Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, einer All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alles von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung ab. Erfahren Sie, wie Sie eine neue Testversion kostenlos starten können!
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe der Copy-Aktivität in Azure Data Factory- und Azure Synapse-Pipelines aus und in Snowflake kopieren sowie Daten mithilfe des Tools „Datenfluss“ in Snowflake transformieren. Weitere Informationen finden Sie im Einführungsartikel für Data Factory oder Azure Synapse Analytics.
Wichtig
Der Snowflake V2-Verbinder bietet verbesserte native Snowflake-Unterstützung. Wenn Sie den Snowflake V1-Connector in Ihrer Lösung verwenden, sollten Sie Ihren Snowflake-Connector vor dem 30. Juni 2025 aktualisieren. Ausführliche Informationen zum Unterschied zwischen V2 und V1 finden Sie in diesem Abschnitt .
Unterstützte Funktionen
Für den Snowflake-Connector werden die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Copy-Aktivität (Quelle/Senke) | (1) (2) |
| Datenflusszuordnung (Quelle/Senke) | (1) |
| Nachschlageaktivität | (1) (2) |
| Skriptaktivität (Version 1.1 (Vorschau) anwenden, wenn Sie den Skriptparameter verwenden) | (1) (2) |
(1) Azure-Integrationslaufzeit (2) Selbst gehostete Integrationslaufzeit
Für die Kopieraktivität unterstützt dieser Snowflake-Connector die folgenden Funktionen:
- Kopieren von Daten aus Snowflake unter Verwendung des Snowflake-Befehls COPY into [Speicherort], um optimale Leistung zu erzielen.
- Kopieren von Daten in Snowflake unter Verwendung des Snowflake-Befehls COPY into [Tabelle], um optimale Leistung zu erzielen. Es unterstützt Snowflake auf Azure.
- Wenn für einen Proxy eine Verbindung mit Snowflake über eine selbstgehostete Integration Runtime erforderlich ist, müssen Sie die Umgebungsvariablen HTTP_PROXY und HTTPS_PROXY auf dem Integration Runtime-Host konfigurieren.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, einem virtuellen Azure-Netzwerk oder amazon Virtual Private Cloud befindet, müssen Sie eine selbst gehostete Integrationslaufzeit konfigurieren, um eine Verbindung damit herzustellen. Stellen Sie sicher, dass Sie die von der selbstgehosteten Integration Runtime verwendeten IP-Adressen zur erlaubten Liste hinzufügen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Wenn der Zugriff auf IPs beschränkt ist, die in den Firewallregeln genehmigt wurden, können Sie der Liste der zulässigen Adressen Azure Integration Runtime-IPs hinzufügen.
Das für „Quelle“ oder „Senke“ verwendete Snowflake-Konto benötigt USAGE-Zugriff auf die Datenbank und Lese-/Schreibzugriff auf das Schema und die zugehörigen Tabellen/Sichten. Außerdem sollte das Schema CREATE STAGE haben, um die externe Stufe mit dem SAS-URI erstellen zu können.
Die folgenden Werte für Kontoeigenschaften müssen festgelegt werden
| Eigenschaft | Beschreibung | Erforderlich | Standard |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Gibt an, ob bei der Erstellung einer benannten externen Phase (mit CREATE STAGE) ein Speicherintegrationsobjekt als Anmeldeinformationen für den Zugriff auf einen privaten Cloudspeicherort benötigt wird. | FALSCH | FALSCH |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Gibt an, ob eine benannte externe Phase, die auf ein Speicherintegrationsobjekt verweist, als Anmeldeinformationen für die Cloud verwendet werden soll, wenn Daten aus einem privaten Cloudspeicherort geladen oder in diesen entladen werden. | FALSCH | FALSCH |
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter "Datenzugriffsstrategien".
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool "Daten kopieren"
- Das Azure-Portal
- The .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Erstellen eines verknüpften Diensts mit Snowflake über die Benutzeroberfläche
Verwenden Sie die folgenden Schritte, um einen verknüpften Dienst mit Snowflake auf der Azure-Portal Benutzeroberfläche zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus und klicken Sie dann auf „Neu“:
Suchen Sie nach Snowflake, und wählen Sie dann den Snowflake-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
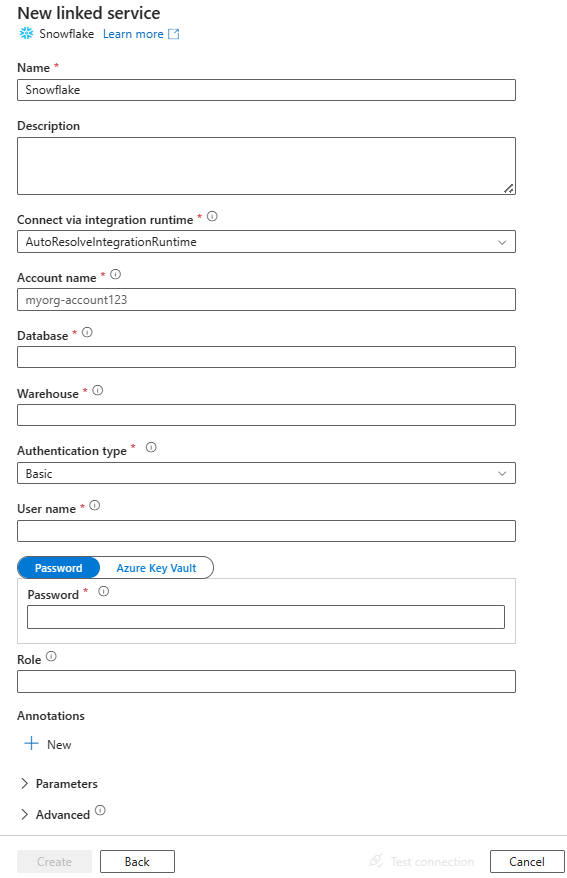
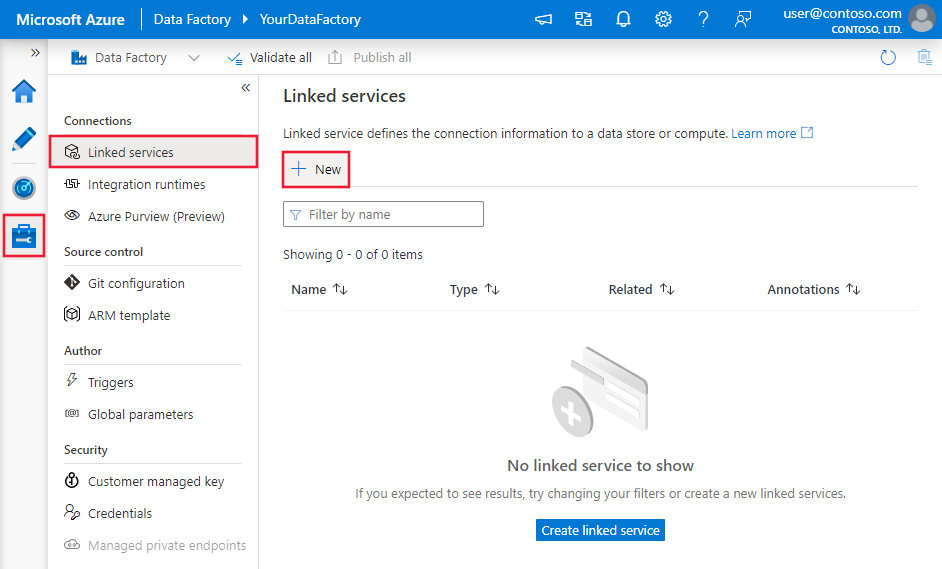
Konfigurationsdetails des Anschlusses
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Entitäten speziell für einen Snowflake-Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Diese generischen Eigenschaften werden für den mit Snowflake verknüpften Dienst unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft muss auf SnowflakeV2 festgelegt werden. | Ja |
| Ausgabe | Die von Ihnen angegebene Version. Empfehlen Sie ein Upgrade auf die neueste Version, um die neuesten Verbesserungen zu nutzen. | Ja für Version 1.1 (Vorschau) |
| Kontoidentifikator | Der Name des Kontos zusammen mit der zugehörigen Organisation. Beispiel: meineOrg-Konto123. | Ja |
| Datenbank | Die Standarddatenbank, die nach dem Herstellen einer Verbindung für die Sitzung verwendet wird. | Ja |
| Lagerhaus | Das standardmäßige virtuelle Warehouse, das nach dem Herstellen einer Verbindung für die Sitzung verwendet wird. | Ja |
| Authentifizierungstyp | Typ der Authentifizierung für die Verbindung mit dem Snowflake-Dienst. Zulässige Werte sind: Standard (Standard) und KeyPair. Weitere Informationen zu anderen Eigenschaften und Beispiele finden Sie weiter unten in den jeweiligen Abschnitten. | Nein |
| Rolle | Die Standardsicherheitsrolle, die nach dem Herstellen einer Verbindung für die Sitzung verwendet wird. | Nein |
| Gastgeber | Der Hostname des Snowflake-Kontos. Beispiel: contoso.snowflakecomputing.com
.cn wird auch unterstützt. |
Nein |
| connectVia | Die Integrationslaufzeit , die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet wird. Sie können die Azure Integration Runtime oder eine selbstgehostete Integration Runtime verwenden (wenn sich der Datenspeicher in einem privaten Netzwerk befindet). Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Dieser Snowflake-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
Standardauthentifizierung
Um die Standardauthentifizierung zu verwenden, geben Sie zusätzlich zu den generischen Eigenschaften, die im vorherigen Abschnitt beschrieben werden, die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Benutzer | Anmeldename für Snowflake-Benutzer. | Ja |
| Kennwort | Das Kennwort für Snowflake-Benutzer. Markieren Sie dieses Feld als Typ SecureString, um es sicher zu speichern. Sie können auch auf einen geheimen Schlüssel verweisen, der in Azure Key Vault gespeichert ist. | Ja |
Beispiel:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Kennwort im Azure Key Vault:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "Basic",
"user": "<username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung per Schlüsselpaar
Um die Schlüsselpaarauthentifizierung zu verwenden, müssen Sie einen Schlüsselpaarauthentifizierungsbenutzer in Snowflake konfigurieren und erstellen, indem Sie auf die Schlüsselpaar-Authentifizierung und Schlüsselpaardrehung verweisen. Notieren Sie sich anschließend den privaten Schlüssel und die Passphrase (optional), die Sie zum Definieren des verknüpften Diensts verwenden.
Geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen generischen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Benutzer | Anmeldename für Snowflake-Benutzer. | Ja |
| privater Schlüssel | Der private Schlüssel, der für die Schlüsselpaarauthentifizierung verwendet wird. Um sicherzustellen, dass der private Schlüssel gültig ist, wenn er an Azure Data Factory gesendet wird, und in Anbetracht der Tatsache, dass die privateKey-Datei Neue-Zeile-Zeichen (\n) enthält, ist es wichtig, den privateKey-Inhalt in seiner Zeichenfolgenliteralform korrekt zu formatieren. Dieser Vorgang umfasst das explizite Hinzufügen von \n zu jeder neuen Zeile. |
Ja |
| Passphrase des privaten Schlüssels | Die Passphrase, die zum Entschlüsseln des privaten Schlüssels verwendet wird, wenn er verschlüsselt ist. | Nein |
Beispiel:
{
"name": "SnowflakeV2LinkedService",
"properties": {
"type": "SnowflakeV2",
"typeProperties": {
"accountIdentifier": "<accountIdentifier>",
"database": "<database>",
"warehouse": "<warehouse>",
"authenticationType": "KeyPair",
"user": "<username>",
"privateKey": {
"type": "SecureString",
"value": "<privateKey>"
},
"privateKeyPassphrase": {
"type": "SecureString",
"value": "<privateKeyPassphrase>"
},
"role": "<role>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Hinweis
Für die Zuordnung von Datenflüssen wird empfohlen, einen neuen privaten RSA-Schlüssel mit dem PKCS#8-Standard im PEM-Format (P8-Datei) zu generieren.
Dataset-Eigenschaften
Eine vollständige Liste der Abschnitte und Eigenschaften, die zum Definieren von Datasets verfügbar sind, finden Sie im Artikel "Datasets ".
Folgende Eigenschaften werden für das Snowflake-Dataset unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft des Datasets muss auf SnowflakeV2Table festgelegt werden. | Ja |
| Schema | Name des Schemas. Beachten Sie, dass beim Schemanamen die Groß- und Kleinschreibung beachtet wird. | Quelle: Nein, Senke: Ja |
| Tisch | Name der Tabelle/Ansicht. Beachten Sie, dass beim Tabellennamen die Groß- und Kleinschreibung beachtet wird. | Quelle: Nein, Senke: Ja |
Beispiel:
{
"name": "SnowflakeV2Dataset",
"properties": {
"type": "SnowflakeV2Table",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste der Abschnitte und Eigenschaften, die zum Definieren von Aktivitäten verfügbar sind, finden Sie im Pipelines-Artikel . Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Snowflake-Quelle und -Senke unterstützt werden.
Snowflake als Quelle
Der Snowflake-Connector verwendet den Snowflake-Befehl COPY into [Speicherort], um optimale Leistung zu erzielen.
Wenn der Senkendatenspeicher und das Format vom Snowflake-Befehl „COPY“ nativ unterstützt werden, können Sie mit der Copy-Aktivität Kopiervorgänge direkt aus Snowflake in die Senke durchführen. Ausführliche Informationen finden Sie unter "Direkte Kopie von Snowflake". Verwenden Sie andernfalls das integrierte gestaffelte Kopieren aus Snowflake.
Um Daten aus Snowflake zu kopieren, werden die folgenden Eigenschaften im Abschnitt " Aktivitätsquelle kopieren" unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die Typeigenschaft der Kopieraktivitätsquelle muss auf SnowflakeV2Source festgelegt werden. | Ja |
| Anfrage | Gibt die SQL-Abfrage an, mit der Daten aus Snowflake gelesen werden. Wenn der Name des Schemas, der Tabelle und Spalten Kleinbuchstaben enthält, geben Sie den Objektbezeichner in der Abfrage an, z. B. select * from "schema"."myTable".Die Ausführung der gespeicherten Prozedur wird nicht unterstützt. |
Nein |
| Exporteinstellungen | Erweiterte Einstellungen, die zum Abrufen von Daten aus Snowflake verwendet werden. Sie können die vom „COPY INTO“-Befehl unterstützten Einstellungen konfigurieren, die vom Dienst übergeben werden, wenn Sie die Anweisung aufrufen. | Ja |
Unter exportSettings: |
||
| Typ | Der Typ des Exportbefehls, der auf SnowflakeExportCopyCommand festgelegt ist. | Ja |
| storageIntegration | Gibt den Namen der Speicherintegration an, die Sie in Ihrer Snowflake-Instanz erstellt haben. Die erforderlichen Schritte zur Verwendung der Speicherintegration finden Sie unter Konfigurieren einer Snowflake-Speicherintegration. | Nein |
| additionalCopyOptions | Zusätzliche Kopieroptionen, die als Wörterbuch mit Schlüssel-Wert-Paaren bereitgestellt werden. Beispiele: MAX_FILE_SIZE, OVERWRITE. Weitere Informationen finden Sie unter Snowflake Copy Options. | Nein |
| Zusätzliche Formatierungsoptionen | Zusätzliche Dateiformatoptionen, die im Befehl „COPY“ als Wörterbuch mit Schlüssel-Wert-Paaren bereitgestellt werden. Beispiele: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT, NULL_IF. Weitere Informationen finden Sie unter Snowflake-Formattypoptionen. Wenn Sie NULL_IF verwenden, wird der NULL-Wert in Snowflake beim Schreiben in die durch Trennzeichen getrennte Textdatei im Stagingspeicher in den angegebenen Wert konvertiert (erfordert einfache Anführungszeichen). Dieser angegebene Wert wird beim Lesen aus der Stagingdatei in den Senkenspeicher als NULL behandelt. Der Standardwert ist 'NULL'. |
Nein |
Hinweis
Stellen Sie sicher, dass Sie über die Berechtigung zum Ausführen des folgenden Befehls verfügen und auf das Schema INFORMATION_SCHEMA und die Tabellenspalten zugreifen können.
COPY INTO <location>
Direktes Kopieren aus Snowflake
Wenn der Senkendatenspeicher und das Format die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mit der Copy-Aktivität Kopiervorgänge direkt aus Snowflake in die Senke durchführen. Der Dienst überprüft die Einstellungen und gibt bei der Copy-Aktivitätsausführung einen Fehler aus, wenn die folgenden Kriterien nicht erfüllt werden:
Wenn Sie
storageIntegrationin der Quelle angeben:Der Senkendatenspeicher ist die Azure Blob Storage-Instanz, auf die Sie in der externen Stage in Snowflake verwiesen haben. Sie müssen die folgenden Schritte ausführen, bevor Sie Daten kopieren:
Erstellen Sie einen mit Azure Blob Storage verknüpften Dienst für die Spüle Azure Blob Storage mit allen unterstützten Authentifizierungstypen.
Gewähren Sie dem Snowflake-Dienstprinzipal in der Zugriffssteuerung (IAM) der Senkeninstanz von Azure Blob Storage mindestens die Rolle Mitwirkender an Storage-Blobdaten.
Wenn Sie
storageIntegrationnicht in der Quelle angeben:Der sink-verknüpfte Dienst ist Azure Blob Storage mit Authentifizierung für gemeinsame Zugriffssignaturen . Wenn Sie Daten direkt in azure Data Lake Storage Gen2 im folgenden unterstützten Format kopieren möchten, können Sie einen mit SAS-Authentifizierung verknüpften Azure Blob Storage-Dienst mit SAS-Authentifizierung für Ihr Azure Data Lake Storage Gen2-Konto erstellen, um die Verwendung von mehrstufiger Kopie aus Snowflake zu vermeiden.
Das Sink-Datenformat besteht aus Parkett, durch Trennzeichen getrenntem Text oder JSON mit den folgenden Konfigurationen:
- Für das Parkettformat ist der Komprimierungscodec "None", "Snappy" oder "Lzo".
- Beim Format Durch Trennzeichen getrennter Text:
-
rowDelimiterist \r\noder ein beliebiges einzelnes Zeichen. -
compressionkann keine Komprimierung, gzip, bzip2 oder Deflate sein. -
encodingNameist als Standard beibehalten oder auf utf-8 gesetzt. -
quoteCharist doppelte Anführungszeichen, einfache Anführungszeichen oder leere Zeichenfolge (kein Anführungszeichen).
-
- Für das JSON-Format unterstützt die direkte Kopie nur den Fall, dass die Snowflake-Quelltabelle oder das Abfrageergebnis nur eine Spalte enthält und der Datentyp dieser Spalte VARIANT, OBJECT oder ARRAY ist.
-
compressionkann keine Komprimierung, gzip, bzip2 oder Deflate sein. -
encodingNameist als Standard beibehalten oder auf utf-8 gesetzt. -
filePatternin der Senke der Copy-Aktivität wird auf dem Standardwert belassen oder auf setOfObjects festgelegt.
-
In der Quelle der Kopieraktivität ist
additionalColumnsnicht angegeben.Die Spaltenzuordnung ist nicht angegeben.
Beispiel:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
},
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Gestaffeltes Kopieren aus Snowflake
Wenn der Senkendatenspeicher oder das Format nicht nativ mit dem Snowflake-Befehl „COPY“ kompatibel ist (wie im letzten Abschnitt beschrieben), aktivieren Sie mithilfe einer Azure Blob Storage-Zwischeninstanz das integrierte gestaffelte Kopieren. Das Feature für gestaffeltes Kopieren bietet Ihnen auch einen höheren Durchsatz. Der Dienst exportiert Daten aus Snowflake in den Stagingspeicher, kopiert dann die Daten in die Senke und bereinigt schließlich die temporären Daten aus dem Stagingspeicher. Details zum Kopieren von Daten mithilfe von Staging finden Sie unter "Mehrstufige Kopie ".
Um dieses Feature zu verwenden, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst , der sich auf das Azure-Speicherkonto als Zwischen-Staging bezieht. Geben Sie dann die Eigenschaften enableStaging und stagingSettings in der Kopieraktivität an.
Wenn Sie
storageIntegrationin der Quelle angeben, sollte der Zwischenspeicher von Azure Blob Storage derjenige sein, auf den Sie in der externen Speicherstufe in Snowflake verwiesen haben. Stellen Sie sicher, dass Sie dafür einen mit Azure Blob Storage verknüpften Dienst erstellen, bei Verwendung der Azure-Integrationslaufzeit mit jeder unterstützten Authentifizierung oder bei Verwendung der selbst gehosteten Integrationslaufzeit mit anonymer Authentifizierung, Kontoschlüssel, freigegebener Zugriffssignatur oder Dienstprinzipalauthentifizierung. Gewähren Sie zusätzlich dem Snowflake-Dienstprinzipal in der Zugriffssteuerung (IAM) der Staginginstanz von Azure Blob Storage mindestens die Rolle Mitwirkender an Storage-Blobdaten.Wenn Sie
storageIntegrationnicht in der Quelle angeben, muss der mit Azure Blob Storage verknüpfte Stagingdienst die SAS-Authentifizierung verwenden, die für den Snowflake-Befehl „COPY“ erforderlich ist. Stellen Sie sicher, dass Sie Snowflake die erforderlichen Zugriffsberechtigungen im Azure Blob Storage-Stagingbereich erteilen. Weitere Informationen hierzu finden Sie in diesem Artikel.
Beispiel:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeV2Source",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Beim Ausführen des gestaffelten Kopierens von Snowflake ist es wichtig, das Verhalten der Senkenkopie auf Dateien zusammenführen festzulegen. Diese Einstellung stellt sicher, dass alle partitionierten Dateien ordnungsgemäß verarbeitet und zusammengeführt werden und verhindern, dass nur die letzte partitionierte Datei kopiert wird.
Beispielkonfiguration
{
"type": "Copy",
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM my_table"
},
"sink": {
"type": "AzureBlobStorage",
"copyBehavior": "MergeFiles"
}
}
Hinweis
Wird das Verhalten der Senkenkopie nicht auf Dateien zusammenführen festgelegt, kann dies dazu führen, dass nur die letzte partitionierte Datei kopiert wird.
Snowflake als Senke
Der Snowflake-Connector verwendet den Snowflake-Befehl COPY into [Tabelle], um optimale Leistung zu erzielen. Er unterstützt das Schreiben von Daten in Snowflake in Azure.
Wenn der Quelldatenspeicher und das Format vom Snowflake-Befehl „COPY“ nativ unterstützt werden, können Sie mit der Kopieraktivität Kopiervorgänge direkt aus der Quelle in Snowflake durchführen. Details finden Sie unter Direktes Kopieren in Snowflake. Verwenden Sie andernfalls das integrierte gestaffelte Kopieren in Snowflake.
Beim Kopieren von Daten in Snowflake werden die folgenden Eigenschaften im Abschnitt sink der Copy-Aktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Typ | Die type-Eigenschaft der Senke der Copy-Aktivität, festgelegt auf SnowflakeV2Sink. | Ja |
| preCopyScript | Geben Sie eine SQL-Abfrage an, die bei jeder Ausführung von der Kopieraktivität ausgeführt werden soll, bevor Daten in Snowflake geschrieben werden. Sie können diese Eigenschaft nutzen, um vorab geladene Daten zu bereinigen. | Nein |
| Einstellungen importieren | Erweiterte Einstellungen, die zum Schreiben von Daten in Snowflake verwendet werden. Sie können die vom „COPY INTO“-Befehl unterstützten Einstellungen konfigurieren, die vom Dienst übergeben werden, wenn Sie die Anweisung aufrufen. | Ja |
Unter importSettings: |
||
| Typ | Der Typ des Importbefehls, der auf SnowflakeImportCopyCommand festgelegt ist. | Ja |
| storageIntegration | Gibt den Namen der Speicherintegration an, die Sie in Ihrer Snowflake-Instanz erstellt haben. Die erforderlichen Schritte zur Verwendung der Speicherintegration finden Sie unter Konfigurieren einer Snowflake-Speicherintegration. | Nein |
| additionalCopyOptions | Zusätzliche Kopieroptionen, die als Wörterbuch mit Schlüssel-Wert-Paaren bereitgestellt werden. Beispiele: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Weitere Informationen finden Sie unter Snowflake Copy Options. | Nein |
| Zusätzliche Formatierungsoptionen | Zusätzliche Dateiformatoptionen, die im Befehl „COPY“ als Wörterbuch mit Schlüssel-Wert-Paaren bereitgestellt werden. Beispiele: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Weitere Informationen finden Sie unter Snowflake-Formattypoptionen. | Nein |
Hinweis
Stellen Sie sicher, dass Sie über die Berechtigung zum Ausführen des folgenden Befehls verfügen und auf das Schema INFORMATION_SCHEMA und die Tabellenspalten zugreifen können.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Direktes Kopieren in Snowflake
Wenn der Quelldatenspeicher und das Format die in diesem Abschnitt beschriebenen Kriterien erfüllen, können Sie mit der Kopieraktivität Kopiervorgänge direkt aus der Quelle in Snowflake durchführen. Der Dienst überprüft die Einstellungen und gibt bei der Copy-Aktivitätsausführung einen Fehler aus, wenn die folgenden Kriterien nicht erfüllt werden:
Wenn Sie
storageIntegrationin der Senke angeben:Der Quelldatenspeicher ist die Azure Blob Storage-Instanz, auf die Sie in der externen Stage in Snowflake verwiesen haben. Sie müssen die folgenden Schritte ausführen, bevor Sie Daten kopieren:
Erstellen Sie einen verknüpften Azure Blob Storage-Dienst für den Quell-Azure Blob Storage mit allen unterstützten Authentifizierungstypen.
Gewähren Sie dem Snowflake-Dienstprinzipal mindestens die Rolle Storage-Blobdatenleser in der Zugriffssteuerung (IAM) der Azure Blob Storage-Quellinstanz.
Wenn Sie
storageIntegrationnicht in der Senke angeben:Der verknüpfte Quelldienst ist Azure Blob Storage mit Authentifizierung für gemeinsame Zugriffssignaturen . Wenn Sie Daten direkt aus Azure Data Lake Storage Gen2 im folgenden unterstützten Format kopieren möchten, können Sie einen mit SAS-Authentifizierung verknüpften Azure Blob Storage-Dienst mit SAS-Authentifizierung für Ihr Azure Data Lake Storage Gen2-Konto erstellen, um die Verwendung von mehrstufiger Kopie in Snowflake zu vermeiden.
Das Quelldatenformat ist Parkett, durch Trennzeichen getrennter Text oder JSON mit den folgenden Konfigurationen:
Für das Parquet-Format ist der Komprimierungscodec None oder Snappy.
Beim Format Durch Trennzeichen getrennter Text:
-
rowDelimiterist \r\noder ein beliebiges einzelnes Zeichen. Wenn das Zeilentrennzeichen nicht "\r\n" ist,firstRowAsHeadermuss "false" sein undskipLineCountnicht angegeben werden. -
compressionkann keine Komprimierung, gzip, bzip2 oder Deflate sein. -
encodingNamewird als Standardwert übernommen oder ist auf „UTF-8“, „UTF-16“, „UTF-16BE“, „UTF-32“, „UTF-32BE“, „BIG5“, „EUC-JP“, „EUC-KR“, „GB18030“, „ISO-2022-JP“, „ISO-2022-KR“, „ISO-8859-1“, „ISO-8859-2“, „ISO-8859-5“, „ISO-8859-6“, „ISO-8859-7“, „ISO-8859-8“, „ISO-8859-9“, „WINDOWS-1250“, „WINDOWS-1251“, „WINDOWS-1252“, „WINDOWS-1253“, „WINDOWS-1254“ oder „WINDOWS-1255“ festgelegt. -
quoteCharist doppelte Anführungszeichen, einfache Anführungszeichen oder leere Zeichenfolge (kein Anführungszeichen).
-
Für das JSON-Format unterstützt direktes Kopieren nur den Fall, dass die Snowflake-Senkentabelle nur eine einzelne Spalte hat und der Datentyp dieser Spalte VARIANT, OBJECT oder ARRAY ist.
-
compressionkann keine Komprimierung, gzip, bzip2 oder Deflate sein. -
encodingNameist als Standard beibehalten oder auf utf-8 gesetzt. - Die Spaltenzuordnung ist nicht angegeben.
-
In der Quelle der Copy-Aktivität:
-
additionalColumnsist nicht angegeben. - Wenn es sich bei der Quelle um einen Ordner handelt, wird
recursiveauf TRUE festgelegt. -
prefix,modifiedDateTimeStart,modifiedDateTimeEndundenablePartitionDiscoverywurden nicht angegeben.
-
Beispiel:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
},
"storageIntegration": "< Snowflake storage integration name >"
}
}
}
}
]
Gestaffeltes Kopieren in Snowflake
Wenn der Quelldatenspeicher oder das Format nicht nativ mit dem Snowflake-Befehl „COPY“ kompatibel ist (wie im letzten Abschnitt beschrieben), aktivieren Sie mithilfe einer Azure Blob Storage-Zwischeninstanz das integrierte gestaffelte Kopieren. Das Feature für gestaffeltes Kopieren bietet Ihnen auch einen höheren Durchsatz. Der Dienst konvertiert die Daten automatisch, damit das Datenformat den Anforderungen von Snowflake entspricht. Dann wird der Befehl „COPY“ aufgerufen, um die Daten in Snowflake zu laden. Abschließend werden Sie die temporären Daten in Blob Storage bereinigt. Details zum Kopieren von Daten mithilfe von Staging finden Sie unter "Mehrstufige Kopie ".
Um dieses Feature zu verwenden, erstellen Sie einen mit Azure Blob Storage verknüpften Dienst , der sich auf das Azure-Speicherkonto als Zwischen-Staging bezieht. Geben Sie dann die Eigenschaften enableStaging und stagingSettings in der Kopieraktivität an.
Wenn Sie
storageIntegrationin der Senke angeben, sollte das Zwischenstaginginstanz von Azure Blob Storage die sein, auf die Sie in der externen Stage in Snowflake verwiesen haben. Stellen Sie sicher, dass Sie dafür einen mit Azure Blob Storage verknüpften Dienst erstellen, bei Verwendung der Azure-Integrationslaufzeit mit jeder unterstützten Authentifizierung oder bei Verwendung der selbst gehosteten Integrationslaufzeit mit anonymer Authentifizierung, Kontoschlüssel, freigegebener Zugriffssignatur oder Dienstprinzipalauthentifizierung. Gewähren Sie zusätzlich dem Snowflake-Dienstprinzipal in der Zugriffssteuerung (IAM) der Staginginstanz von Azure Blob Storage mindestens die Rolle Storage-Blobdatenleser.Wenn Sie
storageIntegrationnicht in der Senke angeben, muss der mit Azure Blob Storage verknüpfte Stagingdienst die SAS-Authentifizierung verwenden, die für den Snowflake-Befehl „COPY“ erforderlich ist.
Beispiel:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeV2Sink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"storageIntegration": "< Snowflake storage integration name >"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Eigenschaften von Zuordnungsdatenflüssen
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie in Snowflake Tabellen lesen und in diese schreiben. Weitere Informationen finden Sie in der Quelltransformation und der Sinktransformation in Zuordnungsdatenflüssen. Sie können ein Snowflake-Dataset oder Inlinedataset als Quell- und Senkentyp verwenden.
Quellentransformation
In der folgenden Tabelle sind die von einer Snowflake-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte " Quelloptionen " bearbeiten. Der Connector nutzt die interne Datenübertragung von Snowflake.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Tabelle | Wenn Sie „Tabelle“ als Eingabe auswählen, ruft der Datenfluss alle Daten aus der Tabelle ab, die im Snowflake-Dataset oder bei Verwendung des Inlinedatasets in den Quelloptionen angegeben ist. | Nein | Schnur |
(nur für Inline-Datasets) Tabellenname schemaName |
| Abfrage | Wenn Sie „Abfrage“ als Eingabe auswählen, geben Sie eine Abfrage zum Abrufen von Daten aus Snowflake ein. Diese Einstellung überschreibt jede Tabelle, die Sie im Dataset ausgewählt haben. Wenn der Name des Schemas, der Tabelle und Spalten Kleinbuchstaben enthält, geben Sie den Objektbezeichner in der Abfrage an, z. B. select * from "schema"."myTable". |
Nein | Schnur | Anfrage |
| Inkrementelle Extrahierung aktivieren (Vorschau) | Verwenden Sie diese Option, um ADF mitzuteilen, dass nur Zeilen verarbeitet werden sollen, die seit der letzten Ausführung der Pipeline geändert wurden. | Nein | Boolescher Typ (Boolean) | AktiviereCdc |
| Inkrementelle Spalte | Wenn Sie das Feature für das inkrementelle Extrahieren verwenden, müssen Sie die Datums-/Uhrzeit-/numerische Spalte auswählen, die Sie als Grenzwert in der Quelltabelle verwenden möchten. | Nein | Schnur | waterMarkColumn |
| Aktivieren der Snowflake-Änderungsnachverfolgung (Vorschau) | Mit dieser Option kann ADF die Snowflake-Change Data Capture-Technologie nutzen, um nur die Deltadaten seit der vorherigen Pipelineausführung zu verarbeiten. Mit dieser Option werden die Deltadaten automatisch mit Vorgängen für Zeileneinfügung, Zeilenaktualisierung und Zeilenlöschung geladen, ohne dass eine inkrementelle Spalte erforderlich ist. | Nein | Boolescher Typ (Boolean) | Nativen CDC aktivieren |
| Netto-Änderungen | Wenn Sie die Snowflake-Änderungsnachverfolgung verwenden, können Sie diese Option verwenden, um deduplizierte geänderte Zeilen oder umfassende Änderungen abzurufen. Deduplizierte geänderte Zeilen zeigen nur die neuesten Versionen der Zeilen an, die seit einem bestimmten Zeitpunkt geändert wurden, während umfassende Änderungen alle Versionen jeder geänderten Zeile anzeigen, einschließlich der Zeilen, die gelöscht oder aktualisiert wurden. Wenn Sie z. B. eine Zeile aktualisieren, wird eine Löschversion und eine Einfügeversion in den umfassenden Änderungen angezeigt, aber nur die Einfügeversion in deduplizierten geänderten Zeilen. Je nach Anwendungsfall können Sie die Option auswählen, die Ihren Bedürfnissen entspricht. Die Standardoption ist FALSCH, was umfassende Änderungen bedeutet. | Nein | Boolescher Typ (Boolean) | netChanges |
| Systemspalten einschließen | Bei Verwendung der Snowflake-Änderungsnachverfolgung können Sie mithilfe der Option „systemColumns“ steuern, ob die von Snowflake bereitgestellten Metadatenstromspalten in die Ausgabe der Änderungsnachverfolgung einbezogen oder ausgeschlossen werden. Standardmäßig ist „systemColumns“ auf WAHR festgelegt, was bedeutet, dass die Metadatenstromspalten eingeschlossen sind. Sie können „systemColumns“ auf FALSCH festlegen, wenn Sie diese ausschließen möchten. | Nein | Boolescher Typ (Boolean) | systemColumns |
| Lesen von Anfang an beginnen | Wenn Sie diese Option mit dem inkrementellen Extrahieren und der Änderungsnachverfolgung festlegen, wird ADF angewiesen, alle Zeilen bei der ersten Ausführung einer Pipeline mit aktiviertem inkrementellem Extrahieren zu lesen. | Nein | Boolescher Typ (Boolean) | skipInitialLoad |
Beispiele für Snowflake-Quellskripts
Wenn Sie das Snowflake-Dataset als Quelltyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Wenn Sie ein Inlinedataset verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Native Änderungsnachverfolgung
Azure Data Factory unterstützt jetzt ein natives Feature in Snowflake, das als Änderungsnachverfolgung bekannt ist, was das Nachverfolgen von Änderungen in Form von Protokollen umfasst. Dieses Feature von Snowflake ermöglicht es uns, die Änderungen der Daten im Zeitverlauf zu verfolgen, was für das inkrementelle Laden von Daten und für Überprüfungszwecke nützlich ist. Wenn Sie dieses Feature verwenden möchten, erstellen wir beim Aktivieren von Change Data Capture und Auswählen der Snowflake-Änderungsnachverfolgung ein Stream-Objekt für die Quelltabelle, das die Änderungsnachverfolgung in der Snowflake-Tabelle ermöglicht. Anschließend verwenden wir die CHANGES-Klausel in unserer Abfrage, um nur die neuen oder aktualisierten Daten aus der Quelltabelle abzurufen. Außerdem wird empfohlen, die Pipeline so zu planen, dass Änderungen innerhalb des Intervalls der für die Snowflake-Quelltabelle festgelegten Datenaufbewahrungszeit aufgenommen werden; andernfalls könnte der Benutzer inkonsistentes Verhalten bei erfassten Änderungen beobachten.
Senkentransformation
In der folgenden Tabelle sind die von einer Snowflake-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte "Einstellungen " bearbeiten. Wenn Sie inline-Datasets verwenden, werden zusätzliche Einstellungen angezeigt, die mit den im Abschnitt "Dataseteigenschaften " beschriebenen Eigenschaften identisch sind. Der Connector nutzt die interne Datenübertragung von Snowflake.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Geben Sie an, welche Vorgänge für das Snowflake-Ziel zulässig sind. Um Zeilen zu aktualisieren, einfügen oder zu löschen, ist eine Änderungszeilentransformation erforderlich, um Zeilen für diese Aktionen zu markieren. |
Ja |
true oder false |
löschbar Insertierbaren aktualisierbar Upsertable |
| Schlüsselspalten | Für Update-, Upsert- und Löschvorgänge muss mindestens eine Schlüsselspalte festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll. | Nein | Anordnung | Schlüssel |
| Tabellenaktion | Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen. - Keine: Es wird keine Aktion an der Tabelle vorgenommen. - Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird. - Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt. |
Nein |
true oder false |
Neu erstellen abschneiden |
Beispiele für Snowflake-Senkenskripts
Wenn Sie das Snowflake-Dataset als Senkentyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Wenn Sie ein Inlinedataset verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Abfrage-Pushdown-Optimierung
Durch Festlegen des Protokolliergrads der Pipeline auf „Keine“ schließen wir die Übertragung von Zwischenmetriken für die Transformation aus, wodurch potenzielle Hindernisse für Spark-Optimierungen vermieden und die von Snowflake bereitgestellte Abfrage-Pushdown-Optimierung ermöglicht werden. Diese Pushdown-Optimierung ermöglicht erhebliche Leistungsverbesserungen für große Snowflake-Tabellen mit umfangreichen Datasets.
Hinweis
In Snowflake werden temporäre Tabellen nicht unterstützt, da sie lokal für die Sitzung oder den Benutzer sind, der sie erstellt, wodurch sie für andere Sitzungen unzugänglich sind und sie anfällig dafür macht, von Snowflake wie reguläre Tabellen überschrieben zu werden. Während Snowflake transiente Tabellen als Alternative bietet, die global zugänglich sind, erfordern sie ein manuelles Löschen, was unserem primären Ziel der Verwendung von temporäre Tabellen widerspricht, das darin besteht, jegliche Löschvorgänge im Quellschema zu vermeiden.
Datentypzuordnung für Snowflake V2
Wenn Sie Daten aus Snowflake kopieren, werden die folgenden Zuordnungen von Snowflake-Datentypen zu Zwischendatentypen innerhalb des Diensts intern verwendet. Informationen dazu, wie die Kopieraktivität das Quellschema und den Datentyp der Spüle zuordnet, finden Sie unter Schema- und Datentypzuordnungen.
| Snowflake-Datentyp | Zwischendatentyp des Diensts |
|---|---|
| ZAHL (p,0) | Dezimalzahl |
| ZAHL (p,s wobei s>0) | Dezimalzahl |
| SCHWEBEN | Doppelt |
| VARCHAR | Schnur |
| VERKOHLEN | Schnur |
| BINÄR | Byte[] |
| BOOLESCH | Boolescher Typ (Boolean) |
| Datum | Datum/Uhrzeit |
| ZEIT | TimeSpan |
| TIMESTAMP_LTZ | DateTimeOffset (Datum/Uhrzeit mit Offset) |
| TIMESTAMP_NTZ | DateTimeOffset (Datum/Uhrzeit mit Offset) |
| TIMESTAMP_TZ | DateTimeOffset (Datum/Uhrzeit mit Offset) |
| VARIANTE | Schnur |
| OBJEKT | Schnur |
| ANORDNUNG | Schnur |
Eigenschaften der Lookup-Aktivität
Weitere Informationen zu den Eigenschaften finden Sie unter Nachschlageaktivität.
Connectorlebenszyklus und -upgrade für Snowflake
Die folgende Tabelle zeigt die Veröffentlichungsphase und Änderungsprotokolle für verschiedene Versionen des Snowflake-Connectors:
| Version | Freigabestufe | Änderungsprotokoll |
|---|---|---|
| Schneeflake V1 | GA-Version verfügbar | / |
| Snowflake V2 (Version 1.0) | GA-Version verfügbar | • Unterstützung für die Schlüsselpaarauthentifizierung hinzufügen. • Die accountIdentifier, warehouse, database, schema und role Eigenschaften werden verwendet, um eine Verbindung anstelle der connectionstring Eigenschaft herzustellen.• Unterstützung für Dezimalstellen in Lookupaktivitäten hinzufügen. Der in Snowflake definierte Typ NUMBER wird als Zeichenfolge in Lookups angezeigt. Wenn Sie ihn in V2 in einen numerischen Typ umwandeln möchten, können Sie den Pipelineparameter mit der int-Funktion oder Float-Funktion verwenden. Beispiel: int(activity('lookup').output.firstRow.VALUE), float(activity('lookup').output.firstRow.VALUE).• Der Timestamp-Datentyp in Snowflake wird in der Such- und Skriptaktivität als DateTimeOffset-Datentyp gelesen. Wenn Sie den Datetime-Wert nach dem Upgrade auf V2 weiterhin als Parameter in Ihrer Pipeline verwenden müssen, können Sie den DateTimeOffset-Typ mithilfe der FormatDateTime-Funktion (empfohlen) oder der Verkettungsfunktion in den DateTime-Typ konvertieren. Beispiel: formatDateTime(activity('lookup').output.firstRow.DATETIMETYPE), concat(substring(activity('lookup').output.firstRow.DATETIMETYPE, 0, 19), 'Z') • ZAHL (p,0) wird als Dezimaldatentyp gelesen. • TIMESTAMP_LTZ, TIMESTAMP_NTZ und TIMESTAMP_TZ werden als DateTimeOffset-Datentyp gelesen. • Skriptparameter werden in der Skriptaktivität nicht unterstützt. Verwenden Sie alternativ dynamische Ausdrücke für Skriptparameter. Weitere Informationen finden Sie unter Ausdrücke und Funktionen in Azure Data Factory und Azure Synapse Analytics. • Die Ausführung mehrerer SQL-Anweisungen in Skriptaktivitäten wird nicht unterstützt. |
| Snowflake V2 (Version 1.1) | Vorschauversion verfügbar | • Unterstützung für Skriptparameter hinzufügen. • Unterstützung für die Ausführung mehrerer Anweisungen in Skriptaktivitäten hinzufügen. |
Aktualisieren des Snowflake-Connectors von V1 auf V2
Um den Snowflake-Connector von V1 auf V2 zu aktualisieren, können Sie ein paralleles Upgrade oder ein direktes Upgrade durchführen.
Paralleles Upgrade
Führen Sie die folgenden Schritte aus, um ein paralleles Upgrade durchzuführen:
- Erstellen Sie einen neuen verknüpften Snowflake-Dienst, und konfigurieren Sie ihn anhand der Eigenschaften des verknüpften V2-Diensts.
- Erstellen Sie ein Dataset basierend auf dem neu erstellten verknüpften Snowflake-Dienst.
- Ersetzen Sie den neuen verknüpften Dienst und das Dataset durch die vorhandenen in den Pipelines, die auf die V1-Objekte verweisen.
Direktes Upgrade
Um ein In-Place-Upgrade durchzuführen, müssen Sie die Nutzdaten des vorhandenen verknüpften Dienstes bearbeiten und das Dataset so aktualisieren, dass der neue verknüpfte Dienst verwendet wird.
Aktualisieren Sie den Typ von Snowflake auf SnowflakeV2.
Ändern Sie die verknüpfte Dienstnutzlast vom V1-Format in V2. Sie können jedes Feld entweder über die Benutzeroberfläche ausfüllen, nachdem Sie den oben genannten Typ geändert haben, oder die Nutzdaten direkt über den JSON-Editor aktualisieren. Im Abschnitt "Verknüpfte Diensteigenschaften" in diesem Artikel finden Sie die unterstützten Verbindungseigenschaften. Die folgenden Beispiele zeigen die Unterschiede im Payload für die verbundenen Snowflake V1- und V2-Dienste.
JSON-Nutzdaten des verknüpften Snowflake V1-Diensts:
{ "name": "Snowflake1", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "annotations": [], "type": "Snowflake", "typeProperties": { "authenticationType": "Basic", "connectionString": "jdbc:snowflake://<fake_account>.snowflakecomputing.com/?user=FAKE_USER&db=FAKE_DB&warehouse=FAKE_DW&schema=PUBLIC", "encryptedCredential": "<your_encrypted_credential_value>" }, "connectVia": { "referenceName": "AzureIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }JSON-Nutzdaten des verknüpften Snowflake V2-Diensts:
{ "name": "Snowflake2", "type": "Microsoft.DataFactory/factories/linkedservices", "properties": { "parameters": { "schema": { "type": "string", "defaultValue": "PUBLIC" } }, "annotations": [], "type": "SnowflakeV2", "typeProperties": { "authenticationType": "Basic", "accountIdentifier": "<FAKE_Account>", "user": "FAKE_USER", "database": "FAKE_DB", "warehouse": "FAKE_DW", "encryptedCredential": "<placeholder>" }, "connectVia": { "referenceName": "AutoResolveIntegrationRuntime", "type": "IntegrationRuntimeReference" } } }Aktualisieren Sie das Dataset, um den neuen verknüpften Dienst zu verwenden. Sie können entweder ein neues Dataset basierend auf dem neu erstellten verknüpften Dienst erstellen oder die Typeigenschaft eines vorhandenen Datasets von SnowflakeTable auf SnowflakeV2Table aktualisieren.
Hinweis
Beim Übergang von verknüpften Diensten zeigt der Abschnitt "Vorlagenparameter überschreiben" möglicherweise nur Datenbankeigenschaften an. Sie können dies beheben, indem Sie die Parameter manuell bearbeiten. Danach zeigt der Abschnitt " Vorlagenparameter außer Kraft setzen " die Verbindungszeichenfolgen an.
Aktualisieren des Snowflake V2-Connectors von Version 1.0 auf Version 1.1 (Vorschau)
Wählen Sie auf der Seite "Verknüpften Dienst bearbeiten " 1.1 für die Version aus. Weitere Informationen finden Sie unter Eigenschaften verknüpfter Dienste.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quellen und Senken für die Copy-Aktivität unterstützt werden, finden Sie unter Unterstützte Datenspeicher und Formate.