Vejledning til sammensatte modeller i Power BI Desktop
Denne artikel henvender sig til dataudformere, der udvikler sammensatte Power BI-modeller. Den beskriver use cases for sammensatte modeller og giver dig designvejledning. Vejledningen kan specifikt hjælpe dig med at finde ud af, om en sammensat model passer til din løsning. Hvis det er det, hjælper denne artikel dig også med at designe optimale sammensatte modeller og rapporter.
Bemærk
En introduktion til sammensatte modeller er ikke beskrevet i denne artikel. Hvis du ikke er helt fortrolig med sammensatte modeller, anbefaler vi, at du først læser artiklen Brug sammensatte modeller i Power BI Desktop .
Da sammensatte modeller består af mindst én DirectQuery-kilde, er det også vigtigt, at du har en grundig forståelse af modelrelationer, DirectQuery-modeller og Vejledning til design af DirectQuery-modeller.
Use cases for sammensatte modeller
En sammensat model kombinerer pr. definition flere kildegrupper. En kildegruppe kan repræsentere importerede data eller en forbindelse til en DirectQuery-kilde. En DirectQuery-kilde kan enten være en relationsdatabase eller en anden tabelmodel, som kan være en semantisk Power BI-model (tidligere kendt som et datasæt) eller en Analysis Services-tabelmodel. Når en tabelmodel opretter forbindelse til en anden tabelmodel, kaldes den sammenkædning. Du kan finde flere oplysninger under Brug af DirectQuery til semantiske Power BI-modeller og Analysis Services.
Bemærk
Når en model opretter forbindelse til en tabelmodel, men ikke udvider den med yderligere data, er det ikke en sammensat model. I dette tilfælde er det en DirectQuery-model, der opretter forbindelse til en ekstern model – så den består kun af én kildegruppe. Du kan oprette denne type model for at ændre egenskaberne for kildemodelobjektet, f.eks. et tabelnavn, en kolonnesorteringsrækkefølge eller en formatstreng.
Forbind ing til tabelmodeller er især relevant, når du udvider en semantisk virksomhedsmodel (når det er en semantisk Power BI-model eller Analysis Services-model). En semantisk virksomhedsmodel er grundlæggende for udviklingen og driften af et data warehouse. Det giver et abstraktionslag over dataene i data warehouse'et for at præsentere forretningsdefinitioner og -terminologi. Den bruges ofte som et link mellem fysiske datamodeller og rapporteringsværktøjer, f.eks. Power BI. I de fleste organisationer administreres det af et centralt team, og derfor beskrives det som virksomhed. Du kan få flere oplysninger i virksomheds-BI-forbrugsscenariet.
Du kan overveje at udvikle en sammensat model i følgende situationer.
- Din model kan være en DirectQuery-model, og du vil øge ydeevnen. I en sammensat model kan du forbedre ydeevnen ved at konfigurere et passende lager for hver tabel. Du kan også tilføje brugerdefinerede sammenlægninger. Begge disse optimeringer beskrives senere i denne artikel.
- Du vil kombinere en DirectQuery-model med flere data, som skal importeres i modellen. Du kan indlæse importerede data fra en anden datakilde eller fra beregnede tabeller.
- Du vil kombinere to eller flere DirectQuery-datakilder i en enkelt model. Disse kilder kan være relationsdatabaser eller andre tabelmodeller.
Bemærk
Sammensatte modeller kan ikke indeholde forbindelser til visse eksterne analysedatabaser. Disse databaser omfatter SAP Business Warehouse og SAP HANA, når SAP HANA behandles som en flerdimensionel kilde.
Evaluer andre modeldesignindstillinger
Selvom sammensatte Power BI-modeller kan løse bestemte designudfordringer, kan de bidrage til langsom ydeevne. I nogle situationer kan der også forekomme uventede beregningsresultater (beskrevet senere i denne artikel). Af disse årsager skal du evaluere andre modeldesignindstillinger, når de findes.
Når det er muligt, er det bedst at udvikle en model i importtilstand. Denne tilstand giver den største designfleksibilitet og bedste ydeevne.
Udfordringer, der er relateret til store datamængder eller rapportering om data i næsten realtid, kan dog ikke altid løses ved hjælp af importmodeller. I begge tilfælde kan du overveje en DirectQuery-model, hvis dine data gemmes i en enkelt datakilde, der understøttes af DirectQuery-tilstand. Du kan finde flere oplysninger under DirectQuery-modeller i Power BI Desktop.
Tip
Hvis dit mål kun er at udvide en eksisterende tabelmodel med flere data, når det er muligt, skal du føje disse data til den eksisterende datakilde.
Tabellagringstilstand
I en sammensat model kan du angive lagringstilstanden for hver tabel (undtagen beregnede tabeller).
- DirectQuery: Vi anbefaler, at du angiver denne tilstand for tabeller, der repræsenterer store datamængder, eller som skal levere resultater i næsten realtid. Data importeres aldrig til disse tabeller. Normalt vil disse tabeller være tabeller af faktatypen, som er tabeller, der opsummeres.
- Import: Vi anbefaler, at du angiver denne tilstand for tabeller, der ikke bruges til filtrering og gruppering af faktatabeller i Tilstanden DirectQuery eller Hybrid. Det er også den eneste indstilling for tabeller, der er baseret på kilder, der ikke understøttes af DirectQuery-tilstand. Beregnede tabeller er altid importtabeller.
- Dual: Vi anbefaler, at du angiver denne tilstand for tabeller af dimensionstypen, når der er en mulighed for, at de forespørges sammen med DirectQuery-faktatypetabeller fra den samme kilde.
- Hybrid: Vi anbefaler, at du angiver denne tilstand ved at føje importpartitioner og én DirectQuery-partition til en faktatabel, når du vil medtage de seneste dataændringer i realtid, eller når du vil give hurtig adgang til de hyppigst anvendte data via importpartitioner, samtidig med at du forlader størstedelen af de data, der bruges sjældnere i data warehouse'et.
Der er flere mulige scenarier, når Power BI forespørger en sammensat model.
- Forespørgsler importerer kun eller to tabeller: Power BI henter alle data fra modelcachen. Det vil levere den hurtigst mulige ydeevne. Dette scenarie er almindeligt for tabeller af dimensionstypen, der forespørges af filtre eller visualiseringer i udsnit.
- Forespørger dual table(s) eller DirectQuery-tabeller fra den samme kilde: Power BI henter alle data ved at sende en eller flere oprindelige forespørgsler til DirectQuery-kilden. Det giver en god ydeevne, især når der findes relevante indeks i kildetabellerne. Dette scenarie er almindeligt for forespørgsler, der relaterer tabeller af dobbelt dimensionstypen og DirectQuery-faktatypetabeller. Disse forespørgsler er en intern kildegruppe, og derfor evalueres alle en til en- eller en til mange-relationer som almindelige relationer.
- Forespørger om dual table(s) eller hybride tabel(er) fra den samme kilde: Dette scenarie er en kombination af de forrige to scenarier. Power BI henter data fra modelcachen, når de er tilgængelige i importpartitioner, ellers sender det en eller flere oprindelige forespørgsler til DirectQuery-kilden. Den leverer den hurtigst mulige ydeevne, fordi der kun sendes en forespørgsel til et udsnit af dataene i data warehouse'et, især når der findes relevante indekser i kildetabellerne. Hvad angår tabeller af dobbelt dimensionstypen og DirectQuery-faktatabeller, er disse forespørgsler en intern kildegruppe, og derfor evalueres alle en til en- eller en til mange-relationer som almindelige relationer.
- Alle andre forespørgsler: Disse forespørgsler omfatter relationer på tværs af kildegrupper. Det skyldes enten, at en importtabel er relateret til en DirectQuery-tabel, eller at en dobbelt tabel er relateret til en DirectQuery-tabel fra en anden kilde – i så fald fungerer den som en importtabel. Alle relationer evalueres som begrænsede relationer. Det betyder også, at grupperinger, der anvendes på ikke-DirectQuery-tabeller, skal sendes til DirectQuery-kilden som materialiserede underforespørgsler (virtuelle tabeller). I dette tilfælde kan den oprindelige forespørgsel være ineffektiv, især for store grupperingssæt.
Kort sagt anbefaler vi, at du:
- Overvej nøje, at en sammensat model er den rigtige løsning – mens den muliggør integration på modelniveau af forskellige datakilder, introducerer den også designkompleksiteter med mulige konsekvenser (beskrevet senere i denne artikel).
- Angiv lagringstilstanden til DirectQuery , når en tabel er en tabel af faktatypen, der lagrer store datamængder, eller når den skal levere resultater i næsten realtid.
- Overvej at bruge hybridtilstand ved at definere en trinvis opdateringspolitik og data i realtid eller ved at partitionere faktatabellen ved hjælp af TOM, TMSL eller et tredjepartsværktøj. Du kan få flere oplysninger under Trinvis opdatering og data i realtid for semantiske modeller og scenariet for administration af avancerede datamodeller.
- Angiv lagringstilstanden til Dual , når en tabel er en tabel af dimensionstypen, og den forespørges sammen med DirectQuery eller hybride tabeller af faktatypen, der findes i den samme kildegruppe.
- Angiv relevante opdateringsfrekvenser for at holde modelcachen for dual- og hybridtabeller (og eventuelle afhængige beregnede tabeller) synkroniseret med kildedatabaserne.
- Stræb efter at sikre dataintegritet på tværs af kildegrupper (herunder modelcachen), fordi begrænsede relationer fjerner rækker i forespørgselsresultater, når relaterede kolonneværdier ikke stemmer overens.
- Når det er muligt, skal du optimere DirectQuery-datakilder med relevante indekser for at opnå effektive joinforbindelser, filtrering og gruppering.
Brugerdefinerede sammenlægninger
Du kan føje brugerdefinerede sammenlægninger til DirectQuery-tabeller. Deres formål er at forbedre ydeevnen for forespørgsler med større detaljering.
Når sammenlægninger cachelagres i modellen, fungerer de som importtabeller (selvom de ikke kan bruges som en modeltabel). Hvis du føjer importsammenlægninger til en DirectQuery-model, resulterer det i en sammensat model.
Bemærk
Hybridtabeller understøtter ikke sammenlægninger, fordi nogle af partitionerne fungerer i importtilstand. Det er ikke muligt at tilføje sammenlægninger på niveauet for en individuel DirectQuery-partition.
Vi anbefaler, at en sammenlægning følger en grundlæggende regel: Rækkeantallet skal være mindst en faktor på 10 mindre end den underliggende tabel. Hvis den underliggende tabel f.eks. gemmer 1 milliard rækker, må sammenlægningstabellen ikke overstige 100 millioner rækker. Denne regel sikrer, at der er en tilstrækkelig ydeevneforøgelse i forhold til omkostningerne ved at oprette og vedligeholde sammenlægningen.
Relationer på tværs af kildegrupper
Når en modelrelation strækker sig over kildegrupper, kaldes den en relation på tværs af kildegrupper. Relationer på tværs af kildegrupper er også begrænsede relationer, fordi der ikke er nogen garanteret "en"-side. Du kan få mere at vide under Evaluering af relationer.
Bemærk
I nogle situationer kan du undgå at oprette en relation på tværs af kildegrupper. Se emnet Brug synkroniser udsnit senere i denne artikel.
Når du definerer relationer på tværs af kildegrupper, skal du overveje følgende anbefalinger.
- Brug kolonner med relationer med lav kardinalitet: For at opnå den bedste ydeevne anbefales det, at relationskolonnerne er lav kardinalitet, hvilket betyder, at de skal gemme mindre end 50.000 entydige værdier. Denne anbefaling gælder især, når du kombinerer tabelmodeller og for kolonner, der ikke er tekst.
- Undgå at bruge store tekstrelationskolonner: Hvis du skal bruge tekstkolonner i en relation, skal du beregne den forventede tekstlængde for filteret ved at multiplicere kardinaliteten med tekstkolonnens gennemsnitlige længde. Den mulige tekstlængde må ikke overstige 1.000.000 tegn.
- Hæv relationsgranulariteten: Hvis det er muligt, skal du oprette relationer på et højere granularitetsniveau. I stedet for at relaterer en datotabel for datonøglen kan du f.eks. bruge månedsnøglen i stedet for. Denne designtilgang kræver, at den relaterede tabel indeholder en måneds nøglekolonne, og rapporter kan ikke vise daglige fakta.
- Stræb efter at opnå et simpelt relationsdesign: Opret kun en relation på tværs af kildegrupper, når det er nødvendigt, og prøv at begrænse antallet af tabeller i relationsstien. Denne designtilgang hjælper med at forbedre ydeevnen og undgå tvetydige relationsstier.
Advarsel!
Da Power BI Desktop ikke validerer relationer på tværs af kildegrupper grundigt, er det muligt at oprette tvetydige relationer.
Relationsscenarie på tværs af kildegrupper 1
Overvej et scenarie med et komplekst relationsdesign, og hvordan det kan give forskellige – men gyldige – resultater.
I dette scenarie har tabellen Region i kildegruppe A en relation til tabellen Date og tabellen Sales i kildegruppe B. Relationen mellem tabellen Region og tabellen Date er aktiv, mens relationen mellem tabellen Region og tabellen Sales er inaktiv. Der er også en aktiv relation mellem tabellen Region og tabellen Sales , som begge er i kildegruppe B. Tabellen Sales indeholder en måling med navnet TotalSales, og tabellen Region indeholder to målinger med navnet RegionalSales og RegionalSalesDirect.
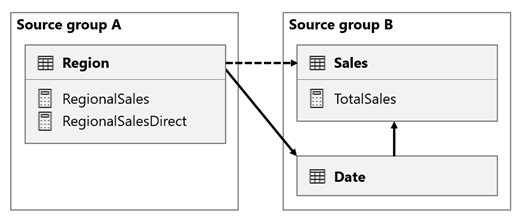
Her er målingsdefinitionerne.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Bemærk, hvordan målingen RegionalSales refererer til målingen TotalSales , mens målingen RegionalSalesDirect ikke gør. I stedet bruger målingen RegionalSalesDirect udtrykket SUM(Sales[Sales]), som er udtrykket for målingen TotalSales .
Forskellen i resultatet er diskret. Når Power BI evaluerer målingen RegionalSales , anvendes filteret fra tabellen Region på både tabellen Sales og tabellen Date . Filteret overføres derfor også fra tabellen Date til tabellen Sales . Når Power BI derimod evaluerer målingen RegionalSalesDirect , overføres filteret kun fra tabellen Region til tabellen Sales . De resultater, der returneres af målingen RegionalSales og målingen RegionalSalesDirect , kan variere, selvom udtrykkene er semantisk ækvivalente.
Vigtigt
Når du bruger funktionen CALCULATE med et udtryk, der er en måling i en ekstern kildegruppe, skal du teste beregningsresultaterne grundigt.
Relationsscenarie for tværgående kildegruppe 2
Overvej et scenarie, når en relation på tværs af kildegrupper har kolonner med relationer med høj kardinalitet.
I dette scenarie er tabellen Date relateret til tabellen Sales i kolonnerne DateKey . Datatypen for DateKey-kolonnerne er heltal, hvor hele tal, der bruger formatet yyyyymmdd, gemmes. Tabellerne tilhører forskellige kildegrupper. Det er desuden en relation med høj kardinalitet, fordi den tidligste dato i tabellen Dato er den 1. januar 1900, og den seneste dato er den 31. december 2100 – så der er i alt 73.414 rækker i tabellen (én række for hver dato i tidsperioden 1900-2100).
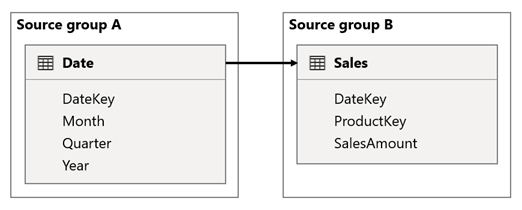
Der er to sager, der giver anledning til bekymring.
Når du først bruger kolonnerne i tabellen Dato som filtre, filtrerer filteroverførsel kolonnen DateKey i tabellen Sales for at evaluere målinger. Når du filtrerer efter et enkelt år, f.eks. 2022, indeholder DAX-forespørgslen et filterudtryk som .Sales[DateKey] IN { 20220101, 20220102, …20221231 } Forespørgslens tekststørrelse kan blive meget stor, når antallet af værdier i filterudtrykket er stort, eller når filterværdierne er lange strenge. Det er dyrt for Power BI at generere den lange forespørgsel og for datakilden at køre forespørgslen.
Når du for det andet bruger tabelkolonner af typen Date – f.eks . Year, Quarter eller Month – som grupperingskolonner, resulterer det i filtre, der indeholder alle entydige kombinationer af år, kvartal eller måned og kolonneværdierne DateKey . Strengstørrelsen for forespørgslen, som indeholder filtre på grupperingskolonnerne og relationskolonnen, kan blive meget stor. Det er især tilfældet, når antallet af grupperingskolonner og/eller kardinaliteten for joinkolonnen (kolonnen DateKey ) er stor.
Hvis du vil løse eventuelle problemer med ydeevnen, kan du:
- Føj tabellen Date til datakilden, hvilket resulterer i en enkelt kildegruppemodel (hvilket betyder, at den ikke længere er en sammensat model).
- Hæv granulariteten af relationen. Du kan f.eks. føje kolonnen MonthKey til begge tabeller og oprette relationen for disse kolonner. Men når du hæver relationens granularitet, mister du muligheden for at rapportere om den daglige salgsaktivitet (medmindre du bruger kolonnen DateKey fra tabellen Sales ).
Relationsscenarie på tværs af kildegrupper 3
Overvej et scenarie, hvor der ikke er matchende værdier mellem tabeller i en relation på tværs af kildegrupper.
I dette scenarie har tabellen Date i kildegruppe B en relation til tabellen Sales i den pågældende kildegruppe og også til tabellen Target i kildegruppe A. Alle relationer er én til mange fra tabellen Dato, der relaterer til kolonnerne Year. Tabellen Sales indeholder kolonnen SalesAmount , der gemmer salgsbeløb, mens tabellen Target indeholder en TargetAmount-kolonne , der indeholder målbeløb.
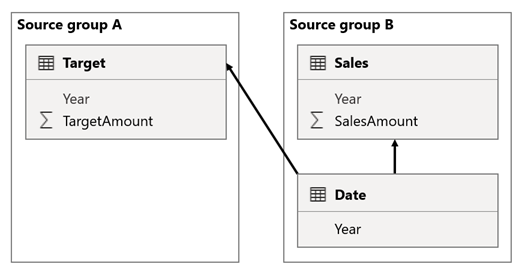
I tabellen Date gemmes årene 2021 og 2022. Tabellen Sales gemmer salgsbeløb for årene 2021 (100) og 2022 (200), mens målbeløbene for 2021 (100), 2022 (200) og 2023 (300) gemmes i tabellen Mål – et kommende år.
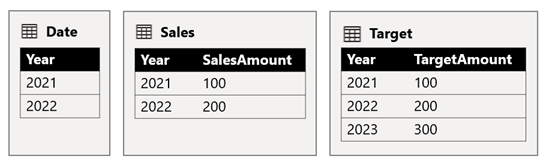
Når en power BI-tabelvisualisering forespørger den sammensatte model ved at gruppere efter kolonnen Year fra tabellen Date og opsummere kolonnerne SalesAmount og TargetAmount , vises der ikke et målbeløb for 2023. Det skyldes, at relationen på tværs af kildegrupper er en begrænset relation, og derfor bruger INNER JOIN den semantik, hvilket eliminerer rækker, hvor der ikke er nogen tilsvarende værdi på begge sider. Det vil dog give et korrekt målbeløb i alt (600), fordi et filter i tabellen Date ikke gælder for evalueringen.
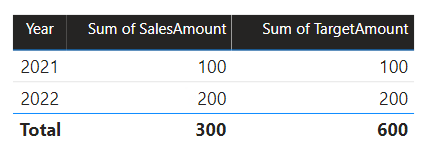
Hvis relationen mellem tabellen Date og tabellen Target er en intern kildegrupperelation (under forudsætning af , at tabellen Mål tilhørte kildegruppe B), indeholder visualiseringen et (Tomt) år til at vise målbeløbet for 2023 (og andre år, der ikke stemmer overens).
Vigtigt
Hvis du vil undgå fejlrapportering, skal du sikre dig, at der er matchende værdier i relationskolonnerne, når dimensions- og faktatabeller er placeret i forskellige kildegrupper.
Du kan få flere oplysninger om begrænsede relationer under Evaluering af relationer.
Beregninger
Du bør overveje specifikke begrænsninger, når du føjer beregnede kolonner og beregningsgrupper til en sammensat model.
Beregnede kolonner
Beregnede kolonner, der føjes til en DirectQuery-tabel, der henter deres data fra en relationsdatabase, f.eks. Microsoft SQL Server, er begrænset til udtryk, der fungerer på en enkelt række ad gangen. Disse udtryk kan ikke bruge DAX-iteratorfunktioner, f.eks SUMX. , eller funktioner til ændring af filterkontekst, f.eks CALCULATE. .
Bemærk
Det er ikke muligt at tilføje beregnede kolonner eller beregnede tabeller, der afhænger af sammenkædede tabelmodeller.
Et beregnet kolonneudtryk i en ekstern DirectQuery-tabel er kun begrænset til evaluering inden for række. Du kan dog oprette et sådant udtryk, men det resulterer i en fejl, når det bruges i en visualisering. Hvis du f.eks. føjer en beregnet kolonne til en ekstern DirectQuery-tabel med navnet DimProduct ved hjælp af udtrykket [Product Sales] / SUM (DimProduct[ProductSales]), kan du gemme udtrykket i modellen. Det vil dog resultere i en fejl, når den bruges i en visualisering, fordi den overtræder begrænsningen for evaluering inden for række.
I modsætning hertil er beregnede kolonner, der føjes til en ekstern DirectQuery-tabel, som er en tabelmodel, som enten er en semantisk Power BI-model eller Analysis Services-model, mere fleksible. I dette tilfælde er alle DAX-funktioner tilladt, fordi udtrykket evalueres i kilde-tabelmodellen.
Mange udtryk kræver, at Power BI materialiserer den beregnede kolonne, før den bruges som en gruppe eller et filter eller aggregerer den. Når en beregnet kolonne materialiseres over en stor tabel, kan det være dyrt med hensyn til CPU og hukommelse, afhængigt af kardinaliteten af de kolonner, som den beregnede kolonne afhænger af. I dette tilfælde anbefaler vi, at du føjer disse beregnede kolonner til kildemodellen.
Bemærk
Når du føjer beregnede kolonner til en sammensat model, skal du sørge for at teste alle modelberegninger. Upstream-beregninger fungerer muligvis ikke korrekt, fordi de ikke overvejede deres indflydelse på filterkonteksten.
Beregningsgrupper
Hvis der findes beregningsgrupper i en kildegruppe, der opretter forbindelse til en semantisk Power BI-model eller en Analysis Services-model, kan Power BI returnere uventede resultater. Du kan få flere oplysninger under Beregningsgrupper, evaluering af forespørgsler og målinger.
Modeldesign
Du bør altid optimere en Power BI-model ved at bruge et stjerneskemadesign.
Tip
Du kan få flere oplysninger under Forstå stjerneskemaet og vigtigheden af Power BI.
Sørg for at oprette dimensionstabeller, der er adskilt fra faktatabeller, så Power BI kan fortolke joinforbindelser korrekt og oprette effektive forespørgselsplaner. Selvom denne vejledning gælder for alle Power BI-modeller, er det især tilfældet for modeller, som du genkender, bliver en kildegruppe for en sammensat model. Det vil muliggøre en enklere og mere effektiv integration af andre tabeller i downstream-modeller.
Når det er muligt, skal du undgå at have dimensionstabeller i én kildegruppe, der er relateret til en faktatabel i en anden kildegruppe. Det skyldes, at det er bedre at have interne kildegrupperelationer end relationer på tværs af kildegrupper, især for kolonner med relationer med høj kardinalitet. Som beskrevet tidligere er relationer på tværs af kildegrupper afhængige af, at der er matchende værdier i relationskolonnerne, ellers kan der vises uventede resultater i rapportvisualiseringer.
Sikkerhed på rækkeniveau
Hvis din model indeholder brugerdefinerede sammenlægninger, beregnede kolonner i importtabeller eller beregnede tabeller, skal du sikre dig, at sikkerhed på rækkeniveau (RLS) er konfigureret korrekt og testet.
Hvis den sammensatte model opretter forbindelse til andre tabelmodeller, anvendes RLS-regler kun på den kildegruppe (lokal model), hvor de er defineret. De anvendes ikke på andre kildegrupper (fjernmodeller). Du kan heller ikke definere regler for sikkerhed på rækkeniveau i en tabel fra en anden kildegruppe, og du kan heller ikke definere RLS-regler for en lokal tabel, der har en relation til en anden kildegruppe.
Rapportdesign
I nogle situationer kan du forbedre ydeevnen for en sammensat model ved at designe et optimeret rapportlayout.
Visualiseringer af en enkelt kildegruppe
Når det er muligt, skal du oprette visualiseringer, der bruger felter fra en enkelt kildegruppe. Det skyldes, at forespørgsler, der genereres af visualiseringer, fungerer bedre, når resultatet hentes fra en enkelt kildegruppe. Overvej at oprette to visualiseringer, der er placeret side om side, og som henter data fra to forskellige kildegrupper.
Brug synkroniser udsnit
I nogle situationer kan du konfigurere synkroniseringsudsnit for at undgå at oprette en relation på tværs af kildegrupper i din model. Det kan give dig mulighed for visuelt at kombinere kildegrupper, der kan fungere bedre.
Overvej et scenarie, når din model har to kildegrupper. Hver kildegruppe har en produktdimensionstabel, der bruges til at filtrere forhandler- og internetsalg.
I dette scenarie indeholder kildegruppe A den produkttabel , der er relateret til tabellen ResellerSales . Kildegruppe B indeholder tabellen Product2 , der er relateret til tabellen InternetSales . Der er ikke nogen relationer på tværs af kildegrupper.
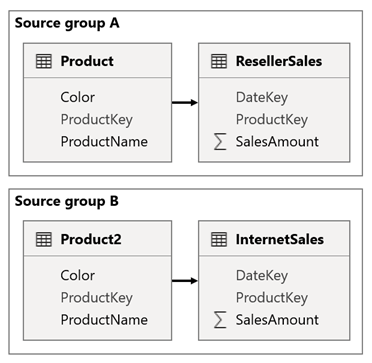
I rapporten kan du tilføje et udsnit, der filtrerer siden ved hjælp af kolonnen Color i tabellen Product . Udsnittet filtrerer som standard tabellen ResellerSales , men ikke tabellen InternetSales . Du tilføjer derefter et skjult udsnitsværktøj ved hjælp af kolonnen Color i tabellen Product2. Ved at angive et identisk gruppenavn (findes i avancerede indstillinger for synkroniseringsudsnit), overføres filtre, der er anvendt på det synlige udsnit, automatisk til det skjulte udsnit.
Bemærk
Når du bruger synkroniseringsudsnit, kan du undgå behovet for at oprette en relation på tværs af kildegrupper, men det øger kompleksiteten af modeldesignet. Sørg for at oplære andre brugere i, hvorfor du har designet modellen med duplikerede dimensionstabeller. Undgå forvirring ved at skjule dimensionstabeller, som andre brugere ikke skal bruge. Du kan også føje beskrivelsestekst til de skjulte tabeller for at dokumentere deres formål.
Du kan få flere oplysninger under Synkroniser separate udsnit.
Anden vejledning
Her er nogle andre vejledninger, der kan hjælpe dig med at designe og vedligeholde sammensatte modeller.
- Ydeevne og skalering: Hvis dine rapporter tidligere var direkte forbundet til en semantisk Power BI-model eller Analysis Services-model, kan Power BI-tjeneste genbruge visuelle cachelagre på tværs af rapporter. Når du har konverteret den direkte forbindelse for at oprette en lokal DirectQuery-model, vil rapporter ikke længere drage fordel af disse cacher. Derfor kan du opleve langsommere ydeevne eller endda opdateringsfejl. Arbejdsbelastningen for Power BI-tjeneste øges også, hvilket kan kræve, at du skalerer kapaciteten op eller distribuerer arbejdsbelastningen på tværs af andre kapaciteter. Du kan få flere oplysninger om dataopdatering og cachelagring under Opdatering af data i Power BI.
- Omdøbning: Vi anbefaler ikke, at du omdøber semantiske modeller, der bruges af sammensatte modeller, eller omdøber deres arbejdsområder. Det skyldes, at sammensatte modeller opretter forbindelse til semantiske Power BI-modeller ved hjælp af navnene på arbejdsområdet og semantiske modeller (og ikke deres interne entydige id'er). Hvis du omdøber en semantisk model eller et arbejdsområde, kan det ødelægge de forbindelser, der bruges af din sammensatte model.
- Styring: Vi anbefaler ikke, at din enkelt version af sandhedsmodellen er en sammensat model. Det skyldes, at det vil være afhængigt af andre datakilder eller modeller, som, hvis de opdateres, kan resultere i, at den sammensatte model brydes. Vi anbefaler i stedet, at du publicerer en semantisk virksomhedsmodel som den enkelte version af sandheden. Betragt denne model som et pålideligt fundament. Andre dataudformere kan derefter oprette sammensatte modeller, der udvider basismodellen til at oprette specialiserede modeller.
- Dataafstamning: Brug funktionerne til effektanalyse af dataafstamning og semantisk model, før du publicerer ændringer af sammensatte modeller. Disse funktioner er tilgængelige i Power BI-tjeneste, og de kan hjælpe dig med at forstå, hvordan semantiske modeller er relaterede og bruges. Det er vigtigt at forstå, at du ikke kan udføre effektanalyse på eksterne semantiske modeller, der vises i afstamningsvisning, men faktisk er placeret i et andet arbejdsområde. Hvis du vil udføre effektanalyse på en ekstern semantisk model, skal du navigere til kildearbejdsområdet.
- Skemaopdateringer: Du bør opdatere din sammensatte model i Power BI Desktop, når der foretages skemaændringer i upstream-datakilder. Du skal derefter publicere modellen igen på Power BI-tjeneste. Sørg for at teste beregninger og afhængige rapporter grundigt.
Relateret indhold
Du kan få flere oplysninger, der er relateret til denne artikel, i følgende ressourcer.
- Bruge sammensatte modeller i Power BI Desktop
- Modelrelationer i Power BI Desktop
- DirectQuery-modeller i Power BI Desktop
- Brug DirectQuery i Power BI Desktop
- Brug af DirectQuery til semantiske Power BI-modeller og Analysis Services
- Lagringstilstand i Power BI Desktop
- Brugerdefinerede sammenlægninger
- Spørgsmål? Prøv at spørge Power BI-community'et
- Forslag? Bidrag med idéer til forbedring af Power BI