Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
Ebben az oktatóanyagban a Spark-futtatókörnyezettel rendelkező jegyzetfüzetekkel alakíthatja át és készítheti elő a nyers adatokat a lakehouse-ban.
Prerequisites
Ha nincs olyan tóháza, amely adatokat tartalmaz, a következőket kell tennie:
Adatok előkészítése
Az előző oktatóanyag lépéseiből nyers adatok vannak betöltve a forrásból a lakehouse Fájlok szakaszára. Most átalakíthatja és előkészítheti az adatokat Delta-táblák létrehozására.
Töltse le a jegyzetfüzeteket a Lakehouse Oktatóanyag forráskód mappájából.
Nyissa meg a munkaterületet, és válassza aJegyzetfüzet>importálása>a számítógépről lehetőséget.
Válassza a Jegyzetfüzet importálása lehetőséget a kezdőlap tetején található Új szakaszból.
Válassza a Feltöltés lehetőséget a képernyő jobb oldalán megnyíló Importálás állapotpanelen .
Jelölje ki a szakasz első lépésében letöltött összes jegyzetfüzetet.
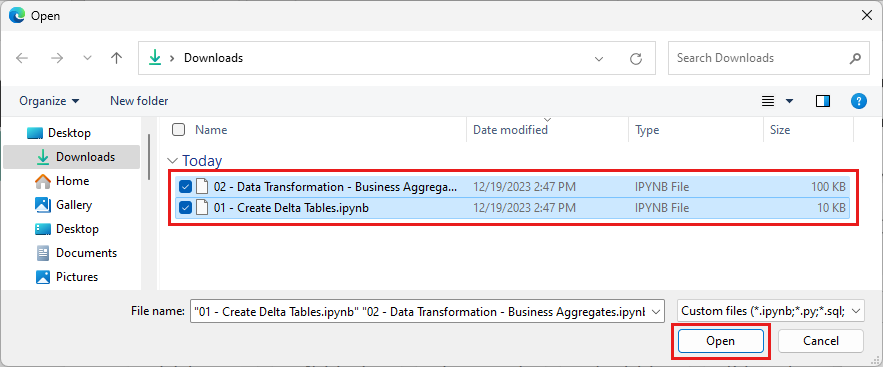
Válassza a Megnyitás lehetőséget. Az importálás állapotát jelző értesítés a böngészőablak jobb felső sarkában jelenik meg.
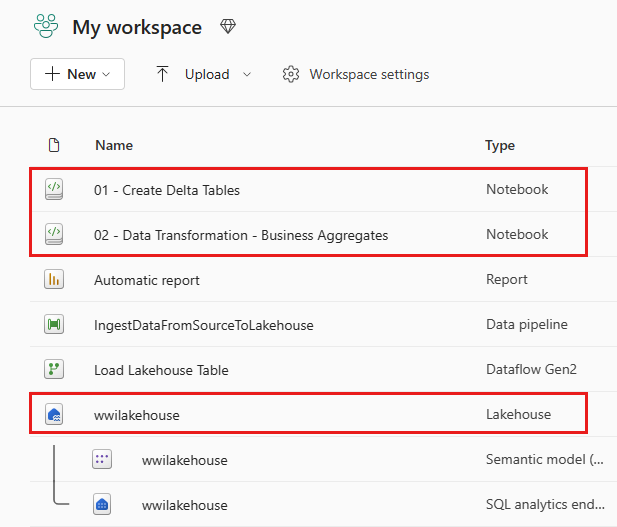
Az importálás sikeressége után nyissa meg a munkaterület elemnézetét, és tekintse meg az újonnan importált jegyzetfüzeteket. Nyissa meg a wwilakehouse lakehouse-t.
A wwilakehouse lakehouse megnyitása után válassza a Meglévő jegyzetfüzet> megnyitásalehetőséget a felső navigációs menüben.
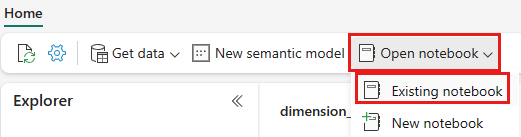
A meglévő jegyzetfüzetek listájában válassza a 01 – Változástáblák létrehozása jegyzetfüzetet, és válassza a Megnyitás lehetőséget.
A lakehouse Explorer megnyitott jegyzetfüzetében láthatja, hogy a jegyzetfüzet már kapcsolódik a megnyitott tóházhoz.
Note
A Fabric biztosítja az optimalizált Delta lake-fájlok írására alkalmas V-rendelési képességet. A V-order gyakran 3-4-szer javítja a tömörítést, és akár 10-szeres teljesítménygyorsítást a nem optimalizált Delta Lake-fájlokon. A Spark in Fabric dinamikusan optimalizálja a partíciókat, miközben alapértelmezett 128 MB méretű fájlokat hoz létre. A célfájl mérete számítási feladatonként konfigurációk használatával módosítható.
Az Írás optimalizálása funkcióval az Apache Spark-motor csökkenti az írott fájlok számát, és célja az írott adatok egyedi fájlméretének növelése.
Mielőtt Delta lake-táblákként ír adatokat a tóház Táblák szakaszában, két Fabric-funkciót (V-order és Optimize Write) használ az optimalizált adatíráshoz és a jobb olvasási teljesítményhez. Ha engedélyezni szeretné ezeket a funkciókat a munkamenetben, állítsa be ezeket a konfigurációkat a jegyzetfüzet első cellájában.
A jegyzetfüzet elindításához és az összes cella egymás utáni végrehajtásához válassza az Összes futtatása a felső menüszalagon (a Kezdőlap alatt). Vagy ha csak egy adott cellából szeretne kódot végrehajtani, jelölje ki a cella bal oldalán megjelenő Futtatás ikont, vagy nyomja le a SHIFT + ENTER billentyűkombinációt a billentyűzeten, miközben a vezérlő a cellában van.
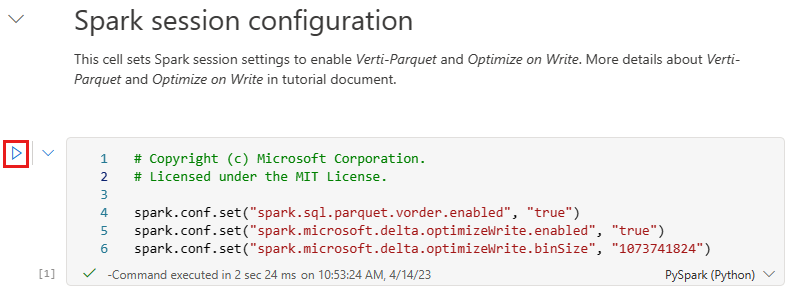
Cella futtatásakor nem kellett megadnia az alapul szolgáló Spark-készlet vagy -fürt adatait, mert a Fabric élő készleten keresztül biztosítja őket. Minden Háló-munkaterülethez tartozik egy alapértelmezett Spark-készlet, az úgynevezett Élő készlet. Ez azt jelenti, hogy jegyzetfüzetek létrehozásakor nem kell aggódnia a Spark-konfigurációk vagy a fürt részleteinek megadása miatt. Amikor végrehajtja az első jegyzetfüzetparancsot, az élő készlet néhány másodperc alatt működik. A Spark-munkamenet létrejött, és megkezdi a kód végrehajtását. A következő kódvégrehajtás szinte azonnal megtörténik ebben a jegyzetfüzetben, amíg a Spark-munkamenet aktív.
Ezután a tóház Fájlok szakaszából olvashat nyers adatokat, és az átalakítás részeként további oszlopokat adhat hozzá a különböző dátumrészekhez. Végül a Partition By Spark API használatával particionálhatja az adatokat, mielőtt az újonnan létrehozott adatrészoszlopok (év és negyedév) alapján Delta-táblázatformátumként íratja.
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)A ténytáblák betöltése után továbbléphet a többi dimenzió adatainak betöltésére. Az alábbi cella létrehoz egy függvényt, amely nyers adatokat olvas be a tóház Fájlok szakaszából minden paraméterként átadott táblanévhez. Ezután létrehozza a dimenziótáblák listáját. Végül végighalad a táblák listáján, és létrehoz egy Delta-táblát a bemeneti paraméterből beolvasott minden egyes táblanévhez. Vegye figyelembe, hogy a szkript elveti az ebben a példában elnevezett
Photooszlopot, mert az oszlop nincs használatban.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)A létrehozott táblák ellenőrzéséhez kattintson a jobb gombbal, és válassza a wwilakehouse lakehouse frissítését. Megjelennek a táblák.
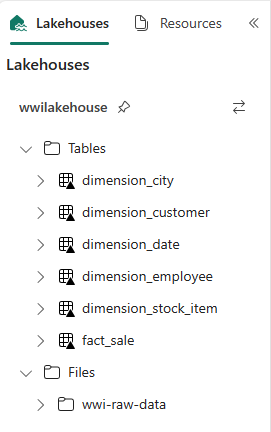
Nyissa meg újra a munkaterület elemnézetét, és válassza ki a wwilakehouse lakehouse-t a megnyitásához.
Most nyissa meg a második jegyzetfüzetet. A lakehouse nézetben válassza aMeglévő jegyzetfüzet>megnyitásalehetőséget a menüszalagon.
A meglévő jegyzetfüzetek listájában válassza a 02 – Adatátalakítás – Üzleti jegyzetfüzetet a megnyitásához.
A lakehouse Explorer megnyitott jegyzetfüzetében láthatja, hogy a jegyzetfüzet már kapcsolódik a megnyitott tóházhoz.
Előfordulhat, hogy a szervezet adatmérnökei a Scalával/Pythonnal, valamint az SQL-vel (Spark SQL vagy T-SQL) dolgozó más adatmérnökökkel dolgoznak, és mindegyik ugyanazon az adatpéldányon dolgozik. A Fabric lehetővé teszi, hogy ezek a különböző csoportok változatos tapasztalattal és preferencia mellett működjenek és működjenek együtt. A két különböző megközelítés átalakítja és létrehozza az üzleti aggregátumokat. Kiválaszthatja az Önnek megfelelőt, vagy keverheti és megfeleltetheti ezeket a megközelítéseket a preferenciája alapján anélkül, hogy veszélyeztetné a teljesítményt:
1. megközelítés – A PySpark használatával összekapcsolhatja és összesítheti az üzleti aggregátumok létrehozásához szükséges adatokat. Ez a megközelítés előnyösebb, ha valaki programozási (Python vagy PySpark) háttérrel rendelkezik.
2. megközelítés – A Spark SQL használata az üzleti aggregátumok létrehozásához szükséges adatok összekapcsolásához és összesítéséhez. Ez a megközelítés előnyösebb egy SQL-háttérrel rendelkező személy számára, aki a Sparkra vált.
1. megközelítés (sale_by_date_city) – A PySpark használatával összekapcsolhatja és összesítheti az üzleti aggregátumok létrehozásához szükséges adatokat. Az alábbi kóddal három különböző Spark-adatkeretet hozhat létre, mindegyik egy meglévő Delta-táblára hivatkozik. Ezután az adatkeretek használatával összekapcsolja ezeket a táblákat, csoportosítja az összesítést, átnevez néhány oszlopot, és végül Delta-táblázatként írja a tóház Táblák szakaszában az adatok megőrzéséhez.
Ebben a cellában három különböző Spark-adatkeretet hoz létre, mindegyik egy meglévő Delta-táblára hivatkozik.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Adja hozzá a következő kódot ugyanahhoz a cellához, hogy a korábban létrehozott adatkeretek használatával csatlakozzon ezekhez a táblákhoz. Csoportosítással összesítést hozhat létre, átnevezhet néhány oszlopot, és végül Delta-táblaként írhatja a lakehouse Táblák szakaszában.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")2. megközelítés (sale_by_date_employee) – A Spark SQL használatával összekapcsolhatja és összesítheti az üzleti aggregátumok létrehozásához szükséges adatokat. Az alábbi kóddal egy ideiglenes Spark-nézetet hozhat létre három tábla összekapcsolásával, csoportosítással összesítést hozhat létre, és átnevezhet néhány oszlopot. Végül felolvassa az ideiglenes Spark nézetet, és végül Delta-táblaként írja a lakehouse Táblák szakaszába, hogy megőrizze az adatokat.
Ebben a cellában egy ideiglenes Spark-nézetet hoz létre három tábla összekapcsolásával, csoportosítással összesítést hoz létre, és átnevez néhány oszlopot.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCEbben a cellában az előző cellában létrehozott ideiglenes Spark-nézetből olvas, és végül Delta-táblázatként írja a tóház Táblák szakaszába.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")A létrehozott táblák ellenőrzéséhez kattintson a jobb gombbal, és válassza a Frissítés lehetőséget a wwilakehouse lakehouse-on. Megjelennek az összesítő táblák.
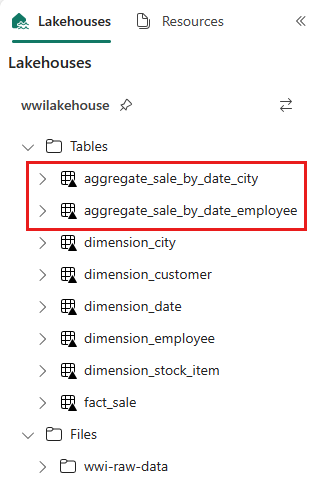







A két megközelítés hasonló eredményt ad. Annak érdekében, hogy minimalizálja az új technológia elsajátítását vagy a teljesítményre vonatkozó kompromisszumot, válassza ki azt a megközelítést, amely a legjobban megfelel a háttérnek és a preferencia-nak.
Észreveheti, hogy Delta Lake-fájlokként ír adatokat. A Fabric automatikus táblafelderítési és -regisztrációs funkciója felveszi és regisztrálja őket a metaadattárban. Nem kell explicit módon meghívnia CREATE TABLE az utasításokat az SQL-hez használandó táblák létrehozásához.