Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menyajikan contoh menyeluruh dari alur kerja Synapse Data Science di Microsoft Fabric. Skenario ini membangun model untuk memprediksi apakah pelanggan bank akan berhenti menjadi pelanggan atau tidak. Tingkat pengurangan pelanggan, atau tingkat kehilangan pelanggan, mengacu pada tingkat di mana nasabah bank mengakhiri hubungan bisnis mereka dengan bank.
Tutorial ini mencakup langkah-langkah berikut:
- Menginstal pustaka kustom
- Muat data
- Memahami dan memproses data melalui analisis data eksploratif, dan menunjukkan penggunaan fitur Fabric Data Wrangler
- Gunakan scikit-learn dan LightGBM untuk melatih model pembelajaran mesin, dan melacak eksperimen dengan fitur MLflow dan Fabric Autologging
- Mengevaluasi dan menyimpan model pembelajaran mesin akhir
- Memperlihatkan performa model dengan visualisasi Power BI
Prasyarat
Dapatkan langganan Microsoft Fabric . Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Gunakan pengalih pengalaman di sisi kiri bawah halaman beranda Anda untuk beralih ke Fabric.

- Jika perlu, buat lakehouse Microsoft Fabric seperti yang dijelaskan di Buat lakehouse di Microsoft Fabric.
Ikuti di dalam buku catatan
Anda bisa memilih salah satu opsi ini untuk diikuti dalam buku catatan:
- Buka dan jalankan buku catatan bawaan.
- Unggah buku catatan Anda dari GitHub.
Buka buku catatan bawaan
Contoh Notebook churn Pelanggan menyertai tutorial ini.
Untuk membuka contoh buku catatan untuk tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data.
Pastikan untuk melampirkan lakehouse ke notebook sebelum Anda mulai menjalankan kode.
Mengimpor notebook dari GitHub
Buku catatan AIsample - Bank Customer Churn.ipynb menyertai tutorial ini sebagai panduan.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi di Menyiapkan sistem Anda untuk tutorial ilmu data mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk menghubungkan lakehouse ke notebook sebelum Anda mulai menjalankan kode.
Langkah 1: Menginstal pustaka kustom
Untuk pengembangan model pembelajaran mesin atau analisis data ad-hoc, Anda mungkin perlu menginstal pustaka kustom dengan cepat untuk sesi Apache Spark Anda. Anda memiliki dua opsi untuk menginstal pustaka.
- Gunakan kemampuan instalasi langsung (
%pipatau%conda) buku catatan Anda untuk menginstal pustaka, hanya di buku catatan Anda saat ini. - Atau, Anda dapat membuat lingkungan Fabric, menginstal pustaka dari sumber publik atau mengunggah pustaka kustom ke dalamnya, dan kemudian admin ruang kerja Anda dapat melampirkan lingkungan sebagai default untuk ruang kerja. Semua pustaka di lingkungan kemudian akan tersedia untuk digunakan dalam berbagai notebook dan definisi tugas Spark di ruang kerja. Untuk informasi selengkapnya tentang lingkungan, lihat membuat, mengonfigurasi, dan menggunakan lingkungan di Microsoft Fabric.
Untuk tutorial ini, gunakan %pip install untuk menginstal pustaka imblearn di buku catatan Anda.
Nota
Kernel PySpark dimulai ulang setelah %pip install berjalan. Instal pustaka yang diperlukan sebelum Anda menjalankan sel lain.
# Use pip to install libraries
%pip install imblearn
Langkah 2: Muat data
Himpunan data dalam churn.csv berisi status churn 10.000 pelanggan, bersama dengan 14 atribut yang mencakup:
- Skor kredit
- Lokasi geografis (Jerman, Prancis, Spanyol)
- Jenis kelamin (laki-laki, perempuan)
- Umur
- Tenure (jumlah tahun orang tersebut menjadi nasabah di bank itu)
- Saldo akun
- Estimasi gaji
- Jumlah produk yang dibeli nasabah melalui bank
- Status kartu kredit (baik pelanggan memiliki kartu kredit atau tidak)
- Status anggota aktif (baik orang tersebut adalah nasabah bank aktif atau tidak)
Himpunan data juga mencakup nomor baris, ID pelanggan, dan kolom nama belakang pelanggan. Nilai dalam kolom ini tidak boleh memengaruhi keputusan pelanggan untuk meninggalkan bank.
Peristiwa penutupan rekening bank pelanggan menentukan churn untuk pelanggan tersebut. Kolom Exited dalam himpunan data mengacu pada penghentian pelanggan. Karena kami memiliki sedikit konteks tentang atribut ini, kami tidak memerlukan informasi latar belakang tentang himpunan data. Kami ingin memahami bagaimana atribut ini berkontribusi pada status Exited.
Dari 10.000 nasabah tersebut, hanya 2037 nasabah (sekitar 20%) yang meninggalkan bank. Karena rasio ketidakseimbangan kelas, kami merekomendasikan pembuatan data sintetis. Akurasi matriks kebingungan mungkin tidak memiliki relevansi untuk klasifikasi yang tidak seimbang. Kita mungkin ingin mengukur akurasi menggunakan Area Di bawah kurva Precision-Recall (AUPRC).
- Tabel ini memperlihatkan pratinjau data
churn.csv:
| ID Pelanggan | Nama keluarga | CreditScore | Geografi | Jenis kelamin | Umur | Kepemilikan | Keseimbangan | NumOfProducts | HasCrCard | ApakahAnggotaAktif | Gaji Perkiraan | Telah Keluar |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Prancis | Perempuan | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Bukit | 608 | Spanyol | Perempuan | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Mengunduh himpunan data dan mengunggah ke lakehouse
Tentukan parameter ini, sehingga Anda bisa menggunakan notebook ini dengan himpunan data yang berbeda:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Kode ini mengunduh versi himpunan data yang tersedia untuk umum, lalu menyimpan himpunan data tersebut di Fabric lakehouse:
Penting
Tambahkan lakehouse ke dalam buku catatan sebelum Anda menjalankannya. Kegagalan untuk melakukannya akan mengakibatkan kesalahan.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.z13.web.core.windows.net/data/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Mulai rekam waktu yang diperlukan untuk menjalankan buku catatan:
# Record the notebook running time
import time
ts = time.time()
Membaca data mentah dari lakehouse
Kode ini membaca data mentah dari bagian Files di lakehouse, dan menambahkan lebih banyak kolom untuk bagian-bagian tanggal yang berbeda. Pembuatan tabel delta yang dipartisi menggunakan informasi ini.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Membuat DataFrame pandas dari himpunan data
Kode ini mengonversi Spark DataFrame ke Pandas DataFrame, untuk pemrosesan dan visualisasi yang lebih mudah:
df = df.toPandas()
Langkah 3: Lakukan analisis data eksploratif
Menampilkan data mentah
Jelajahi data mentah dengan display, hitung beberapa statistik dasar, dan tampilkan tampilan bagan. Anda harus terlebih dahulu mengimpor pustaka yang diperlukan untuk visualisasi data - misalnya, seaborn. Seaborn adalah pustaka visualisasi data Python, dan menyediakan antarmuka tingkat tinggi untuk membangun visual pada dataframe dan array.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Menggunakan Data Wrangler untuk melakukan pembersihan data awal
Luncurkan Data Wrangler langsung dari notebook untuk menjelajahi dan mengubah dataframe panda. Pilih menu dropdown Data Wrangler dari toolbar horizontal untuk menelusuri DataFrame pandas yang telah diaktifkan dan tersedia untuk diedit. Pilih DataFrame yang ingin Anda buka di Data Wrangler.
Nota
Wrangler Data tidak dapat dibuka saat kernel notebook sibuk. Eksekusi sel harus selesai sebelum Anda membuka Data Wrangler. Pelajari selengkapnya tentang Data Wrangler.

Setelah Data Wrangler diluncurkan, gambaran umum deskriptif panel data dihasilkan, seperti yang ditunjukkan pada gambar berikut. Gambaran umum mencakup informasi tentang dimensi DataFrame, nilai yang hilang, dll. Anda dapat menggunakan Data Wrangler untuk menghasilkan skrip untuk menghilangkan baris dengan nilai yang hilang, baris duplikat, dan kolom dengan nama tertentu. Kemudian, Anda dapat menyalin skrip ke dalam sel. Sel berikutnya memperlihatkan skrip yang disalin.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Menentukan atribut
Kode ini menentukan atribut kategoris, numerik, dan target:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Perlihatkan ringkasan lima angka
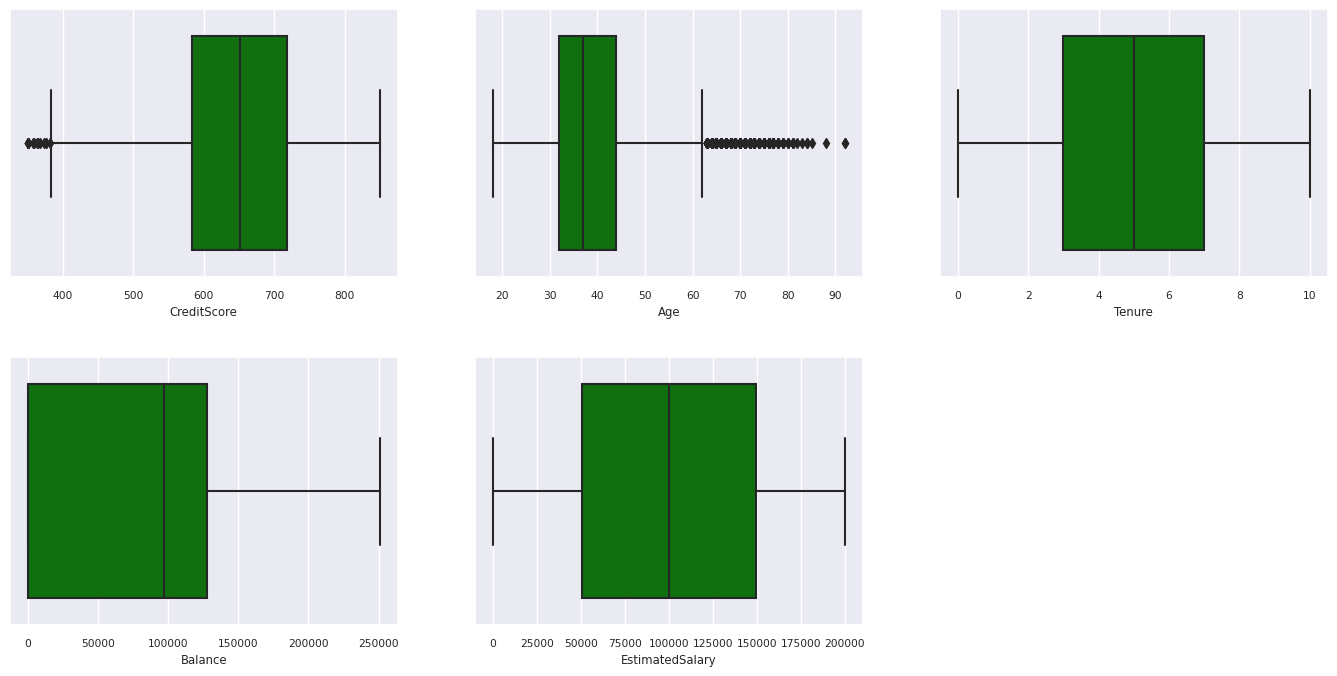
Gunakan plot kotak untuk memperlihatkan ringkasan lima angka
- nilai minimum
- kuartil pertama
- median
- kuartil ketiga
- skor maksimum
untuk atribut numerik.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
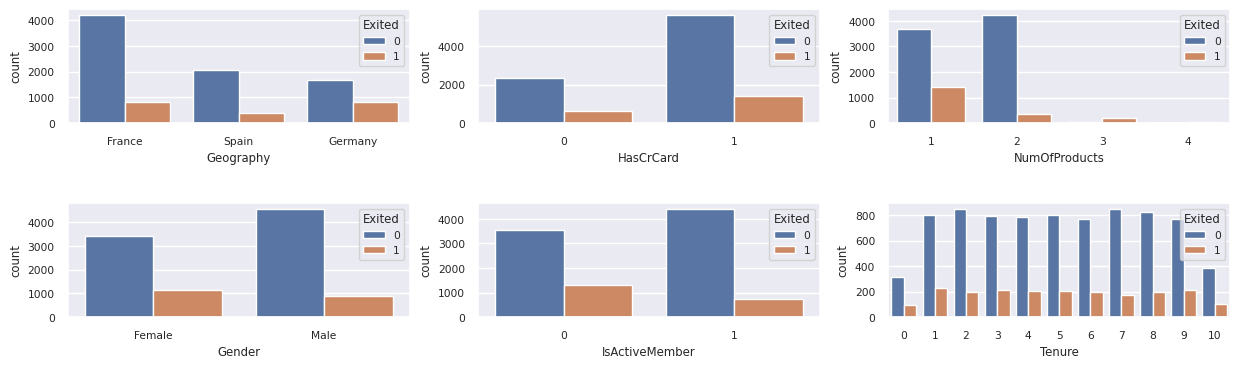
Menampilkan distribusi pelanggan yang keluar dan tidak keluar
Tampilkan distribusi pelanggan yang keluar versus pelanggan yang tidak keluar, di seluruh atribut kategoris:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
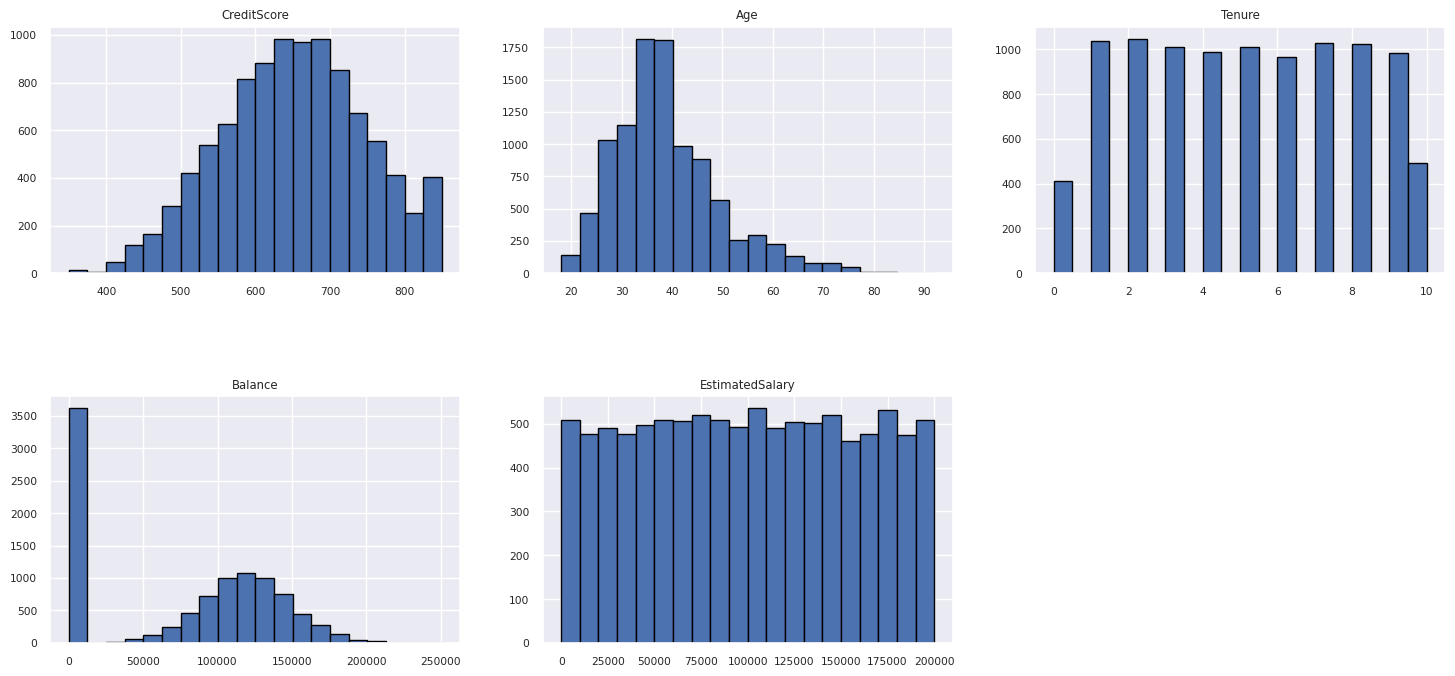
Menampilkan distribusi atribut numerik
Gunakan histogram untuk menunjukkan distribusi frekuensi atribut numerik:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Melakukan rekayasa fitur
Rekayasa fitur ini menghasilkan atribut baru berdasarkan atribut saat ini:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Menggunakan Data Wrangler untuk melakukan one-hot encoding
Dengan langkah-langkah yang sama untuk meluncurkan Data Wrangler, seperti yang dibahas sebelumnya, gunakan Data Wrangler untuk melakukan one-hot encoding. Sel ini menunjukkan skrip hasil salinan yang dihasilkan untuk pengkodean satu-hot.


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Membuat tabel delta untuk menghasilkan laporan Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Ringkasan pengamatan dari analisis data eksploratif
- Sebagian besar pelanggan berasal dari Prancis. Spanyol memiliki tingkat churn terendah, dibandingkan dengan Prancis dan Jerman.
- Sebagian besar pelanggan memiliki kartu kredit
- Beberapa pelanggan berusia di atas 60 tahun dan memiliki skor kredit di bawah 400. Namun, mereka tidak dapat dianggap sebagai outlier
- Sangat sedikit nasabah yang memiliki lebih dari dua produk bank
- Pelanggan yang tidak aktif memiliki tingkat churn yang lebih tinggi
- Gender dan masa jabatan berdampak kecil pada keputusan nasabah untuk menutup rekening bank
Langkah 4: Lakukan pelatihan dan pelacakan model
Dengan data di tempat, Anda sekarang dapat menentukan model. Terapkan model Random Forest dan LightGBM di notebook ini.
Gunakan pustaka scikit-learn dan LightGBM untuk mengimplementasikan model, dengan beberapa baris kode. Selain itu, gunakan MLfLow dan Fabric Autologging untuk melacak eksperimen.
Sampel kode ini memuat tabel delta dari sistem lakehouse. Anda dapat menggunakan tabel delta lain yang juga menggunakan lakehouse sebagai sumber.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Hasilkan eksperimen untuk melacak dan mencatat model dengan menggunakan MLflow
Bagian ini menunjukkan cara menghasilkan eksperimen, dan menentukan parameter model dan pelatihan serta metrik penilaian. Selain itu, ini menunjukkan cara melatih model, mencatatnya, dan menyimpan model terlatih untuk digunakan nanti.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Autologging secara otomatis mengambil nilai parameter input dan metrik output model pembelajaran mesin, saat model tersebut dilatih. Informasi ini kemudian dicatat ke ruang kerja Anda, di mana API MLflow atau eksperimen yang sesuai di ruang kerja Anda dapat mengakses dan memvisualisasikannya.
Setelah selesai, eksperimen Anda akan menyerupai gambar ini.

Semua eksperimen dengan nama masing-masing dicatat, dan Anda dapat melacak parameter dan metrik performanya. Untuk mempelajari selengkapnya tentang autologging, lihat Autologging di Microsoft Fabric.
Mengatur spesifikasi eksperimen dan autologging
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Impor scikit-learn dan LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Menyiapkan himpunan data pelatihan dan pengujian
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Menerapkan SMOTE ke data pelatihan
Klasifikasi yang tidak seimbang memiliki masalah, karena memiliki terlalu sedikit contoh kelas minoritas bagi model untuk mempelajari batas keputusan secara efektif. Untuk menangani hal ini, Synthetic Minority Oversampling Technique (SMOTE) adalah teknik yang paling banyak digunakan untuk mensintesis sampel baru untuk kelas minoritas. Akses SMOTE dengan pustaka imblearn yang Anda instal di langkah 1.
Terapkan SMOTE hanya ke himpunan data pelatihan. Anda harus meninggalkan himpunan data pengujian dalam distribusi aslinya yang tidak seimbang, untuk mendapatkan perkiraan performa model yang valid pada data asli. Eksperimen ini mewakili situasi dalam produksi.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Untuk informasi selengkapnya, lihat SMOTE dan Dari pengambilan sampel berlebih secara acak ke SMOTE dan ADASYN. Situs web imbalanced-learn menghosting sumber daya ini.
Melatih model
Gunakan Random Forest untuk melatih model, dengan kedalaman maksimum empat, dan dengan empat fitur:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Gunakan Random Forest untuk melatih model, dengan kedalaman maksimum delapan, dan dengan enam fitur:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Latih model dengan LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Melihat artefak eksperimen untuk melacak performa model
Jalannya eksperimen secara otomatis disimpan dalam artefak eksperimen. Anda dapat menemukan artefak tersebut di ruang kerja. Nama artefak didasarkan pada nama yang digunakan untuk mengatur eksperimen. Semua model terlatih, eksekusinya, metrik performa, dan parameter model dicatat di halaman eksperimen.
Untuk melihat eksperimen Anda:
- Di panel kiri, pilih ruang kerja Anda.
- Temukan dan pilih nama eksperimen, dalam hal ini, sample-bank-churn-experiment.
Langkah 5: Mengevaluasi dan menyimpan model pembelajaran mesin akhir
Buka eksperimen yang disimpan dari ruang kerja untuk memilih dan menyimpan model terbaik:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Menilai performa model yang disimpan pada himpunan data pengujian
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Menampilkan positif/negatif true/false dengan menggunakan matriks kebingungan
Untuk mengevaluasi akurasi klasifikasi, buat skrip yang memplot matriks kebingungan. Anda juga dapat merencanakan matriks kebingungan menggunakan alat SynapseML, seperti yang ditunjukkan dalam sampel Deteksi Penipuan .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
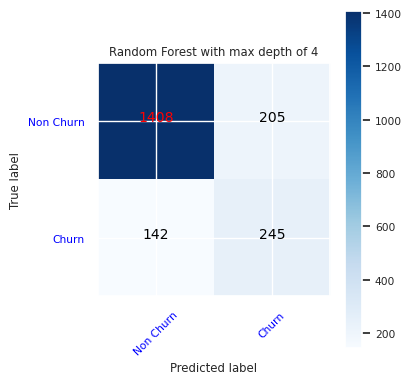
Buat matriks kebingungan untuk pengklasifikasi hutan acak, dengan kedalaman maksimum empat, menggunakan empat fitur.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
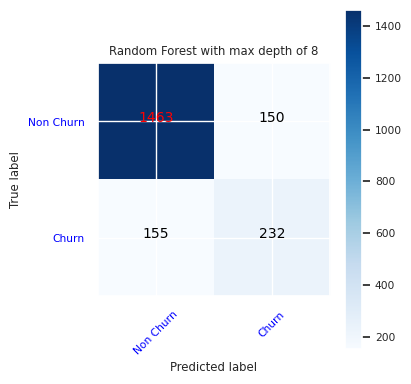
Buat matriks kebingungan untuk pengklasifikasi hutan acak dengan kedalaman maksimum delapan, dengan enam fitur.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
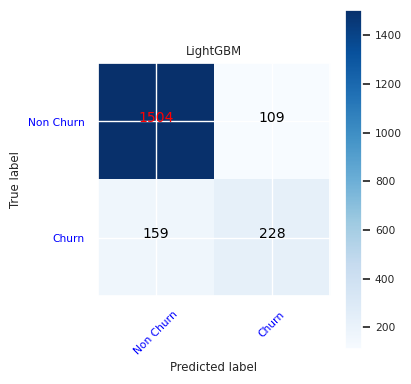
Buat matriks kebingungan untuk LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Menyimpan hasil untuk Power BI
Simpan kerangka delta ke lakehouse, dalam rangka memindahkan hasil-hasil prediksi model ke dalam visualisasi Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Langkah 6: Visualisasi akses di Power BI
Akses tabel tersimpan Anda di Power BI:
- Di sebelah kiri, pilih OneLake.
- Pilih lakehouse yang Anda tambahkan ke buku catatan ini.
- Di bagian Buka Lakehouse ini, pilih Buka.
- Pada pita, pilih Model semantik baru. Pilih
df_pred_results, lalu pilih Konfirmasi untuk membuat model semantik Power BI baru yang ditautkan ke prediksi. - Buka model semantik baru. Anda dapat menemukannya di OneLake.
- Pilih Buat Laporan baru di bawah file dari alat di bagian atas halaman model semantik, untuk membuka halaman penulisan laporan Power BI.
Cuplikan layar berikut menunjukkan beberapa contoh visualisasi. Panel data memperlihatkan tabel dan kolom delta untuk dipilih dari tabel. Setelah pemilihan kategori (x) dan nilai (y) sumbu yang sesuai, Anda dapat memilih filter dan fungsi - misalnya, jumlah atau rata-rata kolom tabel.
Nota
Dalam cuplikan layar ini, contoh yang diilustrasikan menjelaskan analisis hasil prediksi yang disimpan di Power BI:

Namun, untuk kasus nyata churn pelanggan, pengguna mungkin memerlukan serangkaian persyaratan visualisasi yang lebih menyeluruh untuk dibuat, berdasarkan keahlian subjek, dan apa yang telah distandardisasi sebagai metrik oleh tim analitik bisnis dan perusahaan.
Laporan Power BI menunjukkan bahwa pelanggan yang menggunakan lebih dari dua produk bank memiliki tingkat churn yang lebih tinggi. Namun, beberapa pelanggan memiliki lebih dari dua produk. (Lihat plot di panel kiri bawah.) Bank harus mengumpulkan lebih banyak data, tetapi juga harus menyelidiki fitur lain yang berkorelasi dengan lebih banyak produk.
Nasabah bank di Jerman memiliki tingkat churn yang lebih tinggi dibandingkan dengan nasabah di Prancis dan Spanyol. (Lihat plot di panel kanan bawah). Berdasarkan hasil laporan, penyelidikan terhadap faktor-faktor yang mendorong pelanggan untuk pergi mungkin membantu.
Ada lebih banyak pelanggan paruh baya (antara 25 dan 45). Pelanggan antara 45 dan 60 cenderung keluar lebih banyak.
Akhirnya, pelanggan dengan skor kredit yang lebih rendah kemungkinan besar akan meninggalkan bank untuk lembaga keuangan lainnya. Bank harus mengeksplorasi cara-cara untuk mendorong nasabah dengan skor kredit yang lebih rendah dan saldo rekening untuk tetap berada di bank.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")