Menggunakan Azure Data Factory untuk memigrasikan data dari Amazon S3 ke Azure Storage
BERLAKU UNTUK:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Azure Data Factory menyediakan mekanisme yang berperforma tinggi, andal, dan hemat biaya untuk memigrasikan data dalam skala besar dari Amazon S3 ke Azure Blob Storage atau Azure Data Lake Storage Gen2. Artikel ini menyediakan informasi berikut ini untuk teknisi dan pengembang data:
- Performa
- Ketahanan salinan
- Keamanan jaringan
- Arsitektur solusi tingkat tinggi
- Praktik terbaik penerapan
Performa
ADF menawarkan arsitektur tanpa server yang memungkinkan paralelisme pada tingkat yang berbeda, yang memungkinkan pengembang untuk membangun alur untuk sepenuhnya menggunakan bandwidth jaringan dan IOPS penyimpanan dan bandwidth Anda untuk memaksimalkan throughput pergerakan data untuk lingkungan Anda.
Pelanggan telah berhasil memigrasikan petabyte data yang terdiri dari ratusan juta file dari Amazon S3 ke Azure Blob Storage, dengan throughput berkelanjutan 2 GBps dan yang lebih tinggi.
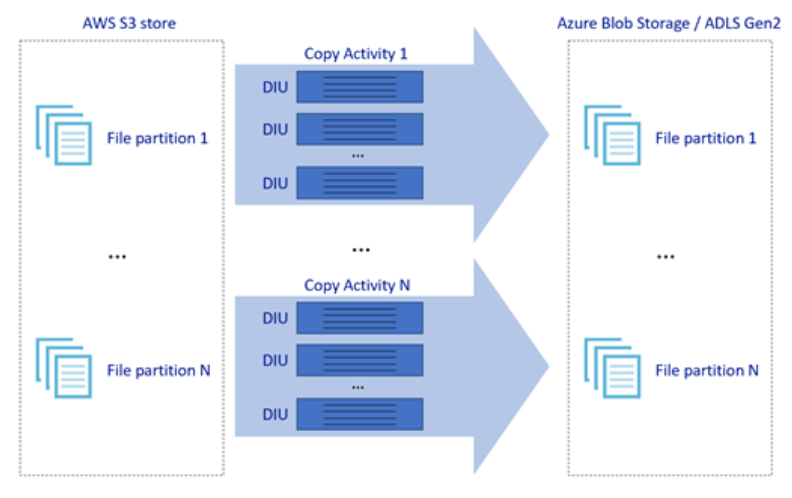
Gambar di atas menggambarkan bagaimana Anda dapat mencapai kecepatan pergerakan data yang hebat melalui berbagai tingkat paralelisme:
- Satu aktivitas penyalinan dapat memanfaatkan sumber daya komputasi yang dapat diskalakan: saat menggunakan Azure Integration Runtime, Anda dapat menentukan hingga 256 DIUs untuk setiap aktivitas penyalinan dengan cara tanpa server; saat menggunakan Integration Runtime yang dihost sendiri, Anda dapat meningkatkan mesin secara manual atau meluaskan skala ke beberapa komputer (hingga empat simpul), dan satu aktivitas salin akan mempartisi set filenya di semua simpul.
- Satu aktivitas penyalinan membaca dari dan menulis ke penyimpanan data dengan menggunakan beberapa rangkaian.
- Alur kontrol ADF dapat memulai beberapa aktivitas penyalinan secara paralel, misalnya menggunakan Untuk Setiap perulangan.
Ketahanan
Dalam satu aktivitas penyalinan yang dijalankan, ADF memiliki mekanisme coba lagi bawaan, yang memungkinkannya untuk menangani tingkat kegagalan sementara tertentu di penyimpanan data atau di jaringan yang mendasarinya.
Saat melakukan penyalinan biner dari S3 ke Blob dan dari S3 ke ADLS Gen2, ADF akan secara otomatis melakukan checkpointing. Jika aktivitas penyalinan gagal atau kehabisan waktu, pada coba lagi berikutnya, penyalinan akan dilanjutkan dari titik kegagalan terakhir, bukan dimulai dari awal.
Keamanan jaringan
Secara default, ADF mentransfer data dari Amazon S3 ke Azure Blob Storage atau Azure Data Lake Storage Gen2 menggunakan koneksi terenkripsi melalui protokol HTTPS. HTTPS menyediakan enkripsi data dalam transit dan mencegah pengupingan/eavesdropping dan serangan man-in-the-middle.
Atau, jika Anda tidak ingin data ditransfer melalui Internet publik, Anda dapat mencapai keamanan yang lebih tinggi dengan mentransfer data melalui tautan peering privat antara AWS Direct Connect dan Azure Express Route. Lihat arsitektur solusi di bagian berikutnya tentang bagaimana hal ini dapat dicapai.
Solusi Arsitektur
Migrasi data melalui Internet publik:
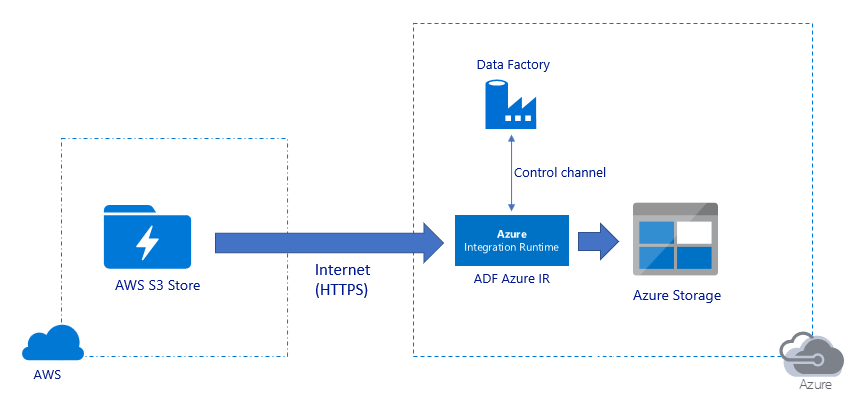
- Dalam arsitektur ini, data ditransfer dengan aman menggunakan HTTPS melalui internet publik.
- Sumber Amazon S3 dan Azure Blob Storage tujuan atau Azure Data Lake Storage Gen2 dikonfigurasi untuk memungkinkan lalu lintas dari semua alamat IP jaringan. Lihat arsitektur kedua yang dirujuk nanti di halaman ini tentang bagaimana Anda dapat membatasi akses jaringan ke rentang IP tertentu.
- Anda dapat dengan mudah meningkatkan jumlah tenaga kuda dengan cara tanpa server untuk sepenuhnya memanfaatkan jaringan dan bandwidth penyimpanan Anda sehingga Anda bisa mendapatkan throughput terbaik untuk lingkungan Anda.
- Baik migrasi snapshot awal maupun migrasi data delta dapat dicapai dengan menggunakan arsitektur ini.
Migrasikan data melalui tautan pribadi:
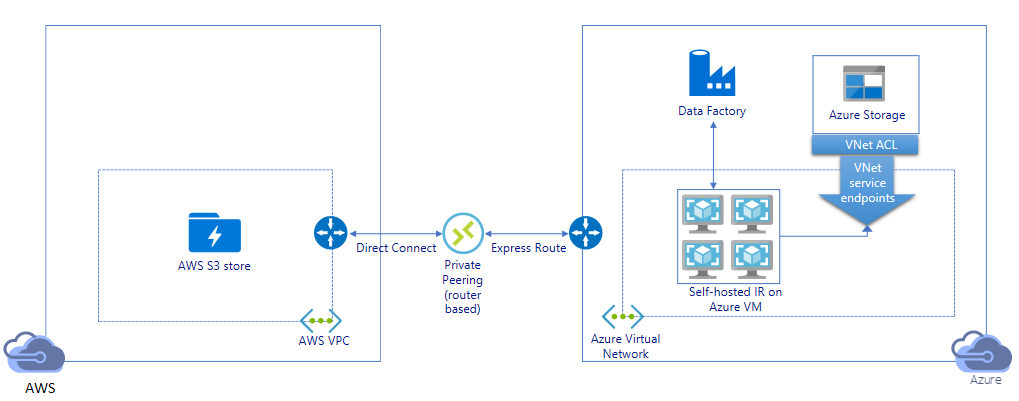
- Dalam arsitektur ini, migrasi data dilakukan melalui tautan peering privat antara AWS Direct Connect dan Azure Express Route sehingga data tidak pernah melintasi Internet publik. Hal ini membutuhkan penggunaan AWS VPC dan jaringan Virtual Azure.
- Anda perlu menginstal runtime integrasi yang dihost sendiri ADF pada VM Windows dalam jaringan virtual Azure Anda untuk mencapai arsitektur ini. Anda dapat meningkatkan VM IR yang dihost sendiri secara manual atau meluaskan skala ke beberapa VM (hingga empat simpul) untuk sepenuhnya menggunakan jaringan dan penyimpanan IOPS/bandwidth Anda.
- Baik migrasi snapshot awal maupun migrasi data delta dapat dicapai dengan menggunakan arsitektur ini.
Praktik terbaik penerapan
Manajemen autentikasi dan kredensial
- Untuk mengautentikasi ke akun Amazon S3, Anda harus menggunakan kunci akses untuk akun IAM.
- Beberapa jenis autentikasi didukung untuk menyambungkan ke Azure Blob Storage. Penggunaan identitas terkelola untuk sumber daya Azure sangat disarankan: dibangun di atas identifikasi ADF yang dikelola secara otomatis di ID Microsoft Entra, memungkinkan Anda untuk mengonfigurasi alur tanpa memberikan kredensial dalam definisi Layanan Tertaut. Atau, Anda dapat mengautentikasi ke Azure Blob Storage dengan menggunakan Perwakilan Layanan, tanda tangan akses bersama, atau kunci akun penyimpanan.
- Beberapa jenis autentikasi juga didukung untuk menyambungkan ke Azure Data Lake Storage Gen2. Penggunaan identitas terkelola untuk sumber daya Azure sangat disarankan, meskipun perwakilan layanan atau kunci akun penyimpanan juga dapat digunakan.
- Saat Anda tidak menggunakan identitas terkelola untuk sumber daya Azure, menyimpan kredensial di Azure Key Vault sangat disarankan untuk mempermudah mengelola dan memutar kunci secara terpusat tanpa memodifikasi layanan tertaut ADF. Ini juga merupakan salah satu praktik terbaik untuk CI/CD.
Migrasi data snapshot awal
Partisi data direkomendasikan terutama ketika memigrasikan lebih dari 100 TB data. Untuk mempartisi data, gunakan pengaturan 'awalan' untuk memfilter folder dan file di Amazon S3 berdasarkan nama, lalu setiap pekerjaan penyalinan ADF dapat menyalin satu partisi sekaligus. Anda dapat menjalankan beberapa pekerjaan penyalinan ADF secara bersamaan untuk throughput yang lebih baik.
Jika salah satu pekerjaan penyalinan gagal karena masalah jaringan atau penyimpanan data sementara, Anda dapat menjalankan kembali pekerjaan penyalinan yang gagal untuk memuat ulang partisi tertentu itu lagi dari AWS S3. Semua pekerjaan penyalinan lain yang memuat partisi lain tidak akan terpengaruh.
Migrasi data delta
Cara paling berkinerja untuk mengidentifikasi file baru atau yang diubah dari AWS S3 adalah dengan menggunakan konvensi penamaan yang dipartisi waktu - ketika data Anda di AWS S3 telah dipartisi waktu dengan informasi ikatan waktu dalam nama file atau folder (misalnya, /yyyy/mm/dd/file.csv), maka alur Anda dapat dengan mudah mengidentifikasi file/folder mana yang akan disalin secara bertahap.
Atau, Jika data Anda di AWS S3 tidak dipartisi waktu, ADF dapat mengidentifikasi file baru atau yang diubah oleh LastModifiedDate mereka. Cara kerjanya adalah ADF akan memindai semua file dari AWS S3, dan hanya menyalin file baru dan yang diperbarui yang stempel waktu terakhirnya diubah lebih besar dari nilai tertentu. Jika Anda memiliki sejumlah besar file di S3, pemindaian file awal dapat memakan waktu lama terlepas dari berapa banyak file yang cocok dengan kondisi filter. Dalam hal ini Anda disarankan untuk mempartisi data terlebih dahulu, menggunakan pengaturan 'awalan' yang sama untuk migrasi rekam jepret awal, sehingga pemindaian file dapat terjadi secara paralel.
Untuk skenario yang memerlukan runtime Integrasi yang dihost sendiri di VM Azure
Baik Anda memigrasikan data melalui tautan privat atau ingin mengizinkan rentang IP tertentu pada firewall Amazon S3, Anda perlu menginstal runtime Integrasi yang dihost sendiri di Azure Windows VM.
- Konfigurasi yang direkomendasikan untuk memulai setiap VM Azure adalah Standard_D32s_v3 dengan 32 vCPU dan memori 128 GB. Anda dapat terus memantau CPU dan pemanfaatan memori VM IR selama migrasi data untuk melihat apakah Anda perlu meningkatkan VM lebih lanjut untuk kinerja yang lebih baik atau menurunkan skala VM untuk menghemat biaya.
- Anda juga dapat meluaskan skala dengan mengaitkan hingga empat simpul VM dengan satu IR yang dihost sendiri. Satu pekerjaan penyalinan yang berjalan terhadap runtime integrasi yang dihost sendiri akan secara otomatis mempartisi kumpulan file dan menggunakan semua simpul VM untuk menyalin file secara paralel. Untuk ketersediaan tinggi, Anda disarankan untuk memulai dengan dua simpul VM untuk menghindari satu titik kegagalan selama migrasi data.
Pembatasan tarif
Sebagai praktik terbaik, lakukan POC performa dengan himpunan data sampel yang representatif, sehingga Anda dapat menentukan ukuran partisi yang sesuai.
Mulailah dengan partisi tunggal dan aktivitas penyalinan tunggal dengan pengaturan DIU default. Tingkatkan pengaturan DIU secara bertahap hingga Anda mencapai batas bandwidth jaringan atau batas IOPS/bandwidth penyimpanan data, atau Anda telah mencapai maksimum 256 DIU yang diizinkan pada satu aktivitas penyalinan.
Selanjutnya, secara bertahap tingkatkan jumlah aktivitas penyalinan bersamaan hingga Anda mencapai batas lingkungan Anda.
Saat Anda mengalami kesalahan pelambatan yang dilaporkan oleh aktivitas penyalinan ADF, kurangi pengaturan bersamaan atau DIU di ADF, atau pertimbangkan untuk meningkatkan batas bandwidth/IOPS jaringan dan penyimpanan data.
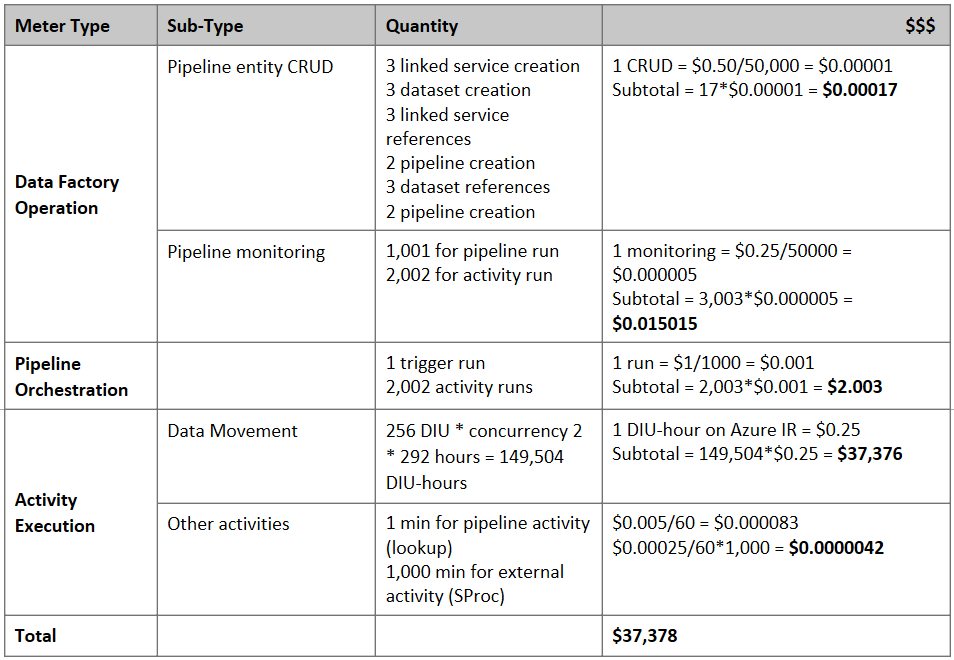
Memperkirakan Harga
Catatan
Ini adalah contoh harga hipotetis. Harga aktual Anda bergantung pada throughput aktual di lingkungan Anda.
Pertimbangkan pipeline berikut yang dibuat untuk memigrasikan data dari S3 ke Azure Blob Storage :
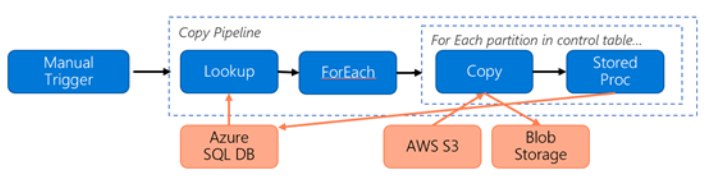
Mari kita asumsikan sebagai berikut:
- Total volume data adalah 2 PB
- Memigrasikan data melalui HTTPS menggunakan arsitektur solusi pertama
- 2 PB dibagi menjadi partisi 1 KB dan setiap salinan memindahkan satu partisi
- Setiap penyalinan dikonfigurasi dengan DIU=256 dan mencapai throughput 1 GBps
- Konkurensi ForEach diatur ke 2 dan throughput agregatnya adalah 2 GBps
- Totalnya, dibutuhkan 292 jam untuk menyelesaikan migrasi
Berikut adalah perkiraan harga berdasarkan asumsi di atas:
Referensi tambahan
- Konektor Layanan Penyimpanan Sederhana Amazon
- Konektor Azure Blob Storage
- Konektor Azure Data Lake Storage Gen2
- Panduan penyetelan performa aktivitas penyalinan
- Membuat dan mengonfigurasi Runtime Integrasi yang dihost sendiri
- Ketersediaan Tinggi dan skalabilitas runtime integrasi yang dihost sendiri
- Pertimbangan keamanan pergerakan data
- Simpan info masuk di Azure Key Vault
- Menyalin file secara bertahap berdasarkan nama file yang dipartisi waktu
- Menyalin file baru dan file yang diubah berdasarkan LastModifiedDate
- Halaman harga ADF
Templat
Berikut adalah templat untuk memulai dengan memigrasikan petabyte data yang terdiri dari ratusan juta file dari Amazon S3 ke Azure Data Lake Storage Gen2.
Konten terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk