AI-elemzések használata a Power BI Desktopban
A Power BI-ban a AI-elemzések használatával hozzáférhet az előre betanított gépi tanulási modellek gyűjteményéhez, amelyek javítják az adat-előkészítési erőfeszítéseket. A Power Query-szerkesztő AI-elemzések érheti el. A kapcsolódó funkciókat és függvényeket a Kezdőlap és az Oszlop hozzáadása lapon találja meg a Power Query-szerkesztő.
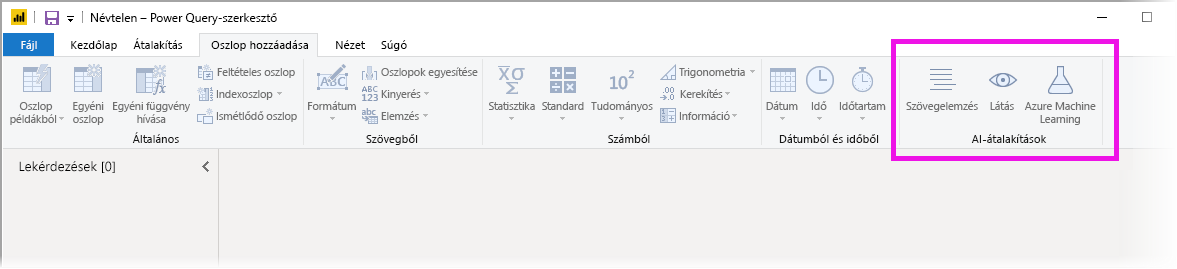
Ez a cikk az Azure Cognitive Services Text Analytics- és Vision-függvényeinek funkcióit ismerteti. Ebben a cikkben az Azure Machine Tanulás power BI-ban elérhető egyéni függvényeket is ismerteti.
A Text Analytics és a Vision használata
A Text Analytics és a Vision a Power BI-ban az Azure Cognitive Services különböző algoritmusaival bővítheti az adatokat a Power Queryben.
Jelenleg a következő szolgáltatások támogatottak:
Az átalakítások végrehajtása a Power BI szolgáltatás történik, és nincs szükség Azure Cognitive Services-előfizetésre.
Fontos
A Text Analytics vagy a Vision funkcióinak használatához a Power BI Premium szükséges.
A Text Analytics és a Vision engedélyezése prémium szintű kapacitásokon
A Cognitive Services az EM2, A2 vagy P1 prémium szintű kapacitáscsomópontokhoz és más, több erőforrással rendelkező csomópontokhoz támogatott. A cognitive services futtatásához külön AI-számítási feladatot használ a kapacitáson. A Cognitive Services Power BI-ban való használata előtt engedélyeznie kell az AI-számítási feladatot a felügyeleti portál kapacitásbeállításaiban . A számítási feladatok szakaszban bekapcsolhatja az AI-számítási feladatot, és meghatározhatja, hogy a számítási feladat mekkora memóriát használjon fel. Az ajánlott memóriakorlát 20%. Ha túllépi ezt a korlátot, a lekérdezés lelassul.
Elérhető függvények
Ez a szakasz a Power BI Cognitive Servicesben elérhető funkcióit ismerteti.
Nyelv felismerése
A Nyelvfelismerés függvény kiértékeli a szövegbevitelt, és minden mező esetében visszaadja a nyelv nevét és az ISO-azonosítót. Ez a függvény olyan adatoszlopok esetében hasznos, amelyek tetszőleges szöveget gyűjtenek, ahol a nyelv ismeretlen. A függvény szöveges formátumú adatokat vár bemenetként.
A Text Analytics 120 nyelv felismerésére képes. További információ: támogatott nyelvek.
Kulcsszavak kinyerése
A Kulcskifejezés-kinyerési függvény strukturálatlan szöveget értékel ki, és minden szövegmezőhöz a kulcskifejezések listáját adja vissza. A függvény bemenetként egy szövegmezőt igényel, és elfogadja a nyelvi ISO-kód opcionális bemenetét.
A kulcskifejezések kinyerése akkor működik a legjobban, ha nagyobb mennyiségű szöveget ad a munkához, ellentétben a hangulatelemzéssel. A hangulatelemzés jobb teljesítményt nyújt a kisebb szövegblokkokon. A legjobb eredmény elérése érdekében célszerű a bemenetet ennek megfelelően átszervezni.
Hangulatpontszámozás
A Score sentiment függvény kiértékeli a szövegbevitelt, és minden dokumentumhoz egy hangulatpontot ad vissza, amely 0 (negatív) és 1 (pozitív) között van. A score sentiment egy nyelvi ISO-kód opcionális bemenetét is elfogadja. Ez a funkció hasznos a pozitív és negatív hangulat észleléséhez a közösségi médiában, az ügyfelek véleményeiben és a vitafórumokon.
A Text Analytics gépi tanulási osztályozó algoritmussal generálja a 0 és 1 közötti hangulatpontszámot. Az 1-hez közelebbi pontszámok pozitív hangulatot jeleznek. A 0-hoz közelebbi pontszámok negatív hangulatot jeleznek. A modell előre betanításra kerül egy átfogó szövegtörzsgel, hangulattársításokkal. Jelenleg nem lehet saját betanítási adatokat megadni. A modell a szövegelemzés során több technika kombinációját alkalmazza, beleértve a szövegfeldolgozást, a beszédrészlet elemzést, a szóelhelyezést és szótársításokat. Az algoritmussal kapcsolatos további információk: A Text Analytics bemutatása.
A hangulatelemzés a teljes beviteli mezőben történik, szemben a szöveg egy adott entitásához tartozó hangulat kinyerésével. A gyakorlatban az a tendencia tapasztalható, hogy a pontozás pontossága javul, ha a dokumentumok egy vagy két mondatot tartalmaznak, nem pedig egy nagy szövegblokkot. Az objektivitás-felmérési fázisban a modell meghatározza, hogy egy bemeneti mező egésze objektív vagy hangulatot tartalmaz-e. A többnyire objektív beviteli mező nem halad tovább a hangulatészlelési kifejezésig, ami 0,50-es pontszámot eredményez, további feldolgozás nélkül. A folyamatban folytatódó bemeneti mezők esetében a következő fázis 0,50-nél nagyobb vagy kisebb pontszámot hoz létre a bemeneti mezőben észlelt hangulat mértékétől függően.
A Hangulatelemzés jelenleg az angol, német, spanyol és francia nyelvet támogatja. Más nyelvek előzetes verzióban érhetők el. További információ: támogatott nyelvek.
Képek címkézése
A Címkeképek függvény több mint 2000 felismerhető objektum, élőlény, táj és művelet alapján ad vissza címkéket. Ha a címkék nem egyértelműek vagy nem általánosak, a kimenet tippeket ad a címke jelentésének tisztázásához egy ismert beállítás kontextusában. A címkék nincsenek rendszerezve osztályozásként, és nem léteznek öröklési hierarchiák. A tartalomcímkék gyűjteménye képezi a teljes mondatokban formázott, emberi olvasásra alkalmas nyelvként megjelenített képleírás alapját.
Egy kép feltöltése vagy egy kép URL-címének megadása után a Computer Vision algoritmusok a képen azonosított objektumok, élőlények és műveletek alapján kimenetcímkéket adnak ki. A címkézés nem korlátozódik a kép fő témájára, például az előtérben szereplő személyre, hanem magában foglalja a környezetet (beltér vagy kültér), bútorokat, eszközöket, növényeket, állatokat, kiegészítőket, készülékeket stb.
Ehhez a függvényhez egy kép URL-címe vagy egy base-64 mező szükséges bemenetként. A képcímkézés jelenleg az angol, a spanyol, a japán, a portugál és az egyszerűsített kínai nyelvet támogatja. További információ: támogatott nyelvek.
Text Analytics- vagy Vision-függvények meghívása a Power Queryben
Az adatok Text Analytics- vagy Vision-függvényekkel való bővítéséhez nyissa meg a Power Query-szerkesztő. Ez a példa végigvezeti egy szöveg hangulatának pontozásán. Ugyanezekkel a lépésekkel kinyerheti a kulcskifejezéseket, észlelheti a nyelvet és címkézheti a képeket.
Válassza a Szövegelemzés gombot a Kezdőlapon vagy az Oszlop hozzáadása menüszalagon. Ezután jelentkezzen be, amikor megjelenik a kérdés.
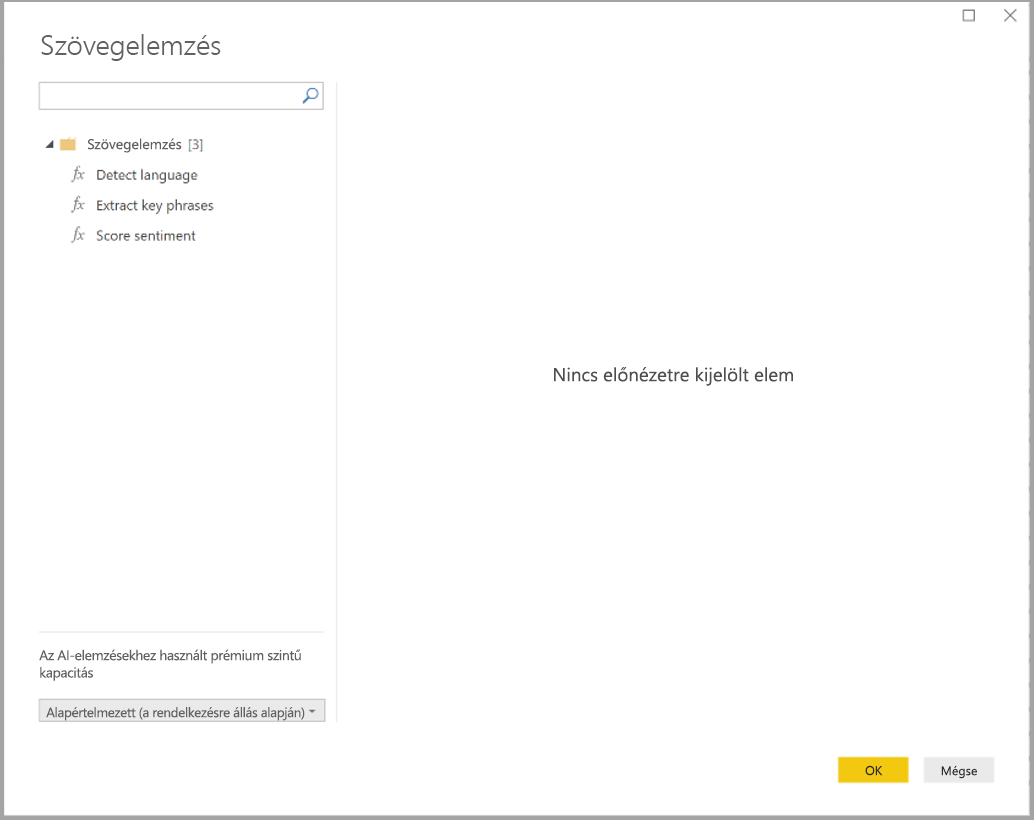
Bejelentkezés után válassza ki a használni kívánt függvényt és az előugró ablakban átalakítani kívánt adatoszlopot.
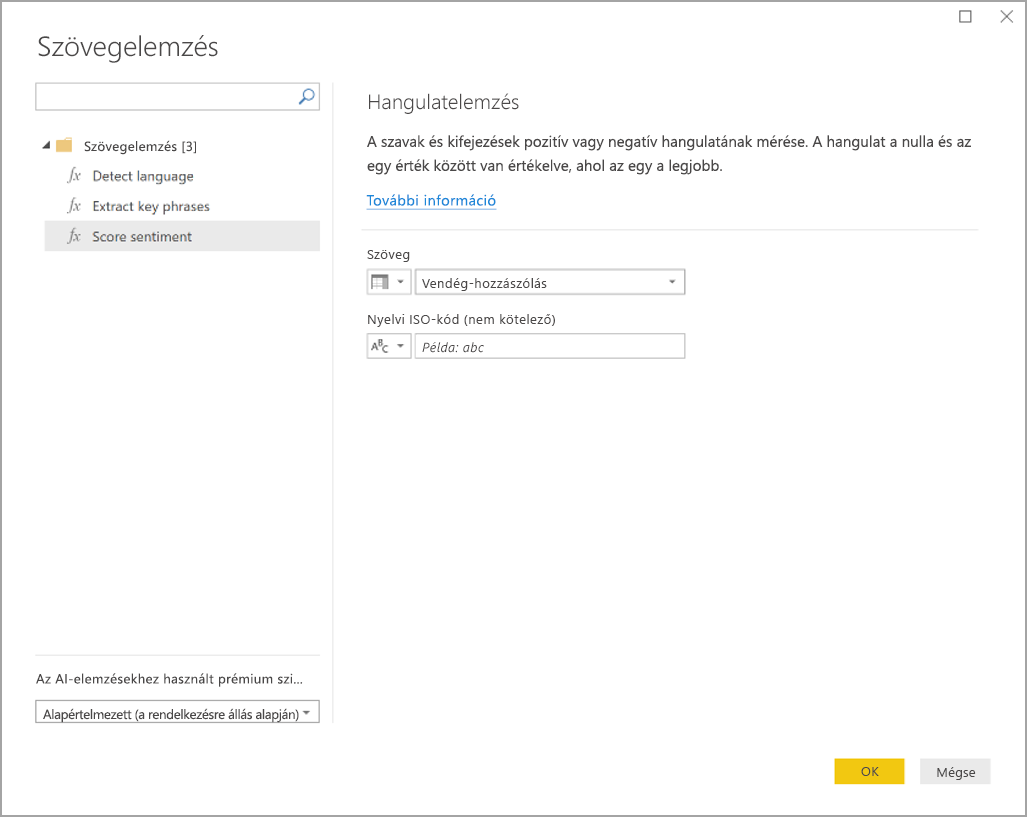
A Power BI kiválaszt egy Prémium szintű kapacitást a függvény futtatásához, és visszaküldi az eredményeket a Power BI Desktopnak. A kijelölt kapacitás csak a Text Analytics és a Vision függvényhez használható a Power BI Desktopban való alkalmazás és frissítések során. Miután a Power BI közzétette a jelentést, a frissítések azon a munkaterület prémium szintű kapacitásán futnak, amelyen a jelentést közzéteszik. Az előugró ablak bal alsó sarkában található legördülő menüben módosíthatja az összes Cognitive Serviceshez használt kapacitást.
A nyelvi ISO-kód opcionális bemenet a szöveg nyelvének megadásához. Használhatja az oszlopot bemenetként vagy statikus mezőként. Ebben a példában a nyelv angol (en) formátumban van megadva az egész oszlophoz. Ha üresen hagyja ezt a mezőt, a Power BI automatikusan észleli a nyelvet a függvény alkalmazása előtt. Ezután válassza az Alkalmaz elemet .
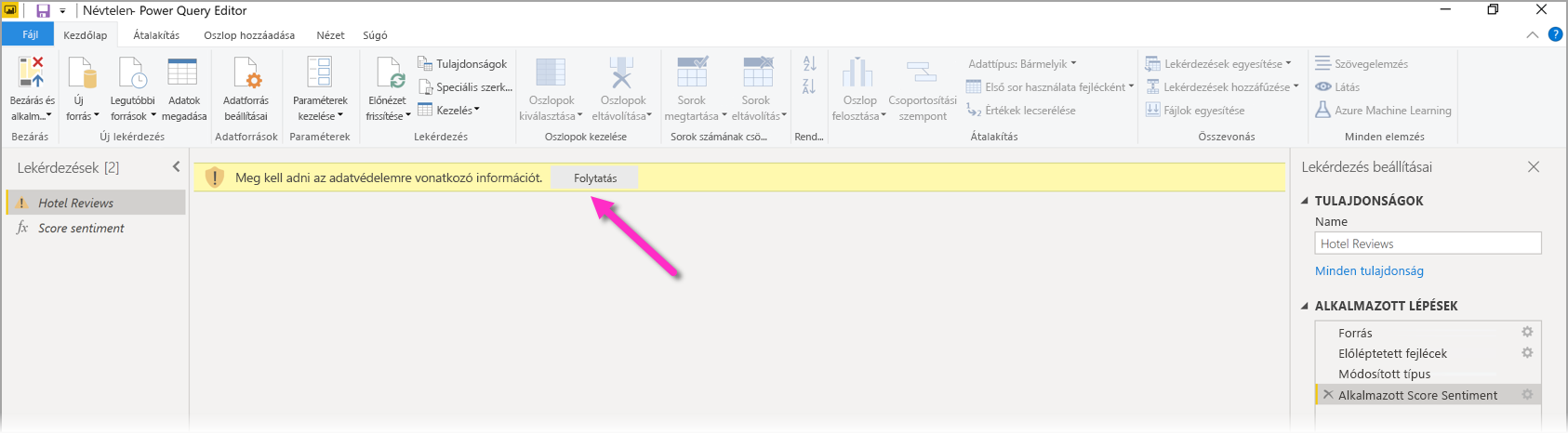
Amikor először használja az AI-elemzések egy új adatforráson, a Power BI Desktop kéri, hogy állítsa be az adatok adatvédelmi szintjét.
Feljegyzés
A Szemantikai modell frissítései a Power BI-ban csak olyan adatforrások esetében működnek, ahol az adatvédelmi szint nyilvános vagy szervezeti.
A függvény meghívása után az eredmény új oszlopként lesz hozzáadva a táblához. Az átalakítás a lekérdezés alkalmazott lépéseként is hozzáadódik.
A képcímkézés és a kulcskifejezések kinyerése esetén az eredmények több értéket is visszaadhatnak. A rendszer minden egyes eredményt az eredeti sor duplikációján ad vissza.
Jelentés közzététele Text Analytics- vagy Vision-függvényekkel
A Power Queryben végzett szerkesztés és a Power BI Desktopban végzett frissítések végrehajtása során a Text Analytics és a Vision a Power Query-szerkesztő-ben kiválasztott Prémium kapacitást használja. Miután a Text Analytics vagy a Vision közzétette a jelentést, annak a munkaterületnek a prémium szintű kapacitását használják, amelyben a jelentést közzétették.
Az alkalmazott Text Analytics- és Vision-függvényekkel rendelkező jelentéseket közzé kell tenni egy prémium szintű kapacitással rendelkező munkaterületen, ellenkező esetben a szemantikai modell frissítése sikertelen.
Prémium szintű kapacitásra gyakorolt hatás kezelése
A következő szakaszok bemutatják, hogyan kezelheti a Text Analytics és a Vision kapacitásra gyakorolt hatását.
Kapacitás kiválasztása
A jelentéskészítők kiválaszthatják azt a Prémium szintű kapacitást, amelyen futtatni szeretné a AI-elemzések. Alapértelmezés szerint a Power BI kiválasztja az első létrehozott kapacitást, amelyhez a felhasználó hozzáfér.
Monitorozás a Kapacitásmetrikák alkalmazással
A Prémium szintű kapacitástulajdonosok a Microsoft Fabric Kapacitásmetrikák alkalmazással figyelhetik a Text Analytics és a Vision függvények kapacitásra gyakorolt hatását. Az alkalmazás részletes metrikákat biztosít a kapacitáson belüli AI-számítási feladatok állapotáról. A felső diagram az AI-számítási feladatok memóriahasználatát mutatja. A prémium szintű kapacitásgazdák kapacitásonként beállíthatják az AI-számítási feladatok memóriakorlátját. Amikor a memóriahasználat eléri a memóriakorlátot, érdemes lehet növelni a memóriakorlátot, vagy áthelyezni néhány munkaterületet egy másik kapacitásba.
A Power Query és a Power Query Online összehasonlítása
A Power Queryben és a Power Query Online-ban használt Text Analytics és Vision függvények megegyeznek. A tapasztalatok között csak néhány különbség van:
- A Power Query külön gombokkal rendelkezik a Text Analytics, a Vision és az Azure Machine Tanulás számára. A Power Query Online-ban ezek a funkciók egyetlen menüben vannak kombinálva.
- A Power Queryben a jelentés készítője kiválaszthatja a függvények futtatásához használt Premium-kapacitást. Ez a választás nem szükséges a Power Query Online-ban, mivel egy adatfolyam már egy adott kapacitáson van.
A Text Analytics szempontjai és korlátozásai
A Text Analytics használatakor figyelembe kell venni néhány szempontot és korlátozást.
- A növekményes frissítés támogatott, de teljesítményproblémákat okozhat az AI-elemzéseket használó lekérdezésekben.
- A Közvetlen lekérdezés nem támogatott.
Az Azure Machine Learning használata
Számos vállalat gépi Tanulás modelleket használ a vállalkozásukkal kapcsolatos jobb elemzésekhez és előrejelzésekhez. A modellekből származó megállapítások vizualizációjának és meghívásának lehetősége segíthet ezeknek az elemzéseknek a terjesztésében azoknak az üzleti felhasználóknak, akiknek a leginkább szükségük van rá. A Power BI egyszerűvé teszi az Azure Machine Tanulás által üzemeltetett modellekből származó megállapítások egyszerű pont- és kattintásos kézmozdulatokkal történő beépítése.
Ennek a képességnek a használatához az adatelemző hozzáférést biztosíthat az Azure Machine Tanulás-modellhez a BI-elemző számára az Azure Portal használatával. Ezután minden munkamenet elején a Power Query felderíti az összes Azure Machine-Tanulás modellt, amelyhez a felhasználó hozzáfér, és dinamikus Power Query-függvényként teszi elérhetővé őket. A felhasználó ezután meghívhatja ezeket a függvényeket a Power Query-szerkesztő menüszalagjáról vagy közvetlenül az M függvény meghívásával. A Power BI automatikusan kötegeli a hozzáférési kérelmeket is, amikor az Azure Machine Tanulás-modellt invokálásakor sorkészletre kéri a jobb teljesítmény érdekében.
Ez a funkció támogatott a Power BI Desktopban, a Power BI-adatfolyamokban és a Power Query Online-ban a Power BI szolgáltatás.
Az adatfolyamokkal kapcsolatos további információkért tekintse meg az önkiszolgáló adat-előkészítést a Power BI-ban.
Az Azure Machine Tanulás az alábbi cikkekben talál további információt:
- Áttekintés: Mi az Azure Machine Tanulás?
- Rövid útmutatók és oktatóanyagok az Azure Machine Tanulás: Az Azure Machine Tanulás dokumentációja
Hozzáférés biztosítása egy Azure Machine-Tanulás-modellhez
Ha egy Azure Machine Tanulás-modellt szeretne elérni a Power BI-ból, a felhasználónak olvasási hozzáféréssel kell rendelkeznie az Azure-előfizetéshez. Emellett olvasási hozzáféréssel kell rendelkezniük a Gép Tanulás munkaterülethez is.
Az ebben a szakaszban ismertetett lépések azt ismertetik, hogyan biztosíthat power BI-felhasználók számára hozzáférést az Azure Machine Tanulás szolgáltatásban üzemeltetett modellhez. Ezzel a hozzáféréssel ezt a modellt Power Query-függvényként használhatják. További információkért lásd a hozzáférés az RBAC és az Azure Portal használatával történő kezelését ismertető cikket.
- Jelentkezzen be az Azure Portalra.
- Nyissa meg az Előfizetések lapot. Az Előfizetések lapot az Azure Portal bal oldali navigációs menüjében található Minden szolgáltatás listában találja.
- Válassza ki előfizetését.
- Válassza a Hozzáférés-vezérlés (IAM) lehetőséget, majd a Hozzáadás gombot.
- Válassza az Olvasó szerepkört. Válassza ki azt a Power BI-felhasználót, akinek hozzáférést szeretne adni az Azure Machine Tanulás modellhez.
- Válassza a Mentés lehetőséget.
- Ismételje meg a 3–6. lépést, hogy olvasói hozzáférést biztosítson a felhasználónak a modellt üzemeltető adott gépi Tanulás munkaterülethez.
Sémafelderítés gépi Tanulás-modellekhez
Az adattudósok elsősorban a Pythont használják a Gépi Tanulás gépi tanulási modelljeinek fejlesztésére és üzembe helyezésére. Az adatelemzőnek explicit módon létre kell hoznia a sémafájlt a Python használatával.
Ezt a sémafájlt szerepelnie kell a Machine Tanulás-modellek üzembe helyezett webszolgáltatásában. A webszolgáltatás sémájának automatikus létrehozásához meg kell adnia egy mintát az üzembe helyezett modell bemeneti/kimeneti szkriptjében. További információkért tekintse meg az Azure Machine Tanulás szolgáltatás dokumentációjában a modellek üzembe helyezése (opcionális) automatikus Swagger-sémagenerálás alszakaszát. A hivatkozás tartalmazza a példabejegyzési szkriptet a sémagenerálás utasításaival.
A beviteli szkript @input_schema és @output_schema függvényei a input_sample és output_sample változók bemeneti és kimeneti mintaformátumára hivatkoznak. A függvények ezeket a mintákat használják a webszolgáltatás OpenAPI (Swagger) specifikációjának létrehozására az üzembe helyezés során.
Ezeket a sémagenerálási utasításokat a belépési szkript frissítésével az Azure Machine Tanulás SDK-val automatizált gépi tanulási kísérletek használatával létrehozott modellekre is alkalmazni kell.
Feljegyzés
Az Azure Machine Tanulás vizualizációs felülettel létrehozott modellek jelenleg nem támogatják a sémagenerálást, de a későbbi kiadásokban is megjelennek.
Azure Machine Tanulás-modell meghívása a Power Queryben
Bármely Olyan Azure Machine-Tanulás modellt meghívhat, amelyhez hozzáférést kapott, közvetlenül a Power Query-szerkesztő. Az Azure Machine Tanulás-modellek eléréséhez válassza az Azure Machine Tanulás gombot a Kezdőlap vagy Az oszlop hozzáadása menüszalagon a Power Query-szerkesztő.

Az összes Azure Machine Tanulás modell, amelyhez hozzáféréssel rendelkezik, itt Power Query-függvényekként jelennek meg. Emellett az Azure Machine Tanulás modell bemeneti paraméterei automatikusan a megfelelő Power Query-függvény paramétereiként vannak leképezve.
Azure Machine-Tanulás-modell meghívásához a legördülő menüből bemenetként megadhatja a kiválasztott entitás bármelyik oszlopát. A bemenetként használandó állandó értéket úgy is megadhatja, hogy a beviteli párbeszédpanel bal oldalán lévő oszlopikont egyesítheti.
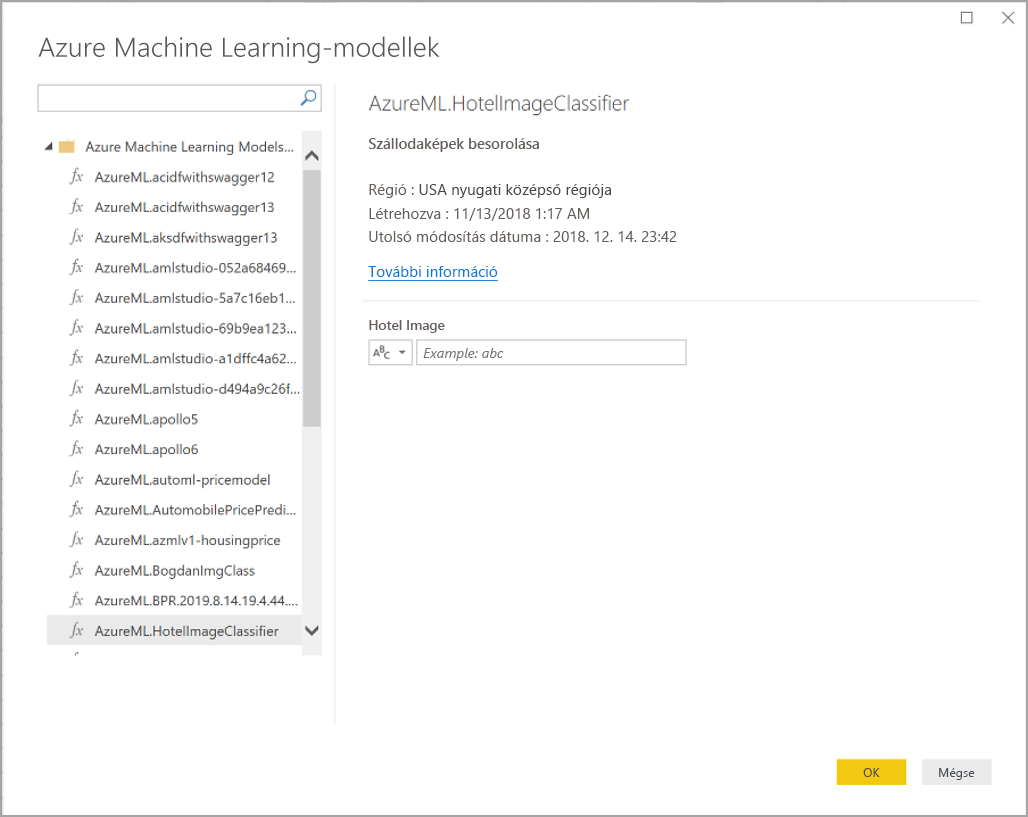
Az OK gombra kattintva megtekintheti az Azure Machine Tanulás modell kimenetének előnézetét új oszlopként az entitástáblában. A modell meghívása a lekérdezés alkalmazott lépéseként jelenik meg.
Ha a modell több kimeneti paramétert ad vissza, azok a kimeneti oszlopban rekordként vannak csoportosítva. Az oszlop kibontásával külön oszlopokban hozhat létre egyedi kimeneti paramétereket.
Az Azure Machine Tanulás szempontjai és korlátozásai
Az alábbi szempontok és korlátozások az Azure Machine Tanulás a Power BI Desktopban érvényesek.
- Az Azure Machine Tanulás vizualizációs felülettel létrehozott modellek jelenleg nem támogatják a sémagenerálást. A további kiadásokban várhatóan támogatottak lesznek.
- A növekményes frissítés támogatott, de teljesítményproblémákat okozhat az AI-elemzéseket használó lekérdezésekben.
- A Közvetlen lekérdezés nem támogatott.
- A felhasználónkénti Premium (PPU) licenccel rendelkező felhasználók nem használhatják a Power BI Desktopból származó AI-elemzések; nem PPU Premium licencet kell használnia a megfelelő Premium-kapacitással. A AI-elemzések továbbra is használhatja a Power BI szolgáltatás PPU-licenccel.
Kapcsolódó tartalom
Ez a cikk áttekintést nyújtott a Machine Tanulás Power BI Desktopba való integrálásáról. Az alábbi cikkek érdekesek és hasznosak is lehetnek.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: