Mengunduh arsitektur referensi lakehouse
Artikel ini membahas panduan arsitektur untuk lakehouse dalam hal sumber data, penyerapan, transformasi, kueri dan pemrosesan, penyajian, analisis/output, dan penyimpanan.
Setiap arsitektur referensi memiliki PDF yang dapat diunduh dalam format 11 x 17 (A3).
Arsitektur referensi generik
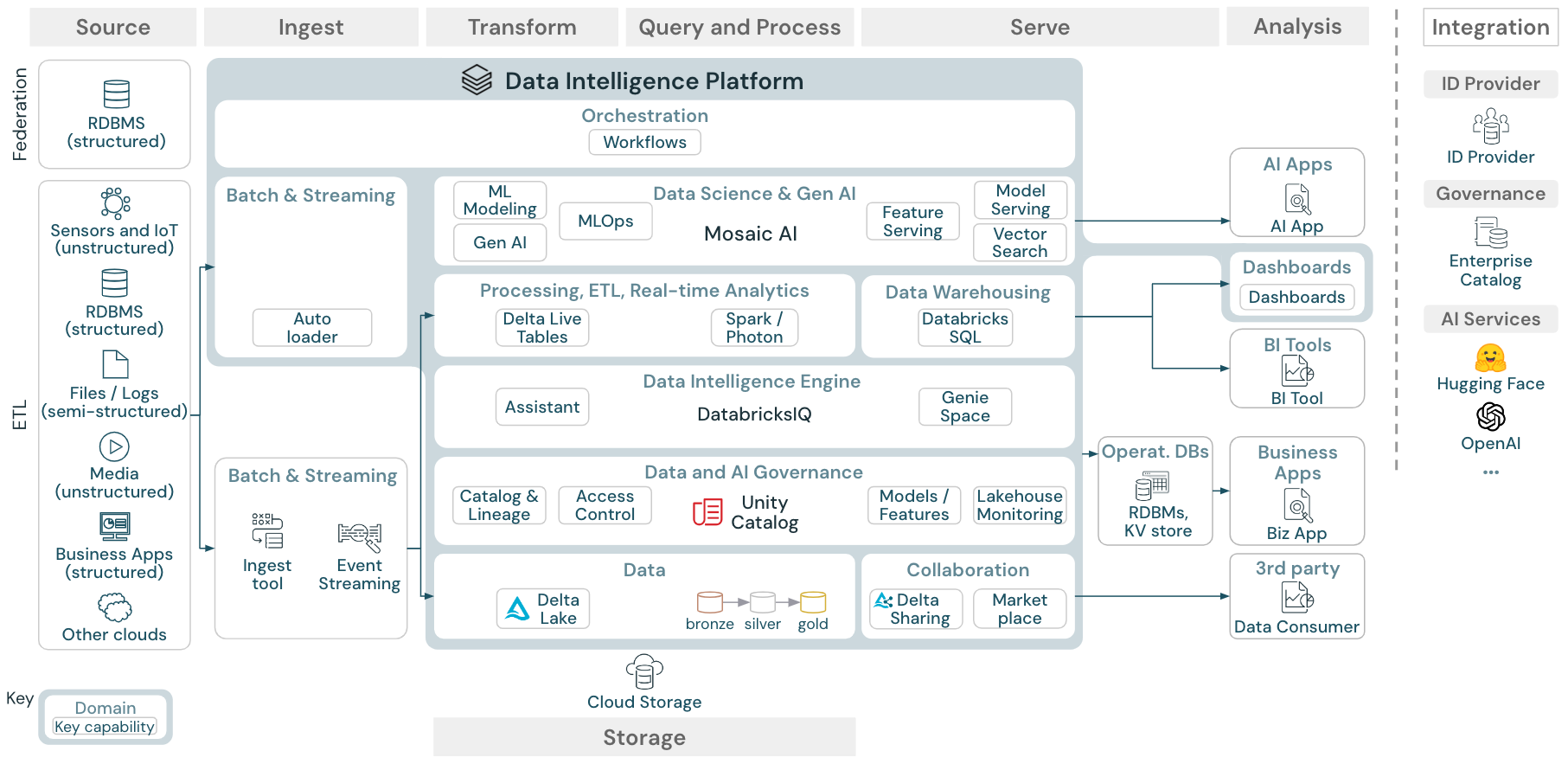
Unduh: Arsitektur referensi lakehouse generik untuk Databricks (PDF)
Organisasi arsitektur referensi
Arsitektur referensi disusun di sepanjang jalur renang Sumber, Penyerapan, Transformasi, Kueri dan Proses, Sajikan, Analisis, dan Penyimpanan:
Sumber
Arsitektur ini membedakan antara data semi terstruktur dan tidak terstruktur (sensor dan IoT, media, file/log), dan data terstruktur (RDBMS, aplikasi bisnis). Sumber SQL (RDBMS) juga dapat diintegrasikan ke dalam lakehouse dan Unity Catalog tanpa ETL melalui federasi lakehouse. Selain itu, data mungkin dimuat dari penyedia cloud lainnya.
Menyerap
Data dapat diserap ke lakehouse melalui batch atau streaming:
- File yang dikirimkan ke penyimpanan cloud dapat dimuat langsung menggunakan Databricks Auto Loader.
- Untuk penyerapan data batch dari aplikasi perusahaan ke Delta Lake, databricks lakehouse bergantung pada alat penyerapan mitra dengan adaptor tertentu untuk sistem rekaman ini.
- Peristiwa streaming dapat diserap langsung dari sistem streaming peristiwa seperti Kafka menggunakan Streaming Terstruktur Databricks. Sumber streaming dapat berupa sensor, IoT, atau mengubah proses pengambilan data.
Penyimpanan
Data biasanya disimpan dalam sistem penyimpanan cloud di mana alur ETL menggunakan arsitektur medali untuk menyimpan data dengan cara yang dikumpulkan sebagai file/tabel Delta.
Transformasi dan Kueri dan proses
Lakehouse Databricks menggunakan mesinnya Apache Spark dan Photon untuk semua transformasi dan kueri.
Karena kesederhanaannya, kerangka kerja deklaratif DLT (Delta Live Tables) adalah pilihan yang baik untuk membangun alur pemrosesan data yang andal, dapat dipertahankan, dan dapat diuji.
Didukung oleh Apache Spark dan Photon, Platform Databricks Data Intelligence mendukung kedua jenis beban kerja: kueri SQL melalui gudang SQL, dan beban kerja SQL, Python, dan Scala melalui kluster ruang kerja.
Untuk ilmu data (ML Modeling dan Gen AI), platform Databricks AI dan Pembelajaran Mesin menyediakan runtime ML khusus untuk AutoML dan untuk pekerjaan ML pengkodian. Semua alur kerja ilmu data dan MLOps paling baik didukung oleh MLflow.
Layani
Untuk kasus penggunaan DWH dan BI, databricks lakehouse menyediakan Databricks SQL, gudang data yang didukung oleh gudang SQL, dan gudang SQL tanpa server.
Untuk pembelajaran mesin, penyajian model adalah model tingkat perusahaan yang dapat diskalakan, real time, dan melayani kemampuan yang dihosting di sarana kontrol Databricks.
Database operasional: Sistem eksternal, seperti database operasional, dapat digunakan untuk menyimpan dan mengirimkan produk data akhir ke aplikasi pengguna.
Kolaborasi: Mitra bisnis mendapatkan akses aman ke data yang mereka butuhkan melalui Berbagi Delta. Berdasarkan Berbagi Delta, Databricks Marketplace adalah forum terbuka untuk bertukar produk data.
Analisis
Aplikasi bisnis akhir berada di jalur renang ini. Contohnya termasuk klien kustom seperti aplikasi AI yang terhubung ke Mosaic AI Model Serving untuk inferensi real time atau aplikasi yang mengakses data yang didorong dari lakehouse ke database operasional.
Untuk kasus penggunaan BI, analis biasanya menggunakan alat BI untuk mengakses gudang data. Pengembang SQL juga dapat menggunakan Editor SQL Databricks (tidak ditampilkan dalam diagram) untuk kueri dan dasbor.
Platform Kecerdasan Data juga menawarkan dasbor untuk membangun visualisasi data dan berbagi wawasan.
Kemampuan untuk beban kerja Anda
Selain itu, Databricks lakehouse dilengkapi dengan kemampuan manajemen yang mendukung semua beban kerja:
Tata kelola data dan AI
Data pusat dan sistem tata kelola AI di Platform Kecerdasan Databricks adalah Unity Catalog. Unity Catalog menyediakan satu tempat untuk mengelola kebijakan akses data yang berlaku di semua ruang kerja dan mendukung semua aset yang dibuat atau digunakan di lakehouse, seperti tabel, volume, fitur (penyimpanan fitur), dan model (registri model). Katalog Unity juga dapat digunakan untuk mengambil silsilah data runtime di seluruh kueri yang berjalan di Databricks.
Pemantauan databricks lakehouse memungkinkan Anda memantau kualitas data di semua tabel di akun Anda. Ini juga dapat melacak performa model pembelajaran mesin dan titik akhir penyajian model.
Untuk pengamatan, tabel sistem adalah penyimpanan analitik yang dihosting Databricks dari data operasional akun Anda. Tabel sistem dapat digunakan untuk pengamatan historis di seluruh akun Anda.
Mesin inteligensi data
Platform Data Intelligence Databricks memungkinkan seluruh organisasi Anda untuk menggunakan data dan AI. Ini didukung oleh DatabricksIQ dan menggabungkan AI generatif dengan manfaat penyatuan lakehouse untuk memahami semantik unik data Anda.
Asisten Databricks tersedia di notebook Databricks, editor SQL, dan editor file sebagai asisten AI sadar konteks untuk pengembang.
Orkestrasi
Pekerjaan Databricks mengatur pemrosesan data, pembelajaran mesin, dan alur analitik pada Databricks Data Intelligence Platform. Tabel Langsung Delta memungkinkan Anda membangun alur ETL yang andal dan dapat dipertahankan dengan sintaks deklaratif.
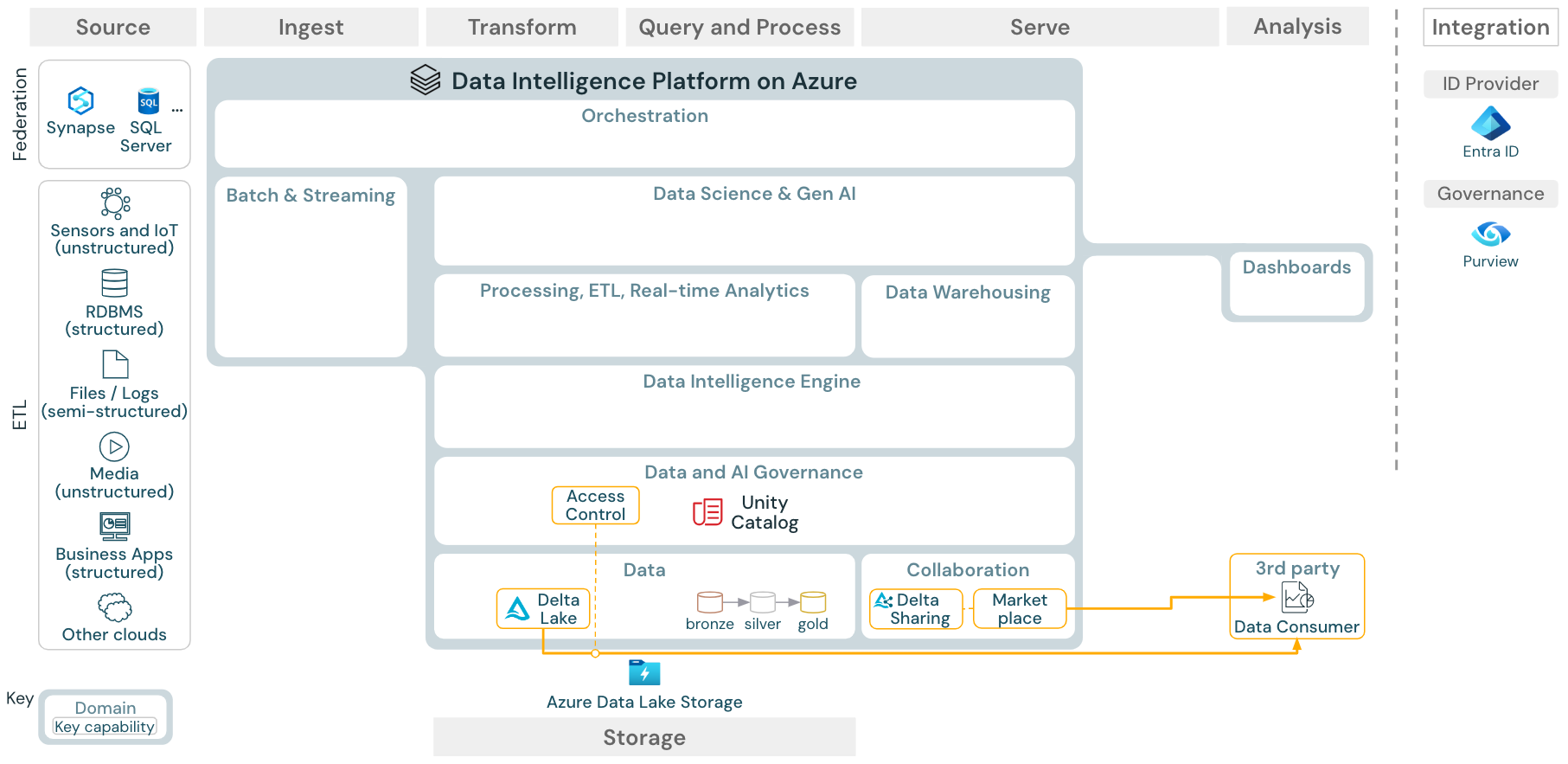
Arsitektur referensi Platform Kecerdasan Data di Azure
Arsitektur Referensi Azure Databricks berasal dari arsitektur referensi generik dengan menambahkan layanan khusus Azure untuk elemen Sumber, Penyerapan, Sajian, Analisis/Output, dan Penyimpanan.
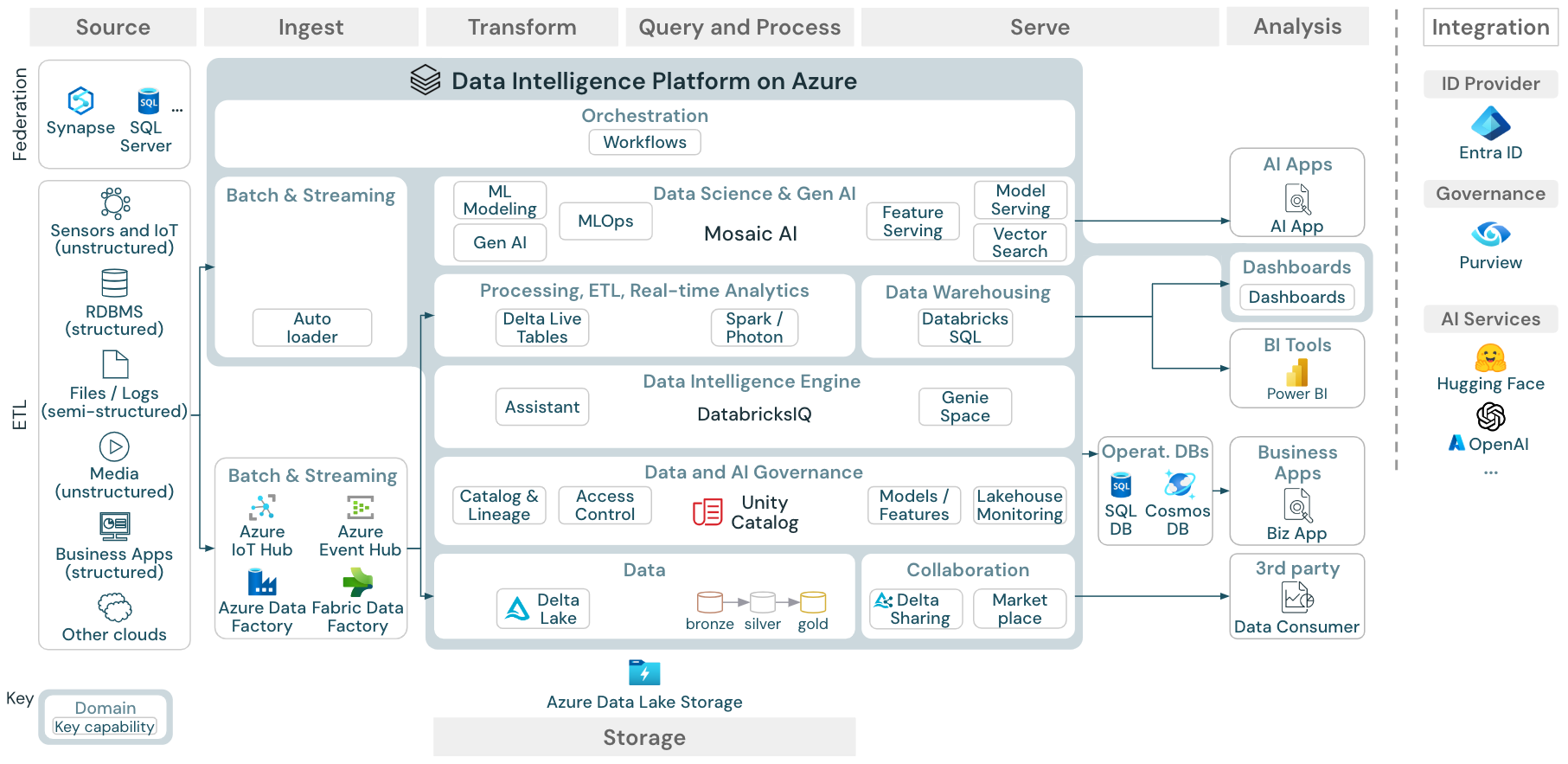
Unduh: Arsitektur referensi untuk databricks lakehouse di Azure
Arsitektur referensi Azure memperlihatkan layanan khusus Azure berikut untuk Ingest, Storage, Serve, dan Analysis/Output:
- Azure Synapse dan SQL Server sebagai sistem sumber untuk Federasi Lakehouse
- Azure IoT Hub dan Azure Event Hubs untuk penyerapan streaming
- Azure Data Factory untuk penyerapan batch
- Azure Data Lake Storage Gen 2 (ADLS) sebagai penyimpanan objek
- Azure SQL DB dan Azure Cosmos DB sebagai database operasional
- Azure Purview sebagai katalog perusahaan tempat UC akan mengekspor skema dan informasi silsilah data
- Power BI sebagai alat BI
Catatan
- Tampilan arsitektur referensi ini hanya berfokus pada layanan Azure dan databricks lakehouse. Lakehouse di Databricks adalah platform terbuka yang terintegrasi dengan ekosistem besar alat mitra.
- Layanan penyedia cloud yang ditampilkan tidak lengkap. Mereka dipilih untuk mengilustrasikan konsep.
Kasus penggunaan: Batch ETL
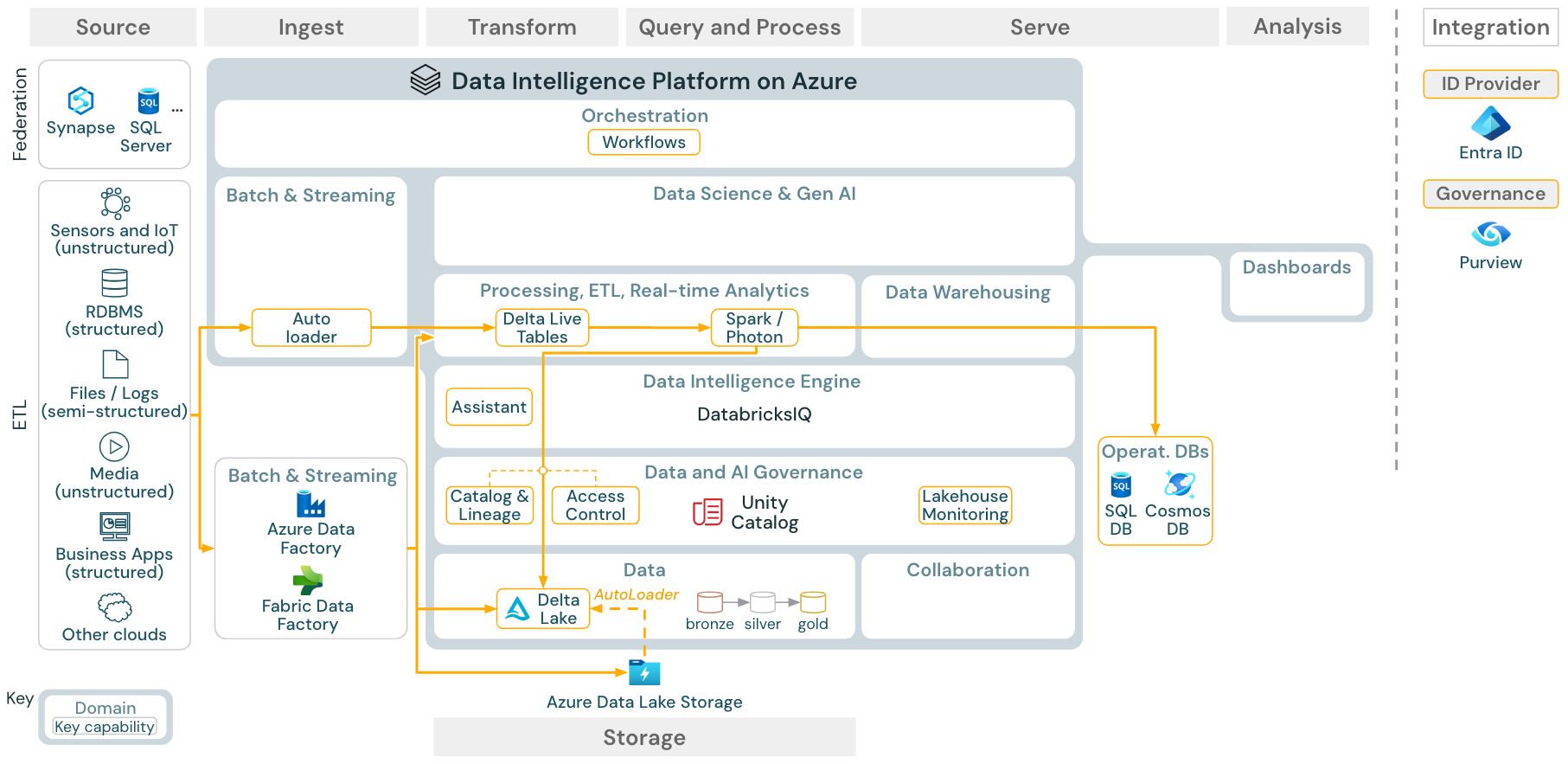
Unduh: Arsitektur referensi ETL Batch untuk Azure Databricks
Alat penyerapan menggunakan adaptor khusus sumber untuk membaca data dari sumber dan kemudian menyimpannya di penyimpanan cloud dari mana Auto Loader dapat membacanya, atau memanggil Databricks secara langsung (misalnya, dengan alat penyerapan mitra yang terintegrasi ke dalam lakehouse Databricks). Untuk memuat data, Databricks ETL dan mesin pemrosesan - melalui DLT - menjalankan kueri. Alur kerja tunggal atau multitugas dapat diorkestrasi oleh Pekerjaan Databricks dan diatur oleh Katalog Unity (kontrol akses, audit, silsilah data, dan sebagainya). Jika sistem operasional latensi rendah memerlukan akses ke tabel emas tertentu, mereka dapat diekspor ke database operasional seperti RDBMS atau penyimpanan nilai kunci di akhir alur ETL.
Kasus penggunaan: Streaming dan ubah pengambilan data (CDC)
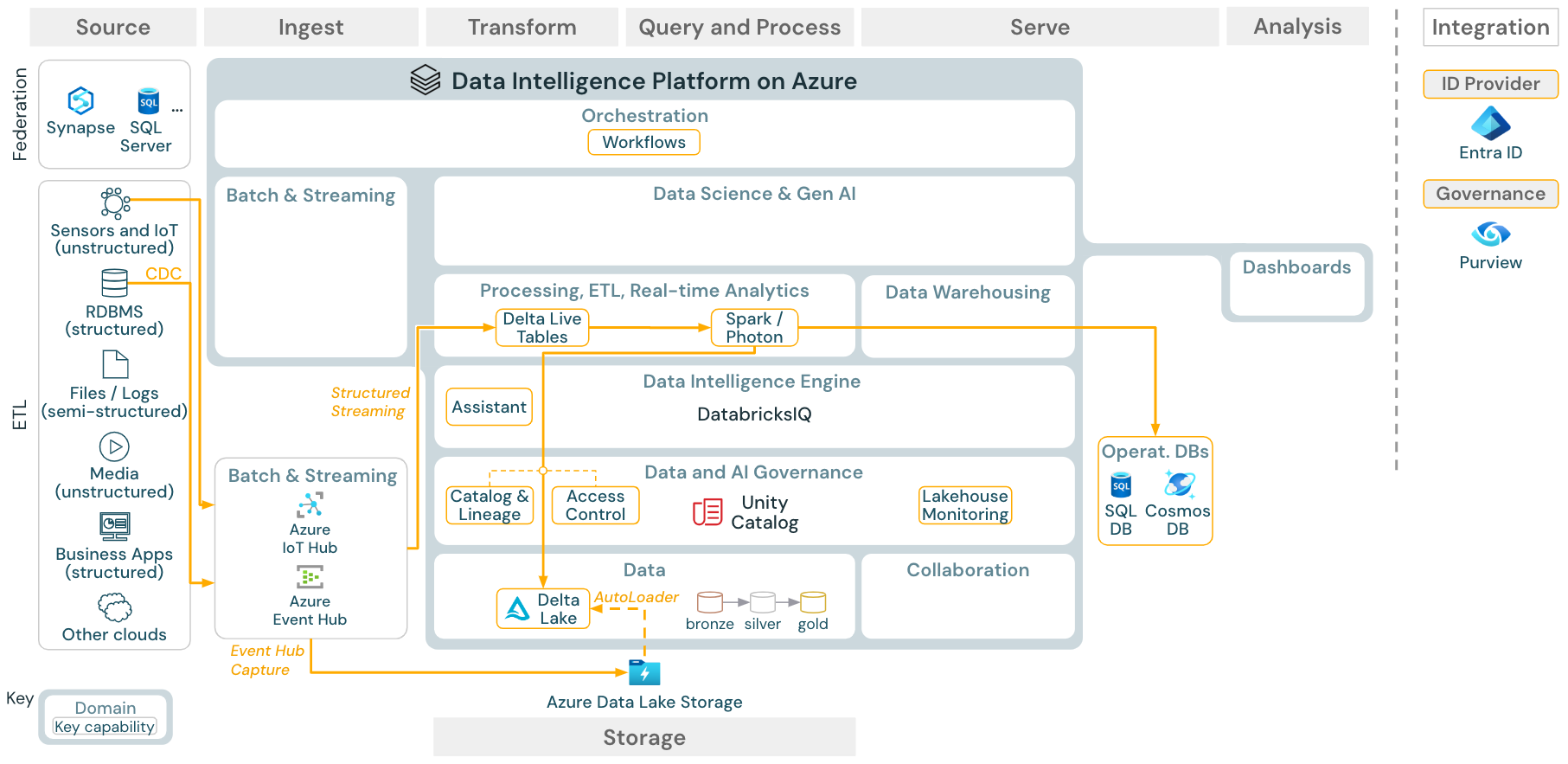
Unduh: Arsitektur streaming terstruktur Spark untuk Azure Databricks
Mesin Databricks ETL menggunakan Spark Structured Streaming untuk membaca dari antrean peristiwa seperti Apache Kafka atau Azure Event Hub. Langkah-langkah hilir mengikuti pendekatan kasus penggunaan Batch di atas.
Pengambilan data perubahan real time (CDC) biasanya menggunakan antrean peristiwa untuk menyimpan peristiwa yang diekstrak. Dari sana, kasus penggunaan mengikuti kasus penggunaan streaming.
Jika CDC dilakukan dalam batch tempat rekaman yang diekstrak disimpan di penyimpanan cloud terlebih dahulu, maka Databricks Autoloader dapat membacanya dan kasus penggunaan mengikuti Batch ETL.
Kasus penggunaan: Pembelajaran mesin dan AI
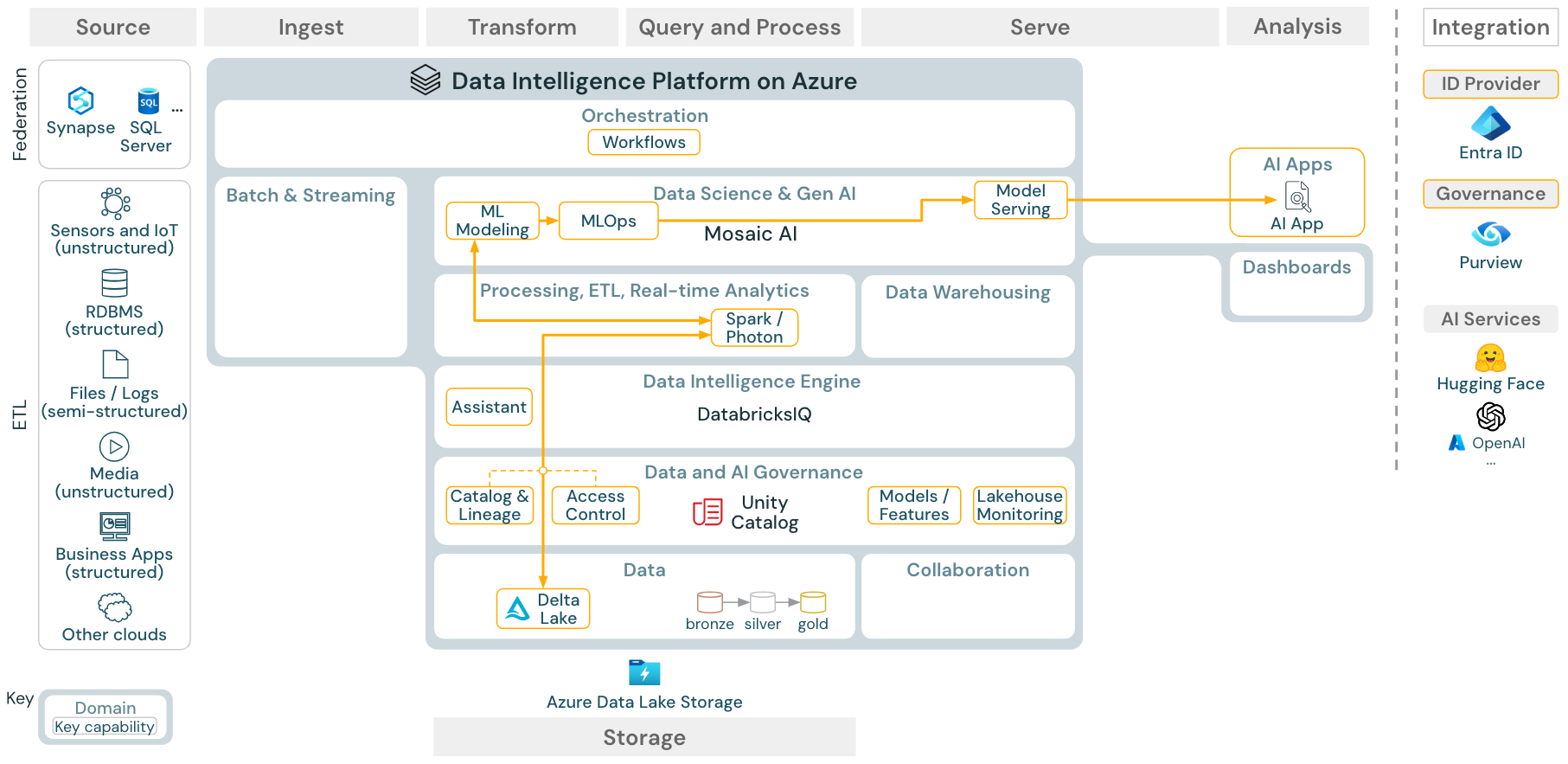
Unduh: Arsitektur referensi pembelajaran mesin dan referensi AI untuk Azure Databricks
Untuk pembelajaran mesin, Databricks Data Intelligence Platform menyediakan Mosaic AI, yang dilengkapi dengan mesin canggih dan pustaka pembelajaran mendalam. Ini menyediakan kemampuan seperti Penyimpanan Fitur dan registri model (keduanya terintegrasi ke dalam Unity Catalog), fitur kode rendah dengan AutoML, dan integrasi MLflow ke dalam siklus hidup ilmu data.
Semua aset terkait ilmu data (tabel, fitur, dan model) diatur oleh Unity Catalog dan ilmuwan data dapat menggunakan Pekerjaan Databricks untuk mengatur pekerjaan mereka.
Untuk menyebarkan model dengan cara yang dapat diskalakan dan tingkat perusahaan, gunakan kemampuan MLOps untuk menerbitkan model dalam penyajian model.
Kasus penggunaan: Pengambilan Augmented Generation (Gen AI)
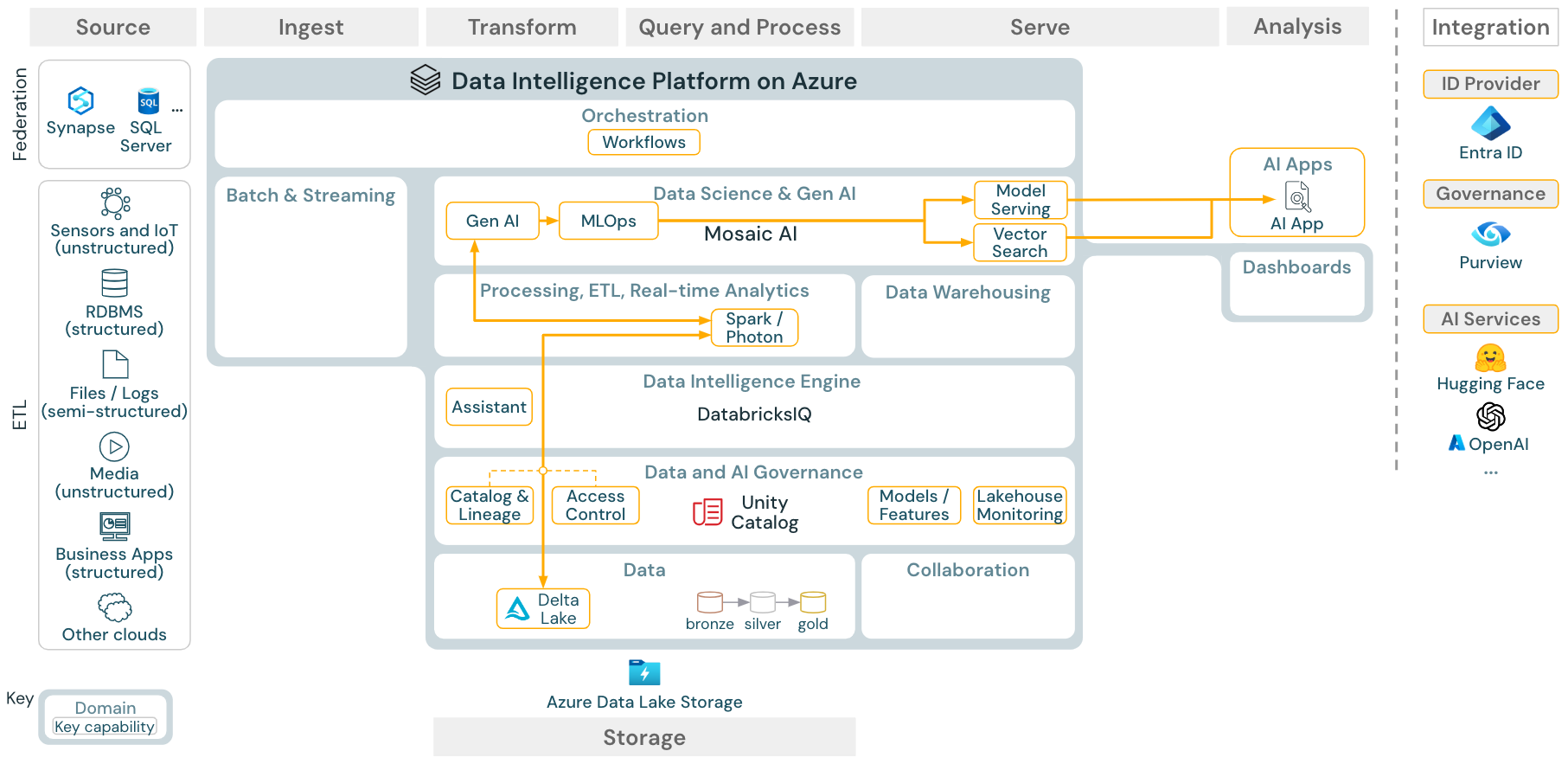
Unduh: Arsitektur referensi GEN AI RAG untuk Azure Databricks
Untuk kasus penggunaan AI generatif, Mosaic AI dilengkapi dengan pustaka canggih dan kemampuan Gen AI tertentu dari rekayasa yang cepat hingga penyempurnaan model yang ada dan pra-pelatihan dari awal. Arsitektur di atas menunjukkan contoh bagaimana pencarian vektor dapat diintegrasikan untuk membuat aplikasi AI RAG (retrieval augmented generation).
Untuk menyebarkan model dengan cara yang dapat diskalakan dan tingkat perusahaan, gunakan kemampuan MLOps untuk menerbitkan model dalam penyajian model.
Kasus penggunaan: Analitik BI dan SQL
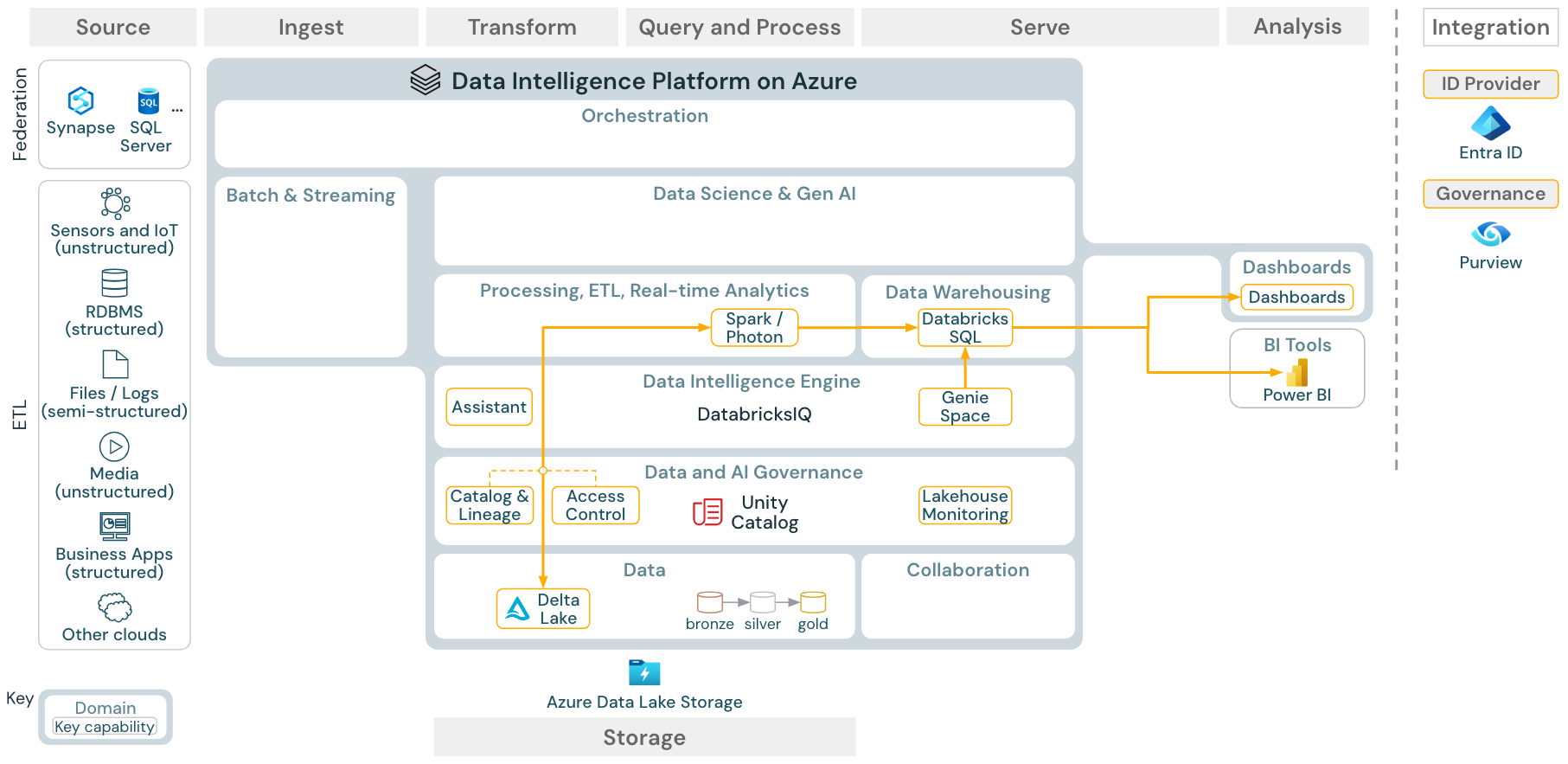
Unduh: Arsitektur referensi analitik BI dan SQL untuk Azure Databricks
Untuk kasus penggunaan BI, analis bisnis dapat menggunakan dasbor, editor Databricks SQL atau alat BI tertentu seperti Tableau atau Power BI. Dalam semua kasus, mesinnya adalah Databricks SQL (tanpa server atau tanpa server) dan penemuan data, eksplorasi, dan kontrol akses disediakan oleh Unity Catalog.
Kasus penggunaan: Federasi Lakehouse
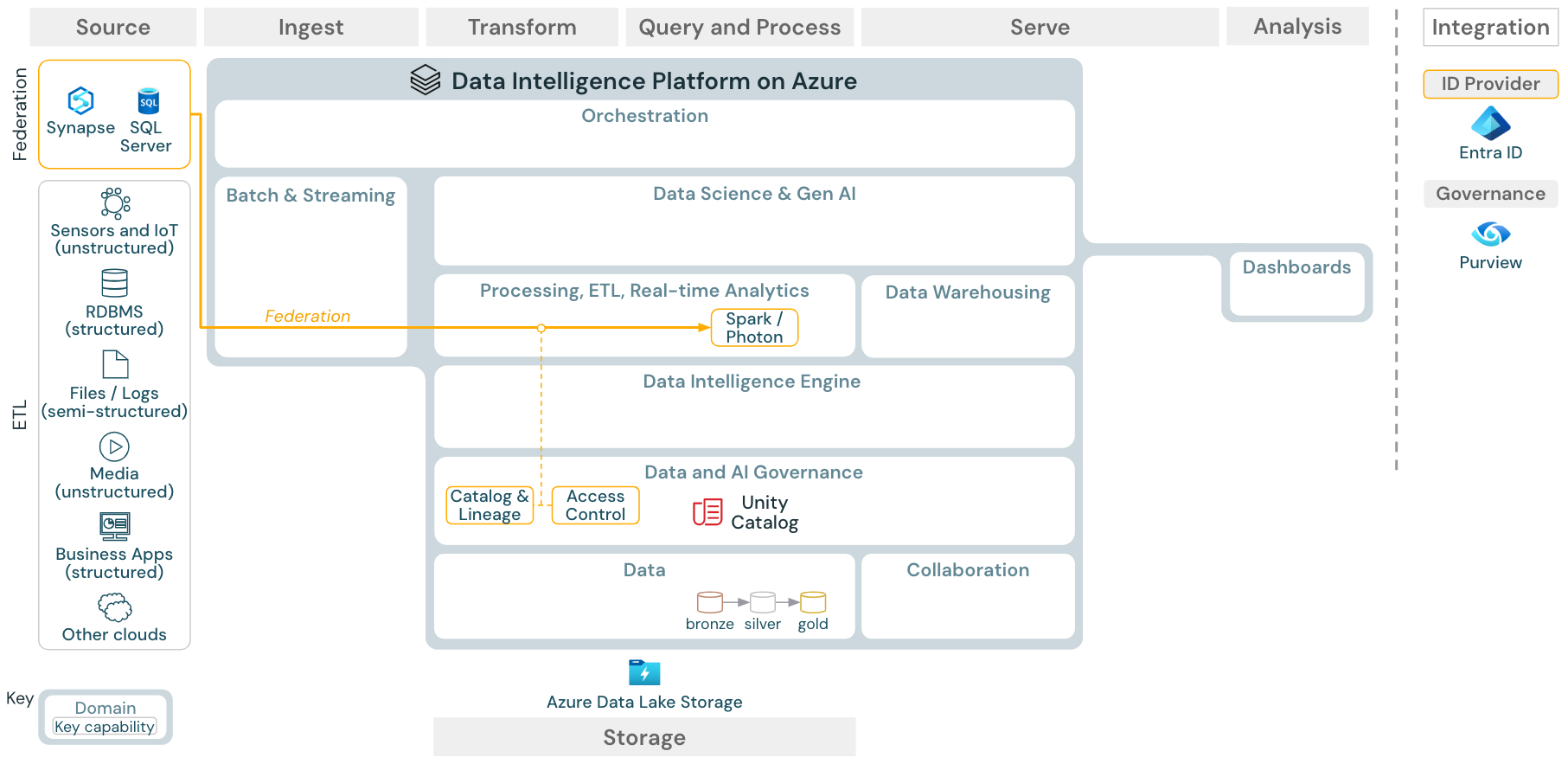
Unduh: Arsitektur referensi federasi Lakehouse untuk Azure Databricks
Federasi Lakehouse memungkinkan database SQL data eksternal (seperti MySQL, Postgres, SQL Server, atau Azure Synapse) untuk diintegrasikan dengan Databricks.
Semua beban kerja (AI, DWH, dan BI) dapat memperoleh manfaat dari ini tanpa perlu ETL data ke penyimpanan objek terlebih dahulu. Katalog sumber eksternal dipetakan ke dalam katalog Unity dan kontrol akses halus dapat diterapkan untuk mengakses melalui platform Databricks.
Kasus penggunaan: Berbagi data perusahaan
Unduh: Arsitektur referensi berbagi data perusahaan untuk Azure Databricks
Berbagi data tingkat perusahaan disediakan oleh Berbagi Delta. Ini menyediakan akses langsung ke data di penyimpanan objek yang diamankan oleh Unity Catalog, dan Databricks Marketplace adalah forum terbuka untuk bertukar produk data.