Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Microsoft Dataverse er standarddataplatformen for mange Microsoft-virksomhedsprogramprodukter, herunder Dynamics 365 Customer Engagement - og Power Apps-lærredsapps og også Dynamics 365 Customer Voice (tidligere Microsoft Forms Pro), Power Automate-godkendelser, Power Apps-portaler og andre.
Denne artikel indeholder en vejledning i, hvordan du opretter en Power BI-datamodel, der opretter forbindelse til Dataverse. Den beskriver forskellene mellem et Dataverse-skema og et optimeret Power BI-skema, og den indeholder en vejledning i at udvide synligheden af dine virksomhedsprogramdata i Power BI.
På grund af den lette konfiguration, hurtige udrulning og omfattende implementering gemmer og administrerer Dataverse en stigende mængde data i miljøer på tværs af organisationer. Det betyder, at der er et endnu større behov – og en endnu større mulighed – for at integrere analyser i disse processer. Salgsmuligheder omfatter:
- Rapportér om alle Dataverse-data, der går ud over begrænsningerne i de indbyggede diagrammer.
- Giv nem adgang til relevante, kontekstfiltrerede rapporter i en bestemt post.
- Gør værdien af Dataverse-data bedre ved at integrere dem med eksterne data.
- Udnyt Power BI's indbyggede kunstig intelligens (AI) uden at skulle skrive kompleks kode.
- Øg indførelsen af Power Platform-løsninger ved at øge deres anvendelighed og værdi.
- Levér værdien af dataene i din app til virksomhedens beslutningstagere.
Opret forbindelse mellem Power BI og Dataverse
Oprettelse af forbindelse mellem Power BI og Dataverse omfatter oprettelse af en Power BI-datamodel. Du kan vælge mellem tre metoder til at oprette en Power BI-model.
- Importér dataverse-data ved hjælp af Dataverse-connectoren: Denne metode cachelagrer (gemmer) Dataverse-data i en Power BI-model. Den leverer hurtig ydeevne takket være forespørgsler i hukommelsen. Det giver også designfleksibilitet til modeludviklere, så de kan integrere data fra andre kilder. På grund af disse styrker er import af data standardtilstanden, når du opretter en model i Power BI Desktop.
- Importér dataverse-data ved hjælp af Azure Synapse Link: Denne metode er en variation af importmetoden, fordi den også cachelagrer data i Power BI-modellen, men gør det ved at oprette forbindelse til Azure Synapse Analytics. Ved hjælp af Azure Synapse Link til Dataverse replikeres Dataverse-tabeller løbende til Azure Synapse eller AdLS (Azure Data Lake Storage) Gen2. Denne fremgangsmåde bruges til at rapportere om hundredtusinder eller endda millioner af poster i Dataverse-miljøer.
- Opret en DirectQuery-forbindelse ved hjælp af Dataverse-connectoren: Denne metode er et alternativ til import af data. En DirectQuery-model består kun af metadata, der definerer modelstrukturen. Når en bruger åbner en rapport, sender Power BI oprindelige forespørgsler til Dataverse for at hente data. Overvej at oprette en DirectQuery-model, når rapporter skal vise data i næsten realtid, eller når Dataverse skal gennemtvinge rollebaseret sikkerhed, så brugerne kun kan se de data, de har adgangsrettigheder til.
Vigtigt
Selvom en DirectQuery-model kan være et godt alternativ, når du har brug for rapportering i nærheden af realtid eller håndhævelse af Dataverse-sikkerhed i en rapport, kan det resultere i langsom ydeevne for den pågældende rapport.
Du kan få mere at vide om overvejelser i forbindelse med DirectQuery senere i denne artikel.
Hvis du vil finde den rigtige metode til din Power BI-model, skal du overveje:
- Forespørgselsydeevne
- Datamængde
- Dataventetid
- Rollebaseret sikkerhed
- Konfiguration af kompleksitet
Tips
Du kan finde en detaljeret diskussion om modelmodeller (import, DirectQuery eller sammensat), deres fordele og begrænsninger og funktioner, der hjælper med at optimere Power BI-datamodeller, under Vælg en Power BI-modelstruktur.
Forespørgselsydeevne
Forespørgsler, der sendes til importmodeller, er hurtigere end oprindelige forespørgsler, der sendes til DirectQuery-datakilder. Det skyldes, at importerede data cachelagres i hukommelsen, og at de er optimeret til analyseforespørgsler (filter-, gruppe- og opsummeringshandlinger).
Omvendt henter DirectQuery-modeller kun data fra kilden, når brugeren åbner en rapport, hvilket resulterer i sekunders forsinkelse, efterhånden som rapporten gengives. Derudover kræver brugerinteraktioner i rapporten, at Power BI genforespørger kilden, hvilket reducerer svartid yderligere.
Datamængde
Når du udvikler en importmodel, skal du bestræbe dig på at minimere de data, der indlæses i modellen. Det gælder især for store modeller, eller modeller, som du forventer, vil vokse og blive store med tiden. Du kan få flere oplysninger under Teknikker til datareduktion i forbindelse med importmodellering.
En DirectQuery-forbindelse til Dataverse er et godt valg, når rapportens forespørgselsresultat ikke er stort. Et stort forespørgselsresultat har mere end 20.000 rækker i rapportens kildetabeller, eller det resultat, der returneres til rapporten, efter at filtrene er anvendt, er mere end 20.000 rækker. I dette tilfælde kan du oprette en Power BI-rapport ved hjælp af Dataverse-connectoren.
Bemærk
Rækkestørrelsen på 20.000 er ikke en hård grænse. Hver datakildeforespørgsel skal dog returnere et resultat inden for 10 minutter. Senere i denne artikel får du mere at vide om, hvordan du arbejder med disse begrænsninger og om andre overvejelser i forbindelse med DirectQuery-design af Dataverse.
Du kan forbedre ydeevnen for større semantiske modeller ved hjælp af Dataverse-connectoren til at importere dataene i datamodellen.
Endnu større semantiske modeller – med flere hundrede tusinde eller endda millioner af rækker – kan drage fordel af at bruge Azure Synapse Link til Dataverse. Denne fremgangsmåde konfigurerer en løbende administreret pipeline, der kopierer Dataverse-data til ADLS Gen2 som CSV- eller Parquet-filer. Power BI kan derefter forespørge en Serveruafhængig SQL-gruppe i Azure Synapse om at indlæse en importmodel.
Dataventetid
Når dataversedataene ændres hurtigt, og rapportbrugerne har brug for at se opdaterede data, kan en DirectQuery-model levere forespørgselsresultater i næsten realtid.
Tips
Du kan oprette en Power BI-rapport, der bruger automatisk sideopdatering til at vise opdateringer i realtid, men kun når rapporten opretter forbindelse til en DirectQuery-model.
Importér datamodeller skal fuldføre en dataopdatering for at tillade rapportering om seneste dataændringer. Vær opmærksom på, at der er begrænsninger for antallet af daglige planlagte dataopdateringshandlinger. Du kan planlægge op til otte opdateringer pr. dag på en delt kapacitet. På en Premium-kapacitet eller Microsoft Fabric-kapacitet kan du planlægge op til 48 opdateringer pr. dag, hvilket kan opnå en opdateringshyppighed på 15 minutter.
Vigtigt
Denne artikel henviser til Power BI Premium eller dets kapacitetsabonnementer (P-SKU'er). Microsoft konsoliderer i øjeblikket købsmuligheder og udfaser Power BI Premium-SKU'erne pr. kapacitet. Nye og eksisterende kunder bør overveje at købe Fabric-kapacitetsabonnementer (F SKU'er) i stedet.
Du kan få flere oplysninger under Vigtige opdateringer, der kommer til Power BI Premium-licenser og Ofte stillede spørgsmål om Power BI Premium.
Du kan også overveje at bruge trinvis opdatering til at opnå hurtigere opdateringer og næsten ydeevne i realtid (kun tilgængelig med Premium eller Fabric).
Rollebaseret sikkerhed
Når der er behov for at gennemtvinge rollebaseret sikkerhed, kan det påvirke valget af Power BI-modelstruktur direkte.
Dataverse kan gennemtvinge kompleks rollebaseret sikkerhed for at styre adgangen for bestemte poster til bestemte brugere. En sælger kan f.eks. få tilladelse til kun at se sine salgsmuligheder, mens salgschefen kan se alle salgsmuligheder for alle sælgere. Du kan skræddersy kompleksitetsniveauet baseret på organisationens behov.
En DirectQuery-model, der er baseret på Dataverse, kan oprette forbindelse ved hjælp af rapportbrugerens sikkerhedskontekst. På den måde kan rapportbrugeren kun se de data, vedkommende har tilladelse til at få adgang til. Denne fremgangsmåde kan forenkle rapportdesignet, hvilket giver en acceptabel ydeevne.
Du kan forbedre ydeevnen ved at oprette en importmodel, der i stedet opretter forbindelse til Dataverse. I dette tilfælde kan du føje sikkerhed på rækkeniveau til modellen, hvis det er nødvendigt.
Bemærk
Det kan være en udfordring at replikere visse dataverse-rollebaserede sikkerhed som Power BI RLS, især når Dataverse gennemtvinger komplekse tilladelser. Det kan desuden kræve løbende administration at holde Power BI-tilladelser synkroniseret med Dataverse-tilladelser.
Du kan finde flere oplysninger om Sikkerhed på rækkeniveau i Vejledning til sikkerhed på rækkeniveau i Power BI Desktop.
Konfiguration af kompleksitet
Brug af Dataverse-connectoren i Power BI – uanset om det er til import eller DirectQuery-modeller – er ligetil og kræver ikke nogen særlig software eller administratorrettigheder til Dataverse. Det er en fordel for organisationer eller afdelinger, der er ved at komme i gang.
Indstillingen Azure Synapse Link kræver systemadministratoradgang til Dataverse og visse Azure-tilladelser. Disse Azure-tilladelser kræves for at konfigurere lagerkontoen og et Synapse-arbejdsområde.
Anbefalede fremgangsmåder
I dette afsnit beskrives designmønstre (og antimønstre), som du bør overveje, når du opretter en Power BI-model, der opretter forbindelse til Dataverse. Kun nogle få af disse mønstre er unikke for Dataverse, men de er som regel almindelige udfordringer for Dataverse-oprettere, når de bygger Power BI-rapporter.
Fokuser på en bestemt use case
I stedet for at forsøge at løse alt, skal du fokusere på den specifikke use case.
Denne anbefaling er sandsynligvis den mest almindelige og let den mest udfordrende anti-mønster at undgå. Det er en udfordring at forsøge at oprette en enkelt model, der opfylder alle behov for selvbetjeningsrapportering. Virkeligheden er, at vellykkede modeller er bygget til at besvare spørgsmål om et centralt sæt fakta om et enkelt kerneemne. Selvom det i første omgang kan synes at begrænse modellen, er det faktisk bemyndigelse, fordi du kan justere og optimere modellen til at besvare spørgsmål i dette emne.
For at sikre, at du har en klar forståelse af modellens formål, skal du stille dig selv følgende spørgsmål.
- Hvilket emneområde understøtter denne model?
- Hvem er målgruppen for rapporterne?
- Hvilke spørgsmål forsøger rapporterne at besvare?
- Hvad er den minimale levedygtige semantiske model?
Undgå at kombinere flere emneområder i en enkelt model, bare fordi rapportbrugeren har spørgsmål på tværs af flere emneområder, som vedkommende vil have behandlet i en enkelt rapport. Ved at opdele rapporten i flere rapporter, der hver især fokuserer på et andet emne (eller en faktatabel), kan du producere meget mere effektive, skalerbare og håndterbare modeller.
Design et stjerneskema
Dataverse-udviklere og -administratorer, der er fortrolige med Dataverse-skemaet, kan blive fristet til at genskabe det samme skema i Power BI. Denne tilgang er et anti-mønster, og det er sandsynligvis den sværeste at overvinde, fordi det bare føles rigtigt at opretholde konsistens.
Dataverse er som relationsmodel velegnet til formålet. Det er dog ikke designet som en analysemodel, der er optimeret til analyserapporter. Det mest udbredte mønster for modellering af analysedata er et stjerneskemadesign . Stjerneskema er en moden modelmetode, der er almindeligt anvendt af relationsdata warehouses. Det kræver, at modeludviklere klassificerer deres modeltabeller som enten dimension eller fakta. Rapporter kan filtrere eller gruppere ved hjælp af dimensionstabel kolonner og opsummere kolonner i faktatabellen.
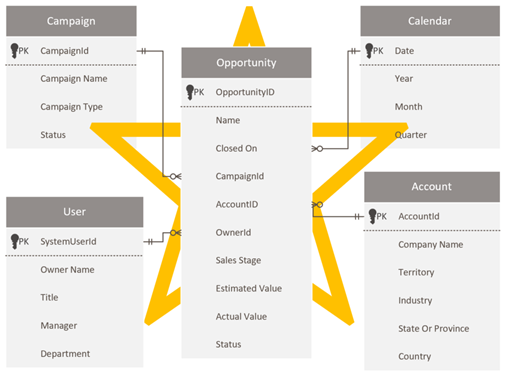
Du kan få flere oplysninger under Forstå stjerneskemaet og vigtigheden af Power BI.
Optimer Power Query-forespørgsler
Power Query-miksprogrammet bestræber sig på at opnå forespørgselsdelegering , når det er muligt af hensyn til effektiviteten. En forespørgsel, der opnår, at delegering af stedfortrædere behandles i kildesystemet.
I dette tilfælde Dataverse skal kildesystemet kun levere filtrerede eller opsummerede resultater til Power BI. En foldet forespørgsel er ofte betydeligt hurtigere og mere effektiv end en forespørgsel, der ikke foldes.
Du kan finde flere oplysninger om, hvordan du kan opnå forespørgselsdelegering, under Forespørgselsdelegering i Power Query.
Bemærk
Optimering af Power Query er et bredt emne. Se Forespørgselsdiagnosticering for at få en bedre forståelse af, hvad Power Query gør ved oprettelse og opdatering af modeller i Power BI Desktop.
Minimer antallet af forespørgselskolonner
Når du bruger Power Query til at indlæse en Dataverse-tabel, hentes alle rækker og alle kolonner som standard. Når du forespørger en systembrugertabel, kan den f.eks. indeholde mere end 1.000 kolonner. Kolonnerne i metadataene omfatter relationer til andre objekter og opslag i indstillingsmærkater, så det samlede antal kolonner vokser med kompleksiteten i tabellen Dataverse.
Forsøg på at hente data fra alle kolonner er et antimønster. Det resulterer ofte i udvidede dataopdateringshandlinger, og det medfører, at forespørgslen mislykkes, når den tid, det tager at returnere dataene, overstiger 10 minutter.
Vi anbefaler, at du kun henter kolonner, der kræves af rapporter. Det er ofte en god idé at evaluere og omstrukturere forespørgsler, når rapportudvikling er fuldført, så du kan identificere og fjerne kolonner, der ikke bruges. Du kan få flere oplysninger under Teknikker til datareduktion til importmodellering (Fjern unødvendige kolonner).
Sørg desuden for, at du introducerer trinnet Fjern kolonner i Power-forespørgsel tidligt, så det kan foldes tilbage til kilden. På den måde kan Power Query undgå det unødvendige arbejde med kun at udtrække kildedata for at kassere dem senere (i et udfoldet trin).
Når du har en tabel, der indeholder mange kolonner, kan det være upraktisk at bruge den interaktive forespørgselsgenerator i Power Query. I dette tilfælde kan du starte med at oprette en tom forespørgsel. Du kan derefter bruge Avanceret editor til at indsætte en minimal forespørgsel, der opretter et startpunkt.
Overvej følgende forespørgsel, der henter data fra blot to kolonner i tabellen account.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Skriv oprindelige forespørgsler
Når du har specifikke transformationskrav, kan du opnå bedre ydeevne ved hjælp af en oprindelig forespørgsel, der er skrevet i Dataverse SQL, som er et undersæt af Transact-SQL. Du kan skrive en oprindelig forespørgsel til:
- Reducer antallet af rækker (ved hjælp af en
WHEREdelsætning). - Aggregere data (ved hjælp af delsætningerne
GROUP BYogHAVING). - Joinforbind tabeller på en bestemt måde (ved hjælp af syntaksen
JOINellerAPPLY). - Brug understøttede SQL-funktioner.
Du kan finde flere oplysninger i:
Udfør oprindelige forespørgsler med indstillingen EnableFolding
Power Query udfører en oprindelig forespørgsel ved hjælp af funktionen Value.NativeQuery .
Når du bruger denne funktion, er det vigtigt at tilføje indstillingen EnableFolding=true for at sikre, at forespørgsler foldes tilbage til Dataverse-tjenesten. En oprindelig forespørgsel kan ikke foldes, medmindre denne indstilling tilføjes. Aktivering af denne indstilling kan resultere i betydelige forbedringer af ydeevnen – op til 97 % hurtigere i nogle tilfælde.
Overvej følgende forespørgsel, der bruger en oprindelig forespørgsel til at hente valgte kolonner fra den account tabel. Den oprindelige forespørgsel foldes, fordi indstillingen EnableFolding=true er angivet.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Du kan forvente at opnå de største forbedringer af ydeevnen, når du henter et undersæt af data fra en stor datamængde.
Tips
Forbedring af ydeevnen kan også afhænge af, hvordan Power BI forespørger kildedatabasen. En måling, der bruger COUNTDISTINCT DAX-funktionen, viste f.eks. næsten ingen forbedring med eller uden foldetip. Da målingsformlen blev omskrevet til at bruge SUMX DAX-funktionen, blev forespørgslen foldet, hvilket resulterede i en forbedring på 97 % i forhold til den samme forespørgsel uden tip.
Du kan finde flere oplysninger under Value.NativeQuery. (Indstillingen EnableFolding er ikke dokumenteret, fordi den kun er specifik for visse datakilder).
Fremskynde evalueringsfasen
Hvis du bruger Dataverse-connectoren (tidligere kaldet Common Data Service), kan du tilføje CreateNavigationProperties=false indstillingen for at fremskynde evalueringsfasen for en dataimport.
Evalueringsfasen for en dataimport gentages via metadataene for kilden for at bestemme alle mulige tabelrelationer. Disse metadata kan være omfattende, især for Dataverse. Når du føjer denne indstilling til forespørgslen, giver du Power Query besked om, at du ikke vil bruge disse relationer. Indstillingen gør det muligt for Power BI Desktop at springe denne fase af opdateringen over og gå videre til hentning af dataene.
Bemærk
Brug ikke denne indstilling, når forespørgslen afhænger af udvidede relationskolonner.
Overvej et eksempel, der henter data fra tabellen account. Den indeholder tre kolonner, der er relateret til område: territory, territoryidog territoryidname.
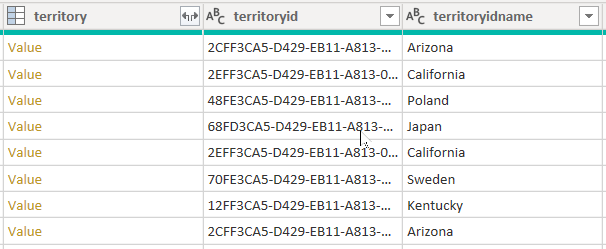
Når du angiver indstillingen CreateNavigationProperties=false, bevares kolonnerne territoryid og territoryidname, men den territory kolonne, som er en relationskolonne (den viser Value links), udelades. Det er vigtigt at forstå, at kolonner med Power Query-relationer er et andet koncept end modelrelationer, som overfører filtre mellem modeltabeller.
Overvej følgende forespørgsel, der bruger indstillingen CreateNavigationProperties=false (i kildetrinnet ) til at fremskynde evalueringsfasen for en dataimport.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Når du bruger denne indstilling, vil du sandsynligvis opleve en betydelig forbedring af ydeevnen, når en Dataverse-tabel har mange relationer til andre tabeller. Da den SystemUser tabel f.eks. er relateret til alle andre tabeller i databasen, vil det være en fordel at opdatere tabellens ydeevne ved at angive indstillingen CreateNavigationProperties=false.
Bemærk
Denne indstilling kan forbedre ydeevnen for opdatering af data for importtabeller eller tabeller med dobbelt lagringstilstand, herunder processen med at anvende Power Query-editor vinduesændringer. Det forbedrer ikke ydeevnen for interaktiv krydsfiltrering af DirectQuery-lagertilstandstabeller.
Løs tomme valgnavne
Hvis du opdager, at dataversevalgmærkater er tomme i Power BI, kan det skyldes, at mærkaterne ikke er publiceret til TDS-slutpunktet (Tabular Data Stream).
I dette tilfælde skal du åbne Dataverse-udviklerportalen, navigere til området Løsninger og derefter vælge Publicer alle tilpasninger. Publikationsprocessen opdaterer TDS-slutpunktet med de nyeste metadata, hvilket gør indstillingsmærkater tilgængelige for Power BI.
Større semantiske modeller med Azure Synapse Link
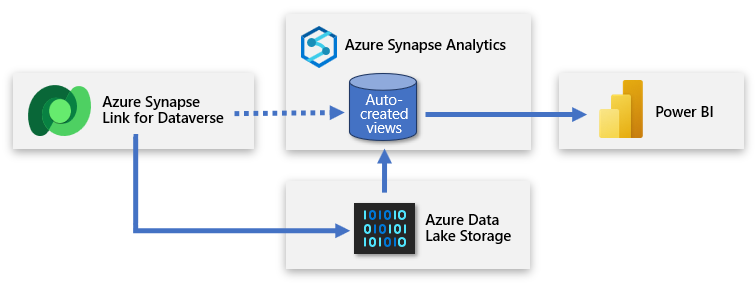
Dataverse indeholder muligheden for at synkronisere tabeller til Azure Data Lake Storage (ADLS) og derefter oprette forbindelse til disse data via et Azure Synapse-arbejdsområde. Med minimal indsats kan du konfigurere Azure Synapse Link for at udfylde Dataverse-data i Azure Synapse og gøre det muligt for datateams at få mere indsigt.
Azure Synapse Link muliggør en kontinuerlig replikering af data og metadata fra Dataverse til datasøen. Den indeholder også en indbygget serveruafhængig SQL-gruppe som en praktisk datakilde til Power BI-forespørgsler.
Styrkerne ved denne fremgangsmåde er betydelige. Kunder får mulighed for at køre analyse-, business intelligence- og machine learning-arbejdsbelastninger på tværs af Dataverse-data ved hjælp af forskellige avancerede tjenester. Avancerede tjenester omfatter Apache Spark, Power BI, Azure Data Factory, Azure Databricks og Azure Machine Learning.
Opret et Azure Synapse-link til Dataverse
Hvis du vil oprette et Azure Synapse-link til Dataverse, skal du have følgende forudsætninger på plads.
- Systemadministratoradgang til Dataverse-miljøet.
- For the Azure Data Lake Storage:
- Du skal have en lagerkonto, der skal bruges sammen med ADLS Gen2.
- Du skal have tildelt Lager-Blob Data Owner og Storage Blob Data Contributor-adgang til lagerkontoen. Du kan få flere oplysninger under Rollebaseret adgangskontrol (Azure RBAC).
- Lagerkontoen skal aktivere hierarkisk navneområde.
- Det anbefales, at lagerkontoen bruger geo-redundant lager med læseadgang (RA-GRS).
- For Synapse-arbejdsområdet:
- Du skal have adgang til et Synapse-arbejdsområde og være tildelt Synapse-administratoradgang . Du kan få flere oplysninger under Indbyggede Roller og områder for Synapse RBAC.
- Arbejdsområdet skal være i det samme område som ADLS Gen2-lagerkontoen.
Konfigurationen omfatter logon til Power Apps og oprettelse af forbindelse mellem Dataverse og Azure Synapse-arbejdsområdet. En guidelignende oplevelse giver dig mulighed for at oprette et nyt link ved at vælge den lagerkonto og de tabeller, der skal eksporteres. Azure Synapse Link kopierer derefter data til ADLS Gen2-lageret og opretter automatisk visninger i den indbyggede Serveruafhængige SQL-gruppe i Azure Synapse. Du kan derefter oprette forbindelse til disse visninger for at oprette en Power BI-model.
Tips
Du kan få komplet dokumentation om oprettelse, administration og overvågning af Azure Synapse Link under Opret et Azure Synapse Link til Dataverse med dit Azure Synapse Workspace.
Opret endnu en serveruafhængig SQL-database
Du kan oprette en anden serveruafhængig SQL-database og bruge den til at tilføje brugerdefinerede rapportvisninger. På den måde kan du præsentere et forenklet datasæt for Power BI-forfatteren, der giver dem mulighed for at oprette en model, der er baseret på nyttige og relevante data. Den nye serveruafhængige SQL-database bliver forfatterens primære kildeforbindelse og en brugervenlig repræsentation af de data, der stammer fra datasøen.
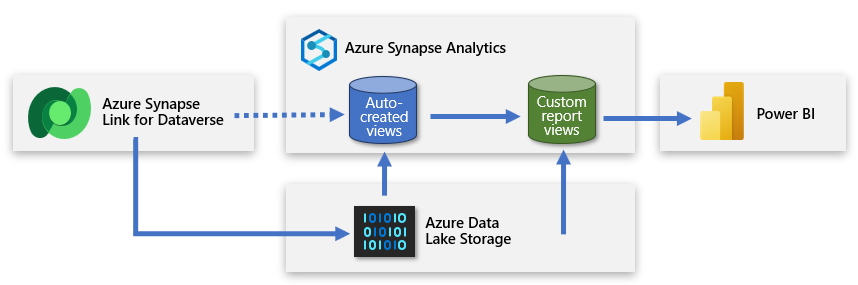
Denne fremgangsmåde leverer data til Power BI, der er fokuseret, forbedret og filtreret.
Du kan oprette en serveruafhængig SQL-database i Azure Synapse-arbejdsområdet ved hjælp af Azure Synapse Studio. Vælg Serveruafhængig som SQL-databasetype, og angiv et databasenavn. Power Query kan oprette forbindelse til denne database ved at oprette forbindelse til SQL-slutpunktet for arbejdsområdet.
Opret brugerdefinerede visninger
Du kan oprette brugerdefinerede visninger, der ombryder serveruafhængige SQL-gruppeforespørgsler. Disse visninger fungerer som enkle, rene datakilder, som Power BI opretter forbindelse til. Visningerne skal:
- Medtag de navne, der er knyttet til valgfelter.
- Reducer kompleksiteten ved kun at inkludere de kolonner, der kræves til datamodellering.
- Filtrer unødvendige rækker fra, f.eks. inaktive poster.
Overvej følgende visning, der henter kampagnedata.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Bemærk, at visningen kun indeholder fire kolonner, der hver især har et fuldt navn. Der er også en WHERE delsætning, der kun returnerer nødvendige rækker, i dette tilfælde aktive kampagner. Visningen forespørger også den kampagnetabel, der er joinforbundet til de OptionsetMetadata og StatusMetadata tabeller, som henter valgnavne.
Tips
Du kan finde flere oplysninger om, hvordan du henter metadata, under Få adgang til valgmærkater direkte fra Azure Synapse Link til Dataverse.
Forespørg om relevante tabeller
Azure Synapse Link til Dataverse sikrer, at data hele tiden synkroniseres med dataene i datasøen. I forbindelse med aktiviteter med højt forbrug kan samtidige skrivninger og læsninger oprette låse, der medfører, at forespørgsler mislykkes. For at sikre pålideligheden ved hentning af data synkroniseres to versioner af tabeldataene i Azure Synapse.
- Datai realtid: Leverer en kopi af data, der er synkroniseret fra Dataverse via Azure Synapse Link, på en effektiv måde ved at registrere, hvilke data der er ændret, siden de blev udtrukket eller sidst synkroniseret.
- Snapshot-data: Leverer en skrivebeskyttet kopi af data i næsten realtid, der opdateres med jævne mellemrum (i dette tilfælde hver time). Navne på snapshotdatatabeller er _partitioned føjet til deres navn.
Hvis du forventer, at der udføres en stor mængde læse- og skrivehandlinger samtidigt, skal du hente data fra snapshottabellerne for at undgå forespørgselsfejl.
Du kan få flere oplysninger under Få adgang til data i næsten realtid og skrivebeskyttede snapshotdata.
Opret forbindelse til Synapse Analytics
Hvis du vil forespørge om en Serveruafhængig SQL-gruppe i Azure Synapse, skal du bruge sql-slutpunktet for arbejdsområdet. Du kan hente slutpunktet fra Synapse Studio ved at åbne egenskaberne for den serveruafhængige SQL-gruppe.
I Power BI Desktop kan du oprette forbindelse til Azure Synapse ved hjælp af Azure Synapse Analytics SQL-connectoren. Når du bliver bedt om at angive serveren, skal du angive SQL-slutpunktet for arbejdsområdet.
Overvejelser i forbindelse med DirectQuery
Der er mange anvendelsestilfælde, når du bruger DirectQuery-lagringstilstand, der kan løse dine krav. Brugen af DirectQuery kan dog påvirke ydeevnen af Power BI-rapporten negativt. En rapport, der bruger en DirectQuery-forbindelse til Dataverse, vil ikke være så hurtig som en rapport, der bruger en importmodel. Generelt bør du importere data til Power BI, når det er muligt.
Vi anbefaler, at du overvejer emnerne i dette afsnit, når du arbejder med DirectQuery.
Du kan finde flere oplysninger om, hvornår du skal arbejde med DirectQuery-lagringstilstand, under Vælg en Power BI-modelstruktur.
Brug dimensionstabeller med dobbelt lagringstilstand
En tabel med dobbelt lagringstilstand er indstillet til at bruge både import- og DirectQuery-lagringstilstande. På forespørgselstidspunktet bestemmer Power BI den mest effektive tilstand at bruge. Når det er muligt, forsøger Power BI at tilfredsstille forespørgsler ved hjælp af importerede data, fordi det er hurtigere.
Du bør overveje at angive dimensionstabeller til dobbelt lagringstilstand, når det er relevant. På den måde gengives visualiseringer i udsnit og filterkortlister – som ofte er baseret på kolonner i dimensionstabeller – hurtigere, fordi der sendes en forespørgsel fra importerede data.
Vigtigt
Når en dimensionstabel skal nedarve dataverse-sikkerhedsmodellen, er det ikke hensigtsmæssigt at bruge dobbelt lagringstilstand.
Faktatabeller, der typisk gemmer store datamængder, skal forblive som DirectQuery-lagertilstandstabeller. De filtreres efter de relaterede dimensionstabeller med dobbelt lagringstilstand, som kan knyttes til faktatabellen for at opnå effektiv filtrering og gruppering.
Overvej følgende datamodeldesign. Tre dimensionstabeller, Owner, Accountog Campaign har en stribet øvre kant, hvilket betyder, at de er indstillet til dobbelt lagringstilstand.
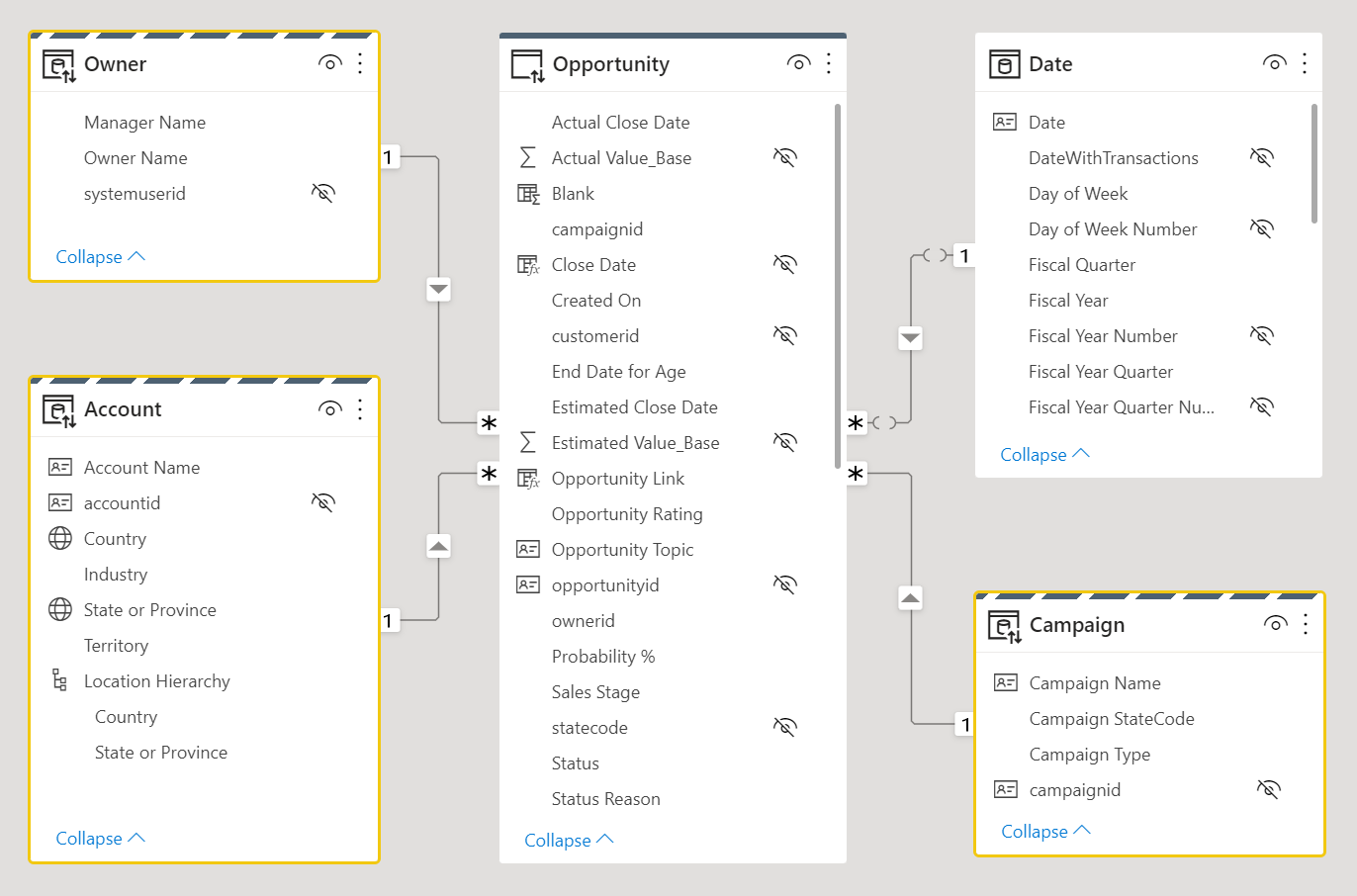
Du kan få flere oplysninger om tabellagringstilstande, herunder dobbelt lagring, under Administrer lagringstilstand i Power BI Desktop.
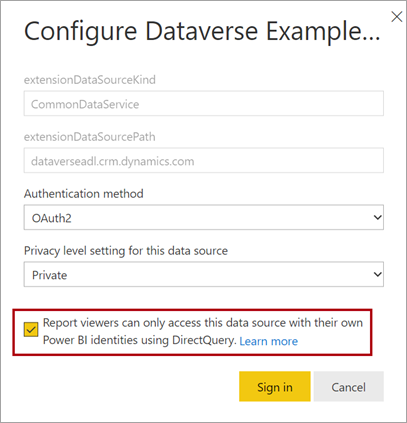
Aktivér enkeltlogon
Når du publicerer en DirectQuery-model til Power BI-tjeneste, kan du bruge indstillingerne for semantiske modeller til at aktivere enkeltlogon (SSO) ved hjælp af Microsoft Entra ID OAuth2 for dine rapportbrugere. Du skal aktivere denne indstilling, når Dataverse-forespørgsler skal udføres i rapportbrugerens sikkerhedskontekst.
Når indstillingen SSO er aktiveret, sender Power BI rapportbrugerens godkendte Microsoft Entra-legitimationsoplysninger i forespørgslerne til Dataverse. Denne indstilling gør det muligt for Power BI at overholde de sikkerhedsindstillinger, der er konfigureret i datakilden.
Du kan finde flere oplysninger under Enkeltlogon (SSO) for DirectQuery-kilder.
Repliker "Mine" filtre i Power Query
Når du bruger Microsoft Dynamics 365 Customer Engagement (CE) og modeldrevne Power Apps, der er baseret på Dataverse, kan du oprette visninger, der kun viser poster, hvor et brugernavnsfelt, f.eks. Owner, er lig med den aktuelle bruger. Du kan f.eks. oprette visninger med navnet "Mine åbne salgsmuligheder", "Mine aktive sager" og andre.
Overvej et eksempel på, hvordan visningen Mine aktive konti i Dynamics 365 indeholder et filter, hvor Ejer er lig med den aktuelle bruger.
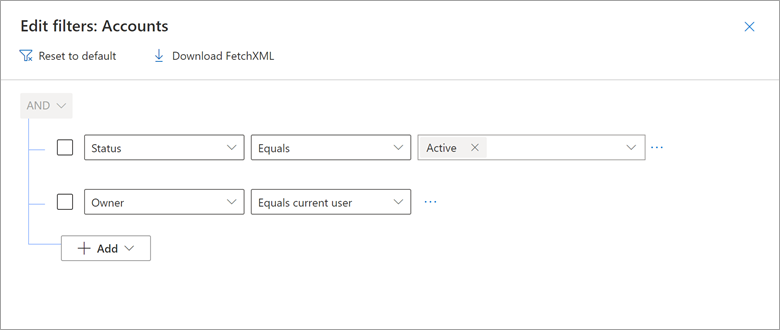
Du kan genskabe dette resultat i Power Query ved hjælp af en oprindelig forespørgsel, der integrerer tokenet CURRENT_USER .
Overvej følgende eksempel, der viser en oprindelig forespørgsel, der returnerer kontiene for den aktuelle bruger. Bemærk, at kolonnen WHERE filtreres efter ownerid-tokenet i CURRENT_USER-delsætningen.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Når du publicerer modellen på Power BI-tjeneste, skal du aktivere enkeltlogon (SSO), så Power BI sender rapportbrugerens godkendte Microsoft Entra-legitimationsoplysninger til Dataverse.
Opret supplerende importmodeller
Du kan oprette en DirectQuery-model, der gennemtvinger Dataverse-tilladelser , vel vidende , at ydeevnen vil være langsom. Du kan derefter supplere denne model med importmodeller, der er målrettet bestemte emner eller målgrupper, der kan gennemtvinge RLS-tilladelser.
En importmodel kan f.eks. give adgang til alle Dataverse-data, men ikke gennemtvinge nogen tilladelser. Denne model er velegnet til ledere, der allerede har adgang til alle Dataverse-data.
Når Dataverse gennemtvinger rollebaserede tilladelser efter salgsområde, kan du som et andet eksempel oprette én importmodel og replikere disse tilladelser ved hjælp af sikkerhed på rækkeniveau. Du kan også oprette en model for hvert salgsområde. Du kan derefter give læsetilladelse til disse modeller (semantiske modeller) til sælgere i hvert område. For at lette oprettelsen af disse regionale modeller kan du bruge parametre og rapportskabeloner. Du kan få flere oplysninger under Opret og brug rapportskabeloner i Power BI Desktop.
Relateret indhold
Du kan få flere oplysninger, der er relateret til denne artikel, i følgende ressourcer.