Stockage vectoriel dans Recherche Azure AI
Recherche Azure AI fournit un stockage vectoriel et des configurations pour la recherche vectorielle et les recherches hybrides. La prise en charge est implémentée au niveau du champ, ce qui signifie que vous pouvez combiner des champs vectoriels et non vectoriels dans le même corpus de recherche.
Les vecteurs sont stockés dans un index de recherche. Pour créer le magasin de vecteurs, utilisez la Création d’une API REST d’index ou une méthode de KIT de développement logiciel (SDK) Azure équivalente.
Les éléments à prendre en compte pour le stockage vectoriel sont les suivants :
- Concevez un schéma pour répondre à votre cas d’usage en fonction du modèle de récupération de vecteur prévu.
- Estimer la taille de l’index et vérifier la capacité du service de recherche.
- Gérer un magasin vectoriel
- Sécuriser un magasin vectoriel
Modèles de récupération de vecteurs
Dans Azure AI Search, il existe deux modèles pour travailler avec les résultats de recherche.
Recherche générative. Les modèles de langage formulent une réponse à la requête de l’utilisateur en utilisant les données de Recherche Azure AI. Ce modèle inclut une couche d’orchestration pour coordonner les invites et gérer le contexte. Dans ce modèle, les résultats de recherche sont alimentés en flux d’invite, reçus par des modèles de conversation tels que GPT et Text-Davinci. Cette approche est basée sur RAG (Génération Augmentée de Récupération) , où l’index de recherche fournit les données de base.
Recherche classique à l’aide d’une barre de recherche, d’une chaîne d’entrée de requête et de résultats rendus. Le moteur de recherche accepte et exécute la requête vectorielle, formule une réponse et vous affichez ces résultats dans une application cliente. Dans Recherche IA Azure, les résultats sont retournés dans un ensemble de lignes aplatis, et vous pouvez choisir les champs à inclure dans les résultats de recherche. Étant donné qu’il n’existe aucun modèle de conversation, il est prévu que vous remplissiez le magasin vectoriel (index de recherche) avec du contenu non-vecteur lisible par l’homme dans votre réponse. Bien que le moteur de recherche corresponde sur des vecteurs, vous devez utiliser des valeurs non-vecteurs pour remplir les résultats de la recherche. Les requêtes vectorielles et les requêtes hybrides couvrent les types de requêtes que vous pouvez formuler pour les scénarios de recherche classiques.
Votre schéma d’index doit refléter votre cas d’usage principal. La section suivante met en évidence les différences de composition de champ pour les solutions conçues pour l’IA générative ou la recherche classique.
Schéma d’un magasin de vecteurs
Un schéma d’index pour un magasin de vecteurs nécessite un nom, un champ clé (chaîne), un ou plusieurs champs vectoriels et une configuration vectorielle. Nous recommandons d’utiliser des champs non vectoriels pour les requêtes hybrides ou pour renvoyer un contenu textuel lisible par l’homme sans passer par un modèle de langage. Pour obtenir des instructions sur la configuration de vecteurs, consultez Créer un magasin de vecteurs.
Configuration de base du champ vectoriel
Les champs vectoriels sont distingués par leur type de données et leurs propriétés spécifiques au vecteur. Voici à quoi ressemble un champ vectoriel dans une collection de champs :
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Les champs vectoriels ont des types de données spécifiques. Actuellement, Collection(Edm.Single) est le plus courant, mais l’utilisation de types de données étroits peut vous permettre d’économiser du stockage.
Les champs vectoriels doivent pouvoir être recherchés et récupérés, mais ils ne peuvent pas être filtrables, facettables ou triables, ni disposer d'analyseurs, de normalisateurs ou d'affectations de cartes de synonymes.
Les champs vectoriels doivent avoir dimensions défini sur le nombre d’incorporations générées par le modèle d’incorporation. Par exemple, l’incorporation de texte-ada-002 génère 1 536 incorporations pour chaque bloc de texte.
Les champs vectoriels sont indexés à l’aide d’algorithmes indiqués par un profil de recherche vectorielle, qui est défini ailleurs dans l’index et ne s’affiche donc pas dans l’exemple. Pour plus d’informations, consultez configuration de recherche vectorielle.
Collection de champs pour les charges de travail vectorielles de base
Les magasins de vecteurs nécessitent davantage de champs en plus des champs vectoriels. Par exemple, un champ clé ("id" dans cet exemple) est une exigence d’index.
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
D’autres champs, tels que le champ "content" fournissent l’équivalent lisible par l’homme du champ "content_vector" . Si vous utilisez exclusivement des modèles de langage pour la formulation de réponse, vous pouvez omettre les champs de contenu non-vecteur, mais les solutions qui envoie (push) les résultats de recherche directement aux applications clientes doivent avoir du contenu non-vecteur.
Les champs de métadonnées sont utiles pour les filtres, en particulier si les métadonnées contiennent des informations sur l’origine du document source. Vous ne pouvez pas filtrer directement sur un champ vectoriel, mais vous pouvez définir des modes de préfiltrage ou de postfiltrage pour filtrer avant ou après l’exécution de la requête vectorielle.
Schéma généré par l’Assistant Importation et vectorisation des données
Pour l’évaluation et les tests de preuve de concept, nous recommandons d’utiliser Assistant Importation et vectorisation des données. L’assistant génère l’exemple de schéma présenté dans cette section.
Le parti pris de ce schéma est que les documents de recherche sont construits autour de blocs de données. Si un modèle de langage formule la réponse, comme c’est le cas pour les applications RAG, vous devez disposer d’un schéma conçu autour des blocs de données.
Il est nécessaire de segmenter les données pour rester dans les limites d’entrée des modèles de langage, mais cela permet également d’améliorer la précision de la recherche par similarité lorsque les requêtes peuvent être comparées à de plus petits blocs de contenu tirés de plusieurs documents parents. Enfin, si vous utilisez le classeur sémantique, celui-ci a également des limites de jetons, qui sont plus facilement respectées si la segmentation des données fait partie de votre approche.
Dans l’exemple suivant, pour chaque document recherché, il y a un ID de bloc, un bloc, un titre et un champ vectoriel. L’ID de bloc chunkID et l’ID de parent sont renseignés par l’assistant, en utilisant l’encodage base 64 des métadonnées d’objet blob (chemin d’accès). Le bloc et le titre sont dérivés du contenu et du nom de l’objet blob. Seul le champ vectoriel est entièrement généré. Il s’agit de la version vectorisée du champ segment. Les incorporations sont générées en appelant un modèle d’incorporation Azure OpenAI que vous fournissez.
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Schéma pour les applications de type RAG et chat
Si vous concevez un stockage pour la recherche générative, vous pouvez créer des index distincts pour le contenu statique que vous avez indexé et vectorisé, et un deuxième index pour les conversations qui peuvent être utilisées dans les flux d’invite. Les index suivants sont créés à partir de l’accélérateur chat-with-your-data-solution-accelerator .
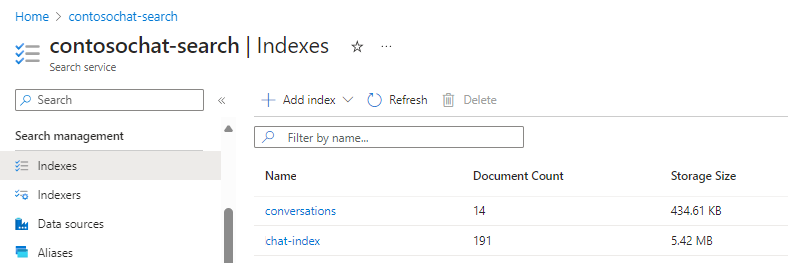
Champs de l’index de conversation qui prennent en charge l’expérience de recherche générative :
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Champs de l’index des conversations qui prennent en charge l’orchestration et l’historique des conversations :
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
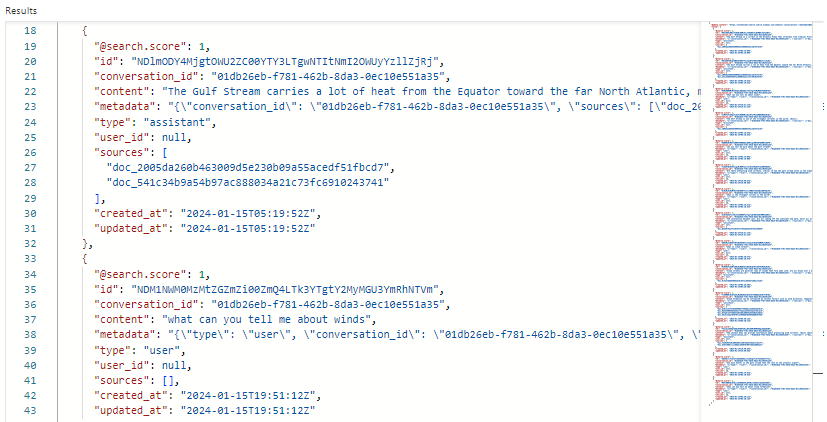
Voici une capture d’écran montrant les résultats de recherche dans l’Explorateur de recherche pour l’index des conversations. Le score de recherche est 1,00, car la recherche n’a pas été qualifiée. Notez les champs qui existent pour prendre en charge l’orchestration et les flux d’invite. Un ID de conversation identifie une conversation spécifique. "type" indique si le contenu provient de l’utilisateur ou de l’Assistant. Les dates sont utilisées pour classer les conversations de l’historique.
Structure et taille physiques
Dans la recherche Azure AI, la structure physique d’un index est en grande partie une implémentation interne. Vous pouvez accéder à son schéma, charger et interroger son contenu, surveiller sa taille et en gérer la capacité, mais les clusters eux-mêmes (index vectoriels et inversés) ainsi que les autres fichiers et dossiers sont gérés en interne par Microsoft.
La taille et la substance d’un index sont déterminées par :
- Quantité et composition de vos documents
- Les attributs sur des champs individuels. Par exemple, davantage de stockage est nécessaire pour les champs filtrables.
- Configuration d’index, y compris la configuration vectorielle qui spécifie la façon dont les structures de navigation internes sont créées en fonction du choix de HNSW ou un KNN exhaustif pour la recherche de similarité.
Azure AI Search impose des limites sur le stockage vectoriel, ce qui permet de maintenir un système équilibré et stable pour toutes les charges de travail. Pour vous aider à rester dans les limites, l’utilisation des vecteurs est suivie et signalée séparément dans le portail Azure, et par programmation par le biais des statistiques de service et d’index.
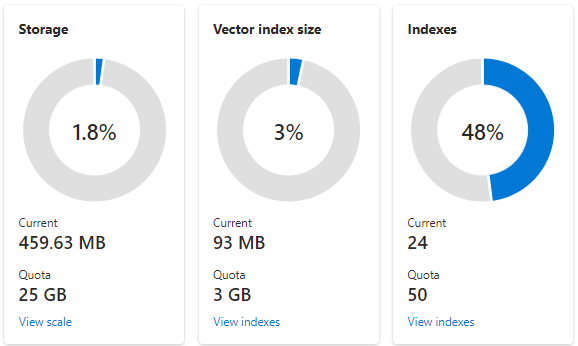
La capture d’écran suivante montre un service S1 configuré avec une partition et un réplica. Ce service particulier a 24 index de petite taille, avec un champ vecteur en moyenne, chaque champ composé de 1536 incorporations. La deuxième vignette affiche le quota et l’utilisation des index vectoriels. Un index vectoriel est une structure de données interne créée pour chaque champ vectoriel. Par conséquent, le stockage pour les index vectoriels est toujours une fraction du stockage utilisé par l’index global. D’autres champs non vectoriels et structure de données consomment le reste.
Les limites et les estimations de l’index vectoriel sont abordées dans un autre article, mais deux points pour mettre l’accent sur le haut est que le stockage maximal varie selon le niveau de service, et également par le moment où le service de recherche a été créé. Les services de même niveau plus récents ont beaucoup plus de capacité pour les index vectoriels. Pour ces raisons, effectuez les actions suivantes :
Vérifiez la date de déploiement de votre service de recherche. S’il a été créé avant le 3 avril 2024, envisagez de créer un nouveau service de recherche pour une plus grande capacité.
Choisissez un niveau évolutif si vous prévoyez des fluctuations dans les exigences de stockage vectoriel. Le niveau de base est fixé à une partition dans les anciens services de recherche. Pensez au niveau Standard 1 (S1) et aux niveaux supérieurs pour gagner en flexibilité et obtenir des performances plus rapides. Vous pouvez également créer un service de recherche qui utilise des limites supérieures et plus de partitions à chaque niveau nillable.
Opérations de base et interaction
Cette section présente les opérations de temps d’exécution vectorielles, notamment la connexion à un seul index et la sécurisation d’un seul index.
Remarque
Lors de la gestion d’un index, sachez qu’il n’existe pas de prise en charge de portail ou d’API pour le déplacement ou la copie d’un index. Au lieu de cela, les clients pointent généralement leur solution de déploiement d’applications sur un service de recherche différent (si vous utilisez le même nom d’index), ou modifient le nom pour créer une copie sur le service de recherche actuel, puis le générer.
Disponible en continu
Un index est immédiatement disponible pour les requêtes dès que le premier document est indexé, mais ne sera pas entièrement opérationnel tant que tous les documents ne seront pas indexés. En interne, un index est distribué entre les partitions et s’exécute sur des réplicas. L’index physique est géré en interne. L’index logique est géré par vous.
Un index est disponible en continu, sans possibilité de suspension ou de mise hors connexion. Étant donné qu’il est conçu pour une opération continue, les mises à jour de son contenu, ou les ajouts à l’index lui-même, se produisent en temps réel. Par conséquent, les requêtes peuvent retourner temporairement des résultats incomplets si une demande coïncide avec une mise à jour de document.
Notez que la continuité des requêtes existe pour les opérations de document (actualisation ou suppression) et pour les modifications qui n’ont pas d’impact sur la structure et l’intégrité existantes de l’index actuel (comme l’ajout de nouveaux champs). Si vous devez effectuer des mises à jour structurelles (en modifiant des champs existants), elles sont généralement gérées à l’aide d’un flux de travail de suppression et de recréation dans un environnement de développement, ou en créant une nouvelle version de l’index sur le service de production.
Pour éviter une regénération d’index, certains clients qui effectuent de petites modifications choisissent de « créer une version » d’un champ en en créant un qui coexiste avec une version précédente. Au fil du temps, cela se traduit par un contenu orphelin sous la forme de champs obsolètes ou de définitions d’analyseur personnalisé obsolètes, en particulier dans un index de production qui est coûteux à répliquer. Vous pouvez résoudre ces problèmes sur les mises à jour planifiées de l’index dans le cadre de la gestion du cycle de vie des index.
Connexion de point de terminaison
Toutes les demandes d’indexation et de requête vectorielles ciblent un index. Les points de terminaison sont généralement l’un des suivants :
| Point de terminaison | Connexion et contrôle d’accès |
|---|---|
<your-service>.search.windows.net/indexes |
Cible la collection d’index. Utilisé lors de la création, de la liste ou de la suppression d’un index. Des droits d’administrateur sont nécessaires pour ces opérations, disponibles par le biais de clés d’API d’administration ou d’un rôle de contributeur de recherche. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Cible la collection documents d’un index unique. Utilisé lors de l’interrogation d’un index ou de l’actualisation des données. Pour les requêtes, les droits de lecture sont suffisants et disponibles par le biais de clés d’API de requête ou d’un rôle de lecteur de données. Pour l’actualisation des données, des droits d’administrateur sont nécessaires. |
Comment se connecter à Recherche Azure AI
Vérifiez que vous disposez des autorisations ou d’une clé d’accès API . Sauf si vous interrogez un index existant, vous avez besoin de droits d’administrateur ou d’une attribution de rôle contributeur pour gérer et afficher du contenu sur un service de recherche.
Démarrez avec le portail Azure. La personne qui a créé le service de recherche peut afficher et gérer le service de recherche, y compris accorder l’accès à d’autres personnes via la page contrôle d’accès (IAM).
Passez à d’autres clients pour l’accès par programmation. Nous vous recommandons les guides de démarrage rapide et les exemples pour les premières étapes :
Accès sécurisé aux données vectorielles
Azure AI Search implémente le chiffrement des données, les connexions privées pour les scénarios sans Internet et les attributions de rôles pour un accès sécurisé via Microsoft Entra ID. La gamme complète de fonctionnalités de sécurité d’entreprise est décrite dans Sécurité dans Azure AI Search.
Gérer les magasins vectoriels
Azure fournit une plateforme de monitoring qui inclut la journalisation et les alertes de diagnostic. Nous vous recommandons d'appliquer les méthodes conseillées ci-dessous :
- Activer la journalisation des diagnostics
- Configurer des alertes
- Analyser les performances des requêtes et des index