Adatok másolása az Azure Data Lake Storage Gen1-be vagy onnan az Azure Data Factory vagy az Azure Synapse Analytics használatával
A következőkre vonatkozik:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk azt ismerteti, hogyan másolhat adatokat az Azure Data Lake Storage Gen1-be és onnan. További információért olvassa el az Azure Data Factory vagy az Azure Synapse Analytics bevezető cikkét.
Feljegyzés
Az Azure Data Lake Storage Gen1 2024. február 29-én megszűnt. Migráljon az Azure Data Lake Storage Gen2-összekötőbe. Ez a cikk az Azure Data Lake Storage Gen1 migrálási útmutatóját ismerteti.
Támogatott képességek
Ez az Azure Data Lake Storage Gen1-összekötő a következő képességeket támogatja:
| Támogatott képességek | IR |
|---|---|
| Copy tevékenység (forrás/fogadó) | (1) (2) |
| Adatfolyam leképezése (forrás/fogadó) | (1) |
| Keresési tevékenység | (1) (2) |
| GetMetadata-tevékenység | (1) (2) |
| Tevékenység törlése | (1) (2) |
(1) Azure-integrációs modul (2) Saját üzemeltetésű integrációs modul
Ezzel az összekötővel a következőt teheti:
- Másolja a fájlokat a következő hitelesítési módszerek egyikével: szolgáltatásnév vagy felügyelt identitások az Azure-erőforrásokhoz.
- Másolja a fájlokat a támogatott fájlformátumokkal és tömörítési kodekekkel, vagy elemezje vagy hozza létre a fájlokat.
- Az ACL-ek megőrzése az Azure Data Lake Storage Gen2-be való másoláskor.
Fontos
Ha a saját üzemeltetésű integrációs modullal másol adatokat, konfigurálja a vállalati tűzfalat úgy, hogy engedélyezze a kimenő forgalmat <ADLS account name>.azuredatalakestore.net a 443-as porton.login.microsoftonline.com/<tenant>/oauth2/token Ez utóbbi az Azure Security Token Service, amellyel az integrációs modulnak kommunikálnia kell a hozzáférési jogkivonat beszerzéséhez.
Első lépések
Tipp.
Az Azure Data Lake Store-összekötő használatának részletes ismertetése: Adatok betöltése az Azure Data Lake Store-ba.
A Copy tevékenység folyamattal való végrehajtásához használja az alábbi eszközök vagy SDK-k egyikét:
- Az Adatok másolása eszköz
- Az Azure Portal
- A .NET SDK
- A Python SDK
- Azure PowerShell
- A REST API
- Az Azure Resource Manager-sablon
Társított szolgáltatás létrehozása az Azure Data Lake Storage Gen1-hez felhasználói felületen
Az alábbi lépésekkel létrehozhat egy társított szolgáltatást az Azure Data Lake Storage Gen1-hez az Azure Portal felhasználói felületén.
Keresse meg az Azure Data Factory vagy a Synapse-munkaterület Kezelés lapját, és válassza a Társított szolgáltatások lehetőséget, majd válassza az Új lehetőséget:
Keresse meg az Azure Data Lake Storage Gen1-et, és válassza ki az Azure Data Lake Storage Gen1-összekötőt.
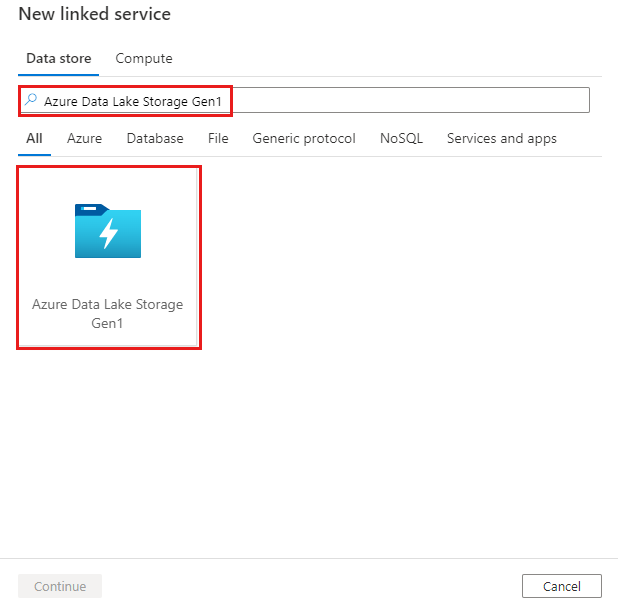
Konfigurálja a szolgáltatás részleteit, tesztelje a kapcsolatot, és hozza létre az új társított szolgáltatást.
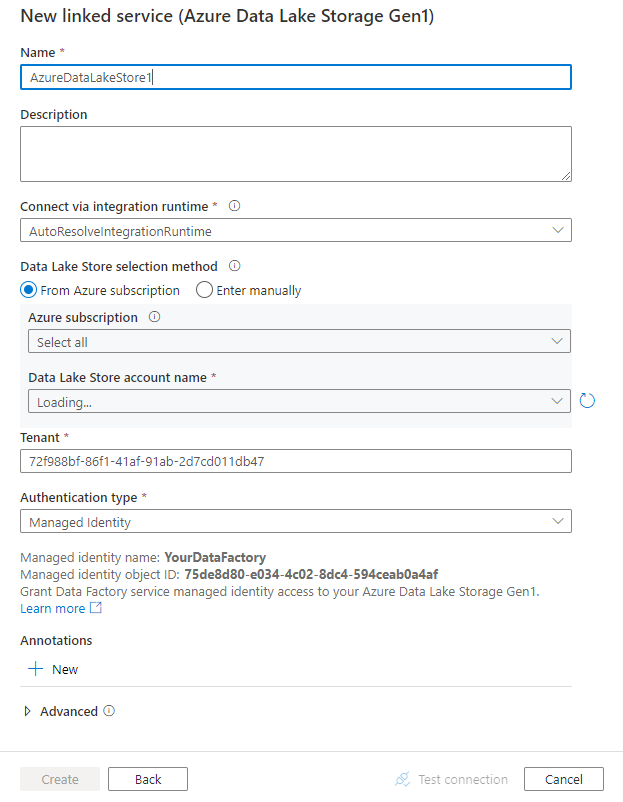
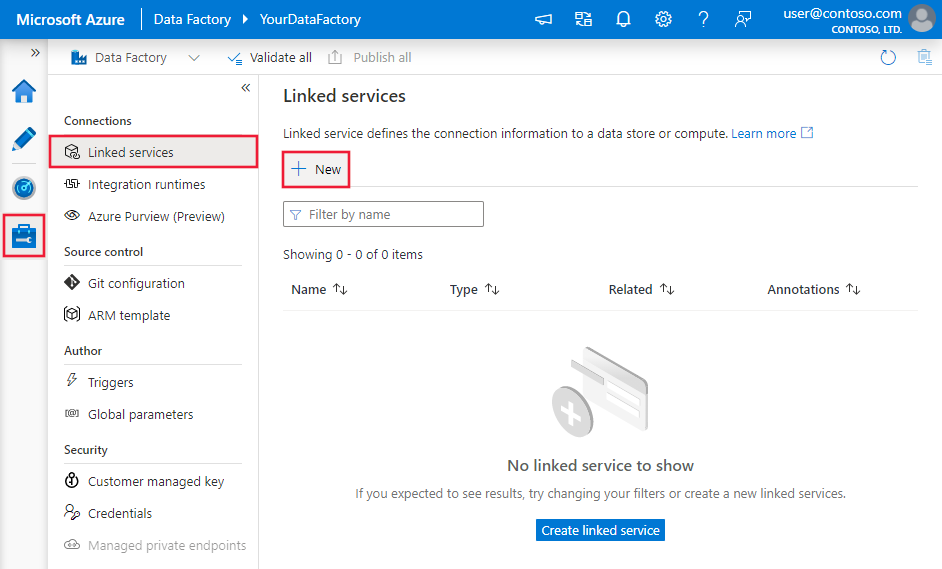
Az összekötő konfigurációjának részletei
A következő szakaszok az 1. generációs Azure Data Lake Store-ra jellemző entitások meghatározásához használt tulajdonságokról nyújtanak információkat.
Társított szolgáltatás tulajdonságai
Az Azure Data Lake Store társított szolgáltatásához a következő tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A type tulajdonságot az AzureDataLakeStore értékre kell állítani. |
Igen |
| dataLakeStoreUri | Információk az Azure Data Lake Store-fiókról. Ez az információ a következő formátumok egyikét tartalmazza: https://[accountname].azuredatalakestore.net/webhdfs/v1 vagy adl://[accountname].azuredatalakestore.net/. |
Igen |
| subscriptionId | Az Azure-előfizetés azonosítója, amelyhez a Data Lake Store-fiók tartozik. | A fogadóhoz szükséges |
| resourceGroupName | Az Azure-erőforráscsoport neve, amelyhez a Data Lake Store-fiók tartozik. | A fogadóhoz szükséges |
| connectVia | Az adattárhoz való csatlakozáshoz használandó integrációs modul . Használhatja az Azure integrációs modult vagy egy saját üzemeltetésű integrációs modult, ha az adattár magánhálózaton található. Ha ez a tulajdonság nincs megadva, a rendszer az alapértelmezett Azure-integrációs modult használja. | Nem |
Egyszerű szolgáltatáshitelesítés használata
A szolgáltatásnév-hitelesítés használatához kövesse az alábbi lépéseket.
Regisztráljon egy alkalmazásentitást a Microsoft Entra-azonosítóban, és adjon hozzáférést a Data Lake Store-hoz. A részletes lépésekért tekintse meg a szolgáltatásközi hitelesítést. Jegyezze fel az alábbi értékeket, amelyeket a társított szolgáltatás definiálásához használ:
- Pályázat azonosítója
- Alkalmazáskulcs
- Bérlőazonosító
Adjon megfelelő engedélyt a szolgáltatásnévnek. Példák az 1. generációs Data Lake Storage hozzáférés-vezérlési jogosultságainak működésére az Azure Data Lake Storage Gen1-ben.
- Forrásként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint olvasási engedélyt a másolandó fájlokhoz. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá. A fiókszintű hozzáférés-vezérlésre (IAM) nincs szükség.
- Fogadóként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint a fogadómappa írási engedélyét. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá.
A következő tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| servicePrincipalId | Adja meg az alkalmazás ügyfél-azonosítóját. | Igen |
| servicePrincipalKey | Adja meg az alkalmazás kulcsát. Jelölje meg ezt a mezőt SecureString biztonságos tárolás céljából, vagy hivatkozzon az Azure Key Vaultban tárolt titkos kódra. |
Igen |
| bérlő | Adja meg a bérlő adatait, például a tartománynevet vagy a bérlőazonosítót, amely alatt az alkalmazás található. A lekéréshez vigye az egérmutatót az Azure Portal jobb felső sarkában. | Igen |
| azureCloudType | A szolgáltatásnév hitelesítéséhez adja meg annak az Azure-felhőkörnyezetnek a típusát, amelyre a Microsoft Entra-alkalmazás regisztrálva van. Az engedélyezett értékek az AzurePublic, az AzureChina, az AzureUsGovernment és az AzureGermany. Alapértelmezés szerint a szolgáltatás felhőkörnyezetét használja a rendszer. |
Nem |
Példa:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Rendszer által hozzárendelt felügyelt identitás hitelesítésének használata
Egy adat-előállító vagy Synapse-munkaterület társítható egy rendszer által hozzárendelt felügyelt identitással, amely a szolgáltatást jelöli a hitelesítéshez. Ezt a rendszer által hozzárendelt felügyelt identitást közvetlenül használhatja a Data Lake Store-hitelesítéshez, hasonlóan a saját szolgáltatásnév használatához. Lehetővé teszi a kijelölt erőforrás számára az adatok elérését és másolását a Data Lake Store-ba vagy onnan.
A rendszer által hozzárendelt felügyelt identitáshitelesítés használatához kövesse az alábbi lépéseket.
Kérje le a rendszer által hozzárendelt felügyelt identitás adatait a gyári vagy Synapse-munkaterülettel együtt létrehozott "Service Identity Application ID" értékének másolásával.
Adjon hozzáférést a rendszer által hozzárendelt felügyelt identitásnak a Data Lake Store-hoz. Példák az 1. generációs Data Lake Storage hozzáférés-vezérlési jogosultságainak működésére az Azure Data Lake Storage Gen1-ben.
- Forrásként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint olvasási engedélyt a másolandó fájlokhoz. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá. A fiókszintű hozzáférés-vezérlésre (IAM) nincs szükség.
- Fogadóként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint a fogadómappa írási engedélyét. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá.
A társított szolgáltatásban nem kell más tulajdonságokat megadnia, mint a Data Lake Store általános információi.
Példa:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Felhasználó által hozzárendelt felügyelt identitás hitelesítésének használata
Egy adat-előállító egy vagy több felhasználó által hozzárendelt felügyelt identitással rendelhető hozzá. Ezt a felhasználó által hozzárendelt felügyelt identitást használhatja a Blob Storage-hitelesítéshez, amely lehetővé teszi az adatok elérését és másolását a Data Lake Store-ból vagy a Data Lake Store-ba. Az Azure-erőforrások felügyelt identitásairól további információt az Azure-erőforrások felügyelt identitásai című témakörben talál .
A felhasználó által hozzárendelt felügyelt identitáshitelesítés használatához kövesse az alábbi lépéseket:
Hozzon létre egy vagy több felhasználó által hozzárendelt felügyelt identitást , és adjon hozzáférést az Azure Data Lake-hez. Példák az 1. generációs Data Lake Storage hozzáférés-vezérlési jogosultságainak működésére az Azure Data Lake Storage Gen1-ben.
- Forrásként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint olvasási engedélyt a másolandó fájlokhoz. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá. A fiókszintű hozzáférés-vezérlésre (IAM) nincs szükség.
- Fogadóként: Az Adatkezelői>hozzáférésben adjon legalább végrehajtási engedélyt az ÖSSZES felsőbb rétegbeli mappához, beleértve a gyökérmappát is, valamint a fogadómappa írási engedélyét. Választhatja, hogy hozzáadja ezt a mappát és az összes gyermeket rekurzívként, és hozzáférési engedélyként és alapértelmezett engedélybejegyzésként adja hozzá.
Rendeljen hozzá egy vagy több felhasználó által hozzárendelt felügyelt identitást az adat-előállítóhoz, és hozzon létre hitelesítő adatokat minden felhasználó által hozzárendelt felügyelt identitáshoz.
A következő tulajdonság támogatott:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| hitelesítő adatok | Adja meg a felhasználó által hozzárendelt felügyelt identitást hitelesítő objektumként. | Igen |
Példa:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Adathalmaz tulajdonságai
Az adathalmazok meghatározásához elérhető szakaszok és tulajdonságok teljes listáját az Adathalmazok című cikkben találja.
Az Azure Data Factory a következő fájlformátumokat támogatja. A formátumalapú beállításokat az egyes cikkekben találja.
- Avro formátum
- Bináris formátum
- Tagolt szövegformátum
- Excel-formátum
- JSON formátum
- ORC formátum
- Parquet formátum
- XML-formátum
Az Azure Data Lake Store Gen1 formátumalapú adatkészlet beállításai között location az alábbi tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának location azureDataLakeStoreLocation értékre kell állítania. |
Igen |
| folderPath | A mappa elérési útja. Ha helyettesítő karakterrel szeretné szűrni a mappákat, hagyja ki ezt a beállítást, és adja meg a tevékenység forrásbeállításaiban. | Nem |
| fileName | A fájl neve az adott folderPath mappában. Ha helyettesítő karakterrel szeretné szűrni a fájlokat, hagyja ki ezt a beállítást, és adja meg a tevékenység forrásbeállításaiban. | Nem |
Példa:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Másolási tevékenység tulajdonságai
A tevékenységek meghatározásához elérhető szakaszok és tulajdonságok teljes listáját a Folyamatok című témakörben találja. Ez a szakasz az Azure Data Lake Store-forrás és fogadó által támogatott tulajdonságok listáját tartalmazza.
Forrásként az Azure Data Lake Store
Az Azure Data Factory a következő fájlformátumokat támogatja. A formátumalapú beállításokat az egyes cikkekben találja.
- Avro formátum
- Bináris formátum
- Tagolt szövegformátum
- Excel-formátum
- JSON formátum
- ORC formátum
- Parquet formátum
- XML-formátum
Az Azure Data Lake Store Gen1 formátumalapú másolási forrás beállításai között storeSettings az alábbi tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A típustulajdonságnak az storeSettings AzureDataLakeStoreReadSettings értékre kell állítania. |
Igen |
| Keresse meg a másolandó fájlokat: | ||
| 1. LEHETŐSÉG: statikus elérési út |
Másolja ki az adathalmazban megadott mappa/fájl elérési útját. Ha az összes fájlt egy mappából szeretné másolni, adja meg wildcardFileName a következőt *is: . |
|
| 2. LEHETŐSÉG: névtartomány - listAfter |
Kérje le azokat a mappákat/fájlokat, amelyek neve betűrendben (kizárólagos) után található. Az ADLS Gen1 szolgáltatásoldali szűrőt használja, amely jobb teljesítményt nyújt, mint egy helyettesítő karakterszűrő. A szolgáltatás ezt a szűrőt az adathalmazban definiált elérési útra alkalmazza, és csak egy entitásszint támogatott. További példák a Névtartomány szűrő példáiban. |
Nem |
| 2. LEHETŐSÉG: névtartomány - listBefore |
Kérje le azokat a mappákat/fájlokat, amelyeknek a neve betűrendben (beleértve) elé kerül. Az ADLS Gen1 szolgáltatásoldali szűrőt használja, amely jobb teljesítményt nyújt, mint egy helyettesítő karakterszűrő. A szolgáltatás ezt a szűrőt az adathalmazban definiált elérési útra alkalmazza, és csak egy entitásszint támogatott. További példák a Névtartomány szűrő példáiban. |
Nem |
| 3. LEHETŐSÉG: helyettesítő karakter - helyettesítő karakterekFolderPath |
A mappa elérési útja helyettesítő karakterekkel a forrásmappák szűréséhez. Az engedélyezett helyettesítő karakterek a következők: * (nulla vagy több karakternek felel meg) és ? (nulla vagy egyetlen karakternek felel meg); akkor használható ^ a feloldáshoz, ha a mappa tényleges neve helyettesítő karaktert tartalmaz, vagy ez a feloldó karakter található benne. További példák a mappa- és fájlszűrő példákban. |
Nem |
| 3. LEHETŐSÉG: helyettesítő karakter - wildcardFileName |
A forrásfájlok szűréséhez használt fájlnév helyettesítő karaktereket tartalmaz az adott mappaPath/helyettesítő karaktermappájában. Az engedélyezett helyettesítő karakterek a következők: * (nulla vagy több karakternek felel meg) és ? (nulla vagy egyetlen karakternek felel meg); akkor használható ^ a feloldásra, ha a tényleges fájlnév helyettesítő karaktert tartalmaz, vagy ez a feloldó karakter található benne. További példák a mappa- és fájlszűrő példákban. |
Igen |
| 4. LEHETŐSÉG: a fájlok listája - fileListPath |
Egy adott fájlkészlet másolását jelzi. Mutasson egy szövegfájlra, amely tartalmazza a másolandó fájlok listáját, soronként egy fájlt, amely az adathalmazban konfigurált elérési út relatív elérési útja. Ha ezt a lehetőséget használja, ne adjon meg fájlnevet az adathalmazban. További példák a Fájllista példákban. |
Nem |
| További beállítások: | ||
| rekurzív | Azt jelzi, hogy az adatok rekurzív módon vannak-e beolvasva az almappákból vagy csak a megadott mappából. Ha a rekurzív érték igaz, és a fogadó fájlalapú tároló, a rendszer nem másol vagy hoz létre üres mappát vagy almappát a fogadóban. Az engedélyezett értékek értéke igaz (alapértelmezett) és hamis. Ez a tulajdonság nem érvényes a konfiguráláskor fileListPath. |
Nem |
| deleteFilesAfterCompletion | Azt jelzi, hogy a bináris fájlok törölve lesznek-e a forrástárból a céltárolóba való sikeres áthelyezés után. A fájltörlés fájlonként történik, ezért ha a másolási tevékenység meghiúsul, látni fogja, hogy egyes fájlok már át lettek másolva a célhelyre, és törölve lettek a forrásból, míg mások továbbra is a forrástárban maradnak. Ez a tulajdonság csak bináris fájlok másolási forgatókönyvében érvényes. Az alapértelmezett érték: hamis. |
Nem |
| modifiedDatetimeStart | A fájlok szűrése a következő attribútum alapján történik: Utolsó módosítás. A fájlok akkor lesznek kijelölve, ha az utolsó módosításuk időpontja nagyobb vagy egyenlő, modifiedDatetimeStart mint modifiedDatetimeEnda . Az idő az UTC időzónára "2018-12-01T05:00:00Z" formátumban lesz alkalmazva. A tulajdonságok null értékűek lehetnek, ami azt jelenti, hogy az adathalmazra nincs fájlattribútum-szűrő alkalmazva. Ha modifiedDatetimeStart dátum/idő érték van megadva, de modifiedDatetimeEnd null értékű, az azt jelenti, hogy az utolsó módosított attribútum nagyobb vagy egyenlő a dátum/idő értékkel. Ha modifiedDatetimeEnd dátum/idő érték van megadva, de modifiedDatetimeStart NULL értékű, az azt jelenti, hogy az utoljára módosított attribútummal rendelkező fájlok kisebbek a dátum/idő értéknél.Ez a tulajdonság nem érvényes a konfiguráláskor fileListPath. |
Nem |
| modifiedDatetimeEnd | Lásd fentebb. | Nem |
| enablePartitionDiscovery | Particionált fájlok esetén adja meg, hogy elemezni szeretné-e a partíciókat a fájl elérési útján, és további forrásoszlopokként adja hozzá őket. Az engedélyezett értékek hamisak (alapértelmezett) és igazak. |
Nem |
| partitionRootPath | Ha a partíciófelderítés engedélyezve van, adja meg az abszolút gyökér elérési utat a particionált mappák adatoszlopként való olvasásához. Ha nincs megadva, alapértelmezés szerint – Ha fájlelérési utat használ az adathalmazban vagy a forrásban lévő fájlok listájában, a partíció gyökérútvonala az adathalmazban konfigurált elérési út. – Helyettesítő karakteres mappaszűrő használata esetén a partíció gyökérútvonala az első helyettesítő karakter előtti alútvonal. Tegyük fel például, hogy az adathalmaz elérési útját "root/folder/year=2020/month=08/day=27" értékre konfigurálja: - Ha a partíció gyökér elérési útját "root/folder/year=2020" értékként adja meg, a másolási tevékenység két további oszlopot month hoz létre, és day a fájlokon belüli oszlopok mellett a "08" és a "27" értéket is tartalmazza.– Ha nincs megadva a partíció gyökérútvonala, a rendszer nem hoz létre további oszlopot. |
Nem |
| maxConcurrentConnections | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
Példa:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Store fogadóként
Az Azure Data Factory a következő fájlformátumokat támogatja. A formátumalapú beállításokat az egyes cikkekben találja.
Az Azure Data Lake Store Gen1 formátumalapú másolási fogadó beállításai között storeSettings az alábbi tulajdonságok támogatottak:
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A típustulajdonságnak az storeSettings AzureDataLakeStoreWriteSettings értékre kell állítania. |
Igen |
| copyBehavior | Meghatározza a másolási viselkedést, ha a forrás fájlalapú adattárból származó fájlok. Az engedélyezett értékek a következők: - PreserveHierarchy (alapértelmezett): Megőrzi a fájlhierarchiát a célmappában. A forrásfájlnak a forrásmappához viszonyított elérési útja megegyezik a célfájl célmappához viszonyított elérési útával. - FlattenHierarchy: A forrásmappából származó összes fájl a célmappa első szintjén található. A célfájlok automatikusan létrehozott névvel rendelkeznek. - MergeFiles: A forrásmappából származó összes fájlt egyetlen fájlba egyesíti. Ha a fájlnév meg van adva, az egyesített fájlnév a megadott név. Ellenkező esetben ez egy automatikusan létrehozott fájlnév. |
Nem |
| expiryDateTime | Az írott fájlok lejárati idejét adja meg. Az idő az UTC-időpontra lesz alkalmazva "2020-03-01T08:00:00Z" formátumban. Alapértelmezés szerint NULL értékű, ami azt jelenti, hogy az írott fájlok soha nem járnak le. | Nem |
| maxConcurrentConnections | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
Példa:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Példa a névtartomány szűrési példáira
Ez a szakasz a névtartomány-szűrők eredő viselkedését ismerteti.
| Minta forrásstruktúra | Konfiguráció | Eredmény |
|---|---|---|
| gyökér a file.csv fejsze file2.csv ax.csv b file3.csv bx.csv c file4.csv cx.csv |
Adatkészletben: - Mappa elérési útja: rootMásolási tevékenység forrása: - Listázás a következő után: a- Lista előtt: b |
Ezután a program a következő fájlokat másolja: gyökér fejsze file2.csv ax.csv b file3.csv |
Mappa- és fájlszűrő példák
Ez a szakasz a mappa elérési útjának és a fájlnévnek helyettesítő karaktereket tartalmazó viselkedését ismerteti.
| folderPath | fileName | rekurzív | A forrásmappa struktúrája és a szűrés eredménye (a félkövér fájlokat a rendszer lekéri) |
|---|---|---|---|
Folder* |
(Üres, alapértelmezett beállítás) | false | FolderA File1.csv File2.json Almappák1 File3.csv File4.json File5.csv MásikFolderB File6.csv |
Folder* |
(Üres, alapértelmezett beállítás) | true | FolderA File1.csv File2.json Almappák1 File3.csv File4.json File5.csv MásikFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Almappák1 File3.csv File4.json File5.csv MásikFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Almappák1 File3.csv File4.json File5.csv MásikFolderB File6.csv |
Példák fájllistára
Ez a szakasz a fájllista elérési útjának másolási tevékenység forrásában való használatát ismerteti.
Feltéve, hogy a következő forrásmappa-struktúrával rendelkezik, és félkövér formátumban szeretné másolni a fájlokat:
| Minta forrásstruktúra | Tartalom a FileListToCopy.txt | Konfiguráció |
|---|---|---|
| gyökér FolderA File1.csv File2.json Almappák1 File3.csv File4.json File5.csv Metaadatok FileListToCopy.txt |
File1.csv Almappák1/File3.csv Almappák1/File5.csv |
Adatkészletben: - Mappa elérési útja: root/FolderAMásolási tevékenység forrása: - Fájllista elérési útja: root/Metadata/FileListToCopy.txt A fájllista elérési útja egy szövegfájlra mutat ugyanabban az adattárban, amely tartalmazza a másolni kívánt fájlok listáját, soronként egy fájlt az adathalmazban konfigurált elérési út relatív elérési útjával. |
Példák a másolási művelet viselkedésére
Ez a szakasz a másolási művelet különböző kombinációinak és copyBehavior értékeinek eredő viselkedését recursive ismerteti.
| rekurzív | copyBehavior | Forrásmappa-struktúra | Eredményként kapott cél |
|---|---|---|---|
| true | preserveHierarchy | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 ugyanazzal a struktúrával jön létre, mint a forrás: Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5. |
| true | flattenHierarchy | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 a következő struktúrával jön létre: Mappa1 a Fájl1 automatikusan létrehozott neve a Fájl2 automatikusan létrehozott neve a Fájl3 automatikusan létrehozott neve a Fájl4 automatikusan létrehozott neve a Fájl5 automatikusan létrehozott neve |
| true | mergeFiles | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 a következő struktúrával jön létre: Mappa1 File1 + File2 + File3 + File4 + File5 tartalom egyesítve egy fájlba, egy automatikusan létrehozott fájlnévvel. |
| false | preserveHierarchy | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 a következő struktúrával jön létre: Mappa1 Fájl1 Fájl2 A Fájl3, File4 és File5 almappák nem lesznek felvéve. |
| false | flattenHierarchy | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 a következő struktúrával jön létre: Mappa1 a Fájl1 automatikusan létrehozott neve a Fájl2 automatikusan létrehozott neve A Fájl3, File4 és File5 almappák nem lesznek felvéve. |
| false | mergeFiles | Mappa1 Fájl1 Fájl2 Almappák1 Fájl3 Fájl4 Fájl5 |
A célmappa1 a következő struktúrával jön létre: Mappa1 Az 1. és a 2. fájl tartalma egy automatikusan létrehozott fájlnévvel rendelkező fájlba egyesül. a Fájl1 automatikusan létrehozott neve A Fájl3, File4 és File5 almappák nem lesznek felvéve. |
ACL-ek megőrzése a Data Lake Storage Gen2-be
Tipp.
Az Azure Data Lake Storage Gen1-ből általában a Gen2-be történő adatmásoláshoz tekintse meg az Adatok másolása az Azure Data Lake Storage Gen1-ből Gen2-be című témakört, amely bemutatja az ajánlott eljárásokat.
Ha replikálni szeretné a hozzáférés-vezérlési listákat (ACL-eket) és az adatfájlokat, amikor a Data Lake Storage Gen1-ről a Data Lake Storage Gen2-re frissít, olvassa el az ACL-ek megőrzése a Data Lake Storage Gen1-ből.
Adatfolyam-tulajdonságok leképezése
A leképezési adatfolyamok adatainak átalakításakor a következő formátumokban olvashat és írhat fájlokat az Azure Data Lake Storage Gen1-ből:
A formátumspecifikus beállítások az adott formátum dokumentációjában találhatók. További információ: Forrásátalakítás a leképezési adatfolyamban és fogadóátalakítás a leképezési adatfolyamban.
Forrásátalakítás
A forrásátalakítás során egy tárolóból, mappából vagy egyéni fájlból olvashat az 1. generációs Azure Data Lake Storage-ban. A Forrásbeállítások lapon kezelheti a fájlok olvasási módját.
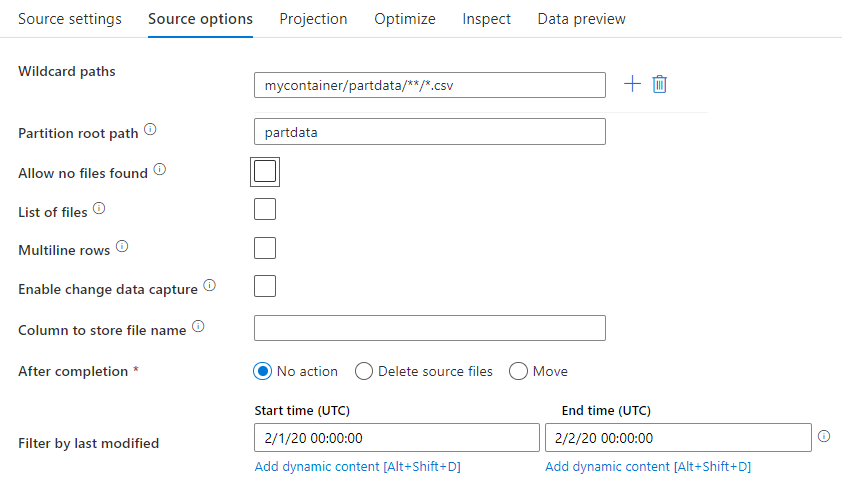
Helyettesítő karakter elérési útja: A helyettesítő karakterek mintájának használatával a szolgáltatás arra utasítja a szolgáltatást, hogy egyetlen forrásátalakítás során végighaladjon az egyes egyező mappákon és fájlokon. Ez egy hatékony módja annak, hogy több fájlt dolgozzanak fel egyetlen folyamaton belül. Adjon hozzá több helyettesítő karakterillesztési mintát a meglévő helyettesítő karakterminta fölé való rámutatáskor megjelenő + jellel.
A forrástárolóban válasszon ki egy mintának megfelelő fájlsorozatot. Az adathalmazban csak tároló adható meg. A helyettesítő karakter elérési útjának ezért tartalmaznia kell a gyökérmappából származó mappa elérési útját is.
Példák helyettesítő karakterekre:
*Tetszőleges karakterkészletet jelöl**Rekurzív címtárbe ágyazást jelöl?Egy karakter cseréje[]A szögletes zárójelek egyikének felel meg/data/sales/**/*.csvLekéri az összes csv-fájlt az /data/sales területen/data/sales/20??/**/Az összes fájlt rekurzívan lekéri az összes megfelelő 20xx mappában/data/sales/*/*/*.csvA csv-fájlok két szintjét kapja meg az /data/sales alatt/data/sales/2004/12/[XY]1?.csv2004 decemberétől az összes csv-fájlt lekéri, kezdve az X vagy Y karakterrel, majd az 1-zel és minden karakterrel
Partíció gyökérútvonala: Ha a fájlforrásban key=value particionált mappák vannak formázva (például year=2019), akkor a partíciómappa legfelső szintjét hozzárendelheti egy oszlopnévhez az adatfolyamban.
Először állítson be egy helyettesítő karaktert, hogy tartalmazza a particionált mappák összes elérési útját, valamint az elolvasni kívánt levélfájlokat.
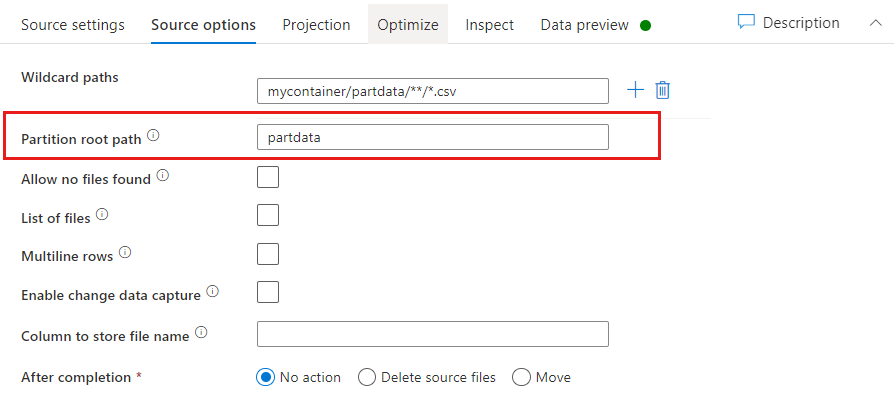
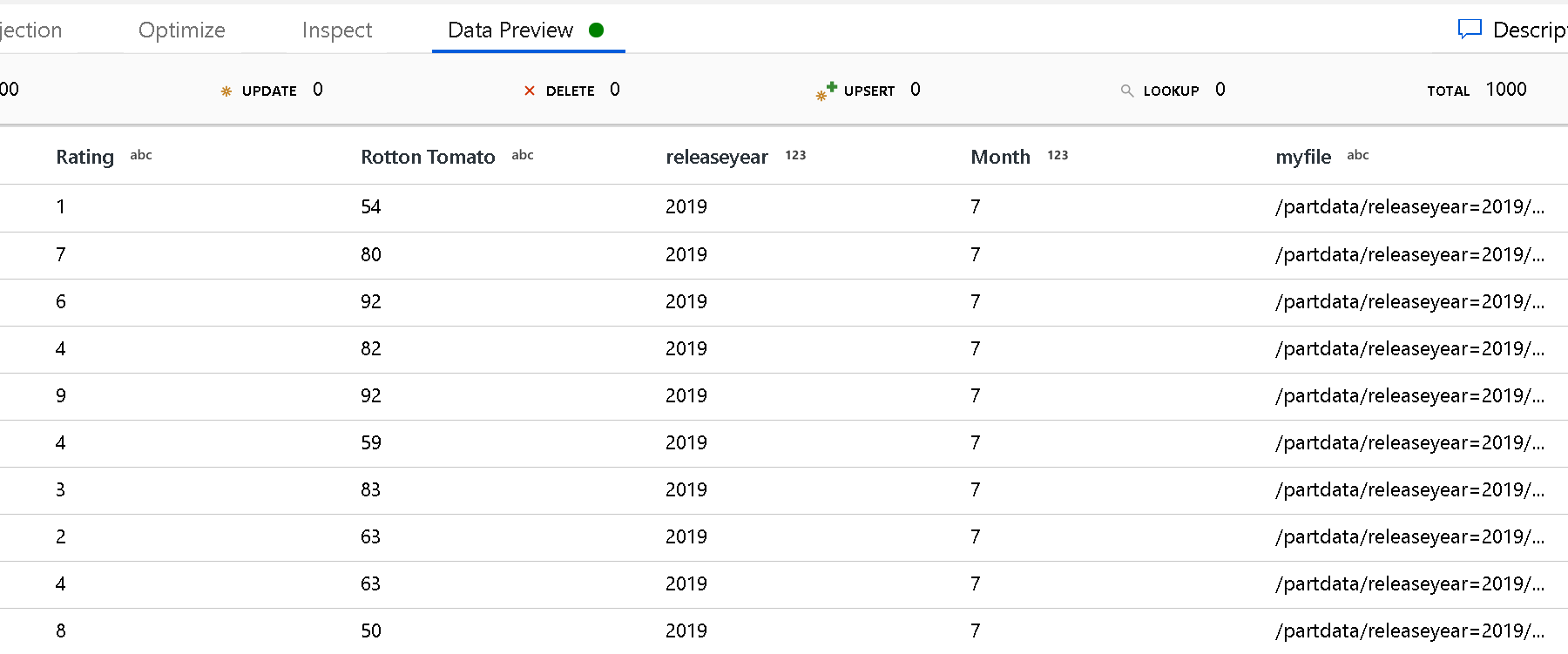
A partíció gyökérútvonal-beállításával meghatározhatja, hogy mi a mappastruktúra legfelső szintje. Ha az adatok tartalmát egy adatelőnézeten keresztül tekinti meg, láthatja, hogy a szolgáltatás hozzáadja az egyes mappaszinteken található feloldott partíciókat.
Fájlok listája: Ez egy fájlkészlet. Hozzon létre egy szövegfájlt, amely tartalmazza a feldolgozandó relatív elérésiút-fájlok listáját. Mutasson erre a szövegfájlra.
A fájlnév tárolására használt oszlop: Tárolja a forrásfájl nevét az adatok egyik oszlopában. Itt adjon meg egy új oszlopnevet a fájlnév-sztring tárolásához.
Befejezés után: Válassza ki, hogy az adatfolyam futtatása után nem szeretne semmit tenni a forrásfájllal, törli a forrásfájlt, vagy áthelyezi a forrásfájlt. Az áthelyezés elérési útjai relatívek.
Ha a forrásfájlokat egy másik helyre szeretné áthelyezni a feldolgozás után, először válassza az "Áthelyezés" lehetőséget a fájlművelethez. Ezután állítsa be a "from" könyvtárat. Ha nem használ helyettesítő karaktereket az elérési úthoz, akkor a "forrás" beállítás ugyanaz a mappa, mint a forrásmappa.
Ha helyettesítő karakterrel rendelkező forrásútvonallal rendelkezik, a szintaxis az alábbihoz hasonlóan néz ki:
/data/sales/20??/**/*.csv
Megadhatja, hogy a "feladó"
/data/sales
És a "to" mint
/backup/priorSales
Ebben az esetben a /data/sales alatt forrásul kapott összes fájl a /backup/priorSales mappába kerül.
Feljegyzés
A fájlműveletek csak akkor futnak, ha egy folyamatfuttatásból (folyamat hibakereséséből vagy végrehajtási futtatásából) indítja el az adatfolyamot, amely a folyamat végrehajtási Adatfolyam tevékenységét használja. A fájlműveletek nem Adatfolyam hibakeresési módban futnak.
Szűrés utoljára módosítva: A legutóbb módosított fájlok dátumtartományának megadásával szűrheti a feldolgozott fájlokat. Minden dátumidő UTC-ben van megadva.
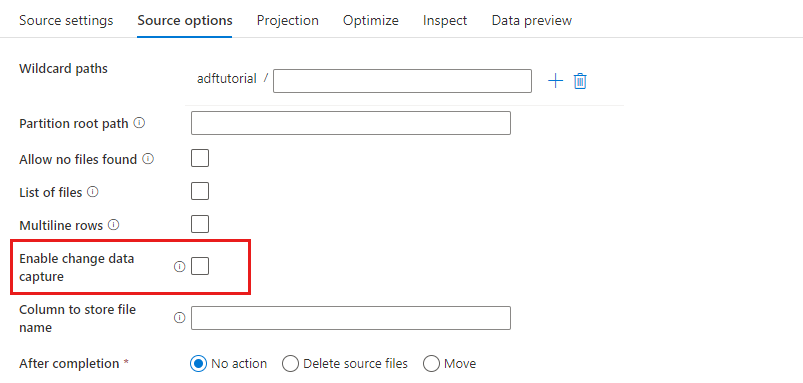
Adatrögzítés engedélyezése: Ha igaz, csak az utolsó futtatáskor kap új vagy módosított fájlokat. A teljes pillanatkép-adatok kezdeti betöltése mindig az első futtatáskor lesz, majd csak a következő futtatások során rögzíti az új vagy módosított fájlokat. További részletekért lásd: Adatrögzítés módosítása.
Fogadó tulajdonságai
A fogadó átalakításával írhat egy tárolóba vagy mappába az Azure Data Lake Storage Gen1-ben. A Beállítások lapon kezelheti a fájlok írási módját.
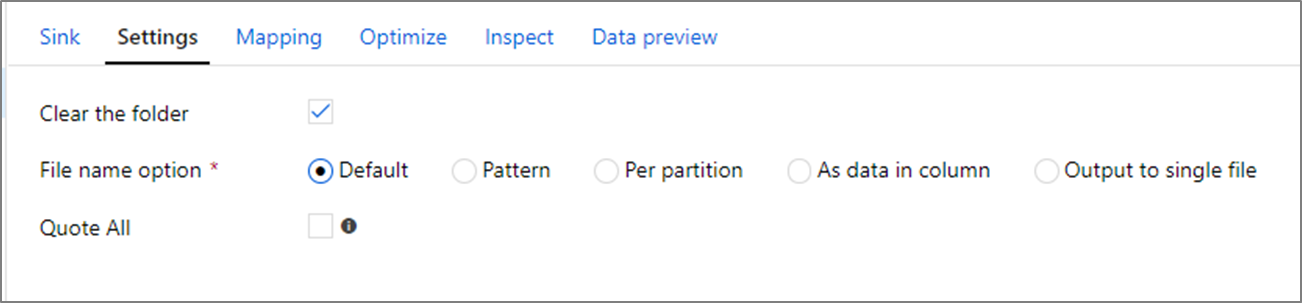
A mappa törlése: Meghatározza, hogy a célmappa törlődjön-e az adatok megírása előtt.
Fájlnév beállítás: Meghatározza, hogy a célfájlok hogyan legyenek elnevezve a célmappában. A fájlnév beállításai a következők:
- Alapértelmezett: Engedélyezze a Sparknak, hogy a PART alapértelmezett érték alapján nevezze el a fájlokat.
- Minta: Adjon meg egy mintát, amely partíciónként számba adja a kimeneti fájlokat. A hitelek[n].csv például loans1.csv, loans2.csv stb.
- Partíciónként: Partíciónként egy fájlnevet adjon meg.
- Adatként az oszlopban: Állítsa a kimeneti fájlt egy oszlop értékére. Az elérési út az adathalmaz-tárolóhoz viszonyítva van, nem a célmappához. Ha van egy mappa elérési útja az adathalmazban, az felül lesz bírálva.
- Kimenet egyetlen fájlba: Egyesítse a particionált kimeneti fájlokat egyetlen elnevezett fájlba. Az elérési út az adathalmaz mappához képest van. Vegye figyelembe, hogy az egyesítési művelet a csomópont méretétől függően meghiúsulhat. Ez a beállítás nagy adathalmazokhoz nem ajánlott.
Az összes idézőjel: Meghatározza, hogy az összes értéket idézőjelekbe foglalja-e
Keresési tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez tekintse meg a keresési tevékenységet.
GetMetadata tevékenység tulajdonságai
A tulajdonságok részleteinek megismeréséhez ellenőrizze a GetMetadata-tevékenységet
Tevékenységtulajdonságok törlése
A tulajdonságok részleteinek megismeréséhez ellenőrizze a Törlési tevékenységet
Örökölt modellek
Feljegyzés
Az alábbi modellek továbbra is támogatottak a visszamenőleges kompatibilitás érdekében. Javasoljuk, hogy a fenti szakaszokban említett új modellt használja, és a szerzői felhasználói felület átállt az új modell létrehozására.
Örökölt adathalmaz-modell
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | Az adathalmaz típustulajdonságának AzureDataLakeStoreFile értékre kell állítania. | Igen |
| folderPath | A Data Lake Store mappájának elérési útja. Ha nincs megadva, a gyökérre mutat. A helyettesítő karakterek szűrője támogatott. Az engedélyezett helyettesítő karakterek * (nulla vagy több karakter) és ? (nulla vagy egyetlen karakternek felel meg). A feloldás akkor használható ^ , ha a mappa tényleges neve helyettesítő karakterrel vagy ezzel a feloldó karakterrel rendelkezik. Például: gyökérmappák/almappák/. További példák a mappa- és fájlszűrő példákban. |
Nem |
| fileName | A megadott "folderPath" alatti fájlok neve vagy helyettesítő karaktere. Ha nem ad meg értéket ehhez a tulajdonsághoz, az adathalmaz a mappában lévő összes fájlra mutat. Szűrő esetén az engedélyezett * helyettesítő karakterek (nulla vagy több karakter) és ? (nulla vagy egyetlen karakternek felel meg).- 1. példa: "fileName": "*.csv"- 2. példa: "fileName": "???20180427.txt"A feloldás akkor használható ^ , ha a tényleges fájlnévben helyettesítő karakter vagy ez a feloldó karakter található.Ha a fileName nincs megadva kimeneti adatkészlethez, és a preserveHierarchy nincs megadva a tevékenység fogadójában, a másolási tevékenység automatikusan létrehozza a fájlnevet a következő mintával: "Data.[ tevékenységfuttatás azonosítója GUID]. [GUID ha FlattenHierarchy]. [formátum, ha konfigurálva van]. [tömörítés, ha konfigurálva van]", például "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Ha táblázatos forrásból másol le lekérdezés helyett táblázatnevet, a névminta a következő: "[táblanév].[ formátum]. [tömörítés, ha konfigurálva van]", például "MyTable.csv". |
Nem |
| modifiedDatetimeStart | A fájlok szűrése a Legutóbb módosítva attribútum alapján történik. A fájlok akkor lesznek kijelölve, ha az utolsó módosításuk időpontja nagyobb vagy egyenlő, modifiedDatetimeStart mint modifiedDatetimeEnda . Az idő az UTC időzónára "2018-12-01T05:00:00Z" formátumban lesz alkalmazva. Az adatáthelyezés általános teljesítményét befolyásolja, hogy engedélyezi ezt a beállítást, ha nagy mennyiségű fájlt tartalmazó fájlszűrőt szeretne végezni. A tulajdonságok null értékűek lehetnek, ami azt jelenti, hogy az adathalmazra nincs fájlattribútum-szűrő alkalmazva. Ha modifiedDatetimeStart van dátum/idő értéke, de modifiedDatetimeEnd NULL értékű, az azt jelenti, hogy a rendszer azokat a fájlokat jelöli ki, amelyek utolsó módosított attribútuma nagyobb vagy egyenlő a datetime értéknél. Ha modifiedDatetimeEnd dátum/idő érték van megadva, de modifiedDatetimeStart NULL értékű, az azt jelenti, hogy az utolsó módosított attribútummal rendelkező fájlok kisebbek a datetime értéknél. |
Nem |
| modifiedDatetimeEnd | A fájlok szűrése a Legutóbb módosítva attribútum alapján történik. A fájlok akkor lesznek kijelölve, ha az utolsó módosításuk időpontja nagyobb vagy egyenlő, modifiedDatetimeStart mint modifiedDatetimeEnda . Az idő az UTC időzónára "2018-12-01T05:00:00Z" formátumban lesz alkalmazva. Az adatáthelyezés általános teljesítményét befolyásolja, hogy engedélyezi ezt a beállítást, ha nagy mennyiségű fájlt tartalmazó fájlszűrőt szeretne végezni. A tulajdonságok null értékűek lehetnek, ami azt jelenti, hogy az adathalmazra nincs fájlattribútum-szűrő alkalmazva. Ha modifiedDatetimeStart van dátum/idő értéke, de modifiedDatetimeEnd NULL értékű, az azt jelenti, hogy a rendszer azokat a fájlokat jelöli ki, amelyek utolsó módosított attribútuma nagyobb vagy egyenlő a datetime értéknél. Ha modifiedDatetimeEnd dátum/idő érték van megadva, de modifiedDatetimeStart NULL értékű, az azt jelenti, hogy az utolsó módosított attribútummal rendelkező fájlok kisebbek a datetime értéknél. |
Nem |
| format | Ha fájlokat szeretne másolni a fájlalapú tárolók (bináris másolás) között, hagyja ki a formátumszakaszt a bemeneti és kimeneti adatkészlet-definíciókban. Ha adott formátumú fájlokat szeretne elemezni vagy létrehozni, a következő fájlformátumtípusok támogatottak: TextFormat, JsonFormat, AvroFormat, OrcFormat és ParquetFormat. A formátum alatti típustulajdonság beállítása az alábbi értékek egyikére. További információ: Szöveg, JSON formátum, Avro formátum, Orc formátum és Parquet formátum szakaszok. |
Nem (csak bináris másolási forgatókönyv esetén) |
| tömörítés | Adja meg az adatok tömörítési típusát és szintjét. További információ: Támogatott fájlformátumok és tömörítési kodekek. A támogatott típusok a GZip, a Deflate, a BZip2 és a ZipDeflate. A támogatott szintek optimálisak és leggyorsabbak. |
Nem |
Tipp.
Ha az összes fájlt át szeretné másolni egy mappában, csak a folderPath értéket adja meg.
Ha egyetlen fájlt szeretne másolni egy adott névvel, adja meg a folderPath mappát egy mapparészlel és egy fájlnévvel rendelkező fileName értéket.
Ha egy mappa alá szeretné másolni a fájlok egy részhalmazát, adja meg a folderPath mappát egy mapparészlel, a fileName tulajdonságot pedig helyettesítő karakter szűrővel.
Példa:
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Régi másolási tevékenység forrásmodellje
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A type másolási tevékenység forrásának tulajdonságát az AzureDataLakeStoreSource értékre kell állítani. |
Igen |
| rekurzív | Azt jelzi, hogy az adatok rekurzív módon vannak-e beolvasva az almappákból vagy csak a megadott mappából. Ha recursive igaz értékre van állítva, és a fogadó fájlalapú tároló, a rendszer nem másol vagy hoz létre üres mappát vagy almappát a fogadóban. Az engedélyezett értékek értéke igaz (alapértelmezett) és hamis. |
Nem |
| maxConcurrentConnections | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
Példa:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Régi másolási tevékenység fogadómodellje
| Tulajdonság | Leírás | Kötelező |
|---|---|---|
| típus | A type másolási tevékenység fogadójának tulajdonságát az AzureDataLakeStoreSink értékre kell állítani. |
Igen |
| copyBehavior | Meghatározza a másolási viselkedést, ha a forrás fájlalapú adattárból származó fájlok. Az engedélyezett értékek a következők: - PreserveHierarchy (alapértelmezett): Megőrzi a fájlhierarchiát a célmappában. A forrásfájlnak a forrásmappához viszonyított elérési útja megegyezik a célfájl célmappához viszonyított elérési útával. - FlattenHierarchy: A forrásmappából származó összes fájl a célmappa első szintjén található. A célfájlok automatikusan létrehozott névvel rendelkeznek. - MergeFiles: A forrásmappából származó összes fájlt egyetlen fájlba egyesíti. Ha a fájlnév meg van adva, az egyesített fájlnév a megadott név. Ellenkező esetben a fájlnév automatikusan létre lesz hozva. |
Nem |
| maxConcurrentConnections | Az adattárhoz a tevékenység futtatása során létrehozott egyidejű kapcsolatok felső korlátja. Csak akkor adjon meg értéket, ha korlátozni szeretné az egyidejű kapcsolatokat. | Nem |
Példa:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Adatrögzítés módosítása (előzetes verzió)
Az Azure Data Factory csak az Azure Data Lake Storage Gen1-ből tud új vagy módosított fájlokat lekérni, ha engedélyezi a változásadatok rögzítésének (előzetes verzió) engedélyezését a leképezési adatfolyam-forrásátalakításban. Ezzel az összekötővel csak új vagy frissített fájlokat olvashat, és átalakításokat alkalmazhat, mielőtt az átalakított adatokat betöltené a választott céladatkészletekbe.
Győződjön meg arról, hogy a folyamat és a tevékenység neve változatlan marad, hogy az ellenőrzőpont mindig rögzíthető legyen az utolsó futtatásból a módosítások lekéréséhez. Ha módosítja a folyamat nevét vagy tevékenységnevét, az ellenőrzőpont alaphelyzetbe lesz állítva, és a következő futtatás kezdetétől kezdve fog elindulni.
A folyamat hibakeresésekor a Módosítási adatrögzítés engedélyezése (előzetes verzió) is működik. Az ellenőrzőpont alaphelyzetbe áll, amikor frissíti a böngészőt a hibakeresési futtatás során. Miután elégedett a hibakeresési futtatás eredményével, közzéteheti és aktiválhatja a folyamatot. A hibakeresési futtatás által rögzített előző ellenőrzőponttól függetlenül mindig az elejétől indul.
A figyelési szakaszban mindig lehetősége van egy folyamat újrafuttatására. Ha így tesz, a módosítások mindig a kiválasztott folyamatfuttatás ellenőrzőpont-rekordjából származnak.
Kapcsolódó tartalom
A másolási tevékenység által forrásként és fogadóként támogatott adattárak listáját a támogatott adattárakban találja.