Artikel ini menjelaskan pendekatan alternatif untuk proyek gudang data yang disebut analisis data eksplorasi (EDA). Pendekatan ini dapat mengurangi tantangan operasi ekstrak, transformasi, muatan (ETL). Ini berfokus pertama pada menghasilkan wawasan bisnis, lalu beralih ke pemecahan tugas pemodelan dan ETL.
Arsitektur

Unduh file Visio arsitektur ini.
Untuk EDA, Anda hanya memperhatikan sisi kanan diagram. Azure Synapse SQL serverless digunakan sebagai mesin komputasi pada file data lake.
Untuk mencapai EDA:
- Kueri T-SQL dijalankan langsung di Azure Synapse SQL serverless atau Azure Synapse Spark.
- Kueri dijalankan dari alat kueri grafis seperti Power BI atau Azure Data Studio.
Sebaiknya simpan semua data lakehouse menggunakan Parquet atau Delta.
Anda dapat menerapkan sisi kiri diagram (penyerapan data) dengan menggunakan alat ekstraksi, pemuatan, transformasi (ELT) apa pun. Hal ini tidak berpengaruh pada EDA.
Komponen
Azure Synapse Analytics menggabungkan integrasi data, pergudangan data perusahaan, dan analitik big data melalui data lakehouse. Dalam solusi ini:
- Ruang kerja Azure Synapse mempromosikan kolaborasi antara teknisi data, ilmuwan data, analis data, dan profesional kecerdasan bisnis (BI) untuk tugas EDA.
- Kumpulan Azure Synapse serverless SQL menganalisis data tidak terstruktur dan semi-terstruktur di Azure Data Lake Storage menggunakan T-SQL standar.
- Kumpulan Azure Synapse serverless Apache Spark melakukan eksplorasi kode pertama di Data Lake Storage menggunakan bahasa Spark seperti Spark SQL, PySpark, dan Scala.
Azure Data Lake Storage menyediakan penyimpanan untuk data yang kemudian dianalisis oleh kumpulan SQL tanpa server Azure Synapse.
Azure Machine Learning menyediakan data ke Azure Synapse Spark.
Power BI digunakan dalam solusi ini untuk meminta data guna menyelesaikan EDA.
Alternatif
Anda dapat mengganti atau melengkapi kumpulan Synapse SQL serverless dengan Azure Databricks.
Daripada menggunakan model lakehouse dengan kumpulan Synapse SQL serverless, Anda dapat menggunakan kumpulan SQL khusus Azure Synapse untuk menyimpan data perusahaan. Tinjau kasus penggunaan dan pertimbangan dalam artikel ini dan sumber daya terkait untuk memutuskan teknologi mana yang akan digunakan.
Detail skenario
Solusi ini menunjukkan implementasi pendekatan EDA untuk proyek gudang data. Pendekatan ini dapat mengurangi tantangan operasi ETL. Ini berfokus terlebih dahulu pada menghasilkan wawasan bisnis dan kemudian beralih untuk memecahkan pemodelan dan tugas ETL.
Kemungkinan kasus penggunaan
Skenario lain yang dapat memanfaatkan pola analitik ini:
Analisis preskriptif. Ajukan pertanyaan tentang data Anda, seperti Tindakan Terbaik Berikutnya, atau apa tindakan selanjutnya? Gunakan data agar lebih berdasarkan data dan lebih sedikit berdasarkan firasat. Data mungkin tidak terstruktur dan dari banyak sumber eksternal dengan kualitas yang bervariasi. Anda mungkin ingin menggunakan data secepat mungkin untuk mengevaluasi strategi bisnis Anda tanpa benar-benar memuat data ke dalam gudang data. Anda mungkin membuang data setelah Anda menjawab pertanyaan Anda.
ETL layanan mandiri. Lakukan ETL/ELT saat melakukan aktivitas kotak pasir data (EDA). Transformasikan data agar menjadi berharga. Melakukan tindakan ini dapat meningkatkan skala pengembang ETL Anda.
Tentang analisis data eksplorasi
Sebelum melihat lebih dekat cara kerja EDA, sebaiknya ringkas pendekatan tradisional untuk proyek gudang data. Pendekatan tradisional terlihat seperti ini:
Persyaratan pengumpulan. Dokumentasikan apa yang harus dilakukan dengan data.
Pemodelan data. Tentukan cara memodelkan data numerik dan atribut ke dalam tabel fakta dan dimensi. Biasanya, Anda melakukan langkah ini sebelum memperoleh data baru.
ETL. Dapatkan data dan masukkan ke dalam model gudang data.
Langkah-langkah ini bisa memakan waktu berminggu-minggu atau bahkan berbulan-bulan. Hanya dengan begitu Anda dapat mulai menanyakan data dan memecahkan masalah bisnis. Pengguna melihat nilai hanya setelah laporan dibuat. Arsitektur solusi biasanya terlihat seperti ini:
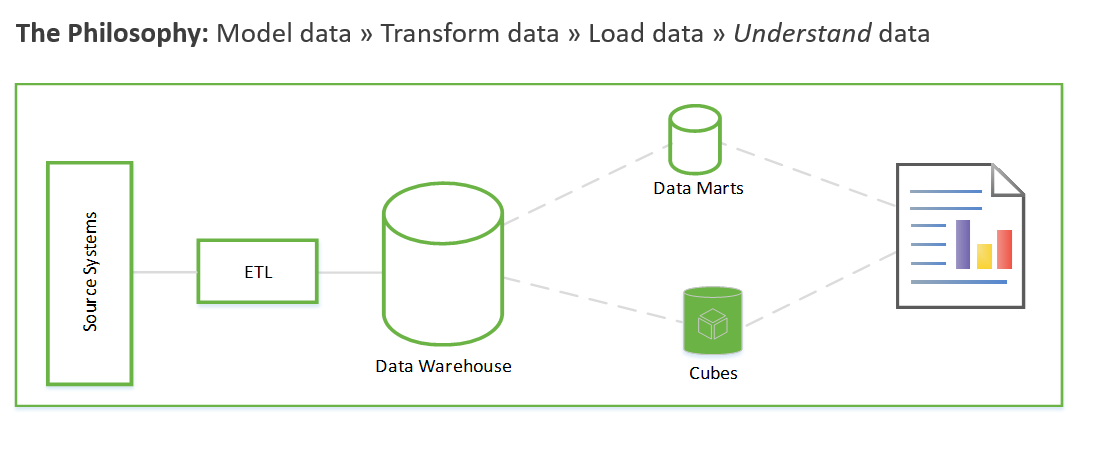
Anda dapat melakukan tindakan ini dengan cara lain yang berfokus pertama pada menghasilkan wawasan bisnis dan kemudian beralih ke penyelesaian tugas pemodelan dan ETL. Prosesnya mirip dengan proses ilmu data. Hal ini terlihat seperti ini:
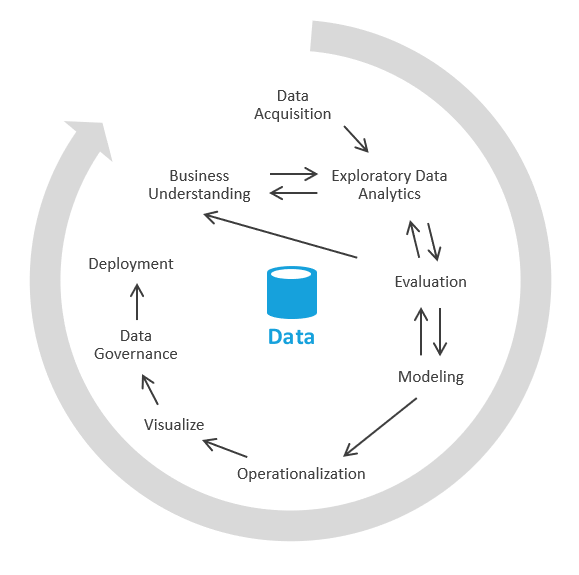
Dalam industri, proses ini disebut EDA, atau analisis data eksplorasi.
Berikut langkah-langkahnya:
Akuisisi data. Pertama, Anda perlu menentukan sumber data apa yang perlu Anda serap ke dalam data lake/kotak pasir Anda. Anda kemudian perlu membawa data tersebut ke area arahan danau Anda. Azure menyediakan alat seperti Azure Data Factory dan Azure Logic Apps yang dapat menyerap data dengan cepat.
Kotak pasir data. Awalnya, seorang analis bisnis dan seorang insinyur yang ahli dalam analisis data eksplorasi melalui Azure Synapse Analytics serverless atau SQL dasar bekerja sama. Selama fase ini, mereka mencoba mengungkap wawasan bisnis menggunakan data baru. EDA adalah proses berulang. Anda mungkin perlu menyerap lebih banyak data, berbicara dengan UKM, mengajukan lebih banyak pertanyaan, atau menghasilkan visualisasi.
Evaluasi. Setelah Anda menemukan wawasan bisnis, Anda perlu mengevaluasi apa yang harus dilakukan dengan data tersebut. Anda mungkin ingin menyimpan data ke dalam gudang data (jadi Anda pindah ke fase pemodelan). Dalam kasus lain, Anda mungkin memutuskan untuk menyimpan data di data lake/lakehouse dan menggunakannya untuk analitik prediktif (algoritma pembelajaran mesin). Dalam kasus lain, Anda mungkin memutuskan untuk mengisi ulang sistem pencatatan Anda dengan wawasan baru. Berdasarkan keputusan ini, Anda dapat memperoleh pemahaman yang lebih baik tentang apa yang perlu Anda lakukan selanjutnya. Anda mungkin tidak perlu melakukan ETL.
Metode ini adalah inti dari analisis layanan mandiri yang sebenarnya. Dengan menggunakan data lake dan alat kueri seperti Azure Synapse serverless yang memahami pola kueri data lake, Anda dapat menyerahkan aset data Anda ke tangan pebisnis yang memahami sedikit SQL. Anda dapat secara radikal mempersingkat waktu-ke-nilai menggunakan metode ini dan menghilangkan beberapa risiko yang terkait dengan inisiatif data perusahaan.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Ketersediaan
Kumpulan Azure Synapse SQL serverless adalah fitur platform as a service (PaaS) yang dapat memenuhi persyaratan ketersediaan tinggi (HA) dan pemulihan bencana (DR).
Kumpulan serverless tersedia sesuai permintaan. Kumpulan ini tidak memerlukan peningkatan, penurunan, perluasan, atau penciutan skala atau administrasi apa pun. Mereka menggunakan model bayar per kueri, jadi tidak ada kapasitas yang tidak digunakan setiap saat. Kumpulan serverless ideal untuk:
- Eksplorasi ilmu data ad-hoc di T-SQL.
- Pembuatan prototipe awal untuk entitas gudang data.
- Menentukan tampilan yang dapat digunakan konsumen, misalnya di Power BI, untuk skenario yang dapat menoleransi kelambatan performa.
- Analisis data eksplorasi.
Operasional
Synapse SQL serverless menggunakan T-SQL standar untuk kueri dan operasi. Anda dapat menggunakan UI ruang kerja Synapse, Azure Data Studio, atau SQL Server Management Studio sebagai alat T-SQL.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Harga Data Lake Store bergantung pada jumlah data yang Anda simpan dan seberapa sering Anda menggunakan data tersebut. Harga sampel mencakup satu TB data yang disimpan, dengan asumsi transaksional selengkapnya. Satu TB mengacu pada ukuran data lake, bukan ukuran database warisan asli.
Kumpulan Azure Synapse Spark menetapkan harga berdasarkan ukuran node, jumlah instans, dan waktu aktif. Contohnya mengasumsikan satu node komputasi kecil dengan pemanfaatan antara lima jam per minggu dan 40 jam per bulan.
Kumpulan SQL serverless Azure Synapse menetapkan harga berdasarkan TB data yang diproses. Sampel mengasumsikan 50 TB diproses per bulan. Angka ini mengacu pada ukuran data lake, bukan ukuran database warisan asli.
Kontributor
Artikel ini sedang diperbarui dan dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Dave Wentzel | Arsitek Teknis MTC Utama
Langkah berikutnya
- Jalur pembelajaran Insinyur Data
- Tutorial: Mulai menggunakan Azure Synapse Analytics
- Membuat database tunggal - Azure SQL Database
- Arsitektur Azure Synapse SQL
- Membuat akun penyimpanan untuk Azure Data Lake Storage
- Mulai Cepat Azure Event Hubs - Membuat event hub menggunakan portal Microsoft Azure
- Mulai Cepat - Membuat pekerjaan Azure Stream Analytics dengan menggunakan portal Azure
- Mulai cepat: Mulai menggunakan Azure Pembelajaran Mesin