Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Fabric es una solución de análisis todo en uno para empresas que abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real y la inteligencia empresarial. Ofrece un conjunto completo de servicios que incluye un lago de datos, ingeniería de datos e integración de datos, todo en un solo lugar. Para obtener más información, consulte ¿Qué es Microsoft Fabric?
Este tutorial le guiará a través de un escenario de un extremo a otro, desde la adquisición de datos hasta el consumo de datos. Le ayuda a crear un conocimiento básico de Fabric, incluidas las diferentes experiencias y cómo se integran, así como las experiencias profesionales y de desarrollador civil que vienen con el trabajo en esta plataforma. Este tutorial no está pensado para ser una arquitectura de referencia, una lista exhaustiva de características y funcionalidades, o una recomendación de procedimientos recomendados específicos.
Escenario de arquitectura Lakehouse integral
Tradicionalmente, las organizaciones han estado creando almacenes de datos modernos para sus necesidades de análisis de datos transaccionales y estructurados. Y almacenes de lago de datos para las necesidades de análisis de macrodatos (semiestructurados/no estructurados). Estos dos sistemas se ejecutaban en paralelo, creando silos, duplicación de datos y un mayor costo total de propiedad.
Fabric con su unificación del almacén de datos y la estandarización en formato Delta Lake permite eliminar silos, eliminar la duplicación de datos y reducir drásticamente el costo total de propiedad.
Con la flexibilidad que ofrece Fabric, puede implementar arquitecturas de almacén de lago o almacenamiento de datos, o combinarlas para obtener lo mejor de ambas con una implementación sencilla. En este tutorial, vas a tomar el ejemplo de una organización minorista y construir su lakehouse de principio a fin. Usa la arquitectura medallion, donde la capa de bronce tiene los datos sin procesar, la capa de plata tiene los datos validados y desduplicados, y la capa dorada tiene datos muy refinados. Puede adoptar el mismo enfoque para implementar un lakehouse para cualquier organización de cualquier sector.
En este tutorial se explica cómo un desarrollador de la empresa ficticia Wide World Importers del dominio minorista completa los pasos siguientes:
Inicie sesión en su cuenta de Power BI y regístrese para obtener la prueba gratuita de Microsoft Fabric. Si no tiene una licencia de Power BI, regístrese para obtener una licencia gratuita de Fabric y entonces puede iniciar la versión de prueba de Fabric.
Construya e implemente un lakehouse de datos completo para su organización.
- Cree un área de trabajo de Fabric.
- Cree un lakehouse.
- Ingiera datos, transfórmelos y cárguelos en el almacén de lago. También puede explorar OneLake, una única copia de sus datos tanto en modo lakehouse como en modo de punto de conexión de análisis SQL.
- Conéctese a lakehouse mediante el punto de conexión de SQL Analytics y cree un modelo semántico y cree un informe para analizar los datos de ventas en diferentes dimensiones.
- De manera opcional, puede orquestar y programar el flujo de ingesta y transformación de los datos con una canalización. Las canalizaciones incluyen actividades centradas en Lakehouse, como la actividad de Mantenimiento de Lakehouse (para automatizar el mantenimiento de tablas Delta con OPTIMIZE y VACUUM) y la actividad de Actualización del punto de conexión de SQL (para mantener sincronizado el punto de conexión de SQL Analytics después de cargar los datos). El generador de expresiones de canalización también incluye asistencia de Copilot para crear expresiones más rápidas y precisas. Para obtener más información, consulte Actividad de mantenimiento de Lakehouse.
Limpie los recursos eliminando el área de trabajo y otros elementos.
Arquitectura
La siguiente imagen muestra la arquitectura integral del lakehouse. Los componentes implicados se describen en la lista siguiente.

Orígenes de datos: Fabric facilita la conexión rápida y sencilla a Azure Data Services, así como a otras plataformas basadas en la nube y orígenes de datos locales, para una ingesta de datos simplificada.
Ingesta: Puede obtener rápidamente perspectivas para su organización con más de 200 conectores nativos. Estos conectores se integran en la canalización de Fabric y usan la transformación de datos fácil de usar mediante arrastrar y soltar en el flujo de datos. Además, con la característica de acceso directo de Fabric, puede conectarse a los datos existentes sin tener que copiarlos ni moverlos. Los accesos directos de OneLake también pueden hacer referencia a productos de datos entre clientes a través del uso compartido de datos externos de OneLake, lo que proporciona acceso a datos operativos controlados y activos sin copiar ni construir canalizaciones de ETL. Fabric también incluye lectores de archivos vectorizados de alto rendimiento para formatos comunes, como CSV (con compatibilidad con JSON próximamente) para reducir la latencia de ingesta.
Transformación y almacenamiento: Fabric normaliza el formato Delta Lake. Esto significa que todos los motores de Fabric pueden acceder y manipular el mismo conjunto de datos almacenado en OneLake sin duplicar los datos. El modelo de gobernanza unificada de OneLake garantiza que los datos a los que se accede a través de accesos directos participan en las mismas directivas de seguridad y cumplimiento que los datos almacenados localmente, lo que proporciona una única versión de verdad en toda la organización. Este sistema de almacenamiento proporciona la flexibilidad de crear "lakehouses" usando una arquitectura de medallón o una malla de datos, de acuerdo con las necesidades de su organización. Puede elegir entre una experiencia de poco código o sin código para la transformación de datos, utilizando canalizaciones o flujos de datos, o cuadernos/Spark para una experiencia orientada al código. Las tablas de Lakehouse también admiten optimizaciones de rendimiento como Z-ordering y Liquid Clustering para mejorar el rendimiento de las consultas y administrar el diseño de datos a escala. Además, las vistas de Materialized Lake están disponibles para calcular previamente y almacenar los resultados en caché sobre los datos de lakehouse, lo que acelera el análisis repetido. La operativización puede incluir el mantenimiento automatizado de las tablas de Lakehouse Delta a través de la actividad de mantenimiento de Lakehouse en canalizaciones y desencadenar una actualización del punto de conexión de análisis de SQL como parte de los pasos posteriores a la carga; consulte el paso opcional de orquestación de canalización en el resumen del escenario anterior para obtener más información.
Consumo: Power BI puede consumir datos de la instancia de Lakehouse para la creación de informes y la visualización. Cada Lakehouse tiene un punto de conexión de TDS integrado, el punto de conexión de análisis de SQL, para facilitar la conectividad y la consulta de datos en las tablas del Lakehouse desde otras herramientas de informes. La orquestación de canalizaciones puede incluir un paso para actualizar el punto de conexión de SQL Analytics de Lakehouse para asegurarse de que el esquema y los metadatos están actualizados para las herramientas de informes después de cargar los datos; consulte el paso opcional de orquestación de canalizaciones en la información general del escenario anterior para obtener más información.
A través del uso compartido de datos entre inquilinos, informes, modelos semánticos y cargas de trabajo de ciencia de datos o inteligencia artificial también pueden consumir datos de OneLake compartidos a través de límites de la organización, lo que permite la colaboración sin duplicación de datos.
Conjunto de datos de ejemplo
En este tutorial se usa la base de datos de ejemplo Wide World Importers (WWI) que se importa en lakehouse en el siguiente tutorial. Para el escenario de un extremo a otro de Lakehouse, el conjunto de datos incluye datos suficientes para explorar las funcionalidades de escala y rendimiento de la plataforma Fabric.
Wide World Importers (WWI) es un importador y distribuidor mayorista de artículos de novedades que opera desde el área de la bahía de San Francisco. Como mayorista, los clientes de WWI principalmente incluyen empresas que revenden a particulares. WWI vende a clientes minoristas de todos los Estados Unidos, incluyendo tiendas especializadas, supermercados, tiendas de informática, tiendas de atracciones turísticas y algunos particulares. WWI también vende a otros mayoristas a través de una red de agentes que promocionan los productos en nombre de WWI. Para obtener más información sobre el perfil y el funcionamiento de la empresa, consulte Bases de datos de ejemplo de Wide World Importers para Microsoft SQL.
En general, los datos se trasladan desde sistemas transaccionales o aplicaciones empresariales a un lakehouse. Sin embargo, para simplificar en este tutorial, se usa el modelo dimensional proporcionado por WWI como origen de datos inicial. Los datos se ingieren en una casa de lago y se transforman a través de diferentes fases (Bronce, Plata y Oro) de una arquitectura de medallón.
Modelo de datos
Aunque el modelo dimensional WWI contiene numerosas tablas de hechos, en este tutorial se usa la tabla de hechos Sale y sus dimensiones correlacionadas. En el ejemplo siguiente se muestra el modelo de datos de WWI:

Flujo de datos y transformación
Como se ha descrito anteriormente, en este tutorial se usan los datos de muestra de Wide World Importers (WWI) para crear un lakehouse de extremo a extremo. En esta implementación, los datos de ejemplo se almacenan en una cuenta de almacenamiento de Azure Data en formato de archivo Parquet para todas las tablas. Sin embargo, en escenarios reales, los datos normalmente se originan en varios orígenes y en distintos formatos.
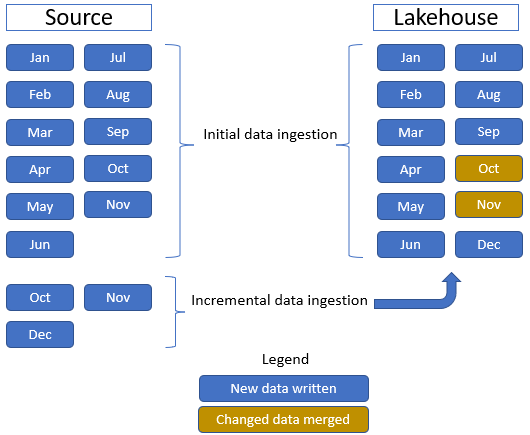
En la imagen siguiente se muestra la transformación de origen, destino y datos:

Origen de datos: los datos de origen están en formato de archivo Parquet y en una estructura sin particiones. Se almacenan en una carpeta para cada tabla. En este tutorial, configurará una canalización para ingerir los datos históricos o datos únicos completos en el lakehouse.
En este tutorial, usas la tabla de hechos Venta, que tiene una carpeta principal con datos históricos de 11 meses (con una subcarpeta para cada mes) y otra carpeta que contiene datos incrementales de tres meses (una subcarpeta para cada mes). Durante la ingesta de datos inicial, se ingieren 11 meses de datos en la tabla del lakehouse. Cuando llegan los datos incrementales, los datos actualizados de octubre y noviembre se combinan con los datos existentes y los nuevos datos de diciembre se escriben en la tabla lakehouse, como se muestra en la siguiente imagen:
Almacén de lago: en este tutorial, crea un almacén de lago, ingiere datos en la sección de archivos del almacén de lago y, a continuación, crea tablas de delta lake en la sección Tablas del almacén de lago.
Transformación: en el caso de la preparación y transformación de datos, en este tutorial se tratan dos enfoques diferentes: cuadernos y Spark para una experiencia de código primero, así como canalizaciones y flujos de datos para una experiencia de código bajo o sin código. La última versión del entorno de ejecución de Fabric incluye un motor de ejecución nativo que ofrece mejoras de rendimiento significativas en comparación con Spark de código abierto para cargas de trabajo de notebooks y trabajos de Spark. El generador de expresiones de canalización incluye ayuda de Copilot para ayudar a crear expresiones y crear lógica de canalización para generar expresiones más rápidas y precisas.
Consumo: Power BI puede consumir datos de lakehouse para informes y visualización. Cada Lakehouse tiene un punto de conexión TDS integrado llamado punto de conexión de análisis de SQL para facilitar la conectividad y la consulta de datos en las tablas de Lakehouse desde otras herramientas de informes. También puede usar Direct Lake a través de OneLake para permitir que Power BI consulte directamente las tablas del lakehouse sin necesidad de importación o un ciclo de actualización de modelo semántico dedicado. Además, puede hacer que los datos estén disponibles para herramientas de informes no-Microsoft mediante el extremo de análisis TDS/SQL para conectar y ejecutar consultas SQL de análisis.
En el caso de las cargas de trabajo de Spark SQL, específicamente, los clientes compatibles con ODBC pueden conectarse mediante el controlador ODBC de Microsoft para Microsoft Fabric Ingeniería de Datos (versión preliminar) con autenticación Microsoft Entra ID (interactiva, CLI de Azure, principal del servicio, certificado o token de acceso).
