Menyiapkan pelatihan AutoML dengan Python
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam panduan ini, pelajari cara menyiapkan pembelajaran mesin otomatis, AutoML, pelatihan yang dijalankan dengan SDK Python Azure Machine Learning menggunakan ML otomatis Azure Machine Learning. ML otomatis memilih algoritma dan hyperparameter untuk Anda dan menghasilkan model yang siap digunakan. Panduan ini memberikan detail berbagai opsi yang dapat Anda gunakan untuk mengonfigurasi eksperimen ML otomatis.
Untuk contoh end to end, lihat Tutorial: Model regresi latih AutoML.
Jika Anda lebih suka pengalaman tanpa kode, Anda juga dapat Menyiapkan pelatihan AutoML tanpa kode di studio Azure Machine Learning.
Prasyarat
Untuk artikel ini Anda memerlukan,
Ruang kerja Azure Machine Learning. Untuk membuat ruang kerja, lihat Membuat sumber daya ruang kerja.
Azure Machine Learning Python SDK yang diinstal. Untuk menginstal SDK Anda dapat baik,
Buat instans komputasi, yang secara otomatis menginstal SDK dan telah dikonfigurasi sebelumnya untuk alur kerja ML. Lihat Membuat dan mengelola instans komputasi Azure Machine Learning untuk informasi selengkapnya.
Instal
automlpaket sendiri, yang mencakup instalasi default SDK.
Penting
Perintah Python dalam artikel ini memerlukan versi paket
azureml-train-automlterbaru.- Pasang paket
azureml-train-automlterbaru ke lingkungan lokal Anda. - Untuk detail tentang paket
azureml-train-automlterbaru, lihat catatan rilis.
Peringatan
Python 3.8 tidak kompatibel dengan
automl.
Memilih jenis eksperimen Anda
Sebelum memulai eksperimen, Anda harus menentukan jenis masalah pembelajaran mesin yang Anda pecahkan. Pembelajaran mesin otomatis mendukung jenis tugas classification, regression dan forecasting. Pelajari selengkapnya tentang tipe tugas.
Catatan
Dukungan untuk tugas pemrosesan bahasa alami (NLP): klasifikasi gambar (multikelas dan multi-label) dan pengenalan entitas karakter tersedia dalam pratinjau publik. Pelajari lebih lanjut tugas NLP di ML otomatis.
Kemampuan pratinjau ini disediakan tanpa perjanjian tingkat layanan (SLA). Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Kode berikut menggunakan task parameter di AutoMLConfig konstruktor untuk menentukan jenis eksperimen sebagai classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Sumber dan format data
Pembelajaran mesin otomatis mendukung data yang berada di desktop lokal Anda atau di cloud seperti Azure Blob Storage. Data dapat dibaca ke dalam Pandas DataFrame atau Azure Machine Learning TabularDataset. Pelajari selengkapnya tentang himpunan data.
Persyaratan untuk data pelatihan dalam pembelajaran mesin:
- Data harus dalam bentuk tabular.
- Nilai yang akan diprediksi, kolom target, harus ada dalam data.
Penting
Eksperimen ML otomatis tidak mendukung pelatihan dengan himpunan data yang menggunakan akses data berbasis identitas.
Untuk eksperimen jarak jauh,data pelatihan harus dapat diakses dari komputasi jarak jauh. ML otomatis hanya menerima Azure Machine Learning TabularDatasets saat mengerjakan komputasi jarak jauh.
Kumpulan data Azure Machine Learning mengekspos fungsi untuk:
- Mentransfer data dengan mudah dari file statik atau sumber URL ke ruang kerja Anda.
- Menjadikan data Anda tersedia untuk skrip pelatihan saat berjalan di sumber daya komputasi cloud. Lihat Cara berlatih dengan set data misalnya menggunakan kelas untuk memasang data ke target komputasi jarak jauh
DatasetAnda.
Kode berikut membuat TabularDataset yang tidak terdaftar dari url web. Lihat Membuat TabularDataset untuk contoh kode tentang cara membuat himpunan data dari sumber lain seperti file lokal dan penyimpanan data.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
Untuk eksperimen komputasi lokal, kamimerekomendasikan pandas dataframe untuk waktu pemrosesan yang lebih cepat.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Pelatihan, validasi, dan data pengujian
Anda dapat menentukan data pelatihan terpisah dan kumpulan data validasi langsung di AutoMLConfig konstruktor. Pelajari selengkapnya cara mengonfigurasikan pelatihan, validasi, validasi silang, dan data uji untuk eksperimen AutoML Anda.
Jika Anda tidak secara eksplisit menentukan validation_data atau n_cross_validation parameter, ML otomatis menerapkan teknik default untuk menentukan bagaimana validasi dilakukan. Penentuan ini tergantung pada jumlah baris dalam set data yang ditetapkan ke parameter training_data Anda.
| Ukuran data pelatihan | Teknik validasi |
|---|---|
| Lebih besar dari 20.000 baris | Pemisahan data pelatihan/validasi diterapkan. Defaultnya yaitu mengambil 10% dari himpunan data pelatihan awal sebagai set validasi. Pada saatnya, set validasi tersebut digunakan untuk perhitungan metrik. |
| Lebih kecil dari 20.000 baris | Pendekatan validasi silang diterapkan. Jumlah lipatan default tergantung pada jumlah baris. Jika himpunan data kurang dari 1.000 baris, 10 lipatan akan digunakan. Jika baris antara 1.000 dan 20.000, maka tiga lipatan digunakan. |
Tip
Anda dapat mengunggah data uji (pratinjau) untuk mengevaluasi ML otomatis yang dihasilkan untuk Anda. Berbagai fitur ini adalah kemampuan pratinjau eksperimental, dan dapat berubah kapan saja. Pelajari cara:
- Teruskan data uji ke objek AutoMLConfig.
- Uji model ML otomatis yang dihasilkan untuk eksperimen Anda.
Jika Anda lebih suka pengalaman tanpa kode, lihat langkah 12 dalam Menyiapkan AutoML dengan UI studio
Data besar
ML otomatis mendukung sejumlah algoritma untuk pelatihan data besar yang dapat berhasil membangun model untuk data besar pada mesin virtual kecil. Heuristik ML otomatis bergantung pada properti seperti ukuran data, ukuran memori mesin virtual, batas waktu percobaan dan pengaturan featurization untuk menentukan apakah algoritma data besar ini harus diterapkan. Pelajari lebih lanjut tentang model apa yang didukung di ML otomatis.
Untuk regresi, Regresor Keturunan Gradien Online dan Regresi Linier Cepat
Untuk klasifikasi, Pengklasifikasi Perceptron Rata-rata dan Pengklasifikasi SVM Linier; di mana pengklasifikasi SVM Linier memiliki versi data besar dan data kecil.
Jika Anda ingin mengesampingkan heuristik ini, terapkan pengaturan berikut:
| Tugas | Pengaturan | Catatan |
|---|---|---|
| Memblokir algoritma streaming data | blocked_models di objek AutoMLConfig Anda dan cantumkan model yang tidak ingin Anda gunakan. |
Menghasilkan kegagalan eksekusi atau waktu eksekusi yang panjang |
| Menggunakan algoritma streaming data | allowed_models di objek AutoMLConfig Anda dan cantumkan model yang ingin Anda gunakan. |
|
| Menggunakan algoritma streaming data (eksperimen UI studio) |
Blokir semua model kecuali algoritma data besar yang ingin Anda gunakan. |
Komputasi untuk menjalankan eksperimen
Selanjutnya tentukan di mana model akan dilatih. Eksperimen pelatihan pembelajaran ML dapat berjalan pada opsi komputasi berikut.
Pilih komputasi lokal: Jika rencana Anda adalah melakukan eksplorasi awal atau demo menggunakan data kecil dan rangkaian pendek (yaitu, beberapa detik atau menit per eksekusi anak), pelatihan di komputer lokal Anda mungkin merupakan pilihan yang lebih baik. Tidak ada waktu pengaturan, sumber daya infrastruktur (PC atau VM Anda) tersedia secara langsung. Lihat notebook ini untuk contoh komputasi lokal.
Pilih kluster komputasi ML jarak jauh: Jika Anda berlatih dengan himpunan data yang lebih besar seperti dalam pelatihan produksi yang menciptakan model yang membutuhkan rangkaian yang lebih panjang, komputasi jarak jauh akan memberikan performa waktu end-to-end yang jauh lebih baik karena
AutoMLakan mejajarkan rangkaian di seluruh node kluster. Pada komputasi jarak jauh, waktu mulai untuk infrastruktur internal akan bertambah sekitar 1,5 menit per turunan, ditambah menit tambahan untuk infrastruktur kluster jika VM belum aktif dan berjalan.Azure Machine Learning Managed Compute adalah sebuah layanan terkelola yang memungkinkan kemampuan untuk melatih model pembelajaran mesin pada kluster mesin virtual Azure. Instans komputasi juga didukung sebagai target komputasi.Klaster Azure Databricks di langganan Azure Anda. Anda dapat menemukan detail lebih lanjut di sini - Menyiapkan kluster Azure Databricks untuk ML Otomatis. Lihat situs GitHub ini untuk contoh notebook dengan Azure Databricks.
Pertimbangkan faktor-faktor ini saat memilih target komputasi:
| Kelebihan (Keuntungan) | Kontra (Kekurangan) | |
|---|---|---|
| Target komputasi lokal | ||
| Kluster komputasi ML jarak jauh |
Mengonfigurasi pengaturan eksperimen Anda
Ada beberapa opsi yang dapat Anda gunakan untuk mengonfigurasi eksperimen ML otomatis Anda. Parameter ini diatur dengan instantiating AutoMLConfig sebuah objek. Lihat kelas AutoMLConfig untuk daftar lengkap parameter.
Contoh berikut adalah untuk tugas klasifikasi. Eksperimen menggunakan pembobotan AUC sebagai metrik utama dan memiliki batas waktu eksperimen yang diatur ke 30 menit dan 2 kali validasi silang.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Anda juga dapat mengonfigurasi tugas prakiraan, yang memerlukan penyiapan ekstra. Lihat artikel Menyiapkan AutoML untuk prakiraan rangkaian waktu untuk mengetahui detail selengkapnya.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Model yang didukung
Pembelajaran mesin otomatis mencoba berbagai model dan algoritme selama proses otomatisasi dan penyetelan. Sebagai pengguna, anda tidak perlu menentukan algoritmanya.
Tiga nilai task parameter yang berbeda menentukan daftar algoritma, atau model, untuk diterapkan. Gunakan allowed_models parameter blocked_models atau untuk memodifikasi iterasi lebih lanjut dengan model yang tersedia untuk disertakan atau dikecualikan.
Tabel berikut ini meringkas model yang didukung menurut tipe tugas.
Catatan
Jika Anda berencana untuk mengekspor model yang dibuat ML otomatis ke model ONNX, hanya algoritme yang ditunjukkan dengan * (tanda bintang) yang dapat dikonversi ke format ONNX. Pelajari selengkapnya tentang mengonversi model ke ONNX.
Perlu diketahui juga, ONNX hanya mendukung tugas klasifikasi dan regresi saat ini.
Metrik utama
Parameter primary_metric menentukan metrik yang akan digunakan selama pelatihan model untuk pengoptimalan. Metrik yang tersedia yang dapat Anda pilih ditentukan oleh jenis tugas yang dipilih.
Memilih metrik utama untuk ML otomatis untuk dioptimalkan tergantung pada banyak faktor. Kami menyarankan pertimbangan utama Anda adalah untuk memilih metrik yang paling mewakili kebutuhan bisnis. Kemudian pertimbangkan apakah metrik cocok untuk profil set data Anda (ukuran data, rentang, distribusi kelas, dll.). Bagian berikut meringkas metrik utama yang disarankan berdasarkan jenis tugas dan skenario bisnis.
Pelajari tentang definisi spesifik dari metrik ini dalam Memahami hasil pembelajaran mesin otomatis.
Metrik untuk skenario klasifikasi
Metrik yang tergantung pada ambang, seperti accuracy, recall_score_weighted, norm_macro_recall, dan precision_score_weighted mungkin juga tidak dioptimalkan untuk himpunan data yang kecil, memiliki kemiringan kelas yang sangat besar (ketidakseimbangan kelas), atau jika nilai metrik yang diharapkan adalah sangat dekat dengan 0,0 atau 1,0. Dalam kasus tersebut, AUC_weighted bisa menjadi pilihan yang lebih baik untuk metrik utama. Setelah ML otomatis selesai, Anda dapat memilih model terbaik berdasarkan metrik yang paling sesuai dengan kebutuhan bisnis Anda.
| Metric | Contoh kasus penggunaan |
|---|---|
accuracy |
Klasifikasi gambar, analisis sentimen, prediksi Churn |
AUC_weighted |
Deteksi penipuan, Klasifikasi gambar, Deteksi anomali/deteksi spam |
average_precision_score_weighted |
Analisis sentimen |
norm_macro_recall |
Prediksi Churn |
precision_score_weighted |
Metrik untuk skenario regresi
r2_score, normalized_mean_absolute_error dan normalized_root_mean_squared_error mencoba meminimalkan kesalahan prediksi. r2_score dan normalized_root_mean_squared_error keduanya meminimalkan kesalahan kuadrat rata-rata sementara sedang menambang nilai absolut normalized_mean_absolute_error rata-rata kesalahan. Nilai absolut memperlakukan kesalahan pada semua besarnya sama dan kesalahan kuadrat akan memiliki penalti yang jauh lebih besar untuk kesalahan dengan nilai absolut yang lebih besar. Tergantung apakah kesalahan yang lebih besar harus dihukum lebih atau tidak, seseorang dapat memilih untuk mengoptimalkan kesalahan kuadrat atau kesalahan absolut.
Perbedaan utama antara r2_score dan normalized_root_mean_squared_error adalah cara mereka dinormalisasi dan maknanya. normalized_root_mean_squared_error adalah akar rata-rata kesalahan kuadrat dinormalisasi oleh rentang dan dapat ditafsirkan sebagai besarnya kesalahan rata-rata untuk prediksi. r2_score adalah kesalahan kuadrat rata-rata yang dinormalisasi oleh perkiraan varians data. Ini adalah proporsi variasi yang dapat diambil oleh model.
Catatan
r2_score dan normalized_root_mean_squared_error juga berperilaku serupa dengan metrik utama. Jika kumpulan validasi tetap diterapkan, kedua metrik ini mengoptimalkan target yang sama, kesalahan kuadrat rata-rata, dan akan dioptimalkan oleh model yang sama. Saat hanya satu set pelatihan yang tersedia dan validasi silang diterapkan, mereka akan sedikit berbeda karena normalizer untuk normalized_root_mean_squared_error diperbaiki sebagai rentang set pelatihan, tetapi normalizer untuk r2_score akan bervariasi untuk setiap lipatan karena varians untuk setiap lipatan.
Jika peringkat, bukan nilai yang tepat adalah menarik, spearman_correlation dapat menjadi pilihan yang lebih baik karena mengukur korelasi peringkat antara nilai-nilai nyata dan prediksi.
Namun, saat ini tidak ada metrik utama untuk regresi yang membahas perbedaan relatif. Semua r2_score, normalized_mean_absolute_error, dan normalized_root_mean_squared_error memperlakukan kesalahan prediksi $ 20k sama untuk pekerja dengan gaji $ 30k sebagai pekerja menghasilkan $ 20 juta, jika kedua titik data ini termasuk dalam himpunan data yang sama untuk regresi, atau seri waktu yang sama yang ditentukan oleh pengenal deret waktu. Sementara pada kenyataannya, memprediksi hanya $ 20k off dari gaji $ 20M sangat dekat (selisih relatif kecil 0,1%), sedangkan $ 20k off dari $ 30k adalah tidak dekat (perbedaan relatif 67% besar). Untuk mengatasi masalah perbedaan relatif, seseorang dapat melatih model dengan metrik utama yang tersedia, kemudian memilih model dengan mean_absolute_percentage_error atau root_mean_squared_log_error terbaik.
| Metric | Contoh kasus penggunaan |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Prediksi harga (rumah/produk/tip), Tinjau prediksi skor |
r2_score |
Keterlambatan maskapai, Estimasi gaji, waktu resolusi bug |
normalized_mean_absolute_error |
Metrik untuk skenario prakiraan seri waktu
Rekomendasinya mirip dengan yang dicatat untuk skenario regresi.
| Metric | Contoh kasus penggunaan |
|---|---|
normalized_root_mean_squared_error |
Prediksi harga (perkiraan), Pengoptimalan persediaan, Perkiraan permintaan |
r2_score |
Prediksi harga (perkiraan), Pengoptimalan persediaan, Perkiraan permintaan |
normalized_mean_absolute_error |
Featurisasi data
Dalam setiap eksperimen ML otomatis, data Anda secara otomatis diskalakan dan dinormalisasi untuk membantu algoritme tertentu yang sensitif terhadap fitur yang berada pada skala yang berbeda. Penskalaan dan normalisasi ini disebut sebagai featurization. Lihat Featurization di AutoML untuk contoh detail dan kode lebih lanjut.
Catatan
Langkah-langkah fiturisasi pembelajaran mesin otomatis (normalisasi fitur, penanganan data yang hilang, mengonversi teks menjadi numerik, dll.) menjadi bagian dari model yang mendasari. Saat menggunakan model untuk prediksi, langkah-langkah fiturisasi yang sama dan diterapkan selama pelatihan akan diterapkan ke data input Anda secara otomatis.
Saat mengonfigurasi eksperimen di AutoMLConfig objek, Anda dapat mengaktifkan/menonaktifkan featurization pengaturan. Tabel berikut ini memperlihatkan pengaturan yang diterima untuk fiturisasi di objek AutoMLConfig.
| Konfigurasi Fiturisasi | Deskripsi |
|---|---|
"featurization": 'auto' |
Menunjukkan bahwa sebagai bagian dari praproses, pagar pembatas data dan langkah-langkah fiturisasi dilakukan secara otomatis. Pengaturan default. |
"featurization": 'off' |
Menunjukkan langkah fiturisasi tidak boleh dilakukan secara otomatis. |
"featurization": 'FeaturizationConfig' |
Menunjukkan langkah fiturisasi yang disesuaikan harus digunakan. Pelajari cara kustomisasi fiturisasi. |
Konfigurasi ansambel
Model ansambel diaktifkan secara default, dan muncul sebagai iterasi jalankan akhir dalam menjalankan AutoML. Saat ini VotingEnsemble dan StackEnsemble didukung.
Pemungutan suara menerapkan soft-voting, yang menggunakan rata-rata tertimbang. Implementasi penumpukan menggunakan implementasi dua lapisan, di mana lapisan pertama memiliki model yang sama dengan ansambel pemungutan suara, dan model lapisan kedua digunakan untuk menemukan kombinasi optimal model dari lapisan pertama.
Jika Anda menggunakan model ONNX, atau mengaktifkan penjelasan model, penumpukan dinonaktifkan dan hanya pemungutan suara yang digunakan.
Pelatihan ansambel dapat dinonaktifkan dengan enable_voting_ensemble menggunakan enable_stack_ensemble parameter dan boolean.
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Untuk mengubah perilaku ansambel default, ada beberapa argumen default yang dapat disediakan seperti kwargs dalam AutoMLConfig objek.
Penting
Parameter berikut bukan parameter eksplisit dari class AutoMLConfig.
ensemble_download_models_timeout_sec: Selama pembuatan model VotingEnsemble dan StackEnsemble, beberapa model yang dipasang dari child runs sebelumnya akan diunduh. Jika Anda mengalami kesalahan ini:AutoMLEnsembleException: Could not find any models for running ensembling, maka Anda mungkin perlu memberikan lebih banyak waktu agar model dapat diunduh. Nilai default adalah 300 detik untuk mengunduh model ini secara paralel dan tidak ada batas waktu habis maksimum. Konfigurasikan parameter ini dengan nilai lebih tinggi dari 300 detik, jika diperlukan lebih banyak waktu.Catatan
Jika waktu habis tercapai dan ada model yang diunduh, maka ansambel akan diproses dengan model sebanyak yang telah diunduh. Tidak semua model harus diunduh untuk menyelesaikan dalam batas waktu tersebut. Parameter berikut hanya berlaku untuk model StackEnsemble:
stack_meta_learner_type: meta-learner adalah model yang dilatih pada output dari model heterogen individu. Pelajar meta default adalahLogisticRegressionuntuk tugas klasifikasiLogisticRegressionCV(atau jika validasi silang diaktifkan)ElasticNetdan untuk tugas regresi/perkiraanElasticNetCV(atau jika validasi silang diaktifkan). Parameter ini bisa menjadi salah satu string berikut:LogisticRegression,LogisticRegressionCV,LightGBMClassifier,ElasticNet,ElasticNetCV,LightGBMRegressor, atauLinearRegression.stack_meta_learner_train_percentage: menentukan proporsi set pelatihan (saat memilih kereta dan jenis pelatihan validasi) yang akan dicadangkan untuk pelatihan meta-learner. Nilai default0.2.stack_meta_learner_kwargs: parameter opsional untuk diteruskan ke inisialisasi meta-learner. Parameter dan jenis parameter ini mencerminkan parameter dan jenis parameter dari konstruktor model yang sesuai, dan diteruskan ke konstruktor model.
Kode berikut menunjukkan contoh menentukan perilaku ansambel kustom dalam AutoMLConfig suatu objek.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Kriteria keluar
Ada beberapa opsi yang dapat Anda tentukan di AutoMLConfig untuk mengakhiri eksperimen Anda.
| Kriteria | description |
|---|---|
| Tidak ada kriteria | Jika Anda tidak menentukan parameter keluar, eksperimen berlanjut hingga tidak ada kemajuan lebih lanjut yang dibuat pada metrik utama Anda. |
| Setelah sekian lama | Gunakan experiment_timeout_minutes dalam pengaturan Anda untuk menentukan berapa lama, dalam hitungan menit, eksperimen Anda harus terus berjalan. Untuk membantu menghindari kegagalan waktu eksperimen, ada minimal 15 menit, atau 60 menit jika ukuran baris demi kolom Melebihi 10 juta. |
| Kuota telah tercapai | Penggunaan experiment_exit_score menyelesaikan eksperimen setelah skor metrik utama yang ditentukan tercapai. |
Menjalankan eksperimen
Peringatan
Jika Anda menjalankan eksperimen dengan pengaturan konfigurasi dan metrik utama yang sama beberapa kali, kemungkinan Anda akan melihat variasi di setiap skor metrik akhir eksperimen dan model yang dihasilkan. Algoritme yang digunakan ML otomatis memiliki keacakan bawaan yang dapat menyebabkan sedikit variasi dalam keluaran model oleh eksperimen dan skor metrik akhir model yang direkomendasikan, seperti akurasi. Anda mungkin juga akan melihat hasil dengan nama model yang sama, tetapi hiperparameter yang berbeda digunakan.
Untuk ML otomatis, Anda membuat Experiment objek, yang merupakan objek bernama dalam Workspace eksperimen yang digunakan untuk menjalankan.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Kirim eksperimen untuk menjalankan dan membuat model. Teruskan AutoMLConfig ke metode submit untuk membuat model.
run = experiment.submit(automl_config, show_output=True)
Catatan
Dependensi pertama kali diinstal pada mesin baru. Mungkin perlu waktu hingga 10 menit sebelum output ditampilkan.
Pengaturan show_output True untuk menghasilkan output yang ditampilkan di konsol.
Beberapa anak berjalan pada kluster
Percobaan ML otomatis yang dijalankan anak dapat dilakukan pada klaster yang sudah menjalankan eksperimen lain. Namun, waktunya tergantung pada berapa banyak node yang memiliki kluster, dan jika node tersebut tersedia untuk menjalankan eksperimen yang berbeda.
Setiap node dalam klaster bertindak sebagai mesin virtual individu (VM) yang dapat mencapai satu pelatihan; untuk ML otomatis ini berarti anak yang dijalankan. Jika semua node sibuk, eksperimen baru akan diantrikan. Tetapi jika ada node gratis, eksperimen baru akan menjalankan anak ML otomatis berjalan secara paralel di node / VM yang tersedia.
Untuk membantu mengelola lari anak dan kapan mereka dapat dilakukan, kami sarankan Anda membuat klaster khusus per percobaan, dan mencocokkan max_concurrent_iterations jumlah eksperimen Anda dengan jumlah node dalam klaster. Dengan cara ini, Anda menggunakan semua node kluster secara bersamaan dengan jumlah run/iterasi anak bersamaan yang Anda inginkan.
Mengonfigurasi max_concurrent_iterations di objek AutoMLConfig Anda. Jika tidak dikonfigurasi, maka secara default hanya satu run/iterasi anak bersamaan yang diizinkan per percobaan.
Untuk instans komputasi, max_concurrent_iterations dapat diatur agar sama dengan jumlah inti pada VM instans komputasi.
Menjelajahi model dan metrik
ML otomatis menawarkan opsi bagi Anda untuk memantau dan mengevaluasi hasil pelatihan Anda.
Anda bisa menampilkan hasil pelatihan Anda di widget atau sebaris jika Anda berada di buku catatan. Lihat Memantau pembelajaran mesin otomatis berjalan untuk detail selengkapnya.
Untuk definisi dan contoh bagan performa dan metrik yang disediakan untuk setiap proses, lihat Mengevaluasi hasil eksperimen pembelajaran mesin otomatis.
Untuk mendapatkan ringkasan fiturisasi dan memahami fitur apa yang ditambahkan ke model tertentu, lihat Transparansi fiturisasi.
Anda dapat melihat hyperparameter, teknik penskalaan dan normalisasi, dan algoritma yang diterapkan ke ML otomatis tertentu yang dijalankan dengan solusi kode kustom berikut, print_model().
Tip
ML otomatis juga memungkinkan Anda melihat kode pelatihan model yang dihasilkan untuk model terlatih auto ML. Fungsi ini ada dalam pratinjau publik dan dapat berubah kapan saja.
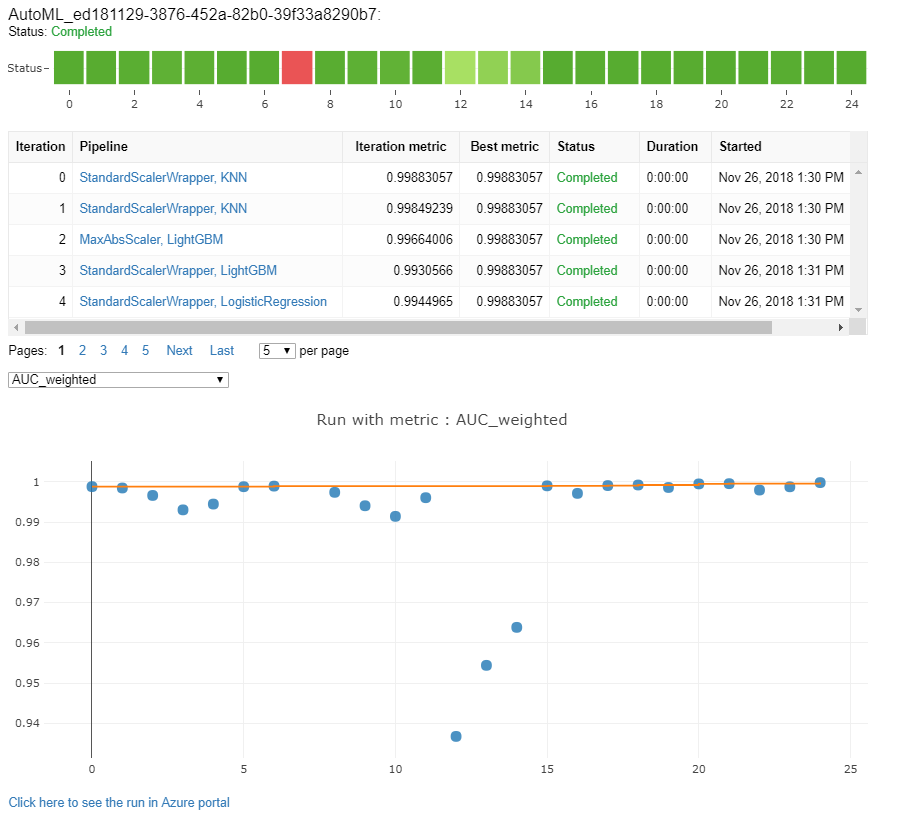
Memantau eksekusi pembelajaran mesin otomatis
Untuk ML yang berjalan otomatis, untuk mengakses bagan dari run sebelumnya, ganti <<experiment_name>> dengan nama eksperimen yang sesuai:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
Model uji (pratinjau)
Penting
Menguji model Anda dengan himpunan data uji untuk mengevaluasi model yang dihasilkan ML otomatis adalah fitur pratinjau. Kemampuan ini adalah fitur pratinjau eksperimental, dan dapat berubah sewaktu-waktu.
Peringatan
Fitur ini tidak tersedia untuk skenario ML otomatis berikut
Meneruskan parameter test_data atau test_sizeke dalam AutoMLConfig, secara otomatis memicu eksekusi uji jarak jauh yang menggunakan data uji yang disediakan untuk mengevaluasi model terbaik yang direkomendasikan ML otomatis setelah menyelesaikan eksperimen. Eksekusi uji jarak jauh ini dilakukan pada akhir eksperimenp, setelah model terbaik ditentukan. Lihata cara meneruskan data uji ke dalam AutoMLConfig.
Mendapatkan hasil pekerjaan pengujian
Anda bisa mendapatkan prediksi dan metrik dari pekerjaan pengujian jarak jauh dari Azure Machine Learning studio atau dengan kode berikut.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Pekerjaan pengujian model menghasilkan file prediksi.csv yang disimpan di penyimpanan data default yang dibuat dengan ruang kerja. Datastore ini dapat dilihat oleh semua pengguna dengan langganan yang sama. Pekerjaan pengujian tidak disarankan untuk skenario jika ada informasi yang digunakan untuk atau dibuat oleh tugas pengujian harus tetap bersifat privat.
Menguji model ML otomatis yang ada
Untuk menguji model ML otomatis lain yang sudah dibuat, pekerjaan terbaik atau pekerjaan turunan, gunakan ModelProxy() untuk menguji model setelah proses AutoML utama selesai. ModelProxy() sudah mengembalikan prediksi dan metrik serta tidak memerlukan pemrosesan lebih lanjut untuk mengambil output.
Catatan
ModelProxy adalah kelas pratinjau eksperimental dan mungkin berubah seiring waktu.
Kode berikut menunjukkan cara menguji model dari eksekusi mana pun dengan menggunakan metode ModelProxy.test(). Dalam metode uji() Anda memiliki opsi untuk menentukan apakah Anda hanya ingin melihat prediksi eksekusi uji dengan parameter include_predictions_only.
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Mendaftarkan dan menggunakan model
Setelah Anda menguji model dan mengonfirmasi bahwa Anda ingin menggunakannya dalam produksi, Anda dapat mendaftarkannya untuk digunakan nanti dan
Untuk mendaftarkan model dari menjalankan ML otomatis, gunakan metode register_model() ini.
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Untuk detail tentang cara membuat konfigurasi penyebaran dan menerapkan model terdaftar ke layanan web, lihat bagaimana dan di mana menerapkan model.
Tip
Untuk model terdaftar, penyebaran satu klik tersedia melalui studio Azure Machine Learning. Lihat cara menggunakan model terdaftar dari studio.
Interpretabilitas model
Interpretabilitas model memungkinkan Anda untuk memahami mengapa model Anda membuat prediksi, dan nilai-nilai penting fitur yang mendasarinya. SDK mencakup berbagai paket untuk memungkinkan fitur interpretasi model, baik pada waktu pelatihan dan inferensi, untuk model lokal dan yang digunakan.
Lihat cara mengaktifkan fitur interpretabilitas khususnya dalam eksperimen ML otomatis.
Untuk mengetahui informasi umum tentang bagaimana penjelasan model dan pentingnya fitur dapat diaktifkan di area lain dari SDK di luar pembelajaran mesin otomatis, lihat artikel konsep tentang interpretabilitas .
Catatan
Model ForecastTCN saat ini tidak didukung oleh Klien Penjelasan. Model ini tidak akan mengembalikan dasbor penjelasan jika dikembalikan sebagai model terbaik, dan tidak mendukung penjelasan sesuai permintaan berjalan.
Langkah berikutnya
Pelajari selengkapnya tentang cara dan tempat menerapkan model.
Pelajari lebih lanjut cara melatih model regresi dengan Pembelajaran mesin otomatis.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk