkelt kilde til sandhed for virksomhedsdataprodukter.
Medaljonsarkitektur garanterer acid-sættet af egenskaber (Atomicity, Consistency, Isolation og Holdbarhed), efterhånden som dataene skrider gennem lagene. Fra og med rådata forbereder en række valideringer og transformationer data, der er optimeret til effektiv analyse. Der er tre medaljonsfaser: bronze (rå), sølv (valideret) og guld (beriget).
Du kan få flere oplysninger under Hvad er medallion lakehouse-arkitekturen?.
OneLake og lakehouse i Fabric
Grundlaget for et moderne data warehouse er en datasø. Microsoft OneLake, som er en enkelt, samlet og logisk datasø for hele organisationen. Den leveres automatisk med alle Fabric-lejere, og den er designet til at være den eneste placering for alle dine analysedata.
Du kan bruge OneLake til at:
- Fjern siloer, og reducer administrationsindsatsen. Alle organisationsdata gemmes, administreres og sikres i én datasøressource. Da OneLake er klargjort med din Fabric-lejer, er der ikke flere ressourcer at klargøre eller administrere.
- Reducer dataflytning og duplikering. Formålet med OneLake er kun at gemme én kopi af data. Færre kopier af data resulterer i færre dataflytningsprocesser, og det medfører effektivitetsgevinster og reduktion af kompleksiteten. Hvis det er nødvendigt, kan du oprette en genvej til at referere til data, der er gemt på andre placeringer, i stedet for at kopiere dem til OneLake.
- Bruges sammen med flere analyseprogrammer. Dataene i OneLake gemmes i et åbent format. På den måde kan dataene forespørges af forskellige analyseprogrammer, herunder Analysis Services (bruges af Power BI), T-SQL og Apache Spark. Andre ikke-Fabric-programmer kan også bruge API'er og SDK'er til at få adgang til OneLake .
Du kan få flere oplysninger i OneLake, OneDrive for data.
Hvis du vil gemme data i OneLake, skal du oprette et lakehouse i Fabric. Et lakehouse er en dataarkitekturplatform til lagring, administration og analyse af strukturerede og ustrukturerede data på en enkelt placering. Den kan nemt skaleres til store datamængder af alle filtyper og størrelser, og fordi den er gemt på en enkelt placering, deles og genbruges den nemt på tværs af organisationen.
Hvert lakehouse har et indbygget SQL Analytics-slutpunkt, der låser op for data warehouse-funktioner uden at skulle flytte data. Det betyder, at du kan forespørge dine data i lakehouse ved hjælp af SQL-forespørgsler og uden nogen særlig konfiguration.
Du kan få flere oplysninger under Hvad er et lakehouse i Microsoft Fabric?.
Tabeller og filer
Når du opretter et lakehouse i Fabric, klargøres to fysiske lagerplaceringer automatisk til tabeller og filer.
- Tabeller er et administreret område til hosting af tabeller i alle formater i Apache Spark (CSV, Parquet eller Delta). Alle tabeller, uanset om de er oprettet automatisk eller eksplicit, genkendes som tabeller i lakehouse. Alle Delta-tabeller, som er Parquet-datafiler med en filbaseret transaktionslogfil, genkendes også som tabeller.
- Filer er et ikke-administreret område til lagring af data i et hvilket som helst filformat. Alle Delta-filer, der er gemt i dette område, genkendes ikke automatisk som tabeller. Hvis du vil oprette en tabel over en Delta Lake-mappe i det ikke-administrerede område, skal du eksplicit oprette en genvej eller en ekstern tabel med en placering, der peger på den ikke-administrerede mappe, der indeholder Delta Lake-filerne i Apache Spark.
Den primære forskel mellem det administrerede område (tabeller) og det ikke-administrerede område (filer) er den automatiske registrerings- og registreringsproces for tabeller. Denne proces kører kun over alle mapper, der er oprettet i det administrerede område, men ikke i det ikke-administrerede område.
I Microsoft Fabric giver Lakehouse-opdagelsesrejsende en samlet grafisk gengivelse af hele Lakehouse, så brugerne kan navigere, få adgang til og opdatere deres data.
Du kan finde flere oplysninger om automatisk registrering af tabeller under Automatisk registrering og registrering af tabeller.
Delta Lake Storage
Delta Lake er et optimeret lagerlag, der er grundlaget for lagring af data og tabeller. Det understøtter ACID-transaktioner for big data-arbejdsbelastninger, og derfor er det standardlagerformatet i et Fabric lakehouse.
Det er vigtigt, at Delta Lake leverer pålidelighed, sikkerhed og ydeevne i lakehouse til både streaming- og batchhandlinger. Internt gemmer den data i Parquet-filformatet, men den vedligeholder også transaktionslogge og statistikker, der leverer funktioner og forbedring af ydeevnen i forhold til standardformatet Parquet.
Delta Lake-formatet i forhold til generiske filformater giver følgende primære fordele.
- Understøttelse af ACID-egenskaber og især holdbarhed for at forhindre beskadigelse af data.
- Hurtigere læseforespørgsler.
- Øget data friskhed.
- Understøttelse af både batch- og streamingarbejdsbelastninger.
- Understøttelse af data rollback ved hjælp af Delta Lake-tidsrejser.
- Forbedret overholdelse af regler og revision ved hjælp af tabellen Delta Lake.
Fabric standardiserer lagringsfilformatet med Delta Lake, og som standard opretter hvert arbejdsbelastningsprogram i Fabric Delta-tabeller, når du skriver data til en ny tabel. Du kan få flere oplysninger under Tabellerne Lakehouse og Delta Lake.
Medaljonsarkitektur i Fabric
Målet med medaljonsarkitekturen er trinvist og gradvist at forbedre strukturen og kvaliteten af data, efterhånden som de skrider frem i hver fase.
Medaljonsarkitekturen består af tre forskellige lag (eller zoner).
- Bronze: Dette første lag, der også kaldes råzonen, gemmer kildedata i det oprindelige format. Dataene i dette lag er typisk kun tilføjelser og uforanderlige.
- Sølv: Dette lag, der også er kendt som den forbedrede zone, gemmer data, der stammer fra bronzelaget. Rådata er blevet renset og standardiseret, og de er nu struktureret som tabeller (rækker og kolonner). Det kan også være integreret med andre data for at give en virksomhedsvisning af alle forretningsobjekter, f.eks. kunde, produkt og andre.
- Guld: Dette sidste lag, der også kaldes den organiserede zone, gemmer data, der stammer fra sølvlaget. Dataene er afgrænset til at opfylde specifikke krav til downstream-forretning og analyse. Tabeller er typisk i overensstemmelse med stjerneskemadesignet, som understøtter udvikling af datamodeller, der er optimeret til ydeevne og anvendelighed.
Vigtigt
Da et Fabric lakehouse repræsenterer en enkelt zone, opretter du ét lakehouse for hver af de tre zoner.
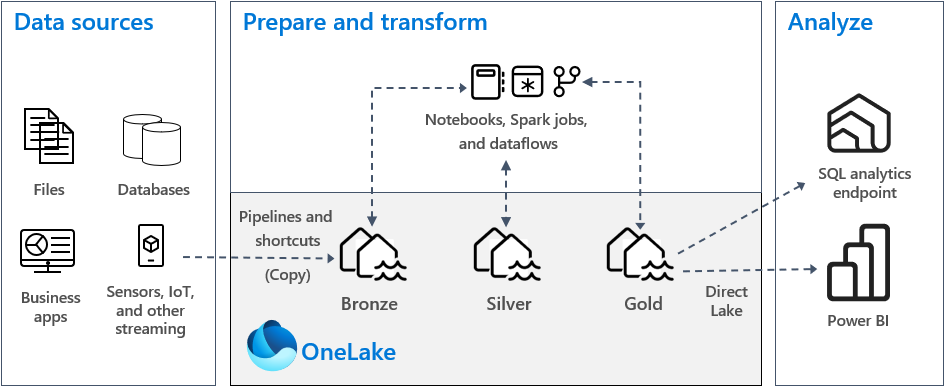
I en typisk implementering af medaljonsarkitektur i Fabric gemmer bronzezonen dataene i samme format som datakilden. Når datakilden er en relationsdatabase, er Delta-tabeller et godt valg. Sølv- og guldzonerne indeholder Delta-tabeller.
Tip
Du kan få mere at vide om, hvordan du opretter et lakehouse, ved at gennemgå selvstudiet om end-to-end-scenariet i Lakehouse.
Vejledning til fabric lakehouse
Dette afsnit indeholder en vejledning i implementering af fabric lakehouse ved hjælp af medaljonsarkitektur.
Udrulningsmodel
Hvis du vil implementere medaljonsarkitektur i Fabric, kan du enten bruge lakehouses (én for hver zone), et data warehouse eller en kombination af begge. Din beslutning skal være baseret på dine præferencer og dit teams ekspertise. Vær opmærksom på, at Fabric giver dig fleksibilitet: Du kan bruge forskellige analyseprogrammer, der fungerer på den ene kopi af dine data i OneLake.
Her er to mønstre, du skal overveje.
- Mønster 1: Opret hver zone som et lakehouse. I dette tilfælde får virksomhedsbrugere adgang til data ved hjælp af SQL-analyseslutpunktet.
- Mønster 2: Opret bronze- og sølvzoner som lakehouses og guldzonen som data warehouse. I dette tilfælde får virksomhedsbrugere adgang til data ved hjælp af data warehouse-slutpunktet.
Selvom du kan oprette alle lakehouses i et enkelt Fabric-arbejdsområde, anbefaler vi, at du opretter hvert enkelt lakehouse i sit eget, separate Fabric-arbejdsområde. Denne fremgangsmåde giver dig mere kontrol og bedre styring på zoneniveau.
I forbindelse med bronzezonen anbefaler vi, at du gemmer dataene i det oprindelige format eller bruger Parquet eller Delta Lake. Når det er muligt, skal du beholde dataene i det oprindelige format. Hvis kildedataene er fra OneLake, Azure Data Lake Store Gen2 (ADLS Gen2), Amazon S3 eller Google, skal du oprette en genvej i bronzezonen i stedet for at kopiere dataene på tværs.
I forbindelse med sølv- og guldzoner anbefaler vi, at du bruger Delta-tabeller på grund af de ekstra funktioner og forbedringer af ydeevnen, de giver. Fabric standardiserer delta lake-formatet, og som standard skriver alle motorer i Fabric data i dette format. Desuden bruger disse motorer V-Order-skrivetidsoptimering til Parquet-filformatet. Denne optimering muliggør ekstremt hurtige læsninger af Fabric-beregningsprogrammer, f.eks. Power BI, SQL, Apache Spark og andre. Du kan få flere oplysninger under Tabeloptimering af Delta Lake og V-Order.
Endelig oplever mange organisationer i dag en massiv vækst i datamængder sammen med et stigende behov for at organisere og administrere disse data på en logisk måde, samtidig med at de faciliterer mere målrettet og effektiv brug og styring. Det kan føre dig til at etablere og administrere en decentraliseret dataorganisation eller en dataorganisation i organisationsnetværket med styring.
Du kan opfylde dette mål ved at overveje at implementere en datanetarkitektur. Datanet er et arkitektonisk mønster, der fokuserer på at oprette datadomæner, der tilbyder data som et produkt.
Du kan oprette en datanetarkitektur for dit dataområde i Fabric ved at oprette datadomæner. Du kan oprette domæner, der knyttes til dine virksomhedsdomæner, f.eks. marketing, salg, lager, HR og andre. Du kan derefter implementere medaljonsarkitektur ved at konfigurere datazoner i hvert af dine domæner.
Du kan få flere oplysninger om domæner under Domæner.
Forstå datalageret i Delta-tabellen
I dette afsnit beskrives andre vejledningsemner i forbindelse med implementering af en medallion lakehouse-arkitektur i Fabric.
Filstørrelse
Generelt fungerer en big data-platform bedre, når den har et lille antal store filer i stedet for et stort antal små filer. Det skyldes, at ydeevnen forringes, når beregningsprogrammet skal administrere mange metadata- og filhandlinger. For at opnå en bedre ydeevne af forespørgsler anbefaler vi, at du søger efter datafiler, der har en størrelse på ca. 1 GB.
Delta Lake har en funktion, der kaldes prædiktiv optimering. Forudsigende optimering fjerner behovet for manuelt at administrere vedligeholdelseshandlinger for Delta-tabeller. Når denne funktion er aktiveret, identificerer Delta Lake automatisk tabeller, der kan drage fordel af vedligeholdelseshandlinger, og optimerer derefter deres lager. Det kan gennemsigtigt samle mange mindre filer i store filer og uden nogen indvirkning på andre læsere og forfattere af dataene. Selvom denne funktion bør være en del af din driftsmæssige ekspertise og dit dataforberedelsesarbejde, har Fabric også mulighed for at optimere disse datafiler under dataskrivning. Du kan få flere oplysninger under Forudsigende optimering af Delta Lake.
Historisk opbevaring
Delta Lake bevarer som standard en oversigt over alle foretagne ændringer. Det betyder, at størrelsen af historiske metadata vokser over tid. Baseret på dine forretningsmæssige krav bør du fokusere på kun at opbevare historiske data i en bestemt periode for at reducere dine lageromkostninger. Overvej kun at bevare historiske data for den sidste måned eller et andet passende tidsrum.
Du kan fjerne ældre historiske data fra en Delta-tabel ved hjælp af kommandoen VACUUM. Vær dog opmærksom på, at du som standard ikke kan slette historiske data inden for de seneste syv dage – det er for at bevare konsistensen i dataene. Standardantal dage styres af tabelegenskaben delta.deletedFileRetentionDuration = "interval <interval>". Det bestemmer, hvor lang tid en fil skal slettes, før den kan betragtes som kandidat til en vakuumhandling.
Tabelpartitioner
Når du gemmer data i hver zone, anbefaler vi, at du bruger en partitioneret mappestruktur, hvor det er relevant. Denne teknik hjælper med at forbedre dataadministration og ydeevne af forespørgsler. Partitionerede data i en mappestruktur resulterer generelt i hurtigere søgning efter bestemte dataposter takket være fjernelse/eliminering af partitioner.
Du føjer typisk data til din destinationstabel, når der modtages nye data. I nogle tilfælde kan du dog flette data, fordi du skal opdatere eksisterende data på samme tid. I så fald kan du udføre en upsert-handling ved hjælp af kommandoen MERGE. Når destinationstabellen er partitioneret, skal du bruge et partitionsfilter til at fremskynde handlingen. På den måde kan programmet fjerne partitioner, der ikke kræver opdatering.
Dataadgang
Endelig skal du planlægge og styre, hvem der skal have adgang til bestemte data i lakehouse. Du bør også forstå de forskellige transaktionsmønstre, de skal bruge, mens du får adgang til disse data. Du kan derefter definere det rette tabelpartitionsskema og datasamlingen med Delta Lake Z-order-indeks.
Relateret indhold
Du kan få flere oplysninger om implementering af et Fabric lakehouse i følgende ressourcer.
- Selvstudium: Lakehouse fra ende til anden-scenarie
- Lakehouse- og Delta Lake-tabeller
- Microsoft Fabric-beslutningsvejledning: Vælg et datalager
- Tabeloptimering af Delta Lake og V-Order
- Behovet for at optimere skrive på Apache Spark
- Spørgsmål? Prøv at spørge Fabric-community'et.
- Forslag? Bidrag med idéer til forbedring af Fabric.
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om