Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tip
Data Factory di Microsoft Fabric adalah generasi Azure Data Factory berikutnya, dengan arsitektur yang lebih sederhana, AI bawaan, dan fitur baru. Jika Anda baru menggunakan integrasi data, mulailah dengan Fabric Data Factory. Beban kerja ADF yang ada dapat ditingkatkan ke Fabric untuk mengakses kemampuan baru di seluruh ilmu data, analitik real time, dan pelaporan.
Aktivitas Spark dalam Data Factory dan alur Synapse menjalankan program Spark pada kluster HDInsight milik Anda sendiri atau sesuai permintaan. Artikel ini membangun artikel aktivitas transformasi data, yang menyajikan gambaran umum tentang transformasi data dan aktivitas transformasi yang didukung. Ketika Anda menggunakan layanan terkait Spark sesuai permintaan, layanan secara otomatis membuat kluster Spark untuk Anda tepat waktu untuk memproses data lalu menghapus kluster setelah pemrosesan selesai.
Menambahkan aktivitas Spark ke alur dengan UI
Untuk menambahkan aktivitas Spark ke dalam alur, lakukan langkah-langkah berikut:
Cari Spark di panel Aktivitas alur, dan seret aktivitas Spark ke kanvas alur.
Pilih aktivitas Spark baru di kanvas jika belum dipilih.
Pilih tab Kluster HDI untuk memilih atau membuat layanan tertaut baru ke kluster HDInsight yang akan digunakan untuk menjalankan aktivitas Spark.
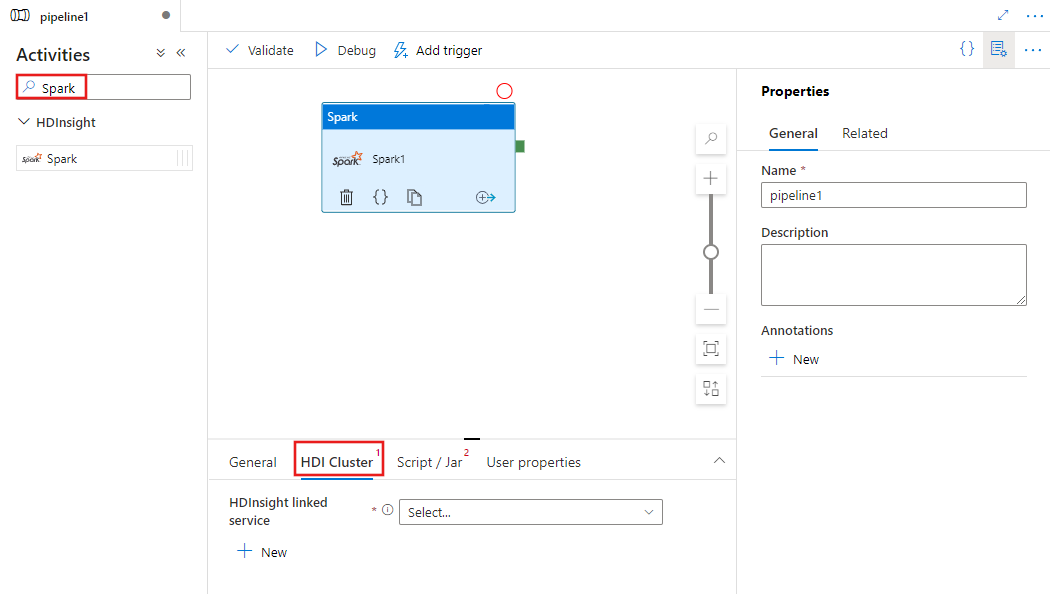
Pilih tab Script / Jar untuk memilih atau membuat layanan terkait pekerjaan baru yang ditautkan ke akun Azure Storage untuk meng-host skrip Anda. Tentukan jalur ke file yang akan dieksekusi di sana. Anda juga dapat mengonfigurasi detail tingkat lanjut termasuk pengguna proksi, konfigurasi debug, dan argumen serta parameter konfigurasi Spark yang akan diteruskan ke skrip.
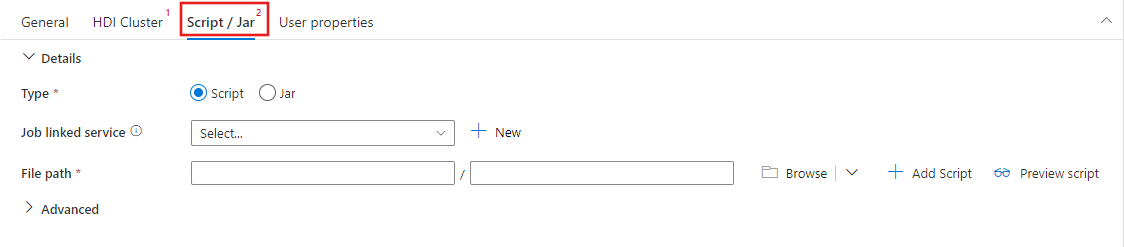
Properti aktivitas Spark
Berikut adalah sampel definisi JSON dengan Aktivitas Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
Tabel berikut menjelaskan properti JSON yang digunakan dalam definisi JSON:
| Properti | Deskripsi | Wajib |
|---|---|---|
| nama | Nama aktivitas di dalam pipa kerja. | Ya |
| deskripsi | Teks yang menjelaskan apa yang aktivitas dilakukan. | Tidak |
| jenis | Untuk Spark Activity, jenis aktivitasnya adalah HDInsightSpark. | Ya |
| Nama Layanan Tertaut | Nama Layanan Tertaut HDInsight Spark tempat program Spark berjalan. Untuk mempelajari layanan tertaut ini, lihat artikel Layanan tertaut komputasi. | Ya |
| SparkJobLinkedService | Layanan tertaut Azure Storage yang menyimpan file pekerjaan, dependensi, dan log Spark. Hanya Azure Blob Storage dan ADLS Gen2 yang didukung di sini. Jika Anda tidak menentukan nilai untuk properti ini, penyimpanan yang terkait dengan kluster HDInsight digunakan. Nilai properti ini hanya dapat berupa layanan terkait Azure Storage. | Tidak |
| rootPath | Kontainer dan folder blob Azure yang berisi file Spark. Nama file peka pada huruf besar-kecil. Lihat bagian struktur folder (bagian berikutnya) untuk detail tentang struktur folder ini. | Ya |
| entryFilePath | Jalur relatif ke folder akar dari kode/paket Spark. File entri harus berupa file Python atau file .jar. | Ya |
| namaKelas | Kelas utama aplikasi Java/Spark | Tidak |
| argumen | Daftar argumen baris perintah ke program Spark. | Tidak |
| proxyUser | Akun pengguna untuk menyamar untuk menjalankan program Spark | Tidak |
| sparkConfig | Tentukan nilai untuk properti konfigurasi Spark yang tercantum dalam topik: Konfigurasi Spark - Properti aplikasi. | Tidak |
| getDebugInfo | Menentukan kapan file log Spark disalin ke penyimpanan Azure yang digunakan oleh kluster HDInsight (atau) yang ditentukan oleh sparkJobLinkedService. Nilai yang diizinkan: Tidak ada, Selalu, atau Gagal. Nilai default: None. | Tidak |
Struktur folder
Pekerjaan Spark lebih dapat dikembangkan daripada pekerjaan Pig/Apache Hive. Untuk pekerjaan Spark, Anda dapat menyediakan beberapa dependensi seperti paket jar (ditempatkan di Java CLASSPATH), file Python (ditempatkan pada PYTHONPATH), dan file lainnya.
Buat struktur folder berikut di penyimpanan blob Azure yang direferensikan oleh layanan tertaut HDInsight. Kemudian, unggah file dependen ke subfolder yang sesuai di folder akar yang diwakili oleh entryFilePath. Misalnya, unggah file Python ke subfolder pyFiles dan file jar ke subfolder jar folder akar. Pada runtime, layanan mengharapkan struktur folder berikut di penyimpanan blob Azure:
| Jalur | Deskripsi | Wajib | Tipe |
|---|---|---|---|
. (akar) |
Jalur utama pekerjaan Spark dalam layanan penyimpanan yang terkait | Ya | Folder |
| <pengguna didefinisikan > | Jalur yang menunjuk ke file entri pekerjaan Spark | Ya | File |
| ./jars | Semua file di bawah folder ini diunggah dan ditempatkan pada classpath Java kluster | Tidak | Folder |
| ./pyFiles | Semua file di bawah folder ini diunggah dan ditempatkan pada PYTHONPATH kluster | Tidak | Folder |
| ./file | Semua file di bawah folder ini diunggah dan ditempatkan pada direktori kerja pelaksana | Tidak | Folder |
| ./arsip | Semua file di bawah folder ini tidak dipadatkan | Tidak | Folder |
| ./logs | Folder yang berisi log dari kluster Spark. | Tidak | Folder |
Berikut adalah contoh penyimpanan yang berisi dua berkas pekerjaan Spark di Azure Blob Storage yang dirujuk oleh layanan tertaut HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Konten terkait
Lihat artikel berikut yang menjelaskan cara mentransformasikan data dengan cara lain: