Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dataflows sind eine cloudbasierte Self-Service-Technologie zur Datenaufbereitung. In diesem Artikel erstellen Sie Ihren ersten Dataflow, Sie rufen Daten für Ihren Dataflow ab, transformieren dann die Daten und veröffentlichen den Dataflow.
Voraussetzungen
Bevor Sie beginnen, müssen die folgenden Voraussetzungen erfüllt sein:
- Ein Microsoft Fabric Mandantenkonto mit einem aktiven Abonnement. Erstellen Sie ein kostenloses Konto.
- Stellen Sie sicher, dass Sie über einen Microsoft Fabric aktivierten Arbeitsbereich verfügen: Arbeitsbereich erstellen.
Erstellen eines Dataflows
In diesem Abschnitt erstellen Sie Ihren ersten Dataflow.
Hinweis
Seit April 2026 werden alle neuen Dataflow Gen2-Elemente standardmäßig mit CI/CD- und Git-Integrationsunterstützung erstellt. Die Option zum Erstellen von Dataflow Gen2-Elementen ohne CI/CD-Unterstützung ist nicht mehr verfügbar. Vorhandene Nicht-CI/CD-Datenflüsse funktionieren weiterhin.
Navigieren Sie zu Ihrem Microsoft Fabric Arbeitsbereich, indem Sie zum portal Microsoft Fabric navigieren, Workspaces im linken Navigationsbereich auswählen und dann Ihren Arbeitsbereich aus der Liste auswählen.
Wählen Sie +Neues Element und dann "Dataflow Gen2" aus.
Datensammlung
Lasst uns Daten holen! In diesem Beispiel rufen Sie Daten von einem OData-Dienst ab. Führen Sie die folgenden Schritte aus, um Daten in Ihren Dataflow abzurufen.
Wählen Sie im Dataflow-Editor die Option Daten abrufen und dann Weitere aus.
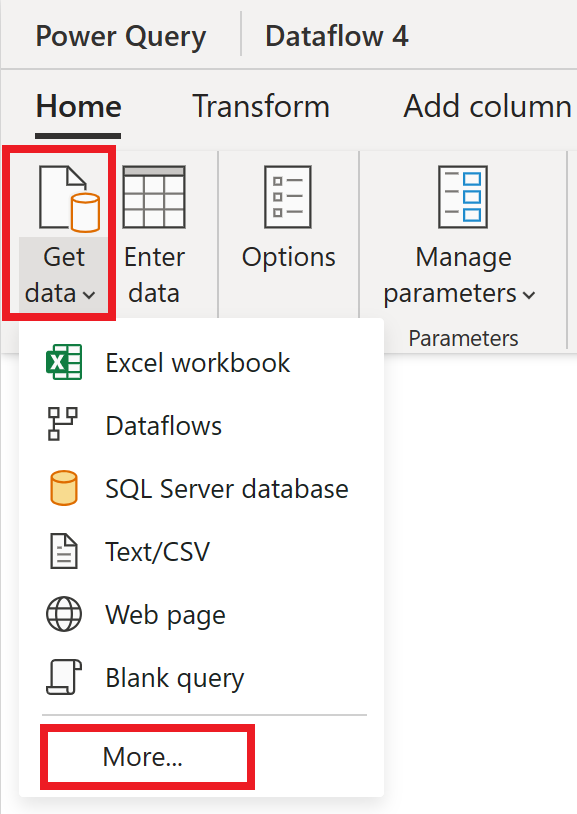
Wählen Sie in Datenquelle auswählen die Option Weitere anzeigen aus.
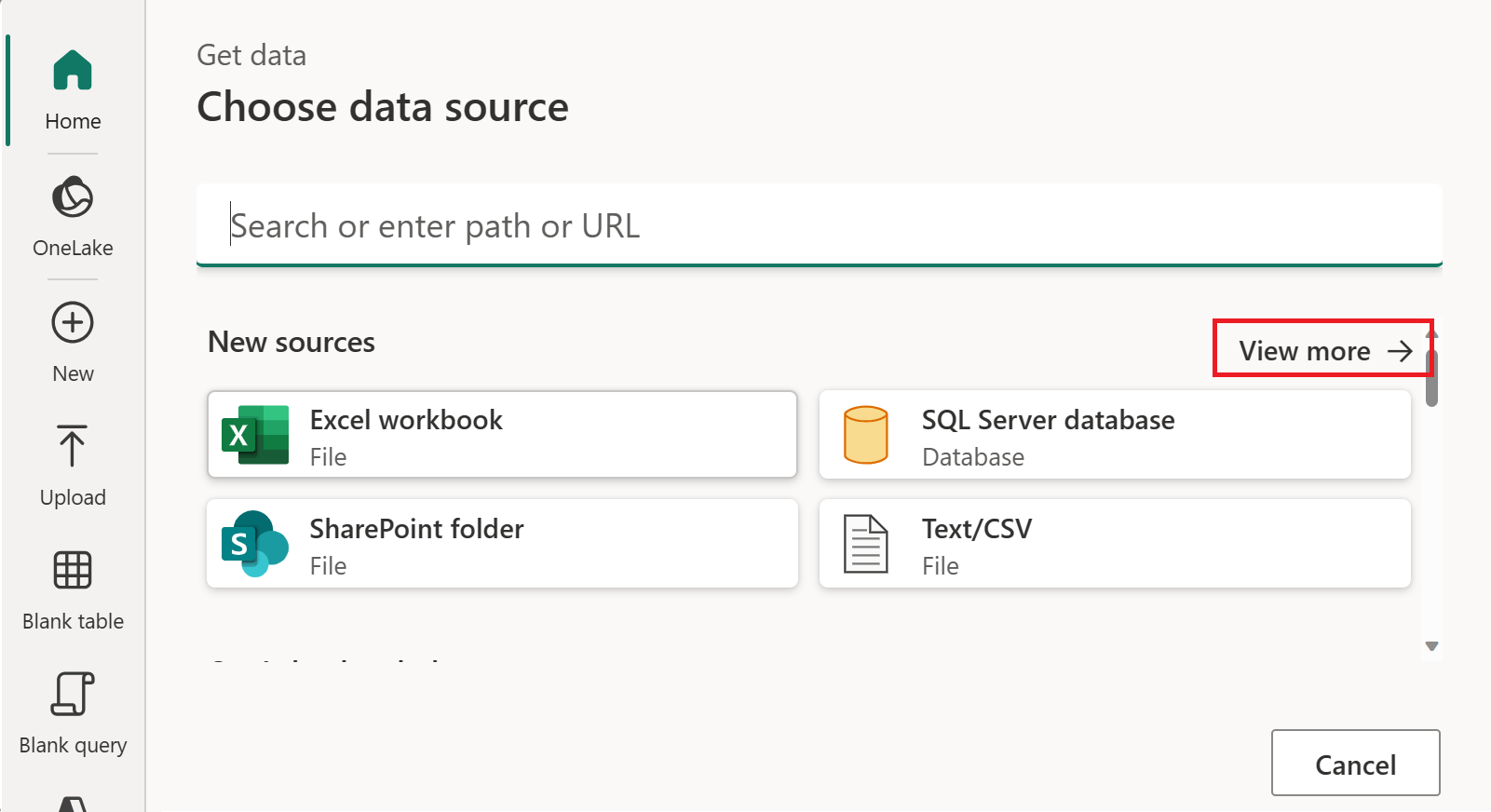
Wählen Sie in Neue Quelle die Option Andere>OData als Datenquelle aus.

Geben Sie die URL
https://services.odata.org/v4/northwind/northwind.svc/ein, und wählen Sie anschließend Weiter aus.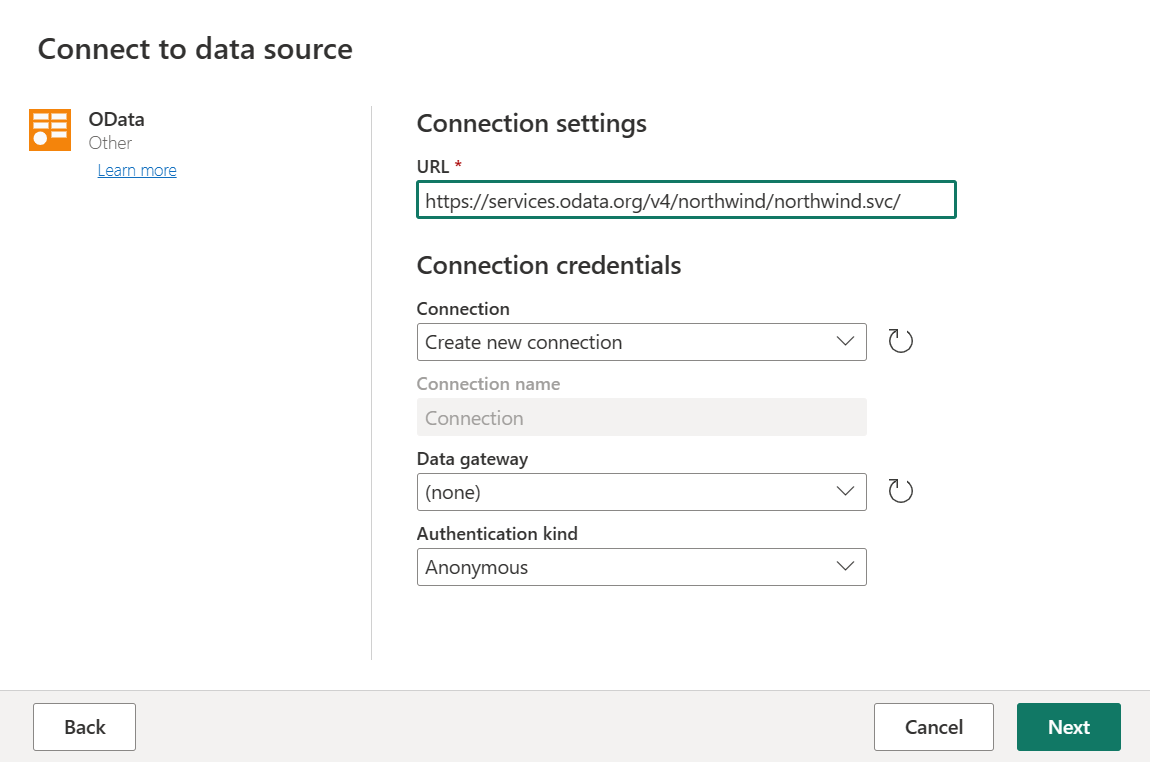
Wählen Sie die Tabellen Orders und Customers und dann Erstellen aus.
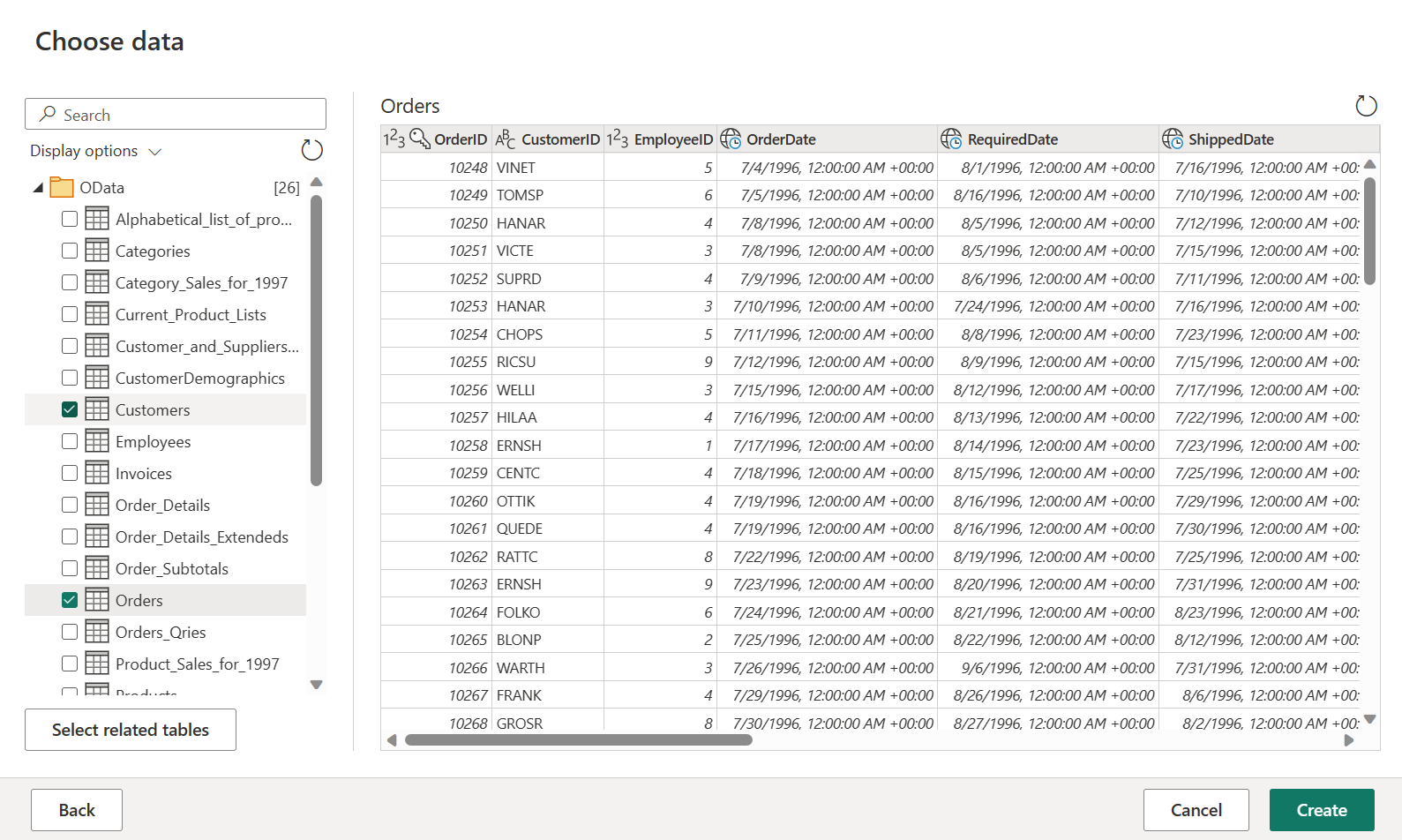



Weitere Informationen zur Datenerfassungsfunktion und -erfahrung finden Sie in der Übersicht über das Abrufen von Daten.
Anwenden von Transformationen und Veröffentlichen
Sie haben Ihre Daten in Ihren ersten Datenfluss geladen. Glückwunsch! Jetzt ist es an der Zeit, ein paar Transformationen anzuwenden, um diese Daten in das benötigte Shape zu übertragen.
Sie transformieren die Daten im Power Query-Editor. Eine detaillierte Übersicht über den Power Query-Editor finden Sie unter Die Power Query Benutzeroberfläche, dieser Abschnitt führt Sie jedoch durch die grundlegenden Schritte:
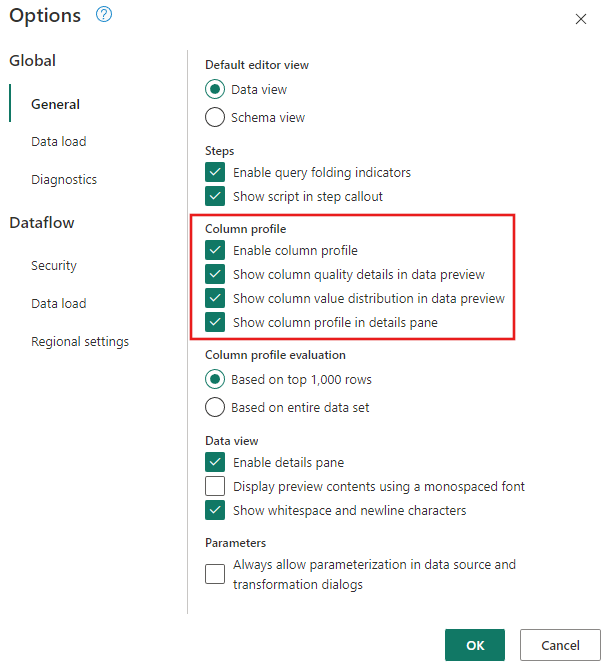
Stellen Sie sicher, dass die Datenprofilerstellungstools aktiviert sind. Wechseln Sie zu Home>Optionen>Globalen Optionen, und wählen Sie dann alle Optionen unter Spaltenprofil aus.
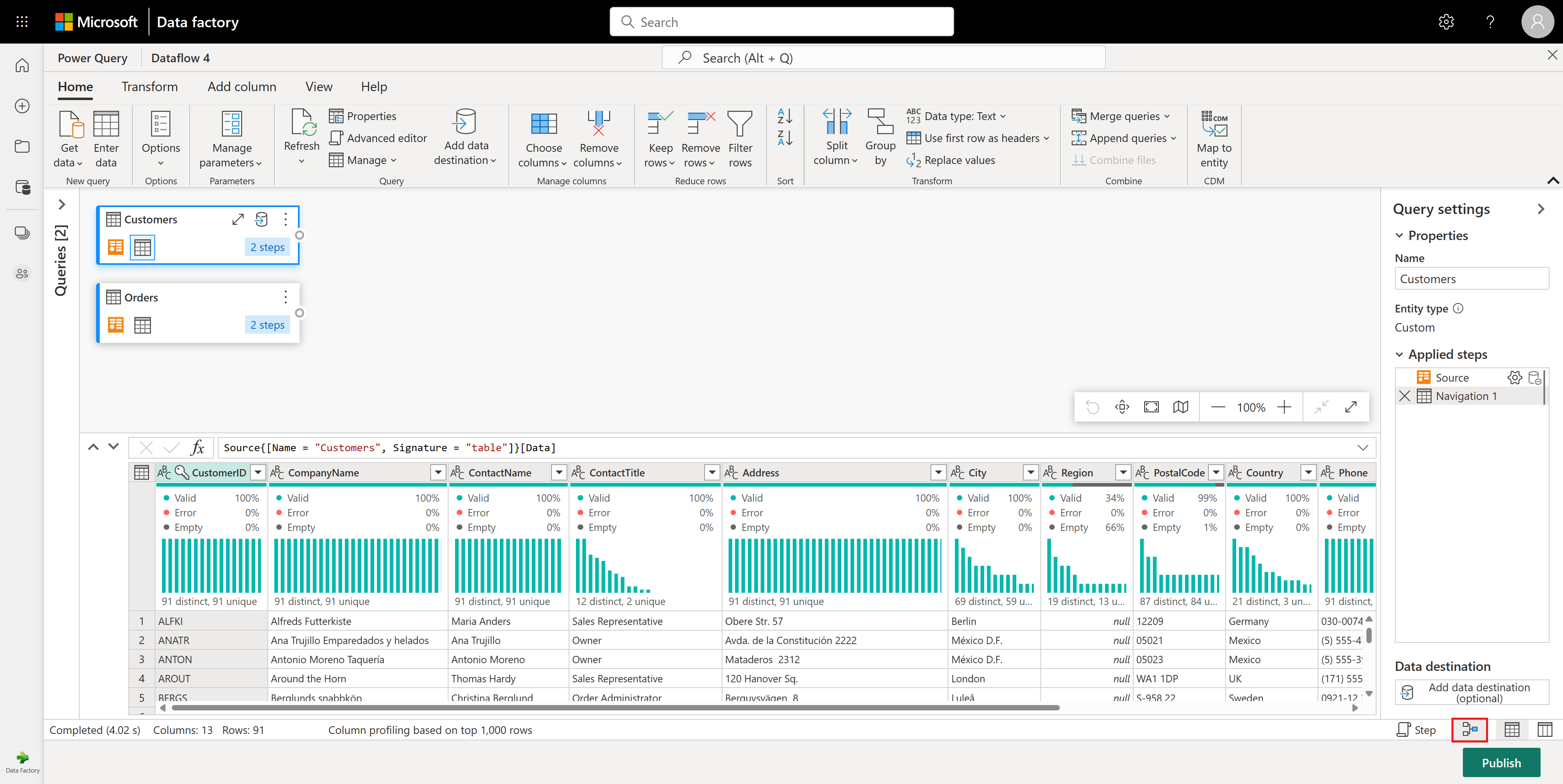
Stellen Sie außerdem sicher, dass Sie die Diagrammansicht mithilfe der Layoutkonfigurationen unter der Registerkarte View im Menüband des Power Query Editors aktivieren oder das Diagrammansichtssymbol auf der unteren rechten Seite des fensters Power Query auswählen.
Berechnen Sie in der Tabelle "Bestellungen" die Gesamtanzahl der Bestellungen pro Kunde: Wählen Sie in der Datenvorschau die Spalte "CustomerID" aus, und wählen Sie dann im Menüband auf der Registerkarte "Transformieren" die Option "Gruppieren nach" aus.
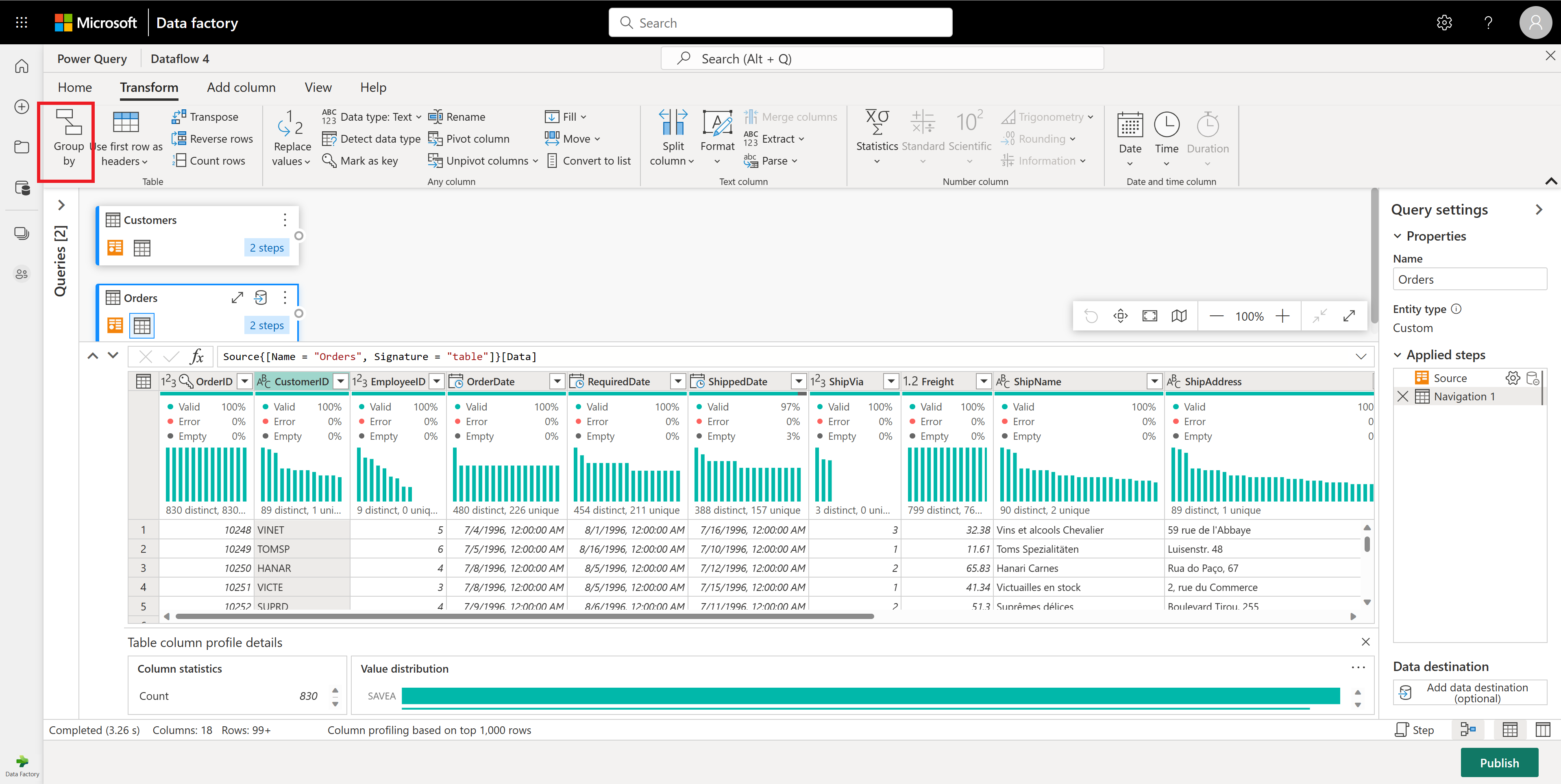
Sie führen eine Zählung der Zeilen als Aggregation innerhalb von Gruppieren nach durch. Weitere Informationen zu den Gruppenfunktionen finden Sie in "Gruppieren" oder "Zusammenfassen von Zeilen".
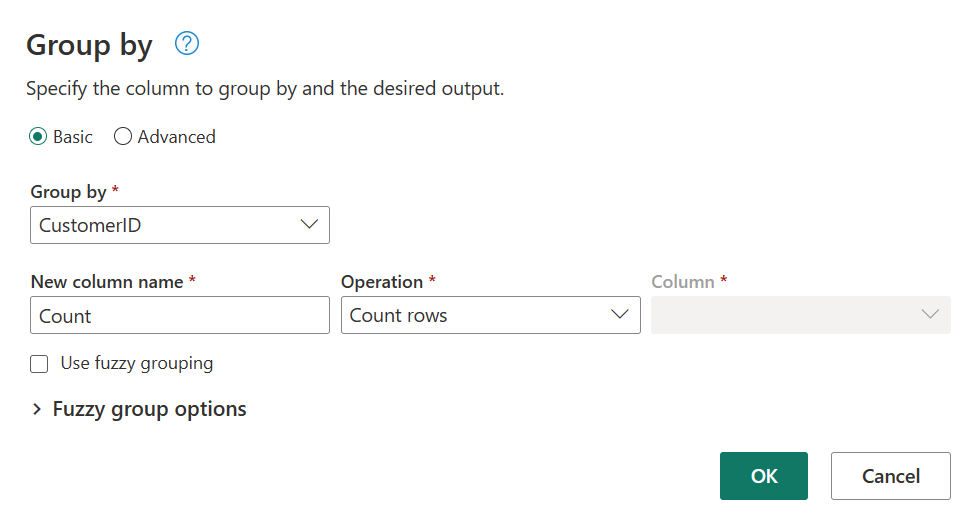
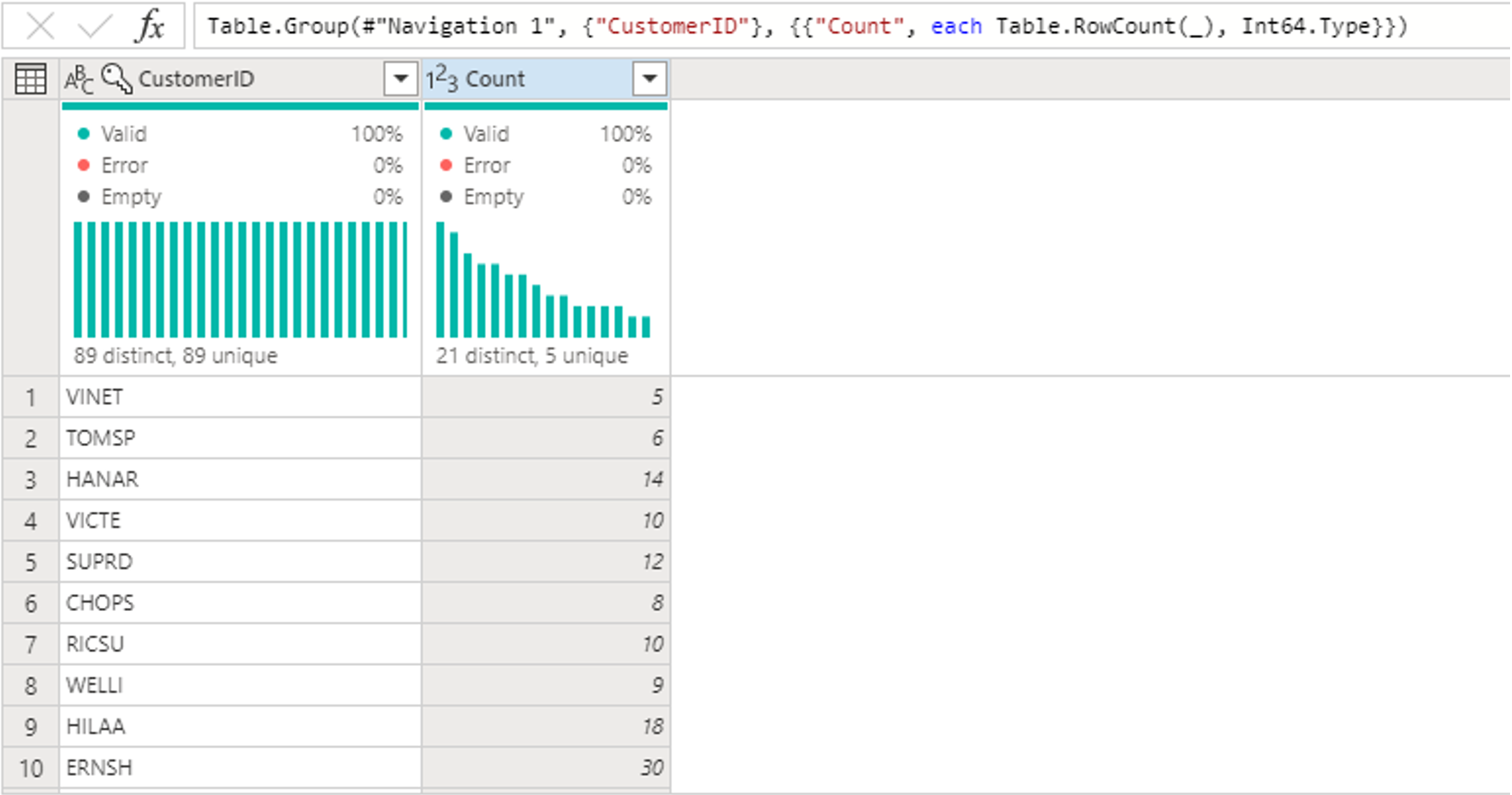
Nach dem Gruppieren von Daten in der Tabelle „Orders erhalten“ wir eine zweispaltige Tabelle mit den Spalten CustomerID und Count.
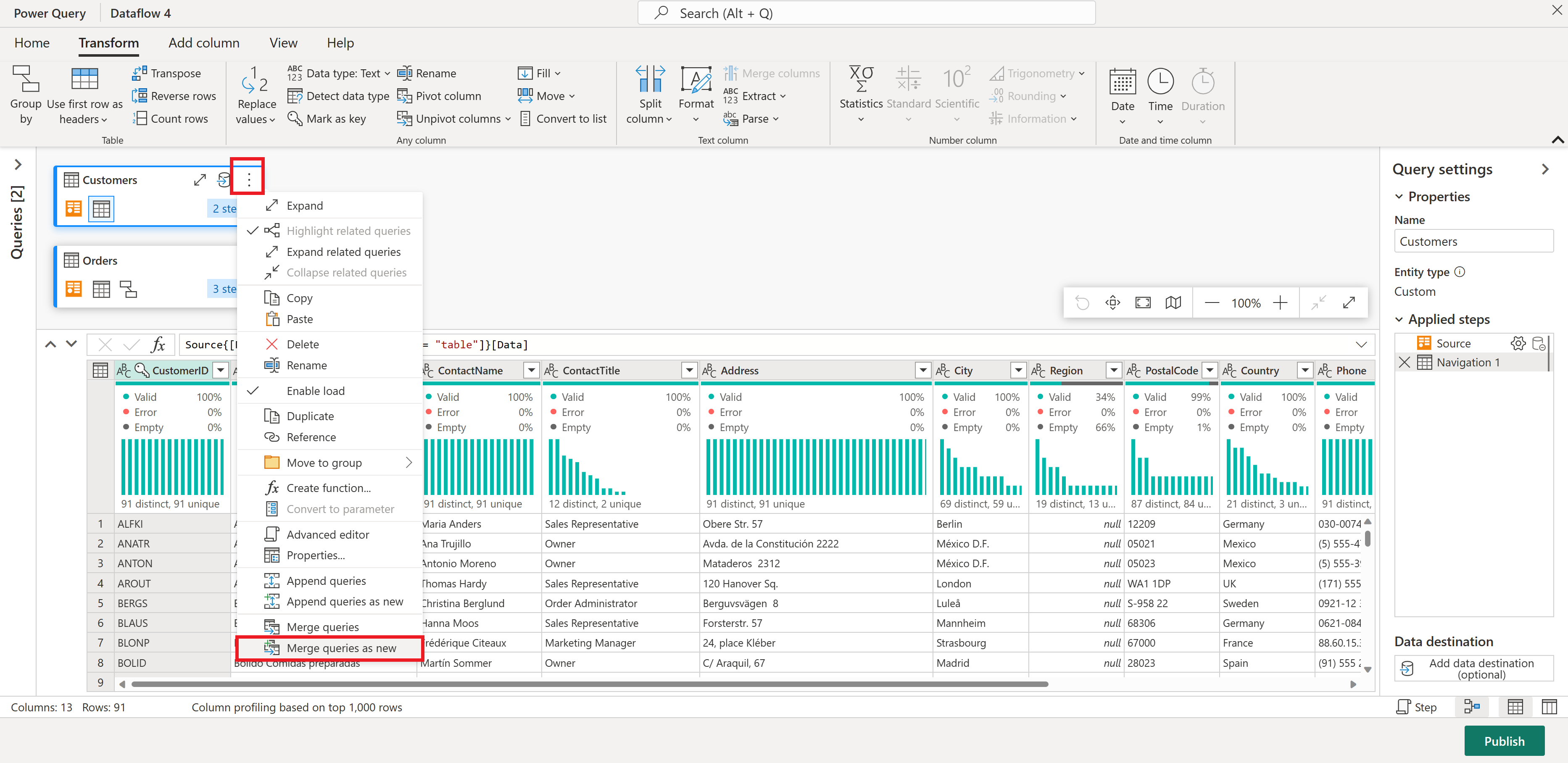
Als Nächstes möchten Sie Daten aus der Tabelle "Kunden" mit der Anzahl der Bestellungen pro Kunde kombinieren: Wählen Sie die Kundenabfrage in der Diagrammansicht aus, und verwenden Sie das Menü "⋮", um auf die Zusammenführungsabfragen als neue Transformation zuzugreifen.
Konfigurieren Sie den Zusammenführungsvorgang , indem Sie "CustomerID " als übereinstimmende Spalte in beiden Tabellen auswählen. Wählen Sie Ok.
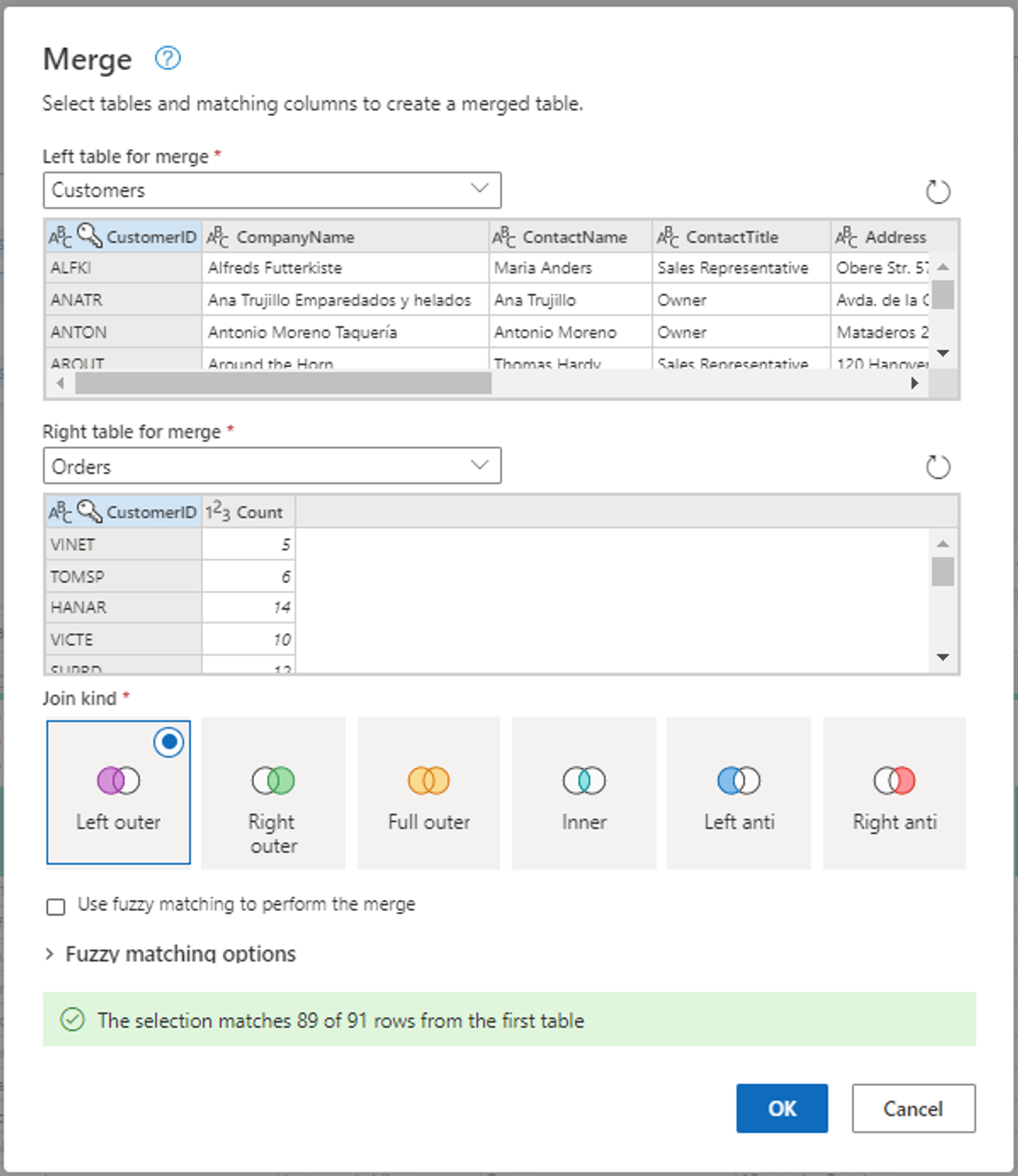
Screenshot des Fenster „Zusammenführen“, in dem als linke Tabelle für das Merge Zusammenführen die Tabelle „Customers“ und als rechte Tabelle für das Zusammenführen die Tabelle „Orders" festgelegt ist. Die Spalte „CustomerID“ ist sowohl für die Tabelle „Customers“ als auch die Tabelle „Orders“ ausgewählt. Außerdem ist die Verknüpfungsart auf „Linkes äußeres Join“ festgelegt. Alle anderen Optionen sind auf ihre Standardwerte festgelegt.
Jetzt gibt es eine neue Abfrage mit allen Spalten aus der Tabelle "Kunden" und einer Spalte mit geschachtelten Daten aus der Tabelle "Bestellungen".
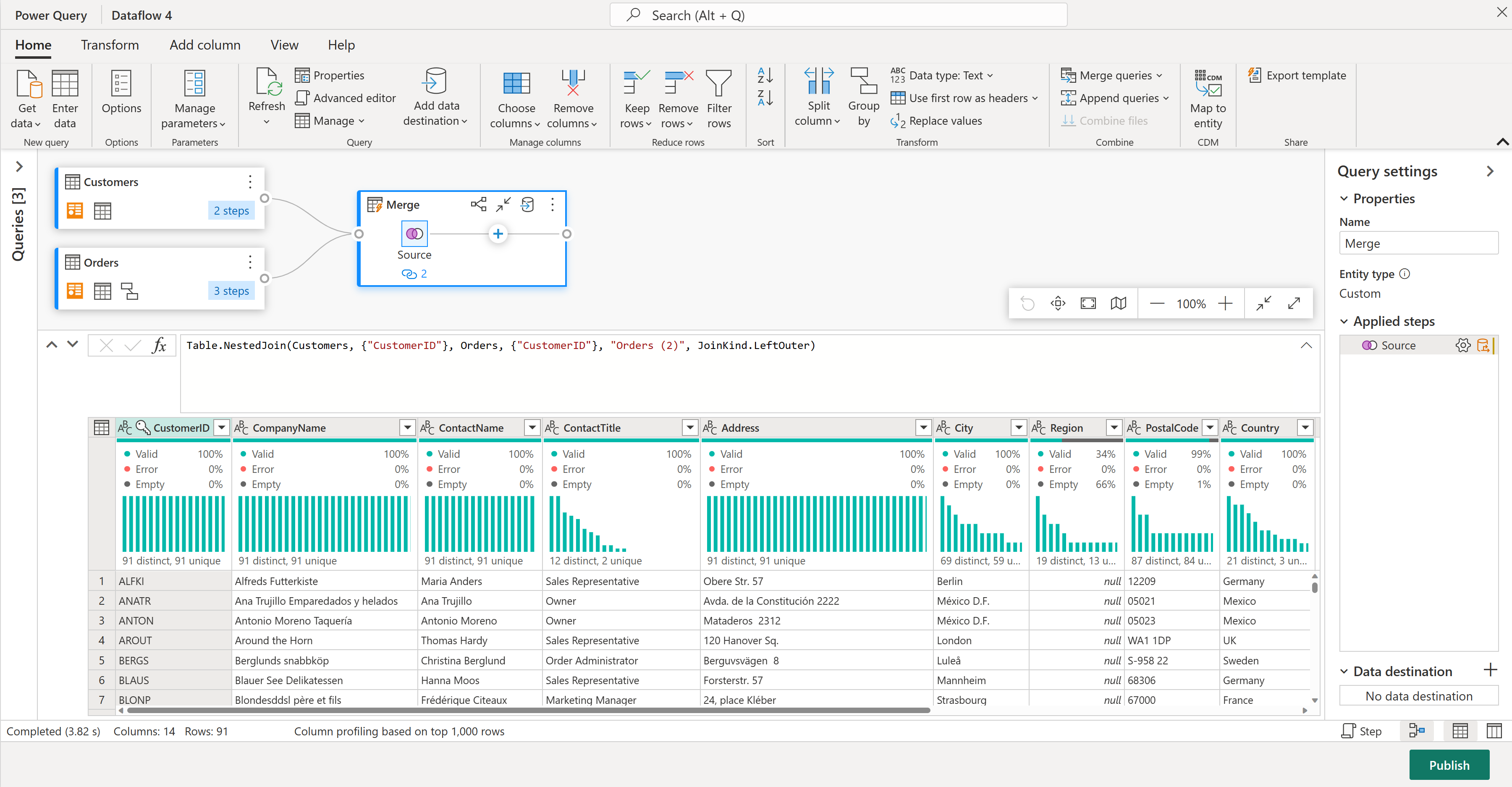
Konzentrieren wir uns auf nur ein paar Spalten aus der Tabelle "Kunden". Aktivieren Sie dazu die Schemaansicht, indem Sie in der unteren rechten Ecke des Datenfluss-Editors die Schaltfläche "Schemaansicht" auswählen.
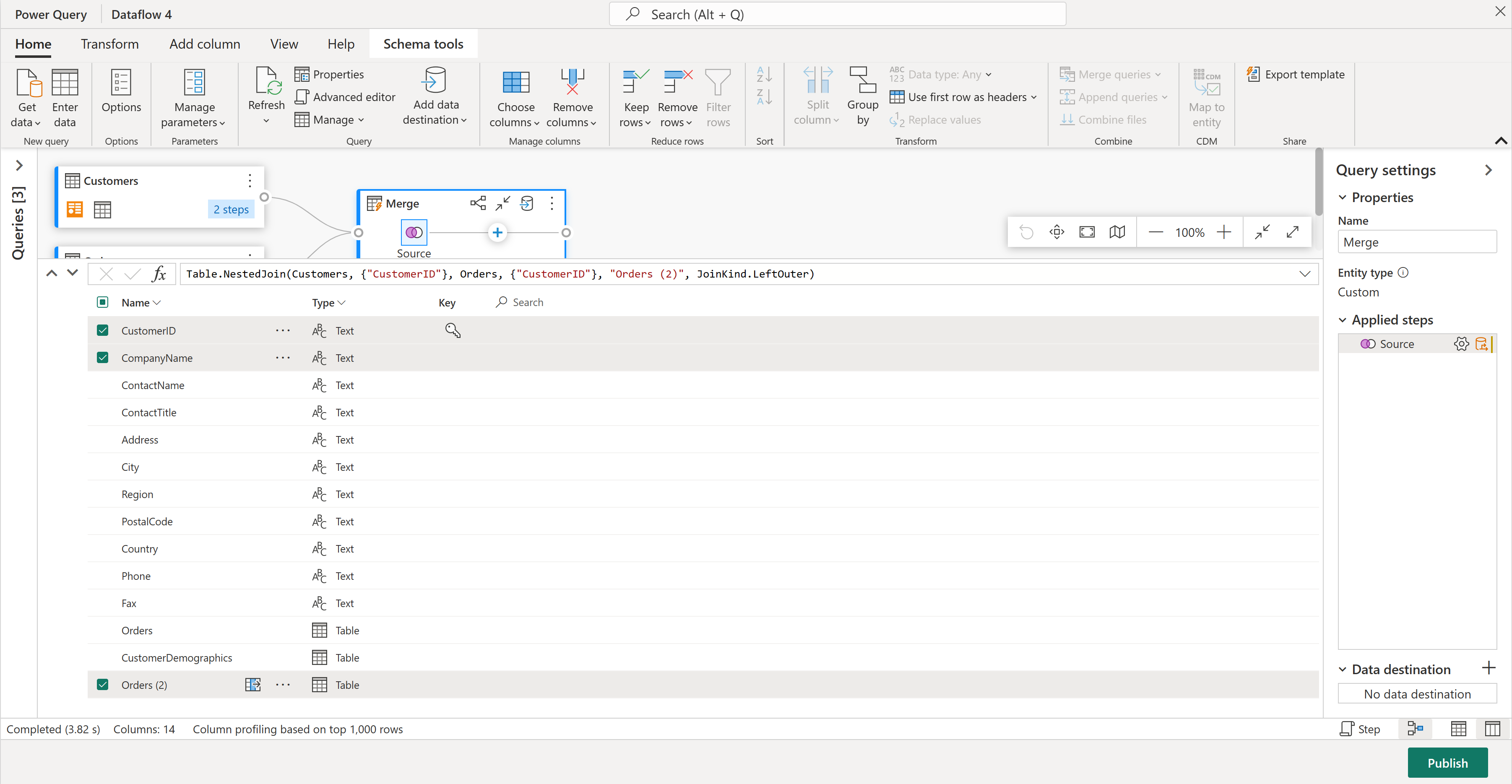
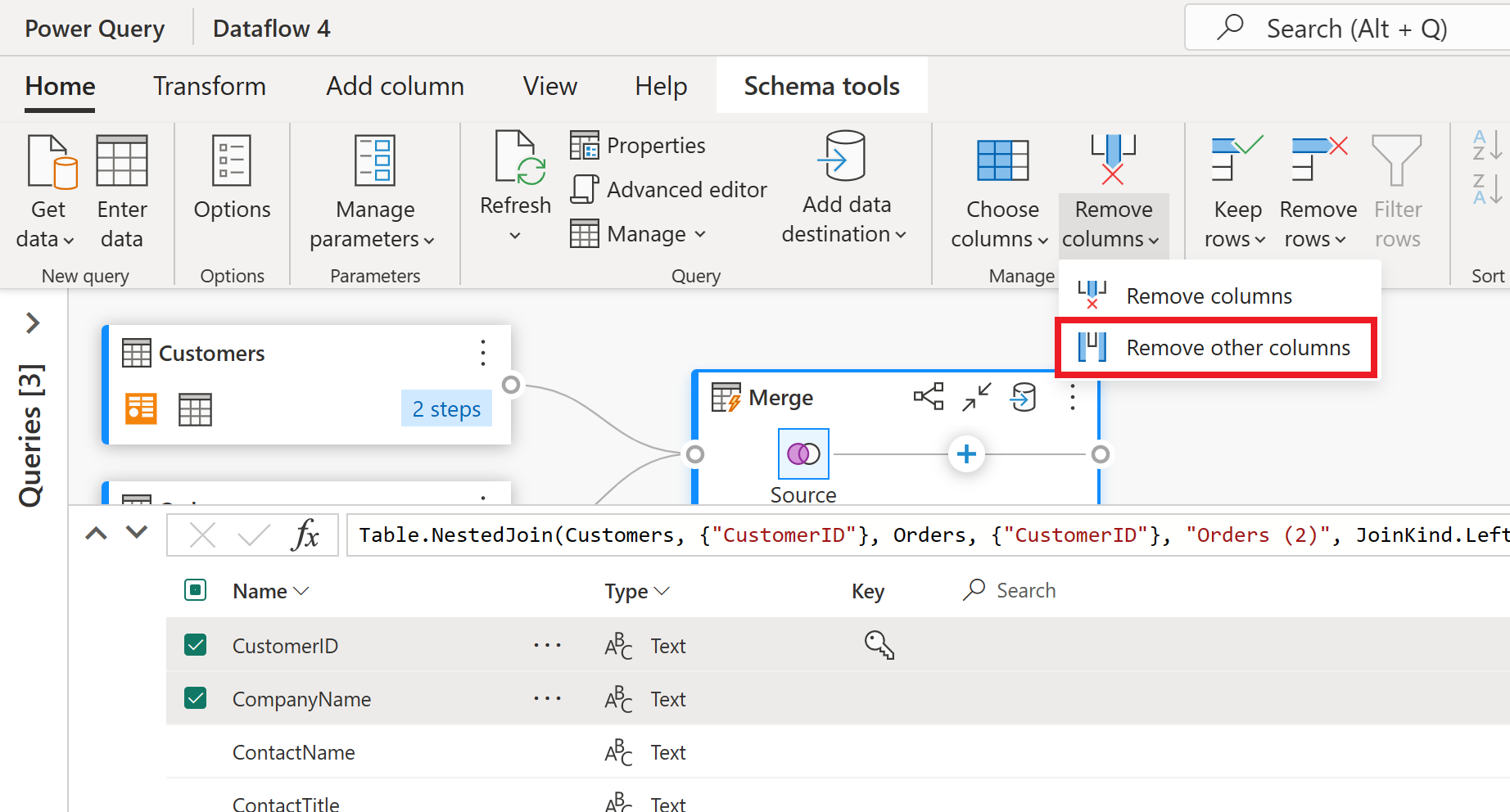
In der Schemaansicht werden alle Spalten in der Tabelle angezeigt. Wählen Sie CustomerID, CompanyName und Orders (2) aus. Wechseln Sie dann zur Registerkarte "Schematools ", wählen Sie "Spalten entfernen" und dann "Andere Spalten entfernen" aus. Dadurch werden nur die gewünschten Spalten beibehalten.
Die Spalte Bestellungen (2) enthält zusätzliche Details aus dem Zusammenführungsschritt. Um diese Daten anzuzeigen und zu verwenden, wählen Sie in der unteren rechten Ecke neben "Schemaansicht anzeigen" die Schaltfläche "Datenansicht anzeigen" aus. Wählen Sie dann in der Spaltenüberschrift "Bestellungen (2) " das Symbol " Spalte erweitern" und dann die Spalte "Anzahl" aus. Dadurch wird die Auftragsanzahl für jeden Kunden zu Ihrer Tabelle hinzugefügt.
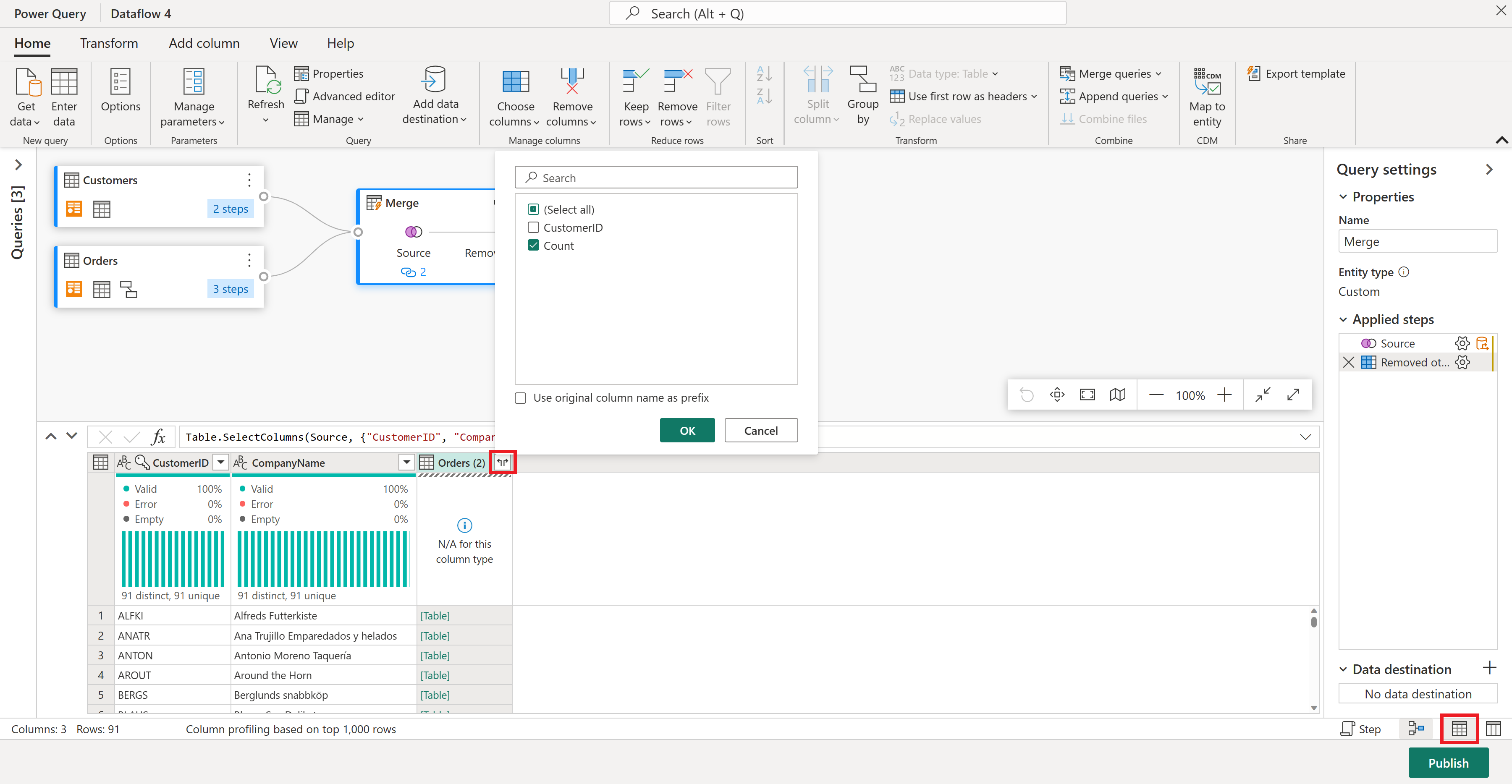
Lassen Sie uns nun Ihre Kunden nach der Anzahl der Bestellungen bewerten, die sie getätigt haben. Wählen Sie die Spalte "Anzahl" aus, wechseln Sie dann zur Registerkarte " Spalte hinzufügen ", und wählen Sie "Rangspalte" aus. Dadurch wird eine neue Spalte hinzugefügt, in der die Rangfolge der einzelnen Kunden basierend auf der Auftragsanzahl angezeigt wird.
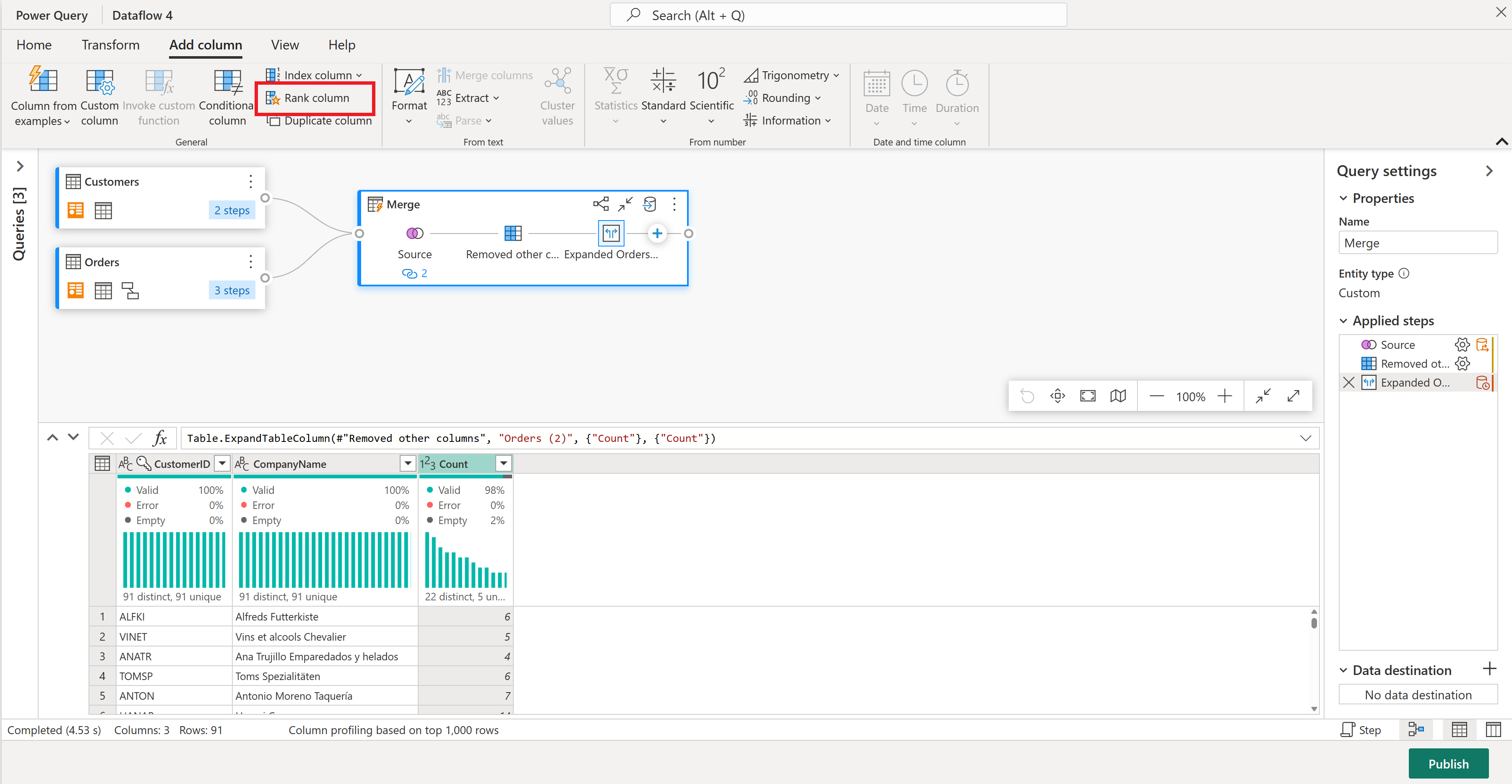
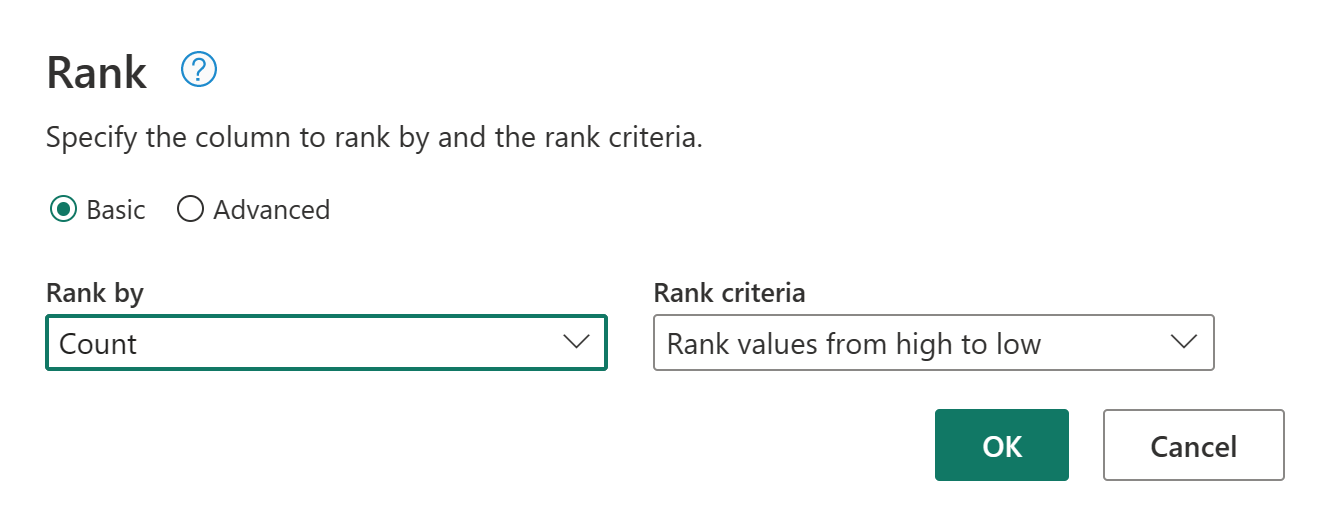
Behalten Sie die Standardeinstellungen in Spaltenrangfolge bei. Wählen Sie OK aus, um diese Transformation anzuwenden.
Benennen Sie nun die resultierende Abfrage im Bereich Abfrageeinstellungen auf der rechten Seite des Bildschirms in Ranked Customers um.
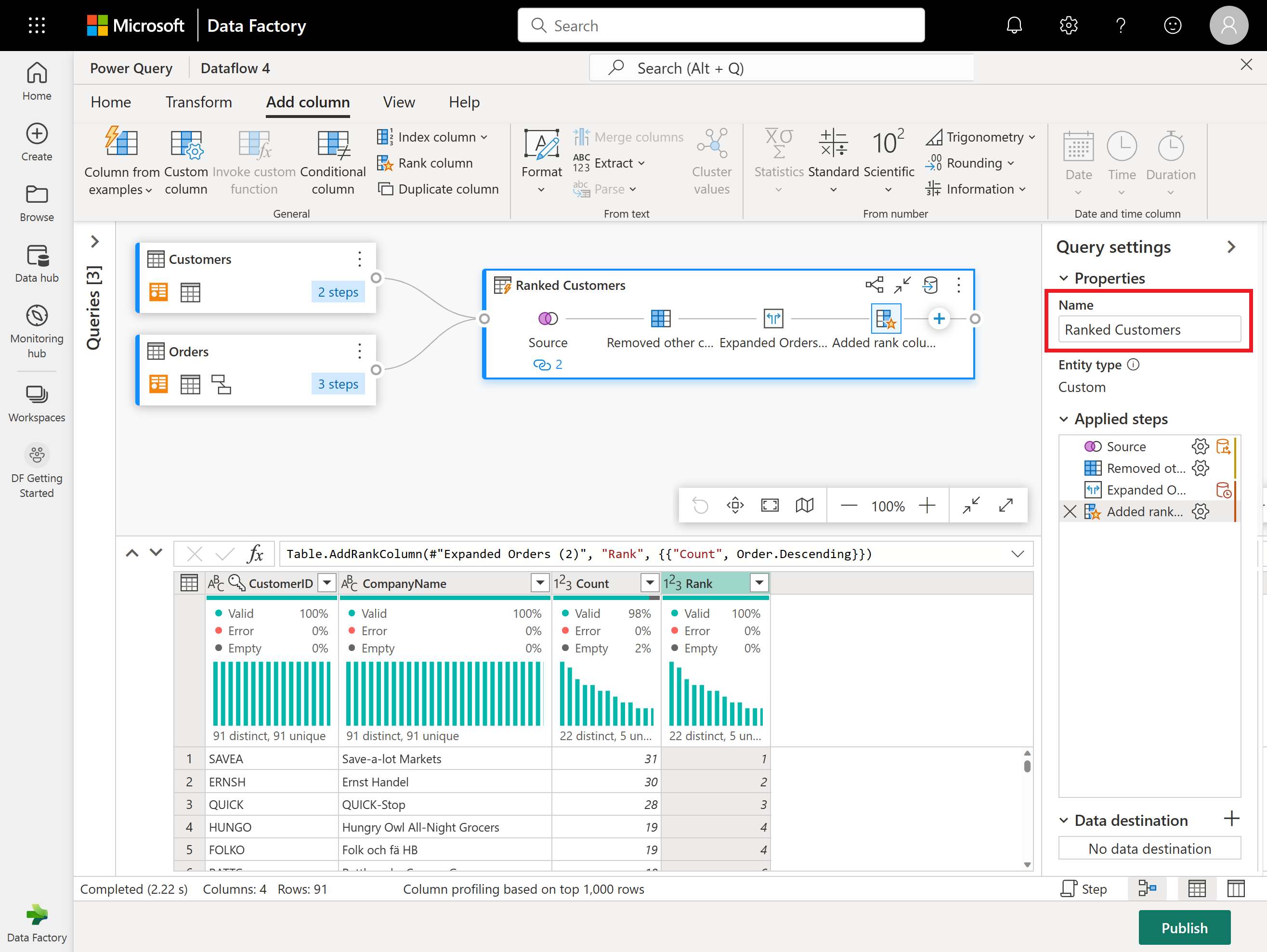
Sie sind bereit festzulegen, wo Ihre Daten hingehen. Scrollen Sie im Bereich "Abfrageeinstellungen " nach unten, und wählen Sie "Datenziel auswählen" aus.
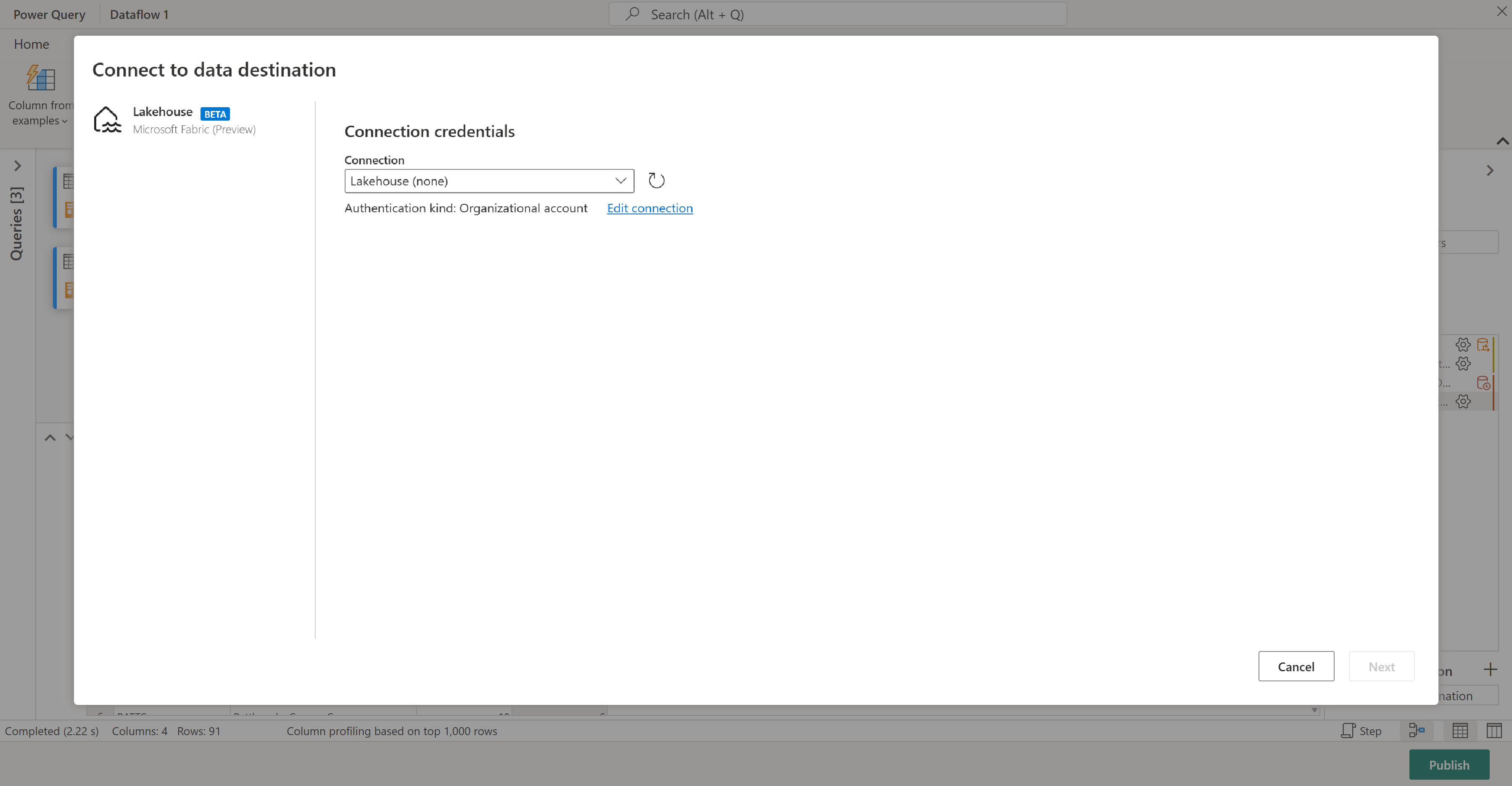
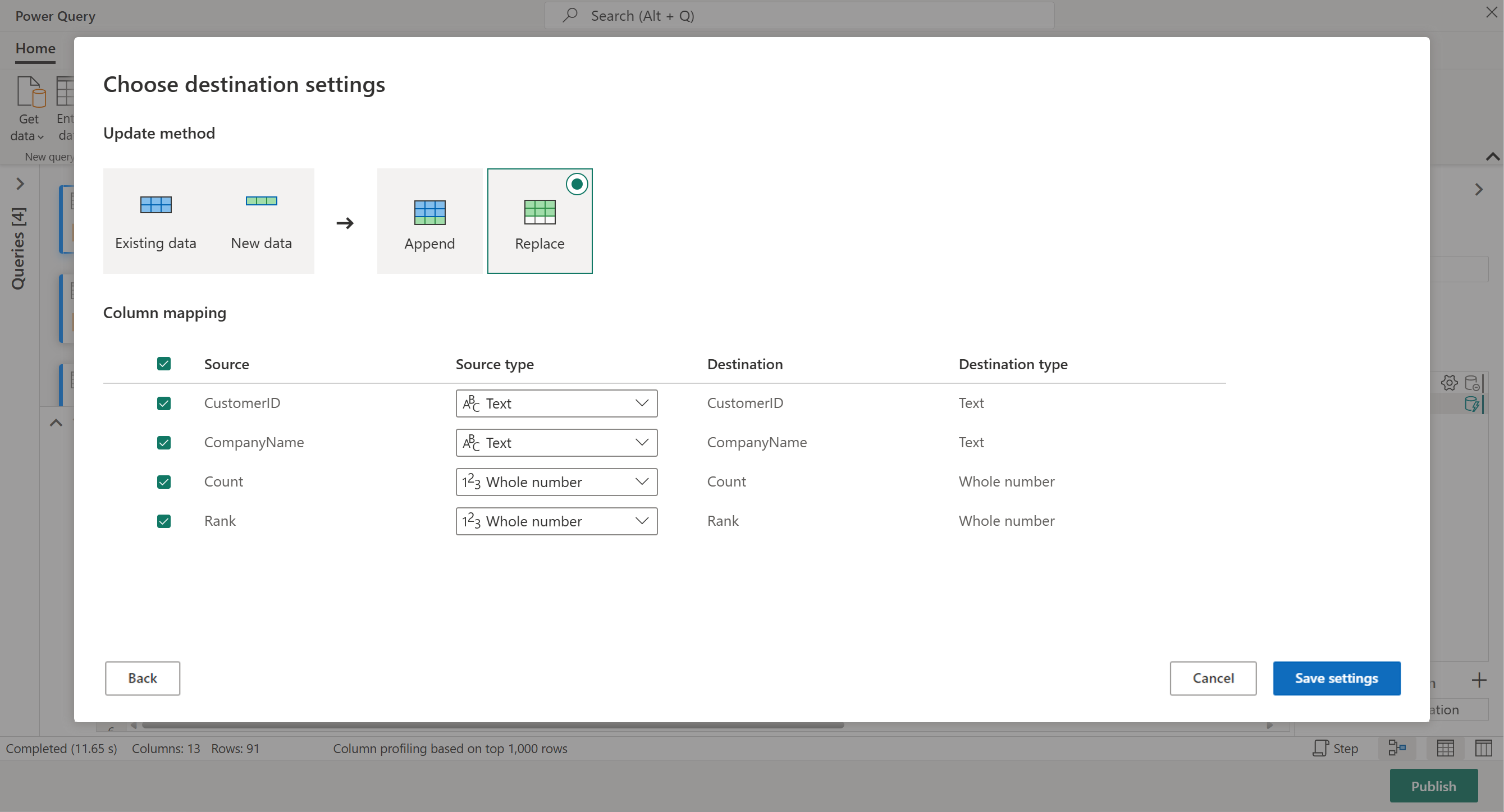
Sie können Ihre Ergebnisse an ein Seehaus senden, wenn Sie über einen verfügen, oder diesen Schritt überspringen, wenn sie nicht. Hier können Sie auswählen, welches Lakehouse und welche Tabelle für Ihre Daten verwendet werden. Zudem können Sie entscheiden, ob Sie neue Daten anfügen oder vorhandene ersetzen möchten.
Ihr Dataflow ist jetzt bereit für die Veröffentlichung. Überprüfen Sie die Abfragen in der Diagrammansicht, und wählen Sie dann Veröffentlichen aus.
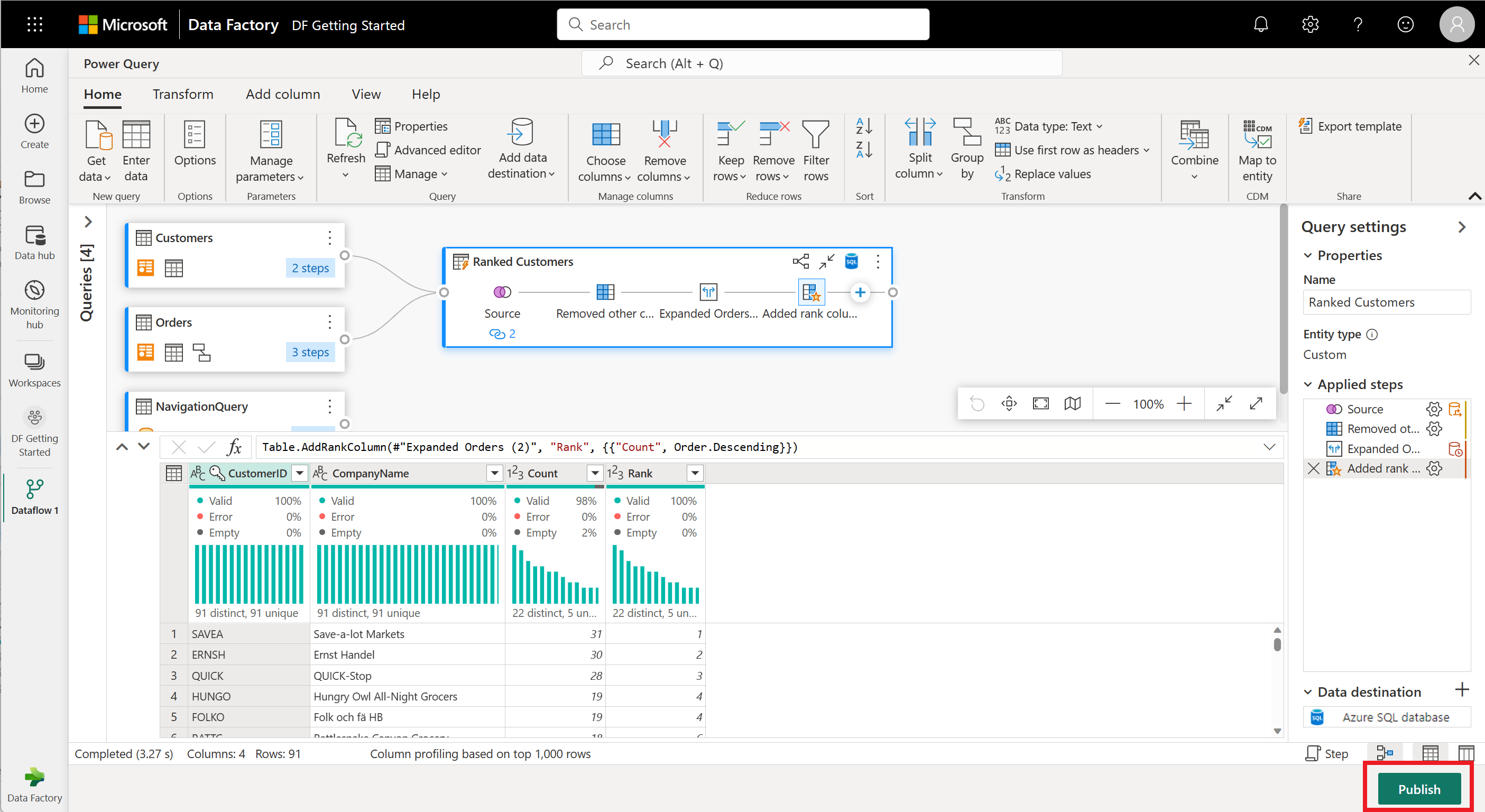
Wählen Sie " Veröffentlichen" in der unteren rechten Ecke aus, um den Datenfluss zu speichern. Sie kehren zu Ihrem Arbeitsbereich zurück, in dem ein Drehfeldsymbol neben dem Namen des Datenflusses die Veröffentlichung anzeigt. Wenn das Ladesymbol verschwindet, ist der Datenfluss bereit zu aktualisieren!
Wichtig
Wenn Sie zum ersten Mal einen Dataflow Gen2 in einem Arbeitsbereich erstellen, richtet Fabric einige Hintergrundelemente (Lakehouse und Warehouse) ein, die die Ausführung des Datenflusses erleichtern. Diese Elemente werden von allen Datenflüssen im Arbeitsbereich genutzt, und Sie sollten sie nicht löschen. Sie sollen nicht direkt verwendet werden und sind in der Regel nicht in Ihrem Arbeitsbereich sichtbar, aber möglicherweise werden sie an anderen Stellen wie Notizbüchern oder SQL-Analysen angezeigt. Suchen Sie nach Namen, die beginnen
DataflowStaging, um sie zu erkennen.Wählen Sie in Ihrem Arbeitsbereich das Symbol Aktualisierung Zeitplan aus.

Aktivieren Sie die geplante Aktualisierung, wählen Sie Weiteren Zeitpunkt hinzufügen aus, und konfigurieren Sie die Aktualisierung wie im folgenden Screenshot dargestellt.
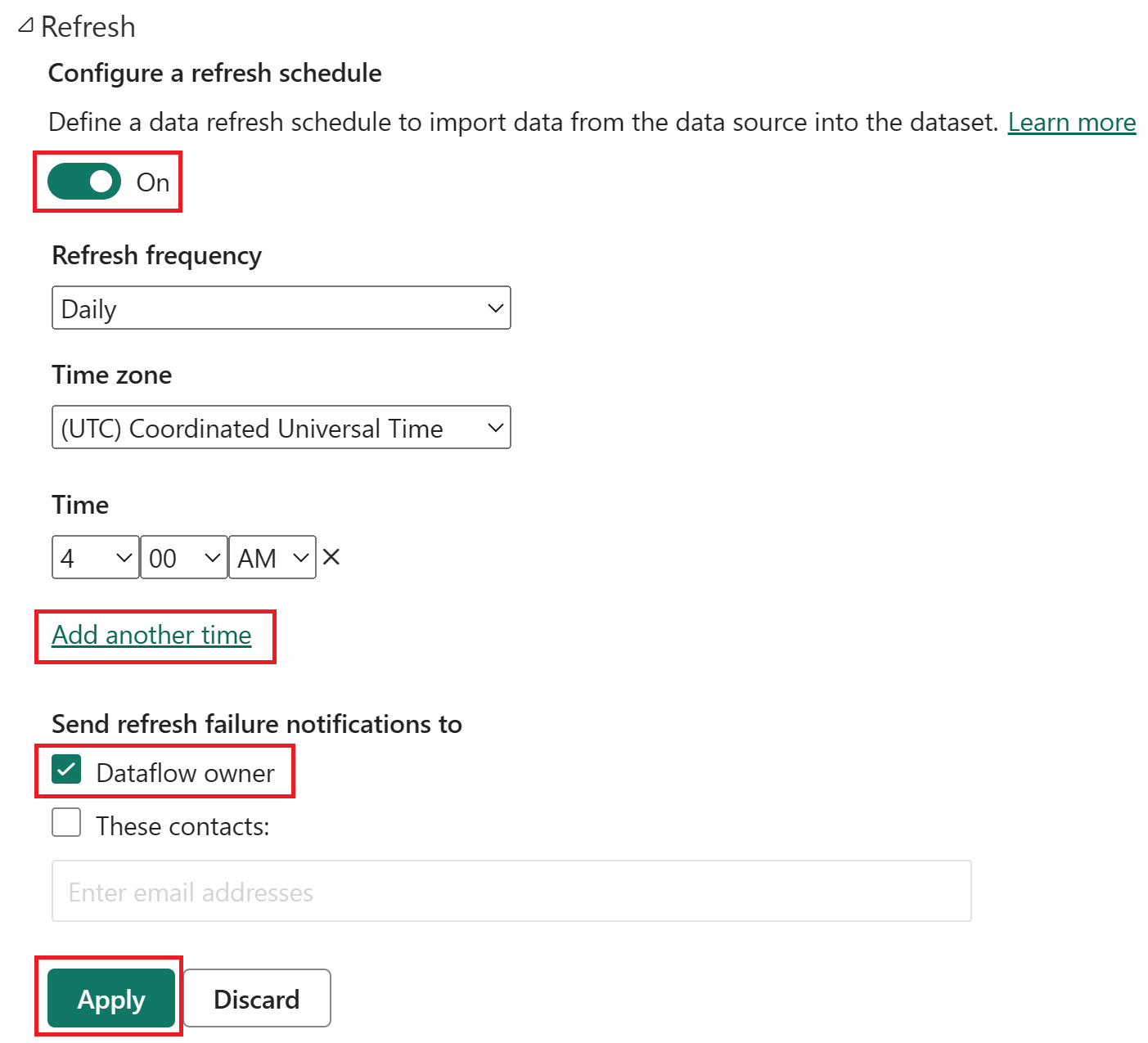
Screenshot der Optionen für geplante Aktualisierungen, bei denen die geplante Aktualisierung aktiviert ist, die Aktualisierungshäufigkeit auf „Täglich“, die Zeitzone auf „Koordinierte Weltzeit“ und die Uhrzeit auf 4:00 Uhr festgelegt ist. Hervorgehoben sind die Schaltfläche „Ein“, die Auswahl „Weiteren Zeitpunkt hinzufügen“, der Eigentümer des Datenflusses und die Schaltfläche „Anwenden“.













Bereinigen von Ressourcen
Wenn Sie diesen Dataflow nicht weiterhin verwenden möchten, löschen Sie ihn mit folgenden Schritten:
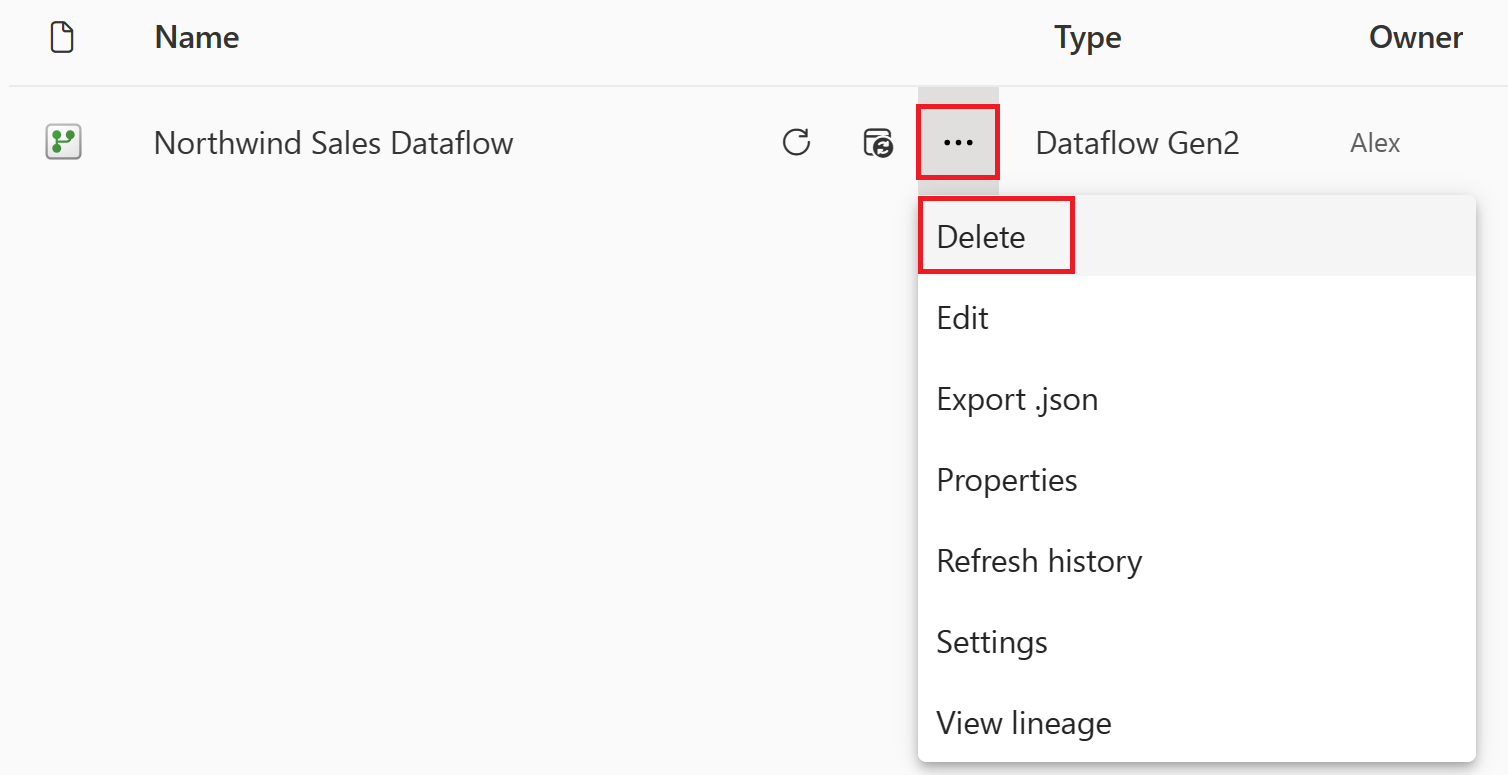
Navigieren Sie zu Ihrem Microsoft Fabric Arbeitsbereich.
Wählen Sie die vertikalen Auslassungspunkte neben dem Namen Ihres Dataflows und wählen Sie dann Löschen aus.
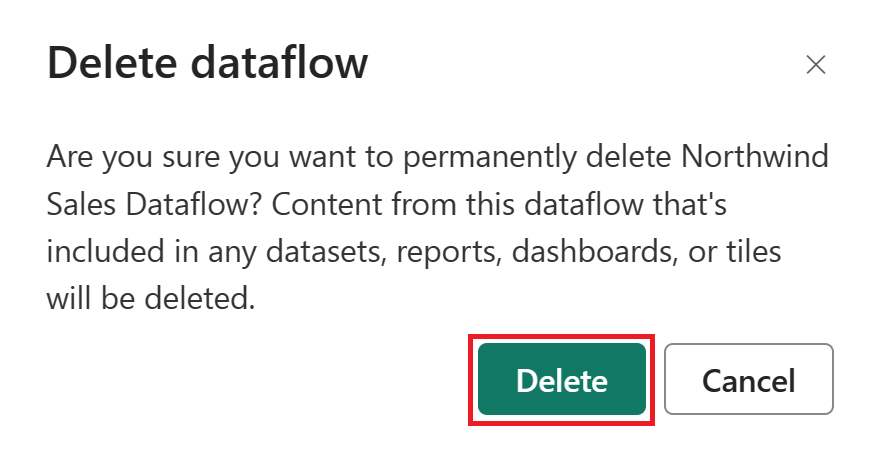
Wählen Sie Löschen aus, um die Löschung des Dataflows zu bestätigen.
Zugehöriger Inhalt
Der Dataflow in diesem Beispiel zeigt, wie Sie Daten in Dataflow „Gen2“ laden und transformieren. Sie haben Folgendes gelernt:
- Erstellen Sie einen Dataflow „Gen2“.
- Transformieren von Daten.
- Konfigurieren Sie Zieleinstellungen für transformierte Daten.
- Führen Sie Ihre Pipeline aus, und planen Sie sie.
Wechseln Sie zum nächsten Artikel, um zu erfahren, wie Sie Ihre erste Pipeline erstellen.