Skillset-Konzepte in Azure AI Search
Dieser Artikel richtet sich an Entwicklerinnen und Entwickler, die ausführlichere Informationen über die Konzepte und den Aufbau von Skillsets benötigen. Es wird vorausgesetzt, dass die Leserin oder der Leser mit den allgemeinen Konzepten der angewandten KI in der Azure KI-Suche vertraut ist.
Bei einem Skillset handelt es sich um ein wiederverwendbares Objekt in der Azure KI-Suche, die einem Indexer angefügt ist. Es enthält mindestens einen Skill, mit dem integrierte KI-Prozesse oder externe benutzerdefinierte Prozesse über Dokumente aufgerufen werden, die aus einer externen Datenquelle abgerufen wurden.
Das folgende Diagramm veranschaulicht den grundlegenden Datenfluss der Skillsetausführung.
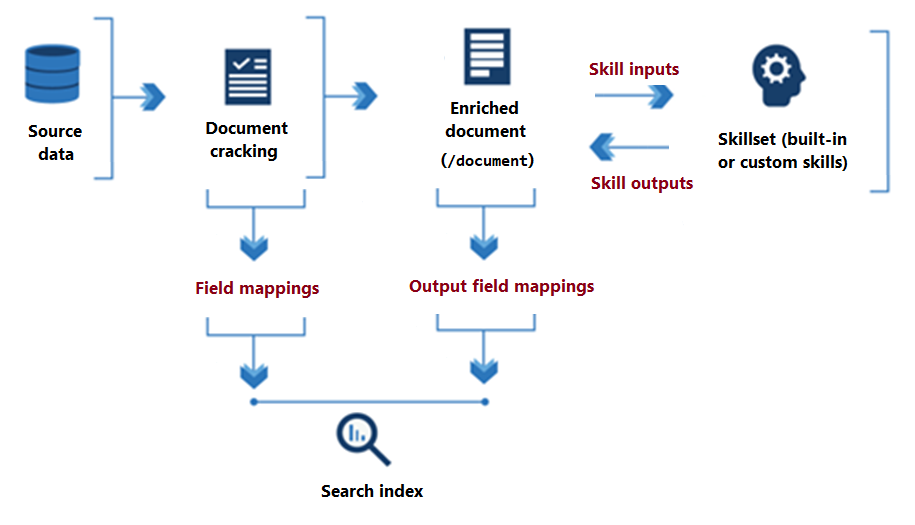
Skills werden während der gesamten Skillsetverarbeitung aus einem angereicherten Dokument, das im Speicher existiert, gelesen und dorthin geschrieben. Zunächst ist ein angereichertes Dokument nur der aus einer Datenquelle extrahierte rohe Inhalt (dargestellt als Stammknoten "/document"). Bei jeder Skillausführung erhält das angereicherte Dokument Struktur und Substanz, da jeder Skill seine Ausgabe als Knoten in das Diagramm schreibt.
Nachdem die Ausführung des Skillsets abgeschlossen ist, fließt die Ausgabe eines angereicherten Dokuments über benutzerdefinierte Ausgabefeldzuordnungen in einen Index. Alle unformatierten Inhalte, die intakt von der Quelle in einen Index übertragen werden sollen, werden durch Feldzuordnungen definiert.
Um die angewandte KI zu konfigurieren, geben Sie Einstellungen in einem Skillset und Indexer an.
Definition von Qualifikationsgruppen
Ein Skillset ist ein Array eines oder mehrerer Skills, die eine Anreicherung ausführen, z. B. Übersetzen von Text oder optische Zeichenerkennung (OCR) in einer Bilddatei. Bei Skills kann es sich um integrierte Skills von Microsoft handeln oder um benutzerdefinierte Skills für Verarbeitungslogik, die Sie extern hosten. Ein Skillset produziert angereicherte Dokumente, die bei der Indizierung verwendet oder in einen Wissensspeicher projiziert werden.
Alle Skills verfügen über einen Kontext, Eingaben und Ausgaben:
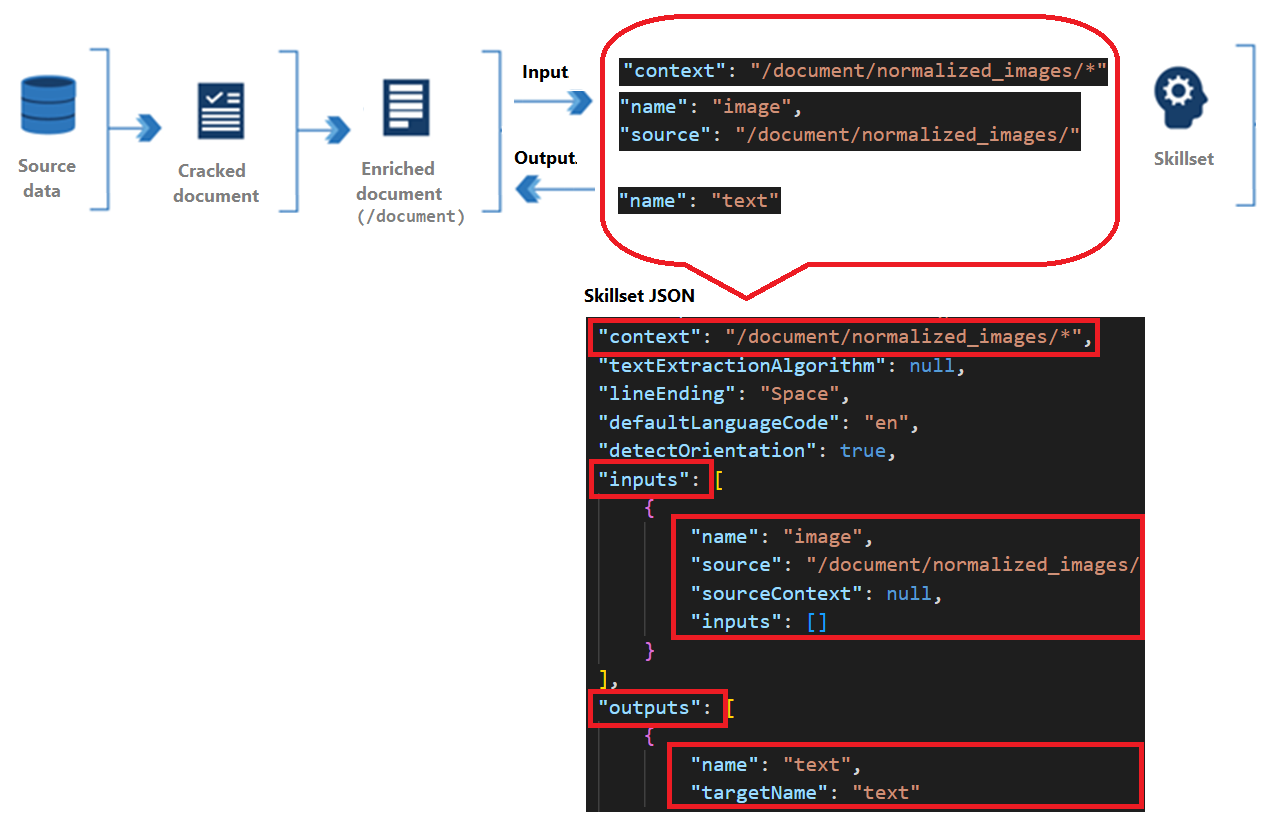
Kontext bezieht sich auf den Umfang des Vorgangs, was einmal pro Dokument oder einmal für jedes Element in einer Sammlung sein könnte.
Eingaben stammen aus Knoten in einem angereicherten Dokument, wobei „Quelle“ und „Name“ einen bestimmten Knoten identifizieren.
Die Ausgabe wird als neuer Knoten an das angereicherte Dokument zurückgesendet. Werte sind der „Name“ des Knotens und der Knoteninhalt. Wenn ein Knotenname dupliziert ist, können Sie einen Zielnamen zum Eindeutigmachen festlegen.
Skillkontext
Jeder Skill verfügt über einen Kontext, bei dem es sich um das gesamte Dokument (/document) oder einen Knoten weiter unten in der Struktur (/document/countries/*) handeln kann.
Ein Kontext bestimmt Folgendes:
Die Anzahl der Skillausführungen für einen einzelnen Wert (einmal pro Feld, pro Dokument) oder für eine Sammlung, wobei das Hinzufügen von
/*dazu führt, dass für jede Instanz in der Sammlung ein Skill aufgerufen wird.Ausgabedeklaration oder die Stelle, an der in der Anreicherungsstruktur die Skillausgaben hinzugefügt werden. Ausgaben werden der Struktur immer als untergeordnete Elemente des Kontextknotens hinzugefügt.
Form der Eingaben. Bei Sammlungen mit mehreren Ebenen hat das Festlegen des Kontexts auf die übergeordnete Sammlung Auswirkungen auf die Form der Eingabe für den Skill. Wenn Sie beispielsweise über eine Anreicherungsstruktur mit einer Liste mit Ländern/Regionen verfügen, von denen jedes Land bzw. jede Region mit einer Liste mit Bundesländern angereichert ist, die wiederum jeweils eine Liste mit Postleitzahlen enthalten, bestimmt die Art, wie Sie den Kontext festlegen, die Art, wie die Eingabe interpretiert wird.
Kontext Eingabe Form der Eingabe Aufruf einer Qualifikation /document/countries/*/document/countries/*/states/*/zipcodes/*Eine Liste aller Postleitzahlen im Land oder der Region Einmal pro Land oder Region /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Eine Liste aller Postleitzahlen im Bundesland Einmal pro Kombination aus Land oder Region und Bundesland/Kanton
Skillabhängigkeiten
Skills können unabhängig voneinander und parallel ausgeführt werden, oder sequenziell, wenn Sie die Ausgabe eines Skills in einen anderen Skill einspeisen. Im folgenden Beispiel werden zwei sequenziell ausgeführte integrierte Skills veranschaulicht:
Der erste Skill ist ein Skill zur Textaufteilung, der den Inhalt des Quellfelds „reviews_text“ als Eingabe akzeptiert und diesen Inhalt als Ausgabe in „Seiten“ mit 5.000 Zeichen aufteilt. Um für Skills wie die Stimmungserkennung bessere Ergebnisse zu erzielen, können große Texte in kleinere Blöcke aufgeteilt werden.
Der zweite Skill ist ein Skill zur Stimmungserkennung, der „Seiten“ als Eingabe akzeptiert und ein neues Feld namens „Sentiment“ (Stimmung) als Ausgabe erstellt, das die Ergebnisse der Stimmungsanalyse enthält.
Beachten Sie, wie die Ausgabe des ersten Skills („pages“) in der Stimmungsanalyse verwendet wird, wobei „/document/reviews_text/pages/*“ sowohl Kontext als auch Eingabe ist. Weitere Informationen zur Pfadformulierung finden Sie unter Wie man auf Anreicherungen verweist.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Anreicherungsstruktur
Bei einem angereicherten Dokument handelt es sich um eine temporäre baumähnliche Struktur, die während der Skillausführung erstellt wird und mit der alle über den Skill vorgenommenen Änderungen erfasst werden. Zusammen werden Anreicherungen als Hierarchie adressierbarer Knoten dargestellt. Knoten enthalten zudem auch alle nicht angereicherten Felder, von der externen Datenquelle unverändert übergeben werden.
Ein angereichertes Dokument ist für die Dauer der Ausführung eines Skillsets vorhanden, kann jedoch zwischengespeichert oder in einem Wissensspeicher gespeichert werden.
Bei einem angereicherten Dokument handelt es sich anfänglich nur um den Inhalt, der bei der Dokumententschlüsselung aus der Datenquelle extrahiert wird. Dabei werden Texte und Bilder aus der Quelle extrahiert und für die Sprach- oder Bildanalyse verfügbar gemacht.
Beim anfänglichen Inhalt handelt es sich um Metadaten und den Stammknoten (document/content). Der Stammknoten ist in der Regel ein ganzes Dokument oder ein normalisiertes Bild, das bei der Dokumententschlüsselung aus einer Datenquelle extrahiert wird. Die Art, wie der Inhalt in einer Anreicherungsstruktur formuliert wird, variiert je nach Datenquellentyp. In der folgenden Tabelle wird für verschiedene unterstützte Datenquellen der Zustand eines Dokuments gezeigt, das in die Anreicherungspipeline wechselt:
| Datenquelle\Analysemodus | Standard | JSON, JSON-Zeilen & CSV |
|---|---|---|
| Blob Storage | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
Nicht zutreffend |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
Nicht zutreffend |
Beim Ausführen von Skills wird der Anreicherungsstruktur die Ausgabe in Form von neuen Knoten hinzugefügt. Wenn die Skillausführung sich über das gesamte Dokument erstreckt, werden Knoten auf der ersten Ebene unter dem Stamm hinzugefügt.
Knoten können als Eingaben für nachgelagerte Skills verwendet werden. Beispielsweise können Skills, die Inhalte erstellen, z. B. übersetzte Zeichenfolgen, Eingaben für Skills werden, die Entitäten erkennen oder Schlüsselbegriffe extrahieren.
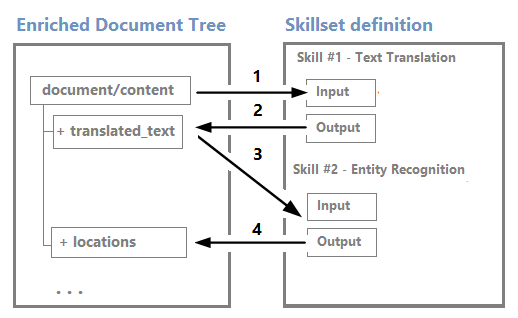
Obwohl Sie eine Anreicherungsstruktur über den visuellen Editor für Debugsitzungen visualisieren und damit arbeiten können, handelt es sich größtenteils um eine interne Struktur.
Anreicherungen sind unveränderlich: Die Knoten können nach der Erstellung nicht bearbeitet werden. Mit steigender Komplexität Ihrer Qualifikationen wird auch Ihre Anreicherungsstruktur komplexer, aber nicht alle Knoten in der Anreicherungsstruktur müssen in den Index oder Wissensspeicher aufgenommen werden.
Sie können nur eine Teilmenge der Anreicherungsausgaben selektiv speichern, sodass Sie nur die Elemente beibehalten, die Sie verwenden möchten. Die Ausgabefeldzuordnungen in Ihrer Indexerdefinition bestimmen, welche Inhalte tatsächlich im Suchindex aufgenommen werden. Entsprechend können Sie beim Erstellen eines Wissensspeichers Ausgaben Formen zuordnen, die Projektionen zugewiesen sind.
Hinweis
Das Anreicherungsstrukturformat ermöglicht es der Anreicherungspipeline, selbst primitiven Datentypen Metadaten anzufügen. Die Metadaten sind keine gültigen JSON-Objekte, können jedoch in Projektionsdefinitionen in einem Wissensspeicher in ein gültiges JSON-Format projiziert werden. Weitere Informationen hierzu finden Sie unter Der Skill „Shaper“.
Indexerdefinition
Ein Indexer verfügt über Eigenschaften und Parameter, die zum Konfigurieren der Indexerausführung verwendet werden. Zu diesen Eigenschaften gehören Zuordnungen, die den Datenpfad auf Felder in einem Suchindex festlegen.

Es gibt zwei Sätze von Zuordnungen:
fieldMappings ordnen ein Quellfeld einem Suchfeld zu.
outputFieldMappings ordnen einen Knoten in einem angereicherten Dokument einem Suchfeld zu.
Die Eigenschaft sourceFieldName gibt entweder ein Feld in Ihrer Datenquelle oder einen Knoten in einer Anreicherungsstruktur an. Die Eigenschaft targetFieldName gibt das Suchfeld in einem Index an, der den Inhalt empfängt.
Beispiel für eine Anreicherung
In diesem Beispiel wird anhand des Skillsets für Hotelbewertungen als Bezugspunkt erläutert, wie sich eine Anreicherungsstruktur mithilfe von konzeptionellen Diagrammen durch die Ausführung von Skills weiterentwickelt.
Anhand dieses Beispiels wird zudem Folgendes erläutert:
- Die Funktionsweise des Kontexts und der Eingaben eines Skills, um zu bestimmen, wie oft ein Skill ausgeführt wird
- Die Form der Eingabe in Abhängigkeit vom Kontext
In diesem Beispiel enthalten Quellfelder aus einer CSV-Datei Kundenbewertungen zu Hotels („reviews_text“) und Bewertungen („reviews_rating“). Über den Indexer werden Metadatenfelder aus Blob Storage hinzugefügt und über Skills übersetzte Texte, Stimmungsbewertungen und die Schlüsselbegriffserkennung.
Im Beispiel für Hotelbewertungen stellt ein „Dokument“ innerhalb des Anreicherungsprozesses eine einzelne Hotelbewertung dar.
Tipp
Sie können einen Suchindex und einen Wissensspeicher für diese Daten im Azure-Portal oder über REST APIs erstellen. Sie können auch Debugsitzungen verwenden, um Informationen über Zusammensetzung, Abhängigkeiten und Auswirkungen von Skillsets auf eine Anreicherungsstruktur zu erhalten. Die Bilder in diesem Artikel stammen von Debugsitzungen.
Konzeptionell sieht die anfängliche Anreicherungsstruktur wie folgt aus:

Der Stammknoten für alle Anreicherungen ist "/document". Wenn Sie Blobindexer verwenden, verfügt der "/document"-Knoten über die untergeordneten Knoten "/document/content" und "/document/normalized_images". Bei CSV-Daten wie in diesem Beispiel werden die Spaltennamen Knoten unter "/document" zugeordnet.
Skill Nr. 1: Split-Skill
Wenn der Quellinhalt aus großen Textblöcken besteht, ist es hilfreich, ihn in kleinere Komponenten zu zerlegen, um eine größere Genauigkeit bei der Erkennung von Sprache, Stimmung und Schlüsselbegriffen zu erreichen. Es stehen zwei Einheiten zur Verfügung: Seiten und Sätze. Eine Seite besteht aus ungefähr 5.000 Zeichen.
Ein Skill zur Textaufteilung erfolgt normalerweise an erster Stelle in einem Skillset.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Mit dem Skillkontext "/document/reviews_text" wird der Skill „Aufteilung“ einmal für reviews_text ausgeführt. Die Qualifikationsausgabe ist eine Liste, in der reviews_text in 5.000-Zeichen-Segmente aufgeteilt ist. Die Ausgabe des Aufteilungsskills wird pages genannt und der Anreicherungsstruktur hinzugefügt. Mit dem Feature targetName können Sie eine Qualifikationsausgabe umbenennen, bevor sie der Anreicherungsstruktur hinzugefügt wird.
Die Anreicherungsstruktur verfügt jetzt über einen neuen Knoten, der unter den Kontext der Qualifikation platziert wird. Dieser Knoten ist für alle Qualifikationen, Projektionen oder Ausgabefeldzuordnungen verfügbar.

Um auf eine der Anreicherungen zuzugreifen, die einem Knoten durch eine Qualifikation hinzugefügt wurden, ist der vollständige Pfad für die Anreicherung erforderlich. Wenn Sie z. B. den Text aus dem Knoten pages als Eingabe für einen anderen Skill verwenden möchten, geben Sie ihn als "/document/reviews_text/pages/*" an. Weitere Informationen zu Pfaden finden Sie unter Verweisen auf Anreicherungen.
Qualifikation 2: Sprachenerkennung
Dokumente zur Hotelbewertung enthalten Kundenfeedback in mehreren Sprachen. Der Skill zur Spracherkennung bestimmt, welche Sprache verwendet wird. Das Ergebnis wird dann an die Extraktion von Schlüsselbegriffen und die Erkennung von Stimmungen (nicht dargestellt) weitergeleitet, wobei die Sprache bei der Erkennung von Stimmungen und Begriffen berücksichtigt wird.
Der Skill zur Spracherkennung ist zwar der dritte im Skillset definierte Skill (Skill 3), wird aber als nächster Skill ausgeführt. Da er keine Eingaben erfordert, wird er parallel mit dem vorherigen Skill ausgeführt. Genau wie die Qualifikation „Aufteilung“ wird die Qualifikation „Spracherkennung“ auch einmal für jedes Dokument aufgerufen. Die Anreicherungsstruktur verfügt jetzt über einen neuen Knoten für die Sprache.

Skills 3 und 4 (Stimmungsanalyse und Schlüsselbegriffserkennung)
Kundenfeedback spiegelt eine Reihe von positiven und negativen Erfahrungen wider. Mit dem Skill „Stimmungsanalyse“ wird das Feedback analysiert und entlang eines Kontinuums eine Bewertung von negativen zu positiven Werten oder bei einer unbestimmten Stimmung neutral zugewiesen. Parallel zur Stimmungsanalyse werden mit der Schlüsselbegriffserkennung folgerichtig erscheinende Wörter und kurze Ausdrücke identifiziert und extrahiert.
Im Kontext von /document/reviews_text/pages/* werden die beiden Skills „Stimmungsanalyse“ und „Schlüsselbegriffserkennung“ einmal für jedes Element in der Sammlung pages aufgerufen. Die Ausgabe der Qualifikation ist ein Knoten unter dem zugeordneten page-Element.
Wenn Sie sich jetzt die restlichen Qualifikationen in der Qualifikationsgruppe anschauen, sollten Sie sich vorstellen können, wie die Anreicherungsstruktur mit der Ausführung jeder weiteren Qualifikation weiter wächst. Einige Qualifikationen, wie z.B. die Qualifikation „Zusammenführen“ und die Qualifikation „Shaper“, erstellen auch neue Knoten, verwenden jedoch nur Daten aus vorhandenen Knoten und erstellen keine eigenen neuen Anreicherungen.

Die Farben der Connectors in der Struktur oben zeigen an, dass die Anreicherungen durch unterschiedliche Skills erstellt wurden, und die Knoten müssen einzeln adressiert werden und sind nicht Teil des Objekts, das bei der Auswahl des übergeordneten Knotens zurückgegeben wird.
Skill 5: Skill „Shaper“
Wenn die Ausgabe einen Wissensspeicher enthält, fügen Sie in einem letzten Schritt den Skill „Shaper“ hinzu. Mit dem Skill „Shaper“ werden aus Knoten in einer Anreicherungsstruktur Formen erstellt. Es kann beispielsweise vorkommen, dass Sie mehrere Knoten in einer einzelnen Form konsolidieren möchten. Dann können Sie diese Form als Tabelle projizieren (aus den Knoten werden die Spalten einer Tabelle) und anhand des Namens an eine Tabellenprojektion übergeben.
Der Skill „Shaper“ erleichtert die Arbeit, da er sich auf die Strukturierung unter einem Skill konzentriert. Alternativ können Sie die Inlinestrukturierung innerhalb einzelner Projektionen verwenden. Mit dem Skill „Shaper“ wird einer Anreicherungsstruktur weder etwas hinzugefügt noch etwas weggenommen, er wird also nicht visualisiert. Der Skill „Shaper“ ist vielmehr ein Mittel, mit dem sich eine bereits vorhandene Anreicherungsstruktur neu formulieren lässt. Vom Konzept her ist dies vergleichbar mit der Erstellung von Sichten aus Tabellen in einer Datenbank.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Nächste Schritte
Nach der Einführung und einem Beispiel erstellen Sie als Nächstes Ihr erstes Skillset mithilfe von integrierten Skills.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für