Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Microsoft Dataverse est la plateforme de données standard pour de nombreux produits d’application métier Microsoft, dont Dynamics 365 Customer Engagement et les applications de canevas Power Apps, ainsi que Dynamics 365 Customer Voice (anciennement Microsoft Forms Pro), les approbations Power Automate, les portails Power Apps et autres.
Cet article fournit des conseils sur la création d’un modèle de données Power BI qui se connecte à Dataverse. Il décrit les différences entre un schéma Dataverse et un schéma Power BI optimisé, et fournit des conseils pour étendre la visibilité de vos données d’application métier dans Power BI.
En raison de sa facilité d’installation, de son déploiement rapide et de son adoption à grande échelle, Dataverse stocke et gère un volume croissant de données dans les environnements des organisations. Cela signifie que le besoin et les perspectives d’intégration de l’analytique à ces processus sont encore plus importants. Ces perspectives sont les suivantes :
- Établir des rapports sur toutes les données Dataverse au-delà des contraintes des graphiques intégrés.
- Proposer un accès facile à des rapports pertinents et filtrés en fonction du contexte au sein d’un enregistrement spécifique.
- Améliorer la valeur des données Dataverse en les intégrant à des données externes.
- Tirer parti de l’intelligence artificielle (IA) intégrée de Power BI sans avoir à écrire du code complexe.
- Accroître l’adoption de solutions Power Platform en accentuant leur utilité et leur valeur.
- Fournir la valeur des données de votre application aux décideurs d’entreprises.
Connecter Power BI à Dataverse
La connexion de Power BI à Dataverse implique de créer un modèle de données Power BI. Pour cela, vous avez le choix entre trois méthodes.
- Importer des données Dataverse à l’aide du connecteur Dataverse: cette méthode met en cache (stocke) les données Dataverse dans un modèle Power BI. Elle assure un niveau de performance élevé grâce à l’interrogation en mémoire. De même, elle offre aux modélisateurs une certaine souplesse de conception en leur permettant d’intégrer des données issues d’autres sources. Du fait de ces points forts, l’importation de données est le mode par défaut lors de la création d’un modèle dans Power BI Desktop.
- Importer des données Dataverse à l’aide d’Azure Synapse Link: cette méthode est une variante de la méthode d’importation, car elle met également en cache les données dans le modèle Power BI, mais en se connectant à Azure Synapse Analytics. En utilisant Azure Synapse Link for Dataverse, les tables Dataverse sont répliquées en continu vers Azure Synapse ou Azure Data Lake Storage (ADLS) Gen2. Cette approche permet de générer des rapports sur des centaines de milliers, voire des millions d’enregistrements d’environnements Dataverse.
- Créer une connexion DirectQuery à l’aide du connecteur Dataverse: cette méthode est une alternative à l’importation de données. Un modèle DirectQuery se compose uniquement de métadonnées définissant la structure du modèle. Quand un utilisateur ouvre un rapport, Power BI envoie des requêtes natives à Dataverse pour récupérer les données. Envisagez de créer un modèle DirectQuery quand les rapports doivent afficher des données Dataverse en quasi-temps réel ou que Dataverse doit appliquer une sécurité basée sur les rôles de sorte que les utilisateurs puissent voir uniquement les données auxquelles ils ont accès.
Important
S’il s’avère qu’un modèle DirectQuery peut être une bonne alternative en cas de nécessité de rapports en quasi-temps réel ou de l’application de la sécurité Dataverse dans un rapport, il peut ralentir les performances pour ces rapports.
Vous pourrez découvrir les éléments à prendre en considération pour DirectQuery plus loin dans cet article.
Pour déterminer la méthode adaptée à votre modèle Power BI, vous devez tenir compte des éléments suivants :
- Performances des requêtes
- Volume de données
- Latence des données
- Sécurité basée sur les rôles
- Complexité de l’installation
Conseil
Pour un exposé détaillé sur les infrastructures de modèles (importation, DirectQuery ou composite), leurs avantages et leur limitations, ainsi que les fonctionnalités permettant d’optimiser les modèles de données Power BI, consultez Choisir une infrastructure de modèles Power BI.
Performances des requêtes
Les requêtes envoyées pour importer des modèles sont plus rapides que les requêtes natives envoyées aux sources de données DirectQuery. Cela s’explique par le fait que les données importées sont mises en cache en mémoire et optimisées pour les requêtes analytiques (opérations de filtrage, de regroupement et de synthèse).
À l’inverse, les modèles DirectQuery récupèrent uniquement les données après de la source après que l’utilisateur a ouvert un rapport, ce qui retarde de quelques secondes le rendu du rapport. Par ailleurs, les interactions de l’utilisateur au niveau du rapport imposent à Power BI de réinterroger la source, ce qui réduire un peu plus la réactivité.
Volume de données
Quand vous développez un modèle d’importation, vous devez vous efforcer de réduire au minimum les données qui sont chargées dans le modèle. C’est particulièrement vrai pour les modèles volumineux ou qui sont amenés à croître au fil du temps. Pour plus d’informations, consultez Techniques de réduction des données pour la modélisation des importations.
Une connexion DirectQuery à Dataverse est un bon choix quand le résultat de la requête du rapport n’est pas volumineux. Un résultat de requête volumineux présente plus de 20 000 lignes dans les tables sources du rapport, ou le résultat retourné au rapport après application des filtres compte plus de 20 000 lignes. Dans ce cas, vous pouvez créer un rapport Power BI à l’aide du connecteur Dataverse.
Notes
La taille de 20 000 lignes n’est pas une limite absolue. Cependant, chaque requête de source de données doit retourner un résultat dans un délai de 10 minutes. Plus loin dans cet article, vous verrez comment respecter ces limitations et découvrirez d’autres éléments à prendre en considération pour la conception DirectQuery avec Dataverse.
Vous pouvez améliorer les performances des modèles sémantiques plus volumineux à l’aide du connecteur Dataverse pour importer les données dans le modèle de données.
Même les modèles sémantiques volumineux, comptant plusieurs centaines de milliers, voire plusieurs millions de lignes, peuvent bénéficier de l’utilisation d’Azure Synapse Link pour Dataverse. Cette approche crée un pipeline managé continu qui copie les données Dataverse dans ADLS Gen2 sous forme de fichiers CSV ou Parquet. Power BI peut ensuite interroger un pool SQL serverless Azure Synapse pour charger un modèle d’importation.
Latence des données
Quand les données Dataverse changent rapidement et que les utilisateurs de rapports ont besoin de voir des données à jour, un modèle DirectQuery peut fournir des résultats de requête en quasi-temps réel.
Conseil
Vous pouvez créer un rapport Power BI qui utilise l’actualisation automatique des pages pour afficher les mises à jour en temps réel, mais uniquement lorsque le rapport se connecte à un modèle DirectQuery.
Les modèles de données d’importation doivent effectuer une actualisation des données pour permettre la création de rapports sur les modifications de données récentes. Gardez à l’esprit qu’il existe des limitations quant au nombre d’opérations d’actualisation de données planifiées quotidiennes. Vous pouvez planifier jusqu’à huit actualisations par jour au niveau d’une capacité partagée. Sur une capacité Premium ou capacité Microsoft Fabric, vous pouvez planifier jusqu’à 48 actualisations par jour, ce qui peut atteindre une fréquence d’actualisation de 15 minutes.
Important
Cet article fait référence à Power BI Premium ou à ses abonnements de capacité (SKU P). Actuellement, Microsoft consolide les options d’achat et met hors service les références SKU Power BI Premium par capacité. Les clients nouveaux et existants doivent plutôt envisager l’achat d’abonnements de capacité Fabric (SKU F).
Pour plus d’informations, consultez Importante mise à jour à venir des licences Power BI Premium et FAQ sur Power BI Premium.
Vous pouvez également envisager d’utiliser d’actualisation incrémentielle pour obtenir des actualisations plus rapides et performances de quasiment en temps réel (disponible uniquement avec Premium ou Fabric).
Sécurité basée sur les rôles
Quand il est nécessaire d’appliquer une sécurité basée sur les rôles, cela peut influencer directement le choix de l’infrastructure de modèles Power BI.
Dataverse peut appliquer une sécurité basée sur les rôles complexe pour contrôler l’accès d’enregistrements spécifiques à des utilisateurs spécifiques. Par exemple, un vendeur peut être autorisé à voir uniquement ses opportunités de vente, tandis que le responsable des ventes peut voir toutes les opportunités de vente de tous les vendeurs. Vous pouvez adapter le niveau de complexité en fonction des besoins de votre organisation.
Un modèle DirectQuery basé sur Dataverse peut se connecter en utilisant le contexte de sécurité de l’utilisateur de rapports. Ainsi, l’utilisateur de rapports ne voit que les données auxquelles il est autorisé à accéder. Cette approche peut simplifier la conception de rapports, à condition que les performances soient acceptables.
Pour de meilleures performances, vous pouvez créer un modèle d’importation qui se connecte plutôt à Dataverse. Dans ce cas, vous pouvez ajouter la sécurité au niveau des lignes (SNL) au modèle, si nécessaire.
Notes
Il peut être difficile de répliquer une sécurité basée sur les rôles Dataverse en tant que SNL Power BI, en particulier lorsque Dataverse applique des autorisations complexes. En outre, cela peut demander une gestion continue pour que les autorisations Power BI restent synchronisées avec les autorisations Dataverse.
Pour plus d’informations sur la SNL Power BI, consultez Aide sur la sécurité au niveau des lignes (SNL) dans Power BI Desktop.
Complexité de l’installation
L’utilisation du connecteur Dataverse dans Power BI, que ce soit pour les modèles d’importation ou DirectQuery, est simple et ne nécessite pas de logiciels spéciaux ou d’autorisations Dataverse élevées. Il s’agit d’un avantage pour les organisations ou les services qui débutent.
L’option Azure Synapse Link demande un accès d’administrateur système à Dataverse et certaines autorisations Azure. Ces autorisations Azure sont nécessaires pour créer le compte de stockage et un espace de travail Synapse.
Pratiques recommandées
Cette section décrit les modèles de conception (et les anti-modèles) que vous devez prendre en compte au moment de créer un modèle Power BI qui se connecte à Dataverse. Seuls quelques-uns de ces modèles sont propres à Dataverse, mais ils ont tendance à poser des problèmes aux créateurs Dataverse quand il s’agit de créer des rapports Power BI.
Se concentrer sur un cas d’usage spécifique
Plutôt que d’essayer de tout résoudre, concentrez-vous sur le cas d’usage précis.
Cette recommandation est probablement l’anti-modèle le plus courant et facilement le plus difficile à éviter. Il est difficile de créer un modèle unique qui permette de répondre à tous les besoins de création de rapports en libre-service. Le fait est que les modèles réussis sont conçus pour répondre à des questions autour d’un ensemble central de faits sur un sujet central unique. Bien que cela puisse a priori sembler limitatif, c’est en fait avantageux dans le sens où vous pouvez ajuster et optimiser le modèle pour répondre aux questions relevant de ce sujet.
Pour être certain de bien comprendre l’objectif du modèle, posez-vous les questions suivantes.
- Quel sujet spécifique ce modèle soutiendra-t-il ?
- À quel public les rapports s’adressent-ils ?
- À quelles questions les rapports tentent-ils de répondre ?
- Quel est le modèle sémantique minimal viable ?
Évitez de combiner plusieurs sujets spécifiques dans un même modèle simplement parce que l’utilisateur de rapports a des questions sur plusieurs sujets spécifiques qu’il souhaite voir traités par un même rapport. En scindant ce rapport en plusieurs rapports, chacun axé sur un sujet (ou une table de faits) différent, vous pouvez produire des modèles beaucoup plus efficaces, évolutifs et gérables.
Concevoir un schéma en étoile
Les développeurs et administrateurs Dataverse qui sont à l’aise avec le schéma Dataverse peuvent être tentés de reproduire le même schéma dans Power BI. Cette approche est un anti-modèle, et c’est probablement le plus difficile à surmonter, car il est de bon ton d’assurer la cohérence.
En tant que modèle relationnel, Dataverse est bien adapté à son objectif. Cependant, il n’est pas conçu en tant que modèle analytique optimisé pour les rapports analytiques. Le modèle le plus répandu pour la modélisation de données d’analyse est une conception de schéma en étoile. Le schéma en étoile est une approche de modélisation mature largement adoptée par les entrepôts de données relationnels. Les modélisateurs doivent classer leurs tables de modèle en tant que table de dimension ou table de faits. Les rapports peuvent filtrer ou regrouper en utilisant les colonnes de la table de dimensions
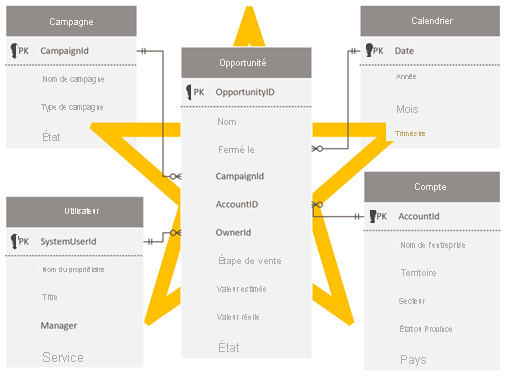
Pour plus d’informations, consultez Comprendre le schéma en étoile et son importance pour Power BI.
Optimiser les requêtes Power Query
Le Moteur Mashup Power Query s’efforce de mener à bien le Query Folding (pliage des requêtes) dans la mesure du possible, pour des raisons d’efficacité. Une requête qui effectue le pliage délègue le traitement des requêtes au système source.
Le système source, en l’occurrence Dataverse, a seulement besoin de fournir des résultats filtrés ou synthétisés à Power BI. Une requête pliée est souvent beaucoup plus rapide et plus efficace qu’une requête qui ne se plie pas.
Pour plus d’informations sur la façon de mener à bien le Query Folding, consultez Pliage des requêtes Power Query.
Notes
L’optimisation de Power Query est un large sujet. Pour mieux comprendre ce que fait Power Query au moment de la création et de l’actualisation de modèle dans Power BI Desktop, consultez Diagnostics de requête.
Réduire le nombre de colonnes de requête
Par défaut, quand vous utilisez Power Query pour charger une table Dataverse, l’ensemble des lignes et des colonnes sont récupérées. Quand vous interrogez une table utilisateur système, par exemple, elle peut contenir plus de 1 000 colonnes. Les colonnes contenues dans les métadonnées comportent les relations aux autres entités et les recherches dans les étiquettes d’options, si bien que le nombre total de colonnes augmente à mesure que la table Dataverse gagne en complexité.
Tenter de récupérer les données de toutes les colonnes est un anti-modèle. Cela donne souvent lieu à des opérations d’actualisation des données étendues et provoque l’échec de la requête quand le temps nécessaire pour retourner les données dépasse 10 minutes.
Nous vous recommandons de récupérer uniquement les colonnes nécessaires aux rapports. Il est souvent judicieux de réévaluer et de refactoriser les requêtes une fois que le développement du rapport est terminé, ce qui vous permet d’identifier et de supprimer les colonnes non utilisées. Pour plus d’informations, consultez Techniques de réduction des données pour la modélisation des importations (Supprimer les colonnes non nécessaires).
Par ailleurs, veillez à introduire l’étape Power Query Supprimer les colonnes à un stade précoce pour permettre un pliage dans la source. Power Query peut ainsi éviter le travail inutile d’extraction de données sources uniquement pour les ignorer par la suite (dans une étape qui s’est déroulée).
Quand vous disposez d’une table contenant un grand nombre colonnes, il n’est pas nécessaire commode d’utiliser le générateur de requêtes interactif Power Query. Dans ce cas, vous pouvez commencer par créer une requête vide. Vous pouvez ensuite utiliser l’Éditeur avancé pour coller une requête minimale qui crée un point de départ.
Considérez la requête suivante qui récupère des données à partir de deux colonnes seulement de la table account.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name"})
in
#"Removed Other Columns"
Écrire des requêtes natives
Quand vous avez des exigences de transformation spécifiques, vous pouvez espérer bénéficier d’un meilleur niveau de performance en utilisant une requête native écrite en Dataverse SQL, qui est un sous-ensemble de Transact-SQL. Vous pouvez écrire une requête native pour :
- Réduire le nombre de lignes (à l’aide d’une clause
WHERE). - Agréger des données (à l’aide des classes
GROUP BYetHAVING). - Joindre des tables d’une manière spécifique (à l’aide de la syntaxe
JOINouAPPLY). - Utiliser des fonctions SQL prises en charge.
Pour plus d'informations, consultez les pages suivantes :
Exécuter des requêtes natives avec l’option EnableFolding
Power Query exécute une requête native à l’aide de la fonction Value.NativeQuery.
Au moment d’utiliser cette fonction, il est important d’ajouter l’option EnableFolding=true pour garantir que les requêtes sont pliées dans le service Dataverse. Une requête native ne se plie que si cette option est ajoutée. L’activation de cette option peut entraîner des améliorations significatives en termes de performances, avec jusqu’à 97 % de rapidité en plus dans certains cas.
Considérez la requête suivante qui utilise une requête native pour sourcer des colonnes sélectionnées à partir de la table account. La requête native est pliée, car l’option EnableFolding=true est définie.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"),
dbo_account = Value.NativeQuery(
Source,
"SELECT A.accountid, A.name FROM account A"
,null
,[EnableFolding=true]
)
in
dbo_account
Vous pouvez vous attendre à bénéficier des meilleures améliorations de performances en récupérant un sous-ensemble de données à partir d’un important volume de données.
Conseil
L’amélioration des performances peut aussi dépendre de la façon dont Power BI interroge la base de données source. Par exemple, une mesure qui utilise la fonction DAX COUNTDISTINCT n’a montré presque aucune amélioration avec ou sans l’indicateur de pliage. Quand la formule de mesure a été réécrite pour utiliser la fonction DAX SUMX, la requête a été pliée, ce qui s’est traduit par une amélioration de 97 % par rapport à la même requête sans l’indicateur.
Pour plus d'informations, consultez Value.NativeQuery. (L’option EnableFolding n’est pas documentée, car elle est spécifique à certaines sources de données uniquement.)
Accélérer la phase d’évaluation
Si vous utilisez le connecteur Dataverse (anciennement Common Data Service), vous pouvez ajouter l’option CreateNavigationProperties=false pour accélérer la phase d’évaluation d’une importation de données.
La phase d’évaluation d’une importation de données itère dans les métadonnées de sa source pour déterminer toutes les relations de tables possibles. Ces métadonnées peuvent être très complètes, en particulier pour Dataverse. En ajoutant cette option à la requête, vous faites savoir à Power Query que vous n’avez pas l’intention d’utiliser ces relations. L’option permet à Power BI Desktop d’ignorer cette phase de l’actualisation et de passer à la récupération des données.
Notes
N’utilisez pas cette option lorsque la requête dépend de colonnes de relation développées.
Prenons un exemple qui récupère les données de la table account. Il contient trois colonnes liées au territoire : territory, territoryidet territoryidname.
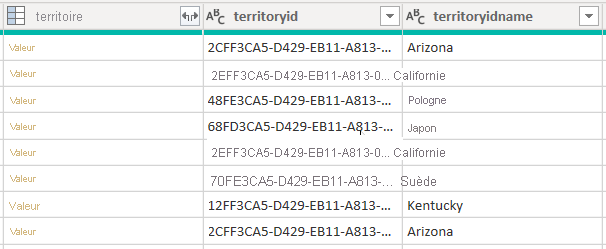
Lorsque vous définissez l’option CreateNavigationProperties=false, les colonnes territoryid et territoryidname resteront, mais la colonne territory, qui est une colonne de relations (elle affiche les liens de valeur de à), sera exclue. Il est important de comprendre que les colonnes de relation Power Query sont un concept différent des relations de modèle, qui propagent des filtres entre les tables de modèle.
Examinez la requête suivante qui utilise l’option CreateNavigationProperties=false (à l’étape Source) pour accélérer la phase d’évaluation d’une importation de données.
let
Source = CommonDataService.Database("demo.crm.dynamics.com"
,[CreateNavigationProperties=false]),
dbo_account = Source{[Schema="dbo", Item="account"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(dbo_account, {"accountid", "name", "address1_stateorprovince", "address1_country", "industrycodename", "territoryidname"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns", {{"name", "Account Name"}, {"address1_country", "Country"}, {"address1_stateorprovince", "State or Province"}, {"territoryidname", "Territory"}, {"industrycodename", "Industry"}})
in
#"Renamed Columns"
Quand vous utilisez cette option, il y a des chances que vous constatiez une amélioration significative des performances quand une table Dataverse présente de nombreuses relations avec d’autres tables. Par exemple, étant donné que la table SystemUser est liée à toutes les autres tables de la base de données, les performances d’actualisation de cette table bénéficient de la définition de l’option CreateNavigationProperties=false.
Notes
Cette option peut améliorer les performances d’actualisation des données des tables d’importation ou des tables en mode de stockage double, y compris le processus d’application des modifications de la fenêtre de l’Éditeur Power Query. Elle n’améliore pas le niveau de performance du filtrage croisé interactif des tables en mode de stockage DirectQuery.
Résoudre les étiquettes de choix vides
Si vous découvrez que les étiquettes de choix Dataverse sont vides dans Power BI, cela peut être le signe que les étiquettes n’ont pas été publiées sur le point de terminaison TDS (Tabular Data Stream).
Dans ce cas, ouvrez le portail Dataverse Maker, accédez à la zone Solutions, puis sélectionnez Publier toutes les personnalisations. Le processus de publication met alors à jour le point de terminaison TDS avec les dernières métadonnées, ce qui permet à Power BI d’accéder aux étiquettes d’option.
Modèles sémantiques plus volumineux avec Azure Synapse Link
Dataverse offre la possibilité de synchroniser les tables avec Azure Data Lake Storage (ADLS), puis de se connecter à ces données via un espace de travail Azure Synapse. Avec un minimum d’effort, vous pouvez configurer Azure Synapse Link de façon à remplir Azure Synapse avec les données Dataverse et permettre aux équipes de données de découvrir des insights plus approfondis.
Azure Synapse Link permet une réplication continue des données et des métadonnées de Dataverse dans le lac de données. Il fournit également un pool SQL serverless intégré faisant office de source de données pratique pour les requêtes Power BI.
Les points forts de cette approche sont notables. Les clients ont la possibilité d’exécuter des charges de travail d’analytique, de décisionnel et de Machine Learning sur des données Dataverse en utilisant divers services avancés. Il s’agit notamment des services Apache Spark, Power BI, Azure Data Factory, Azure Databricks et Azure Machine Learning.
Créer une liaison Azure Synapse Link for Dataverse
Pour créer une liaison Azure Synapse Link for Dataverse, vous devez satisfaire les prérequis suivants.
- Accès administrateur système à l’environnement Dataverse.
- Pour Azure Data Lake Storage :
- Vous devez disposer d’un compte de stockage à utiliser avec ADLS Gen2.
- Vous devez bénéficier d’un accès Propriétaire des données Blob du stockage et Contributeur aux données Blob du stockage sur le compte de stockage. Pour plus d’informations, consultez Contrôle d'accès en fonction du rôle (Azure RBAC).
- Le compte de stockage doit activer l’espace de noms hiérarchique.
- Le compte de stockage doit de préférence utiliser le stockage géoredondant avec accès en lecture (RA-GRS).
- Pour l’espace de travail Synapse :
- Vous devez avoir accès à un espace de travail Synapse et disposer d’un accès Administrateur Synapse. Pour plus d’informations, consultez Rôles RBAC Synapse intégrés et étendues.
- L’espace de travail doit se trouver dans la même région que le compte de stockage ADLS Gen2.
La configuration implique de se connecter à Power Apps et de connecter de Dataverse à l’espace de travail Azure Synapse. Une expérience semblable à un Assistant vous permet de créer une liaison en sélectionnant le compte de stockage et les tables à exporter. Azure Synapse Link copie ensuite les données dans le stockage ADLS Gen2 et crée automatiquement des vues dans le pool SQL serverless Azure Synapse intégré. Vous pouvez ensuite vous connecter à ces vues pour créer un modèle Power BI.
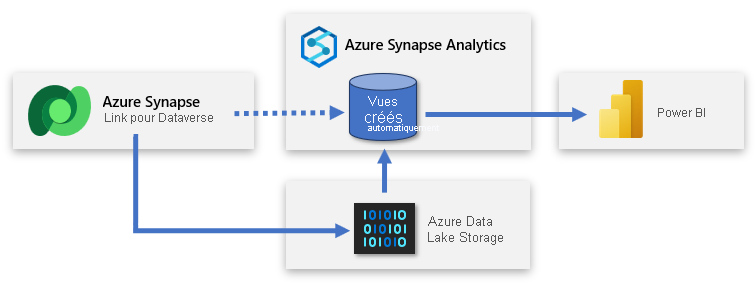
Conseil
Pour obtenir une documentation complète sur la création, la gestion et la supervision d’une liaison Azure Synapse Link, consultez Créer une liaison Azure Synapse for Dataverse avec votre espace de travail Azure Synapse.
Créer une deuxième base de données SQL serverless
Vous pouvez créer une deuxième base de données SQL serverless et vous en servir pour ajouter des vues personnalisées de rapport. De cette façon, vous pouvez présenter un ensemble simplifié de données au créateur Power BI qui lui permettra de créer un modèle basé sur des données utiles et pertinentes. La nouvelle base de données SQL serverless devient la connexion source principale du créateur et une représentation conviviale des données provenant du lac de données.
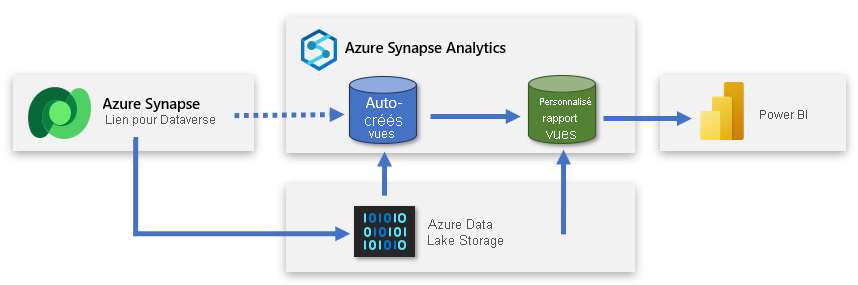
Cette approche fournit à Power BI des données ciblées, enrichies et filtrées.
Vous pouvez créer une base de données SQL serverless dans l’espace de travail Azure Synapse à l’aide d’Azure Synapse Studio. Sélectionnez Serverless comme type de base de données SQL et entrez un nom de base de données. Power Query peut se connecter à cette base de données en se connectant au point de terminaison SQL de l’espace de travail.
Créer des vues personnalisées
Vous pouvez créer des vues personnalisées qui encapsulent des requêtes de pool SQL serverless. Ces vues serviront de sources de données simples et propres auxquelles Power BI se connectera. Ces vues doivent :
- Inclure les étiquettes associées aux champs de choix.
- Limiter la complexité en incluant uniquement les colonnes nécessaires à la modélisation des données.
- Filtrer les lignes inutiles, telles que les enregistrements inactifs.
Examinez la vue suivante qui récupère des données de campagne.
CREATE VIEW [VW_Campaign]
AS
SELECT
[base].[campaignid] AS [CampaignID]
[base].[name] AS [Campaign],
[campaign_status].[LocalizedLabel] AS [Status],
[campaign_typecode].[LocalizedLabel] AS [Type Code]
FROM
[<MySynapseLinkDB>].[dbo].[campaign] AS [base]
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[OptionsetMetadata] AS [campaign_typecode]
ON [base].[typecode] = [campaign_typecode].[option]
AND [campaign_typecode].[LocalizedLabelLanguageCode] = 1033
AND [campaign_typecode].[EntityName] = 'campaign'
AND [campaign_typecode].[OptionSetName] = 'typecode'
LEFT OUTER JOIN [<MySynapseLinkDB>].[dbo].[StatusMetadata] AS [campaign_status]
ON [base].[statuscode] = [campaign_Status].[status]
AND [campaign_status].[LocalizedLabelLanguageCode] = 1033
AND [campaign_status].[EntityName] = 'campaign'
WHERE
[base].[statecode] = 0;
Notez que la vue comprend seulement quatre colonnes, chacune disposant d’un alias sous la forme d’un nom convivial. Il existe également une clause WHERE pour retourner uniquement les lignes nécessaires, dans ce cas les campagnes actives. De même, la vue interroge la table de campagne jointe aux tables OptionsetMetadataet StatusMetadata, qui récupèrent les étiquettes de choix.
Conseil
Pour plus d’informations sur la récupération de métadonnées, consultez Accéder aux étiquettes de choix directement à partir d’Azure Synapse Link for Dataverse.
Interroger les tables appropriées
Azure Synapse Link for Dataverse garantit que les données sont synchronisées en continu avec les données du lac de données. Pour les activités à utilisation intensive, les écritures et les lectures simultanées peuvent créer des verrous qui entraînent l’échec des requêtes. Pour assurer la fiabilité pendant la récupération des données, deux versions des données de table sont synchronisées dans Azure Synapse.
- données en quasi-temps réel: fournit une copie des données synchronisées à partir de Dataverse via Azure Synapse Link de manière efficace en détectant les données qui ont changé depuis son extraction initiale ou sa dernière synchronisation.
- données d’instantané: fournit une version en lecture seule de données en quasi temps réel mises à jour à intervalles réguliers (dans ce cas, toutes les heures). Les tables de données d’instantanés se voient ajouter _partitioned à leur nom.
Si vous prévoyez l’exécution simultanée d’un volume important d’opérations de lecture et d’écriture, récupérez les données des tables d’instantanés pour éviter les échecs de requête.
Pour plus d’informations, consultez Accéder aux données en quasi-temps réel et aux données d’instantané en lecture seule.
Se connecter à Synapse Analytics
Pour interroger un pool SQL serverless Azure Synapse, vous aurez besoin de son point de terminaison SQL d’espace de travail. Vous pouvez récupérer le point de terminaison à partir de Synapse Studio en ouvrant les propriétés du pool SQL serverless.
Dans Power BI Desktop, vous pouvez vous connecter à Azure Synapse à l’aide du connecteur SQL Azure Synapse Analytics. Quand vous êtes invité à entrer le serveur, entrez le point de terminaison SQL de l’espace de travail.
Éléments à prendre en considération pour DirectQuery
Il existe un grand nombre de cas d’usage où le mode de stockage DirectQuery peut répondre à vos besoins. Cependant, l’utilisation de DirectQuery peut influer négativement sur les performances des rapports Power BI. Un rapport qui utilise une connexion DirectQuery à Dataverse ne sera pas aussi rapide qu’un rapport qui utilise un modèle d’importation. En règle générale, vous avez tout intérêt à importer les données dans Power BI dans la mesure du possible.
Si vous utilisez DirectQuery, nous vous recommandons de consulter les rubriques de cette section.
Pour mieux savoir dans quels cas utiliser le mode de stockage DirectQuery, consultez Choisir une infrastructure de modèles Power BI.
Utiliser des tables de dimension en mode de stockage double
Une table en mode de stockage Double est définie pour utiliser les modes de stockage Importer et DirectQuery. Au moment de la requête, Power BI détermine le mode le plus efficace à utiliser. Dans la mesure du possible, Power BI tente de satisfaire les requêtes en utilisant des données importées, car cela est plus rapide.
Envisagez de définir les tables de dimension en mode de stockage double, le cas échéant. Ainsi, les visuels de segments et les listes de cartes de filtre, qui sont souvent basées sur des colonnes de table de dimension, s’affichent plus rapidement, car ils sont interrogés à partir de données importées.
Important
Quand une table de dimension doit hériter du modèle de sécurité Dataverse, il n’est pas approprié d’utiliser le mode de stockage double.
Les tables de faits, qui stockent généralement de gros volumes de données, doivent rester des tables en mode de stockage DirectQuery. Elles seront filtrées par les tables de dimension en mode de stockage double associées, qui peuvent être jointes à la table de faits pour parvenir à un filtrage et un regroupement efficaces.
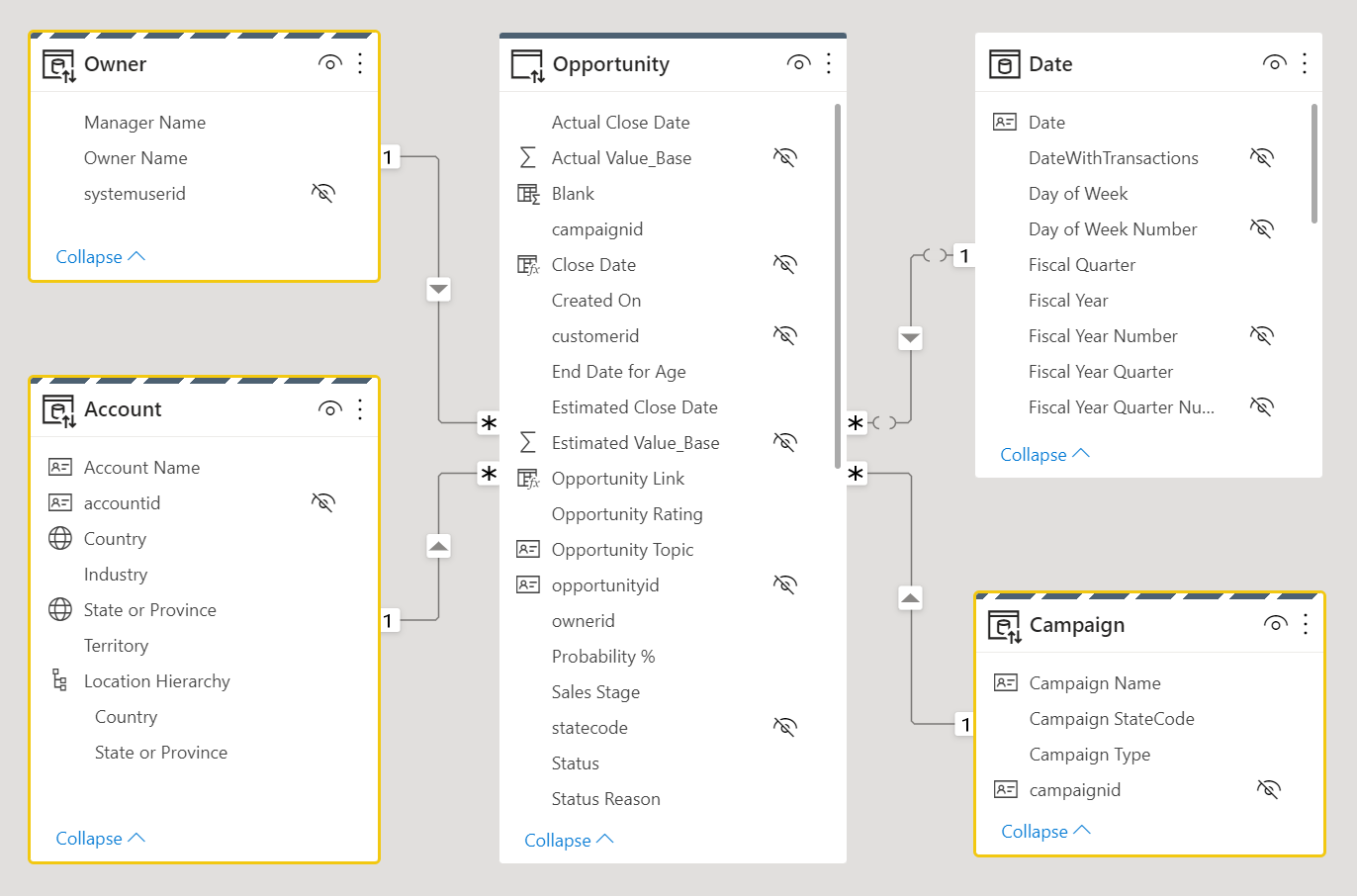
Examinez la conception de modèle de données suivant. Trois tables de dimension, Owner, Accountet Campaign ont une bordure supérieure rayée, ce qui signifie qu'elles sont paramétrées en mode de stockage double.
Pour plus d’informations sur les modes de stockage de table, notamment le stockage double, consultez Gérer le mode de stockage dans Power BI Desktop.
Activer l’authentification unique
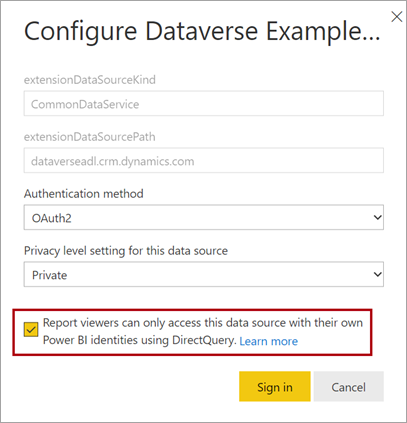
Lorsque vous publiez un modèle DirectQuery sur le service Power BI, vous pouvez utiliser les paramètres du modèle sémantique pour activer l’authentification unique (SSO) à l’aide de l’ID OAuth2 Microsoft Entra pour vos utilisateurs de rapports. Vous devez activer cette option quand les requêtes Dataverse doivent s’exécuter dans le contexte de sécurité de l’utilisateur de rapport.
Quand l’option authentification unique est activée, Power BI envoie les informations d’identification Microsoft Entra authentifiées de l’utilisateur du rapport contenues dans les requêtes à Dataverse. Cette option permet à Power BI d’honorer les paramètres de sécurité qui sont configurés dans la source de données.
Pour plus d’informations, consultez Authentification unique (SSO) pour les sources DirectQuery.
Répliquer « Mes » filtres dans Power Query
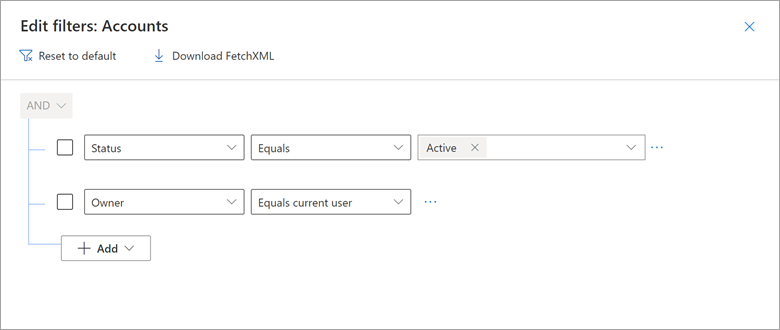
Lorsque vous utilisez Microsoft Dynamics 365 Customer Engagement (CE) et power Apps pilotés par modèle basés sur Dataverse, vous pouvez créer des vues qui affichent uniquement les enregistrements où un champ nom d’utilisateur, tel que Owner, est égal à l’utilisateur actuel. Par exemple, vous pouvez créer des vues nommées « Mes opportunités ouvertes », « Mes cas actifs », etc.
Prenons un exemple de la façon dont la vue Dynamics 365 Mes comptes actifs inclut le filtre Propriétaire est égal à l’utilisateur actuel.
Vous pouvez reproduire ce résultat dans Power Query à l’aide d’une requête native qui incorpore le jeton CURRENT_USER.
Prenons l’exemple suivant qui montre une requête native qui retourne les comptes de l’utilisateur actuel. Dans la clause WHERE, notez que la colonne ownerid est filtrée par le jeton CURRENT_USER.
let
Source = CommonDataService.Database("demo.crm.dynamics.com", [CreateNavigationProperties=false],
dbo_account = Value.NativeQuery(Source, "
SELECT
accountid, accountnumber, ownerid, address1_city, address1_stateorprovince, address1_country
FROM account
WHERE statecode = 0
AND ownerid = CURRENT_USER
", null, [EnableFolding]=true])
in
dbo_account
Quand vous publiez le modèle sur le service Power BI, vous devez activer l’authentification unique (SSO) de sorte que Power BI envoie les informations d’identification Microsoft Entra authentifiées de l’utilisateur de rapport au Dataverse.
Créer des modèles d’importation supplémentaires
Vous pouvez créer un modèle DirectQuery qui applique des autorisations Dataverse tout en sachant que le niveau de performance sera faible. Vous pouvez ensuite compléter ce modèle avec des modèles d’importation qui ciblent des sujets ou des publics spécifiques qui peuvent appliquer des autorisations SNL.
Par exemple, un modèle d’importation pourrait donner accès à toutes les données Dataverse, mais n’appliquer aucune autorisation. Ce modèle pourrait convenir à des cadres disposant déjà d’un accès à toutes les données Dataverse.
Autre exemple : quand Dataverse applique des autorisations basées sur les rôles par région commerciale, vous pourriez créer un modèle d’importation et répliquer ces autorisations en utilisant la SNL. Vous pourriez également créer un modèle pour chaque région commerciale. Vous pouvez ensuite accorder une autorisation en lecture de ces modèles (modèles sémantiques) aux vendeurs de chaque région. Pour faciliter la création de ces modèles régionaux, vous pouvez utiliser des paramètres et des modèles de rapport. Pour plus d’informations, consultez Créer et utiliser des modèles de rapport dans Power BI Desktop.
Contenu connexe
Pour plus d’informations en rapport avec cet article, consultez les ressources suivantes.
- Azure Synapse Link pour Dataverse
- Comprendre le schéma en étoile et son importance pour Power BI
- Techniques de réduction des données pour la modélisation des importations
- Des questions ? Essayez de demander à la communauté Fabric
- Vous avez des suggestions ? Envoyez-nous vos idées pour améliorer Fabric