Tutorial: membuat, mengevaluasi, dan menilai model deteksi kesalahan mesin
Tutorial ini menyajikan contoh end-to-end dari alur kerja Ilmu Data Synapse di Microsoft Fabric. Skenario ini menggunakan pembelajaran mesin untuk pendekatan yang lebih sistematis untuk diagnosis kesalahan, untuk secara proaktif mengidentifikasi masalah dan mengambil tindakan sebelum kegagalan mesin yang sebenarnya. Tujuannya adalah untuk memprediksi apakah mesin akan mengalami kegagalan berdasarkan suhu proses, kecepatan rotasi, dll.
Tutorial ini mencakup langkah-langkah berikut:
- Menginstal pustaka kustom
- Memuat dan memproses data
- Memahami data melalui analisis data eksploratif
- Gunakan scikit-learn, LightGBM, dan MLflow untuk melatih model pembelajaran mesin, dan menggunakan fitur Fabric Autologging untuk melacak eksperimen
- Menilai model terlatih dengan fitur Fabric
PREDICT, menyimpan model terbaik, dan memuat model tersebut untuk prediksi - Memperlihatkan performa model yang dimuat dengan visualisasi Power BI
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Gunakan pengalih pengalaman di sisi kiri halaman beranda Anda untuk beralih ke pengalaman Ilmu Data Synapse.

- Jika perlu, buat Microsoft Fabric lakehouse seperti yang dijelaskan dalam Membuat lakehouse di Microsoft Fabric.
Ikuti di buku catatan
Anda bisa memilih salah satu opsi ini untuk diikuti dalam buku catatan:
- Buka dan jalankan buku catatan bawaan dalam pengalaman Ilmu Data
- Unggah buku catatan Anda dari GitHub ke pengalaman Ilmu Data
Buka buku catatan bawaan
Contoh notebook kegagalan Mesin menyertai tutorial ini.
Untuk membuka buku catatan sampel bawaan tutorial dalam pengalaman Ilmu Data Synapse:
Buka halaman beranda Synapse Ilmu Data.
Pilih Gunakan sampel.
Pilih sampel yang sesuai:
- Dari tab Alur kerja end-to-end (Python) default, jika sampelnya adalah untuk tutorial Python.
- Dari tab Alur kerja end-to-end (R), jika sampelnya adalah untuk tutorial R.
- Dari tab Tutorial cepat, jika sampel adalah untuk tutorial cepat.
Lampirkan lakehouse ke buku catatan sebelum Anda mulai menjalankan kode.
Mengimpor notebook dari GitHub
Notebook AISample - Pemeliharaan Prediktif menyertai tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi dalam Menyiapkan sistem Anda untuk tutorial ilmu data, untuk mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk melampirkan lakehouse ke buku catatan sebelum Anda mulai menjalankan kode.
Langkah 1: Menginstal pustaka kustom
Untuk pengembangan model pembelajaran mesin atau analisis data ad-hoc, Anda mungkin perlu menginstal pustaka kustom dengan cepat untuk sesi Apache Spark Anda. Anda memiliki dua opsi untuk menginstal pustaka.
- Gunakan kemampuan penginstalan sebaris (
%pipatau%conda) buku catatan Anda untuk menginstal pustaka, hanya di buku catatan Anda saat ini. - Atau, Anda dapat membuat lingkungan Fabric, menginstal pustaka dari sumber publik atau mengunggah pustaka kustom ke dalamnya, dan kemudian admin ruang kerja Anda dapat melampirkan lingkungan sebagai default untuk ruang kerja. Semua pustaka di lingkungan kemudian akan tersedia untuk digunakan dalam notebook dan definisi pekerjaan Spark di ruang kerja. Untuk informasi selengkapnya tentang lingkungan, lihat membuat, mengonfigurasi, dan menggunakan lingkungan di Microsoft Fabric.
Untuk tutorial ini, gunakan %pip install untuk menginstal imblearn pustaka di buku catatan Anda.
Catatan
Kernel PySpark dimulai ulang setelah %pip install dijalankan. Instal pustaka yang diperlukan sebelum Anda menjalankan sel lain.
# Use pip to install imblearn
%pip install imblearn
Langkah 2: Muat data
Himpunan data mensimulasikan pengelogan parameter mesin manufaktur sebagai fungsi waktu, yang umum dalam pengaturan industri. Ini terdiri dari 10.000 titik data yang disimpan sebagai baris dengan fitur sebagai kolom. Fitur-fitur tersebut meliputi:
Pengidentifikasi Unik (UID) yang berkisar antara 1 hingga 10000
ID produk, terdiri dari huruf L (untuk rendah), M (untuk sedang), atau H (tinggi), untuk menunjukkan varian kualitas produk, dan nomor seri khusus varian. Varian rendah, sedang, dan berkualitas tinggi masing-masing terdiri dari 60%, 30%, dan 10% dari semua produk
Suhu udara, dalam derajat Kelvin (K)
Suhu Proses, dalam derajat Kelvin
Kecepatan Rotasi, dalam revolusi per menit (RPM)
Torsi, di Newton-Meters (Nm)
Alat keausan, dalam hitung menit. Varian kualitas H, M, dan L menambahkan masing-masing 5, 3, dan 2 menit alat ke alat yang digunakan dalam proses
Label Kegagalan Mesin, untuk menunjukkan apakah komputer gagal dalam titik data tertentu. Titik data khusus ini dapat memiliki salah satu dari lima mode kegagalan independen berikut:
- Tool Wear Failure (TWF): alat ini diganti atau gagal pada waktu keausan alat yang dipilih secara acak, antara 200 dan 240 menit
- Kegagalan Disipasi Panas (HDF): disipasi panas menyebabkan kegagalan proses jika perbedaan antara suhu udara dan suhu proses kurang dari 8,6 K, dan kecepatan rotasi alat kurang dari 1380 RPM
- Power Failure (PWF): produk torsi dan kecepatan rotasi (dalam rad/dtk) sama dengan daya yang diperlukan untuk proses. Proses gagal jika daya ini berada di bawah 3.500 W atau melebihi 9.000 W
- Kegagalan OverStrain (OSF): jika produk keausan alat dan torsi melebihi 11.000 Nm minimum untuk varian produk L (12.000 untuk M, 13.000 untuk H), proses gagal karena overstrain
- Kegagalan Acak (RNF): setiap proses memiliki peluang kegagalan 0,1%, terlepas dari parameter prosesnya
Catatan
Jika setidaknya salah satu mode kegagalan di atas benar, proses gagal, dan label "kegagalan mesin" diatur ke 1. Metode pembelajaran mesin tidak dapat menentukan mode kegagalan mana yang menyebabkan kegagalan proses.
Mengunduh himpunan data dan mengunggah ke lakehouse
Koneksi ke kontainer Azure Open Datasets, dan muat himpunan data Pemeliharaan Prediktif. Kode ini mengunduh versi himpunan data yang tersedia untuk umum, lalu menyimpannya di Fabric lakehouse:
Penting
Tambahkan lakehouse ke buku catatan sebelum Anda menjalankannya. Jika tidak, Anda akan mendapatkan kesalahan. Untuk informasi tentang menambahkan lakehouse, lihat Koneksi lakehouse dan notebook.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Setelah mengunduh himpunan data ke lakehouse, Anda dapat memuatnya sebagai Spark DataFrame:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
Tabel ini memperlihatkan pratinjau data:
| UDI | ID Produk | Jenis | Suhu udara [K] | Suhu proses [K] | Kecepatan rotasi [rpm] | Torsi [Nm] | Keausan alat [min] | Target | Jenis Kegagalan |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298,1 | 308,6 | 1551 | 42,8 | 0 | 0 | Tidak Ada Kegagalan |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Tidak Ada Kegagalan |
| 3 | L47182 | L | 298,1 | 308.5 | 1498 | 49.4 | 5 | 0 | Tidak Ada Kegagalan |
| 4 | L47183 | L | 298.2 | 308,6 | 1433 | 39,5 | 7 | 0 | Tidak Ada Kegagalan |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Tidak Ada Kegagalan |
Menulis Spark DataFrame ke tabel delta lakehouse
Format data (misalnya, ganti spasi dengan garis bawah) untuk memfasilitasi operasi Spark dalam langkah-langkah berikutnya:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
Tabel ini memperlihatkan pratinjau data dengan nama kolom yang diformat ulang:
| UDI | Product_ID | Jenis | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Target | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298,1 | 308,6 | 1551 | 42,8 | 0 | 0 | Tidak Ada Kegagalan |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Tidak Ada Kegagalan |
| 3 | L47182 | L | 298,1 | 308.5 | 1498 | 49.4 | 5 | 0 | Tidak Ada Kegagalan |
| 4 | L47183 | L | 298.2 | 308,6 | 1433 | 39,5 | 7 | 0 | Tidak Ada Kegagalan |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | Tidak Ada Kegagalan |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Langkah 3: Praproses data dan lakukan analisis data eksploratif
Konversikan Spark DataFrame menjadi pandas DataFrame, untuk menggunakan pustaka plotting populer yang kompatibel dengan Pandas.
Tip
Untuk himpunan data besar, Anda mungkin perlu memuat sebagian himpunan data tersebut.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Mengonversi kolom tertentu dari himpunan data menjadi float atau jenis bilangan bulat sesuai kebutuhan, dan memetakan string ('L', , 'M''H') ke nilai numerik (0, 1, 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Menjelajahi data melalui visualisasi
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
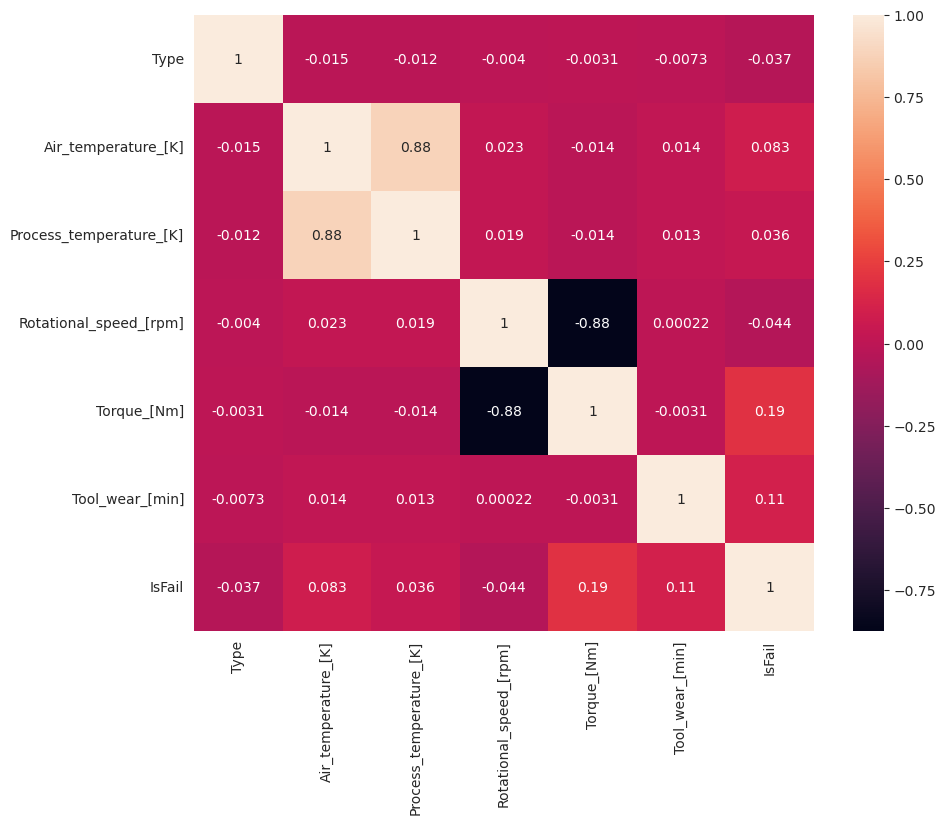
Seperti yang diharapkan, kegagalan (IsFail) berkorelasi dengan fitur (kolom) yang dipilih. Matriks korelasi menunjukkan bahwa Air_temperature, , Process_temperatureRotational_speed, Torque, dan Tool_wear memiliki korelasi tertinggi dengan IsFail variabel .
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
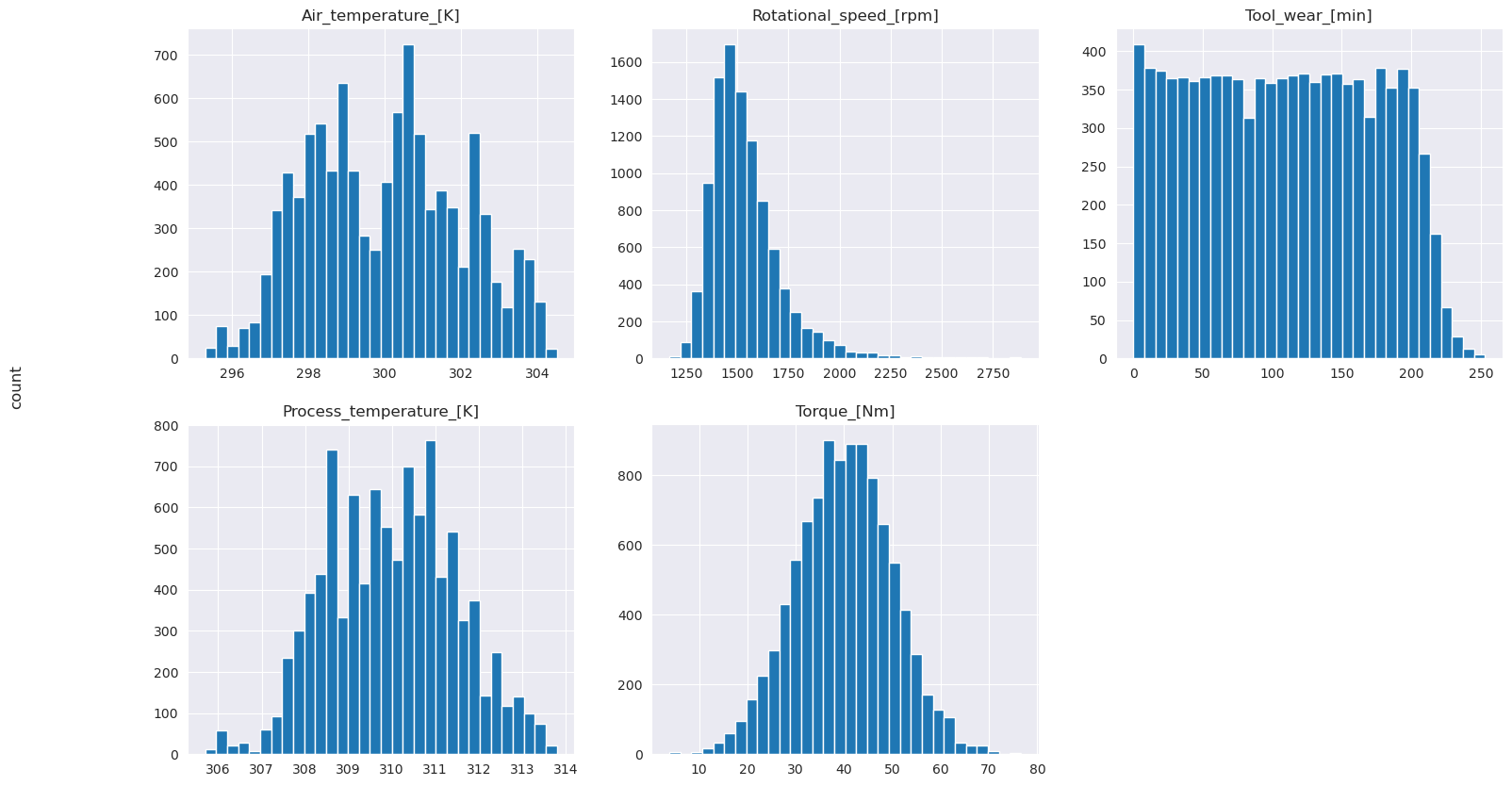
Seperti yang ditunjukkan grafik yang diplot, Air_temperaturevariabel , , Process_temperatureRotational_speed, Torque, dan Tool_wear tidak jarang. Mereka tampaknya memiliki kelangsungan yang baik di ruang fitur. Plot ini mengonfirmasi bahwa melatih model pembelajaran mesin pada himpunan data ini kemungkinan menghasilkan hasil yang andal yang dapat digeneralisasi ke himpunan data baru.
Memeriksa variabel target untuk ketidakseimbangan kelas
Hitung jumlah sampel untuk komputer yang gagal dan tidak jatuh, dan periksa keseimbangan data untuk setiap kelas (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
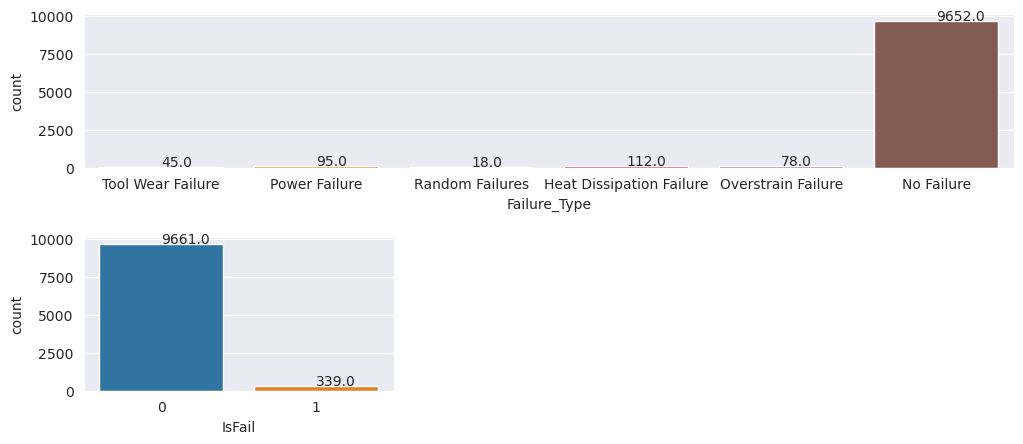
Plot menunjukkan bahwa kelas tanpa kegagalan (ditampilkan seperti IsFail=0 di plot kedua) merupakan sebagian besar sampel. Gunakan teknik pengambilan sampel berlebih untuk membuat himpunan data pelatihan yang lebih seimbang:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Oversample untuk menyeimbangkan kelas dalam himpunan data pelatihan
Analisis sebelumnya menunjukkan bahwa himpunan data sangat tidak seimbang. Ketidakseimbangan itu menjadi masalah, karena kelas minoritas memiliki terlalu sedikit contoh bagi model untuk mempelajari batas keputusan secara efektif.
SMOTE dapat menyelesaikan masalah. SMOTE adalah teknik pengambilan sampel berlebih yang banyak digunakan yang menghasilkan contoh sintetis. Ini menghasilkan contoh untuk kelas minoritas berdasarkan jarak Euclidian antara titik data. Metode ini berbeda dari pengambilan sampel berlebih acak, karena membuat contoh baru yang tidak hanya menduplikasi kelas minoritas. Metode ini menjadi teknik yang lebih efektif untuk menangani himpunan data yang tidak seimbang.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
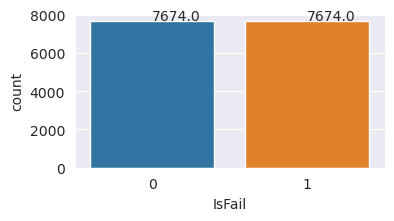
Anda berhasil menyeimbangkan himpunan data. Anda sekarang dapat pindah ke pelatihan model.
Langkah 4: Melatih dan mengevaluasi model
MLflow mendaftarkan model, melatih, dan membandingkan berbagai model, dan memilih model terbaik untuk tujuan prediksi. Anda dapat menggunakan tiga model berikut untuk pelatihan model:
- Penggolak hutan acak
- Pengklasifikasi regresi logistik
- Pengklasifikasi XGBoost
Melatih pengklasifikasi hutan acak
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
Dari output, himpunan data pelatihan dan pengujian menghasilkan skor F1, akurasi, dan pengenalan sekitar 0,9 saat menggunakan pengklasifikasi forest acak.
Melatih pengklasifikasi regresi logistik
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Melatih pengklasifikasi XGBoost
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Langkah 5: Pilih model terbaik dan prediksi output
Di bagian sebelumnya, Anda melatih tiga pengklasifikasi yang berbeda: forest acak, regresi logistik, dan XGBoost. Anda sekarang memiliki pilihan untuk mengakses hasil secara terprogram, atau menggunakan antarmuka pengguna (UI).
Untuk opsi jalur UI, navigasikan ke ruang kerja Anda dan filter model.
Pilih model individual untuk detail performa model.
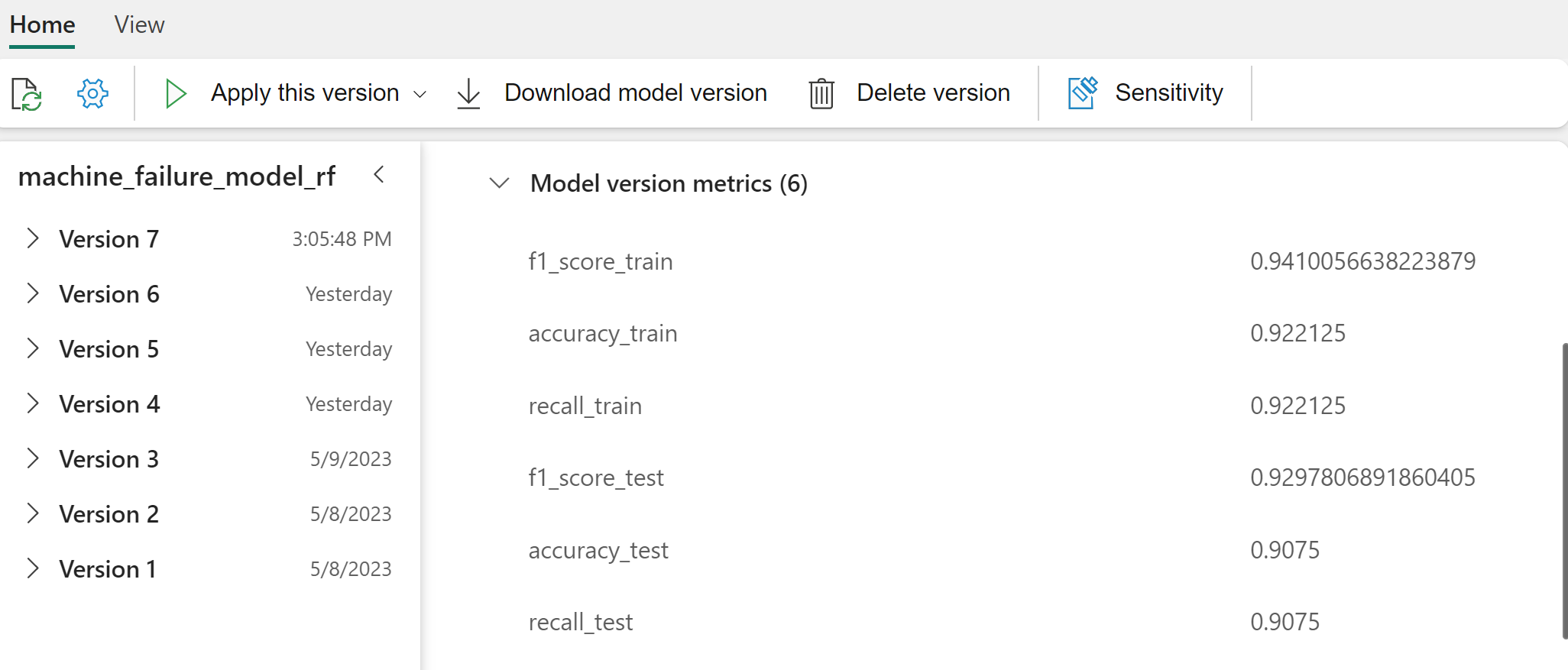
Contoh ini menunjukkan cara mengakses model secara terprogram melalui MLflow:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Meskipun XGBoost memberikan hasil terbaik pada set pelatihan, XGBoost berkinerja buruk pada himpunan data pengujian. Performa buruk itu menunjukkan terlalu pas. Pengklasifikasi regresi logistik berkinerja buruk pada himpunan data pelatihan dan pengujian. Secara keseluruhan, hutan acak mencapai keseimbangan yang baik antara performa pelatihan dan menghindari overfitting.
Di bagian berikutnya, pilih model forest acak terdaftar, dan lakukan prediksi dengan fitur PREDICT :
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
Dengan objek yang MLFlowTransformer Anda buat untuk memuat model untuk inferensi, gunakan Transformer API untuk menilai model pada himpunan data pengujian:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
Tabel ini memperlihatkan output:
| Jenis | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Prediksi |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36,8 | 140,0 | 0 |
| 1 | 299.1 | 308,6 | 1491.0 | 38,5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24,0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308,2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41,5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298,4 | 307.9 | 1981.0 | 23.2 | 16,0 | 0 |
| 0 | 299,3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298,1 | 309.2 | 1460.0 | 45.8 | 80,0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26.0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48,0 | 9.0 | 0 |
Simpan data ke lakehouse. Data kemudian tersedia untuk digunakan nanti - misalnya, dasbor Power BI.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Langkah 6: Menampilkan kecerdasan bisnis melalui visualisasi di Power BI
Perlihatkan hasil dalam format offline, dengan dasbor Power BI.
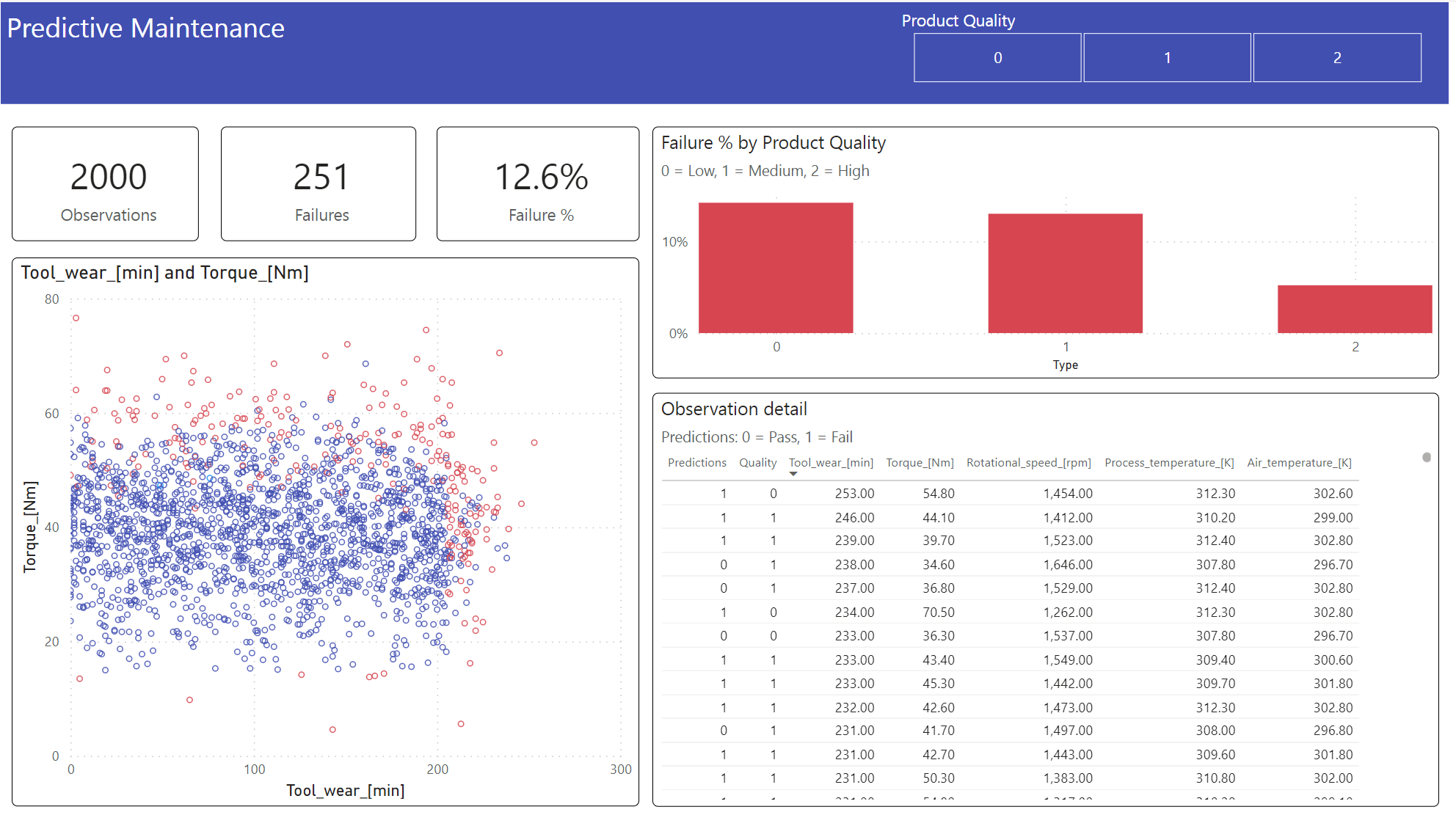
Dasbor menunjukkan bahwa dan Torque membuat batas yang terlihat antara kasus yang gagal dan tidak jatuh, seperti yang Tool_wear diharapkan dari analisis korelasi sebelumnya di langkah 2.
Konten terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk