Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article explique comment utiliser l’activité Copy dans Azure Data Factory et Azure Synapse pour copier des données depuis/vers Azure Databricks Delta Lake. Il s’appuie sur l’article Activité Copy, qui présente une vue d’ensemble de l’activité de copie.
Fonctionnalités prises en charge
Ce connecteur Azure Databricks Delta Lake est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Mappage de flux de données (source/récepteur) | ① |
| Activité de recherche | ① ② |
① runtime d’intégration Azure ② runtime d’intégration auto-hébergé
En général, le service prend en charge Delta Lake avec les fonctionnalités suivantes pour répondre à vos différents besoins.
- L’activité de copie prend en charge le connecteur Azure Databricks Delta Lake pour copier des données d’un magasin de données source pris en charge vers une table Azure Databricks Delta Lake, et d’une table Delta Lake vers un magasin de données récepteur pris en charge. Elle tire parti de votre cluster Databricks pour effectuer le déplacement des données. Pour plus d’informations, consultez la section des prérequis.
- Le flux de données de mappage prend en charge le format Delta générique sur Stockage Azure en tant que source et récepteur pour lire et écrire des fichiers Delta pour l’ETL sans code, et s’exécute sur un Azure Integration Runtime géré.
- Les activités Databricks prennent en charge l’orchestration de votre charge de travail ETL centrée sur le code ou de Machine Learning sur Delta Lake.
Prérequis
Pour utiliser ce connecteur Azure Databricks Delta Lake, vous devez configurer un cluster dans Azure Databricks.
- Pour copier des données vers Delta Lake, l’activité Copy appelle le cluster Azure Databricks pour lire des données à partir d’un Stockage Azure, qui est votre source originale ou une zone de transit dans laquelle le service écrit d’abord les données source via la copie intermédiaire intégrée. En savoir plus sur Delta Lake en tant que récepteur.
- De même, pour copier des données depuis Delta Lake, l’activité Copy appelle le cluster Azure Databricks pour écrire des données à partir d’un Stockage Azure, qui est soit votre récepteur original soit une zone de transit de laquelle le service continue d’écrire des données vers le récepteur final via la copie intermédiaire intégrée. En savoir plus sur Delta Lake en tant que source.
Le cluster Databricks doit avoir accès à un compte Stockage Blob Azure ou Azure Data Lake Storage Gen2, à la fois au conteneur de stockage/système de fichiers utilisé pour la source/le récepteur/le transit, et au conteneur/système de fichiers dans lequel vous voulez écrire les tables Delta Lake.
Pour utiliser Azure Data Lake Storage Gen2, vous pouvez configurer un principal de service sur le cluster Databricks dans le cadre de la configuration Apache Spark. Suivez la procédure dans Accès direct avec le principal de service.
Pour utiliser Stockage Blob Azure, vous pouvez configurer une clé d’accès de compte de stockage ou un jeton SAS sur le cluster Databricks dans le cadre de la configuration Apache Spark. Suivez la procédure décrite dans Accéder à Stockage Blob Azure à l’aide de l’API RDD.
Pendant l’exécution de l’activité Copy, si le cluster que vous avez configuré a été arrêté, le service le redémarre automatiquement. Si vous créez un pipeline à l’aide de l’interface utilisateur de création, pour les opérations telles que l’aperçu des données, vous devez avoir un cluster actif, car le service ne démarre pas le cluster en votre nom.
Spécifier la configuration du cluster
Dans le menu déroulant Mode du cluster, sélectionnez Standard.
Dans le menu déroulant Version du runtime Databricks, sélectionnez une version de runtime Databricks.
Activez Optimisation automatique en ajoutant les propriétés suivantes à votre configuration Spark :
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueConfigurez votre cluster en fonction de vos besoins en matière d’intégration et de mise à l’échelle.
Pour plus d’informations sur la configuration du cluster, consultez Configurer des clusters.
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
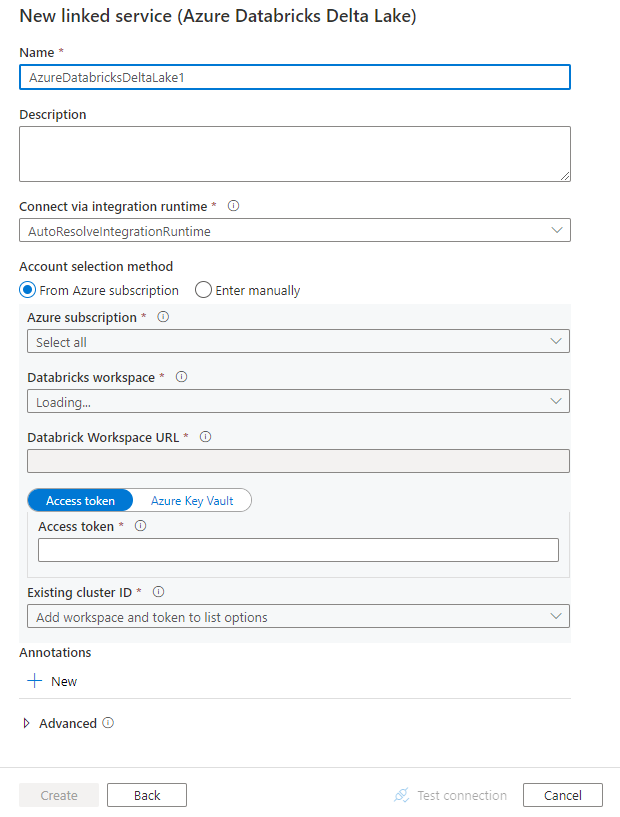
Créer un service lié pour Azure Databricks Delta Lake à l’aide de l’interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Azure Databricks Delta Lake dans l’interface utilisateur du Portail Azure.
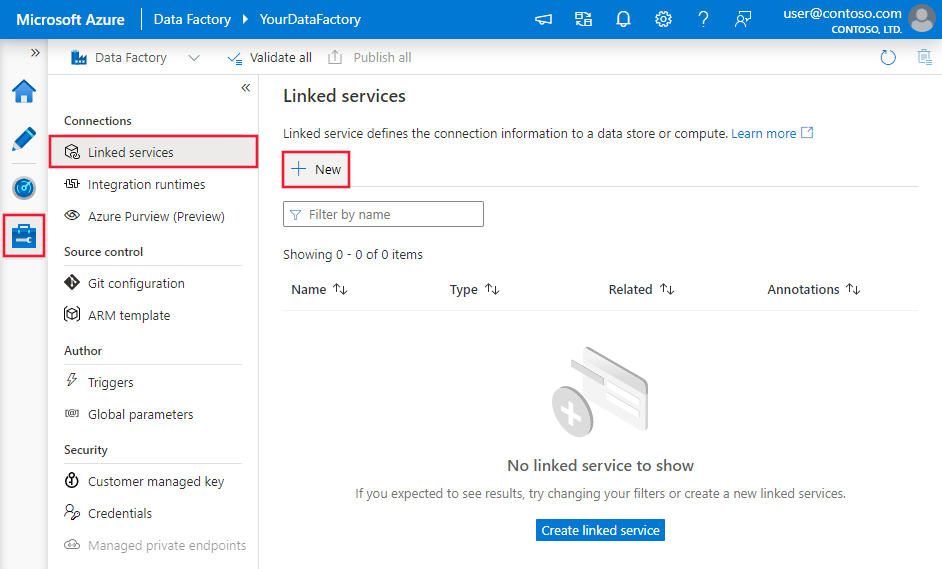
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez Delta et sélectionnez le connecteur Azure Databricks Delta Lake.

Configurez les informations du service, testez la connexion et créez le nouveau service lié.
Informations de configuration du connecteur
Les sections suivantes donnent des précisions sur les propriétés utilisées qui définissent des entités propres à un connecteur Azure Databricks Delta Lake.
Propriétés du service lié
Ce connecteur Azure Databricks Delta Lake prend en charge les types d’authentification suivants. Pour plus d’informations, consultez les sections correspondantes.
- Access token (Jeton d’accès)
- Authentification d’identité managée affectée par le système
- Authentification d’identité managée affectée par l’utilisateur
Access token (Jeton d’accès)
Les propriétés prises en charge pour le service lié à Delta Lake Azure Databricks sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type doit être définie sur AzureDatabricksDeltaLake. | Oui |
| domaine | Spécifiez l’URL de l’espace de travail Azure Databricks, par exemple https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Spécifiez l’ID de cluster d’un cluster existant. Il doit s’agir d’un cluster interactif déjà créé. Vous pouvez trouver l’ID de cluster d’un cluster interactif dans l’espace de travail Databricks -> Clusters -> Nom du cluster interactif -> Configuration -> Étiquettes. En savoir plus |
|
| accessToken | Un jeton d’accès est requis pour que le service s’authentifie auprès d’Azure Databricks. Un jeton d’accès doit être généré à partir de l’espace de travail Databricks. Des étapes plus détaillées pour rechercher le jeton d’accès sont disponibles ici. | |
| connectVia | Le runtime d’intégration utilisé pour la connexion à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Authentification d’identité managée affectée par le système
Pour en savoir plus sur les identités managées affectées par le système pour les ressources Azure, consultez identité managée affectée par le système pour les ressources Azure.
Pour utiliser l’authentification via une identité managée affectée par le système, procédez comme suit pour accorder les autorisations :
Récupérez les informations d’identité managée en copiant la valeur de l’ d’objet d’identité managée (ID) générée en même temps que votre fabrique de données ou espace de travail Synapse.
Accordez à l’identité managée les autorisations appropriées dans Azure Databricks. En général, vous devez accorder au moins le rôle contributeur à votre identité managée affectée par le système dans le contrôle d’accès (IAM) d’Azure Databricks.
Les propriétés prises en charge pour le service lié à Delta Lake Azure Databricks sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type doit être définie sur AzureDatabricksDeltaLake. | Oui |
| domaine | Spécifiez l’URL de l’espace de travail Azure Databricks, par exemple https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Oui |
| clusterId | Spécifiez l’ID de cluster d’un cluster existant. Il doit s’agir d’un cluster interactif déjà créé. Vous pouvez trouver l’ID de cluster d’un cluster interactif dans l’espace de travail Databricks -> Clusters -> Nom du cluster interactif -> Configuration -> Étiquettes. En savoir plus |
Oui |
| workspaceResourceId | Spécifiez l’ID de ressource de l’espace de travail de votre Azure Databricks. | Oui |
| connectVia | Le runtime d’intégration utilisé pour la connexion à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentification d’identité managée affectée par l’utilisateur
Pour en savoir plus sur les identités managées affectées par l’utilisateur pour les ressources Azure, consultez la section identités managées affectées par l’utilisateur
Pour utiliser l’authentification par identité managée affectée par l’utilisateur, effectuez les étapes suivantes :
Créez une ou plusieurs identités managées affectées par l’utilisateur et accordez une autorisation dans votre Azure Databricks. En général, vous devez accorder au moins le rôle Contributeur à votre identité managée affectée par le système dans le contrôle d’accès (IAM) de Azure Databricks.
Attribuez une ou plusieurs identités managées affectées par l’utilisateur à votre fabrique de données ou espace de travail Synapse et créez des informations d’identification pour chaque identité managée affectée par l’utilisateur.
Les propriétés prises en charge pour le service lié à Delta Lake Azure Databricks sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type doit être définie sur AzureDatabricksDeltaLake. | Oui |
| domaine | Spécifiez l’URL de l’espace de travail Azure Databricks, par exemple https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Oui |
| clusterId | Spécifiez l’ID de cluster d’un cluster existant. Il doit s’agir d’un cluster interactif déjà créé. Vous pouvez trouver l’ID de cluster d’un cluster interactif dans l’espace de travail Databricks -> Clusters -> Nom du cluster interactif -> Configuration -> Étiquettes. En savoir plus |
Oui |
| credentials | Spécifiez l’identité managée affectée par l’utilisateur en tant qu’objet d’informations d’identification. | Oui |
| workspaceResourceId | Spécifiez l’ID de ressource de l’espace de travail de votre Azure Databricks. | Oui |
| connectVia | Le runtime d’intégration utilisé pour la connexion à la banque de données. Vous pouvez utiliser le runtime d’intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Exemple :
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article Jeux de données.
Les propriétés suivantes sont prises en charge pour le jeu de données Azure Databricks Delta Lake.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur AzureDatabricksDeltaLakeDataset. | Oui |
| database | Nom de la base de données. | Non pour Source, Oui pour Récepteur |
| table | Nom de la table Delta. | Non pour Source, Oui pour Récepteur |
Exemple :
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez l’article Pipelines. Cette section fournit la liste des propriétés prises en charge par Azure Databricks Delta Lake en tant que source et récepteur.
Delta Lake en tant que source
Pour copier des données à partir d’Azure Databricks Delta Lake, les propriétés suivantes sont prises en charge dans la section source de l’activité de copie.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur AzureDatabricksDeltaLakeSource. | Oui |
| query | Spécifier la requête SQL pour lire les données. Pour le contrôle du voyage dans le temps, suivez le modèle ci-dessous : - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Non |
| exportSettings | Paramètres avancés utilisés pour récupérer des données de la table Delta. | Non |
Sous exportSettings : |
||
| type | Type de la commande d’exportation, définie sur AzureDatabricksDeltaLakeExportCommand. | Oui |
| dateFormat | Définissez le format du type date sur une chaîne avec un format de date. Les formats de date personnalisés suivent les formats du modèle datetime. En l’absence de spécification, la valeur par défaut est yyyy-MM-dd. |
Non |
| timestampFormat | Définissez le format du type timestamp sur une chaîne avec un format timestamp. Les formats de date personnalisés suivent les formats du modèle datetime. En l’absence de spécification, la valeur par défaut est yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Non |
Copie directe à partir de Delta Lake
Si le format et le magasin de données récepteur remplissent les critères décrits dans cette section, vous pouvez utiliser l’activité de copie pour effectuer une copie directe de la table Delta Azure Databricks vers un récepteur. Le service vérifie les paramètres et fait échouer l’exécution de l’activité Copy si les critères suivants ne sont pas satisfaits :
Le service lié au récepteur est Stockage Blob Azure ou Azure Data Lake Storage Gen2. Les informations d’identification du compte doivent être préconfigurées dans la configuration du cluster Azure Databricks. Pour plus d’informations, consultez les Prérequis.
Le format de données du récepteur est Parquet, Texte délimité ou Avro avec les configurations suivantes, et pointe vers un dossier plutôt qu’un fichier.
- Pour le format Parquet, le codec de compression est aucun, snappyou gzip.
- Pour le format texte délimité :
-
rowDelimiterest un caractère unique quelconque. -
compressionpeut être aucun, bzip2 ou gzip. -
encodingNameUTF-7 n’est pas pris en charge.
-
- Pour le format Avro, le codec de compression est aucun, deflate ou snappy.
Dans la source de l’activité de copie,
additionalColumnsn’est pas spécifié.Si vous copiez des données dans du texte délimité, dans le récepteur de l’activité de copie,
fileExtensiondoit être « .csv ».Dans le mappage de l’activité de copie, la conversion de type n’est pas activée.
Exemple :
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copie intermédiaire à partir de Delta Lake
Lorsque le format ou le magasin de données récepteur ne respecte pas les critères de la copie directe, comme indiqué dans la dernière section, activez la copie intermédiaire intégrée à l’aide d’une instance de stockage Azure intermédiaire. La fonctionnalité de copie intermédiaire offre également un meilleur débit. Le service exporte les données d’Azure Databricks Delta Lake vers le stockage intermédiaire, les copie sur le récepteur, puis nettoie vos données temporaires sur le stockage intermédiaire. Pour plus d’informations sur la copie de données à l’aide de la mise en lots, consultez Copie intermédiaire.
Pour utiliser cette fonctionnalité, créez un service lié Stockage Blob Azure ou un service lié Azure Data Lake Storage Gen2 qui fait référence au compte de stockage comme intermédiaire temporaire. Spécifiez ensuite les propriétés enableStaging et stagingSettings dans l’activité de copie.
Notes
Les informations d’identification du compte de stockage intermédiaire doivent être préconfigurées dans la configuration du cluster Azure Databricks. Pour plus d’informations, consultez les Prérequis.
Exemple :
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake en tant que récepteur
Pour copier des données vers Azure Databricks Delta Lake, les propriétés suivantes sont prises en charge dans la section récepteur de l’activité de copie.
| Propriété | Description | Obligatoire |
|---|---|---|
| type | Propriété type du récepteur de l’activité de copie, définie sur AzureDatabricksDeltaLakeSink. | Oui |
| preCopyScript | Spécifiez une requête SQL pour l’activité de copie à exécuter avant l’écriture de données dans la table Delta Databricks à chaque exécution. Exemple : VACUUM eventsTable DRY RUN vous pouvez utiliser cette propriété pour nettoyer les données préchargées ou ajouter une instruction Tronquer la table ou Vider. |
Non |
| importSettings | Paramètres avancés utilisés pour écrire des données dans la table Delta. | Non |
Sous importSettings : |
||
| type | Type de la commande d’importation, définie sur AzureDatabricksDeltaLakeImportCommand. | Oui |
| dateFormat | Définissez le format de la chaîne sur un type date avec un format de date. Les formats de date personnalisés suivent les formats du modèle datetime. En l’absence de spécification, la valeur par défaut est yyyy-MM-dd. |
Non |
| timestampFormat | Définissez le format de la chaîne sur un type timestamp avec un format timestamp. Les formats de date personnalisés suivent les formats du modèle datetime. En l’absence de spécification, la valeur par défaut est yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Non |
Copie directe vers Delta Lake
Si le format et le magasin de données source remplissent les critères décrits dans cette section, vous pouvez utiliser l’activité de copie pour effectuer une copie directe depuis une source vers Azure Databricks Delta Lake. Le service vérifie les paramètres et fait échouer l’exécution de l’activité Copy si les critères suivants ne sont pas satisfaits :
Le service lié à la source est Stockage Blob Azure ou Azure Data Lake Storage Gen2. Les informations d’identification du compte doivent être préconfigurées dans la configuration du cluster Azure Databricks. Pour plus d’informations, consultez les Prérequis.
Le format de données de la source est Parquet, Texte délimité ou Avro avec les configurations suivantes, et pointe vers un dossier plutôt qu’un fichier.
- Pour le format Parquet, le codec de compression est aucun, snappyou gzip.
- Pour le format texte délimité :
-
rowDelimiterest la valeur par défaut ou n’importe quel caractère unique. -
compressionpeut être aucun, bzip2 ou gzip. -
encodingNameUTF-7 n’est pas pris en charge.
-
- Pour le format Avro, le codec de compression est aucun, deflate ou snappy.
Dans la source de l’activité de copie :
-
wildcardFileNamecontient uniquement le caractère générique*mais pas?, etwildcardFolderNamen’est pas spécifié. -
prefix,modifiedDateTimeStart,modifiedDateTimeEndetenablePartitionDiscoveryne sont pas spécifiés. -
additionalColumnsn'est pas spécifié.
-
Dans le mappage de l’activité de copie, la conversion de type n’est pas activée.
Exemple :
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Copie intermédiaire vers Delta Lake
Lorsque le format ou le magasin de données source ne respecte pas les critères de la copie directe, comme indiqué dans la dernière section, activez la copie intermédiaire intégrée à l’aide d’une instance de stockage Azure intermédiaire. La fonctionnalité de copie intermédiaire offre également un meilleur débit. Le service convertit automatiquement les données pour respecter les exigences du format de données dans le stockage intermédiaire, puis charge les données dans Delta Lake à partir de là. Enfin, il nettoie vos données temporaires sur le stockage. Pour plus d’informations sur la copie de données à l’aide de la mise en lots, consultez Copie intermédiaire.
Pour utiliser cette fonctionnalité, créez un service lié Stockage Blob Azure ou un service lié Azure Data Lake Storage Gen2 qui fait référence au compte de stockage comme intermédiaire temporaire. Spécifiez ensuite les propriétés enableStaging et stagingSettings dans l’activité de copie.
Notes
Les informations d’identification du compte de stockage intermédiaire doivent être préconfigurées dans la configuration du cluster Azure Databricks. Pour plus d’informations, consultez les Prérequis.
Exemple :
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Surveillance
La même expérience de surveillance de l’activité Copy est fournie que pour les autres connecteurs. De plus, le chargement des données depuis et vers Delta Lake étant exécuté sur votre cluster Azure Databricks, vous pouvez également consulter les journaux de cluster détaillés et surveiller les performances.
Propriétés de l’activité Lookup
Pour plus d’informations sur les propriétés, consultez Activité de recherche.
L’activité de recherche peut retourner jusqu’à 1 000 lignes. Si le jeu de résultats contient plus d’enregistrements, les 1 000 premières lignes sont retournées.
Contenu connexe
Consultez les formats et magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité Copy.