Mengembangkan, mengevaluasi, dan menilai model prakiraan untuk penjualan superstore
Tutorial ini menyajikan contoh end-to-end dari alur kerja Ilmu Data Synapse di Microsoft Fabric. Skenario ini membangun model prakiraan yang menggunakan data penjualan historis untuk memprediksi penjualan kategori produk di superstore.
Prakiraan adalah aset penting dalam penjualan. Ini menggabungkan data historis dan metode prediktif untuk memberikan wawasan tentang tren di masa depan. Prakiraan dapat menganalisis penjualan sebelumnya untuk mengidentifikasi pola, dan belajar dari perilaku konsumen untuk mengoptimalkan inventarisasi, produksi, dan strategi pemasaran. Pendekatan proaktif ini meningkatkan kemampuan beradaptasi, responsivitas, dan performa bisnis secara keseluruhan di marketplace dinamis.
Tutorial ini mencakup langkah-langkah berikut:
- Muat data
- Menggunakan analisis data eksploratif untuk memahami dan memproses data
- Melatih model pembelajaran mesin dengan paket perangkat lunak sumber terbuka, dan melacak eksperimen dengan MLflow dan fitur autologging Fabric
- Simpan model pembelajaran mesin akhir, dan buat prediksi
- Memperlihatkan performa model dengan visualisasi Power BI
Prasyarat
Dapatkan langganan Microsoft Fabric. Atau, daftar untuk uji coba Microsoft Fabric gratis.
Masuk ke Microsoft Fabric.
Gunakan pengalih pengalaman di sisi kiri halaman beranda Anda untuk beralih ke pengalaman Ilmu Data Synapse.

- Jika perlu, buat Microsoft Fabric lakehouse seperti yang dijelaskan dalam Membuat lakehouse di Microsoft Fabric.
Ikuti di buku catatan
Anda bisa memilih salah satu opsi ini untuk diikuti dalam buku catatan:
- Buka dan jalankan notebook bawaan dalam pengalaman Ilmu Data Synapse
- Unggah buku catatan Anda dari GitHub ke pengalaman Ilmu Data Synapse
Buka buku catatan bawaan
Contoh notebook prakiraan penjualan menyertai tutorial ini.
Untuk membuka buku catatan sampel bawaan tutorial dalam pengalaman Ilmu Data Synapse:
Buka halaman beranda Synapse Ilmu Data.
Pilih Gunakan sampel.
Pilih sampel yang sesuai:
- Dari tab Alur kerja end-to-end (Python) default, jika sampelnya adalah untuk tutorial Python.
- Dari tab Alur kerja end-to-end (R), jika sampelnya adalah untuk tutorial R.
- Dari tab Tutorial cepat, jika sampel adalah untuk tutorial cepat.
Lampirkan lakehouse ke buku catatan sebelum Anda mulai menjalankan kode.
Mengimpor notebook dari GitHub
Notebook AIsample - Superstore Forecast.ipynb menyertai tutorial ini.
Untuk membuka buku catatan yang menyertai tutorial ini, ikuti instruksi dalam Menyiapkan sistem Anda untuk tutorial ilmu data, untuk mengimpor buku catatan ke ruang kerja Anda.
Jika Anda lebih suka menyalin dan menempelkan kode dari halaman ini, Anda bisa membuat buku catatan baru.
Pastikan untuk melampirkan lakehouse ke buku catatan sebelum Anda mulai menjalankan kode.
Langkah 1: Muat data
Himpunan data berisi 9.995 instans penjualan berbagai produk. Ini juga mencakup 21 atribut. Tabel ini berasal dari file Superstore.xlsx yang digunakan dalam buku catatan ini:
| ID baris | ID Pesanan | Tanggal Pesanan | Tanggal Pengiriman | Mode Pengiriman | ID Pelanggan | Nama Pelanggan | Segmen | Negara | Kota | Provinsi | Kode Pos | Wilayah | ID Produk | Category | Sub-Kategori | Nama Produk | Penjualan | Quantity | Discount | Keuntungan |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Kelas Standar | SO-20335 | Sean O'Donnell | Konsumen | Amerika Serikat | Fort Lauderdale | Florida | 33311 | Selatan | FUR-TA-10000577 | Mebel | Tabel | Bretford CR4500 Series Slim Rectangular Table | 957.5775 | 5 | 0,45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Kelas Standar | Kelas Standar | Brosina Hoffman | Konsumen | Amerika Serikat | Los Angeles | California | 90032 | Barat | FUR-TA-10001539 | Mebel | Tabel | Tabel Konferensi Persegi Panjang Kromcraft | 1706.184 | 9 | 0,2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Kelas Standar | TB-21520 | Tracy Blumstein | Konsumen | Amerika Serikat | Philadelphia | Pennsylvania | 19140 | Timur | OFF-EN-10001509 | Perlengkapan Kantor | Amplop | Amplop Dasi String Poli | 3.264 | 2 | 0,2 | 1.1016 |
Tentukan parameter ini, sehingga Anda bisa menggunakan notebook ini dengan himpunan data yang berbeda:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Mengunduh himpunan data dan mengunggah ke lakehouse
Kode ini mengunduh versi himpunan data yang tersedia untuk umum, lalu menyimpannya di Fabric lakehouse:
Penting
Pastikan untuk menambahkan lakehouse ke buku catatan sebelum Anda menjalankannya. Jika tidak, Anda akan mendapatkan kesalahan.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Menyiapkan pelacakan eksperimen MLflow
Microsoft Fabric secara otomatis menangkap nilai parameter input dan metrik output model pembelajaran mesin saat Anda melatihnya. Ini memperluas kemampuan autologging MLflow. Informasi kemudian dicatat ke ruang kerja, di mana Anda dapat mengakses dan memvisualisasikannya dengan API MLflow atau eksperimen yang sesuai di ruang kerja. Untuk mempelajari selengkapnya tentang autologging, lihat Autologging di Microsoft Fabric.
Untuk menonaktifkan autologging Microsoft Fabric dalam sesi notebook, panggil mlflow.autolog() dan atur disable=True:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Membaca data mentah dari lakehouse
Baca data mentah dari bagian File di lakehouse. Tambahkan lebih banyak kolom untuk bagian tanggal yang berbeda. Informasi yang sama digunakan untuk membuat tabel delta yang dipartisi. Karena data mentah disimpan sebagai file Excel, Anda harus menggunakan panda untuk membacanya:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Langkah 2: Lakukan analisis data eksploratif
Mengimpor pustaka
Sebelum analisis apa pun, impor pustaka yang diperlukan:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Menampilkan data mentah
Tinjau subset data secara manual, untuk lebih memahami himpunan data itu display sendiri, dan gunakan fungsi untuk mencetak DataFrame. Selain itu, Chart tampilan dapat dengan mudah memvisualisasikan subset himpunan data.
display(df)
Notebook ini terutama berfokus pada prakiraan Furniture penjualan kategori. Ini mempercepat komputasi, dan membantu menunjukkan performa model. Namun, notebook ini menggunakan teknik yang dapat disesuaikan. Anda dapat memperluas teknik tersebut untuk memprediksi penjualan kategori produk lainnya.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Prapemroscesan data
Skenario bisnis dunia nyata sering kali perlu memprediksi penjualan dalam tiga kategori yang berbeda:
- Kategori produk tertentu
- Kategori pelanggan tertentu
- Kombinasi khusus kategori produk dan kategori pelanggan
Pertama, hilangkan kolom yang tidak perlu untuk melakukan praproses data. Beberapa kolom (Row ID, Order ID,Customer ID, dan Customer Name) tidak perlu karena tidak berdampak. Kami ingin memperkirakan penjualan keseluruhan, di seluruh negara bagian dan wilayah, untuk kategori produk tertentu (Furniture), sehingga kita dapat menghilangkan Statekolom , , RegionCountry, City, dan Postal Code . Untuk memperkirakan penjualan untuk lokasi atau kategori tertentu, Anda mungkin perlu menyesuaikan langkah pra-pemrosesan yang sesuai.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Himpunan data disusun setiap hari. Kita harus mengambil sampel ulang pada kolom Order Date, karena kita ingin mengembangkan model untuk memperkirakan penjualan setiap bulan.
Pertama, kelompokkan Furniture kategori menurut Order Date. Kemudian, hitung jumlah Sales kolom untuk setiap grup, untuk menentukan total penjualan untuk setiap nilai unik Order Date . Buat ulang Sales kolom dengan MS frekuensi, untuk mengagregasi data menurut bulan. Terakhir, hitung nilai rata-rata penjualan untuk setiap bulan.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Menunjukkan dampak pada Order Date Sales untuk Furniture kategori:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Sebelum analisis statistik apa pun, Anda harus mengimpor statsmodels modul Python. Ini menyediakan kelas dan fungsi untuk estimasi banyak model statistik. Ini juga menyediakan kelas dan fungsi untuk melakukan pengujian statistik dan eksplorasi data statistik.
import statsmodels.api as sm
Melakukan analisis statistik
Rangkaian waktu melacak elemen data ini pada interval yang ditetapkan, untuk menentukan variasi elemen tersebut dalam pola rangkaian waktu:
Tingkat: Komponen dasar yang mewakili nilai rata-rata untuk periode waktu tertentu
Tren: Menjelaskan apakah rangkaian waktu berkurang, tetap konstan, atau meningkat dari waktu ke waktu
Musiman: Menjelaskan sinyal berkala dalam rangkaian waktu, dan mencari kejadian siklik yang berdampak pada meningkat atau menurunnya pola rangkaian waktu
Kebisingan/Residu: Mengacu pada fluktuasi dan varianbilitas acak dalam data rangkaian waktu yang tidak dapat dijelaskan model.
Dalam kode ini, Anda mengamati elemen-elemen tersebut untuk himpunan data Anda setelah pra-pemrosesan:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
Plot menggambarkan musiman, tren, dan kebisingan dalam data prakiraan. Anda dapat menangkap pola yang mendasar, dan mengembangkan model yang membuat prediksi akurat yang tahan terhadap fluktuasi acak.
Langkah 3: Melatih dan melacak model
Sekarang setelah Anda memiliki data yang tersedia, tentukan model prakiraan. Dalam buku catatan ini, terapkan model prakiraan yang disebut rata-rata bergerak terintegrasi otomatis musiman dengan faktor eksogen (SARIMAX). SARIMAX menggabungkan komponen autoregressive (AR) dan moving average (MA), perbedaan musiman, dan prediktor eksternal untuk membuat perkiraan yang akurat dan fleksibel untuk data rangkaian waktu.
Anda juga menggunakan autologging MLflow dan Fabric untuk melacak eksperimen. Di sini, muat meja delta dari lakehouse. Anda mungkin menggunakan tabel delta lain yang menganggap lakehouse sebagai sumbernya.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Sesuaikan hyperparameter
SARIMAX memperhitungkan parameter yang terlibat dalam mode regular autoregressive integrated moving average (ARIMA) (p, d, q), dan menambahkan parameter musiman (P, , DQ, s). Argumen model SARIMAX ini disebut urutan (p, , dq) dan urutan musiman (P, , DQ, s), masing-masing. Oleh karena itu, untuk melatih model, kita harus terlebih dahulu menyetel tujuh parameter.
Parameter pesanan:
p: Urutan komponen AR, mewakili jumlah pengamatan sebelumnya dalam rangkaian waktu yang digunakan untuk memprediksi nilai saat ini.Biasanya, parameter ini harus berupa bilangan bulat non-negatif. Nilai umum berada dalam rentang
0hingga3, meskipun nilai yang lebih tinggi dimungkinkan, tergantung pada karakteristik data tertentu. Nilai yang lebih tinggipmenunjukkan memori nilai sebelumnya yang lebih panjang dalam model.d: Urutan yang berbeda, mewakili berapa kali rangkaian waktu perlu dibedakan, untuk mencapai stasioneritas.Parameter ini harus berupa bilangan bulat non-negatif. Nilai umum berada dalam rentang
0hingga2. Nilaidberarti rangkaian0waktu sudah stasioner. Nilai yang lebih tinggi menunjukkan jumlah operasi yang berbeda yang diperlukan untuk membuatnya stasioner.q: Urutan komponen MA, mewakili jumlah istilah kesalahan white-noise sebelumnya yang digunakan untuk memprediksi nilai saat ini.Parameter ini harus berupa bilangan bulat non-negatif. Nilai umum berada dalam rentang
0hingga3, tetapi nilai yang lebih tinggi mungkin diperlukan untuk rangkaian waktu tertentu. Nilai yang lebih tinggiqmenunjukkan keandalan yang lebih kuat pada istilah kesalahan sebelumnya untuk membuat prediksi.
Parameter urutan musiman:
P: Urutan musiman komponen AR, mirippdengan tetapi untuk bagian musimanD: Urutan musiman berbeda, miripddengan tetapi untuk bagian musimanQ: Urutan musiman komponen MA, miripqdengan tetapi untuk bagian musimans: Jumlah langkah waktu per siklus musiman (misalnya, 12 untuk data bulanan dengan musiman tahunan)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX memiliki parameter lain:
enforce_stationarity: Apakah model harus memberlakukan stasioneritas pada data rangkaian waktu atau tidak, sebelum menyesuaikan model SARIMAX.Jika
enforce_stationaritydiatur keTrue(default), ini menunjukkan bahwa model SARIMAX harus memberlakukan stasioneritas pada data rangkaian waktu. Model SARIMAX kemudian secara otomatis menerapkan perbedaan pada data, untuk membuatnya stasioner, seperti yang ditentukan oleh pesananddanD, sebelum menyesuaikan model. Ini adalah praktik umum karena banyak model rangkaian waktu, termasuk SARIMAX, mengasumsikan bahwa data bersifat stasioner.Untuk rangkaian waktu nonstationary (misalnya, ini menunjukkan tren atau musiman), praktik yang baik untuk diatur
enforce_stationaritykeTrue, dan membiarkan model SARIMAX menangani perbedaan untuk mencapai stasioneritas. Untuk rangkaian waktu stasioner (misalnya, satu tanpa tren atau musiman), aturenforce_stationaritykeFalseuntuk menghindari perbedaan yang tidak perlu.enforce_invertibility: Mengontrol apakah model harus memberlakukan invertibilitas pada perkiraan parameter selama proses pengoptimalan.Jika
enforce_invertibilitydiatur keTrue(default), ini menunjukkan bahwa model SARIMAX harus memberlakukan invertibilitas pada estimasi parameter. Invertibilitas memastikan bahwa model didefinisikan dengan baik, dan bahwa perkiraan koefisien AR dan MA mendarat dalam rentang stasioneritas.Penegakan invertibilitas membantu memastikan bahwa model SARIMAX mematuhi persyaratan teoritis untuk model rangkaian waktu yang stabil. Ini juga membantu mencegah masalah dengan estimasi dan stabilitas model.
Defaultnya adalah AR(1) model. Ini mengacu pada (1, 0, 0). Namun, adalah praktik umum untuk mencoba kombinasi yang berbeda dari parameter pesanan dan parameter urutan musiman, dan mengevaluasi performa model untuk himpunan data. Nilai yang sesuai dapat bervariasi dari satu rangkaian waktu ke rangkaian waktu lainnya.
Penentuan nilai optimal sering melibatkan analisis fungsi korelasi otomatis (ACF) dan fungsi korelasi otomatis parsial (PACF) dari data rangkaian waktu. Ini juga sering melibatkan penggunaan kriteria pemilihan model - misalnya, kriteria informasi Akaike (AIC) atau kriteria informasi Bayesian (BIC).
Sesuaikan hiperparameter:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Setelah evaluasi hasil sebelumnya, Anda dapat menentukan nilai untuk parameter pesanan dan parameter urutan musiman. Pilihannya adalah order=(0, 1, 1) dan seasonal_order=(0, 1, 1, 12), yang menawarkan AIC terendah (misalnya, 279,58). Gunakan nilai-nilai ini untuk melatih model.
Melatih model
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Kode ini memvisualisasikan perkiraan rangkaian waktu untuk data penjualan furnitur. Hasil yang diplot menunjukkan data yang diamati dan prakiraan satu langkah ke depan, dengan wilayah berbayang untuk interval keyakinan.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Gunakan predictions untuk menilai performa model, dengan mengkontraskannya dengan nilai aktual. Nilai predictions_future menunjukkan prakiraan di masa mendatang.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Langkah 4: Menilai model dan menyimpan prediksi
Integrasikan nilai aktual dengan nilai yang diperkirakan, untuk membuat laporan Power BI. Simpan hasil ini dalam tabel di dalam lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Langkah 5: Memvisualisasikan di Power BI
Laporan Power BI memperlihatkan kesalahan persentase absolut rata-rata (MAPE) 16,58. Metrik MAPE mendefinisikan akurasi metode prakiraan. Ini mewakili akurasi jumlah yang diperkirakan, dibandingkan dengan jumlah aktual.
MAPE adalah metrik yang mudah. MAPE 10% menunjukkan bahwa penyimpangan rata-rata antara nilai yang diperkirakan dan nilai aktual adalah 10%, terlepas dari apakah penyimpangan positif atau negatif. Standar nilai MAPE yang diinginkan bervariasi di seluruh industri.
Garis biru muda dalam grafik ini mewakili nilai penjualan aktual. Garis biru tua mewakili nilai penjualan yang diperkirakan. Perbandingan penjualan aktual dan perkiraan mengungkapkan bahwa model secara efektif memprediksi penjualan untuk Furniture kategori selama enam bulan pertama 2023.
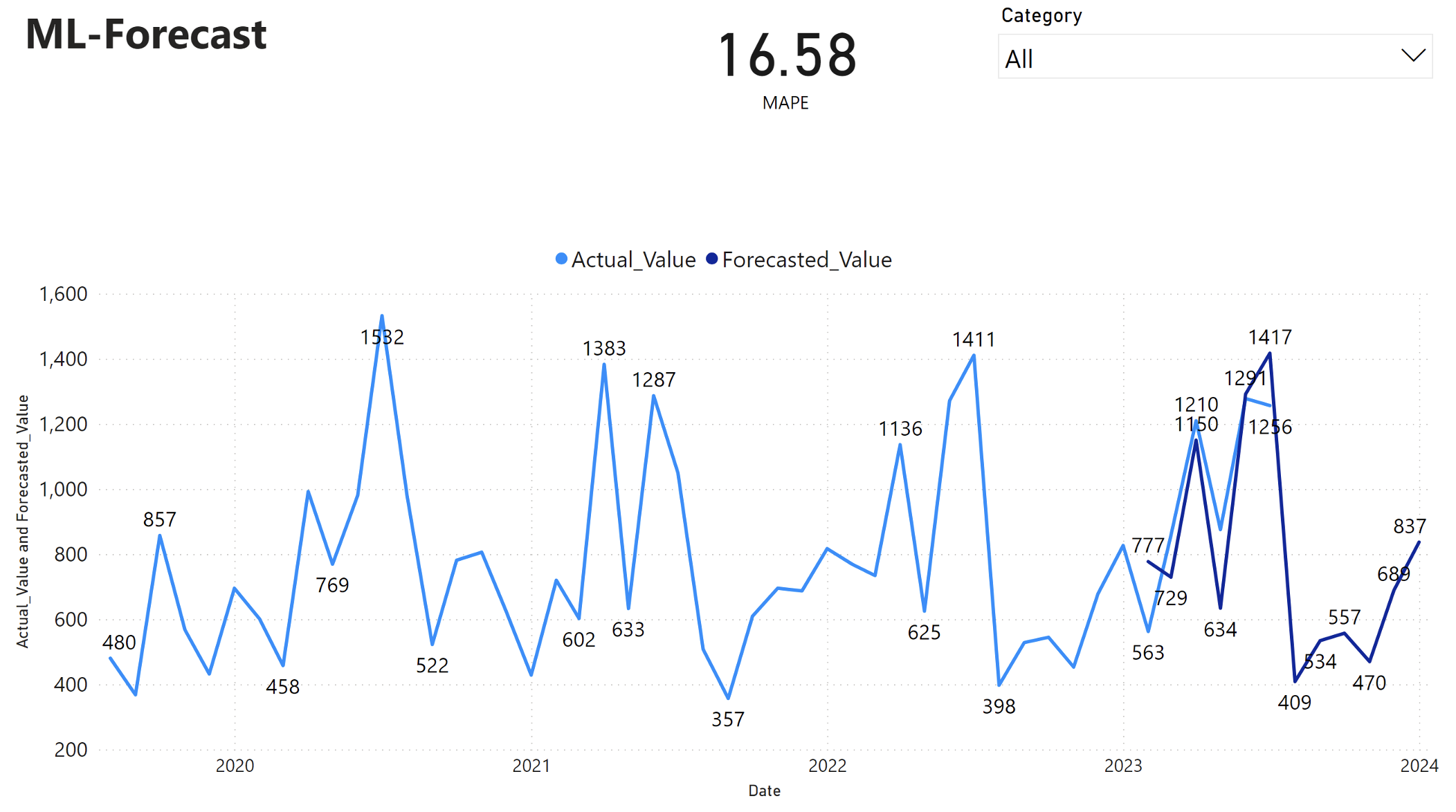
Berdasarkan pengamatan ini, kita dapat memiliki keyakinan pada kemampuan prakiraan model, untuk penjualan keseluruhan dalam enam bulan terakhir 2023, dan meluas ke 2024. Keyakinan ini dapat menginformasikan keputusan strategis tentang manajemen inventaris, pengadaan bahan baku, dan pertimbangan terkait bisnis lainnya.