Összetett modell útmutatója a Power BI Desktopban
Ez a cikk power BI-összetett modelleket fejlesztő adatmodellezőket céloz meg. Ez az összetett modellhasználati eseteket ismerteti, és tervezési útmutatást nyújt. Az útmutató segítséget nyújt annak meghatározásában, hogy egy összetett modell megfelel-e a megoldásnak. Ha igen, akkor ez a cikk az optimális összetett modellek és jelentések tervezésében is segít.
Feljegyzés
Ebben a cikkben nem foglalkozunk az összetett modellek bemutatásával. Ha nem ismeri teljesen az összetett modelleket, javasoljuk, hogy először olvassa el az Összetett modellek használata című cikket a Power BI Desktopban .
Mivel az összetett modellek legalább egy DirectQuery-forrásból állnak, fontos, hogy alaposan megismerje a modellkapcsolatokat, a DirectQuery-modelleket és a DirectQuery-modellek tervezési útmutatóját.
Összetett modell használati esetei
Az összetett modell definíció szerint több forráscsoportot egyesít. A forráscsoportok az importált adatokat vagy a DirectQuery-forráshoz való kapcsolatot jelölhetik. A DirectQuery-forrás lehet relációs adatbázis vagy egy másik táblázatos modell, amely lehet Power BI szemantikai modell (korábbi nevén adathalmaz) vagy Analysis Services táblázatos modell. Amikor egy táblázatos modell egy másik táblázatos modellhez csatlakozik, azt láncolásnak nevezzük. További információ: A DirectQuery használata Power BI szemantikai modellekhez és Analysis Serviceshez.
Feljegyzés
Ha egy modell táblázatos modellhez csatlakozik, de nem bővíti ki további adatokkal, az nem összetett modell. Ebben az esetben ez egy DirectQuery-modell, amely egy távoli modellhez csatlakozik, tehát csak egy forráscsoportból áll. Létrehozhat ilyen típusú modellt a forrásmodell objektumtulajdonságainak módosításához, például táblanév, oszlop rendezési sorrend vagy sztring formázása céljából.
A táblázatos modellekre való Csatlakozás különösen fontos egy vállalati szemantikai modell kiterjesztésekor (power BI szemantikai modell vagy Analysis Services-modell esetén). A vállalati szemantikai modell alapvető fontosságú az adattárház fejlesztéséhez és működéséhez. Absztrakciós réteget biztosít az adattárházban lévő adatok felett az üzleti definíciók és a terminológia bemutatásához. Gyakran használják fizikai adatmodellek és jelentéskészítő eszközök, például a Power BI közötti kapcsolatként. A legtöbb szervezetben egy központi csapat kezeli, ezért nevezik nagyvállalatnak. További információkért tekintse meg a vállalati BI használati forgatókönyvét.
Az alábbi helyzetekben érdemes lehet összetett modellt fejleszteni.
- A modell lehet DirectQuery-modell, és növelni szeretné a teljesítményt. Az összetett modellben az egyes táblákhoz megfelelő tároló beállításával javíthatja a teljesítményt. Felhasználó által definiált összesítéseket is hozzáadhat. Mindkét optimalizálást a cikk későbbi részében ismertetjük.
- Egy DirectQuery-modellt több adattal szeretne kombinálni, amelyeket importálni kell a modellbe. Az importált adatokat betöltheti egy másik adatforrásból vagy számított táblákból.
- Két vagy több DirectQuery-adatforrást szeretne egyetlen modellbe egyesíteni. Ezek a források lehetnek relációs adatbázisok vagy más táblázatos modellek.
Feljegyzés
Az összetett modellek nem tartalmazhatnak kapcsolatokat bizonyos külső elemzési adatbázisokhoz. Ezek az adatbázisok közé tartozik az SAP Business Warehouse és az SAP HANA, amikor az SAP HANA-t többdimenziós forrásként kezeli.
Egyéb modelltervezési beállítások kiértékelése
Bár a Power BI összetett modelljei bizonyos tervezési kihívásokat oldhatnak meg, hozzájárulhatnak a lassú teljesítményhez. Bizonyos helyzetekben váratlan számítási eredmények is előfordulhatnak (erről a cikk későbbi részében olvashat). Ezen okokból értékelje ki az egyéb modelltervezési lehetőségeket, ha léteznek.
Amikor csak lehetséges, a legjobb, ha importáló módban fejleszt egy modellt. Ez a mód biztosítja a legnagyobb tervezési rugalmasságot és a legjobb teljesítményt.
A nagy adatmennyiségekkel vagy a közel valós idejű adatokkal kapcsolatos problémák azonban nem mindig oldhatók meg importálási modellekkel. Bármelyik ilyen esetben megfontolhat egy DirectQuery-modellt, feltéve, hogy az adatok egyetlen, DirectQuery módban támogatott adatforrásban vannak tárolva. További információ: DirectQuery-modellek a Power BI Desktopban.
Tipp.
Ha a cél csak egy meglévő táblázatos modell kiterjesztése több adattal, lehetőség szerint adja hozzá ezeket az adatokat a meglévő adatforráshoz.
Táblatárolási mód
Összetett modellben minden táblához beállíthatja a tárolási módot (kivéve a számított táblákat).
- DirectQuery: Javasoljuk, hogy ezt a módot olyan táblákhoz állítsa be, amelyek nagy adatmennyiségeket jelölnek, vagy amelyeknek közel valós idejű eredményeket kell nyújtaniuk. Az adatok soha nem lesznek importálva ezekbe a táblákba. Ezek a táblák általában tény típusú táblák, amelyek összegzett táblák.
- Importálás: Javasoljuk, hogy ezt a módot olyan táblákhoz állítsa be, amelyek nem a DirectQuery vagy hibrid módban használják a ténytáblák szűrésére és csoportosítására. Ez az egyetlen lehetőség a DirectQuery mód által nem támogatott forrásokon alapuló táblákhoz is. A számított táblák mindig importálnak táblákat.
- Kettős: Azt javasoljuk, hogy ezt a módot dimenzió típusú táblákhoz állítsa be, ha lehetséges, hogy azokat a DirectQuery tény típusú táblákkal együtt kérdezik le ugyanabból a forrásból.
- Hibrid: Azt javasoljuk, hogy ezt a módot importálási partíciókkal és egy DirectQuery-partícióval állítsa be egy ténytáblába, ha valós időben szeretné megjeleníteni a legújabb adatváltozásokat, vagy ha gyors hozzáférést szeretne biztosítani a leggyakrabban használt adatokhoz importálási partíciókon keresztül, miközben a ritkán használt adatok nagy részét az adattárházban hagyja.
A Power BI több esetben is lekérdez egy összetett modellt.
- A lekérdezések csak importálást vagy kettős táblát használnak: A Power BI az összes adatot lekéri a modellgyorsítótárból. A lehető leggyorsabb teljesítményt nyújtja. Ez a forgatókönyv gyakori a szűrők vagy szeletelővizualizációk által lekérdezett dimenzió típusú táblák esetében.
- Kéttáblás vagy DirectQuery-tábla(ok) lekérdezése ugyanabból a forrásból: A Power BI az összes adatot lekéri úgy, hogy egy vagy több natív lekérdezést küld a DirectQuery-forrásnak. Ez jó teljesítményt nyújt, különösen akkor, ha megfelelő indexek találhatók a forrástáblákon. Ez a forgatókönyv gyakori kettős dimenzió típusú táblákat és DirectQuery-tény típusú táblákat összekapcsoló lekérdezéseknél. Ezek a lekérdezések forráscsoporton belüliek, ezért a rendszer minden egy-az-egyhez vagy egy-a-többhöz kapcsolatot normál kapcsolatként értékel ki.
- Két tábla vagy hibrid tábla lekérdezése ugyanabból a forrásból: Ez a forgatókönyv az előző két forgatókönyv kombinációja. A Power BI akkor kéri le az adatokat a modellgyorsítótárból, ha az importálási partíciókban elérhető, ellenkező esetben egy vagy több natív lekérdezést küld a DirectQuery-forrásnak. A lehető leggyorsabb teljesítményt nyújtja, mert az adattárházban csak az adatok egy szelete kérdezhető le, különösen akkor, ha a forrástáblákban megfelelő indexek találhatók. Ami a kettős dimenzió típusú táblákat és a DirectQuery tény típusú táblákat illeti, ezek a lekérdezések forráscsoporton belüliek, így minden egy-az-egyhez vagy egy-a-többhöz kapcsolat normál kapcsolatként lesz kiértékelve.
- Minden más lekérdezés: Ezek a lekérdezések forráscsoportközi kapcsolatokat foglalnak magukban. Ennek az az oka, hogy egy importálási tábla DirectQuery-táblához kapcsolódik, vagy egy kettős tábla egy másik forrásból származó DirectQuery-táblához kapcsolódik – ebben az esetben importálási táblaként viselkedik. A rendszer minden kapcsolatot korlátozott kapcsolatként értékel ki. Azt is jelenti, hogy a nem DirectQuery-táblákra alkalmazott csoportosításokat materializált részqueriesként (virtuális táblákként) kell elküldeni a DirectQuery-forrásnak. Ebben az esetben a natív lekérdezés nem hatékony, különösen nagy csoportosítási csoportok esetén.
Összefoglalva, javasoljuk, hogy:
- Gondosan gondolja át, hogy az összetett modell a megfelelő megoldás – bár lehetővé teszi a különböző adatforrások modellszintű integrációját, de lehetséges következményekkel járó tervezési összetettségeket is bevezet (a cikk későbbi részében).
- Állítsa a tárolási módot DirectQueryre , ha egy tábla egy nagy adatmennyiségeket tároló tény típusú tábla, vagy ha közel valós idejű eredményeket kell szolgáltatnia.
- Fontolja meg a hibrid mód használatát növekményes frissítési szabályzat és valós idejű adatok definiálásával, vagy a ténytábla tom, TMSL vagy külső eszköz használatával történő particionálásával. További információ: Növekményes frissítés és valós idejű adatok szemantikai modellekhez és a speciális adatmodell-kezelési használati forgatókönyvhöz.
- Állítsa a tárolási módot Kettős értékre, ha egy tábla dimenzió típusú tábla, és a rendszer directQuery vagy hibrid tény típusú táblákkal együtt kérdezi le, amelyek ugyanabban a forráscsoportban találhatók.
- Állítsa be a megfelelő frissítési gyakoriságokat, hogy a modell gyorsítótára szinkronban maradjon a forrásadatbázis(ok)tal a kettős és hibrid táblák (és a függő számított táblák) esetében.
- Törekedjen az adatintegritás biztosítására a forráscsoportokban (beleértve a modellgyorsítótárat is), mert a korlátozott kapcsolatok megszüntetik a lekérdezési eredmények sorait, ha a kapcsolódó oszlopértékek nem egyeznek.
- Amikor csak lehetséges, optimalizálja a DirectQuery-adatforrásokat a megfelelő indexekkel a hatékony illesztéshez, szűréshez és csoportosításhoz.
Felhasználó által definiált összesítések
Felhasználó által definiált összesítéseket adhat a DirectQuery-táblákhoz. Céljuk a nagyobb szemcsés lekérdezések teljesítményének javítása.
A modellben gyorsítótárazott összesítések importálási táblákként viselkednek (bár nem használhatók modelltáblázatként). Az importálási aggregációk DirectQuery-modellhez való hozzáadása összetett modellt eredményez.
Feljegyzés
A hibrid táblák nem támogatják az aggregációkat, mert egyes partíciók importálási módban működnek. Az egyes DirectQuery-partíciók szintjén nem lehet aggregációkat hozzáadni.
Javasoljuk, hogy az összesítés egy alapvető szabályt kövessen: A sorszámnak legalább 10-rel kisebbnek kell lennie, mint az alapul szolgáló tábla. Ha például az alapul szolgáló tábla 1 milliárd sort tárol, akkor az összesítő tábla nem haladhatja meg a 100 millió sort. Ez a szabály biztosítja, hogy az összesítés létrehozásának és fenntartásának költségeihez képest megfelelő teljesítménynövekedés legyen.
Forráscsoportközi kapcsolatok
Ha egy modellkapcsolat kiterjed a forráscsoportokra, akkor ezt forráscsoportközi kapcsolatnak nevezzük. A forráscsoportközi kapcsolatok is korlátozott kapcsolatok, mert nincs garantált "egy" oldal. További információ: Kapcsolatértékelés.
Feljegyzés
Bizonyos helyzetekben elkerülheti a forráscsoportközi kapcsolatok létrehozását. A cikk későbbi részében tekintse meg a Szinkronizálási szeletelők használata című témakört.
Forráscsoportközi kapcsolatok definiálásakor vegye figyelembe az alábbi javaslatokat.
- Alacsony számosságú kapcsolatoszlopok használata: A legjobb teljesítmény érdekében azt javasoljuk, hogy a kapcsolatoszlopok alacsony számosságúak legyenek, ami azt jelenti, hogy kevesebb mint 50 000 egyedi értéket kell tárolniuk. Ez a javaslat különösen igaz a táblázatos modellek és a nem szöveges oszlopok kombinálásakor.
- Kerülje a nagy szöveges kapcsolatoszlopok használatát: Ha szövegoszlopokat kell használnia egy kapcsolatban, számítsa ki a szűrő várható szöveghosszát úgy, hogy megszorozza a számosságot a szövegoszlop átlagos hosszával. A szöveg lehetséges hossza nem haladhatja meg az 1 000 000 karaktert.
- A kapcsolat részletességének növelése: Ha lehetséges, hozzon létre kapcsolatokat magasabb részletességi szinten. Például ahelyett, hogy egy dátumtáblát a dátumkulcsához kapcsolódóan használnál, használd inkább a hónapkulcsot. Ez a tervezési megközelítés megköveteli, hogy a kapcsolódó táblázat tartalmaz egy hónap kulcsoszlopot, és a jelentések nem tudják megjeleníteni a napi tényeket.
- Törekedjen egyszerű kapcsolattervezésre: Csak akkor hozzon létre forráscsoportközi kapcsolatot, ha szükség van rá, és próbálja meg korlátozni a táblák számát a kapcsolati útvonalon. Ez a tervezési megközelítés segít javítani a teljesítményt, és elkerülni a kétértelmű kapcsolati útvonalakat.
Figyelmeztetés
Mivel a Power BI Desktop nem ellenőrzi alaposan a forráscsoportok közötti kapcsolatokat, kétértelmű kapcsolatokat is létrehozhat.
Forráscsoportközi kapcsolati forgatókönyv 1
Fontolja meg egy összetett kapcsolat kialakításának forgatókönyvét, és azt, hogy hogyan hozhat létre különböző – mégis érvényes – eredményeket.
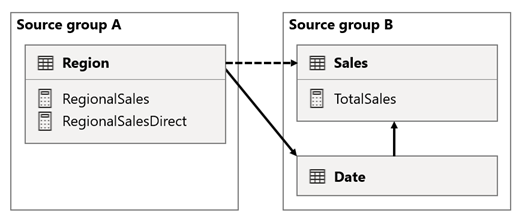
Ebben a forgatókönyvben az A forráscsoport Régió táblája kapcsolatban áll a B forráscsoport Dátum és Értékesítés táblával. A Régió tábla és a Dátum tábla közötti kapcsolat aktív, míg a Régió tábla és az Értékesítés tábla közötti kapcsolat inaktív. Emellett aktív kapcsolat van a Region tábla és a Sales tábla között, amelyek mindegyike a B forráscsoportban található. A Sales tábla tartalmaz egy TotalSales nevű mértéket, a Régió tábla pedig két, RegionalSales és RegionalSalesDirect nevű mértéket.
Íme a mértékdefiníciók.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Figyelje meg, hogy a RegionalSales mérték hogyan hivatkozik a TotalSales mértékre , míg a RegionalSalesDirect mérték nem. Ehelyett a RegionalSalesDirect mérték a TotalSales mérték kifejezését SUM(Sales[Sales])használja.
Az eredmény különbsége finom. Amikor a Power BI kiértékeli a RegionalSales mértéket, a Régió táblából származó szűrőt a Sales és a Date táblára is alkalmazza. Ezért a szűrő a Dátum táblából a Sales táblába is propagálja. Ezzel szemben, amikor a Power BI kiértékeli a RegionalSalesDirect mértéket, csak a Régió táblából propagálja a szűrőt a Sales táblába. A RegionalSales mérték és a RegionalSalesDirect mérték által visszaadott eredmények eltérőek lehetnek, annak ellenére, hogy a kifejezések szemantikailag egyenértékűek.
Fontos
Amikor egy távoli forráscsoportban mértékként használt kifejezéssel használja a CALCULATE függvényt, alaposan tesztelje a számítási eredményeket.
Forráscsoportközi kapcsolati forgatókönyv 2
Fontolja meg azt a forgatókönyvet, amikor egy forráscsoport közötti kapcsolat magas számosságú kapcsolatoszlopokkal rendelkezik.
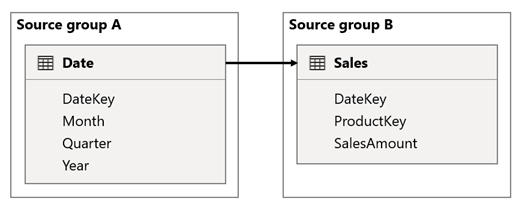
Ebben a forgatókönyvben a Date tábla a DateKey oszlopok Sales táblájára vonatkozik. A DateKey oszlopok adattípusa egész szám, amely az yymmdd formátumot használó egész számokat tárolja. A táblák különböző forráscsoportokhoz tartoznak. Emellett ez egy magas számosságú kapcsolat, mivel a Dátum tábla legkorábbi dátuma 1900. január 1., a legutóbbi dátum pedig 2100. december 31. – tehát összesen 73 414 sor van a táblában (az 1900–2100-ig tartó időszak minden dátumának egy sora).
Két ügy van aggodalomra ad okot.
Először is, ha a Dátum tábla oszlopait használja szűrőkként, a szűrőpropagálás a Sales tábla DateKey oszlopát szűri a mértékek kiértékeléséhez. Ha egyetlen év( például 2022) alapján szűr, a DAX-lekérdezés egy olyan szűrőkifejezést fog tartalmazni, mint a Sales[DateKey] IN { 20220101, 20220102, …20221231 }. A lekérdezés szövegmérete rendkívül nagy lehet, ha a szűrőkifejezésben lévő értékek száma nagy, vagy ha a szűrőértékek hosszú sztringek. A Power BI költségesen hozza létre a hosszú lekérdezést és az adatforrás számára a lekérdezés futtatását.
Másodszor, ha dátumtábla oszlopokat (például Év, Negyedév vagy Hónap) használ csoportosítási oszlopként, az olyan szűrőket eredményez, amelyek tartalmazzák az év, negyedév vagy hónap összes egyedi kombinációját, valamint a DateKey oszlop értékeit. A lekérdezés sztringmérete, amely szűrőket tartalmaz a csoportosítási oszlopokon és a kapcsolatoszlopon, rendkívül nagy lehet. Ez különösen akkor igaz, ha a csoportosítási oszlopok száma és/vagy az illesztési oszlop (a DateKey oszlop) számossága nagy.
A teljesítménnyel kapcsolatos problémák megoldásához az alábbiakat teheti:
- Adja hozzá a Dátum táblát az adatforráshoz, és egyetlen forráscsoportmodellt eredményez (ami azt jelenti, hogy az már nem összetett modell).
- Növelje a kapcsolat részletességét. Hozzáadhat például egy MonthKey oszlopot mindkét táblához, és létrehozhatja a kapcsolatot ezeken az oszlopokon. A kapcsolat részletességének növelésével azonban elveszíti a napi értékesítési tevékenységek jelentésének képességét (kivéve, ha a Sales tábla DateKey oszlopát használja).
Forráscsoportközi kapcsolati forgatókönyv 3
Akkor érdemes megfontolni egy forgatókönyvet, ha nem egyeznek egyező értékek a táblák között a forráscsoportközi kapcsolatokban.
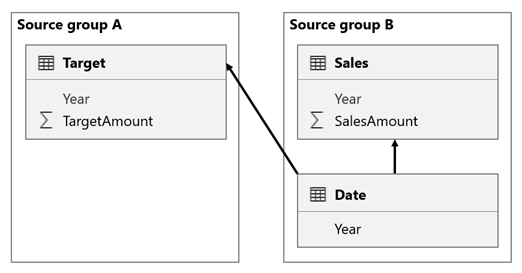
Ebben a forgatókönyvben a B forráscsoport Dátum táblája kapcsolatban áll az adott forráscsoport Sales táblával és az A forráscsoport Cél táblával. Minden kapcsolat egy-a-többhöz az Év oszlopokkal kapcsolatos Date táblából. A Sales tábla tartalmaz egy SalesAmount oszlopot, amely az értékesítési összegeket tárolja, a Céltábla pedig egy TargetAmount oszlopot, amely a célösszegeket tárolja.
A Date tábla a 2021-2022-et tárolja. A Sales tábla a 2021-es (100) és a 2022-es (200) évre, a Céltábla pedig a 2021-es (100), a 2022-es (200) és a 2023-ra (300) vonatkozó célösszegeket tárolja– egy jövőbeli évre vonatkozóan.
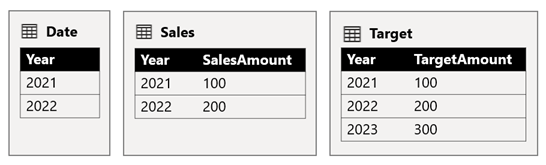
Amikor egy Power BI-táblavizualizáció lekérdezi az összetett modellt a Date tábla Év oszlopának csoportosításával és a SalesAmount és a TargetAmount oszlopok összegzésével, az nem jeleníti meg a 2023-ra vonatkozó célértéket. Ennek az az oka, hogy a forráscsoportközi kapcsolat egy korlátozott kapcsolat, ezért szemantikát használ INNER JOIN , amely kiküszöböli azokat a sorokat, ahol nincs egyező érték mindkét oldalon. Ez azonban megfelelő célösszeget (600) eredményez, mivel a Dátumtábla szűrő nem vonatkozik a kiértékelésére.
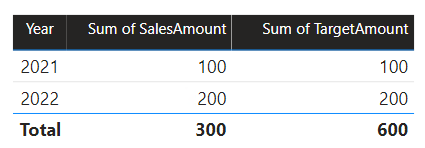
Ha a Dátum tábla és a Cél tábla közötti kapcsolat egy forráscsoporton belüli kapcsolat (feltéve, hogy a Céltábla a B forráscsoporthoz tartozik), a vizualizáció egy (üres) évet fog tartalmazni a 2023-ra (és bármely más nem egyező évre) vonatkozó célösszeg megjelenítéséhez.
Fontos
A helytelen bejelentés elkerülése érdekében győződjön meg arról, hogy a kapcsolatoszlopokban vannak egyező értékek, ha a dimenzió- és ténytáblák különböző forráscsoportokban találhatók.
A korlátozott kapcsolatokról további információt a Kapcsolat kiértékelése című témakörben talál.
Számítások
Ha számított oszlopokat és számítási csoportokat ad hozzá egy összetett modellhez, figyelembe kell vennie bizonyos korlátozásokat.
Számított oszlopok
A DirectQuery-táblához hozzáadott számított oszlopok, amelyek az adataikat egy relációs adatbázisból, például a Microsoft SQL Serverből származtatják, olyan kifejezésekre korlátozódnak, amelyek egyszerre egyetlen sorban működnek. Ezek a kifejezések nem használhatják a DAX iterátorfüggvényeket, például SUMXa környezetmódosítási függvényeket, például CALCULATE.
Feljegyzés
Nem lehet olyan számított oszlopokat vagy számított táblákat hozzáadni, amelyek láncolt táblázatos modellektől függenek.
A távoli DirectQuery-táblák számított oszlopkifejezései csak soron belüli kiértékelésre korlátozódnak. Létrehozhat azonban egy ilyen kifejezést, de az egy vizualizációban való használat során hibát fog eredményezni. Ha például egy DimProduct nevű távoli DirectQuery-táblához hozzáad egy számított oszlopot a kifejezés [Product Sales] / SUM (DimProduct[ProductSales])használatával, sikeresen mentheti a kifejezést a modellben. Ez azonban hibát fog eredményezni, ha egy vizualizációban használják, mert megsérti a soron belüli kiértékelési korlátozást.
Ezzel szemben a távoli DirectQuery-táblához hozzáadott számított oszlopok rugalmasabbak, amelyek egy táblázatos modell, amely power BI szemantikai modell vagy Analysis Services-modell. Ebben az esetben az összes DAX-függvény engedélyezett, mert a kifejezés kiértékelése a forrás táblázatos modellben történik.
Számos kifejezés megköveteli, hogy a Power BI a számított oszlopot csoportként vagy szűrőként használja, vagy összesítse. Ha egy számított oszlop egy nagy táblán keresztül valósul meg, a processzor és a memória szempontjából költséges lehet attól függően, hogy a számított oszlop milyen számosságtól függ. Ebben az esetben javasoljuk, hogy ezeket a számított oszlopokat adja hozzá a forrásmodellhez.
Feljegyzés
Ha számított oszlopokat ad hozzá egy összetett modellhez, mindenképpen tesztelje az összes modellszámítást. Előfordulhat, hogy a felsőbb rétegbeli számítások nem működnek megfelelően, mert nem tekintették a szűrőkörnyezetre gyakorolt hatásukat.
Számítási csoportok
Ha olyan forráscsoportban vannak számítási csoportok, amelyek Power BI szemantikai modellhez vagy Analysis Services-modellhez csatlakoznak, a Power BI váratlan eredményeket adhat vissza. További információ: Számítási csoportok, lekérdezések és mértékek kiértékelése.
Modellterv
A Power BI-modelleket mindig csillagséma-kialakítással kell optimalizálnia.
Tipp.
További információ: A csillagséma és a Power BI fontossága.
Mindenképpen hozzon létre olyan dimenziótáblákat, amelyek különböznek a ténytábláktól, hogy a Power BI megfelelően értelmezhesse az illesztéseket, és hatékony lekérdezési terveket hozhasson létre. Bár ez az útmutató minden Power BI-modellre igaz, különösen igaz azokra a modellekre, amelyek felismerése egy összetett modell forráscsoportjává válik. Lehetővé teszi a többi tábla egyszerűbb és hatékonyabb integrációját az alsóbb rétegbeli modellekben.
Amikor csak lehetséges, kerülje, hogy dimenziótáblák legyenek egy olyan forráscsoportban, amely egy másik forráscsoport ténytábláihoz kapcsolódik. Ennek az az oka, hogy a forráscsoporton belüli kapcsolatok jobbak, mint a forráscsoportközi kapcsolatok, különösen a nagy számosságú kapcsolatoszlopok esetében. A korábban leírtaknak megfelelően a forráscsoportközi kapcsolatok a kapcsolatoszlopokban lévő egyező értékekre támaszkodnak, máskülönben váratlan eredmények jelenhetnek meg a jelentésvizualizációkban.
Sorszintű biztonság
Ha a modell felhasználó által definiált összesítéseket, importált táblák számított oszlopait vagy számított táblákat tartalmaz, győződjön meg arról, hogy a sorszintű biztonság (RLS) megfelelően van beállítva és tesztelve.
Ha az összetett modell más táblázatos modellekhez csatlakozik, az RLS-szabályok csak azon a forráscsoporton (helyi modellen) lesznek alkalmazva, ahol definiálva vannak. Ezek más forráscsoportokra (távoli modellekre) nem lesznek alkalmazva. Nem definiálhat RLS-szabályokat egy táblán egy másik forráscsoportból, és nem definiálhat RLS-szabályokat egy olyan helyi táblán, amely egy másik forráscsoporthoz kapcsolódik.
Jelentésterv
Bizonyos esetekben optimalizált jelentéselrendezés kialakításával javíthatja az összetett modellek teljesítményét.
Egyforráscsoportos vizualizációk
Amikor csak lehetséges, hozzon létre olyan vizualizációkat, amelyek egyetlen forráscsoport mezőit használják. Ennek az az oka, hogy a vizualizációk által létrehozott lekérdezések jobban fognak teljesíteni, ha az eredményt egyetlen forráscsoportból kérik le. Érdemes lehet két egymás mellett elhelyezett vizualizációt létrehozni, amelyek két különböző forráscsoportból kérnek le adatokat.
Szinkronizálási szeletelők használata
Bizonyos esetekben beállíthatja a szinkronizálási szeletelőket , hogy ne hozzon létre forráscsoportközi kapcsolatot a modellben. Lehetővé teszi, hogy vizuálisan egyesítse a forráscsoportokat, amelyek jobban teljesíthetnek.
Fontolja meg azt a forgatókönyvet, amikor a modell két forráscsoportot használ. Minden forráscsoport rendelkezik egy termékdimenziós táblával, amellyel szűrheti a viszonteladói és internetes értékesítéseket.
Ebben az esetben az A forráscsoport a ResellerSales táblához kapcsolódó Termék táblát tartalmazza. A B forráscsoport az InternetSales táblához kapcsolódó Product2 táblát tartalmazza. Nincs forráscsoportközi kapcsolat.
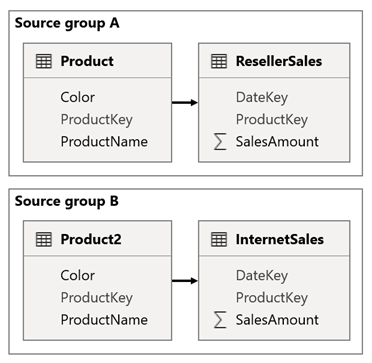
A jelentésben hozzáad egy szeletelőt, amely a Termék tábla Szín oszlopával szűri a lapot. A szeletelő alapértelmezés szerint a ResellerSales táblát szűri , az InternetSales táblát azonban nem. Ezután a Product2 tábla Szín oszlopával hozzáadhat egy rejtett szeletelőt. Ha egy azonos csoportnevet ad meg (a szinkronizálási szeletelők speciális beállításai között található), a látható szeletelőre alkalmazott szűrők automatikusan propagálásra kerülnek a rejtett szeletelőbe.
Feljegyzés
A szinkronizálási szeletelők használata elkerülheti a forráscsoportok közötti kapcsolat létrehozását, ami növeli a modell kialakításának összetettségét. Mindenképpen tájékoztassa a többi felhasználót arról, hogy miért tervezte a modellt ismétlődő dimenziótáblákkal. A félreértések elkerülése érdekében rejtse el azokat a dimenziótáblákat, amelyeket más felhasználók nem szeretnének használni. A rejtett táblákhoz leírási szöveget is hozzáadhat a céljuk dokumentálásához.
További információ: Különálló szeletelők szinkronizálása.
Egyéb útmutató
Az alábbiakban további útmutatást talál az összetett modellek tervezéséhez és karbantartásához.
- Teljesítmény és skálázás: Ha a jelentések korábban élőben csatlakoztak egy Power BI szemantikai modellhez vagy Analysis Services-modellhez, a Power BI szolgáltatás újra felhasználhatja a vizualizációs gyorsítótárakat a jelentések között. Miután az élő kapcsolatot helyi DirectQuery-modellté alakította át, a jelentések már nem fogják kihasználni ezeket a gyorsítótárakat. Ennek eredményeképpen előfordulhat, hogy lassabb teljesítményt vagy akár frissítési hibákat tapasztal. Emellett a Power BI szolgáltatás számítási feladatai is növekedni fognak, ami szükségessé teheti a kapacitás vertikális felskálázását vagy a számítási feladat más kapacitások közötti elosztását. Az adatok frissítésével és gyorsítótárazásával kapcsolatos további információkért lásd : Adatfrissítés a Power BI-ban.
- Átnevezés: Nem javasoljuk, hogy az összetett modellek által használt szemantikai modelleket nevezze át, és ne nevezze át a munkaterületüket. Ennek az az oka, hogy az összetett modellek a munkaterület és a szemantikai modellnevek (és nem a belső egyedi azonosítók) használatával csatlakoznak a Power BI szemantikai modelljeihez. A szemantikai modell vagy munkaterület átnevezése megszakíthatja az összetett modell által használt kapcsolatokat.
- Irányítás: Nem javasoljuk, hogy az igazságmodell egyetlen verziója összetett modell legyen. Ennek az az oka, hogy más adatforrásoktól vagy modellektől függ, amelyek frissítésekor az összetett modell feltörése is előfordulhat. Ehelyett azt javasoljuk, hogy az igazság egyetlen verziójaként tegyen közzé egy vállalati szemantikai modellt. Tekintsük ezt a modellt megbízható alapnak. Más adatmodellezők ezután összetett modelleket hozhatnak létre, amelyek kibővítik az alapmodellt a speciális modellek létrehozásához.
- Adatkimenet: Az összetett modell módosításainak közzététele előtt használja az adatkimeneti és szemantikai modell hatáselemzési funkcióit. Ezek a funkciók a Power BI szolgáltatás érhetők el, és segítenek megérteni, hogyan kapcsolódnak és használhatók a szemantikai modellek. Fontos tisztában lenni azzal, hogy nem végezhet hatáselemzést olyan külső szemantikai modelleken, amelyek vonalas nézetben jelennek meg, de valójában egy másik munkaterületen találhatók. Ha külső szemantikai modellen szeretne hatáselemzést végezni, keresse meg a forrás-munkaterületet.
- Sémafrissítések: Az összetett modellt frissítenie kell a Power BI Desktopban, ha a sémamódosítások a felsőbb rétegbeli adatforrásokban történnek. Ezután újra közzé kell tennie a modellt a Power BI szolgáltatás. Ügyeljen arra, hogy alaposan tesztelje a számításokat és a függő jelentéseket.
Kapcsolódó tartalom
A cikkhez kapcsolódó további információkért tekintse meg az alábbi forrásokat.
- Összetett modellek használata a Power BI Desktopban
- Modellkapcsolatok a Power BI Desktopban
- DirectQuery-modellek a Power BI Desktopban
- A DirectQuery használata a Power BI Desktopban
- A DirectQuery használata Power BI szemantikai modellekhez és Analysis Serviceshez
- Tárolási mód a Power BI Desktopban
- Felhasználó által definiált összesítések
- Kérdése van? Kérdezze meg a Power BI-közösség
- Javaslatok? Ötletek hozzáadása a Power BI fejlesztéséhez
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: