Note
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de changer d’annuaire.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de changer d’annuaire.
Cet article aborde les points suivants :
- Types de données de monitoring que vous pouvez collecter pour ce service.
- Méthodes d’analyse de ces données.
Remarque
Si vous connaissez déjà ce service et/ou Azure Monitor et que vous voulez simplement savoir comment analyser les données de monitoring, consultez la section Analyser vers la fin de cet article.
Quand vous avez des applications critiques et des processus métier qui s’appuient sur des ressources Azure, vous devez monitorer votre système et obtenir des alertes. Le service Azure Monitor collecte et agrège les métriques et les journaux de chaque composant de votre système. Azure Monitor vous fournit une vue de la disponibilité, des performances et de la résilience, et vous avertit des problèmes. Vous pouvez utiliser le portail Azure, PowerShell, Azure CLI, l’API REST ou des bibliothèques de client pour configurer et visualiser les données de monitoring.
- Pour plus d’informations sur Azure Monitor, consultez la vue d’ensemble d’Azure Monitor.
- Pour plus d’informations sur le monitoring des ressources Azure en général, consultez Monitorer les ressources Azure avec Azure Monitor.
Insights
Dans Azure, certains services ont un tableau de bord de monitoring intégré dans le portail Azure, qui constitue un point de départ pour le monitoring de votre service. Ces tableaux de bord sont appelés insights et vous pouvez les trouver dans le Hub d’insights d’Azure Monitor dans le portail Azure.
Virtual WAN utilise Network Insights pour permettre aux utilisateurs et aux opérateurs de voir l’état et le statut d’une instance de Virtual WAN, via une carte topologique ayant fait l’objet d’une découverte automatique. Les superpositions de l'état et du statut des ressources sur la carte vous fournissent une vue instantanée de l'intégrité globale du WAN virtuel. Vous pouvez naviguer parmi les ressources de la carte et accéder en un clic aux pages de configuration des ressources du portail Virtual WAN. Pour plus d’informations, consultez Azure Monitor Network Insights pour Virtual WAN.
Types de ressources
Azure utilise le concept des types de ressources et des ID pour identifier chaque chose dans un abonnement. Les types de ressource font également partie des ID de ressource pour chaque ressource exécutée dans Azure. Par exemple, le type de ressource pour une machine virtuelle peut être Microsoft.Compute/virtualMachines. Pour obtenir la liste des services et leurs types de ressource associés, consultez Fournisseurs de ressources.
Azure Monitor organise de façon similaire les données de surveillance de base en métriques et en journaux en fonction des types de ressources, également appelés espaces de noms. Différentes métriques et journaux sont disponibles pour les différents types de ressource. Votre service peut être associé à plusieurs types de ressource.
Pour plus d’informations sur les types de ressources de Virtual WAN, consultez Informations de référence sur les données de monitoring d’Azure Virtual WAN.
Stockage des données
Pour Azure Monitor :
- Les données de métriques sont stockées dans la base de données des métriques Azure Monitor.
- Les données de journal sont stockées dans le magasin de journaux Azure Monitor. Log Analytics est un outil du portail Azure qui peut interroger ce magasin.
- Le journal d’activité Azure est un magasin distinct avec sa propre interface dans le portail Azure.
Vous pouvez choisir d’acheminer les données des métriques et des journaux d’activité vers le magasin des journaux d’activité Azure Monitor. Vous pouvez ensuite utiliser Log Analytics pour interroger les données et les mettre en corrélation avec d’autres données de journal.
De nombreux services peuvent utiliser les paramètres de diagnostic pour envoyer les données des métriques et des journaux vers d’autres emplacements de stockage en dehors d’Azure Monitor. Par exemple, le Stockage Azure, les systèmes partenaires hébergés et les systèmes partenaires non-Azure, en utilisant Event Hubs.
Pour plus d’informations sur la façon dont Azure Monitor stocke les données, consultez Plateforme de données Azure Monitor.
Métriques de plateforme Azure Monitor
Azure Monitor fournit des métriques de plateforme pour la plupart des services. Ces mesures sont :
- Définies individuellement pour chaque espace de noms.
- Stockées dans la base de données de métriques de série chronologique Azure Monitor.
- Légères et capables de prendre en charge les alertes en quasi-temps réel.
- Utilisées pour suivre les performances d’une ressource au fil du temps.
Collecte : Azure Monitor collecte automatiquement les métriques de plateforme. Aucune configuration n'est requise.
Routage : vous pouvez également acheminer certaines mesures de plateforme vers Azure Monitor Logs/Log Analytics afin de pouvoir les interroger avec d’autres données de journal. Vérifiez le paramètre d’exportation DS pour chaque métrique pour voir si vous pouvez utiliser un paramètre de diagnostic pour router la métrique vers les journaux Azure Monitor / Log Analytics.
- Pour plus d’informations, consultez le paramètre de diagnostic des métriques.
- Pour configurer les paramètres de diagnostic d’un service, consultez Créer des paramètres de diagnostic dans Azure Monitor.
Pour obtenir la liste de toutes les métriques qu’il est possible de collecter pour toutes les ressources dans Azure Monitor, consultez Métriques prises en charge dans Azure Monitor.
Pour obtenir la liste des métriques disponibles pour Virtual WAN, consultez Informations de référence sur les données de monitoring d’Azure Virtual WAN.
Vous pouvez voir les métriques de Virtual WAN à l’aide du portail Azure. Les étapes suivantes vous aident à localiser et à afficher les métriques :
Sélectionnez Surveiller la passerelle, puis Métriques. Vous pouvez également sélectionner Métriques en bas afin d’afficher un tableau de bord des métriques les plus importantes pour les VPN site à site et point à site.
Dans la page Métriques, vous pouvez voir les métriques.
Pour voir les métriques du routeur du hub virtuel, vous pouvez sélectionner Métriques dans la page Vue d’ensemble du hub virtuel.
Pour plus d’informations, consultez Analyser les métriques d’une ressource Azure.
Étapes dans PowerShell
Vous pouvez voir les métriques de Virtual WAN à l’aide de PowerShell. Pour effectuer une requête, utilisez les exemples de commandes PowerShell suivants.
$MetricInformation = Get-AzMetric -ResourceId "/subscriptions/<SubscriptionID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Network/VirtualHubs/<VirtualHubName>" -MetricName "VirtualHubDataProcessed" -TimeGrain 00:05:00 -StartTime 2022-2-20T01:00:00Z -EndTime 2022-2-20T01:30:00Z -AggregationType Sum
$MetricInformation.Data
- ID de ressource. L’ID de ressource de votre hub virtuel se trouve sur le portail Azure. Accédez à la page du hub virtuel dans vWAN et sélectionnez Vue JSON sous Éléments principaux.
-
Nom de métrique. Fait référence au nom de la métrique que vous interrogez, qui se nomme
VirtualHubDataProcesseddans le cas présent. Cette métrique montre toutes les données traitées par le routeur du hub virtuel au cours de la période sélectionnée pour le hub. - Fragment de temps. Fait référence à la fréquence à laquelle vous souhaitez voir l’agrégation. Dans la commande actuelle, vous voyez une unité agrégée sélectionnée toutes les 5 minutes. Vous pouvez sélectionner : 5M/15M/30M/1H/6H/12H et 1J.
- Heure de début et heure de fin. Cette heure est basée sur l’heure UTC. Vérifiez que vous entrez des valeurs UTC lors de l’entrée de ces paramètres. Si ces paramètres ne sont pas utilisés, les données pour la dernière heure précédente sont montrées par défaut.
- Type d’agrégation Sum. Le type d’agrégation Sum vous indique le nombre total d’octets qui ont traversé le routeur du hub virtuel pendant une période sélectionnée. Par exemple, si vous affectez 5 minutes à la granularité temporelle, chaque point de données correspond au nombre d’octets envoyés dans cet intervalle de cinq minutes. Pour convertir cette valeur en Gbit/s, vous pouvez diviser ce nombre par 37 500 000 000. En fonction de la capacité du hub virtuel, le routeur du hub peut prendre en charge entre 3 Gbits/s et 50 Gbits/s. Les types d’agrégation Max et Min ne sont pas significatifs pour l’instant.
Journaux d’activité de ressources Azure Monitor
Les journaux de ressource fournissent des insights sur les opérations effectuées par une ressource Azure. Les journaux sont générés automatiquement, mais vous devez les router vers les journaux Azure Monitor pour les enregistrer ou les interroger. Les journaux sont organisés en catégories. Un espace de noms donné peut avoir plusieurs catégories de journal de ressource.
Collecte : les journaux d’activité de ressources ne sont pas collectés ni stockés tant que vous n’avez pas créé de paramètre de diagnostic et routé les journaux d'activité vers un ou plusieurs emplacements. Lorsque vous créez un paramètre de diagnostic, vous spécifiez les catégories de journaux à collecter. Il existe plusieurs façons de créer et gérer des paramètres de diagnostic, notamment le portail Azure, programmatiquement et avec Azure Policy.
Routage : la valeur par défaut suggérée est le routage des journaux de ressource vers les journaux Azure Monitor afin de pouvoir les interroger avec d’autres données de journal. D’autres emplacements comme le Stockage Azure, Azure Event Hubs et certains partenaires de monitoring de Microsoft sont également disponibles. Pour plus d’informations, consultez Journaux de ressource Azure et Destinations des journaux de ressource.
Pour plus d’informations sur la collecte, le stockage et le routage des journaux de ressource, consultez Paramètres de diagnostic dans Azure Monitor.
Pour obtenir la liste de toutes les catégories de journal de ressource disponibles dans Azure Monitor, consultez Journaux de ressource pris en charge dans Azure Monitor.
Tous les journaux de ressource dans Azure Monitor ont les mêmes champs d’en-tête, suivis de champs propres au service. Le schéma commun est décrit dans Schéma des journaux des ressources Azure Monitor.
Pour plus d’informations sur les catégories de journaux de ressources disponibles, les tables Log Analytics associées ainsi que les schémas de journaux relatifs à Virtual WAN, consultez Informations de référence sur les données de monitoring d’Azure Virtual WAN.
Schémas
Pour une description détaillée du schéma général des journaux de diagnostic, consultez Services, schémas et catégories pris en charge pour les journaux de diagnostic Azure.
Quand vous passez en revue des métriques via Log Analytics, la sortie contient les colonnes suivantes :
| Colonne | Type | Description |
|---|---|---|
| TimeGrain | ficelle | PT1M (les valeurs de métriques sont envoyées [push] toutes les minutes) |
| Nombre | réel | Généralement égale à 2 (chaque MSEE envoie [push] une valeur métrique unique toutes les minutes) |
| Minimum | réel | Minimum des deux valeurs de métriques envoyées (push) par les deux MSEE |
| Maximale | réel | Maximum des deux valeurs de métriques envoyées (push) par les deux MSEE |
| Moyen | réel | Égale à (Minimum + Maximum)/2 |
| Somme | réel | Somme des deux valeurs de métriques des deux MSEE (principale valeur sur laquelle se concentrer pour la métrique interrogée) |
Créer un paramètre de diagnostic pour afficher les journaux
Les étapes suivantes vous permettent de créer, modifier et afficher les paramètres de diagnostic :
Dans le portail, accédez à votre ressource Virtual WAN, puis sélectionnez Hubs dans le groupe Connectivité.
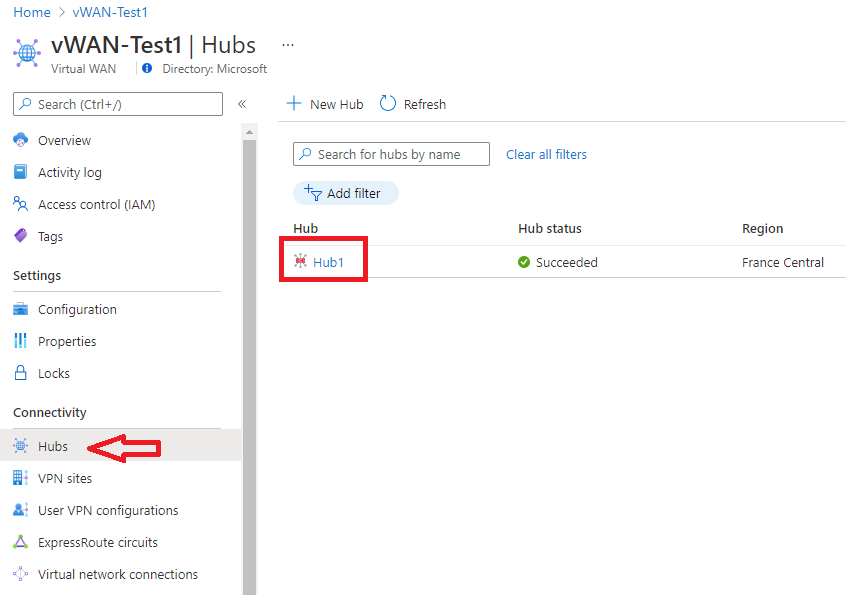
Sous le groupe Connectivité à gauche, sélectionnez la passerelle dont vous voulez examiner les diagnostics :
Dans la partie droite de la page, sélectionnez Surveiller la passerelle, puis Journaux.
Dans cette page, vous pouvez créer un paramètre de diagnostic (+Ajouter un paramètre de diagnostic) ou en modifier un existant (Modifier le paramètre). Vous pouvez choisir d’envoyer les journaux de diagnostic à Log Analytics (comme le montre l’exemple suivant), de les transmettre en continu à un Event Hub, de les envoyer à une solution tierce ou de les archiver dans un compte de stockage.
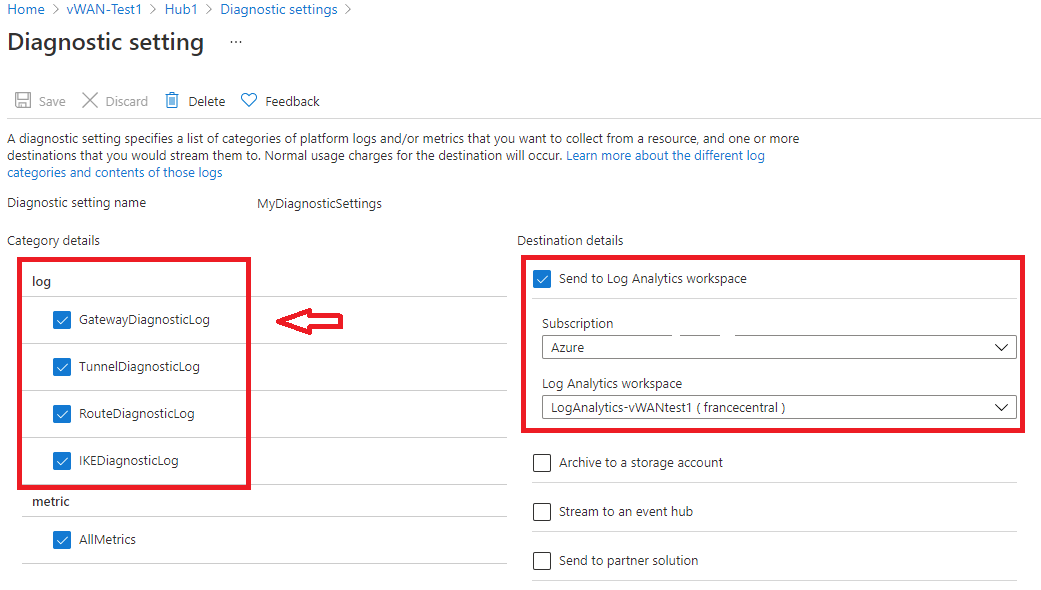
Quelques heures après avoir cliqué sur Enregistrer, des journaux devraient commencer à apparaître dans cet espace de travail Log Analytics.
Pour surveiller un hub sécurisé (avec Pare-feu Azure), les diagnostics et la configuration de la journalisation doivent être effectués depuis l’onglet Paramètre de diagnostic :




Important
L’activation de ces paramètres nécessite des services Azure supplémentaires (compte de stockage, hub d’événements ou Log Analytics), ce qui peut augmenter vos coûts. Pour calculer un coût estimé, consultez la rubrique Calculatrice de prix Azure.
Surveillance du hub sécurisé (Pare-feu Azure)
Si vous choisissez de sécuriser votre hub virtuel à l’aide du Pare-feu Azure, les journaux et les métriques appropriés sont disponibles ici : Journaux et métriques du Pare-feu Azure.
Vous pouvez superviser le hub sécurisé à l’aide des journaux et métriques du Pare-feu Azure. Vous pouvez également utiliser les journaux d’activité pour auditer les opérations sur les ressources de Pare-feu Azure. Pour chaque instance d’Azure Virtual WAN que vous sécurisez et convertissez en hub sécurisé, le Pare-feu Azure crée un objet de ressource de pare-feu explicite. L’objet se trouve dans le groupe de ressources où se trouve le hub.

Journal des activités Azure
Le journal d’activité contient des événements au niveau de l’abonnement qui suivent les opérations sur chaque ressource Azure qui sont vues comme extérieures à cette ressource, par exemple la création d’une ressource ou le démarrage d’une machine virtuelle.
Collection : les événements du journal d’activité sont automatiquement générés et collectés dans un magasin distinct pour être affichés dans le Portail Azure.
Routage : vous pouvez envoyer les données de journal d’activité aux journaux Azure Monitor afin de pouvoir les analyser en même temps que d’autres données de journal. D’autres emplacements comme le Stockage Azure, Azure Event Hubs et certains partenaires de monitoring de Microsoft sont également disponibles. Pour plus d’informations sur le routage du journal d’activité, consultez Vue d’ensemble du journal d’activité Azure.
Analyser les données de surveillance
Il existe de nombreux outils pour analyser les données de surveillance.
Outils Azure Monitor
Azure Monitor prend en charge les outils de base suivants :
Metrics Explorer, un outil du portail Azure qui vous permet de voir et d’analyser les métriques des ressources Azure. Pour plus d’informations, consultez Analyser les métriques avec l’Explorateur de métriques Azure Monitor.
Log Analytics, un outil du portail Azure qui vous permet d’interroger et d’analyser les données de journal en utilisant le langage de requête Kusto (KQL). Pour plus d’informations, voir Bien démarrer avec les requêtes de journal dans Azure Monitor.
Le journal d’activité, qui a une interface utilisateur dans le portail Azure pour la consultation et les recherches de base. Pour effectuer une analyse plus approfondie, vous devez router les données vers les journaux Azure Monitor et exécuter des requêtes plus complexes dans Log Analytics.
Les outils qui permettent une visualisation plus complexe sont notamment :
- Les tableaux de bord, qui vous permettent de combiner différentes sortes de données dans un même volet du portail Azure.
- Classeurs, rapports personnalisables que vous pouvez créer dans le portail Azure. Les workbooks peuvent inclure du texte, des métriques et des requêtes de journal.
- Grafana, un outil de plateforme ouvert, parfait pour les tableaux de bord opérationnels. Vous pouvez utiliser Grafana pour créer des tableaux de bord à partir de données de plusieurs sources autres qu’Azure Monitor.
- Power BI, un service d’analyse métier qui fournit des visualisations interactives pour diverses sources de données. Vous pouvez configurer Power BI pour importer automatiquement les données de journal à partir d’Azure Monitor afin de tirer parti de ces visualisations supplémentaires.
Outils d’exportation Azure Monitor
Vous pouvez extraire des données d’Azure Monitor dans d’autres outils en utilisant les méthodes suivantes :
Métriques : utilisez l’API REST pour les métriques pour extraire les données de métriques de la base de données de métriques Azure Monitor. L’API prend en charge les expressions de filtre pour affiner les données récupérées. Pour plus d’informations, consultez Informations de référence sur l’API REST Azure Monitor.
Journaux : utilisez l’API REST ou les bibliothèques de client associées.
Une autre option est l’exportation des données d’espace de travail.
Pour bien démarrer avec l’API REST pour Azure Monitor, consultez Procédure pas à pas de l’API REST d’analyse Azure.
Requêtes Kusto
Vous pouvez analyser les données de surveillance dans les journaux d'activité Azure Monitor ou le magasin Log Analytics en utilisant le langage de requête Kusto (KQL).
Important
Quand vous sélectionnez Journaux d’activité dans le menu du service dans le portail, Log Analytics s’ouvre avec l’étendue de requête définie sur le service actuel. Cette étendue signifie que les requêtes de journal ont seulement des données de ce type de ressource. Si vous voulez exécuter une requête qui comprend des données d’autres services Azure, sélectionnez Journaux dans le menu Azure Monitor. Pour plus d’informations, consultez Étendue de requête de journal et intervalle de temps dans la fonctionnalité Log Analytics d’Azure Monitor.
Pour obtenir la liste des requêtes courantes pour n’importe quel service, consultez l’Interface de requêtes Log Analytics.
Alertes
Azure Monitor vous alerte de façon proactive quand des conditions spécifiques sont détectées dans vos données de monitoring. Les alertes permettent d’identifier et de résoudre les problèmes affectant votre système avant que vos clients ne les remarquent. Pour plus d’informations, consultez Alertes Azure Monitor.
Il existe de nombreuses sources d’alertes courantes pour les ressources Azure. Pour obtenir des exemples d’alertes courantes pour les ressources Azure, consultez Exemples de requêtes d’alerte de journal. Le site Azure Monitor Baseline Alerts (AMBA) fournit une méthode semi-automatisée de mise en œuvre des alertes, des tableaux de bord et des recommandations concernant les métriques de plateforme. Le site s’applique à un sous-ensemble des services Azure en constante expansion, y compris tous les services qui font partie de la zone d’atterrissage Azure (ALZ).
Le schéma d’alerte commun standardise la consommation de notifications d'alerte pour Azure Monitor. Pour plus d’informations, consultez Schéma d’alerte courant.
Types d'alertes
Vous pouvez définir une alerte sur n’importe quelle source de données de métrique ou de journal dans la plateforme de données Azure Monitor. Il existe de nombreux types d’alertes différents en fonction des services que vous monitorez et des données de monitoring que vous collectez. Les différents types d’alertes ont divers avantages et inconvénients. Pour plus d’informations, consultez Choisir le bon type d’alerte de monitoring.
La liste suivante décrit les types d’alertes Azure Monitor que vous pouvez créer :
- Les alertes de métrique évaluent les métriques de ressource à intervalles réguliers. Les métriques peuvent être des métriques de plateforme, des métriques personnalisées, des journaux provenant d’Azure Monitor convertis en métriques ou des métriques Application Insights. Les alertes de métriques peuvent également appliquer plusieurs conditions et seuils dynamiques.
- Les alertes de journal permettent aux utilisateurs d’utiliser une requête Log Analytics pour évaluer les journaux de ressource à une fréquence prédéfinie.
- Les alertes de journal d’activité sont déclenchées quand un nouvel événement de journal d’activité correspond à des conditions définies. Les alertes Resource Health et les alertes Service Health sont des alertes de journal d’activité qui concernent l’intégrité de votre service et de vos ressources.
Certains services Azure prennent également en charge les alertes de détection intelligente, les alertes Prometheus ou les règles d’alerte recommandées.
Pour certains services, vous pouvez opérer une surveillance à grande échelle en appliquant la même règle d’alerte de métrique à plusieurs ressources du même type qui existent dans la même région Azure. Les notifications individuelles sont envoyées pour chaque ressource supervisée. Pour connaître les services et clouds Azure pris en charge, consultez Monitorer plusieurs ressources avec une seule règle d’alerte.
Remarque
Si vous créez ou exécutez une application qui s’exécute sur votre service, il est possible qu’Azure Monitor Application Insights vous propose d’autres types d’alertes.
Règles d’alerte de Virtual WAN
Vous pouvez définir des alertes pour n’importe quelle métrique, entrée de journal ou entrée de journal d’activité listée dans les Informations de référence sur les données de monitoring d’Azure Virtual WAN.
Analyse d'Azure Virtual WAN – Meilleures pratiques
Cet article présente les meilleures pratiques de configuration pour l'analyse de Virtual Wan et les différents composants qui peuvent être déployés avec ce dernier. Les recommandations présentées dans cet article sont principalement basées sur les mesures Azure Monitor existantes et les journaux générés par Azure Virtual WAN. Pour obtenir une liste des mesures et des journaux collectés pour Virtual WAN, reportez-vous à la référence des données d'analyse de Virtual WAN.
La plupart des recommandations dans cet article suggèrent la création d'alertes Azure Monitor. Les alertes Azure Monitor vous envoient des notifications de manière proactive quand il existe un événement important dans les données de monitoring. Ces informations vous aident à traiter la cause racine plus rapidement, et à réduire le temps d’arrêt. Pour savoir comment créer une alerte de métrique, reportez-vous à Tutoriel : créer une alerte de métrique pour une ressource Azure. Pour savoir comment créer une alerte de requête de journal, reportez-vous à Tutoriel : créer une alerte de requête de journal pour une ressource Azure.
Passerelles Virtual WAN
Cette section décrit les meilleures pratiques pour les passerelles Virtual WAN.
Passerelle VPN de site à site
Liste de vérification de conception – alertes de métrique
- Créez une règle d'alerte en cas d'augmentation du nombre de dépôts de paquets à la sortie et/ou à l'entrée du tunnel.
- Créez une règle d'alerte pour l'analyse de l'état du pair BGP.
- Créez une règle d'alerte pour analyser le nombre d'itinéraires BGP publiés et maîtrisés.
- Créez une règle d'alerte pour l'utilisation excessive de la passerelle VPN.
- Créez une règle d'alerte pour l'utilisation excessive du tunnel.
| Recommandation | Descriptif |
|---|---|
| Créez une règle d'alerte en cas d'augmentation du nombre de dépôts de paquets à la sortie et/ou à l'entrée du tunnel. | Une augmentation du nombre de dépôts de paquets à l’entrée et/ou à la sortie du tunnel peut indiquer un problème au niveau de la passerelle VPN Azure ou du périphérique VPN distant. Sélectionnez la métrique Nombre de paquets perdus en sortie/en entrée du tunnel au moment de la création de règles d’alerte. Définissez une valeur de seuil statique supérieure à 0 et le type d'agrégation Total lors de la configuration de la logique d'alerte. Vous pouvez choisir d'analyser la connexion dans son ensemble, ou de fractionner la règle d'alerte par instance et l'IP distant afin de recevoir une alerte pour les en cas de problèmes impliquant des tunnels individuels. Pour savoir quelle est la différence entre le concept de connexion VPN, le lien, et le tunnel dans le Virtual WAN, reportez-vous à la FAQ sur le Virtual WAN. |
| Créez une règle d'alerte pour l'analyse de l'état du pair BGP. | Lorsque vous utilisez BGP pour vos connexions de site à site, il est important d'analyser l'état des appairages BGP entre les instances de la passerelle et les appareils distants. En effet, des défaillances récurrentes peuvent perturber la connectivité. Sélectionnez la métrique État de pair BGP lors de la création de la règle d'alerte. En utilisant un seuil statique, choisissez le type d'agrégation Moyen et configurez l'alerte pour qu'elle soit déclenchée chaque fois que la valeur est inférieure à 1. Nous vous recommandons de fractionner l’alerte par instance et par adresse de pair BGP afin de détecter les problèmes liés aux appairages individuels. Évitez de sélectionner les IP de l'instance de passerelle comme adresse de pair BGP. En effet, cette métrique analyse l'état BGP pour toutes les combinaisons possibles, y compris avec l'instance elle-même (qui est toujours 0). |
| Créez une règle d'alerte pour analyser le nombre d'itinéraires BGP publiés et maîtrisés. |
Les itinéraires BGP publiés et itinéraires BGP appris analysent respectivement le nombre d'itinéraires publiés vers des pairs par la passerelle VPN et le nombre d'itinéraires appris de ces mêmes pairs par la passerelle VPN. Si ces mesures baissent au niveau zéro de manière inattendue, la raison peut être un problème au niveau de la passerelle ou du local. Nous vous recommandons de configurer une alerte pour ces deux métriques afin qu’elle soit déclenchée chaque fois que leur valeur est égale à zéro. Choisissez le type d'agrégation Total. Fractionnez par instance afin d'analyser les instances de passerelle individuelles. |
| Créez une règle d'alerte pour l'utilisation excessive de la passerelle VPN. | Le nombre d’unités d’échelle par instance détermine le débit agrégé d’une passerelle VPN. Tous les tunnels qui se terminent dans la même instance de passerelle partagent son débit agrégé. Il est probable que la stabilité du tunnel soit affectée si une instance fonctionne à pleine capacité pendant une longue période. Sélectionnez Bande passante S2S de passerelle lors de la création de la règle d’alerte. Configurez l’alerte pour qu’elle soit déclenchée chaque fois que le débit Moyen est supérieur à une valeur proche du débit agrégé maximal des deux instances. Vous pouvez également fractionner l’alerte par instance et utiliser le débit maximal par instance comme référence. Nous vous recommandons de déterminer les besoins en débit par tunnel à l’avance afin de choisir le nombre approprié d’unités d’échelle. Pour en savoir plus sur les valeurs d’unité d’échelle prises en charge pour les passerelles VPN site à site, consultez la FAQ sur Virtual WAN. |
| Créez une règle d'alerte pour l'utilisation excessive du tunnel. | Le débit maximal autorisé par tunnel est déterminé par le nombre d’unités d’échelle affectées à l’instance de passerelle où le tunnel se termine. Vous pouvez être alerté si un tunnel approche de son débit maximal, car cela peut poser des problèmes de performances et de connectivité. Agissez de manière proactive en investiguant la cause racine de l’augmentation de l’utilisation du tunnel, ou en augmentant le nombre d’unités d’échelle de la passerelle. Sélectionnez la bande passante du tunnel lors de la création de la règle d'alerte. Effectuez un fractionnement par Instance et par IP distante pour permettre un monitoring de tous les tunnels individuels, ou pour choisir des tunnels spécifiques à la place. Configurez l'alerte pour qu'elle soit déclenchée chaque fois que le débit moyen est supérieur à une valeur proche du débit maximal autorisé par tunnel. Pour en savoir plus sur l’impact des unités d’échelle de la passerelle sur le débit maximal d’un tunnel, consultez le FAQ sur Virtual WAN. |
Liste de vérification de conception – Alertes de requête de journal
Pour configurer les alertes relatives aux journaux, vous devez créer au préalable un paramètre de diagnostic pour votre passerelle VPN site à site/point à site. Un paramètre de diagnostic vous permet de définir les journaux et/ou les mesures que vous souhaitez collecter et la manière dont vous souhaitez stocker ces données pour analyse ultérieure. Contrairement aux métriques de passerelle, les journaux de passerelle ne sont pas disponibles si aucun paramètre de diagnostic n’est configuré. Pour savoir comment créer un paramètre de diagnostic, reportez-vous à Créer un paramètre de diagnostic pour afficher les journaux.
- Créez une règle d'alerte de déconnexion de tunnel.
- Créez une règle d'alerte de déconnexion de BGP.
| Recommandation | Descriptif |
|---|---|
| Créez une règle d'alerte de déconnexion de tunnel. |
Utilisez les journaux de diagnostic de tunnel pour suivre les événements de déconnexion dans vos connexions de site à site. Les causes possibles d'un événement de déconnexion sont une défaillance de négociation des SA, une absence de réponse du périphérique VPN distant, entre autres. Les journaux de diagnostic de tunnel indiquent également la raison de la déconnexion. Reportez-vous à Créer une règle d'alerte de déconnexion de tunnel – requête de journal en sous ce tableau pour sélectionner les événements de déconnexion lors de la création de la règle d'alerte. Configurez l’alerte pour qu’elle se déclenche chaque fois que le nombre de lignes résultant de l’exécution de la requête est supérieur à 0. Pour que cette alerte soit efficace, sélectionnez la granularité de l'agrégation et la fréquence d'évaluation tout en vous assurant qu'elles sont comprises respectivement entre 1 et 5 minutes. Ainsi, une fois l’intervalle Précision d’agrégation passé, le nombre de lignes est à nouveau égal à 0 pour un nouvel intervalle. Pour obtenir des conseils de résolution de problèmes lors de l'analyse des journaux de diagnostic de tunnel, reportez-vous à Résoudre des problèmes de la passerelle VPN Azure à l'aide des journaux de diagnostic. En outre, utilisez les journaux de diagnostic IKE pour compléter votre résolution des problèmes, car ces journaux contiennent des diagnostics détaillés spécifiques à l'IKE. |
| Créez une règle d'alerte de déconnexion de BGP. | Utilisez les journaux de diagnostic d'itinéraires pour suivre les mises à jour d'itinéraire et les problèmes liés aux sessions BGP. Des événements de déconnexion BGP répétés peuvent affecter la connectivité et provoquer des temps d’arrêt. Reportez-vous à Créer une règle d'alerte de déconnexion de BGP – requête de journal en sous ce tableau pour sélectionner les événements de déconnexion lors de la création de la règle d'alerte. Configurez l’alerte pour qu’elle se déclenche chaque fois que le nombre de lignes résultant de l’exécution de la requête est supérieur à 0. Pour que cette alerte soit efficace, sélectionnez la granularité de l'agrégation et la fréquence d'évaluation tout en vous assurant qu'elles sont comprises respectivement entre 1 et 5 minutes. Ainsi, une fois l’intervalle Précision d’agrégation passé, le nombre de lignes est à nouveau égal à 0 pour un nouvel intervalle, si les sessions BGP sont restaurées. Pour en savoir plus sur les données collectées par les journaux de diagnostic d'itinéraires, reportez-vous à Résolution des problèmes relatifs à la passerelle VPN Azure à l'aide des journaux de diagnostic. |
Requêtes dans les journaux
Créer une règle d'alerte de déconnexion de tunnel – requête de journal : la requête de journal suivante peut être utilisée pour sélectionner les événements de déconnexion de tunnel lors de la création de la règle d'alerte :
AzureDiagnostics | where Category == "TunnelDiagnosticLog" | where OperationName == "TunnelDisconnected"Créer une règle d'alerte de déconnexion de BGP – requête de journal : la requête de journal suivante peut être utilisée pour sélectionner les événements de déconnexion de BGP lors de la création de la règle d'alerte :
AzureDiagnostics | where Category == "RouteDiagnosticLog" | where OperationName == "BgpDisconnectedEvent"
Passerelle VPN de point à site
La section suivante fournit de plus amples informations sur la configuration des alertes basées sur les métriques uniquement. Toutefois, les passerelles de point à site Virtual WAN prennent également en charge les journaux de diagnostic. Pour en savoir plus sur les journaux de diagnostic disponibles pour les passerelles point à site, reportez-vous à Diagnostic des passerelles VPN point à site Virtual WAN.
Liste de vérification de conception – Alertes de métriques
- Créez une règle d'alerte pour l'utilisation excessive de la passerelle.
- Créez une alerte pour le nombre de connexions P2S qui s'approche de la limite.
- Créez une alerte pour le nombre d'itinéraires VPN utilisateur qui s'approche de la limite.
| Recommandation | Descriptif |
|---|---|
| Créez une règle d'alerte pour l'utilisation excessive de la passerelle. | Le nombre d’unités d’échelle configurées détermine la bande passante d’une passerelle point à site. Pour en savoir plus sur les unités d'échelle de passerelle point à site, reportez-vous à Point à site (VPN d'utilisateur). Utilisez la métrique de bande passante P2S de la passerelle pour effectuer un monitoring de l’utilisation de la passerelle, et configurer une règle d’alerte qui se déclenche chaque fois que la bande passante de la passerelle est supérieure à une valeur proche de son débit agrégé. Par exemple, si la passerelle a été configurée avec 2 unités d’échelle, elle a un débit agrégé de 1 Gbit/s. Dans ce cas, vous pouvez définir une valeur de seuil de 950 Mbits/s. Utilisez cette alerte pour rechercher de manière proactive la cause racine de l'augmentation de l'utilisation, et le cas échéant, augmenter le nombre d'unités d'échelle. Sélectionnez le type d'agrégation Moyen lors de la configuration de la règle d'alerte. |
| Créer une alerte pour le nombre de connexions P2S s'approchant de la limite | Le nombre maximum de connexions point à site autorisées dépend également du nombre d'unités d'échelle configurées sur la passerelle. Pour en savoir plus sur les unités d'échelle de passerelle point à site, reportez-vous à la FAQ relatives à Point à site (VPN d'utilisateur). Utilisez la métrique du nombre de connexion P2S pour l'analyse du nombre de connexions. Sélectionnez cette métrique pour configurer une règle d'alerte qui se déclenche chaque fois que le nombre de connexions s'approche du maximum autorisé. Par exemple, une passerelle d'une unité d'échelle 1 prend en charge jusqu'à 500 connexions simultanées. Dans ce cas, vous pouvez configurer l'alerte pour qu'elle soit déclenchée chaque fois que le nombre de connexions est supérieur à 450. Cette alerte permet de déterminer si une augmentation du nombre d'unités d'échelle est nécessaire ou non. Choisissez le type d'agrégation Total lors de la configuration de la règle d'alerte. |
| Créez une règle d'alerte pour le nombre d'itinéraires VPN utilisateur qui s'approche de la limite. | Le protocole utilisé détermine le nombre maximal d’itinéraires VPN utilisateur. IKEv2 a une limite de 255 itinéraires au niveau du protocole, alors qu’OpenVPN a une limite de 1 000 itinéraires. Pour en savoir plus, consultez Concepts de configuration du serveur VPN. Vous souhaiterez peut-être recevoir une alerte si vous êtes sur le point d’atteindre le nombre maximum d’itinéraires VPN d’utilisateur et agir de manière proactive afin d’éviter les temps d’arrêt. Utilisez le paramètre Nombre d’itinéraires VPN utilisateur pour effectuer un monitoring de cette situation, et configurer une règle d’alerte qui se déclenche chaque fois que le nombre d’itinéraires dépasse une valeur proche de la limite. Par exemple, si la limite est de 255 itinéraires, la valeur appropriée du seuil pourrait être 230. Choisissez le type d'agrégation Total lors de la configuration de la règle d'alerte. |
Passerelle ExpressRoute
La section suivante porte sur les alertes basées sur des métriques. En plus des alertes décrites ici, qui se concentrent sur le composant de passerelle, nous vous recommandons d’utiliser les métriques, journaux et outils disponibles pour effectuer un monitoring du circuit ExpressRoute. Pour en savoir plus sur l'analyse d'ExpressRoute, reportez-vous à Analyse, mesures et alertes d'ExpressRoute. Pour savoir comment utiliser l'outil ExpressRoute Traffic Collector, reportez-vous à Configurer ExpressRoute Traffic Collector pour ExpressRoute Direct.
Liste de vérification de conception – Alertes de métriques
- Créez une règle d’alerte pour les bits reçus par seconde.
- Créez la règle d'alerte pour l'utilisation excessive du processeur.
- Créez une règle d’alerte pour les paquets par seconde.
- Créez une règle d’alerte pour le nombre d’itinéraires publiés sur un pair.
- Règle d’alerte de comptage pour le nombre d’itinéraires appris d’un pair.
- Créez une règle d'alerte pour une fréquence élevée dans les changements d'itinéraire.
| Recommandation | Descriptif |
|---|---|
| Créez la règle d'alerte pour les bits reçus par seconde. |
Bits reçus par seconde permet d'analyser le volume total de trafic reçu par la passerelle en provenance des MSEE. Vous pouvez être alerté si le volume de trafic reçu par la passerelle risque d’atteindre son débit maximal. Cette situation peut entraîner des problèmes de performances et de connectivité. Cette approche vous permet d’agir de manière proactive en investiguant la cause racine de l’utilisation accrue de la passerelle, ou en augmentant le débit maximal autorisé de la passerelle. Lors de la configuration de la règle d'alerte, choisissez le type d'agrégation Moyen et une valeur de seuil proche du débit maximum approvisionné pour la passerelle. De plus, nous vous recommandons de définir une alerte lorsque le nombre de bits reçus par seconde avoisine zéro, car cela peut indiquer un problème au niveau de la passerelle ou des MSEE. Le nombre d’unités d’échelle approvisionnées détermine le débit maximal d’une passerelle ExpressRoute. Pour en savoir plus sur les performances des passerelles ExpressRoute, reportez-vous à À propos des connexions ExpressRoute dans Azure Virtual WAN. |
| Créez la règle d'alerte pour l'utilisation excessive du processeur. | Lorsque vous utilisez des passerelles ExpressRoute, il est important d'analyser l'utilisation du processeur. Une utilisation élevée et prolongée peut affecter les performances et la connectivité. Utilisez la métrique Utilisation du processeur pour effectuer un monitoring de l’utilisation, et créer une alerte chaque fois que l’utilisation du processeur est supérieure à 80 %, afin d’investiguer la cause racine, et d’augmenter le nombre d’unités d’échelle, le cas échéant. Choisissez le type d'agrégation Moyen lors de la configuration de la règle d'alerte. Pour en savoir plus sur les performances des passerelles ExpressRoute, reportez-vous à À propos des connexions ExpressRoute dans Azure Virtual WAN. |
| Créez une règle d'alerte pour les paquets reçus par seconde. |
Paquets par seconde permet d'analyser le nombre de paquets entrants qui traversent la passerelle ExpressRoute Virtual WAN. Vous souhaiterez peut-être recevoir une alerte si le nombre de paquets par seconde avoisine la limite autorisée pour le nombre d’unités d’échelle configurées sur la passerelle. Choisissez le type d'agrégation Moyen lors de la configuration de la règle d'alerte. Choisissez une valeur de seuil qui avoisine le nombre maximal de paquets par seconde autorisés en fonction du nombre d'unités d'échelle de la passerelle. Pour en savoir plus sur les performances d'ExpressRoute, reportez-vous à À propos des connexions ExpressRoute dans Azure Virtual WAN. De plus, nous vous recommandons de définir une alerte lorsque le nombre de paquets par seconde avoisine zéro, car cela peut indiquer un problème au niveau de la passerelle ou des MSEE. |
| Créez une règle d’alerte pour le nombre d’itinéraires publiés sur un pair. |
Le Nombre d’itinéraires publiés sur les pairs surveille le nombre d’itinéraires publiés à partir de la passerelle ExpressRoute sur le routeur de hub virtuel et les appareils Microsoft Enterprise Edge. Nous vous recommandons d’ajouter un filtre pour sélectionner uniquement les deux homologues BGP affichés en tant que périphérique ExpressRoute et de créer une alerte pour identifier quand le nombre d’itinéraires annoncés approche de la limite documentée de 1 000. Par exemple, configurez l’alerte pour qu’elle soit déclenchée lorsque le nombre d’itinéraires publiés est supérieur à 950. Nous vous recommandons également de configurer une alerte lorsque le nombre d’itinéraires publiés sur les appareils Microsoft Edge est égal à zéro afin de détecter de manière proactive tout problème de connectivité. Pour ajouter ces alertes, sélectionnez la métrique Nombre d’itinéraires publiés sur les pairs, puis sélectionnez l’option Ajouter un filtre et les appareils ExpressRoute. |
| Créez une règle d’alerte pour le nombre d’itinéraires appris d’un pair. |
Le Nombre d’itinéraires appris des pairs surveille le nombre d’itinéraires que la passerelle ExpressRoute apprend du routeur de hub virtuel et de l’appareil Microsoft Enterprise Edge. Nous vous recommandons d’ajouter un filtre pour sélectionner uniquement les deux homologues BGP affichés en tant que périphérique ExpressRoute et de créer une alerte pour identifier lorsque le nombre d’itinéraires appris approche de la limite documentée de 4 000 pour les circuits SKU Standard et de 10 000 pour les circuits SKU Premium. Nous vous recommandons également de configurer une alerte lorsque le nombre d’itinéraires publiés sur les appareils Microsoft Edge est égal à zéro. Cette approche peut vous aider à détecter le moment où votre environnement local cesse de publier les itinéraires. |
| Créez une règle d'alerte pour une fréquence élevée dans les changements d'itinéraire. |
La fréquence des changements d'itinéraires indique la fréquence de changements des itinéraires appris et publiés depuis des pairs et vers ces mêmes pairs, y compris d'autres types de branches comme le VPN site à site et le VPN point à site. Cette métrique fournit une visibilité lorsqu'une nouvelle branche ou plusieurs circuits sont connectés/déconnectés. Cette métrique est un outil utile qui permet d'identifier les problèmes relatifs aux publications BGP, comme les défaillances. Nous vous recommandons de définir une alerte si l’environnement est statique et que des changements BGP ne sont pas attendus. Sélectionnez une valeur de seuilsupérieure à 1 et une granularité d'agrégation de 15 minutes pour analyser de manière cohérente le comportement de BGP. Si l’environnement est dynamique et que des changements de BGP sont fréquemment attendus, vous pouvez choisir de ne pas définir d’alerte afin d’éviter les faux positifs. Toutefois, vous pouvez toujours prendre en compte cette métrique pour l'observabilité de votre réseau. |
Hub virtuel
La section suivante se concentre sur les alertes basées sur des métriques pour les hubs virtuels.
Liste de vérification de conception – Alertes de métriques
- Créer une règle d’alerte pour l’état des homologues BGP
| Recommandation | Descriptif |
|---|---|
| Créez une règle d'alerte pour l'analyse de l'état du pair BGP. | Sélectionnez la métrique État de pair BGP lors de la création de la règle d'alerte. En utilisant un seuil statique, choisissez le type d'agrégation Moyen et configurez l'alerte pour qu'elle soit déclenchée chaque fois que la valeur est inférieure à 1. Cette approche vous permet d’identifier les moments où le routeur du hub virtuel rencontre des problèmes de connectivité avec les passerelles ExpressRoute, de VPN site à site et de VPN point à site déployées dans le hub. |
Pare-feu Azure
Cette section de l'article porte sur les alertes de métriques. Le pare-feu Azure propose une liste complète de mesures et journaux à des fins d'analyse. En plus de la configuration des alertes décrites dans la section suivante, découvrez comment le Classeur Pare-feu Azure peut vous aider à effectuer un monitoring de votre service Pare-feu Azure. Découvrez également les avantages de la connexion des journaux du Pare-feu Azure à Microsoft Sentinel à l’aide du Connecteur du Pare-feu Azure pour Microsoft Sentinel.
Liste de vérification de conception – Alertes de métriques
- Créez une règle d'alerte pour le risque d'épuisement de ports SNAT.
- Créez une règle d'alerte pour l'utilisation excessive du pare-feu.
| Recommandation | Descriptif |
|---|---|
| Créez une règle d'alerte pour le risque d'épuisement de ports SNAT. | Pare-feu Azure fournit 2 496 ports SNAT par adresse IP publique configurée par instance d'échelle de machine virtuelle dorsale. Il est important d’estimer à l’avance le nombre de ports SNAT qui peuvent répondre aux besoins de votre organisation pour le trafic sortant vers Internet. Si vous ne le faites pas, vous risquez d'épuiser le nombre de ports SNAT disponibles sur Pare-feu Azure, ce qui peut entraîner des défaillances de la connectivité sortante. La métrique de l'utilisation des ports SNAT permet d'analyser le pourcentage de ports SNAT sortants en cours d'utilisation. Créez une règle d’alerte pour que cette métrique se déclenche chaque fois que ce pourcentage dépasse 95 % (à la suite d’une augmentation imprévue du trafic, par exemple). Ainsi, vous pourrez agir de manière appropriée en configurant une autre adresse IP publique sur le Pare-feu Azure, ou en utilisant à la place une instance d’Azure NAT Gateway. Utilisez le type d'agrégation Maximal lors de la configuration de la règle d'alerte. Pour en savoir plus sur l'interprétation de la métrique de l'utilisation de port SNAT, reportez-vous à Vue d'ensemble des journaux et des mesures de Pare-feu Azure. Pour en savoir plus sur la mise à l'échelle des ports SNAT dans Pare-feu Azure, reportez-vous à Mise à l'échelle des ports SNAT avec NAT Gateway Azure. |
| Créez une règle d'alerte pour l'utilisation excessive du pare-feu. | Le débit maximal de Pare-feu Azure varie en fonction de SKU et des caractéristiques activées. Pour en savoir plus sur les performances du Pare-feu Azure, consultez Performances du Pare-feu Azure. Vous pouvez être alerté si votre pare-feu approche de son débit maximal. Vous pouvez résoudre la cause sous-jacente, car cette situation est susceptible d’affecter les performances du pare-feu. Créez une règle d’alerte qui se déclenche chaque fois que la métrique Débit dépasse une valeur proche du débit maximal du pare-feu. Si le débit maximal est de 30 Gbit/s, configurez 25 Gbit/s en tant que valeur Seuil, par exemple. L’unité métrique du débit est bit/sec. Choisissez le type d’agrégation Moyen lors de la création de la règle d’alerte. |
Alertes Resource Health
Vous pouvez également configurer des Alertes Resource Health via Service Health pour les ressources ci-dessous. Avec cette approche, vous avez la garantie d’être informé sur la disponibilité de votre environnement Virtual WAN. Les alertes vous permettent de déterminer si les problèmes réseau sont dus au fait que vos ressources Azure entrent dans un état non sain, ou au contraire à des défaillances liées à votre environnement local. Nous vous recommandons de configurer des alertes quand l’état de la ressource se dégrade ou n’est plus disponible. Si l’état de la ressource devient dégradé/indisponible, vous pouvez analyser s’il y a eu des pics dans le trafic récent traité par ces ressources, les itinéraires annoncés vers ces ressources ou le nombre de connexions créées entre branches et réseaux virtuels. Pour plus d’informations sur les limites prises en charge dans Virtual WAN, consultez Limites d’Azure Virtual WAN.
- Microsoft.Network/vpnGateways
- Microsoft.Network/expressRouteGateways
- Microsoft.Network/azureFirewalls
- Microsoft.Network/virtualHubs
- Microsoft.Network/p2sVpnGateways
Contenu connexe
- Consultez Informations de référence sur les données de monitoring d’Azure Virtual WAN pour obtenir des informations de référence sur les métriques, les journaux et d’autres valeurs importantes créées pour Virtual WAN.
- Pour obtenir des informations générales sur la supervision des ressources Azure, consultez Supervision de ressources Azure avec Azure Monitor.