Apache Sqoop est un outil d’interface de ligne de commande pour transférer des données entre des clusters Apache Hadoop et des bases de données relationnelles. Il dispose d’une interface de ligne de commande.
Vous pouvez utiliser Sqoop pour importer des données vers HDFS à partir de bases de données relationnelles telles que MySQL, PostgreSQL, Oracle et SQL Server, et exporter des données HDFS vers ces bases de données. Sqoop peut utiliser MapReduce et Apache Hive pour convertir des données sur Hadoop. Les fonctionnalités avancées incluent le chargement incrémentiel, la mise en forme à l’aide de SQL et la mise à jour des jeux de données. Sqoop fonctionne en parallèle pour obtenir un transfert de données à grande vitesse.
Notes
Le projet Sqoop a été mis hors service. Sqoop a été déplacé dans Apache Attic en juin 2021. Le site web, les téléchargements et le suivi des problèmes restent disponibles. Pour plus d’informations, voir Apache Sqoop dans Apache Attic .
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Storm®, Apache Sqoop®, Apache Kafka® et le logo de flamme sont des marques déposées ou des marques de l’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture et composants Sqoop
Il existe deux versions de Sqoop : Sqoop1 et Sqoop2. Sqoop1 est un outil client simple, tandis que Sqoop2 a une architecture client/serveur. Ils ne sont pas compatibles entre eux, et leur utilisation diffère. Sqoop2 n’est pas terminé et n’est pas destiné au déploiement de production.
Architecture de Sqoop1
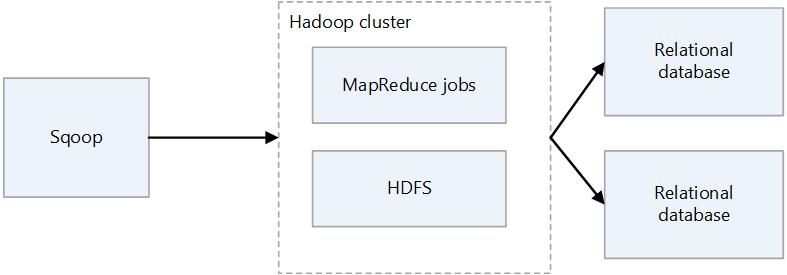
Importation et exportation de Sqoop1
Importer
Lit les données des bases de données relationnelles et génère des données dans HDFS. Chaque enregistrement de la table de bases de données relationnelles est généré en tant que ligne unique dans HDFS. Text, SequenceFiles et Avro sont les formats de fichier qui peuvent être écrits dans HDFS.
Export
Lit les données de HDFS et les transfère aux bases de données relationnelles. Les bases de données relationnelles cibles prennent en charge l’insertion et la mise à jour.
Architecture Sqoop2
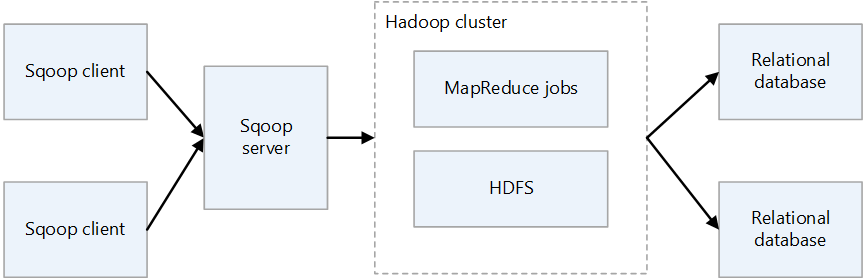
Serveur Sqoop
Fournit un point d’entrée pour les clients Sqoop.
Client Sqoop
Interagit avec le serveur Sqoop. Le client peut se trouver sur n’importe quel nœud, à condition que le client puisse communiquer avec le serveur. Étant donné que le client doit uniquement communiquer avec le serveur, il n’est pas nécessaire d’effectuer des réglages comme vous le feriez avec MapReduce.
Défis de Sqoop en local
Voici quelques défis courants liés à un déploiement de Sqoop local :
- La mise à l’échelle peut être difficile, en fonction de la capacité matérielle et du centre de données.
- La mise à l’échelle à la demande peut se révéler complexe.
- Lorsque la prise en charge se termine pour une infrastructure vieillissante, vous pouvez être contraint de songer au remplacement et à la mise à niveau.
- Il n’y a pas d’outils natifs à fournir :
- Transparence des coûts
- Surveillance
- DevOps
- Automatisation
Considérations
- Lorsque vous migrez Sqoop vers Azure, si votre source de données reste en local, vous devez prendre en compte sa connectivité. Vous pouvez établir une connexion VPN sur Internet entre Azure et votre réseau local existant, ou vous pouvez utiliser Azure ExpressRoute pour établir une connexion privée.
- Lorsque vous migrez Sqoop vers Azure HDInsight, tenez compte de votre version de Sqoop. HDInsight prend uniquement en charge Sqoop1. Par conséquent, si vous utilisez Sqoop2 dans votre environnement local, vous devez le remplacer par Sqoop1 sur HDInsight ou conserver Sqoop2 de façon indépendante.
- Lorsque vous migrez Sqoop vers Azure Data Factory, vous devez prendre en compte les formats de fichier de données. Data Factory ne prend pas en charge le format SequenceFile. L’absence de prise en charge peut être un problème si votre implémentation Sqoop importe des données au format SequenceFile. Pour plus d’informations, consultez Format de fichier.
Approche de migration
Azure a plusieurs cibles de migration pour Apache Sqoop. Selon les exigences et les fonctionnalités de produit, vous pouvez choisir entre les machines virtuelles Azure IaaS, Azure HDInsight et Azure Data Factory.
Voici un graphique de décision pour sélectionner une cible de migration :
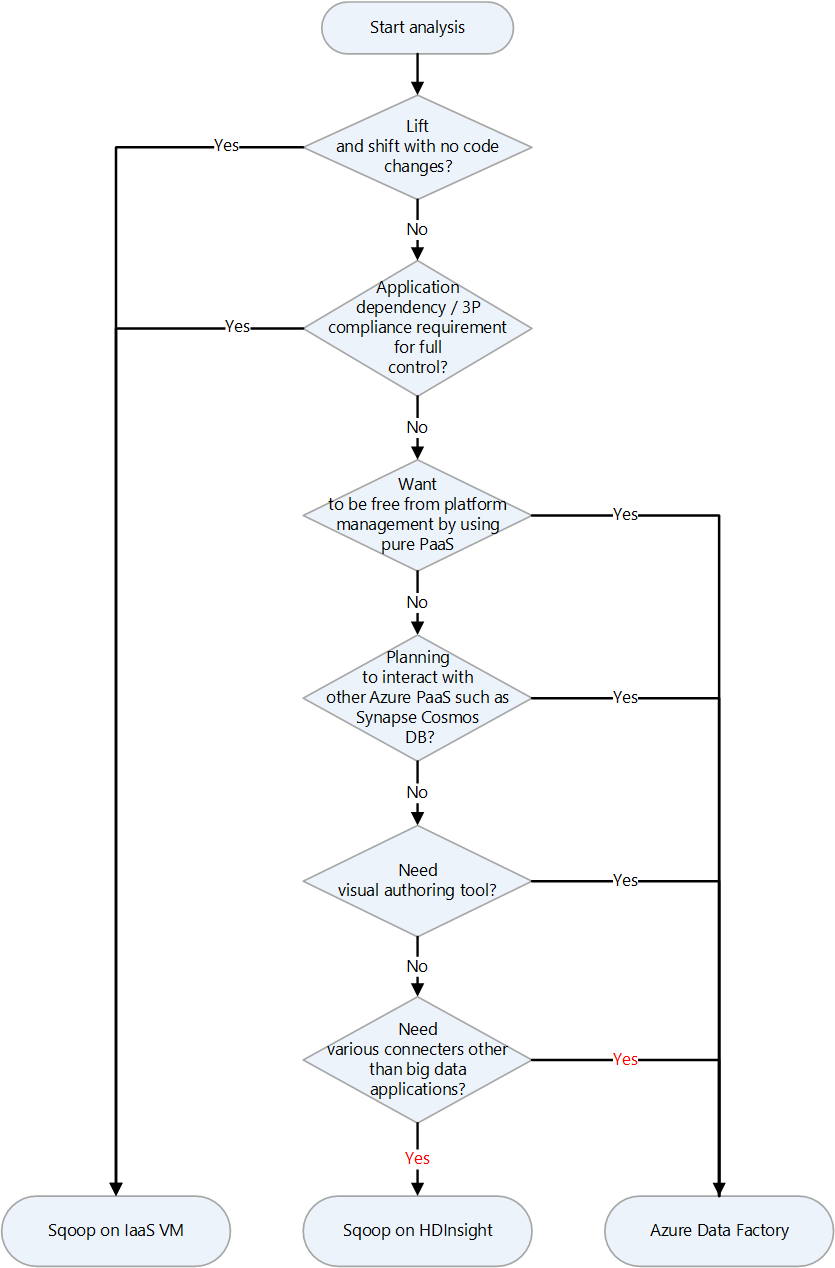
Ces cibles de migration sont abordées dans les sections suivantes :
Migration lift-and-shift vers Azure IaaS
Si vous choisissez des machines virtuelles IaaS Azure comme destination de migration pour votre Sqoop local, vous pouvez effectuer une migration de lift-and-shift. Vous utilisez la même version de Sqoop pour créer un environnement entièrement contrôlable. Par conséquent, vous n’avez pas à apporter de modifications au logiciel Sqoop. Sqoop fonctionne avec un cluster Hadoop et est généralement migré avec un cluster Hadoop. Les articles suivants sont des guides pour une migration lift-and-shift d’un cluster Hadoop. Choisissez l’article qui s’applique au service à migrer.
Préparation de la migration
Pour préparer la migration, vous planifiez la migration et vous établissez une connexion réseau.
Planifier la migration
Rassemblez les informations suivantes pour préparer la migration de votre Sqoop local. Les informations vous aident à déterminer la taille de la machine virtuelle de destination et à planifier les composants logiciels et les configurations réseau.
| Élément | Arrière-plan |
|---|---|
| Taille actuelle de l’hôte | Obtenez des informations sur le processeur, la mémoire, le disque et d’autres composants de l’hôte ou de la machine virtuelle sur laquelle le client Sqoop ou le serveur est exécuté. Vous utilisez ces informations pour estimer la taille de base requise pour votre machine virtuelle Azure. |
| Métriques d’hôte et d’application | Obtenez les informations sur l’utilisation des ressources (processeur, mémoire, disque et autres composants) de l’ordinateur qui exécute le client Sqoop et estimez les ressources réellement utilisées. Si vous utilisez moins de ressources que ce qui est alloué à votre hôte, envisagez de réduire la taille lorsque vous migrez vers Azure. Après avoir identifié la quantité requise de ressources, sélectionnez le type de machine virtuelle vers lequel effectuer la migration en faisant référence à la taille de la machine virtuelle Azure. |
| Version de Sqoop | Vérifiez la version de Sqoop locale pour déterminer la version de Sqoop à installer sur la machine virtuelle Azure. Si vous utilisez une distribution telle que Cloudera ou Hortonworks, la version du composant dépend de la version de cette distribution. |
| Exécution de travaux et de scripts | Identifiez les tâches qui exécutent Sqoop et les méthodes de planification de celles-ci. Les tâches et méthodes sont des candidats à la migration. |
| Bases de données à connecter | Identifiez les bases de données auxquelles Sqoop se connecte, comme spécifié par les commandes d’importation et d’exportation dans les tâches Sqoop. Une fois que vous les avez identifiés, vous devez voir si vous pouvez vous connecter à ces bases de données après avoir migré Sqoop vers vos machines virtuelles Azure. Si certaines des bases de données auxquelles vous vous connectez sont toujours locales, vous avez besoin d’une connexion réseau entre Azure et l’environnement local. Pour plus d’informations, consultez la section Établir une connexion réseau . |
| Plug-ins | Identifiez les plug-ins Sqoop que vous utilisez et déterminez si vous pouvez les migrer. |
| Haute disponibilité, continuité d’activité, reprise d’activité après sinistre | Déterminez si les techniques de résolution des problèmes que vous utilisez localement peuvent être utilisées sur Azure. Par exemple, si vous avez une configuration active/de secours sur deux nœuds, préparez deux machines virtuelles Azure pour les clients Sqoop qui ont la même configuration. La même chose s’applique lors de la configuration de la récupération d’urgence. |
Établir une connexion réseau
Si certaines des bases de données auxquelles vous vous connectez restent locales, vous avez besoin d’une connexion réseau entre Azure et l’environnement local.
Il existe deux options principales pour la connexion locale et Azure sur un réseau privé :
Passerelle VPN
Vous pouvez utiliser la passerelle VPN Azure pour l'envoi du trafic chiffré entre un réseau virtuel Azure et votre emplacement local sur le réseau Internet public. Cette technique est peu coûteuse et facile à configurer. Toutefois, en raison de la connexion chiffrée sur Internet, la bande passante de communication n’est pas garantie. Si vous devez garantir la bande passante, vous devez choisir ExpressRoute, qui est la deuxième option. Pour plus d’informations sur l’option VPN, consultez Qu’est-ce que la passerelle VPN ? et Conception de la passerelle VPN.
ExpressRoute
ExpressRoute peut connecter votre réseau local à Azure ou à Microsoft 365 à l’aide d’une connexion privée fournie par un fournisseur de connectivité. ExpressRoute ne passe pas par l’Internet public. Ill est donc plus sécurisé, plus fiable et a des latences plus cohérentes que les connexions sur Internet. En outre, les options de bande passante de la ligne que vous achetez peuvent garantir des latences stables. Pour plus d’informations, consultez Qu’est-ce qu’Azure ExpressRoute ?.
Si ces méthodes de connexion privée ne répondent pas à vos besoins, envisagez Azure Data Factory comme destination de migration. Le runtime d’intégration auto-hébergé dans Data Factory vous permet de transférer des données d’un site local vers Azure sans avoir à configurer un réseau privé.
Migrer des données et des paramètres
Lorsque vous migrez un environnement Sqoop local vers des machines virtuelles Azure, incluez les données et les paramètres suivants :
Fichiers de configuration Sqoop : cela dépend de votre environnement, mais les fichiers suivants sont souvent inclus :
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml, si vous utilisez Oraoop
Tâches enregistrées : si vous avez enregistré des tâches dans le metastore Sqoop à l’aide de la commande
sqoop job --create, vous devez les migrer. La destination d’enregistrement du metastore est définie dans sqoop-site.xml. Si le métastore partagé n’est pas défini, recherchez les tâches enregistrées dans le sous-répertoire .sqoop du répertoire d’accueil de l’utilisateur qui exécute le metastore.Vous pouvez utiliser les commandes suivantes pour afficher des informations sur les travaux enregistrés.
Obtenez la liste de tâches enregistrées :
sqoop job --listAfficher les paramètres pour les tâches enregistrées
sqoop job --show <job-id>
Scripts : si vous avez des fichiers de script qui exécutent Sqoop, vous devez les migrer.
Planificateur : si vous planifiez l’exécution de Sqoop, vous devez identifier son planificateur, tel qu’une tâche cron Linux ou un outil de gestion des tâches. Vous devez ensuite déterminer si le planificateur peut être migré vers Azure.
Plugins : si vous utilisez des plug-ins personnalisés dans Sqoop, par exemple un connecteur à une base de données externe, vous devez les migrer. Si vous avez créé un fichier de correctif, appliquez le correctif au Sqoop migré.
Migrer vers HDInsight
HDInsight regroupe les composants Apache Hadoop et la plateforme HDInsight dans un package déployé sur un cluster. Au lieu de migrer Sqoop lui-même vers Azure, il est plus courant d’exécuter Sqoop sur un cluster HDInsight. Pour plus d’informations sur l’utilisation de HDInsight pour exécuter des infrastructures open source telles que Hadoop et Spark, consultez Qu’est-ce qu’Azure HDInsight ? et Guide de migration des charges de travail Big Data vers Azure HDInsight.
Consultez les articles suivants pour accéder aux versions des composants dans HDInsight.
Migrer vers Data Factory
Azure Data Factory est un service d’intégration de données serverless complètement managé. Il peut être mis à l’échelle à la demande en fonction de facteurs tels que le volume de données. Il dispose d’une interface graphique pour la modification et le développement intuitifs à l’aide de modèles Python, .NET et Azure Resource Manager (modèles ARM).
Connexion aux sources de données
Consultez l’article approprié pour obtenir la liste des connecteurs Sqoop standard :
Data Factory dispose d’un grand nombre de connecteurs. Pour plus d’informations, consultez Présentation du connecteur Azure Data Factory et Azure Synapse Analytics.
Le tableau suivant illustre les connecteurs Data Factory à utiliser pour Sqoop1 version 1.4.7 et Sqoop2 version 1.99.7. Veillez à faire référence à la documentation la plus récente, car la liste des versions prises en charge peut changer.
| Sqoop1 - 1.4.7 | Sqoop2 - 1.99.7 | Data Factory | Considérations |
|---|---|---|---|
| MySQL JDBC Connector | Generic JDBC Connector | MySQL, Azure Database pour MySQL | |
| MySQL Direct Connector | N/A | N/A | Direct Connector utilise mysqldump pour faire entrer et sortir des données sans passer par JDBC. La méthode est différente dans Data Factory, mais le connecteur MySQL peut être utilisé à la place. |
| Connecteur Microsoft SQL | Connecteur générique JDBC | SQL Server, Azure SQL Database, Azure SQL Managed Instance | |
| Connecteur PostgreSQL | PostgreSQL, Connecteur générique JDBC | Azure Database pour PostgreSQL | |
| PostgreSQL Direct Connector | N/A | N/A | Direct Connector ne passe pas par JDBC et utilise la commande COPY pour entrer et générer des données. La méthode est différente dans Data Factory, mais le connecteur PostgreSQL peut être utilisé à la place. |
| connecteur pg_bulkload | N/A | N/A | Chargez dans PostgreSQL à l’aide de pg_bulkload. La méthode est différente dans Data Factory, mais le connecteur PostgreSQL peut être utilisé à la place. |
| Connecteur Netezza | Connecteur générique JDBC | Netteza | |
| Connecteur de données pour Oracle et Hadoop | Connecteur générique JDBC | Oracle | |
| N/A | Connecteur FTP | FTP | |
| N/A | Connecteur SFTP | SFTP | |
| N/A | Connecteur Kafka | N/A | Data Factory ne peut pas se connecter directement à Kafka. Envisagez d’utiliser Spark Streaming, comme Azure Databricks ou HDInsight, pour vous connecter à Kafka. |
| N/A | Connecteur Kite | N/A | Data Factory ne peut pas se connecter directement à Kite. |
| HDFS | HDFS | HDFS | Data Factory prend en charge HDFS en tant que source, mais pas en tant que récepteur. |
Se connecter à des bases de données locales
Si, après avoir migré Sqoop vers Data Factory, vous devez toujours copier des données entre un magasin de données de votre réseau local et Azure, envisagez d’utiliser ces méthodes :
Runtime d’intégration auto-hébergé
Si vous essayez d’intégrer des données dans un environnement de réseau privé où il n’existe aucun chemin de communication direct à partir de l’environnement de cloud public, vous pouvez effectuer les opérations suivantes pour améliorer la sécurité :
- Installez un runtime d’intégration auto-hébergé dans l’environnement local, soit dans le pare-feu interne, soit dans le réseau privé virtuel.
- Établissez une connexion sortante basée sur HTTPS à partir du runtime d’intégration auto-hébergé vers Azure afin d’établir une connexion pour le déplacement des données.
Le runtime d’intégration auto-hébergé est uniquement pris en charge sur Windows. Vous pouvez également obtenir une scalabilité et une haute disponibilité en installant et en associant des runtimes d’intégration auto-hébergés sur plusieurs machines. Le runtime d’intégration auto-hébergé est également responsable de la distribution d’activités de transformation de données vers des ressources qui ne sont pas locales ou dans le réseau virtuel Azure.
Pour plus d’informations sur la configuration d’un runtime d’intégration auto-hébergé, consultez Créer et configurer un runtime d’intégration auto-hébergé.
Réseau virtuel managé à l’aide d’un point de terminaison privé
Si vous disposez d’une connexion privée entre un environnement local et Azure (tel qu’ExpressRoute ou une passerelle VPN), vous pouvez utiliser un réseau virtuel managé et un point de terminaison privé dans Data Factory pour établir une connexion privée à vos bases de données locales. Vous pouvez utiliser des réseaux virtuels pour transférer le trafic vers vos ressources locales, comme illustré dans le diagramme suivant, pour accéder à vos ressources locales sans passer par Internet.

Téléchargez un fichier Visio de cette architecture.
Pour plus d’informations, voir Tutoriel : Guide pratique pour accéder à un serveur SQL local à partir d’un VNet managé Data Factory en utilisant un point de terminaison privé.
Options réseau
Data Factory propose deux options réseau :
Les deux créent un réseau privé et permettent de sécuriser le processus d’intégration des données. Elles ne peuvent pas être utilisées en même temps.
Réseau virtuel managé
Vous pouvez déployer le runtime d’intégration, qui est le runtime Data Factory, au sein d’un réseau virtuel managé. En déployant un point de terminaison privé tel qu’un magasin de données qui se connecte au réseau virtuel managé, vous pouvez améliorer la sécurité de l’intégration des données au sein d’un réseau privé fermé.

Téléchargez un fichier Visio de cette architecture.
Pour plus d’informations, voir Réseau virtuel managé Azure Data Factory.
Liaison privée
Vous pouvez utiliser Azure Private Link pour Azure Data Factory pour vous connecter à Data Factory.

Téléchargez un fichier Visio de cette architecture.
Pour plus d’informations, consultez Qu’est-ce qu’un point de terminaison privé ? et Documentation Private Link.
Performances de la copie de données
Sqoop améliore les performances de transfert de données à l’aide de MapReduce pour le traitement parallèle. Après avoir migré Sqoop, Data Factory peut ajuster les performances et l’extensibilité pour les scénarios qui effectuent des migrations de données à grande échelle.
Une unité d’intégration de données (DIU) est une unité de performances Data Factory. Il s’agit d’une combinaison de l’allocation des ressources du processeur, de la mémoire et du réseau. Data Factory peut ajuster jusqu’à 256 DIU pour les activités de copie qui utilisent le runtime d’intégration Azure. Pour plus d’informations, consultez Unités d’intégration de données.
Si vous utilisez le runtime d’intégration auto-hébergé, vous pouvez améliorer les performances en mettant à l’échelle la machine qui héberge le runtime d’intégration auto-hébergé. Le scale-out maximal est de quatre nœuds.
Pour plus d’informations sur la réalisation des ajustements pour atteindre les performances souhaitées, voir Guide sur les performances et la scalabilité de l’activité de copie.
Appliquer SQL
Sqoop peut importer le jeu de résultats d’une requête SQL, comme illustré dans cet exemple :
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
Data Factory peut également interroger la base de données et copier le jeu de résultats :
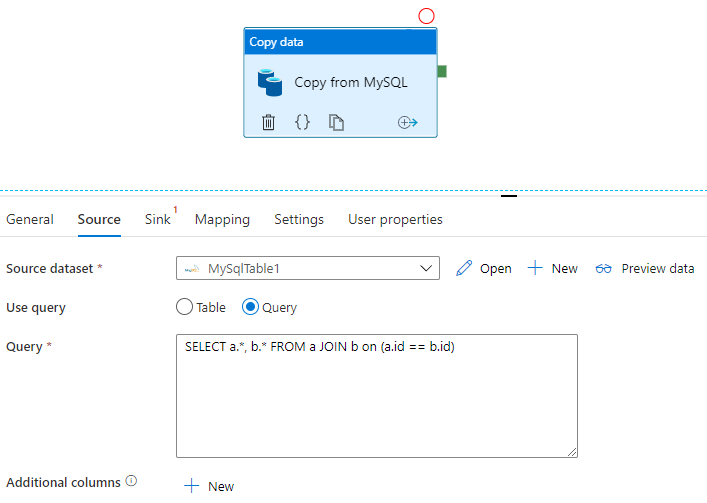
Consultez Propriétés de l’activité de copie pour obtenir un exemple qui donne le jeu de résultats d’une requête sur une base de données MySQL.
Transformation des données
Data Factory et HDInsight peuvent effectuer diverses activités de transformation de données.
Transformer des données à l’aide d’activités Data Factory
Data Factory peut effectuer diverses activités de transformation de données, telles que le flux de données et le data wrangling. Pour les deux, vous définissez les transformations à l’aide d’une interface utilisateur visuelle. Vous pouvez également utiliser les activités de différents composants Hadoop de HDInsight, Databricks, des procédures stockées et d’autres activités personnalisées. Envisagez d’utiliser ces activités lorsque vous migrez Sqoop et souhaitez inclure des transformations de données dans le processus. Pour plus d’informations, consultez Transformer des données dans Azure Data Factory.
Transformer des données à l’aide d’activités HDInsight
Les différentes activités HDInsight dans un pipeline Azure Data Factory, notamment Hive, Pig, MapReduce, Streaming et Spark, peuvent exécuter des programmes et des requêtes sur votre propre cluster ou sur un cluster HDInsight à la demande. Si vous migrez une implémentation Sqoop qui utilise la logique de transformation de données de l’écosystème Hadoop, il est facile de migrer les transformations vers des activités HDInsight. Pour plus de détails, consultez les articles suivants.
- Transformer des données à l’aide d’une activité Hadoop Hive dans Azure Data Factory ou Synapse Analytics | Microsoft Docs
- Transformer des données à l’aide d’une activité Hadoop MapReduce dans Azure Data Factory ou Synapse Analytics | Microsoft Docs
- Transformer des données à l’aide d’une activité Hadoop Pig dans Azure Data Factory ou Synapse Analytics
- Transformer des données à l'aide d'une activité Spark dans Azure Data Factory et Synapse Analytics
- Transformer des données à l'aide d'une activité de diffuser en continu Hadoop dans Azure Data Factory ou Synapse Analytics
Format de fichier
Sqoop prend en charge le texte, SequenceFile et Avro en tant que formats de fichiers lors de l’importation des données dans HDFS. Data Factory ne prend pas en charge HDFS comme récepteur de données, mais il utilise Azure Data Lake Storage ou Stockage Blob Azure comme stockage de fichiers. Pour plus d’informations sur la migration HDFS, consultez Migration Apache HDFS.
Les formats pris en charge pour Data Factory à écrire dans le stockage de fichiers sont texte, binaire, Avro, JSON, ORC et Parquet, mais pas SequenceFile. Vous pouvez utiliser une activité telle que Spark pour convertir un fichier en SequenceFile à l’aide de saveAsSequenceFile :
data.saveAsSequenceFile(<path>)
Planification des travaux
Sqoop ne fournit pas de fonctionnalités de planificateur. Si vous exécutez des travaux Sqoop sur un planificateur, vous devez migrer cette fonctionnalité vers Data Factory. Data Factory peut utiliser des déclencheurs pour planifier l’exécution du pipeline de données. Choisissez un déclencheur Data Factory en fonction de votre configuration de planification existante. Voici les différents types de déclencheurs.
- Déclencheur de planification : un déclencheur de planification exécute le pipeline selon une planification de temps horloge.
- Déclencheur de fenêtre bascule : un déclencheur de fenêtre bascule s’exécute régulièrement à partir d’une heure de début spécifiée tout en conservant son état.
- Déclencheur basé sur les événements : un déclencheur basé sur les événements déclenche le pipeline en réponse à l’événement. Il existe deux types de déclencheurs basés sur des événements :
- Déclencheur d’événement de stockage : un déclencheur d’événement de stockage déclenche le pipeline en réponse à un événement de stockage tel que la création, la suppression ou l’écriture dans un fichier.
- Déclencheur d’événement personnalisé : un déclencheur d’événement personnalisé déclenche le pipeline en réponse à un événement envoyé à une rubrique personnalisée dans une grille d’événements. Pour plus d’informations sur les rubriques personnalisées, consultez Rubriques personnalisées dans Azure Event Grid.
Pour plus d’informations sur les déclencheurs, consultez Exécution de pipeline et déclencheurs dans Azure Data Factory ou Azure Synapse Analytics.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Namrata Maheshwary | Architecte de solutions cloud senior
- Raja N | Directeur, Réussite des clients
- Hideo Takagi | Architecte de solutions cloud
- Ram Yerrabotu | Architecte de solutions cloud senior
Autres contributeurs :
- Ram Baskaran | Architecte de solutions cloud senior
- Jason Bouska | Ingénieur logiciel senior
- Eugene Chung | Architecte de solutions cloud senior
- Pawan Hosatti | Architecte de solutions cloud senior - Ingénierie
- Daman Kaur | Architecte de solutions cloud
- Danny Liu | Architecte de solutions cloud senior - Ingénierie
- Jose Mendez | Architecte de solutions cloud senior
- Ben Sadeghi | Spécialiste senior
- Sunil Sattiraju | Architecte de solutions cloud senior
- Amanjeet Singh | Responsable principal du programme
- Nagaraj Seeplapudur Venkatesan | Architecte de solutions cloud senior - Ingénierie
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Présentations des produits Azure
- Introduction à Azure Data Lake Storage Gen2
- Présentation d’Apache Spark dans Azure HDInsight
- Qu’est-ce qu’Apache Hadoop dans Azure HDInsight ?
- Qu’est-ce qu’Apache HBase dans Azure HDInsight
- Présentation d’Apache Kafka dans Azure HDInsight
- Vue d’ensemble de la sécurité d’entreprise dans Azure HDInsight
Informations de référence sur les produits Azure
- Documentation Microsoft Entra
- Documentation Azure Cosmos DB
- Documentation Azure Data Factory
- Documentation Azure Databricks
- Documentation Azure Event Hubs
- Documentation Azure Functions
- Documentation Azure HDInsight
- Documentation sur la gouvernance des données Microsoft Purview
- Documentation d’Azure Stream Analytics
- Azure Synapse Analytics
Autres
- Pack Sécurité Entreprise pour Azure HDInsight
- Développer des programmes MapReduce Java pour Apache Hadoop sur HDInsight
- Utiliser Apache Sqoop avec Hadoop dans HDInsight
- Vue d’ensemble d’Apache Spark Streaming
- Tutoriel sur Structured Streaming
- Utiliser Azure Event Hubs à partir d’applications Apache Kafka