Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menargetkan profesional TI dan manajer TI. Anda akan mempelajari tentang arsitektur solusi BI di COE dan berbagai teknologi yang digunakan. Teknologi termasuk Azure, Power BI, dan Excel. Bersama-sama, mereka dapat dimanfaat untuk memberikan platform BI cloud yang dapat diskalakan dan digerakkan oleh data.
Merancang platform BI yang kuat agak seperti membangun jembatan; jembatan yang menghubungkan data sumber yang diubah dan diperkaya ke konsumen data. Desain struktur yang begitu kompleks membutuhkan pola pikir rekayasa, meskipun bisa menjadi salah satu arsitektur IT yang paling kreatif dan bermanfaat yang dapat Anda desain. Dalam organisasi besar, arsitektur solusi BI dapat terdiri dari:
- Sumber data
- Penyerapan data
- Big data / persiapan data
- Gudang data
- Model semantik BI
- Laporan
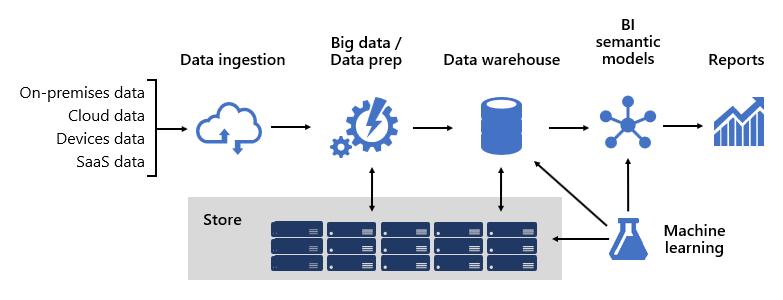
Platform harus mendukung tuntutan tertentu. Secara khusus, harus mampu melakukan skala dan berfungsi untuk memenuhi harapan layanan bisnis dan konsumen data. Pada saat yang sama, itu harus aman dari bawah ke atas. Dan harus cukup tangguh untuk beradaptasi dengan perubahan — karena itu adalah kepastian bahwa pada waktunya data baru dan bidang subjek harus tersedia secara online.
Kerangka kerja
Di Microsoft, sejak awal kami mengadopsi pendekatan seperti sistem dengan berinvestasi dalam pengembangan kerangka kerja. Kerangka kerja proses teknis dan bisnis meningkatkan penggunaan kembali desain dan logika dan memberikan hasil yang konsisten. Mereka juga menawarkan fleksibilitas dalam arsitektur yang memanfaatkan banyak teknologi, dan mereka merampingkan dan mengurangi overhead rekayasa melalui proses yang dapat diulang.
Kami mempelajari bahwa kerangka kerja yang dirancang dengan baik meningkatkan visibilitas ke dalam silsilah data, analisis dampak, pemeliharaan logika bisnis, mengelola taksonomi, dan menyederhanakan tata kelola. Juga, pengembangan menjadi lebih cepat dan kolaborasi di seluruh tim besar menjadi lebih responsif dan efektif.
Kami akan menjelaskan beberapa kerangka kerja kami dalam artikel ini.
Model data
Model data memberi Anda kontrol atas bagaimana data disusun dan diakses. Untuk layanan bisnis dan konsumen data, model data adalah antarmuka mereka dengan platform BI.
Platform BI dapat memberikan tiga jenis model yang berbeda:
- Model perusahaan
- Model semantik BI
- Model Pembelajaran Mesin (ML)
Model perusahaan
model Enterprise dibangun dan dikelola oleh arsitek TI. Mereka terkadang disebut sebagai model dimensi atau mart data. Biasanya, data disimpan dalam format relasional sebagai tabel dimensi dan fakta. Tabel ini menyimpan data yang dibersihkan dan diperkaya yang dikonsolidasikan dari banyak sistem dan mewakili sumber otoritatif untuk pelaporan dan analitik.
Model perusahaan memberikan sumber data yang konsisten dan tunggal untuk pelaporan dan BI. Mereka dibangun sekali dan dibagikan sebagai standar perusahaan. Kebijakan tata kelola memastikan data aman, sehingga akses ke himpunan data sensitif—seperti informasi atau keuangan pelanggan—dibatasi berdasarkan kebutuhan. Mereka mengadopsi konvensi penamaan yang memastikan konsistensi, sehingga lebih membangun kredibilitas data dan kualitas.
Dalam platform BI cloud, model perusahaan dapat disebarkan ke kumpulan Synapse SQL di Azure Synapse. Kumpulan Synapse SQL kemudian menjadi satu-satunya sumber kebenaran yang dapat diandalkan oleh organisasi untuk mendapatkan wawasan yang cepat dan mendalam.
Model semantik BI
model semantik BI mewakili lapisan semantik atas model perusahaan. Mereka dibangun dan dikelola oleh pengembang BI dan pengguna bisnis. Pengembang BI membuat model semantik BI inti yang sumber data dari model perusahaan. Pengguna bisnis dapat membuat model independen berskala lebih kecil—atau, mereka dapat memperluas model semantik BI inti dengan sumber departemen atau eksternal. Model semantik BI umumnya berfokus pada satu area subjek, dan sering dibagikan secara luas.
Kemampuan bisnis diaktifkan bukan oleh data saja, tetapi oleh model semantik BI yang menjelaskan konsep, hubungan, aturan, dan standar. Dengan cara ini, mereka mewakili struktur intuitif dan mudah dipahami yang menentukan hubungan data dan merangkum aturan bisnis sebagai perhitungan. Mereka juga dapat memberlakukan izin data terperintah, memastikan orang yang tepat memiliki akses ke data yang tepat. Yang penting, mereka mempercepat performa kueri, menyediakan analitik interaktif yang sangat responsif—bahkan lebih dari terabyte data. Seperti model perusahaan, model semantik BI mengadopsi konvensi penamaan yang memastikan konsistensi.
Dalam platform BI cloud, pengembang BI dapat menyebarkan model semantik BI ke Azure Analysis Services, kapasitas Power BI Premium dari kapasitas Microsoft Fabric .
Penting
Artikel ini mengacu pada Power BI Premium atau langganan kapasitasnya (SKU P). Saat ini, Microsoft sedang mengonsolidasikan opsi pembelian dan menghentikan SKU Power BI Premium per kapasitas. Pelanggan baru dan yang sudah ada sebaiknya mempertimbangkan untuk membeli langganan kapasitas Fabric (F SKU) sebagai alternatif.
Untuk informasi selengkapnya, lihat Pembaruan penting yang akan datang untuk lisensi Power BI Premium dan FAQ Power BI Premium.
Kami merekomendasikan untuk menerapkan ke Power BI ketika digunakan sebagai lapisan pelaporan dan analitik Anda. Produk-produk ini mendukung mode penyimpanan yang berbeda, memungkinkan tabel model data untuk menyimpan data mereka atau menggunakan DirectQuery, yang merupakan teknologi yang meneruskan kueri ke sumber data yang mendasarinya. DirectQuery adalah mode penyimpanan yang ideal ketika tabel model mewakili volume data besar atau ada kebutuhan untuk memberikan hasil yang hampir real time. Dua mode penyimpanan dapat digabungkan: Model komposit menggabungkan tabel yang menggunakan mode penyimpanan yang berbeda dalam satu model.
Untuk model yang sering diberi kueri, Azure Load Balancer dapat digunakan untuk mendistribusikan beban kueri secara merata ke replika-replika model. Ini juga memungkinkan Anda untuk menskalakan aplikasi Anda dan membuat model semantik BI yang sangat tersedia.
Model Pembelajaran Mesin
model Pembelajaran Mesin (ML) dibangun dan dikelola oleh ilmuwan data. Sebagian besar dikembangkan dari sumber mentah di dalam kumpulan data (data lake).
Model ML terlatih dapat mengungkapkan pola dalam data Anda. Dalam banyak keadaan, pola-pola tersebut dapat digunakan untuk membuat prediksi yang dapat digunakan untuk memperkaya data. Misalnya, perilaku pembelian dapat digunakan untuk memprediksi pelanggan yang berhenti atau mengelompokkan pelanggan. Hasil prediksi dapat ditambahkan ke model perusahaan untuk memungkinkan analisis oleh segmen pelanggan.
Di platform BI cloud, Anda dapat menggunakan Azure Machine Learning untuk melatih, menyebarkan, mengotomatiskan, mengelola, dan melacak model ML.
Gudang data
Duduk di jantung platform BI adalah gudang data, yang menghosting model perusahaan Anda. Ini adalah sumber data yang disetujui—sebagai sistem pencatatan dan sebagai hub—melayani model perusahaan untuk pelaporan, BI, dan ilmu data.
Banyak layanan bisnis, termasuk aplikasi lini bisnis (LOB), dapat mengandalkan gudang data sebagai sumber pengetahuan perusahaan yang otoritatif dan diatur.
Di Microsoft, gudang data kami dihosting di Azure Data Lake Storage Gen2 (ADLS Gen2) dan Azure Synapse Analytics.
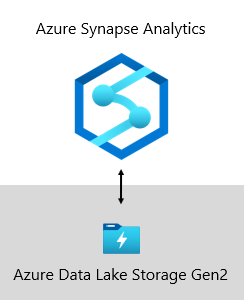
- ADLS Gen2 menjadikan Azure Storage sebagai fondasi untuk membangun data lake perusahaan di Azure. Ini dirancang untuk melayani beberapa petabyte informasi sambil mempertahankan ratusan gigabit throughput. Ia menawarkan kapasitas penyimpanan dan transaksi dengan biaya rendah. Terlebih lagi, ini mendukung akses yang kompatibel dengan Hadoop, yang memungkinkan Anda mengelola dan mengakses data seperti yang Anda lakukan dengan Hadoop Distributed File System (HDFS). Bahkan, Azure HDInsight, Azure Databricks, dan Azure Synapse Analytics semuanya dapat mengakses data yang disimpan di ADLS Gen2. Jadi, dalam platform BI, ini adalah pilihan yang baik untuk menyimpan data sumber mentah, data semi-diproses atau ditahapkan, dan data siap produksi. Kami menggunakannya untuk menyimpan semua data bisnis kami.
- Azure Synapse Analytics adalah layanan analitik yang menyatukan pergudangan data perusahaan dan analitik Big Data. Ini memberi Anda kebebasan untuk mengkueri data berdasarkan persyaratan Anda, menggunakan sumber daya sesuai permintaan atau yang disediakan tanpa server—dalam skala besar. Synapse SQL, komponen Azure Synapse Analytics, mendukung analitik berbasis T-SQL lengkap, sehingga ideal untuk menghosting model perusahaan yang terdiri dari tabel dimensi dan fakta Anda. Tabel dapat dimuat secara efisien dari ADLS Gen2 menggunakan kueri Polybase T-SQL sederhana. Anda kemudian memiliki kekuatan MPP untuk menjalankan analitik berkinerja tinggi.
Kerangka kerja Mesin Aturan Bisnis
Kami mengembangkan kerangka kerja Business Rules Engine (BRE) untuk membuat katalog logika bisnis apa pun yang dapat diterapkan di lapisan gudang data. BRE dapat berarti banyak hal, tetapi dalam konteks gudang data berguna untuk membuat kolom terhitung dalam tabel relasional. Kolom terhitung ini biasanya direpresentasikan sebagai perhitungan atau ekspresi matematika menggunakan pernyataan kondisional.
Tujuannya adalah untuk membagi logika bisnis dari kode BI inti. Secara tradisional, aturan bisnis dikodekan secara permanen ke dalam prosedur tersimpan SQL, sehingga sering menghasilkan banyak upaya untuk mempertahankannya ketika kebutuhan bisnis berubah. Dalam BRE, aturan bisnis didefinisikan sekali dan digunakan beberapa kali ketika diterapkan ke entitas gudang data yang berbeda. Jika logika perhitungan perlu berubah, logika hanya perlu diperbarui di satu tempat dan tidak dalam banyak prosedur tersimpan. Ada manfaat sampingan juga: kerangka kerja BRE mendorong transparansi dan visibilitas ke dalam logika bisnis yang diimplementasikan, yang dapat diekspos melalui serangkaian laporan yang membuat dokumentasi pembaruan mandiri.
Sumber data
Gudang data dapat mengonsolidasikan data dari hampir semua sumber data. Sebagian besar dibangun di atas sumber data LOB, yang biasanya merupakan database relasional yang menyimpan data khusus subjek untuk penjualan, pemasaran, keuangan, dll. Database ini dapat dihosting cloud atau dapat berada di tempat. Sumber data lain dapat berbasis file, terutama log web atau data IOT yang bersumber dari perangkat. Terlebih lagi, data dapat bersumber dari vendor Software-as-a-Service (SaaS).
Di Microsoft, beberapa sistem internal kami menghasilkan data operasional langsung ke ADLS Gen2 menggunakan format file mentah. Selain data lake kami, sistem sumber lainnya terdiri dari aplikasi LOB relasional, buku kerja Excel, sumber berbasis file lainnya, dan Manajemen Data Master (MDM) dan repositori data kustom. Repositori MDM memungkinkan kami mengelola data master kami untuk memastikan versi data yang otoritatif, terstandarisasi, dan tervalidasi.
Penyerapan data
Secara berkala, dan sesuai dengan ritme bisnis, data diserap dari sistem sumber dan dimuat ke dalam gudang data. Bisa sekali sehari atau pada interval yang lebih sering. Penyerapan data berkaitan dengan mengekstrak, mengubah, dan memuat data. Atau, mungkin sebaliknya: mengekstrak, memuat, dan kemudian mengubah data. Perbedaan datang ke tempat transformasi terjadi. Transformasi diterapkan untuk membersihkan, menyesuaikan, mengintegrasikan, dan menstandarkan data. Untuk informasi selengkapnya, lihat Ekstraksi, transformasi, dan pemuatan (ETL).
Pada akhirnya, tujuannya adalah untuk memuat data yang tepat ke dalam model perusahaan Anda secepat dan seefisien mungkin.
Di Microsoft, kami menggunakan Azure Data Factory (ADF). Layanan ini digunakan untuk menjadwalkan dan mengatur validasi data, transformasi, dan beban massal dari sistem sumber eksternal ke dalam data lake kami. Ini dikelola oleh kerangka kerja kustom untuk memproses data secara paralel dan dalam skala besar. Selain itu, pengelogan komprehensif dilakukan untuk mendukung pemecahan masalah, pemantauan performa, dan untuk memicu pemberitahuan pemberitahuan saat kondisi tertentu terpenuhi.
Sementara itu, Azure Databricks—platform analitik berbasis Apache Spark yang dioptimalkan untuk platform layanan cloud Azure—melakukan transformasi khusus untuk ilmu data. Ini juga membangun dan menjalankan model ML menggunakan notebook Python. Skor dari model ML ini dimuat ke dalam gudang data untuk mengintegrasikan prediksi dengan aplikasi dan laporan perusahaan. Karena Azure Databricks mengakses file data lake secara langsung, Azure Databricks menghilangkan atau meminimalkan kebutuhan untuk menyalin atau memperoleh data.
Diagram 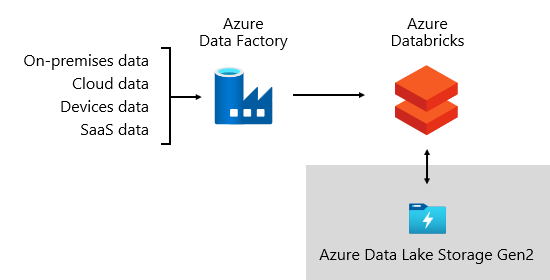
Kerangka kerja penyerapan
Kami mengembangkan kerangka kerja penyerapan sebagai serangkaian tabel dan prosedur konfigurasi. Ini mendukung pendekatan berbasis data untuk memperoleh data dalam volume besar dengan kecepatan tinggi dan dengan kode minimal. Singkatnya, kerangka kerja ini menyederhanakan proses akuisisi data untuk memuat gudang data.
Kerangka kerja bergantung pada tabel konfigurasi yang menyimpan sumber data dan informasi terkait tujuan data seperti jenis sumber, server, database, skema, dan detail terkait tabel. Pendekatan desain ini berarti kita tidak perlu mengembangkan alur ADF tertentu atau paket
Kerangka kerja penyerapan dirancang untuk menyederhanakan proses penanganan perubahan skema sumber hulu juga. Sangat mudah untuk memperbarui data konfigurasi—secara manual atau otomatis, ketika perubahan skema terdeteksi untuk memperoleh atribut yang baru ditambahkan dalam sistem sumber.
Kerangka kerja orkestrasi
Kami mengembangkan kerangka kerja orkestrasi untuk mengoprasikan dan mengatur alur data kami. Kerangka kerja orkestrasi menggunakan desain berbasis data yang bergantung pada sekumpulan tabel konfigurasi. Tabel ini menyimpan metadata yang menjelaskan dependensi alur dan cara memetakan data sumber ke struktur data target. Investasi dalam mengembangkan kerangka kerja adaptif ini telah dibayar sendiri; tidak ada lagi persyaratan untuk mengkodekan secara permanen setiap pergerakan data.
Penyimpanan data
Data lake dapat menyimpan data mentah dalam volume besar untuk digunakan nanti bersama dengan transformasi data sementara.
Di Microsoft, kami menggunakan ADLS Gen2 sebagai sumber kebenaran tunggal kami. Ini menyimpan data mentah bersama data bertahap dan data siap produksi. Ini menyediakan solusi data lake yang sangat dapat diskalakan dan hemat biaya untuk analitik big data. Menggabungkan kekuatan sistem file berkinerja tinggi dengan skala besar, sistem ini dioptimalkan untuk beban kerja analitik data, mempercepat waktu untuk mendapatkan wawasan.
ADLS Gen2 menyediakan keunggulan dari kedua dunia: ini adalah penyimpanan BLOB dan namespace sistem file berkinerja tinggi, yang kami konfigurasikan dengan izin akses yang rinci.
Data yang disempurnakan kemudian disimpan dalam database relasional untuk memberikan penyimpanan data berkinerja tinggi dan sangat dapat diskalakan untuk model perusahaan, dengan keamanan, tata kelola, dan pengelolaan. Mart data yang spesifik untuk subjek disimpan di Azure Synapse Analytics, yang dimuat menggunakan kueri Azure Databricks atau Polybase T-SQL.
Konsumsi data
Pada lapisan pelaporan, layanan bisnis menggunakan data perusahaan yang bersumber dari gudang data. Mereka juga mengakses data langsung di data lake untuk analisis ad hoc atau tugas ilmu data.
Izin yang lebih terperinci diberlakukan di semua lapisan: dalam data lake, model bisnis, dan model semantik BI. Izin memastikan konsumen data hanya dapat melihat data yang mereka miliki hak untuk diakses.
Di Microsoft, kami menggunakan laporan dan dasbor Power BI, dan laporan berhalaman Power BI. Beberapa pelaporan dan analisis ad hoc dilakukan di Excel—terutama untuk pelaporan keuangan.
Kami menerbitkan kamus data, yang memberikan informasi referensi tentang model data kami. Mereka tersedia untuk pengguna kami sehingga mereka dapat menemukan informasi tentang platform BI kami. Kamus mendesain model dokumen, memberikan deskripsi tentang entitas, format, struktur, silsilah data, hubungan, dan perhitungan. Kami menggunakan Azure Data Catalog
Biasanya, pola konsumsi data berbeda berdasarkan peran:
- Analis data terhubung langsung ke model semantik BI inti. Saat model semantik BI inti berisi semua data dan logika yang mereka butuhkan, model tersebut menggunakan koneksi langsung untuk membuat laporan dan dasbor Power BI. Saat perlu memperluas model dengan data departemen, mereka membuat model komposit Power BI . Jika ada kebutuhan akan laporan gaya lembar bentang, mereka menggunakan Excel untuk menghasilkan laporan berdasarkan model semantik BI inti atau model semantik BI departemen.
- pengembang BI dan penulis laporan operasional terhubung langsung ke model perusahaan. Mereka menggunakan Power BI Desktop untuk membuat laporan analitik koneksi langsung. Mereka juga dapat menulis laporan BI jenis operasional sebagai laporan paginasi Power BI, menulis kueri SQL asli untuk mengakses data dari model perusahaan Azure Synapse Analytics dengan menggunakan model semantik T-SQL, atau Power BI dengan menggunakan DAX atau MDX.
- Ilmuwan data terhubung langsung ke data di data lake. Mereka menggunakan notebook Azure Databricks dan Python untuk mengembangkan model ML, yang sering bersifat eksperimental dan memerlukan keterampilan khusus untuk penggunaan produksi.
diagram 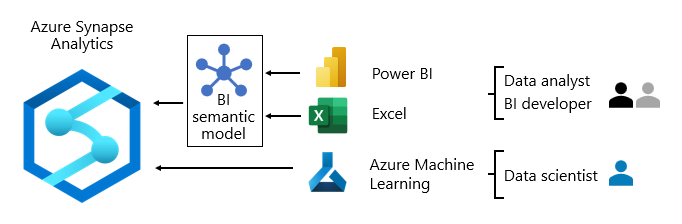
Konten terkait
Untuk informasi selengkapnya tentang artikel ini, lihat sumber daya berikut ini:
- rencana adopsi Fabric: Pusat Keunggulan
- Enterprise BI di Azure dengan Azure Synapse Analytics
- Pertanyaan? Coba tanyakan kepada Komunitas Fabric
- Saran? Sumbangkan ide untuk meningkatkan Fabric
Layanan profesional
Mitra Power BI bersertifikat tersedia untuk membantu organisasi Anda berhasil saat menyiapkan COE. Mereka dapat memberi Anda pelatihan hemat biaya atau audit data Anda. Untuk menemukan mitra Power BI, kunjungi portal mitra Microsoft Power BI .
Anda juga dapat berinteraksi dengan mitra konsultasi berpengalaman. Mereka dapat membantu Anda menilai, mengevaluasi, atau menerapkan Power BI.