Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit comment utiliser l’activité de copie dans Azure Data Factory pour copier des données à partir d’une base de données Amazon RDS for Oracle. Il s’appuie sur la vue d’ensemble de l’activité de copie.
Important
Le connecteur Amazon RDS pour Oracle version 2.0 fournit un support natif amélioré pour Amazon RDS pour Oracle. Si vous utilisez Amazon RDS pour le connecteur Oracle version 1.0 dans votre solution, mettez à niveau le connecteur Amazon RDS pour Oracle avant le 31 octobre 2025. Pour plus de détails sur les différences entre la version 2.0 et la version 1.0, reportez-vous à cette section.
Fonctionnalités prises en charge
Ce connecteur Amazon RDS for Oracle est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/-) | (1) (2) |
| Activité de recherche | (1) (2) |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Pour obtenir la liste des banques de données prises en charge en tant que sources ou récepteurs par l’activité de copie, consultez le tableau banques de données prises en charge.
Plus précisément, ce connecteur Amazon RDS for Oracle prend en charge :
- Les versions suivantes d’une base de données Amazon RDS pour Oracle pour la version 2.0 :
- Amazon RDS pour Oracle 19c ou version ultérieure
- Les versions suivantes d’une base de données Amazon RDS pour Oracle pour la version 1.0 :
- Amazon RDS for Oracle 19c R1 (19.1) et versions ultérieures
- Amazon RDS for Oracle 18c R1 (18.1) et versions ultérieures
- Amazon RDS for Oracle 12c R1 (12.1) et versions ultérieures
- Amazon RDS for Oracle 11g R1 (11.1) et versions ultérieures
- La copie parallèle à partir d’une source Amazon RDS for Oracle Pour plus d’informations, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle.
Notes
Le serveur proxy Amazon RDS for Oracle n’est pas pris en charge.
Prérequis
Si votre magasin de données se trouve dans un réseau local, un réseau virtuel Azure ou un cloud privé virtuel Amazon, vous devez configurer un runtime d’intégration auto-hébergé pour vous y connecter.
Si votre magasin de données est un service de données cloud managé, vous pouvez utiliser Azure Integration Runtime. Si l’accès est limité aux adresses IP qui sont approuvées dans les règles de pare-feu, vous pouvez ajouter les adresses IP Azure Integration Runtime dans la liste d’autorisation.
Vous pouvez également utiliser la fonctionnalité de runtime d’intégration de réseau virtuel managé dans Azure Data Factory pour accéder au réseau local sans installer et configurer un runtime d’intégration auto-hébergé.
Pour plus d’informations sur les mécanismes de sécurité réseau et les options pris en charge par Data Factory, consultez Stratégies d’accès aux données.
Le runtime d’intégration intègre un pilote Amazon RDS for Oracle. Par conséquent, vous n’avez pas besoin d’installer manuellement un pilote pour copier des données à partir d’Amazon RDS for Oracle.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Amazon RDS for Oracle à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Amazon RDS for Oracle dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Amazon RDS for Oracle et sélectionnez le connecteur Amazon RDS for Oracle.
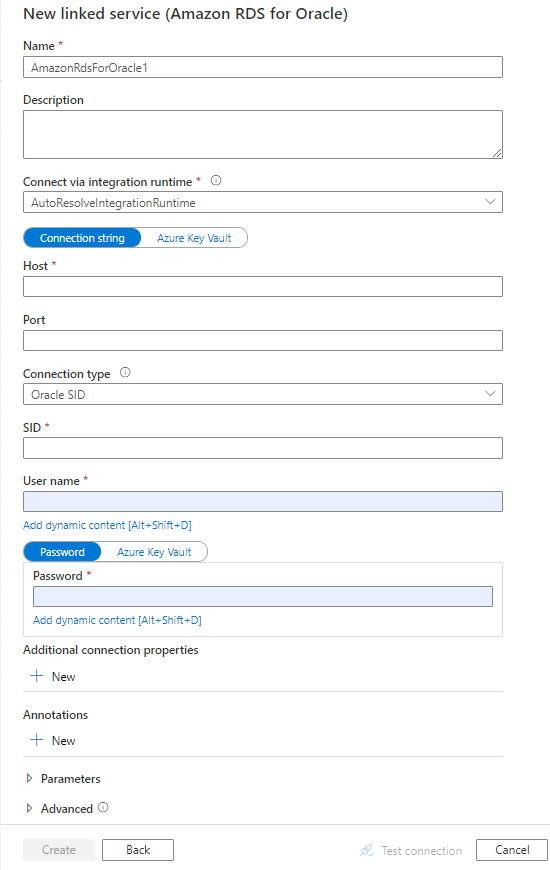
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
Détails de configuration du connecteur
Les sections suivantes fournissent des informations sur les propriétés utilisées pour définir les entités spécifiques du connecteur Amazon RDS for Oracle.
Propriétés du service lié
Le connecteur Amazon RDS pour Oracle version 2.0 prend en charge TLS 1.3. Reportez-vous à cette section pour mettre à niveau votre version du connecteur Amazon RDS pour Oracle à partir de la version 1.0. Pour plus d’informations sur la propriété, consultez les sections correspondantes.
Version 2.0
Le service lié Amazon RDS pour Oracle prend en charge les propriétés suivantes lors de l’application de la version 2.0 :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonRdsForOracle. | Oui |
| Version | Version que vous spécifiez. La valeur est 2.0. |
Oui |
| serveur | Emplacement de la base de données Amazon RDS pour Oracle auquel vous souhaitez vous connecter. Vous pouvez faire référence à la configuration des propriétés du serveur pour la spécifier. | Oui |
| type d'authentification | Type d’authentification pour la connexion à la base de données Amazon RDS pour Oracle. Seule l’authentification de base est prise en charge maintenant. | Oui |
| nom d'utilisateur | Nom d’utilisateur de la base de données Amazon RDS pour Oracle. | Oui |
| mot de passe | Mot de passe de la base de données Amazon RDS pour Oracle. Marquez ce champ comme SecureString pour le stocker en toute sécurité. Vous pouvez également référencer un secret stocké dans Azure Key Vault. | Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Plus de propriétés de connexion que vous pouvez définir dans le service lié en fonction de votre cas :
| Propriété | Descriptif | Obligatoire | Valeur par défaut |
|---|---|---|---|
| client de chiffrement | Spécifie le comportement du client de chiffrement. Les valeurs prises en charge sont accepted, , rejectedrequestedou required. Type : chaîne |
Non | required |
| encryptionTypesClient | Spécifie les algorithmes de chiffrement que le client peut utiliser. Les valeurs prises en charge sont AES128, , AES192AES256, 3DES112, 3DES168. Type : chaîne |
Non | (AES256) |
| cryptoChecksumClient | Spécifie le comportement d’intégrité des données souhaité lorsque ce client se connecte à un serveur. Les valeurs prises en charge sont accepted, , rejectedrequestedou required. Type : chaîne |
Non | required |
| cryptoChecksumTypesClient | Spécifie les algorithmes de somme de contrôle de chiffrement que le client peut utiliser. Les valeurs prises en charge sont SHA1, , SHA256SHA384, SHA512. Type : chaîne |
Non | (SHA512) |
| initialLobFetchSize | Spécifie la quantité que la source récupère initialement pour les colonnes LOB. Type : int | Non | 0 |
| fetchSize | Spécifie le nombre d’octets que le pilote alloue pour extraire les données dans un aller-retour de base de données. Type : int | Non | 10 Mo |
| statementCacheSize | Spécifie le nombre de curseurs ou d’instructions à mettre en cache pour chaque connexion de base de données. Type : int | Non | 0 |
| initializationString | Spécifie une commande qui est émise immédiatement après la connexion à la base de données pour gérer les paramètres de session. Type : chaîne | Non | zéro |
| enableBulkLoad | Spécifie s’il faut utiliser la copie en bloc ou l’insertion par lot lors du chargement de données dans la base de données. Type : booléen | Non | vrai |
| supportV1DataTypes | Spécifie s’il faut utiliser les mappages de types de données version 1.0. Ne définissez pas cette valeur sur true, sauf si vous souhaitez conserver la compatibilité descendante avec les mappages de types de données de la version 1.0. Type : booléen | Non, cette propriété est destinée à une utilisation de compatibilité descendante uniquement | faux |
| fetchTswtzAsTimestamp | Spécifie si le pilote retourne une valeur de colonne avec le type de données TIMESTAMP WITH TIME ZONE en tant que DateTime ou chaîne. Ce paramètre est ignoré si supportV1DataTypes n’est pas vrai. Type : booléen | Non, cette propriété est destinée à une utilisation de compatibilité descendante uniquement | vrai |
Exemple :
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"username": "<user name>",
"password": "<password>",
"authenticationType": "<authentication type>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : stockage du mot de passe dans Azure Key Vault
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"username": "<user name>",
"authenticationType": "<authentication type>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Configuration de propriété server
Pour server la propriété, vous pouvez la spécifier dans l’un des trois formats suivants :
| Format | Exemple : |
|---|---|
| Connecter le descripteur | (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=sales.us.acme.com))) |
| Dénomination Easy Connect (Plus) | salesserver1:1521/sales.us.example.com |
| Nom Oracle Net Services (alias TNS) ( uniquement pour le runtime d’intégration auto-hébergé) | ventes |
La liste suivante montre les paramètres pris en charge utilisés dans server. Si vous utilisez des paramètres qui ne figurent pas dans la liste suivante, votre connexion échoue.
Lors de l’utilisation du runtime d’intégration Azure :
HÔTE
PORT
PROTOCOLE
SERVICE_NAME
SID
INSTANCE_NAME
SERVEUR
CONNECT_TIMEOUT
RETRY_COUNT
Délai de nouvelle tentative
SSL_VERSION
SSL_SERVER_DN_MATCH
SSL_SERVER_CERT_DNLors de l’utilisation du runtime d’intégration auto-hébergé :
HÔTE
PORT
PROTOCOLE
ACTIVER
TEMPS_D'EXPIRATION
BASCULEMENT
Équilibrage de charge
RECV_BUF_SIZE
Service de Documentation Universitaire
SEND_BUF_SIZE
SOURCE_ROUTE
Type de Service
COLOCATION_TAG
CONNECTION_ID_PREFIX
FAILOVER_MODE
GLOBAL_NAME
HS
INSTANCE_NAME
LIMITE_DE_LA_PISCINE
POOL_CONNECTION_CLASS
NOM_DE_PISCINE
Pureté de la Piscine
BASE DE DONNÉES RDB
SHARDING_KEY
SHARDING_KEY_ID
SUPER_SHARDING_KEY
SERVEUR
SERVICE_NAME
SID
TUNNEL_SERVICE_NAME
Authentification du Client SSL
SSL_CERTIFICATE_ALIAS
SSL_CERTIFICATE_THUMBPRINT (Empreinte numérique du certificat SSL)
SSL_VERSION
SSL_SERVER_DN_MATCH
SSL_SERVER_CERT_DN
WALLET_LOCATION
CONNECT_TIMEOUT
RETRY_COUNT
Délai de nouvelle tentative
TRANSPORT_CONNECT_TIMEOUT
RECV_TIMEOUT
COMPRESSION
NIVEAUX_DE_COMPRESSION
Version 1.0
Le service lié Amazon RDS pour Oracle prend en charge les propriétés suivantes lors de l’application de la version 1.0 :
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur AmazonRdsForOracle. | Oui |
| connectionString | Spécifie les informations requises pour se connecter à l’instance de base de données Amazon RDS for Oracle. Vous pouvez également définir un mot de passe dans Azure Key Vault et extraire la configuration password de la chaîne de connexion. Pour plus d’informations, reportez-vous aux exemples suivants et à Stocker des informations d’identification dans Azure Key Vault. Type de connexion pris en charge : Vous pouvez utiliser l’identificateur de sécurité Amazon RDS for Oracle ou le nom du service Amazon RDS for Oracle pour identifier votre base de données : - Si vous utilisez le SID : Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;- Si vous utilisez le nom du service : Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Comme options avancées de connexion native Amazon RDS for Oracle, vous pouvez choisir d’ajouter une entrée dans le fichier TNSNAMES.ORA sur le serveur Amazon RDS for Oracle et, dans le service lié à Amazon RDS for Oracle, choisissez d’utiliser le type de connexion avec nom du service Amazon RDS for Oracle et configurez le nom du service correspondant. |
Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Pour plus d’informations, consultez la section Conditions préalables. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Si vous avez plusieurs instances Amazon RDS for Oracle pour le scénario de basculement, vous pouvez créer un service lié à Amazon RDS for Oracle, renseigner l’hôte principal, le port, le nom d’utilisateur, le mot de passe, etc., et ajouter une nouvelle propriété « Propriétés de connexion supplémentaires » avec le nom AlternateServers et la valeur (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>). N’oubliez pas les crochets et faites attention aux signes deux-points (:) utilisés comme séparateur. À titre d’exemple, la valeur suivante de serveurs secondaires définit deux serveurs de base de données de remplacement pour le basculement de connexion : (HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Autres propriétés de connexion que vous pouvez définir dans la chaîne de connexion selon votre cas :
| Propriété | Descriptif | Valeurs autorisées |
|---|---|---|
| ArraySize | Nombre d’octets que le connecteur peut extraire dans un aller-retour réseau. Par exemple : ArraySize=10485760.Des valeurs plus élevées augmentent le débit en réduisant le nombre de fois que des données sont extraites sur le réseau. Des valeurs réduites augmentent le temps de réponse, car il y a moins de retard à attendre que le serveur transmette les données. |
Entier compris entre 1 et 4294967296 (4 Go). La valeur par défaut est 60000. La valeur 1 ne définit pas le nombre d’octets, mais indique une allocation d’espace pour une seule ligne de données. |
Pour activer le chiffrement sur la connexion Amazon RDS for Oracle, deux options s’offrent à vous :
Pour utiliser le chiffrement 3DES (Triple-DES) et AES (Advanced Encryption Standard) , du côté du serveur Amazon RDS for Oracle, accédez à Oracle Advanced Security (OAS) et configurez les paramètres de chiffrement. Pour plus d’informations, consultez cette documentation Oracle. Le connecteur Amazon RDS for Oracle Application Development Framework (ADF) négocie automatiquement la méthode de chiffrement pour utiliser celle que vous configurez dans OAS lors de l’établissement d’une connexion à Amazon RDS for Oracle.
Pour utiliser TLS :
Obtenez les informations de certificat TLS/SSL. Obtenez les informations de certificat encodé DER (Distinguished Encoding Rules) de votre certificat TLS/SSL et enregistrez la sortie (----- Begin Certificate … End Certificate -----) sous forme de fichier texte.
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -textExemple : Extrayez les informations de certificat de DERcert.cer, puis enregistrez la sortie dans cert.txt.
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----Générez le
keystoreou letruststore. La commande suivante crée le fichiertruststore, avec ou sans mot de passe, au format PKCS-12.openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -exportExemple : Créez un fichier
truststorePKCS12 nommé MyTrustStoreFile, avec un mot de passe.openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -exportPlacez le fichier
truststoresur l’ordinateur IR auto-hébergé. Par exemple, placez le fichier sur C:\MyTrustStoreFile.Dans le service, configurez la chaîne de connexion Amazon RDS for Oracle avec
EncryptionMethod=1et la valeurTrustStore/TrustStorePasswordcorrespondante. Par exemple :Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Exemple :
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemple : stockage du mot de passe dans Azure Key Vault
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Cette section fournit la liste des propriétés prises en charge par le jeu de données Amazon RDS for Oracle. Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données.
Pour copier des données à partir d’Amazon RDS for Oracle, définissez la propriété type du jeu de données sur AmazonRdsForOracleTable. Les propriétés suivantes sont prises en charge.
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur AmazonRdsForOracleTable. |
Oui |
| schéma | Nom du schéma. | Non |
| table | Nom de la table/vue. | Non |
| tableName | Nom de la table/vue avec schéma. Cette propriété est prise en charge pour la compatibilité descendante. Pour les nouvelles charges de travail, utilisez schema et table. |
Non |
Exemple :
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Cette section fournit la liste des propriétés prises en charge par la source Amazon RDS for Oracle. Pour obtenir la liste complète des sections et propriétés disponibles pour la définition des activités, consultez Pipelines.
Amazon RDS for Oracle en tant que source
Conseil
Pour charger efficacement les données d’Amazon RDS for Oracle en utilisant le partitionnement des données, apprenez-en plus sur la copie parallèle à partir d’Amazon RDS for Oracle.
Pour copier des données à partir d’Amazon RDS for Oracle, définissez le type de source dans l’activité de copie sur AmazonRdsForOracleSource. Les propriétés suivantes sont prises en charge dans la section source de l’activité de copie.
| Propriété | Descriptif | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur AmazonRdsForOracleSource. |
Oui |
| oracleReaderQuery | Utiliser la requête SQL personnalisée pour lire les données. par exemple "SELECT * FROM MyTable".Lorsque vous activez la charge partitionnée, vous devez utiliser les paramètres de partition intégrés correspondants dans votre requête. Pour voir des exemples, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle. |
Non |
| convertirDécimalEnEntier | Amazon RDS pour le type NUMBER d'Oracle avec une échelle nulle ou non spécifiée sera converti en un entier correspondant. Les valeurs autorisées sont True et False (par défaut). Si vous utilisez Amazon RDS pour Oracle version 2.0, cette propriété est uniquement autorisée à être définie lorsque la prise en chargeV1DataTypes est vraie. |
Non |
| options de partition | Spécifie les options de partitionnement des données utilisées pour charger des données à partir d’Amazon RDS for Oracle. Les valeurs autorisées sont les suivantes : None (valeur par défaut), PhysicalPartitionsOfTable et DynamicRange. Lorsqu’une option de partition est activée (autrement dit, pas None), le degré de parallélisme pour charger simultanément des données à partir d’une base de données Amazon RDS for Oracle est contrôlé par le paramètre parallelCopies de l’activité de copie. |
Non |
| paramètres de partition | Spécifiez le groupe de paramètres pour le partitionnement des données. S’applique lorsque l’option de partitionnement n’est pas None. |
Non |
| Noms de partition | La liste des partitions physiques qui doivent être copiées. S’applique lorsque l’option de partitionnement est PhysicalPartitionsOfTable. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfTabularPartitionName dans la clause WHERE. Pour voir un exemple, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle. |
Non |
| partitionColumnName | Spécifiez le nom de la colonne source dans type entier qu’utilisera le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, la clé primaire de la table sera automatiquement détectée et utilisée en tant que colonne de partition. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionColumnName dans la clause WHERE. Pour voir un exemple, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle. |
Non |
| Limite supérieure de la partition | Valeur maximale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionUpbound dans la clause WHERE. Pour voir un exemple, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle. |
Non |
| partitionLowerBound | Valeur minimale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionLowbound dans la clause WHERE. Pour voir un exemple, consultez la section Copie en parallèle à partir d’Amazon RDS for Oracle. |
Non |
Exemple : copie de données à l’aide de la requête de base sans partition
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copie en parallèle à partir d’Amazon RDS for Oracle
Le connecteur Amazon RDS for Oracle propose un partitionnement de données intégré pour copier des données à partir d’Amazon RDS for Oracle en parallèle. Vous trouverez des options de partitionnement de données dans l’onglet Source de l’activité de copie.
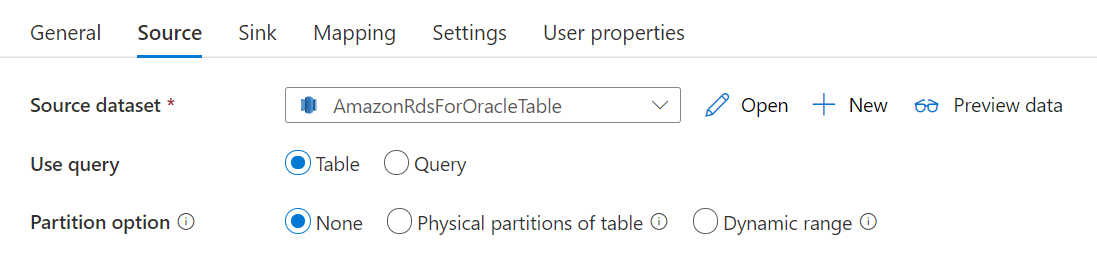
Lorsque vous activez la copie partitionnée, le service exécute des requêtes en parallèle sur votre source Amazon RDS for Oracle pour charger des données par partitions. Le degré de parallélisme est contrôlé via le paramètre parallelCopies sur l’activité de copie. Par exemple, si vous définissez parallelCopies sur quatre, le service génère et exécute simultanément quatre requêtes basées sur l’option de partition et les paramètres que vous avez spécifiés, chacune récupérant une partie des données à partir de votre base de données Amazon RDS for Oracle.
Il vous est recommandé d’activer la copie en parallèle avec partitionnement des données notamment lorsque vous chargez une grande quantité de données à partir de votre base de données Amazon RDS for Oracle. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. |
Option de partition : Partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partition. |
| Chargement complet d’une table volumineuse, sans partitions physiques, avec une colonne entière pour le partitionnement des données. |
Options de partition : Partition dynamique par spécification de plages de valeurs. Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Si la valeur n’est pas spécifiée, la colonne de la clé primaire est utilisée. |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, avec des partitions physiques. |
Option de partition : Partitions physiques de la table. Requête: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Nom de la partition : Spécifiez le(s) nom(s) de partition à copier. Si ce n’est pas spécifié, le service détecte automatiquement les partitions physiques de la table que vous avez spécifiée dans le jeu de données Amazon RDS for Oracle. Pendant l’exécution, le service remplace ?AdfTabularPartitionName par le nom réel de la partition et l’envoie à Amazon RDS for Oracle. |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, sans partitions physiques, et avec une colonne entière pour le partitionnement des données. |
Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Vous pouvez procéder au partitionnement par rapport à la colonne avec le type de données entier. Limite supérieure de partition et limite inférieure de partition : Indiquez si vous souhaitez filtrer le contenu par rapport à la colonne de partition pour récupérer uniquement les données entre les plages inférieure et supérieure. Lors de l’exécution, le service remplace ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound et ?AdfRangePartitionLowbound par le nom de colonne et les plages de valeurs réels de chaque partition et les envoie à Amazon RDS for Oracle. Par exemple, si votre colonne de partition « ID » est définie sur une limite inférieure de 1 et une limite supérieure de 80, avec une copie en parallèle définie sur 4, le service récupère les données via 4 partitions. Les ID sont inclus entre [1, 20], [21, 40], [41, 60] et [61, 80], respectivement. |
Conseil
Lorsque vous copiez des données à partir d’une table non partitionnée, vous pouvez utiliser l’option de partition « Plage dynamique » afin de partitionner par rapport à une colonne d’entiers. Si vos données sources n’incluent pas un tel type de colonne, vous pouvez tirer parti de la fonction ORA_HASH dans une requête source pour générer une colonne et l’utiliser comme colonne de partition.
Exemple : requête avec partition physique
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Exemple : requête avec partition dynamique par spécification de plages de valeurs
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mappage de type de données pour Amazon RDS pour Oracle
Lorsque vous copiez des données depuis et vers Amazon RDS pour Oracle, les mappages de types de données intermédiaires suivants sont utilisés dans le service. Pour découvrir comment l’activité de copie mappe le schéma et le type de données la source au récepteur, consultez Mappage de schéma dans l’activité de copie.
| Type de données Amazon Services Bureau à distance pour Oracle | Type de données de service intermédiaire (pour la version 2.0) | Type de données de service intermédiaire (pour la version 1.0) |
|---|---|---|
| BFILE | Octet[] | Octet[] |
| BINARY_FLOAT | Célibataire | Célibataire |
| BINAIRE_DOUBLE | Double | Double |
| Objet Binaire de Grande Taille (BLOB) | Octet[] | Octet[] |
| CARBONISER | Chaîne | Chaîne |
| CLOB | Chaîne | Chaîne |
| date | Date et heure | Date et heure |
| FLOAT (P < 16) | Double | Double |
| FLOAT (P >= 16) | Décimal | Double |
| INTERVAL ANNEE À MOIS | Int64 | Chaîne |
| INTERVALLE JOUR À SECONDE | TimeSpan | Chaîne |
| LONG | Chaîne | Chaîne |
| LONG RAW | Octet[] | Octet[] |
| NCHAR | Chaîne | Chaîne |
| NCLOB | Chaîne | Chaîne |
| NOMBRE (p,s) | Int16, Int32, Int64, double, simple, décimal | Decimal, String (si p > 28) |
| NUMBER sans précision ni échelle | Décimal | Double |
| NVARCHAR2 | Chaîne | Chaîne |
| CRU | Octet[] | Octet[] |
| HORODATAGE | Date et heure | Date et heure |
| TIMESTAMP AVEC FUSEAU HORAIRE LOCAL | Date et heure | Date et heure |
| TIMESTAMP AVEC FUSEAU HORAIRE | DateTimeOffset | Date et heure |
| VARCHAR2 | Chaîne | Chaîne |
| XMLTYPE | Chaîne | Chaîne |
Notes
NUMBER(p,s) est associé au type de données approprié de service intermédiaire en fonction de la précision (p) et de l’échelle (s).
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Mettre à niveau le connecteur Amazon RDS pour Oracle
Voici les étapes qui vous aident à mettre à niveau le connecteur Amazon RDS pour Oracle :
Dans la page Modifier le service lié , sélectionnez la version 2.0 et configurez le service lié en faisant référence aux propriétés du service lié version 2.0.
Pour les propriétés associées à l’authentification, notamment le nom d’utilisateur et le mot de passe, spécifiez les valeurs d’origine dans les champs correspondants dans la version 2.0. D’autres propriétés de connexion telles que l’hôte, le port et Amazon RDS pour Oracle Service Name/Amazon RDS pour Oracle SID dans la version 1.0 sont désormais des paramètres de la propriété dans la
serverversion 2.0.Par exemple, si vous configurez le service lié version 1.0, comme indiqué ci-dessous :
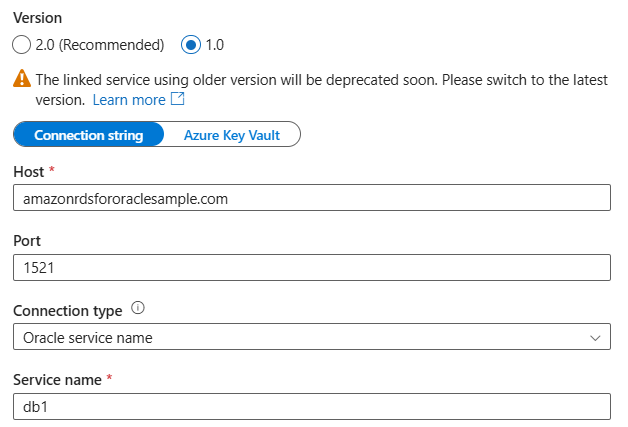
{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "typeProperties": { "connectionString": "host=amazonrdsfororaclesample.com;port=1521;servicename=db1" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }La configuration identique du service lié version 2.0 utilisant Easy Connect (Plus) Naming est la suivante :

{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "amazonrdsfororaclesample.com:1521/db1", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }La configuration de service lié identique de la version 2.0 utilisant le descripteur de connecteur est la suivante :

{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST= amazonrdsfororaclesample.com)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=db1)))", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }Conseil
La propriété
serverest prise en charge par Azure Key Vault. Vous pouvez modifier le json du service lié pour ajouter la référence Azure Key Vault, comme indiqué ci-dessous :

Notez les points suivants :
Si vous utilisez le nom du service Oracle dans la version 1.0, vous pouvez utiliser Easy Connect (Plus) ou descripteur de connecteur comme format de serveur dans la version 2.0.
Si vous utilisez oracle SID dans la version 1.0, vous devez utiliser le descripteur du connecteur comme format de serveur dans la version 2.0.
Pour certaines propriétés de connexion supplémentaires dans la version 1.0, nous fournissons d’autres propriétés ou paramètres dans la propriété
serverde la version 2.0. Vous pouvez faire référence au tableau ci-dessous pour mettre à niveau les propriétés de la version 1.0.Version 1.0 Version 2.0 méthode de chiffrement PROTOCOL (paramètre dans server)tnsnamesfile TNS_ADMIN (variable d’environnement prise en charge sur le runtime d’intégration auto-hébergé) nom_serveur serveur enablebulkload
Valeur : 1, 0enableBulkLoad
Valeur : true, falsefetchtswtzastimestamp
Valeur : 1, 0fetchTswtzAsTimestamp
Valeur : true, falseserveurs alternatifs DESCRIPTION_LIST (paramètre dans server)arraysize fetchSize cachedcursorlimit statementCacheSize connectionretrycount RETRY_COUNT (paramètre dans server)initializationstring initializationString délai d'attente de connexion CONNECT_TIMEOUT (paramètre dans server)cryptoprotocolversion SSL_VERSION (paramètre dans server)truststore WALLET_LOCATION (paramètre dans server)Par exemple, si vous utilisez
alternateserversla version 1.0, vous pouvez définir leDESCRIPTION_LISTparamètre dans la propriété du serveur dans la version 2.0 :Version 1.0 du service lié utilisant
alternateservers:{ "name": "AmazonRdsForOracleV1", "properties": { "type": "AmazonRdsForOracle", "typeProperties": { "connectionString": "host=amazonrdsfororaclesample.com;port=1521;servicename=db1;alternateservers=(HostName= amazonrdsfororaclesample2.com:PortNumber=1521:SID=db2,HostName=255.201.11.24:PortNumber=1522:ServiceName=db3)" } } }Service lié de version 2.0 identique utilisant le paramètre
DESCRIPTION_LISTdans Descripteur du connecteur :{ "name": "AmazonRdsForOracleV2", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "(DESCRIPTION_LIST=(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=amazonrdsfororaclesample.com)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=db1)))(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=amazonrdsfororaclesample2.com)(PORT=1521))(CONNECT_DATA=(SID=db2)))(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=255.201.11.24)(PORT=1522))(CONNECT_DATA=(SERVICE_NAME=db3))))", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" } } }
Le mappage de type de données pour le service lié Amazon RDS pour Oracle version 2.0 est différent de celui de la version 1.0. Pour en savoir plus sur le mappage de type de données le plus récent, consultez Mappage de type de données pour Amazon RDS pour Oracle.
Une propriété
supportV1DataTypesde connexion supplémentaire dans la version 2.0 peut réduire les difficultés de mise à niveau causées par les modifications de type de données. Définir cette propriété surtruegarantit que le type de données dans la version 2.0 reste cohérent avec la version 1.0.
Différences entre Amazon RDS pour Oracle version 2.0 et version 1.0
Le connecteur Amazon RDS pour Oracle version 2.0 offre de nouvelles fonctionnalités et est compatible avec la plupart des fonctionnalités de la version 1.0. Le tableau suivant présente les différences de fonctionnalités entre la version 2.0 et la version 1.0.
| Version 2.0 | Version 1.0 |
|---|---|
| Les mappages suivants utilisés par Amazon RDS pour les types de données Oracle sont appliqués aux types de données temporaires utilisés en interne par le service. NUMBER(p,s) –> Int16, Int32, Int64, double, simple, décimal FLOAT(p)-> Double ou Décimal en fonction de sa précision NOMBRE -> Décimal TIMESTAMP WITH TIME ZONE –> DateTimeOffset INTERVAL ANNEE À MOIS -> Int64 INTERVAL DAY TO SECOND –> TimeSpan |
Les mappages suivants utilisés par Amazon RDS pour les types de données Oracle sont appliqués aux types de données temporaires utilisés en interne par le service. NUMBER(p,s) :> décimal ou chaîne en fonction de sa précision FLOAT(p)–> Double NUMBER –> Double TIMESTAMP WITH TIME ZONE –> DateTime INTERVAL YEAR TO MONTH –> String INTERVAL DAY TO SECOND (m) –> String |
Prise en charge de convertDecimalToInteger dans la source de copie lorsque supportV1DataTypes est réglé sur true. |
Prise en charge de convertDecimalToInteger lors de la copie de la source. |
| Prise en charge de TLS 1.3. | TLS 1.3 n’est pas pris en charge. |
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.