Oktatóanyag: Gépi tanulási alkalmazás létrehozása az Apache Spark MLlib és Azure Synapse Analytics használatával
Ebből a cikkből megtudhatja, hogyan hozhat létre olyan gépi tanulási alkalmazást az Apache Spark MLlib használatával, amely egyszerű prediktív elemzést végez egy Azure-beli nyílt adathalmazon. A Spark beépített gépi tanulási kódtárakat biztosít. Ez a példa logisztikai regresszión keresztüli besorolást használ.
A SparkML és az MLlib alapvető Spark-kódtárak, amelyek számos olyan segédprogramot biztosítanak, amelyek hasznosak a gépi tanulási feladatokhoz, beleértve a következőkhöz megfelelő segédprogramokat:
- Besorolás
- Regresszió
- Fürtözés
- Témakörmodellezés
- Szingular value decomposition (SVD) és a fő összetevő elemzése (PCA)
- Hipotézistesztelés és mintastatisztikák kiszámítása
A besorolás és a logisztikai regresszió ismertetése
A besorolás, amely népszerű gépi tanulási feladat, a bemeneti adatok kategóriákba rendezésének folyamata. Egy besorolási algoritmus feladata, hogy kitalálja, hogyan rendelhet címkéket a megadott bemeneti adatokhoz. Gondolhat például egy gépi tanulási algoritmusra, amely bemenetként fogadja el a készletinformációkat, és két kategóriába osztja az állományt: az eladandó készleteket és azokat a készleteket, amelyeket meg kell tartania.
A logisztikai regresszió a besoroláshoz használható algoritmus. A Spark logisztikai regressziós API-ja hasznos bináris besoroláshoz, vagy a bemeneti adatok két csoport egyikébe való besorolásához. A logisztikai regresszióval kapcsolatos további információkért lásd a Wikipédiát.
Összefoglalva, a logisztikai regresszió folyamata egy logisztikai függvényt hoz létre, amellyel előre jelezheti annak valószínűségét, hogy egy bemeneti vektor az egyik csoportba vagy a másikba tartozik.
Prediktív elemzési példa nyc taxiadatokra
Ebben a példában a Spark használatával prediktív elemzést végez a New York-i taxi-utazási tipp adatairól. Az adatok az Azure Open-adathalmazokon keresztül érhetők el. Az adathalmaz ezen részhalmaza információkat tartalmaz a sárga taxis utakról, beleértve az egyes utazásokkal, a kezdési és befejezési időpontokkal, a helyszínekkel, a költségek és egyéb érdekes attribútumokkal kapcsolatos információkat.
Fontos
Előfordulhat, hogy az adatok tárolási helyről való lekérése további költségekkel jár.
A következő lépésekben egy modellt fejleszt, amely előrejelzi, hogy egy adott utazás tartalmaz-e tippet.
Apache Spark gépi tanulási modell létrehozása
Hozzon létre egy jegyzetfüzetet a PySpark kernel használatával. Útmutatásért lásd: Jegyzetfüzet létrehozása.
Importálja az alkalmazáshoz szükséges típusokat. Másolja és illessze be a következő kódot egy üres cellába, majd nyomja le a Shift+Enter billentyűkombinációt. Vagy futtassa a cellát a kódtól balra található kék lejátszás ikonnal.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorA PySpark kernel miatt nem kell explicit módon környezeteket létrehoznia. A Spark-környezet automatikusan létrejön Az első kódcella futtatásakor.
A bemeneti DataFrame létrehozása
Mivel a nyers adatok Parquet formátumúak, a Spark-környezettel közvetlenül DataFrame-ként lekérheti a fájlt a memóriába. Bár a következő lépésekben szereplő kód az alapértelmezett beállításokat használja, szükség esetén kényszeríthető az adattípusok és más sémaattribútumok leképezése.
Futtassa az alábbi sorokat egy Spark DataFrame létrehozásához, ha beilleszti a kódot egy új cellába. Ez a lépés lekéri az adatokat az Open Datasets API-val. Az összes adat lekérése körülbelül 1,5 milliárd sort hoz létre.
A kiszolgáló nélküli Apache Spark-készlet méretétől függően előfordulhat, hogy a nyers adatok túl nagyok, vagy túl sok időt vesznek igénybe a működéshez. Ezeket az adatokat kisebbre is szűrheti. Az alábbi példakód egy olyan szűrőt használ
start_dateésend_datealkalmaz, amely egyetlen hónapnyi adatot ad vissza.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Az egyszerű szűrés hátránya, hogy statisztikai szempontból torzítást eredményezhet az adatokban. Egy másik megközelítés a Sparkba beépített mintavételezés használata.
Az alábbi kód körülbelül 2000 sorra csökkenti az adathalmazt, ha az előző kód után van alkalmazva. Ezt a mintavételezési lépést használhatja az egyszerű szűrő helyett vagy az egyszerű szűrővel együtt.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Most már meg lehet nézni az adatokat, hogy lássa, mi volt olvasott. Általában jobb, ha az adatokat az adatkészlet méretétől függően a teljes készlet helyett egy részhalmazsal tekinti át.
Az alábbi kód kétféleképpen tekintheti meg az adatokat. Az első módszer az alapszintű. A második módszer sokkal gazdagabb rácsélményt biztosít, valamint az adatok grafikus megjelenítésének képességét.
#sampled_taxi_df.show(5) display(sampled_taxi_df)A létrehozott adatkészlet méretétől és a jegyzetfüzet többszöri kísérletezéséhez vagy futtatásához szükségestől függően érdemes lehet az adathalmazt helyileg gyorsítótárazni a munkaterületen. Az explicit gyorsítótárazásnak három módja van:
- Mentse a DataFrame-et helyileg fájlként.
- Mentse a DataFrame-et ideiglenes táblaként vagy nézetként.
- Mentse a DataFrame-et állandó táblaként.
Az alábbi példakódok a fenti megközelítések első két részét tartalmazzák.
Az ideiglenes tábla vagy nézet létrehozása különböző elérési utakat biztosít az adatokhoz, de csak a Spark-példány munkamenetének időtartamára tart.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Az adatok előkészítése
A nyers formában lévő adatok gyakran nem alkalmasak közvetlenül a modellnek való továbbításra. Több műveletet kell végrehajtania az adatokon ahhoz, hogy olyan állapotba juttassa, amelyben a modell felhasználhatja őket.
A következő kódban négy műveletosztályt hajt végre:
- Kiugró értékek vagy helytelen értékek eltávolítása szűréssel.
- Az oszlopok eltávolítása, amelyekre nincs szükség.
- A nyers adatokból származó új oszlopok létrehozása a modell hatékonyabbá tétele érdekében. Ezt a műveletet néha featurizációnak is nevezik.
- Címkézés. Mivel bináris besorolást végez (lesz-e tipp egy adott utazáson, vagy nem), a tippösszeget 0 vagy 1 értékké kell konvertálnia.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Ezután egy második továbbítást kell végeznie az adatokon a végső funkciók hozzáadásához.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Logisztikai regressziós modell létrehozása
Az utolsó feladat a címkézett adatok olyan formátumba konvertálása, amely logisztikai regresszióval elemezhető. A logisztikai regressziós algoritmus bemenetének címke-/funkcióvektorpároknak kell lennie, ahol a funkcióvektor a bemeneti pontot jelképező számok vektora.
Ezért a kategorikus oszlopokat számmá kell konvertálnia. Pontosabban a és weekdayString az trafficTimeBins oszlopokat egész számábrázolásokká kell konvertálnia. Az átalakítás végrehajtásának több módszere is van. Az alábbi példa a OneHotEncoder gyakori megközelítésre mutat.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Ez a művelet egy új DataFrame-et eredményez, amely a modell betanítása érdekében az összes oszlopot a megfelelő formátumban tartalmazza.
Logisztikai regressziós modell betanítása
Az első feladat az adathalmaz felosztása betanítási csoportra, valamint egy tesztelési vagy érvényesítési csoportra. A felosztás itt tetszőleges. Kísérletezzen a különböző felosztási beállításokkal annak megtekintéséhez, hogy hatással vannak-e a modellre.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Most, hogy két DataFrame van, a következő feladat a modellképlet létrehozása és futtatása a betanítási DataFrame-ben. Ezután ellenőrizheti a tesztelési DataFrame-et. Kísérletezzen a modellképlet különböző verzióival a különböző kombinációk hatásának megtekintéséhez.
Megjegyzés
A modell mentéséhez rendelje hozzá a Storage-blobadatok közreműködője szerepkört a Azure SQL Adatbázis-kiszolgáló erőforrás-hatóköréhez. A részletes lépésekért tekintse meg az Azure-szerepköröknek az Azure Portalon történő hozzárendelését ismertető cikket. Ezt a lépést csak tulajdonosi jogosultságokkal rendelkező tagok hajthatják végre.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
A cellából származó kimenet a következő:
Area under ROC = 0.9779470729751403
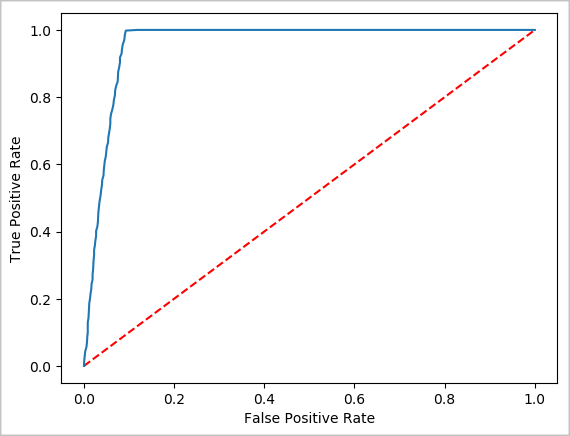
Az előrejelzés vizuális ábrázolásának létrehozása
Most már létrehozhat egy végleges vizualizációt, amely segít a teszt eredményeinek okának megismerésében. A ROC-görbe az eredmény áttekintésének egyik módja.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
A Spark-példány leállítása
Miután befejezte az alkalmazás futtatását, állítsa le a jegyzetfüzetet az erőforrások felszabadításához a lap bezárásával. Vagy válassza a Munkamenet befejezése lehetőséget a jegyzetfüzet alján található állapotpanelen.
Lásd még
Következő lépések
- Az Apache Sparkhoz készült .NET dokumentációja
- Azure Synapse Analytics
- Az Apache Spark hivatalos dokumentációja
Megjegyzés
Néhány hivatalos Apache Spark-dokumentáció a Spark-konzol használatára támaszkodik, amely nem érhető el az Apache Sparkon Azure Synapse Analyticsben. Használja inkább a jegyzetfüzetet vagy az IntelliJ-felületet .