Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Fabric
Azure Blob Storage
Microsoft Entra ID
Power BI
This article describes how to transfer data from an on-premises data warehouse to a cloud environment and then use a business intelligence (BI) model to serve the data. You can use this approach as an end goal or as a first step toward full modernization with cloud-based components.
This guidance builds on the Microsoft Fabric end-to-end scenario. There are multiple options to extract data from an on-premises SQL server, such as Fabric Data Factory pipelines, mirroring, copy job, and Fabric real-time eventstreams change data capture (CDC) for SQL. After extraction, the data is transformed for analysis.
Architecture

Download a Visio file of this architecture.
Workflow
The following workflow corresponds to the previous diagram.
Data source
- A SQL Server database in Azure contains the source data. To simulate the on-premises environment, deployment scripts for this scenario configure an Azure SQL database. The AdventureWorks sample database is used as the source data schema and sample data. For more information, see Copy and transform data to and from SQL Server.
Ingestion and data storage
Fabric OneLake is a single, unified, logical data lake for your entire organization. This SaaS provides various data storage options such as Fabric Lakehouse for data engineering lakehouse workloads, Fabric Warehouse for data warehouse workloads, and Fabric Eventhouse for high volume time series and log datasets.
Fabric Data Factory pipelines allow you to build complex extract, transform, load (ETL) and data factory workflows that can perform many different tasks at scale. Control flow capabilities are built into data pipelines that allow you to build workflow logic, which provides loops and conditionals. In this architecture, metadata-driven frameworks enable incremental ingestion of multiple tables at scale.
Fabric Data Factory mirroring allows you to avoid complex ETL processes and integrate your existing SQL Server estate with the rest of your data in Fabric. You can continuously replicate your existing SQL Server databases directly into Fabric OneLake. The Fabric Data Factory copy job makes it easy to move data from your source to your destination without needing pipelines. Data transfers can be configured through built-in patterns for batch and incremental copy, with support for scalable performance.
Fabric eventstreams provide high-throughput, real-time data ingestion from a SQL Server database hosted on a virtual machine (VM) by using CDC extraction. This pattern suits use cases that require real-time dashboards and alerting.
Analysis and reporting
- The data-modeling approach in this scenario combines the enterprise model and the BI semantic model. Fabric SKUs provide the compute for Power BI semantic models. Power BI can access the data via Import, DirectQuery, or Direct Lake connectivity.
Components
Azure SQL Database is an Azure-hosted PaaS SQL server. In this architecture, SQL Database provides the source data and demonstrates the flow of data for the migration scenario.
OneLake is a unified, cloud-based data lake for storing both structured and unstructured data across the organization. In this architecture, OneLake serves as the central storage layer. It uses artifacts such as Fabric Lakehouse, Fabric Warehouse, Fabric Eventhouse, and mirrored databases to persist and organize various types of data for analytics and reporting.
Fabric Data Warehouse is a SaaS offering that hosts data warehouse workloads for large datasets. In this architecture, Fabric Data Warehouse serves as the final store for dimensional datasets and supports analytics and reporting.
Power BI is a business intelligence tool hosted on Fabric compute. It presents and visualizes data in this scenario, enabling business users to interact with dashboards and reports based on data from Fabric Data Warehouse and other sources.
Microsoft Entra ID is a multicloud identity and network solution suite that supports the authentication and authorization flow. In this architecture, Microsoft Entra ID provides secure access for users who connect to Power BI and Fabric resources.
Scenario details
In this scenario, an organization has a SQL database that contains a large on-premises data warehouse. The organization wants to use Fabric to ingest and analyze the data and to deliver analytic insights to users through Power BI.
When to use this architecture
You can use various methods to meet business requirements for enterprise business intelligence. Various aspects define business requirements, such as current technology investments, human skills, the timeline for modernization, future goals, and whether you prefer platform as a service (PaaS) or software as a service (SaaS).
Consider the following design approaches:
Fabric and Azure Databricks for customers that have existing investment in Azure Databricks and Power BI and want to modernize with Fabric
Enterprise BI for small and medium businesses that use an Azure SQL ecosystem and Fabric
End-to-end data warehousing on Fabric for customers who prefer a SaaS solution
The architecture in this article assumes that you use a Fabric lakehouse or Fabric warehouse as the persistent layer of the enterprise semantic model and that you use Power BI for business intelligence. This SaaS approach has the flexibility to accommodate various business requirements and preferences.
Authentication
Microsoft Entra ID authenticates users who connect to Power BI dashboards and apps. Single sign-on (SSO) connects users to the data in the Fabric warehouse and Power BI semantic model. Authorization occurs at the source.
Incremental loading
When you run an automated ETL or ELT process, you should load only the data that changed since the previous run. This process is known as an incremental load. In contrast, a full load loads all the data. To perform an incremental load, determine how to identify the changed data. You can use a high water mark value approach, which tracks the latest value of a date-time column or a unique integer column in the source table.
You can use temporal tables in SQL Server. Temporal tables are system-versioned tables that store data-change history. The database engine automatically records the history of every change in a separate history table. To query the historical data, you can add a FOR SYSTEM_TIME clause to a query. Internally, the database engine queries the history table, but it's transparent to the application.
Temporal tables support dimension data, which can change over time. Fact tables typically represent immutable transactions, such as a sale, where keeping system version history isn't meaningful. Instead, transactions typically have a column that represents the transaction date. The column can be used as the watermark value. For example, in the AdventureWorks data warehouse, the SalesLT.* tables have a LastModified field.
The following steps describe the general flow of the ELT pipeline:
For each table in the source database, track the cutoff time when the last ELT job ran. Store this information in the data warehouse. On initial setup, all times are set to
1-1-1900.During the data export step, the cutoff time is passed as a parameter to a set of stored procedures in the source database. These stored procedures query any records that are changed or created after the cutoff time. For all tables in the example, you can use the
ModifiedDatecolumn.When the data migration is complete, update the table that stores the cutoff times.
Data pipeline
This scenario uses the AdventureWorks sample database as a data source. The incremental data load pattern ensures that only data that's modified or added after the most recent pipeline run is loaded.
Metadata-driven ingestion framework
The metadata-driven ingestion framework within Fabric Data Factory pipelines incrementally loads all tables that are contained in the relational database. The article refers to a data warehouse as a source, but it can be replaced with an Azure SQL database as a source.
Select a watermark column. Choose one column in your source table that helps track new or changed records. This column typically contains values that increase when rows are added or updated (like a timestamp or ID). Use the highest value in this column as your watermark to know where you left off.
Set up a table to store your last watermark value.
Build a pipeline that includes the following activities:
Two lookup activities. The first activity gets the last watermark value (where we stopped last time). The second activity gets the new watermark value (where we stop this time). Both values are passed to the copy activity.
A copy activity that finds rows where the watermark column value is between the old and new watermarks. It then copies this data from your data warehouse to your lakehouse as a new file.
A stored procedure activity that saves the new watermark value to determine the starting point for the next pipeline run.
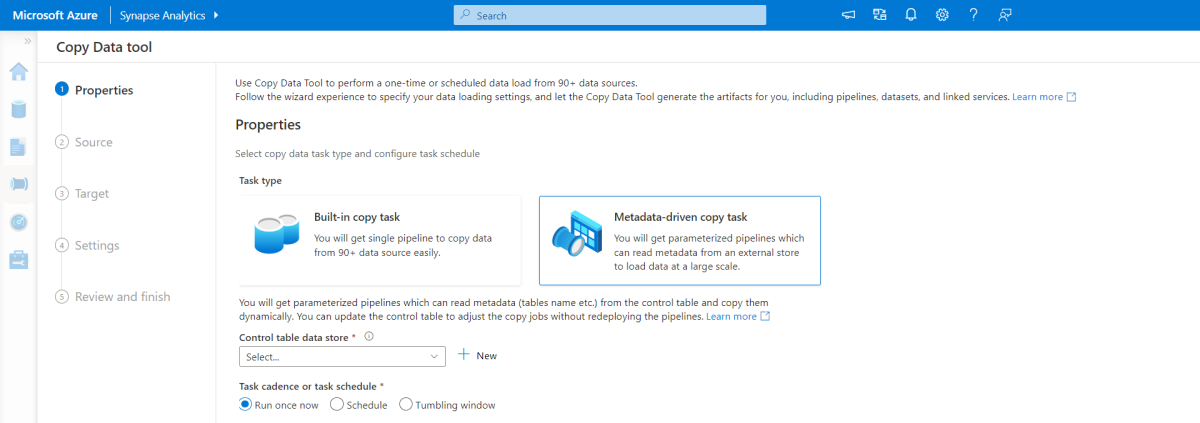

The following image shows a completed pipeline. For more information, see Incremental ingestion.

Load data into a Fabric data warehouse
The copy activity copies data from the SQL database into the Fabric data warehouse. This example's SQL database is in Azure, so it uses a connection set up within the Fabric portal under Manage Connection and Gateways.
Use Fabric Data Factory pipelines
Pipelines in Fabric Data Factory define an ordered set of activities to complete an incremental load pattern. Manual or automatic triggers start the pipeline.
Transform the data
If transformation is needed, then use Fabric dataflows to design low-code, AI-assisted ETL transformations that reshape the data. Fabric dataflows rely on the Power Query engine to apply those transformations and write the results to Fabric Data Warehouse.
In a production environment, use Fabric notebooks to implement ETL transformations that work well for large datasets via a distributed computing framework that's driven by Apache Spark.
Note
Use the native execution engine to run data engineering or ETL workloads.
Use Power BI with Fabric capacities to access, model, and visualize data
Fabric capacities in Power BI support multiple storage modes for connecting to Azure data sources:
Import: Loads data into the Power BI semantic model for in-memory querying.
DirectQuery: Runs queries directly against relational storage without loading data into memory.
Composite model: Combines Import mode for some tables with DirectQuery for others in the same dataset.
Direct Lake: Queries delta tables stored in OneLake from a Fabric workspace semantic model. It's optimized for interactive analysis of large tables by loading data into memory on demand.
This scenario uses the DirectQuery dashboard because it has a small amount of data and low model complexity. DirectQuery delegates the query to the underlying compute engine and uses security capabilities on the source. DirectQuery ensures that results are always consistent with the latest source data.
Import mode can provide the lowest query latency. Consider Import mode if the following factors are true:
- The model fits entirely within the memory of Power BI.
- The data latency between refreshes is acceptable.
- You require complex transformations between the source system and the final model.
In this case, the users want full access to the most recent data with no delays in Power BI refreshing, and they want all historical data, which exceeds the Power BI dataset capacity. A Power BI dataset can handle 25 gigabytes (GB) to 400 GB, depending on the capacity size. The data model in the dedicated SQL pool is already in a star schema and doesn't require transformation, so DirectQuery is an appropriate choice.

Use Power BI to manage large models, paginated reports, and deployment pipelines. Take advantage of the built-in Azure Analysis Services endpoint. You can also have dedicated capacity with a unique value proposition.
When the BI model grows or dashboard complexity increases, you can switch to composite models and import parts of lookup tables via hybrid tables, and import preaggregated data. You can enable query caching within Power BI for imported datasets and use dual tables for the storage mode property.
Within the composite model, datasets serve as a virtual pass-through layer. When users interact with visualizations, Power BI generates SQL queries to Fabric Data Warehouse. Power BI determines whether to use in-memory or DirectQuery storage based on efficiency. The engine decides when to switch from in-memory to DirectQuery and pushes the logic to the Fabric data warehouse. Depending on the context of the query tables, they can serve as either cached (imported) or noncached composite models. You can choose which table to cache into memory, combine data from one or more DirectQuery sources, or combine DirectQuery source data and imported data.
When you use DirectQuery with a Fabric data warehouse or lakehouse, take the following actions:
Use Fabric Z-Order and V-Order to improve query performance by optimizing storage of underlying table data in delta format files.
Use Fabric lakehouse materialized views to precompute, store, and maintain data like a table. Queries that use all data or a subset of the data in materialized views can achieve faster performance without needing to directly reference the defined materialized view to use it.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that you can use to improve the quality of a workload. For more information, see Well-Architected Framework.
Reliability
Reliability helps ensure that your application can meet the commitments that you make to your customers. For more information, see Design review checklist for Reliability.
The article Reliability explains how Fabric supports reliability, including regional resiliency through availability zones, along with cross-region recovery and business continuity. Fabric provides a disaster recovery switch on the capacity settings page. It's available where Azure regional pairings align with the Fabric service presence. When the disaster recovery capacity setting is turned on, cross-region replication is enabled as a disaster recovery capability for OneLake data.
Security
Security provides assurances against deliberate attacks and the misuse of your valuable data and systems. For more information, see Design review checklist for Security.
Cloud modernization introduces security concerns, such as data breaches, malware infections, and malicious code injection. You need a cloud provider or service solution that can address your concerns because inadequate security measures can create major problems.
This scenario addresses the most demanding security concerns by using a combination of layered security controls, including network, identity, privacy, and authorization controls. A Fabric data warehouse stores most of the data. Power BI accesses the data via DirectQuery through SSO. Use Microsoft Entra ID for authentication. There are also extensive security controls for data authorization within the provisioned pools.
Consider the following common security concerns:
Define who can see what data.
Ensure that your data complies with federal, local, and company guidelines to mitigate data breach risks. Fabric provides comprehensive data protection capabilities to support security and promote compliance.
OneLake security controls all access to OneLake data with different permissions inherited from the parent item or workspace permissions.
A workspace is a collaborative environment for creating and managing items. Workspace roles can be managed at this level.
An item is a set of capabilities bundled together into a single component. A data item is a subtype of item that allows data to be stored within it by using OneLake. Items inherit permissions from the workspace roles but can have extra permissions as well. Folders within an item are used for storing and managing data, such as
Tables/orFiles/.
Determine how to verify a user's identity.
- Use Fabric to control who can access what data via access control and authentication.
Choose a network security technology to protect the integrity, confidentiality, and access of your networks and data.
- Help secure Fabric by using network security options.
Choose tools to detect and notify you of threats.
- Fabric doesn't have built-in threat detection. We recommend that you use combination of Microsoft Purview Compliance Manager to set up alerts and review audit logs to track user activities.
Determine how to protect data on Fabric OneLake.
- Help protect data on Fabric by using sensitivity labels from Microsoft Purview Information Protection. Labels such as General, Confidential, and Highly Confidential are widely used in Microsoft Office apps such as Word, PowerPoint, and Excel to protect sensitive information. They follow the data automatically from item to item as it flows through Fabric, all the way from data source to business user.
Cost Optimization
Cost Optimization focuses on ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Design review checklist for Cost Optimization.
This section outlines pricing details for the various services used in the solution and explains the decisions made for this scenario by using a sample dataset. Use the starting configuration in the Azure pricing calculator and adjust it to fit your scenario. For more information about Fabric SKUs, see Fabric pricing overview. For more information about how to generate an estimate of overall Fabric consumption, see the Fabric capacity estimator.
Fabric scalable architecture
Fabric is a serverless architecture for most workloads that you can use to scale your compute and storage levels independently. Compute resources incur costs based on usage. You can scale or pause these resources on demand. Storage resources incur costs per GB, so your costs increase as you ingest data.
Fabric factory pipelines
Three main components influence the price of a pipeline:
Data pipeline activities for orchestration: To optimize cost, reduce the total orchestration time by implementing parallel flows.
Dataflow Gen2 for compute: To optimize cost, simplify ETL pipelines by filtering unnecessary data and processing incremental extraction.
Data movement for copy job or copy activity: To optimize cost, configure the copy job with incremental extraction and adjust throughput for the copy activity.
For more information, see the Data Factory pricing meters tab on Data Factory pricing.
The price varies depending on components or activities, frequency, and the overall compute associated with orchestration. Any data movement that results from pipeline activities or a copy job incurs a cost. However, compute associated with data movement via Fabric mirroring is free, and the storage cost of mirrored data is free up to the capacity size. For example, if you purchase an F64 capacity, you receive 64 free terabytes (TB) of storage that's exclusively used for mirroring. OneLake storage is billed if the free mirroring storage limit is exceeded or when the capacity is paused.
Fabric workload decision guide
Use this decision guide to select a data store for your Fabric workloads. All options are available in unified storage within OneLake.
The SQL endpoint for Fabric Lakehouse or Fabric Warehouse provides the capability to run ad-hoc queries for analysis. It also allows Power BI semantic models to import or direct query the data. The cost associated with a lakehouse or warehouse is equivalent to the CUs consumption for SQL queries against the SQL endpoint. To optimize cost, implement Z-Ordering and V-Ordering in Fabric Lakehouse to improve query performance. For Data Warehouse, optimize queries to read smaller batches.
OneLake storage
OneLake storage is billed at a pay-as-you-go rate per GB of data used and doesn't consume Fabric capacity units (CUs). Fabric items like lakehouses and warehouses consume OneLake storage. For more information, see Fabric pricing.
To optimize OneLake costs, focus on managing storage volume by regularly deleting unused data, including data in soft delete storage, and optimizing read/write operations. OneLake storage is billed separately from compute, so it's important to monitor usage with the Fabric capacity metrics app. To reduce storage costs, which are calculated based on average daily usage over the month, consider minimizing the amount of data stored.
Power BI
This scenario uses Power BI workspaces with built-in performance enhancements to accommodate demanding analytical needs. To optimize cost, implement incremental refresh for Import mode extraction. Implement Direct Lake mode for reporting on larger datasets when possible to reduce overall load on Fabric capacities.
For more information, see Power BI pricing.
Operational Excellence
Operational Excellence covers the operations processes that deploy an application and keep it running in production. For more information, see Design review checklist for Operational Excellence.
Use an Azure DevOps release pipeline and GitHub Actions to automate the deployment of a Fabric workspace artifact across multiple environments. For more information, see Continuous integration and continuous delivery for a Fabric workspace.
Put each workload in a separate deployment template, and store the resources in source control systems. You can deploy the templates together or individually as part of a continuous integration and continuous delivery (CI/CD) process. This approach simplifies the automation process. This architecture has four main workloads:
- The data warehouse and related resources
- Data Factory pipelines
- Power BI assets, including dashboards, apps, and datasets
- An on-premises to cloud simulated scenario
Consider staging your workloads where practical. Deploy your workload to various stages. Run validation checks at each stage before you move to the next stage. This approach pushes updates to your production environments in a controlled way and minimizes unanticipated deployment problems. Use blue-green deployment and canary release strategies to update live production environments.
Use a rollback strategy to handle failed deployments. For example, you can automatically redeploy an earlier, successful deployment from your deployment history. Use the
--rollback-on-errorflag in the Azure CLI.Use the Fabric capacity metrics app for comprehensive monitoring of Fabric capacity consumption. Use workspace monitoring for detailed monitoring of Fabric workspace telemetry logs.
Use the Fabric capacity estimator to estimate your Fabric capacity needs.
Performance Efficiency
Performance Efficiency refers to your workload's ability to scale to meet user demands efficiently. For more information, see Design review checklist for Performance Efficiency.
This article uses the Fabric F64 capacity to demonstrate BI capabilities. Dedicated Power BI capacities in Fabric range from F64 to the maximum SKU size. For more information, see Fabric pricing.
To determine how much capacity you need, take the following actions:
Evaluate the load on your capacity.
Install the Fabric capacity metrics app for ongoing monitoring.
Consider using workload-related capacity optimization techniques.
Contributors
Microsoft maintains this article. The following contributors wrote this article.
Principal author:
- Bibhu Acharya | Principal Cloud Solution Architect
Other contributors:
- Jim McLeod | Cloud Solution Architect
- Miguel Myers | Senior Program Manager
- Galina Polyakova | Senior Cloud Solution Architect
- George Stevens | Solution Engineer
To see nonpublic LinkedIn profiles, sign in to LinkedIn.
Next steps
- What is Power BI Premium?
- What is Microsoft Entra ID?
- What is Fabric?
- What is Data Factory in Fabric?
- What is Azure SQL?