Copia de datos en Azure Data Explorer mediante Azure Data Factory
Importante
Este conector se puede usar en Inteligencia en tiempo real en Microsoft Fabric. Use las instrucciones de este artículo con las siguientes excepciones:
- Si es necesario, cree una bases de datos con las instrucciones de Crear una base de datos KQL.
- Si es necesario, cree tablas con las instrucciones de Crear una tabla vacía.
- Obtenga los URI de consulta o ingesta mediante las instrucciones de Copiar URI.
- Ejecute consultas en un conjunto de consultas KQL .
Azure Data Explorer es un servicio de análisis de datos rápido y totalmente administrado. Ofrece análisis en tiempo real de grandes volúmenes de datos que se transmiten desde muchos orígenes, como aplicaciones, sitios web y dispositivos IoT. Con Azure Data Explorer, puede explorar datos de forma iterativa e identificar patrones y anomalías para mejorar los productos y la experiencia del cliente, supervisar los dispositivos e impulsar las operaciones. Le ayuda a explorar nuevas preguntas y obtener respuestas en cuestión de minutos.
Azure Data Factory es un servicio de integración de datos basado en la nube totalmente administrado. Se puede usar para rellenar la base de datos de Azure Data Explorer con datos del sistema existente. Puede ayudarle a ahorrar tiempo al compilar soluciones de análisis.
Al cargar datos en Azure Data Explorer, Data Factory ofrece las siguientes ventajas:
- Configuración fácil: obtenga un asistente intuitivo en cinco pasos sin necesidad de scripting.
- Amplia compatibilidad para el almacenamiento de datos: obtener compatibilidad integrada para un amplio conjunto de almacenes de datos tanto locales como en la nube. Para una lista detallada, consulte la tabla de almacenes de datos admitidos.
- Seguro y compatible: los datos se transfieren a través de HTTPS o Azure ExpressRoute. La presencia del servicio global garantiza que los datos nunca abandonan el límite geográfico.
- Alto rendimiento: la velocidad de carga de datos es de hasta 1 gigabyte por segundo (GBps) en Azure Data Explorer. Para obtener más información, vea el artículo Copiar rendimiento de actividad.
En este artículo se utiliza la herramienta Copiar datos de Data Factory para cargar datos de Amazon Simple Storage Service (S3) en Azure Data Explorer. Puede seguir el mismo proceso para copiar datos de otros tipos de almacenes de datos, tales como:
- Almacenamiento de blobs de Azure
- Azure SQL Database
- Azure SQL Data Warehouse
- Google BigQuery
- Oracle
- Sistema de archivos
Requisitos previos
- Suscripción a Azure. Cree una cuenta de Azure gratuita.
- Un clúster y la base de datos de Azure Data Explorer. Cree un clúster y una base de datos.
- Un origen de datos.
Crear una factoría de datos
Inicie sesión en Azure Portal.
En el panel izquierdo, seleccione Crear un recurso>Analytics>Data Factory.

En el panel New data factory (Nueva factoría de datos), especifique valores para los campos de la tabla siguiente:
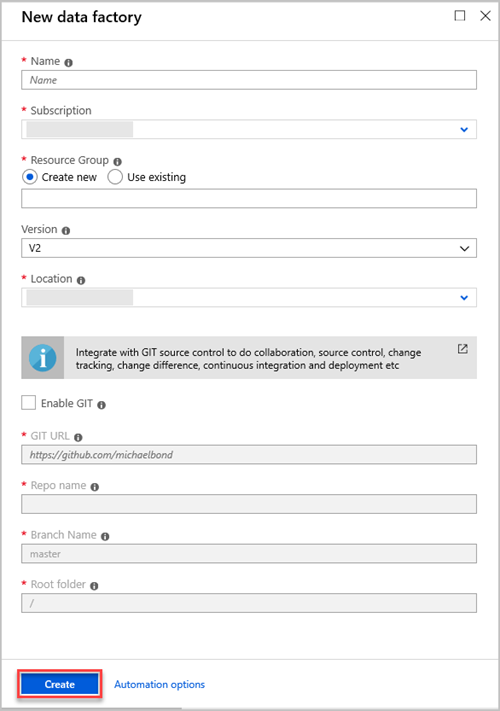
Configuración Valor que se va a especificar Nombre En el cuadro, escriba un nombre único global para la factoría de datos. Si recibe el error El nombre de la factoría de datos "LoadADXDemo" no está disponible, escriba otro distinto. Para conocer las reglas sobre nomenclatura de los artefactos de Data Factory, consulte Data Factory: reglas de nomenclatura. Suscripción En la lista desplegable, seleccione la suscripción de Azure en la que quiere crear la factoría de datos. Grupo de recursos Seleccione Crear nuevo y escriba el nombre de un nuevo grupo de recursos. Si ya tiene un grupo de recursos, seleccione Usar existente. Versión En la lista desplegable, seleccione V2. Ubicación En la lista desplegable, seleccione la ubicación de la factoría de datos. Solo las ubicaciones admitidas se muestran en la lista. Los almacenes de datos que las factorías de datos usan pueden estar en otras ubicaciones o regiones. Seleccione Crear.
Para supervisar el proceso de creación, seleccione Notificaciones en la barra de herramientas. Una vez creada la factoría de datos, selecciónela.
Se abre el panel Data Factory.
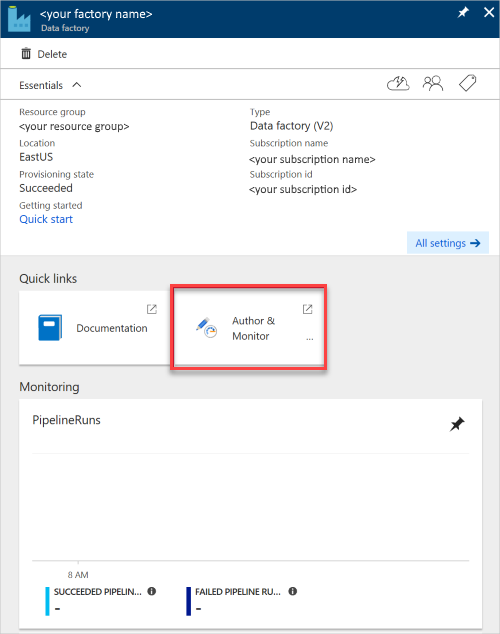
Para abrir la aplicación en otro panel, seleccione el icono Author & Monitor (Crear y supervisar).
Carga de datos en Azure Data Explorer
Puede cargar datos procedentes de muchos tipos de almacenes de datos en Azure Data Explorer. En este artículo se describe cómo cargar datos de Amazon S3.
Puede cargar los datos de una de las maneras siguientes:
- En la interfaz de usuario de Azure Data Factory, en el panel izquierdo, seleccione el icono Crear. Esto se muestra en la sección "Crear una factoría de datos" de Creación de una factoría de datos con la interfaz de usuario de Azure Data Factory.
- En la herramienta Copiar datos de Azure Data Factory, tal como se muestra en Uso de la herramienta Copiar datos para copiar datos.
Copia de datos desde Amazon S3 (origen)
En el panel Let's get started (Introducción), seleccione Copy Data (Copiar datos) para abrir la herramienta Copiar datos.
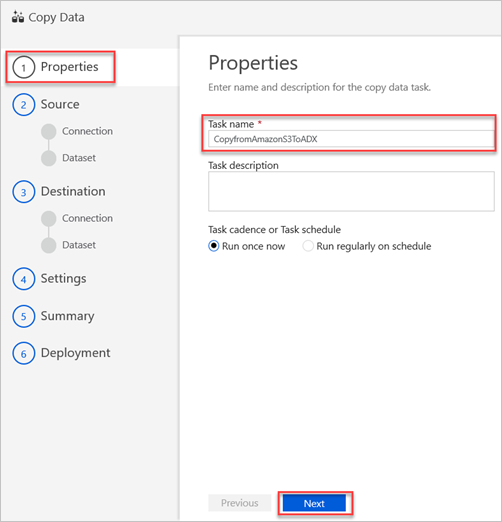
En el cuadro Task name (Nombre de tarea) del panel Properties (Propiedades), escriba un nombre y seleccione Next (Siguiente).
En el panel Source data store (Almacén de datos de origen), seleccione Crear nueva conexión.
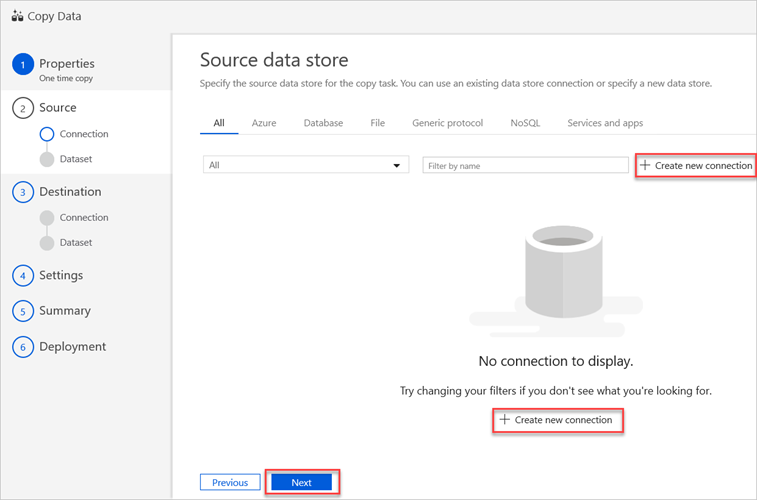
Seleccione Amazon S3 y luego, Continuar.
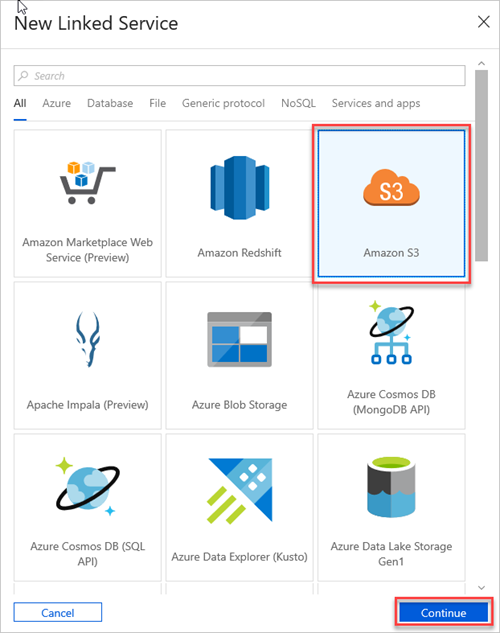
En el panel New Linked Service (Amazon S3) (Nuevo servicio vinculado [Amazon S3]), haga lo siguiente:
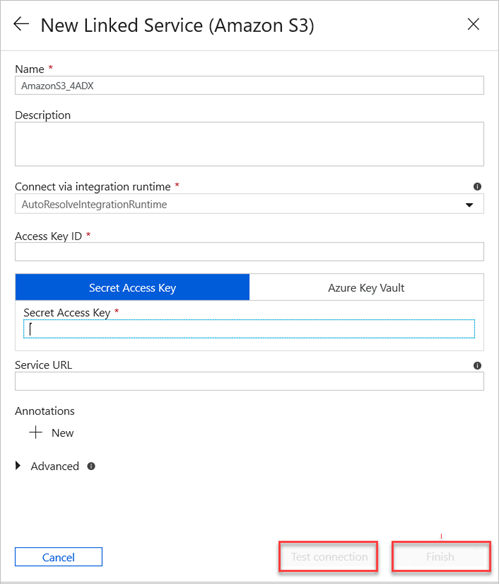
a. En el cuadro Name (Nombre), escriba el nombre del nuevo servicio vinculado.
b. En la lista desplegable Connect via integration runtime (Conectar mediante IR), seleccione el valor.
c. En el cuadro Access Key ID (Identificador de clave de acceso), escriba el valor.
Nota:
En Amazon S3, para buscar la clave de acceso, seleccione su nombre de usuario de Amazon en la barra de navegación y luego, My Security Credentials (Mis credenciales de seguridad).
d. En el cuadro Secret Access Key (Clave de acceso secreta), escriba un valor.
e. Para probar la conexión de servicio vinculado que creó, seleccione Probar conexión.
f. Seleccione Finalizar.
En el panel Source data store (Almacén de datos de origen) se muestra la nueva conexión AmazonS31.
Seleccione Siguiente.
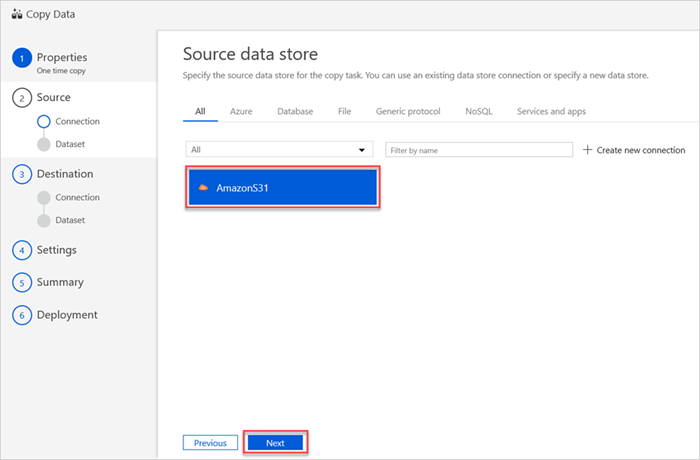
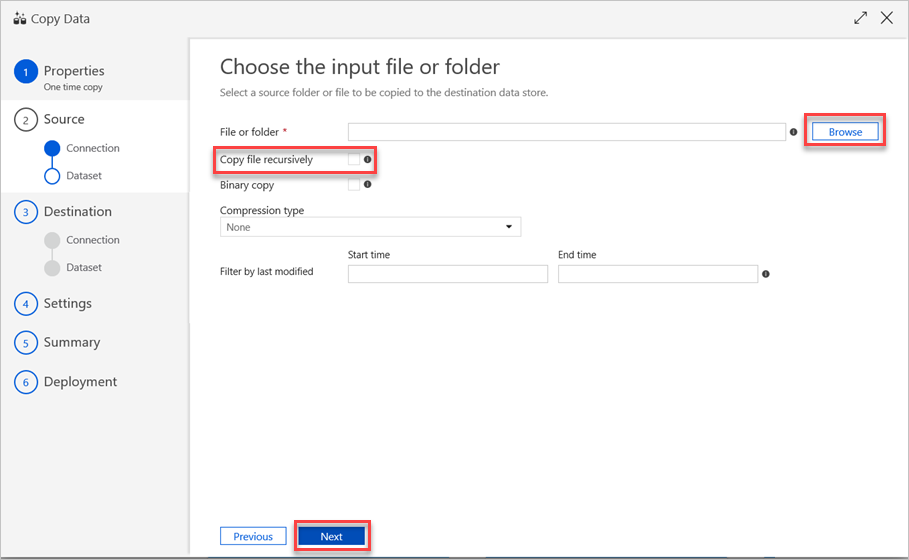
En el panel Seleccione el archivo o la carpeta de entrada, haga lo siguiente:
a. Busque el archivo o la carpeta que quiere copiar y selecciónelo.
b. Seleccione el comportamiento de copia que quiera. Asegúrese de que la casilla Binary Copy (Copia binaria) esté desactivada.
c. Seleccione Siguiente.
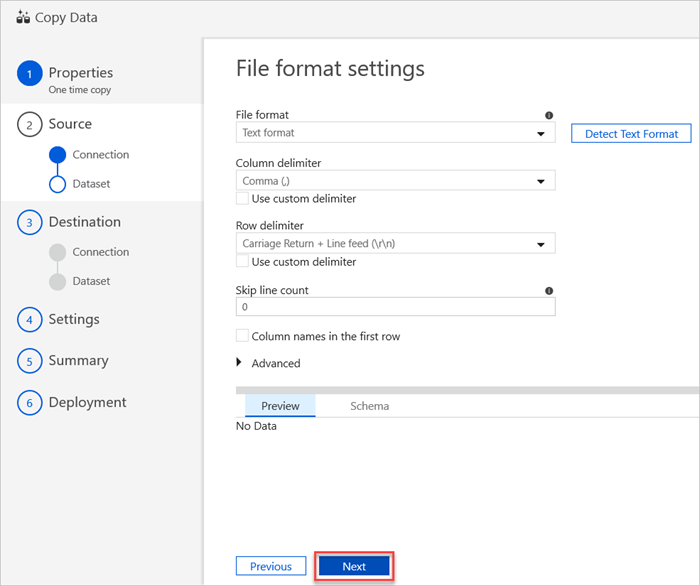
En el panel File format settings (Configuración de formato de archivo), seleccione la configuración relevante para su archivo. Luego, seleccione Next (Siguiente).
Copia de datos en Azure Data Explorer (destino)
Se ha creado el servicio vinculado de Azure Data Explorer para copiar los datos en la tabla de destino de Azure Data Explorer (receptor) que se especifica en esta sección.
Nota:
Use la Actividad comando de Azure Data Factory para ejecutar comandos de administración de Azure Data Explorer y usar cualquiera de los ingesta de comandos de consulta, como .set-or-replace.
Creación del servicio vinculado de Azure Data Explorer
Para crear el servicio vinculado de Azure Data Explorer, haga lo siguiente:
Para usar una conexión del almacén de datos existente o especificar un nuevo almacén de datos, en el panel Destination data store (Almacén de datos de destino), seleccione Create new connection (Crear conexión).
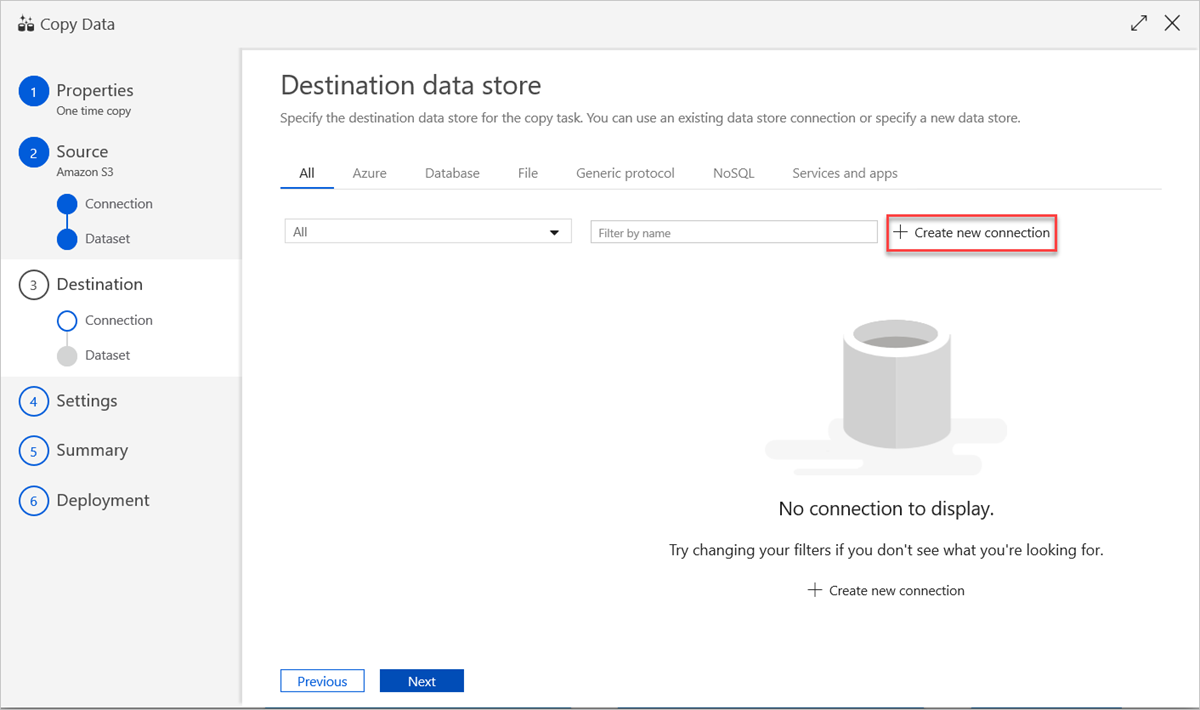
En el panel New Linked Service (Nuevo servicio vinculado), seleccione Azure Data Explorer y después Continuar.

En el panel New Linked Service (Azure Data Explorer) (Nuevo servicio vinculado [Azure Data Explorer]), haga lo siguiente:
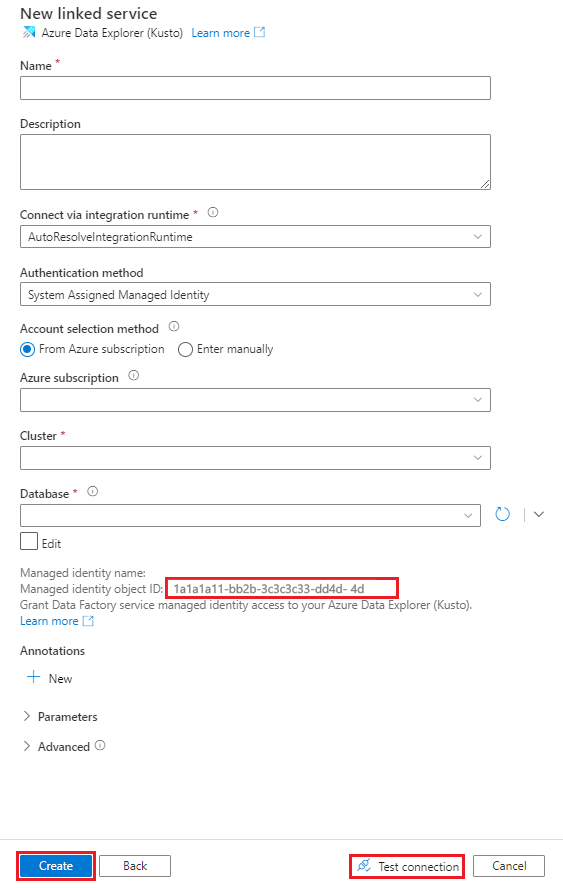
En el cuadro Name (Nombre), escriba un nombre para el servicio vinculado de Azure Data Explorer.
En Método de autenticación, elija Identidad administrada asignada por el sistema o Entidad de servicio.
Para Autenticarse mediante una Identidad administrada, conceda a la Identidad administrada acceso a la base de datos mediante el Nombre de identidad administrada o el Id. del objeto de identidad administrada.
Para autenticarse mediante una Entidad de servicio:
- En el cuadro Inquilino, escriba el nombre del inquilino.
- En el cuadro Id. de entidad de servicio, escriba el identificador de la entidad de servicio.
- Seleccione Clave de entidad de servicio y luego, en el cuadro Clave de entidad de servicio, escriba el valor de la clave.
Nota:
- Azure Data Factory usa la entidad de servicio para acceder al servicio de Azure Data Explorer. Para crear una entidad de servicio, vaya a Crear una entidad de servicio de Microsoft Entra.
- Para asignar permisos a una Identidad administrada o a una Entidad de servicio o , consulte Administración de permisos.
- No use el método Azure Key Vault ni la Identidad administrada asignada por el usuario.
En Método de selección de cuentas, elija una de las siguientes opciones:
Seleccione From Azure subscription (Desde suscripción de Azure) y luego, en las listas desplegables, seleccione su suscripción de Azure y su clúster.
Nota:
- En el control desplegable Cluster (Clúster) solo aparecen los clústeres asociados a la suscripción.
- El clúster debe tener la SKU adecuada para obtener el mejor rendimiento.
Seleccione Enter manually (Especificar manualmente) y especifique su punto de conexión.
En la lista desplegable Base de datos, seleccione el nombre de la base de datos. También puede activar la casilla Editar y escribir el nombre de la base de datos.
Para probar la conexión de servicio vinculado que creó, seleccione Probar conexión. Si puede conectarse al servicio vinculado, el panel muestra una marca de verificación verde y un mensaje Conexión correcta.
Seleccione Crear para completar la creación del servicio vinculado.
Configuración de la conexión de datos de Azure Data Explorer
Una vez creada la conexión de servicio vinculado, se abre el panel Destination data store (Almacén de datos de destino) y la conexión que creó está disponible para su uso. Para configurar la conexión, haga lo siguiente:
Seleccione Siguiente.
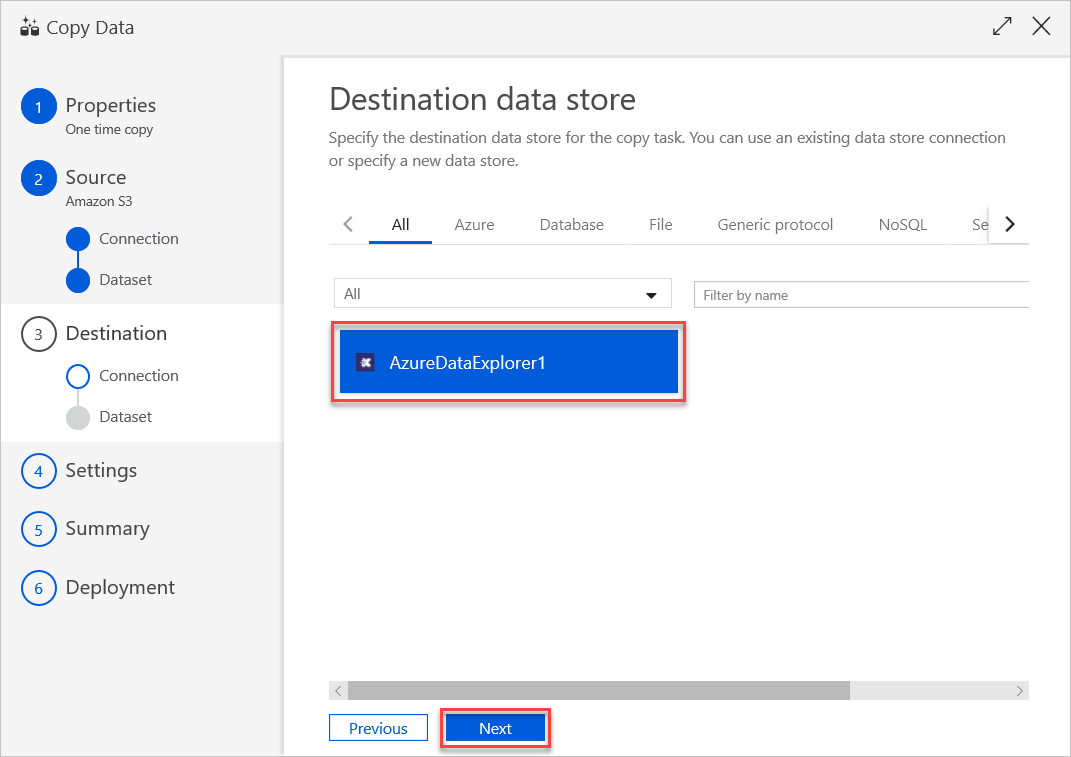
Enel panel Table mapping (Asignación de tabla), establezca el nombre de tabla de destino y seleccione Next (Siguiente).
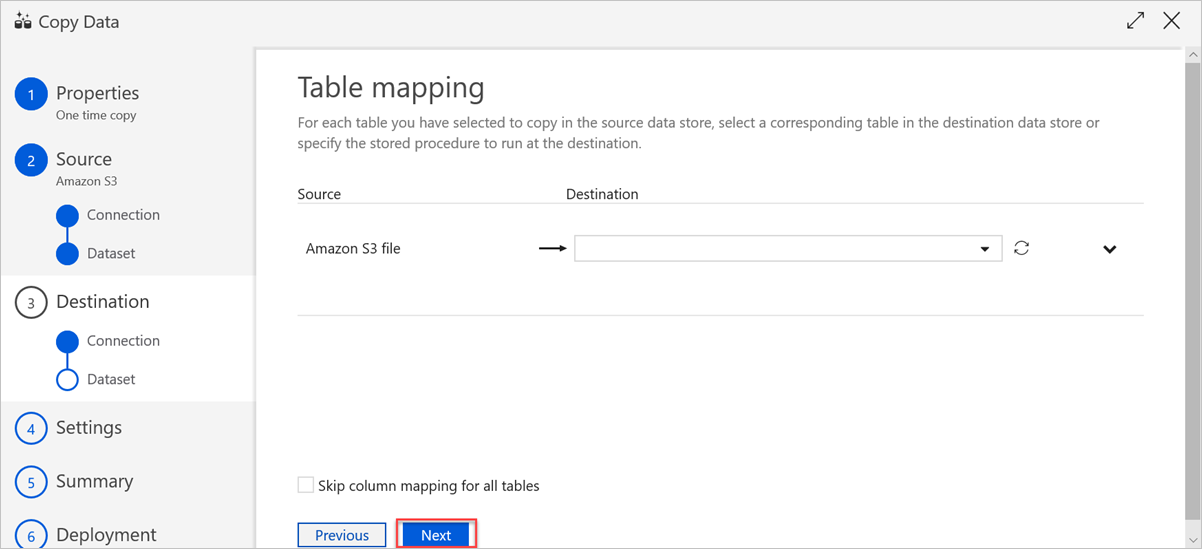
En el panel Asignación de columnas, se realizan las siguientes asignaciones:
a. Azure Data Factory realiza la primera asignación según la asignación de esquemas de Azure Data Factory. Haga lo siguiente:
Establezca las asignaciones de columna para la tabla de destino de Azure Data Factory. La asignación predeterminada se muestra desde el origen hasta la tabla de destino de Azure Data Factory.
Cancele la selección de las columnas que no necesite para definir su asignación de columnas.
b. La segunda asignación se produce cuando estos datos tabulares se insertan en Azure Data Explorer. La asignación se realiza según las reglas de asignación de CSV. Aunque los datos de origen no estén en formato CSV, Azure Data Factory convierte los datos a un formato tabular. Por lo tanto, la asignación de CSV es la única asignación relevante en esta fase. Haga lo siguiente:
(Opcional) En las propiedades del receptor de Azure Data Explorer (Kusto), agregue el nombre de asignación de ingesta de manera que se pueda usar la asignación de columnas.
Si no se especifica el nombre de asignación de ingesta, se usará el orden de asignación por nombre en la sección Asignaciones de columnas. Si se produce un error en la asignación por nombre, Azure Data Explorer intenta ingerir los datos en el orden de posición por columna (es decir, se asigna por posición de forma predeterminada).
Seleccione Siguiente.
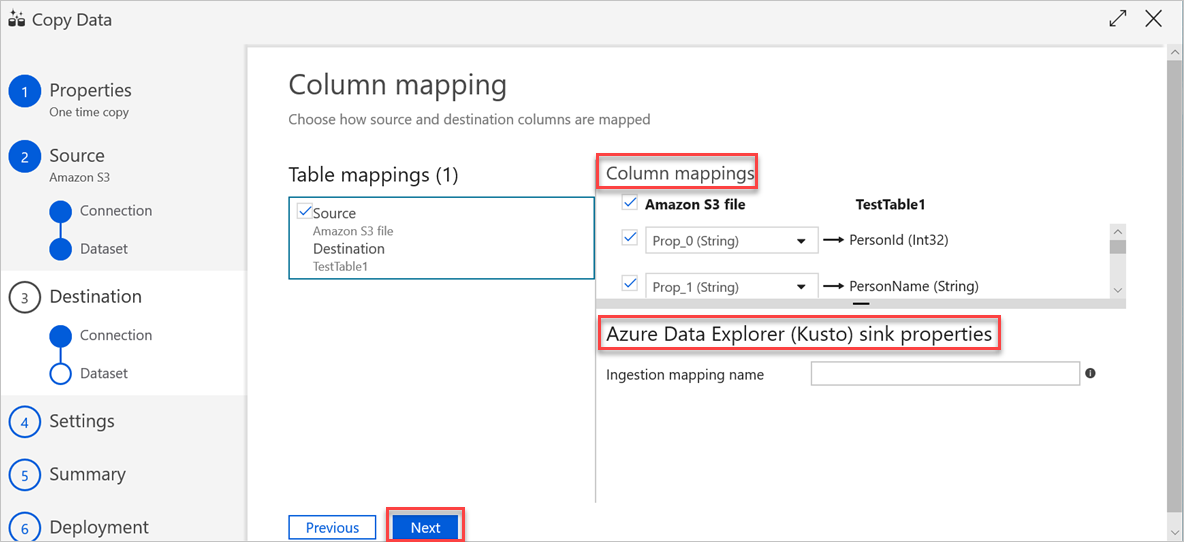
En el panel Configuración, haga lo siguiente:
a. En Fault tolerance settings (Configuración de tolerancia a errores), escriba la configuración correspondiente.
b. En Performance settings (Configuración de rendimiento), no se aplica Enable staging (Permitir almacenamiento provisional) y Advanced settings (Configuración avanzada) incluye consideraciones de costo. Si no tiene ningún requisito específico, deje esta configuración tal y como está.
c. Seleccione Siguiente.
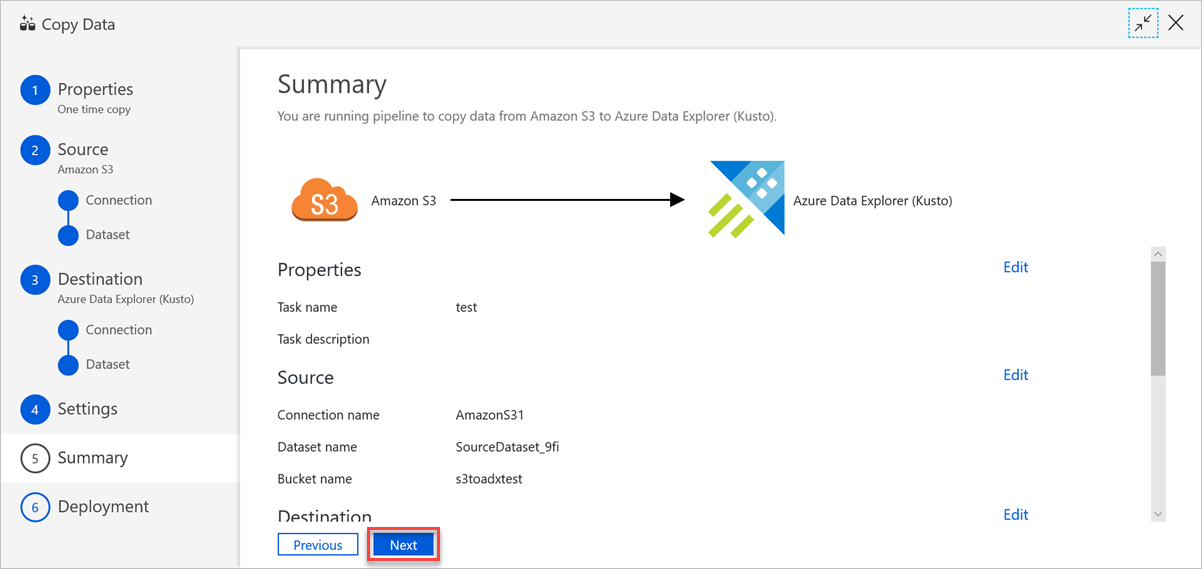
En el panel Summary (Resumen), revise la configuración y seleccione Next (Siguiente).
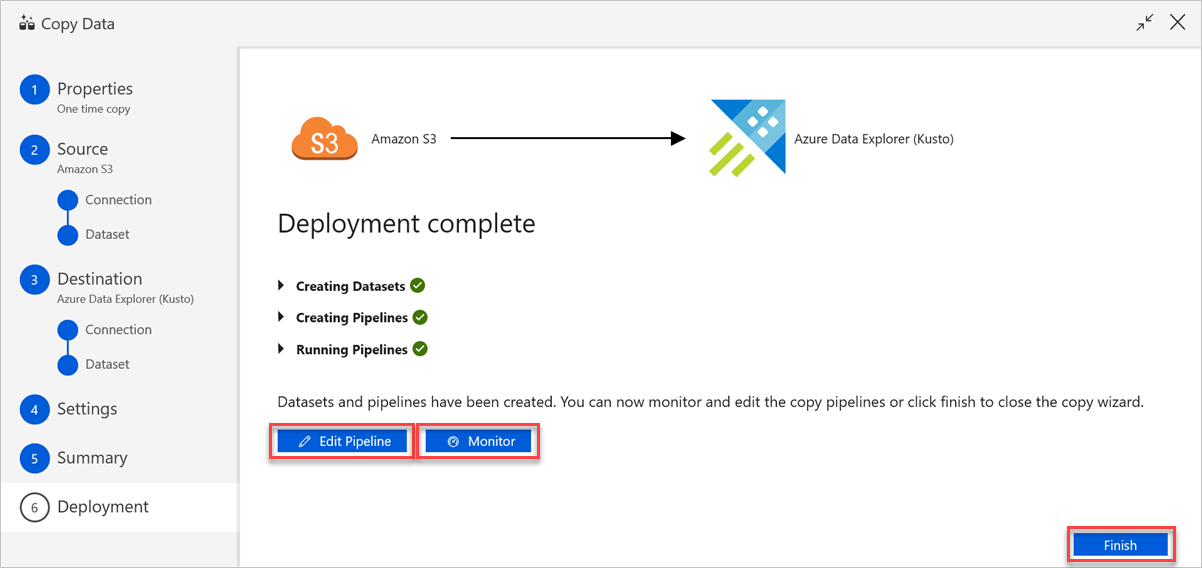
En el panel Deployment complete (Implementación finalizada), haga lo siguiente:
a. Para pasar a la pestaña Supervisar y ver el estado de la canalización (es decir, progreso, errores y flujo de datos), seleccione Supervisar.
b. Para poder editar los servicios vinculados, los conjuntos de datos y las canalizaciones, seleccione Editar canalización.
c. Seleccione Finalizar para completar la tarea de copia de datos.
Contenido relacionado
- Obtenga más información sobre el conector de Azure Data Explorer para Azure Data Factory.
- Edición de servicios vinculados, conjuntos de datos y canalizaciones en la interfaz de usuario de Data Factory.
- Consulta de datos en la interfaz de usuario web de Azure Data Explorer.