Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Une fois que vous avez attaché un notebook à un cluster et exécuté une ou plusieurs cellules, votre notebook aura un état et affichera des résultats. Cette section explique comment gérer l’état et les résultats d’un notebook.
Effacer l’état et les sorties des notebooks
Pour effacer l’état et les sorties du notebook, sélectionnez l’une des options Effacer en bas du menu Exécuter.
| Option de menu | Descriptif |
|---|---|
| Effacer toutes les sorties de cellule | Efface les sorties de cellule. Cela est utile si vous partagez le notebook et que vous souhaitez éviter d’inclure des résultats. |
| État clair | Efface l’état du notebook, y compris les définitions de fonction et de variable, les données et les bibliothèques importées. |
| Effacer l’état et les sorties | Efface les sorties de cellule et l’état du notebook. |
| Effacer l’état et exécuter tout | Efface l’état du notebook et démarre une nouvelle exécution. |
Table des résultats
Lorsqu’une cellule est exécutée, les résultats sont affichés dans un tableau de résultats. Avec le tableau des résultats, vous pouvez effectuer les opérations suivantes :
- Copiez une colonne ou un autre sous-ensemble des résultats tabulaires dans le presse-papiers.
- Effectuez une recherche de texte sur la table de résultats.
- Trier et filtrer des données.
- Naviguez entre les cellules de la table en utilisant les touches de direction du clavier.
- Sélectionnez une partie du nom de colonne ou de la valeur de cellule en double-cliquant et en faisant glisser pour sélectionner le texte souhaité.
- Utilisez l’Explorateur de colonnes pour rechercher, afficher ou masquer, épingler et réorganiser des colonnes.
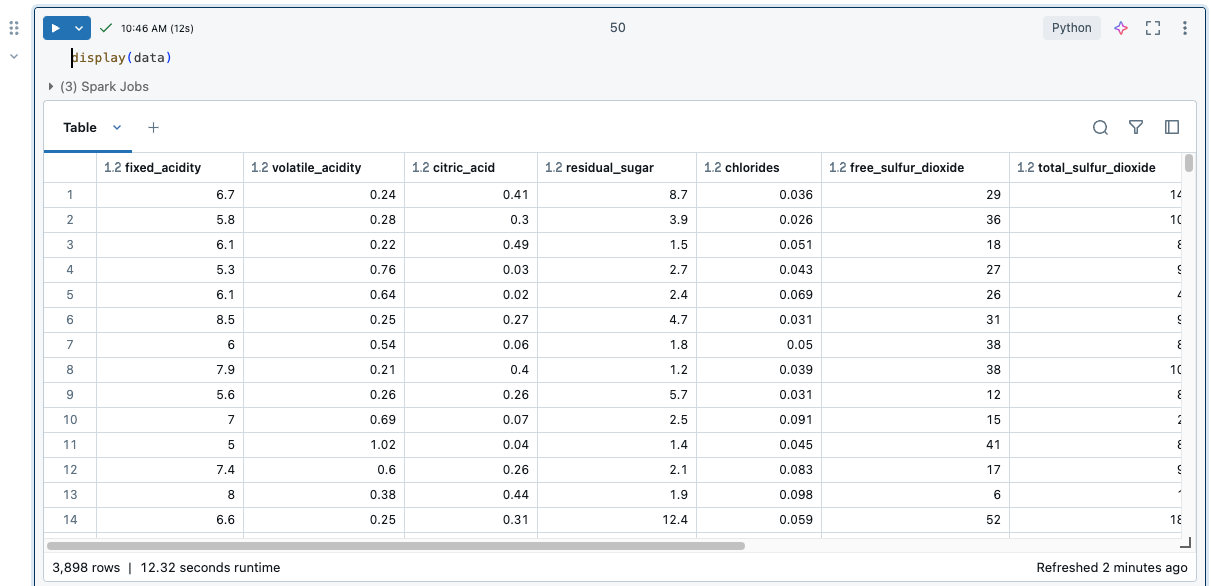
Pour afficher les limites de la table de résultats, consultez Limites du tableau de résultats du notebook.
Sélectionner les données
Pour sélectionner des données dans la table de résultats, effectuez l’une des opérations suivantes.
- Copiez les données ou un sous-ensemble dans le presse-papiers.
- Cliquez sur une colonne ou un en-tête de ligne.
- Cliquez dans la cellule supérieure gauche du tableau pour sélectionner l’intégralité du tableau.
- Faites glisser votre curseur sur n’importe quel ensemble de cellules pour les sélectionner.
Pour ouvrir un panneau latéral qui affiche des informations sur la sélection, cliquez sur l’icône ![]() dans le coin supérieur droit, à côté du champ de Rechercher.
dans le coin supérieur droit, à côté du champ de Rechercher.
![]()
Copier les données dans le Presse-papiers
Pour copier le tableau de résultats au format CSV dans le Presse-papiers, cliquez sur la flèche vers le bas en regard de l’onglet titre du tableau, puis cliquez sur Copier les résultats dans le Presse-papiers.

Vous pouvez également cliquer sur la zone située en haut à gauche du tableau pour sélectionner la table complète, puis cliquer avec le bouton droit et sélectionner Copier dans le menu déroulant.
Il existe plusieurs façons de copier les données sélectionnées :
- Appuyez sur
Cmd + Csur MacOS ouCtrl + Csur Windows pour copier les résultats dans le Presse-papiers au format CSV. - Cliquez avec le bouton droit et sélectionnez Copier pour copier les résultats dans le Presse-papiers au format CSV.
- Cliquez avec le bouton droit et sélectionnez Copier en tant que pour copier les données sélectionnées au format CSV, TSV ou Markdown.

Trier les résultats
Pour trier la table de résultats en fonction des valeurs d’une colonne, placez le curseur sur le nom de la colonne. Une icône contenant le nom de la colonne apparaît à droite de la cellule. Cliquez sur la flèche pour trier la colonne.
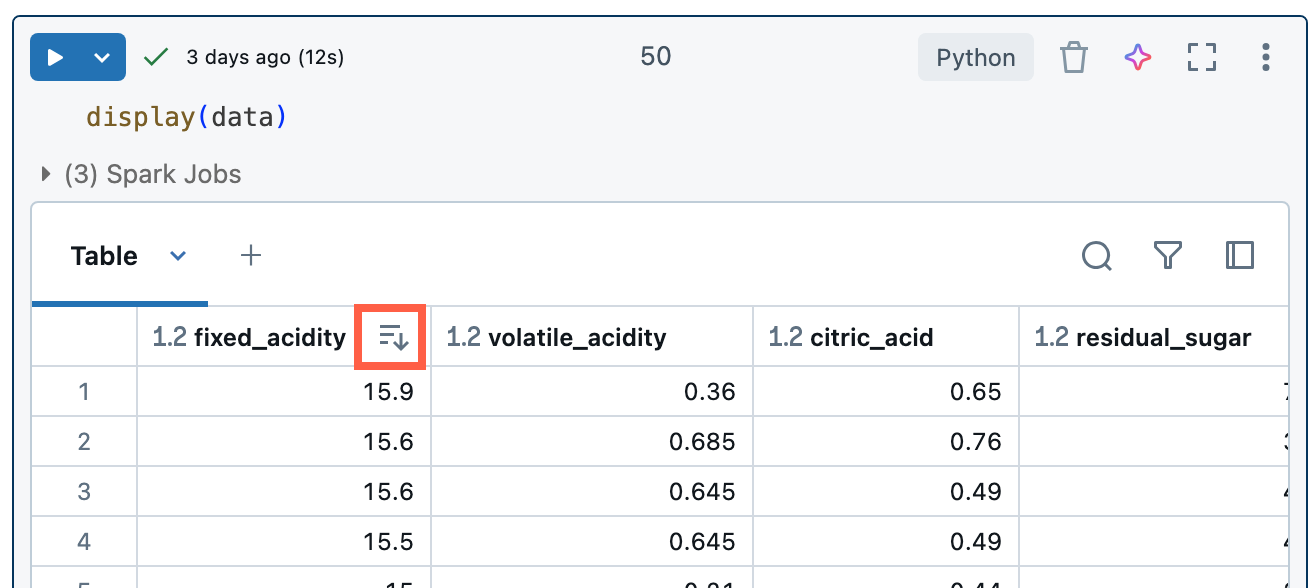
Pour trier sur plusieurs colonnes, maintenez enfoncée la touche Maj pendant que vous cliquez sur la flèche de tri pour les colonnes.
Le tri suit l’ordre de tri naturel par défaut. Pour appliquer un ordre de tri lexicographique, utilisez ORDER BY dans SQL ou les fonctions de SORT respectives disponibles dans votre environnement.
Filtrer les résultats
Utilisez des filtres sur une table de résultats pour examiner de plus près les données. Les filtres appliqués aux tables de résultats affectent également les visualisations, ce qui permet une exploration interactive sans modifier la requête ou le jeu de données sous-jacent. Voir Filtrer une visualisation.
Il existe plusieurs façons de créer un filtre :
Databricks Assistant
Utiliser des invites en langage naturel avec Assistant
Créez des filtres à l’aide d’instructions en langage naturel :
- Cliquez sur
 En haut à droite des résultats de la cellule.
En haut à droite des résultats de la cellule. - Dans la boîte de dialogue qui s’affiche, entrez du texte qui décrit le filtre souhaité.
- Cliquez sur
 . L’Assistant génère et applique le filtre pour vous.
. L’Assistant génère et applique le filtre pour vous.
Si vous souhaitez créer des filtres supplémentaires avec Assistant, cliquez sur ![]() à côté des filtres, pour entrer une autre invite.
à côté des filtres, pour entrer une autre invite.
Consultez Filtrer les données avec des prompts en langage naturel.
Boîte de dialogue de filtre
Utiliser la boîte de dialogue de filtre intégrée
- Si l’Assistant Databricks n’est pas activé, cliquez sur haut à droite des résultats de la cellule pour ouvrir la boîte de dialogue de filtre. Vous pouvez également accéder à cette boîte de dialogue en cliquant sur
 .
. - Sélectionnez la colonne que vous souhaitez filtrer.
- Sélectionnez la règle de filtre à appliquer.
- Sélectionnez la ou les valeurs que vous souhaitez filtrer.
Par valeur
Filtrer par une valeur spécifique
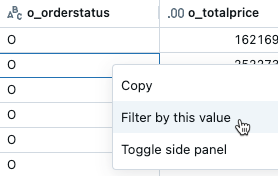
- Dans le tableau de résultats, cliquez avec le bouton droit sur une cellule avec cette valeur.
- Sélectionnez Filtrer par cette valeur dans le menu déroulant.
Par colonne
Filtrer sur une colonne spécifique
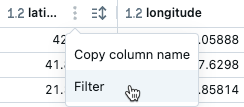
- Pointez sur la colonne sur laquelle vous souhaitez filtrer.
- Cliquez sur
 .
. - Sélectionnez Filtrer.
- Sélectionnez les valeurs à filtrer.
Pour activer ou désactiver temporairement un filtre, faites basculer le bouton Activé/Désactivé dans la boîte de dialogue.
Pour supprimer un filtre, cliquez sur ![]() En regard du nom de
En regard du nom de  .
.
Appliquer des filtres à un jeu de données complet
Par défaut, les filtres sont appliqués uniquement aux résultats affichés dans la table des résultats. Si les données retournées sont tronquées (par exemple, lorsqu’une requête retourne plus de 10 000 lignes ou que le jeu de données est supérieur à 2 Mo), le filtre est appliqué uniquement aux lignes retournées. Une note en haut à droite de la table indique que le filtre a été appliqué aux données tronquées.
Vous pouvez choisir de filtrer le jeu de données complet à la place. Cliquez sur Données tronquées, puis choisissez Jeu de données complet. En fonction de la taille du jeu de données, il peut prendre beaucoup de temps pour que le filtre s’applique.

Créer une requête à partir de résultats filtrés
À partir d’une table de résultats filtrée ou d’une visualisation dans un notebook avec SQL comme langage par défaut, vous pouvez créer une requête avec les filtres appliqués. En haut à droite de la table ou de la visualisation, cliquez sur Créer une requête. La requête est ajoutée en tant que cellule suivante dans le bloc-notes.
La requête créée applique vos filtres au-dessus de la requête d’origine. Cela vous permet d’utiliser un jeu de données plus petit et plus pertinent, ce qui permet une exploration et une analyse des données plus efficaces.

Explorer les colonnes
Pour faciliter l’utilisation des tables qui ont de nombreuses colonnes, vous pouvez utiliser l’Explorateur de colonnes. Pour ouvrir l’Explorateur de colonnes, cliquez sur l’icône de colonne (![]() ) en haut à droite d’une table de résultats.
) en haut à droite d’une table de résultats.
L’Explorateur de colonnes vous permet de :
- Rechercher des colonnes : tapez dans la barre de recherche pour filtrer la liste des colonnes. Cliquez sur une colonne dans l’Explorateur pour y accéder dans la table de résultats.
- Afficher ou masquer les colonnes : utilisez les cases à cocher pour contrôler la visibilité des colonnes. La case à cocher en haut active la visibilité de toutes les colonnes en même temps. Les colonnes individuelles peuvent être affichées ou masquées à l’aide des cases à cocher en regard de leurs noms.
- Épingler des colonnes : pointez sur un nom de colonne pour afficher une icône d’épingle. Cliquez sur l’icône de l'épingle pour fixer la colonne. Les colonnes épinglées restent visibles lorsque vous faites défiler horizontalement la table de résultats.
-
Réorganiser les colonnes : cliquez et maintenez l’icône glisser (
 la droite du nom d’une colonne), puis faites glisser-déplacer la colonne vers sa nouvelle position souhaitée. Cette opération réorganise les colonnes de la table de résultats.
la droite du nom d’une colonne), puis faites glisser-déplacer la colonne vers sa nouvelle position souhaitée. Cette opération réorganise les colonnes de la table de résultats.

Mettre en forme les colonnes
Les en-têtes de colonnes indiquent le type de données de la colonne. Par exemple,  indique le type de données d’entier. Pointez au-dessus de l’indicateur pour afficher le type de données.
indique le type de données d’entier. Pointez au-dessus de l’indicateur pour afficher le type de données.
Vous pouvez mettre en forme des colonnes dans les tables de résultats en tant que types tels que Devise, Pourcentage, URL et bien plus, avec un contrôle sur les décimales pour des tables plus claires.
Mettez en forme les colonnes à partir du menu kebab dans le nom de colonne.
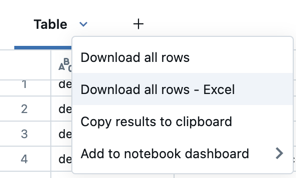
Télécharger les résultats
Par défaut, le téléchargement des résultats est activé. Pour activer/désactiver ce paramètre, consultez Gérer la possibilité de télécharger des résultats à partir de notebooks.
Vous pouvez télécharger un résultat de cellule qui contient une sortie tabulaire sur votre ordinateur local. Cliquez sur la flèche pointant vers le bas après le titre de l’onglet. Les options de menu dépendent du nombre de lignes dans le résultat et de la version de Databricks Runtime. Les résultats téléchargés sont enregistrés sur votre ordinateur local sous la forme d’un fichier CSV dont le nom correspond au nom de votre notebook.
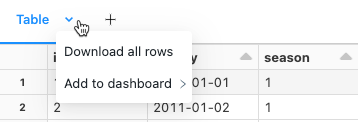
Pour les notebooks connectés aux entrepôts SQL ou au calcul sans serveur, vous pouvez également télécharger les résultats sous forme de fichier Excel.
Explorer les résultats des cellules SQL
Dans un notebook Databricks, les résultats d’une cellule de langage SQL sont automatiquement disponibles en tant que DataFrame affecté à la variable _sqldf. Vous pouvez utiliser la _sqldf variable pour faire référence à la sortie SQL précédente dans les cellules Python et SQL suivantes. Pour plus d’informations, consultez Explorer les résultats des cellules SQL.
Afficher plusieurs sorties par cellule
Les notebooks et les cellules Python dans les notebooks %python non-Python prennent en charge plusieurs sorties par cellule. Par exemple, la sortie du code suivant inclut à la fois le tracé et le tableau :
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
Redimensionner les sorties
Redimensionnez les sorties de cellule en faisant glisser le coin inférieur droit de la table ou de la visualisation.

Commiter les sorties de notebook dans des dossiers Git Databricks
Pour en savoir plus sur la validation des sorties de notebook .ipynb, consultez Autoriser la validation de la sortie du notebook .ipynb.
- Le notebook doit être un fichier .ipynb
- Les paramètres d’administration de l’espace de travail doivent autoriser la validation des sorties de notebook.