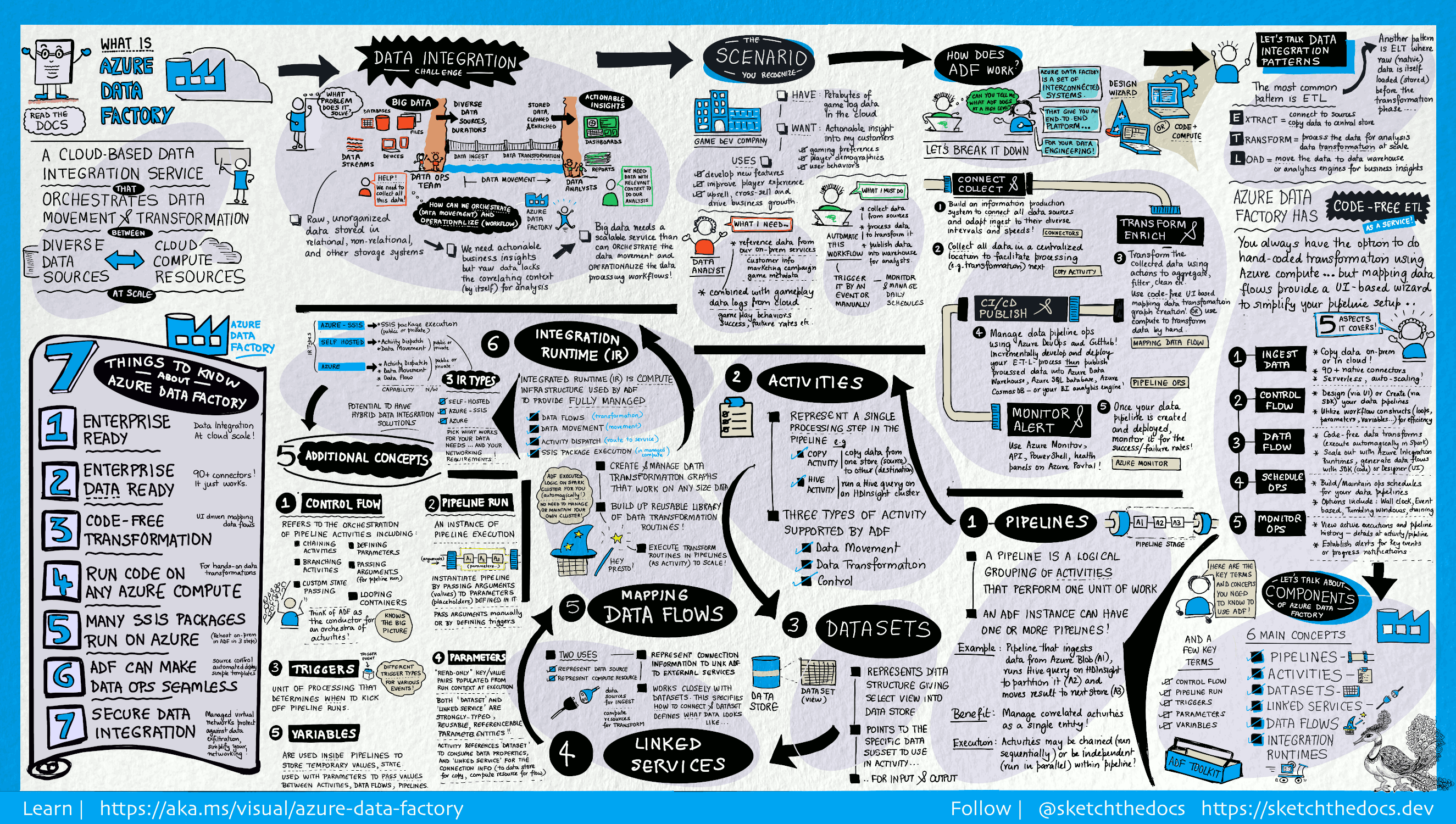
Mi az az Azure Data Factory?
A következőkre vonatkozik:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
A big data világában a nyers, rendezetlen adatok tárolása leggyakrabban relációs, nem relációs vagy egyéb tárolórendszerekben történik. A nyers adatok önmagukban azonban nem biztosítanak megfelelő környezetet, sem értelmezhető elemzési lehetőségeket az elemzők, adatelemzők vagy üzleti döntéshozók számára.
A big data olyan szolgáltatást igényel, amely képes folyamatok vezénylésére és üzembe helyezésére a nyers adatok hatalmas tárolóinak végrehajtható üzleti elemzésekké való finomításához. Az Azure Data Factory egy ilyen, az összetett hibrid ETL-, ELT- és adatintegrációs projektek kezelésre szolgáló felügyelt felhőszolgáltatás.
Az Azure Data Factory funkciói
Adattömörítés: Az adatok Copy tevékenység során tömörítheti az adatokat, és a tömörített adatokat a cél adatforrásba írhatja. Ez a funkció segít optimalizálni a sávszélesség-használatot az adatmásolás során.
A különböző adatforrások széles körű kapcsolati támogatása: Az Azure Data Factory széles körű kapcsolati támogatást nyújt a különböző adatforrásokhoz való csatlakozáshoz. Ez akkor hasznos, ha különböző adatforrásokból szeretne adatokat lekérni vagy írni.
Egyéni eseményindítók: Az Azure Data Factory lehetővé teszi az adatfeldolgozás automatizálását egyéni eseményindítók használatával. Ezzel a funkcióval automatikusan végrehajthat egy bizonyos műveletet egy adott esemény bekövetkezésekor.
Adatelőnézet és érvényesítés: Az adatok Copy tevékenység során az adatok előnézetének megtekintéséhez és ellenőrzéséhez eszközök állnak rendelkezésre. Ezzel a funkcióval biztosítható, hogy az adatok megfelelően legyenek másolva és a cél adatforrásba írva.
Testreszabható Adatfolyam: Az Azure Data Factory lehetővé teszi testre szabható adatfolyamok létrehozását. Ez a funkció lehetővé teszi egyéni műveletek vagy lépések hozzáadását az adatfeldolgozáshoz.
Integrált biztonság: Az Azure Data Factory olyan integrált biztonsági funkciókat kínál, mint az Entra ID integrációja és a szerepköralapú hozzáférés-vezérlés az adatfolyamokhoz való hozzáférés szabályozásához. Ez a funkció növeli az adatfeldolgozás biztonságát, és védi az adatokat.
Használati forgatókönyvek
Képzeljünk el például egy játékfejlesztő vállalatot, amely több petabájtnyi, a játékok által készített naplót gyűjt össze a felhőben. A vállalat e naplókat szeretné elemezni, hogy betekintést nyerhessen az ügyfelek preferenciáiba, demográfiai adataiba és felhasználói viselkedésébe, hogy ezek alapján azonosítsa az értékesítési és keresztértékesítési lehetőségeket, új funkciókat fejlesszen az üzleti növekedés elősegítése érdekében, és jobb felhasználói élményt nyújtson az ügyfeleinek.
A naplók elemzéséhez a vállalatnak a helyszíni adattárban tárolt referenciaadatokat kell felhasználnia, mint például az ügyféladatokat, a játékadatokat és a reklámkampány-adatokat. A vállalat úgy kívánja hasznosítani ezeket a helyszíni adattárakból származó adatokat, hogy azokat további, a felhőalapú adattárban lévő naplóadatokkal kombinálja.
Az elemzések kinyeréséhez azt reméli, hogy egy Felhőbeli Spark-fürttel (Azure HDInsight) feldolgozhatja az összekapcsolt adatokat, és közzéteheti az átalakított adatokat egy felhőalapú adattárházban, például az Azure Synapse Analyticsben, hogy könnyen elkészíthesse a jelentéseket. A vállalat automatizálni, illetve napi rendszerességgel monitorozni és kezelni szeretné ezt a munkafolyamatot. Ezenkívül végre is szeretné hajtani, ha fájlok kerülnek egy blobtárolóba.
Az Azure Data Factory az a platform, amely az ilyen adatforgatókönyvek esetében sikeresen használható. Ez a felhőalapú ETL- és adatintegrációs szolgáltatás lehetővé teszi adatvezérelt munkafolyamatok létrehozását az adatáthelyezés és az adatok nagy léptékű átalakításához. Az Azure Data Factory segítségével létrehozhatók és ütemezhetők a különböző adattárolókból adatokat beolvasó adatvezérelt munkafolyamatok. Összetett ETL-folyamatokat hozhat létre, amelyek vizuálisan átalakítják az adatokat adatfolyamokkal, vagy olyan számítási szolgáltatások használatával, mint az Azure HDInsight Hadoop, az Azure Databricks és az Azure SQL Database.
Emellett közzéteheti az átalakított adatokat olyan adattárakban, mint az Azure Synapse Analytics üzletiintelligencia-alkalmazások( BI- vagy üzletiintelligencia-alkalmazások). Végső soron az Azure Data Factory segítségével a nyers adatokat használható adattárakba rendezhetjük, így jobb üzleti döntéseket hozhatunk.
Hogyan működik?
A Data Factory egymással összekapcsolt rendszerek sorozatát tartalmazza, amelyek teljes körű platformot biztosítanak az adatszakértők számára.

Ez a vizuális útmutató részletes áttekintést nyújt a Data Factory teljes architektúrájáról:

További részletekért jelölje ki az előző képet a nagyításhoz, vagy keresse meg a nagy felbontású képet.
{kind=link}
Csatlakozás és összegyűjtés
A vállalatok a legkülönfélébb adatokkal rendelkeznek a legkülönfélébb (helyszíni, felhőbeli, strukturált, strukturálatlan és részben strukturált) forrásokból, amelyek ráadásul eltérő időközzel és sebességgel érkeznek be.
Az információ-előállítási rendszerek kiépítésének első lépése az összes szükséges adatforrás és feldolgozó, például az SaaS-szolgáltatások, az adatbázisok, a fájlmegosztások és az FTP-alapú webszolgáltatások összekapcsolása. A következő lépés az adatok igényalapú átmozgatása egy központi helyre a további feldolgozás előtt.
A Data Factory nélkül a vállalatoknak egyéni adattovábbítási összetevőket kell készíteniük vagy egyéni szolgáltatásokat kell írniuk az adatforrások és feldolgozók integrálására. Az ilyen rendszerek költségesek, nehezen integrálhatóak és tarthatók karban. Továbbá gyakran nem áll rendelkezésre az a vállalati szintű monitorozási, riasztási és vezérlési funkcionalitás, amelyet egy teljes mértékben felügyelt szolgáltatás biztosítani képes.
A Data Factory segítségével a Másolási tevékenység keretében az adatok egyazon adatfolyamatban helyszíni és felhőalapú forrásadattárakból egyaránt továbbíthatóak egy, a felhőben lévő adattárba további elemzésre. Például adatokat gyűjthet az Azure Data Lake Storage-ban, és később átalakíthatja az adatokat egy Azure Data Lake Analytics számítási szolgáltatás használatával. Esetleg begyűjtheti az adatokat egy Azure Blob Storage tárolóból, és később átalakíthatja azokat egy Azure HDInsight Hadoop-fürt használatával.
Átalakítás és bővítés
Miután az adatok egy központi adattárban vannak a felhőben, feldolgozhatja vagy átalakíthatja az összegyűjtött adatokat az ADF-leképezési adatfolyamok használatával. Az adatfolyamok lehetővé teszik az adatmérnökök számára, hogy spark-fürtök vagy Spark-programozás nélkül olyan adatátalakítási diagramokat építsenek ki és tartsanak fenn, amelyek a Sparkon futnak.
Ha inkább kézzel szeretné kódolni az átalakításokat, az ADF támogatja a külső tevékenységeket az átalakítások végrehajtásához olyan számítási szolgáltatásokon, mint a HDInsight Hadoop, a Spark, a Data Lake Analytics és a Machine Learning.
CI/CD és közzététel
A Data Factory teljes körű támogatást nyújt az adatfolyamok CI/CD-hez az Azure DevOps és a GitHub használatával. Ez lehetővé teszi az ETL-folyamatok növekményes fejlesztését és továbbítását a kész termék közzététele előtt. Miután a nyers adatokat üzleti használatra kész formában finomították, töltse be az adatokat az Azure Data Warehouse-ba, az Azure SQL Database-be, az Azure Cosmos DB-be vagy bármelyik elemzési motorba, amelyre az üzleti felhasználók az üzletiintelligencia-eszközeikről mutathatnak.
Monitor
Miután sikeresen kiépítette és üzembe helyezte az adatintegrációs folyamatot, amely üzleti értéket állít elő a feldolgozott adatokból, kövesse figyelemmel az ütemezett tevékenységek és folyamatok sikerességi arányát. Az Azure Data Factory beépített támogatást nyújt a folyamatfigyeléshez az Azure Monitor, az API, a PowerShell, az Azure Monitor-naplók és az Állapotpanelek használatával az Azure Portalon.
Legfelső szintű fogalmak
Az Azure-előfizetések több Azure Data Factory-példányt (más néven adat-előállítókat) is tartalmazhatnak. Az Azure Data Factory a következő fő összetevőkből áll:
- Pipelines
- Tevékenységek
- Adathalmazok
- Társított szolgáltatások
- Adatfolyamok
- Integrációs modulok
Ezek együtt alkotják azt a platformot, amelyen létrehozhatók olyan adatvezérelt munkafolyamatok, amelyeknek a lépései áthelyezik és átalakítják az adatokat.
Folyamat
Az adat-előállító egy vagy több folyamattal rendelkezhet. A folyamatok a tevékenységek logikus csoportosításai egy adott munkaegység végrehajtásához. A folyamatban lévő tevékenységek együtt egy feladatot hajtanak végre. Például a folyamat tartalmazhat egy csoportnyi műveletet, amelyek adatokat fogadnak egy Azure-blobból, majd egy Hive-lekérdezést futtatnak egy HDInsight-fürtön az adatok particionálásához.
A folyamatok használatának az az előnye, hogy így a tevékenységek egy készletben kezelhetők, nem pedig külön-külön. Egy adott folyamat tevékenységei összefűzhetők, így azok egymás után vagy egymástól függetlenül, párhuzamosan üzemeltethetők.
Adatfolyamok leképezése
Olyan adatátalakítási logikát tartalmazó grafikonok létrehozása és kezelése, amelyekkel bármilyen méretű adatot átalakíthat. Az adatátalakítási rutinok újrafelhasználható tárát létrehozhatja, és az ADF-folyamatokból kibővített módon hajthatja végre ezeket a folyamatokat. A Data Factory végrehajtja a logikát egy Spark-fürtön, amely szükség esetén felfelé és lefelé pörög. Soha nem kell fürtöket kezelnie vagy karbantartania.
Tevékenység
Egy folyamatban a tevékenységek a feldolgozási lépéseket jelentik. A másolási tevékenység használatával például az egyik adattárból a másikba másolhatja az adatokat. Hasonlóképpen, egy Hive-tevékenység használatával Hive-lekérdezést futtathat egy Azure HDInsight-fürtön az adatok átalakításához és elemzéséhez. A Data Factory három típusú tevékenységet támogat: az adattovábbítási tevékenységeket, az adat-átalakítási tevékenységeket és a vezérlési tevékenységeket.
Adathalmazok
Az adatkészletek adatstruktúrákat jelölnek az adattárakon belül, amelyek egyszerűen rámutatnak vagy meghivatkozzák az adatokat, amelyeket a tevékenységekben be- vagy kimenetként használni szeretne.
Társított szolgáltatások
A társított szolgáltatások nagyon hasonlóak a kapcsolati sztringekhoz, amelyek meghatározzák azokat a kapcsolati információkat, amelyeket a Data Factory a külső erőforrásokhoz történő csatlakozáshoz igényel. Tulajdonképpen a társított szolgáltatás határozza meg az adatforrással való kapcsolatot, míg az adatkészlet jelöli az adatok struktúráját. Az Azure Storage társított szolgáltatása például kapcsolati sztringet szolgáltat az Azure Storage-fiókhoz való csatlakozáshoz. Az Azure Blob-adatkészlet pedig meghatározza a blobtárolót és az adatokat tartalmazó mappát.
A társított szolgáltatásokat két célból használjuk a Data Factoryban:
Sql Server-adatbázist, Oracle-adatbázist, fájlmegosztást vagy Azure Blob Storage-fiókot tartalmazó adattárat jelöl. A támogatott adattárak listáját lásd a másolási tevékenység cikkben.
Olyan számítási erőforrás jelölésére, amelyen végrehajtható a tevékenység. A HDInsightHive-tevékenység végrehajtása például egy HDInsight Hadoop-fürtön történik. Az átalakítási tevékenységek és a támogatott számítási környezetek listáját lásd az adatok átalakítása cikkben.
Integrációs modul
A Data Factoryban a végrehajtandó műveletet egy tevékenység határozza meg. A társított szolgáltatások a céladattárat vagy a számítási szolgáltatást határozzák meg. Az integrációs modulok hídként szolgálnak a tevékenység és a társított szolgáltatások között. A társított szolgáltatás vagy tevékenység hivatkozik rá, és azt a számítási környezetet biztosítja, ahol a tevékenység fut, vagy onnan lesz elküldve. Ily módon a tevékenység végrehajtható a céladattárhoz vagy számítási szolgáltatáshoz lehető legközelebb eső régióban, a lehető leghatékonyabban, a biztonsági és megfelelőségi igényeknek is megfelelően.
Triggerek
Az eseményindítók olyan feldolgozási egységek, amelyek meghatározzák, hogy mikor kezdődjön egy folyamat végrehajtása. A különböző típusú eseményekhez eltérő típusú eseményindítók tartoznak.
Folyamatfuttatások
A folyamatfuttatások a folyamat-végrehajtás egy-egy példányát jelentik. A folyamatfuttatások példányosítása jellemzően az argumentumoknak a folyamatokban meghatározott paraméterekhez történő továbbításával történik. Az argumentumok továbbítása történhet manuálisan vagy az eseményindító meghatározásán keresztül is.
Paraméterek
A paraméterek írásvédett konfigurációk kulcs-érték párjainak tekintendők. A paraméterek meghatározása a folyamatban történik. Az e paraméterekhez tartozó argumentumok továbbítása a végrehajtás során történik a futtatási környezetből, amelyet egy eseményindító vagy egy manuálisan végrehajtott folyamat hoz létre. A folyamatok tevékenységei a paraméterértékeket dolgozzák fel.
Az adatkészletek szigorúan típusos paraméterek és újrahasznosítható/hivatkozható entitások együttesei. A tevékenységek hivatkozhatnak adatkészletekre, és képesek az adatkészlet-meghatározásban megadott tulajdonságok feldolgozására.
A társított szolgáltatások szintén adattárak vagy számítási környezetek kapcsolatadatait tartalmazó, szigorúan típusos paraméterek. Ezenkívül újrahasznosítható/hivatkozható entitások.
Átvitelvezérlés
Átvitelvezérlés: folyamattevékenységek vezénylése, például egy sorozat láncolási tevékenységei, elágaztatás és olyan paraméterek, amelyek folyamatszinten határozhatók meg, valamint olyan argumentumok, amelyek a folyamat igény szerinti meghívása során vagy egy eseményindítóból továbbítódnak. Ilyen tevékenységek az egyéniállapot-átadás és a tárolók hurkolása, vagyis a For-each iterátorok is.
Változók
A változók a folyamatokon belül ideiglenes értékek tárolására használhatók, és paraméterekkel együtt is használhatók az értékek folyamatok, adatfolyamok és egyéb tevékenységek közötti átadásának engedélyezéséhez.
Kapcsolódó tartalom
Az alábbiakban a következő fontos lépéseket ismertető dokumentumokat ismerheti meg: