Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Databricks est une plateforme d’analyse ouverte unifiée permettant de générer, déployer, partager et gérer des données de niveau entreprise, des analyses et des solutions d’IA à grande échelle. Databricks Data Intelligence Platform s’intègre au stockage cloud et à la sécurité dans votre compte cloud, et gère et déploie l’infrastructure cloud pour vous.
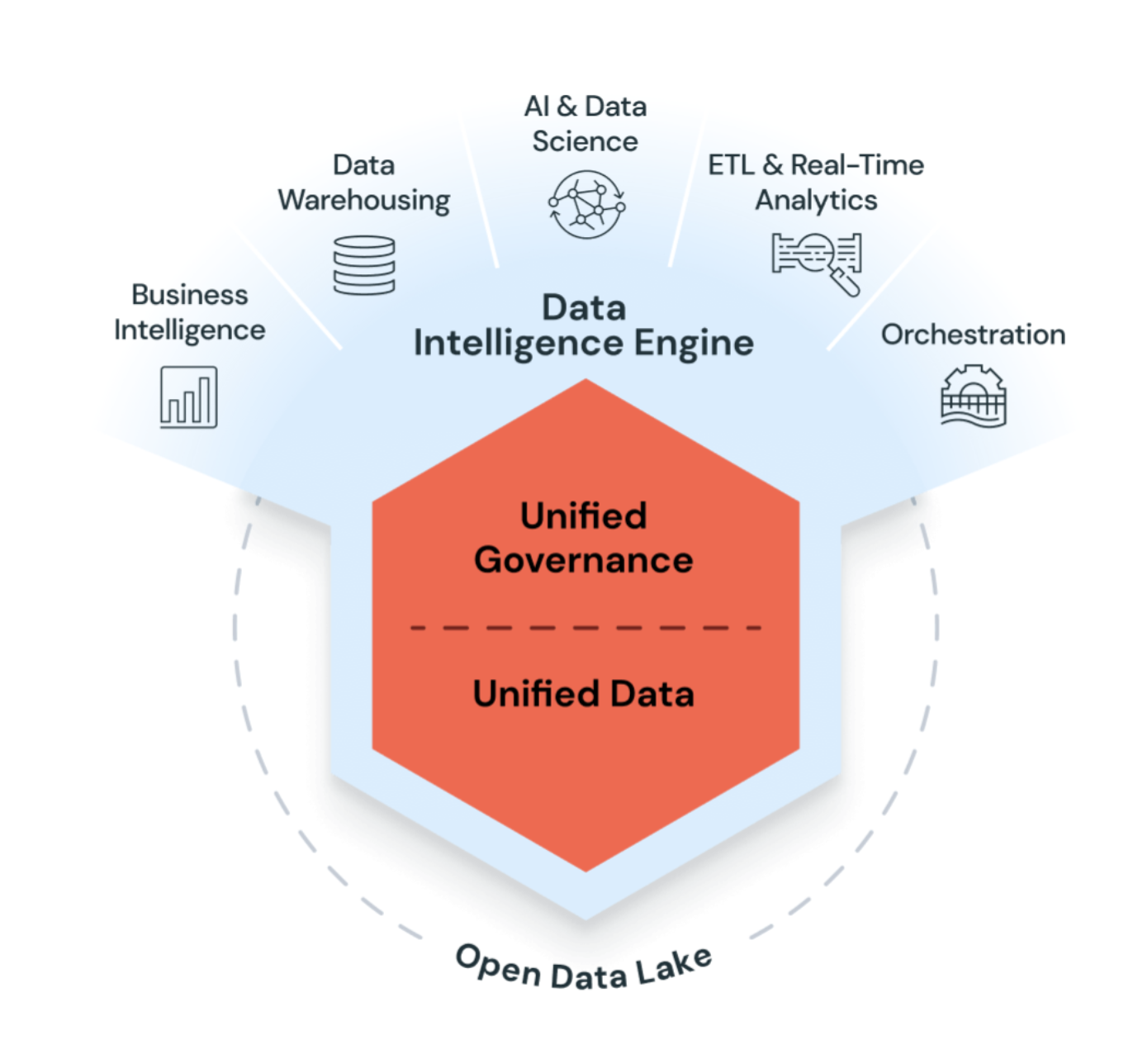
Azure Databricks utilise l’IA générative avec le data lakehouse pour comprendre la sémantique unique de vos données. Ensuite, il optimise automatiquement le niveau de performance et gère l’infrastructure pour répondre aux besoins de votre entreprise.
Le traitement du langage naturel apprend la langue de votre entreprise, ce qui vous permet de rechercher et de découvrir des données en posant une question en vos propres mots. L’assistance en langage naturel vous aide à écrire du code, à résoudre les erreurs et à trouver des réponses dans la documentation.
Intégration open source managée
Databricks est engagé dans la communauté open source et gère les mises à jour des intégrations open source avec les versions databricks Runtime. Les technologies suivantes sont des projets open source créés à l’origine par les employés de Databricks :
Cas d’utilisation courants
Les cas d’usage suivants mettent en évidence certaines des façons dont les clients utilisent Azure Databricks pour accomplir des tâches essentielles au traitement, au stockage et à l’analyse des données qui pilotent les fonctions et décisions métier critiques.
Générer un data lakehouse d’entreprise
Le data lakehouse combine des entrepôts de données d’entreprise et des lacs de données pour accélérer, simplifier et unifier des solutions de données d’entreprise. Les ingénieurs données, les scientifiques des données, les analystes et les systèmes de production peuvent tous utiliser le data lakehouse comme source unique de vérité, ce qui permet d’accéder à des données cohérentes et de réduire la complexité de la création, de la maintenance et de la synchronisation de nombreux systèmes de données distribués. Consultez Qu’est-ce qu’un data lakehouse ?.
ETL et engineering données
Que vous génériez des tableaux de bord ou alimentiez des applications d’intelligence artificielle, l’ingénierie des données fournit l’épine dorsale des entreprises centrées sur les données en vous assurant que les données sont disponibles, propres et stockées dans des modèles de données pour une découverte et une utilisation efficaces. Azure Databricks combine la puissance d’Apache Spark avec delta et des outils personnalisés pour offrir une expérience ETL inégalée. Utilisez SQL, Python et Scala pour composer la logique ETL et orchestrer le déploiement de travaux planifiés en quelques clics.
Lakeflow Declarative Pipelines simplifie davantage ETL en gérant intelligemment les dépendances entre les jeux de données et en déployant et en mettant automatiquement à l’échelle l’infrastructure de production pour garantir la livraison de données en temps opportun et précis à vos spécifications.
Azure Databricks fournit des outils pour l’ingestion des données, notamment le chargeur automatique, un outil efficace et évolutif pour charger de manière incrémentielle et idempotente des données à partir du stockage d’objets cloud et des lacs de données dans le data lakehouse.
Apprentissage automatique, IA et science des données
Azure Databricks Machine Learning étend les fonctionnalités principales de la plateforme avec une suite d’outils adaptés aux besoins des scientifiques des données et des ingénieurs ML, notamment MLflow et Databricks Runtime pour Machine Learning.
Modèles de langage volumineux et IA générative
Databricks Runtime pour Machine Learning inclut des bibliothèques comme Hugging Face Transformers qui vous permettent d’intégrer des modèles préentraînés existants ou d’autres bibliothèques open source dans votre workflow. L’intégration Databricks MLflow facilite l’utilisation du service de suivi MLflow avec des pipelines de transformateur, des modèles et des composants de traitement. Intégrez des modèles ou des solutions OpenAI de partenaires comme John Snow Labs dans vos workflows Databricks.
Avec Azure Databricks, personnalisez un LLM sur vos données pour votre tâche spécifique. Grâce à l’aide d’outils open source, tels que Hugging Face et DeepSpeed, vous pouvez utiliser efficacement un grand modèle de langage (LLM) de base et commencer à vous entraîner avec vos propres données afin de bénéficier de plus d’exactitude pour votre domaine et votre charge de travail.
En outre, Azure Databricks fournit des fonctions IA que les analystes de données SQL peuvent utiliser pour accéder aux modèles LLM, y compris à partir d’OpenAI, directement dans leurs pipelines de données et flux de travail. Consultez Appliquer l’IA aux données à l’aide d’Azure Databricks AI Functions.
Entreposage de données, analyse et décisionnel
Azure Databricks combine des interfaces utilisateur conviviales avec des ressources de calcul rentables et un stockage infiniment évolutif et abordable pour fournir une plateforme puissante pour exécuter des requêtes analytiques. Les administrateurs configurent des clusters de calcul évolutifs en tant qu’entrepôts SQL, ce qui permet aux utilisateurs finaux d’exécuter des requêtes sans se soucier de la complexité de l’utilisation dans le cloud. Les utilisateurs SQL peuvent exécuter des requêtes sur des données dans lakehouse à l’aide de l’éditeur de requête SQL ou dans les notebooks. Les notebooks prennent en charge Python, R et Scala en plus de SQL et permettent aux utilisateurs d’incorporer les mêmes visualisations que celles disponibles dans les tableaux de bord hérités, ainsi que les liens, images et commentaires écrits en Markdown.
Gouvernance des données et partage de données sécurisé
Unity Catalog fournit un modèle de gouvernance des données unifié pour le data lakehouse. Les administrateurs cloud configurent et intègrent des autorisations de contrôle d’accès grossiers pour Unity Catalog, puis les administrateurs Azure Databricks peuvent gérer les autorisations pour les équipes et les individus. Les privilèges sont gérés avec des listes de contrôle d’accès (ACL) via des interfaces utilisateur conviviales ou une syntaxe SQL, ce qui facilite l’accès aux données par les administrateurs de base de données sans avoir à effectuer une mise à l’échelle sur la gestion de l’accès aux identités (IAM) natives cloud et la mise en réseau.
Unity Catalog facilite l’exécution d’analyses sécurisées dans le cloud et fournit une division de responsabilité qui permet de limiter la requalification ou la mise à niveau nécessaire pour les administrateurs et les utilisateurs finaux de la plateforme. Consultez Qu’est-ce que Unity Catalog ?.
Le lakehouse rend le partage de données au sein de votre organisation aussi simple que l’octroi de l’accès aux requêtes à une table ou à une vue. Pour le partage en dehors de votre environnement sécurisé, Unity Catalog propose une version managée de Delta Sharing.
DevOps, CI/CD et orchestration de tâches
Les cycles de vie de développement pour les pipelines ETL, les modèles ML et les tableaux de bord d’analyse présentent chacun leurs propres défis uniques. Azure Databricks permet à tous vos utilisateurs de tirer parti d’une seule source de données, ce qui réduit les efforts redondants et les rapports hors synchronisation. En fournissant en outre une suite d’outils courants pour le contrôle de version, l’automatisation, la planification, le déploiement de ressources de code et de production, vous pouvez simplifier votre surcharge pour la supervision, l’orchestration et les opérations.
Les Travaux planifient des notebooks Azure Databricks, des requêtes SQL et d’autres codes arbitraires. Les bundles de ressources Databricks vous permettent de définir, déployer et exécuter des ressources Databricks telles que des travaux et des pipelines par programmation. Les dossiers Git vous permettent de synchroniser des projets Azure Databricks avec un certain nombre de fournisseurs Git populaires.
Pour les meilleures pratiques et recommandations CI/CD, consultez les flux de travail CI/CD recommandés sur Databricks. Pour obtenir une vue d’ensemble complète des outils pour les développeurs, consultez Développer sur Databricks.
Analyse de streaming et en temps réel
Azure Databricks tire parti d’Apache Spark Structured Streaming pour travailler avec les données de streaming et les modifications de données incrémentielles. Structured Streaming s’intègre étroitement à Delta Lake, et ces technologies fournissent les bases des pipelines déclaratifs Lakeflow et du chargeur automatique. Consultez les concepts de streaming structuré.