Format XML dans Data Factory dans Microsoft Fabric
Cet article explique comment configurer le format XML dans le pipeline de données de Data Factory dans Microsoft Fabric.
Le format XML est pris en charge pour les activités et les connecteurs suivants en tant que source.
| Catégorie | Connecteur/activité |
|---|---|
| Connecteur pris en charge | Amazon S3 |
| Compatible avec Amazon S3 | |
| Stockage Blob Azure | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Système de fichiers | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Fichiers Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Activité prise en charge | Activité Copy (source/-) |
| Activité de recherche | |
| Activité GetMetadata | |
| Supprimer l’activité |
Pour configurer le format XML, choisissez votre connexion dans la source de l’activité de copie du pipeline de données, puis sélectionnez XML dans la liste déroulante du Format de fichier. Sélectionnez Paramètres pour poursuivre la configuration de ce format.
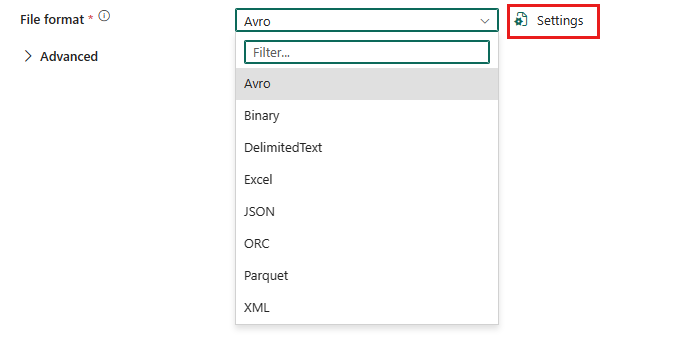
Après avoir sélectionné Paramètres dans la section Format de fichier, les propriétés suivantes s'affichent dans la boîte de dialogue contextuelle Paramètres de format de fichier.
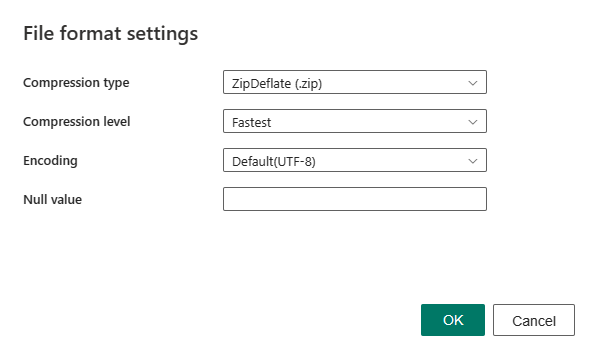
Type de compression : le codec de compression utilisé pour lire les fichiers XML. Vous pouvez choisir parmi les types Aucun, bzip2, gzip, deflate, ZipDeflate, TarGZip ou tar dans la liste déroulante.
Si vous sélectionnez le type de compression ZipDeflate, Conserver le nom du fichier zip en tant que dossier s’affiche sous les paramètres avancés dans l’onglet Source.
- Conserver le nom du fichier zip en tant que dossier : indique si le nom du fichier zip source doit être conservé en tant que structure de dossiers lors de la copie.
- Si cette case est activée (valeur par défaut), le service écrit les fichiers décompressés dans
<specified file path>/<folder named as source zip file>/. - Si cette case est décochée, le service écrit les fichiers décompressés directement dans
<specified file path>. Assurez-vous de ne pas avoir de noms de fichiers dupliqués dans les différents fichiers zip sources afin d’éviter toute course ou tout comportement inattendu.
- Si cette case est activée (valeur par défaut), le service écrit les fichiers décompressés dans
Si vous sélectionnez le type de compression TarGZip/tar, l’option Conserver le nom du fichier de compression en tant que dossier s’affiche sous les paramètres Avancés dans l’onglet Source.
- Conserver le nom du fichier de compression en tant que dossier : indique si le nom du fichier compressé source doit être conservé en tant que structure de dossiers lors de la copie.
- Si cette case est activée (valeur par défaut), le service écrit les fichiers décompressés dans
<specified file path>/<folder named as source compressed file>/. - Si cette case est décochée, le service écrit les fichiers décompressés directement dans
<specified file path>. Assurez-vous de ne pas avoir de noms de fichiers en double dans différents fichiers sources afin d’éviter toute course ou tout comportement inattendu.
- Si cette case est activée (valeur par défaut), le service écrit les fichiers décompressés dans
- Conserver le nom du fichier zip en tant que dossier : indique si le nom du fichier zip source doit être conservé en tant que structure de dossiers lors de la copie.
Niveau de compression : spécifiez le taux de compression lorsque vous sélectionnez un type de compression. Vous pouvez choisir entre Le plus rapide ou Optimal.
- Fastest : l'opération de compression doit se terminer le plus rapidement possible, même si le fichier résultant n'est pas compressé de façon optimale.
- Optimal : l’opération de compression doit aboutir à une compression optimale, même si elle prend plus de temps. Pour plus d’informations, consultez la rubrique Niveau de compression.
Encodage : spécifiez le type de codage utilisé pour écrire des fichiers de test. Sélectionnez un type dans la liste déroulante. La valeur par défaut est UTF-8.
Valeur null : Spécifie la représentation sous forme de chaîne de la valeur null. La valeur par défaut est une chaîne vide.
Dans la section des paramètres Avancés sous l’onglet Source, les propriétés suivantes relatives au format XML sont affichées.
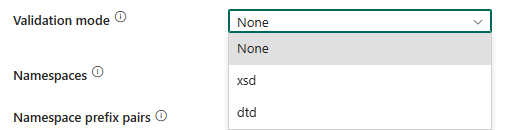
Mode de validation : spécifie s’il faut valider le schéma XML. Sélectionnez un mode dans la liste déroulante.
- Aucun : sélectionnez cette option pour ne pas utiliser le mode de validation.
- xsd : sélectionnez cette option pour valider le schéma XML à l’aide de XSD.
- dtd : sélectionnez cette option pour valider le schéma XML à l’aide de DTD.
Espaces de noms : spécifiez s’il faut activer l’espace de noms lors de l’analyse des fichiers XML. Il est sélectionné par défaut.
Paires de préfixes d’espaces de noms : si les espaces de noms sont activés, sélectionnez + Nouveau et spécifiez l’URL et le préfixe. Vous pouvez ajouter d’autres paires en sélectionnant + Nouveau.
Le mappage d’URI d’espace de noms à préfixe est utilisé pour nommer les champs lors de l’analyse du fichier XML. Si un fichier XML a un espace de noms et que celui-ci est activé, par défaut, le nom du champ est le même que dans le document XML. Si un élément est défini pour l’URI d’espace de noms dans ce mappage, le nom du champ estprefix:fieldName.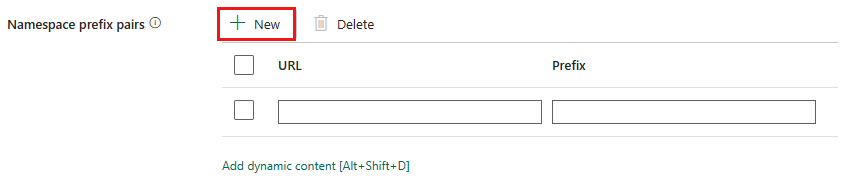
Détecter le type de données : spécifiez s’il faut détecter des types de données entiers, doubles et booléens. Il est sélectionné par défaut.
Les propriétés suivantes sont prises en charge dans la section Source de l’activité de copie lors de l’utilisation du format XML.
| Nom | Description | Valeur | Obligatoire | Propriété de script JSON |
|---|---|---|---|---|
| Format de fichier | Le format de fichier que vous souhaitez utiliser. | XML | Oui | type (sous datasetSettings) :Xml |
| Type de compression | Le codec de compression utilisé pour lire les fichiers XML. | Aucun bzip2 gzip deflate ZipDeflate TarGZip tar |
Non | type (sous compression) :bzip2 gzip deflate ZipDeflate TarGZip tar |
| Niveau de compression | Le taux de compression. | Fastest Optimal |
Aucune | level (sous compression) :Le plus rapide Optimal |
| Encodage | Le type de codage utilisé pour lire des fichiers de test. | "UTF-8" (par défaut),"UTF-8 without BOM", "UTF-16LE", "UTF-16BE", "UTF-32LE", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Aucune | encodingName |
| Conserver le nom du fichier zip en tant que dossier | Indique si le nom du fichier zip source doit être conservé en tant que structure de dossiers lors de la copie. | Sélectionné (par défaut) ou non sélectionné | Non | preserveZipFileNameAsFolder (sous compressionProperties–>type en tant que ZipDeflateReadSettings) :true (valeur par défaut) ou false |
| Conserver le nom du fichier de compression en tant que dossier | Indique si le nom du fichier source compressé doit être conservé en tant que structure de dossiers lors de la copie. | Sélectionné (par défaut) ou non sélectionné | Non | preserveCompressionFileNameAsFolder (sous compressionProperties–>type en tant que TarGZipReadSettings ou TarReadSettings) :true (valeur par défaut) ou false |
| Valeur null | La représentation sous forme de chaîne de la valeur null. | <votre valeur null> chaîne vide (par défaut) |
Aucune | nullValue |
| Mode de validation | Spécifier s’il faut valider le schéma XML. | Aucun xsd dtd |
Non | validationMode : xsd dtd |
| Espaces de noms | Indique s’il faut activer l’espace de noms lors de l’analyse des fichiers XML. | Sélectionné (par défaut) ou non sélectionné | Non | espaces de noms : true (valeur par défaut) ou false |
| Paires de préfixes d’espaces de noms | Le mappage d’URI d’espace de noms à préfixe, utilisé pour nommer les champs lors de l’analyse du fichier XML. Si un fichier XML a un espace de noms et que celui-ci est activé, par défaut, le nom du champ est le même que dans le document XML. Si un élément est défini pour l’URI d’espace de noms dans ce mappage, le nom du champ est prefix:fieldName. |
< url > :< préfixe > | Non | namespacePrefixes : < url > :< préfixe > |
| Détecter le type de données | Indique s’il faut détecter les types de données entier, double et booléen. | Sélectionné (par défaut) ou non sélectionné | Non | detectDataType : true (valeur par défaut) ou false |