Sinkronisasi multi-mesin
Sebagian besar GPU modern berisi beberapa mesin independen yang menyediakan fungsionalitas khusus. Banyak yang memiliki satu atau beberapa mesin salinan khusus, dan mesin komputasi, biasanya berbeda dari mesin 3D. Masing-masing mesin ini dapat menjalankan perintah secara paralel satu sama lain. Direct3D 12 menyediakan akses mendetail ke mesin 3D, komputasi, dan salinan, menggunakan antrean dan daftar perintah.
Mesin GPU
Diagram berikut menunjukkan utas CPU judul, masing-masing mengisi satu atau beberapa antrean salinan, komputasi, dan 3D. Antrean 3D dapat mendorong ketiga mesin GPU; antrean komputasi dapat mendorong mesin komputasi dan salinan; dan antrean salin hanya mesin salin.
Karena utas yang berbeda mengisi antrean, tidak ada jaminan sederhana dari urutan eksekusi, oleh karena itu perlu mekanisme sinkronisasi—ketika judul memerlukannya.
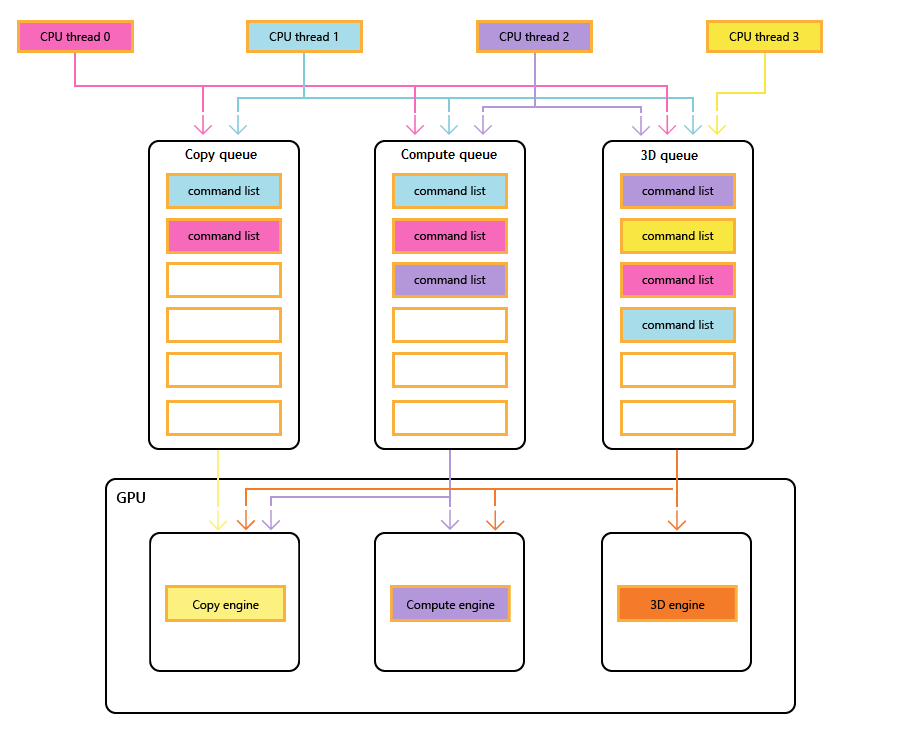
Gambar berikut menggambarkan bagaimana judul mungkin menjadwalkan pekerjaan di beberapa mesin GPU, termasuk sinkronisasi antar-mesin jika perlu: ini menunjukkan beban kerja per mesin dengan dependensi antar-mesin. Dalam contoh ini, mesin salin terlebih dahulu menyalin beberapa geometri yang diperlukan untuk penyajian. Mesin 3D menunggu salinan ini selesai, dan merender pra-melewati geometri. Ini kemudian dikonsumsi oleh mesin komputasi. Hasil pengiriman mesin komputasi, bersama dengan beberapa operasi salinan tekstur pada mesin salin, dikonsumsi oleh mesin 3D untuk panggilan Gambar akhir.
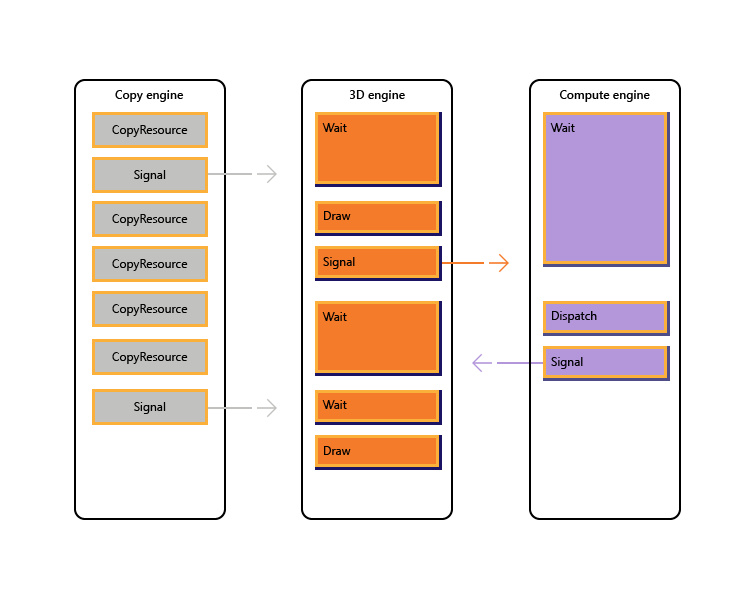
Kode semu berikut menggambarkan bagaimana judul mungkin mengirimkan beban kerja seperti itu.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Kode pseudo berikut mengilustrasikan sinkronisasi antara mesin salinan dan 3D untuk mencapai alokasi memori seperti tumpukan melalui buffer cincin. Judul memiliki fleksibilitas untuk memilih keseimbangan yang tepat antara memaksimalkan paralelisme (melalui buffer besar) dan mengurangi konsumsi dan latensi memori (melalui buffer kecil).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Skenario multi-mesin
Direct3D 12 memungkinkan Anda menghindari ketidakefisienan yang tidak sengaja disebabkan oleh penundaan sinkronisasi yang tidak terduga. Ini juga memungkinkan Anda untuk memperkenalkan sinkronisasi pada tingkat yang lebih tinggi di mana sinkronisasi yang diperlukan dapat ditentukan dengan kepastian yang lebih besar. Masalah kedua yang diatasi multi-mesin adalah membuat operasi mahal lebih eksplisit, yang mencakup transisi antara 3D dan video yang secara tradisional mahal karena sinkronisasi antara beberapa konteks kernel.
Secara khusus, skenario berikut dapat diatasi dengan Direct3D 12.
- Pekerjaan GPU asinkron dan prioritas rendah. Ini memungkinkan eksekusi bersamaan dari pekerjaan GPU berprioritas rendah dan operasi atomik yang memungkinkan satu utas GPU untuk mengonsumsi hasil utas lain yang tidak disinkronkan tanpa memblokir.
- Pekerjaan komputasi prioritas tinggi. Dengan komputasi latar belakang dimungkinkan untuk mengganggu penyajian 3D untuk melakukan sejumlah kecil pekerjaan komputasi prioritas tinggi. Hasil pekerjaan ini dapat diperoleh lebih awal untuk pemrosesan tambahan pada CPU.
- Pekerjaan komputasi latar belakang. Antrean prioritas rendah terpisah untuk beban kerja komputasi memungkinkan aplikasi menggunakan siklus GPU cadangan untuk melakukan komputasi latar belakang tanpa dampak negatif pada tugas penyajian utama (atau lainnya). Tugas latar belakang dapat mencakup dekompresi sumber daya atau memperbarui simulasi atau struktur akselerasi. Tugas latar belakang harus jarang disinkronkan pada CPU (kira-kira sekali per bingkai) untuk menghindari mengulur-ulur atau memperlambat pekerjaan latar depan.
- Streaming dan unggah data. Antrean salinan terpisah menggantikan konsep D3D11 dari data awal dan memperbarui sumber daya. Meskipun aplikasi bertanggung jawab untuk detail lebih lanjut dalam model Direct3D 12, tanggung jawab ini dilengkapi dengan kekuatan. Aplikasi dapat mengontrol berapa banyak memori sistem yang dikhususkan untuk buffering mengunggah data. Aplikasi ini dapat memilih kapan dan bagaimana (CPU vs GPU, pemblokiran vs non-pemblokiran) untuk disinkronkan, dan dapat melacak kemajuan dan mengontrol jumlah pekerjaan yang diantrekan.
- Peningkatan paralelisme. Aplikasi dapat menggunakan antrean yang lebih dalam untuk beban kerja latar belakang (misalnya dekode video) ketika aplikasi memiliki antrean terpisah untuk pekerjaan latar depan.
Dalam Direct3D 12 konsep antrean perintah adalah representasi API dari urutan pekerjaan yang kira-kira serial yang dikirimkan oleh aplikasi. Hambatan dan teknik lain memungkinkan pekerjaan ini dijalankan dalam alur atau di luar urutan, tetapi aplikasi hanya melihat satu garis waktu penyelesaian. Ini sesuai dengan konteks langsung di D3D11.
API Sinkronisasi
Perangkat dan antrean
Perangkat Direct3D 12 memiliki metode untuk membuat dan mengambil antrean perintah dari berbagai jenis dan prioritas. Sebagian besar aplikasi harus menggunakan antrean perintah default karena ini memungkinkan penggunaan bersama oleh komponen lain. Aplikasi dengan persyaratan konkurensi tambahan dapat membuat antrean tambahan. Antrean ditentukan oleh jenis daftar perintah yang mereka konsumsi.
Lihat metode pembuatan ID3D12Device berikut.
- CreateCommandQueue : membuat antrean perintah berdasarkan informasi dalam struktur 12_COMMAND_QUEUE_DESC Direct3D .
- CreateCommandList : membuat daftar perintah jenis Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : membuat pagar, mencatat bendera di Direct3D 12_FENCE_FLAGS. Pagar digunakan untuk menyinkronkan antrean.
Antrean semua jenis (3D, komputasi, dan salin) berbagi antarmuka yang sama dan semuanya berbasis daftar perintah.
Lihat metode ID3D12CommandQueue berikut.
- ExecuteCommandLists : mengirimkan array daftar perintah untuk eksekusi. Setiap daftar perintah yang ditentukan oleh ID3D12CommandList.
- Sinyal : menetapkan nilai pagar saat antrean (berjalan pada GPU) mencapai titik tertentu.
- Tunggu : antrean menunggu hingga pagar yang ditentukan mencapai nilai yang ditentukan.
Perhatikan bahwa bundel tidak digunakan oleh antrean apa pun dan oleh karena itu jenis ini tidak dapat digunakan untuk membuat antrean.
Fences
API multi-mesin menyediakan API eksplisit untuk membuat dan menyinkronkan menggunakan pagar. Pagar adalah konstruksi sinkronisasi yang dikendalikan oleh nilai UINT64. Nilai pagar ditetapkan oleh aplikasi. Operasi sinyal memodifikasi nilai pagar dan operasi tunggu memblokir hingga pagar telah mencapai nilai yang diminta atau lebih besar. Peristiwa dapat ditembakkan ketika pagar mencapai nilai tertentu.
Lihat metode antarmuka ID3D12Fence .
- GetCompletedValue : mengembalikan nilai pagar saat ini.
- SetEventOnCompletion : menyebabkan peristiwa menyala saat pagar mencapai nilai tertentu.
- Sinyal : mengatur pagar ke nilai yang diberikan.
Pagar memungkinkan akses CPU ke nilai pagar saat ini, dan CPU menunggu dan memberi sinyal.
Metode Signal pada antarmuka ID3D12Fence memperbarui pagar dari sisi CPU. Pembaruan ini segera terjadi. Metode Signal pada ID3D12CommandQueue memperbarui pagar dari sisi GPU. Pembaruan ini terjadi setelah semua operasi lain pada antrean perintah telah selesai.
Semua simpul dalam pengaturan multi-mesin dapat membaca dan bereaksi terhadap pagar apa pun yang mencapai nilai yang tepat.
Aplikasi menetapkan nilai pagar mereka sendiri, titik awal yang baik mungkin meningkatkan pagar sekali per bingkai.
Sebuah pagar mungkinterbalik. Ini berarti bahwa nilai pagar tidak perlu hanya kenaikan. Jika operasi Sinyal diantrekan pada dua antrean perintah yang berbeda, atau jika dua utas CPU keduanya memanggil Sinyal di pagar, mungkin ada perlombaan untuk menentukan Sinyal mana yang selesai terakhir, dan oleh karena itu nilai pagar mana yang akan tetap ada. Jika pagar terbalik, setiap penantian baru (termasuk permintaan SetEventOnCompletion ) akan dibandingkan dengan nilai pagar yang lebih rendah baru, dan oleh karena itu mungkin tidak terpenuhi, bahkan jika nilai pagar sebelumnya cukup tinggi untuk memenuhinya. Jika perlombaan memang terjadi, antara nilai yang akan memenuhi penantian yang luar biasa, dan nilai yang lebih rendah yang tidak akan, penantian akan terpenuhi terlepas dari nilai mana yang tetap ada setelahnya.
API pagar menyediakan fungsionalitas sinkronisasi yang kuat tetapi dapat menciptakan masalah yang berpotensi sulit di-debug. Disarankan agar setiap pagar hanya digunakan untuk menunjukkan kemajuan pada satu garis waktu untuk mencegah perlombaan antar signaler.
Salin dan komputasi daftar perintah
Ketiga jenis daftar perintah menggunakan antarmuka ID3D12GraphicsCommandList , namun hanya subset metode yang didukung untuk penyalinan dan komputasi.
Salin dan komputasi daftar perintah dapat menggunakan metode berikut.
Daftar perintah komputasi juga dapat menggunakan metode berikut.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- DiscardResource
- Pengiriman
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Daftar perintah komputasi harus mengatur PSO komputasi saat memanggil SetPipelineState.
Bundel tidak dapat digunakan dengan daftar perintah komputasi atau salin atau antrean.
Contoh komputasi dan grafik yang disalurkan
Contoh ini menunjukkan bagaimana sinkronisasi pagar dapat digunakan untuk membuat alur pekerjaan komputasi pada antrean (direferensikan oleh pComputeQueue) yang dikonsumsi oleh grafik bekerja pada antrean pGraphicsQueue. Pekerjaan komputasi dan grafik disalurkan dengan antrean grafis yang menggunakan hasil pekerjaan komputasi dari beberapa bingkai kembali, dan peristiwa CPU digunakan untuk membatasi total pekerjaan yang diantrekan secara keseluruhan.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Untuk mendukung alur ini, harus ada buffer salinan ComputeGraphicsLatency+1 data yang berbeda yang meneruskan dari antrean komputasi ke antrean grafis. Daftar perintah harus menggunakan UAV dan tidak langsung untuk membaca dan menulis dari "versi" data yang sesuai di buffer. Antrean komputasi harus menunggu hingga antrean grafis selesai membaca dari data untuk bingkai N sebelum dapat menulis bingkai N+ComputeGraphicsLatency.
Perhatikan bahwa jumlah antrean komputasi yang bekerja relatif terhadap CPU tidak bergantung langsung pada jumlah buffering yang diperlukan, namun, mengantre pekerjaan GPU di luar jumlah ruang buffer yang tersedia kurang berharga.
Mekanisme alternatif untuk menghindari tidak langsung adalah dengan membuat beberapa daftar perintah yang sesuai dengan masing-masing versi data "diganti namanya". Contoh berikutnya menggunakan teknik ini sambil memperluas contoh sebelumnya untuk memungkinkan antrean komputasi dan grafik berjalan lebih asinkron.
Contoh komputasi dan grafik asinkron
Contoh berikutnya ini memungkinkan grafik untuk merender secara asinkron dari antrean komputasi. Masih ada sejumlah data buffer tetap antara dua tahap, namun sekarang pekerjaan grafis berlanjut secara independen dan menggunakan hasil terbaru dari tahap komputasi seperti yang diketahui pada CPU ketika pekerjaan grafis diantrekan. Ini akan berguna jika pekerjaan grafik sedang diperbarui oleh sumber lain, misalnya input pengguna. Harus ada beberapa daftar perintah untuk memungkinkan ComputeGraphicsLatency bingkai grafik berfungsi dalam penerbangan pada satu waktu, dan fungsi UpdateGraphicsCommandList mewakili pembaruan daftar perintah untuk menyertakan data input terbaru dan membaca dari data komputasi dari buffer yang sesuai.
Antrean komputasi masih harus menunggu antrean grafis selesai dengan buffer pipa, tetapi pagar ketiga (pGraphicsComputeFence) diperkenalkan sehingga kemajuan pekerjaan komputasi pembacaan grafis versus kemajuan grafis secara umum dapat dilacak. Ini mencerminkan fakta bahwa sekarang bingkai grafis berturut-turut dapat dibaca dari hasil komputasi yang sama atau dapat melewati hasil komputasi. Desain yang lebih efisien tetapi sedikit lebih rumit hanya akan menggunakan pagar grafis tunggal dan menyimpan pemetaan ke bingkai komputasi yang digunakan oleh setiap bingkai grafis.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + PipeBufferIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Akses sumber daya multi-antrean
Untuk mengakses sumber daya pada lebih dari satu antrean, aplikasi harus mematuhi aturan berikut.
Akses sumber daya (lihat Direct3D 12_RESOURCE_STATES) ditentukan oleh kelas jenis antrean bukan objek antrean. Ada dua kelas jenis antrean: Antrean Komputasi/3D adalah satu kelas jenis, Salin adalah kelas jenis kedua. Jadi sumber daya yang memiliki hambatan ke status NON_PIXEL_SHADER_RESOURCE pada satu antrean 3D dapat digunakan dalam status tersebut pada antrean 3D atau Komputasi apa pun, tunduk pada persyaratan sinkronisasi yang mengharuskan sebagian besar penulisan diserialisasikan. Status sumber daya yang dibagikan antara dua kelas jenis (COPY_SOURCE dan COPY_DEST) dianggap sebagai status yang berbeda untuk setiap kelas jenis. Sehingga jika sumber daya beralih ke COPY_DEST pada antrean Salin, sumber daya tidak dapat diakses sebagai tujuan salinan dari antrean 3D atau Komputasi dan sebaliknya.
Untuk meringkas.
- Antrean "objek" adalah antrean tunggal apa pun.
- "Jenis" antrean adalah salah satu dari ketiganya: Komputasi, 3D, dan Salin.
- Antrean "jenis kelas" adalah salah satu dari dua ini: Komputasi/3D dan Salin.
Bendera COPY (COPY_DEST dan COPY_SOURCE) yang digunakan sebagai status awal mewakili status di kelas jenis 3D/Compute. Untuk menggunakan sumber daya awalnya pada antrean Salin, sumber daya harus dimulai dalam status COMMON. Status COMMON dapat digunakan untuk semua penggunaan pada antrean Salin menggunakan transisi status implisit.
Meskipun status sumber daya dibagikan di semua antrean Komputasi dan 3D, tidak diizinkan untuk menulis ke sumber daya secara bersamaan pada antrean yang berbeda. "Secara bersamaan" di sini berarti tidak disinkronkan, mencatat eksekusi yang tidak disinkronkan tidak dimungkinkan pada beberapa perangkat keras. Aturan berikut berlaku.
- Hanya satu antrean yang dapat menulis ke sumber daya pada satu waktu.
- Beberapa antrean dapat membaca dari sumber daya selama mereka tidak membaca byte yang dimodifikasi oleh penulis (membaca byte yang ditulis secara bersamaan menghasilkan hasil yang tidak terdefinisi).
- Pagar harus digunakan untuk menyinkronkan setelah menulis sebelum antrean lain dapat membaca byte tertulis atau membuat akses tulis apa pun.
Buffer belakang yang sedang disajikan harus dalam status 12_RESOURCE_STATE_COMMON Direct3D.
Topik terkait
Panduan pemrograman Direct3D 12
Menggunakan penghalang sumber daya untuk menyinkronkan status sumber daya di Direct3D 12
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk