Attenzione
Questo articolo fa riferimento a CentOS, una distribuzione Linux che è End Of Life (EOL). Valutare le proprie esigenze e pianificare di conseguenza. Per ulteriori informazioni, consultare la Guida alla fine del ciclo di vita di CentOS.
Questo scenario di esempio illustra come eseguire Apache NiFi in Azure. NiFi fornisce un sistema per l'elaborazione e la distribuzione dei dati.
Apache®, Apache NiFi®, and NiFi® sono marchi o marchi registrati di Apache Software Foundation negli Stati Uniti e/o in altri paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Architettura

Scaricare un file di Visio di questa architettura.
Workflow
L'applicazione NiFi viene eseguita nelle macchine virtuali in nodi del cluster NiFi. Le macchine virtuali sono inserite in un set di scalabilità di macchine virtuali distribuito dalla configurazione tra zone di disponibilità.
Apache ZooKeeper viene eseguito nelle macchine virtuali in un cluster separato. NiFi usa il cluster ZooKeeper per questi scopi:
- Per scegliere un nodo coordinatore del cluster
- Per coordinare il flusso di dati
Il gateway applicazione di Azure fornisce il bilanciamento del carico di livello 7 per l'interfaccia utente in esecuzione nei nodi NiFi.
Monitoraggio e la relativa funzionalità Log Analytics raccolgono, analizzano e agiscono sui dati di telemetria del sistema NiFi. I dati di telemetria includono i log di sistema NiFi, le metriche di integrità del sistema e le metriche delle prestazioni.
Azure Key Vault archivia in modo sicuro i certificati e le chiavi per il cluster NiFi.
Microsoft Entra ID fornisce l'accesso Single Sign-On (SSO) e l'autenticazione a più fattori.
Componenti
- NiFi fornisce un sistema per l'elaborazione e la distribuzione dei dati.
- ZooKeeper è un server open source che gestisce i sistemi distribuiti.
- Macchine virtuali offre una soluzione di infrastruttura come servizio (IaaS, Infrastructure as a Service). È possibile usare Macchine virtuali per distribuire risorse di elaborazione scalabili su richiesta. Macchine virtuali offre la flessibilità della virtualizzazione eliminando però le esigenze di manutenzione dell'hardware fisico.
- I set di scalabilità di macchine virtuali di Azure consentono di gestire un gruppo di macchine virtuali con carico bilanciato. Il numero di istanze di macchine virtuali in un set può aumentare o diminuire automaticamente in risposta alla domanda o a una pianificazione definita.
- Le zone di disponibilità sono località fisiche esclusive all'interno di un'area di Azure. Queste offerte a disponibilità elevata proteggono le applicazioni e i dati dagli errori dei data center.
- Gateway applicazione è un servizio di bilanciamento del carico che gestisce il traffico verso le applicazioni Web.
- Monitoraggio raccoglie e analizza i dati in ambienti e risorse di Azure. Questi dati includono i dati di telemetria delle app, ad esempio le metriche delle prestazioni e i log attività. Per altre informazioni, vedere Considerazioni sul monitoraggio più avanti in questo articolo.
- Log Analytics è uno strumento del portale di Azure che esegue query sui dati di log di Monitoraggio. Log Analytics offre anche funzionalità per la creazione di grafici e l'analisi statistica dei risultati delle query.
- Azure DevOps Services fornisce servizi, strumenti e ambienti per la gestione di progetti e distribuzioni di codice.
- Key Vault archivia in modo sicuro i segreti di sistema e ne controlla l'accesso, ad esempio chiavi API, password, certificati e chiavi crittografiche.
- Microsoft Entra ID è un servizio di gestione delle identità basato sul cloud che controlla l'accesso ad Azure e ad altre app cloud.
Alternative
- Azure Data Factory offre un'alternativa a questa soluzione.
- Invece di Key Vault, è possibile usare un servizio equivalente per archiviare i segreti di sistema.
- Apache Airflow. Scopri in che modo Airflow e NiFi sono diversi.
- È possibile usare un'alternativa NiFi aziendale supportata, ad esempio Cloudera Apache NiFi. L'offerta Cloudera è disponibile tramite Azure Marketplace.
Dettagli dello scenario
In questo scenario NiFi viene eseguito in una configurazione cluster tra macchine virtuali di Azure in un set di scalabilità. Ma la maggior parte delle raccomandazioni di questo articolo si applica anche agli scenari che eseguono NiFi in modalità a istanza singola in una singola macchina virtuale (VM). Le procedure consigliate in questo articolo illustrano una distribuzione scalabile, a disponibilità elevata e sicura.
Potenziali casi d'uso
NiFi è particolarmente indicato per lo spostamento dei dati e la gestione del flusso di dati:
- Connessione di sistemi disaccoppiati nel cloud
- Spostamento di dati da e verso Archiviazione di Azure e altri archivi dati
- Integrazione di applicazioni di cloud ibrido e dalla rete perimetrale al cloud con Azure IoT, Azure Stack e servizio Azure Kubernetes
Di conseguenza, questa soluzione è applicabile in molte aree:
Data warehouse moderni che riuniscono dati strutturati e non strutturati su larga scala. Raccolgono e archiviano dati provenienti da diverse origini, sink e formati. NiFi eccelle nell'inserimento di dati in data warehouse moderni basati su Azure per i motivi seguenti:
- Sono disponibili oltre 200 processori per la lettura, la scrittura e la manipolazione dei dati.
- Il sistema supporta servizi di archiviazione come Archiviazione BLOB di Azure, Azure Data Lake Storage, Hub eventi di Azure, Archiviazione code di Azure, Azure Cosmos DB e Azure Synapse Analytics.
- Le funzionalità affidabili di provenienza dei dati rendono possibile l'implementazione di soluzioni conformi. Per informazioni sull'acquisizione della provenienza dei dati nella funzionalità Log Analytics di Monitoraggio di Azure, vedere Considerazioni sulla creazione di report più avanti in questo articolo.
NiFi può essere eseguito in modo autonomo su dispositivi in formato ridotto. In questi casi, NiFi consente di elaborare i dati perimetrali e di spostarli in istanze o cluster NiFi più grandi nel cloud. NiFi consente di filtrare, trasformare e classificare in ordine di priorità i dati perimetrali in movimento, garantendo flussi di dati affidabili ed efficienti.
Le soluzioni di IoT industriale (IIoT) gestiscono il flusso di dati dalla rete perimetrale al data center. Tale flusso inizia con l'acquisizione dei dati da apparecchiature e sistemi di controllo industriali. I dati vengono quindi spostati in soluzioni di gestione dei dati e data warehouse moderni. NiFi offre funzionalità che lo rendono particolarmente adatto per l'acquisizione e lo spostamento dei dati:
- Funzionalità di elaborazione dei dati perimetrali
- Supporto per i protocolli usati da gateway e dispositivi IoT
- Integrazione con Hub eventi e servizi di archiviazione
Le applicazioni IoT nelle aree della manutenzione predittiva e della gestione della supply chain possono usare questa funzionalità.
Consigli
Per l'uso di questa soluzione, tenere presente quanto segue:
Versioni consigliate di NiFi
Quando si esegue questa soluzione in Azure, è consigliabile usare la versione 1.13.2 o successiva di NiFi. È possibile eseguire altre versioni, ma potrebbero richiedere configurazioni diverse da quelle descritte in questa guida.
Per installare NiFi nelle macchine virtuali di Azure, è preferibile scaricare i file binari indipendenti dalla pagina di download di NiFi. È anche possibile compilare i binari dal codice sorgente.
Versioni consigliate di ZooKeeper
Per questo carico di lavoro di esempio, è consigliabile usare le versioni 3.5.5 e successive o 3.6.x di ZooKeeper.
È possibile installare ZooKeeper nelle macchine virtuali di Azure usando i file binari indipendenti o il codice sorgente. Entrambi sono disponibili nella pagina delle versioni di Apache ZooKeeper.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Per informazioni sulla configurazione di NiFi, vedere la Guida dell'amministratore di sistema di Apache NiFi. Tenere presenti anche queste considerazioni quando si implementa questa soluzione.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
- Usare il calcolatore dei prezzi di Azure per stimare il costo delle risorse di questa architettura.
- Per una stima che includa tutti i servizi di questa architettura, ad eccezione della soluzione personalizzata di generazione di avvisi, vedere questo profilo di costo di esempio.
Considerazioni sulle VM
Le sezioni seguenti forniscono una descrizione dettagliata di come configurare le macchine virtuali NiFi:
Dimensioni della VM
Questa tabella elenca le dimensioni consigliate delle macchine virtuali da cui iniziare. Per la maggior parte dei flussi di dati per utilizzo generico, Standard_D16s_v3 è la soluzione migliore. Tuttavia, ogni flusso di dati di NiFi presenta requisiti diversi. Testare il flusso e ridimensionarlo se necessario in base ai requisiti effettivi.
Valutare la possibilità di abilitare la rete accelerata nelle macchine virtuali per migliorare le prestazioni di rete. Per altre informazioni, vedere Rete per i set di scalabilità di macchine virtuali.
| Dimensioni della VM | vCPU | Memoria in GB | Velocità effettiva massima dei dischi dati senza memorizzazione nella cache in operazioni di I/O al secondo per MBps* | Numero massimo di interfacce di rete/Larghezza di banda di rete prevista (Mbps) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12.800/192 | 4/4.000 |
| Standard_D16s_v3** | 16 | 64 | 25.600/384 | 8/8.000 |
| Standard_D32s_v3 | 32 | 128 | 51.200/768 | 8/16.000 |
| Standard_M16m | 16 | 437,5 | 10.000/250 | 8/4.000 |
* Disabilitare la memorizzazione nella cache delle operazioni di scrittura dei dischi dati per tutti i dischi dati usati nei nodi NiFi.
** È consigliabile usare questo SKU per la maggior parte dei flussi di dati per utilizzo generico. Anche gli SKU di VM di Azure con configurazioni simili di vCPU e memoria devono essere adeguati.
Sistema operativo della macchina virtuale
È consigliabile eseguire NiFi in Azure in uno dei sistemi operativi guest seguenti:
- Ubuntu 18.04 LTS o versione successiva
- CentOS 7.9
Per soddisfare i requisiti specifici del flusso di dati, è importante modificare diverse impostazioni a livello di sistema operativo, tra cui:
- Numero massimo di processi creati con copia tramite fork.
- Numero massimo di handle di file.
- Ora di accesso,
atime.
Dopo aver modificato il sistema operativo in base al caso d'uso previsto, usare Image Builder per macchine virtuali di Azure per codificare la generazione di tali immagini ottimizzate. Per indicazioni specifiche di NiFi, vedere Procedure consigliate per la configurazione nella Guida dell'amministratore di sistema di Apache NiFi.
Storage
Archiviare i vari repository NiFi nei dischi dati e non nel disco del sistema operativo per tre motivi principali:
- I flussi hanno spesso requisiti elevati in termini di velocità effettiva del disco che un singolo disco non è in grado di soddisfare.
- È consigliabile separare le operazioni del disco NiFi dalle operazioni del disco del sistema operativo.
- I repository non devono trovarsi in una risorsa di archiviazione temporanea.
Le sezioni seguenti illustrano le linee guida per la configurazione dei dischi dati. Queste linee guida sono specifiche di Azure. Per altre informazioni sulla configurazione dei repository, vedere la sezione relativa alla gestione dello stato nella Guida dell'amministratore di sistema di Apache NiFi.
Tipo e dimensioni dei dischi dati
Per configurare i dischi dati per NiFi, tenere presenti questi fattori:
- Tipo di disco
- Dimensioni del disco
- Numero totale di dischi
Nota
Per informazioni aggiornate su tipi, dimensioni e prezzi dei dischi, vedere Introduzione ai dischi gestiti di Azure.
La tabella seguente illustra i tipi di dischi gestiti attualmente disponibili in Azure. È possibile usare NiFi con uno qualsiasi di questi tipi di disco. Tuttavia, per i flussi di dati ad alta velocità effettiva, è consigliabile scegliere SSD Premium.
| Disco Ultra (NVM Express)) | SSD Premium | SSD Standard | Unità disco rigido Standard | |
|---|---|---|---|---|
| Tipo di disco | SSD | SSD | SSD | HDD |
| Dimensioni massime disco | 65.536 GB | 32.767 GB | 32.767 GB | 32.767 GB |
| Velocità effettiva massima | 2.000 MiB/s | 900 MiB/s | 750 MiB/s | 500 MiB/s |
| Operazioni di I/O al secondo max | 160.000 | 20.000 | 6.000 | 2.000 |
Usare almeno tre dischi dati per aumentare la velocità effettiva del flusso di dati. Per le procedure consigliate per la configurazione dei repository nei dischi, vedere Configurazione dei repository più avanti in questo articolo.
La tabella seguente elenca i numeri appropriati di dimensioni e velocità effettiva per ogni dimensione e tipo di disco.
| HDD Standard S15 | HDD Standard S20 | HDD Standard S30 | SSD Standard S15 | SSD Standard S20 | SSD Standard S30 | SSD Premium P15 | SSD Premium P20 | SSD Premium P30 | |
|---|---|---|---|---|---|---|---|---|---|
| Dimensioni disco in GB | 256 | 512 | 1.024 | 256 | 512 | 1.024 | 256 | 512 | 1.024 |
| Operazioni di I/O al secondo per disco | Fino a 500 | Fino a 500 | Fino a 500 | Fino a 500 | Fino a 500 | Fino a 500 | 1.100 | 2.300 | 5,000 |
| Velocità effettiva per disco | Fino a 60 MBps | Fino a 60 MBps | Fino a 60 MBps | Fino a 60 MBps | Fino a 60 MBps | Fino a 60 MBps | 125 MBps | 150 MBps | 200 MBps |
Se il sistema raggiunge i limiti delle macchine virtuali, l'aggiunta di più dischi potrebbe non aumentare la velocità effettiva:
- I limiti delle operazioni di I/O al secondo e della velocità effettiva dipendono dalle dimensioni del disco.
- Le dimensioni della macchina virtuale scelta applicano i limiti di operazioni di I/O al secondo e velocità effettiva per la macchina virtuale a tutti i dischi dati.
Per i limiti di velocità effettiva del disco a livello di macchina virtuale, vedere Dimensioni delle macchine virtuali Linux in Azure.
Memorizzazione nella cache del disco della VM
Nelle macchine virtuali di Azure, la funzionalità Memorizzazione nella cache dell'host gestisce la memorizzazione nella cache delle operazioni di scrittura su disco. Per aumentare la velocità effettiva nei dischi dati usati come repository, disattivare la memorizzazione nella cache delle operazioni di scrittura su disco impostando Memorizzazione nella cache dell'host su None.
Configurazione dei repository
Le linee guida basate su procedure consigliate per NiFi prevedono l'uso di uno o più dischi distinti per ognuno di questi repository:
- Contenuto
- FlowFile
- Provenance
Questo approccio richiede almeno tre dischi.
NiFi supporta anche lo striping a livello di applicazione. Questa funzionalità aumenta le dimensioni o le prestazioni dei repository di dati.
L'estratto seguente proviene dal file di configurazione nifi.properties. Questa configurazione prevede il partizionamento e lo striping dei repository tra i dischi gestiti collegati alle VM:
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
Per altre informazioni sulla progettazione per l'archiviazione con prestazioni elevate, vedere Archiviazione Premium di Azure: progettazione per prestazioni elevate.
Creazione di report
NiFi include un'attività di creazione di report sulla provenienza per la funzionalità Log Analytics.
È possibile usare questa attività di creazione di report per eseguire l'offload degli eventi di provenienza in una risorsa di archiviazione a lungo termine conveniente e durevole. La funzionalità Log Analytics offre un'interfaccia di query per la visualizzazione e la creazione di grafici dei singoli eventi. Per altre informazioni su queste query, vedere Query di Log Analytics più avanti in questo articolo.
È anche possibile usare questa attività con l'archiviazione volatile di provenienza in memoria. In molti scenari è quindi possibile ottenere un aumento della velocità effettiva. Questo approccio è tuttavia rischioso se è necessario conservare i dati degli eventi. Assicurarsi che l'archiviazione volatile soddisfi i requisiti di durabilità per gli eventi di provenienza. Per altre informazioni, vedere la sezione relativa al repository Provenance nella Guida dell'amministratore di sistema di Apache NiFi.
Prima di usare questo processo, creare un'area di lavoro Log Analytics nella sottoscrizione di Azure. È preferibile configurare l'area di lavoro nella stessa area del carico di lavoro.
Per configurare l'attività di creazione di report di provenienza:
- Aprire le impostazioni del controller in NiFi.
- Selezionare il menu delle attività di creazione report.
- Selezionare Create a new reporting task (Crea una nuova attività di creazione report).
- Selezionare Azure Log Analytics Reporting Task (Attività di creazione report di Log Analytics).
Lo screenshot seguente mostra il menu delle proprietà per questa attività di creazione di report:
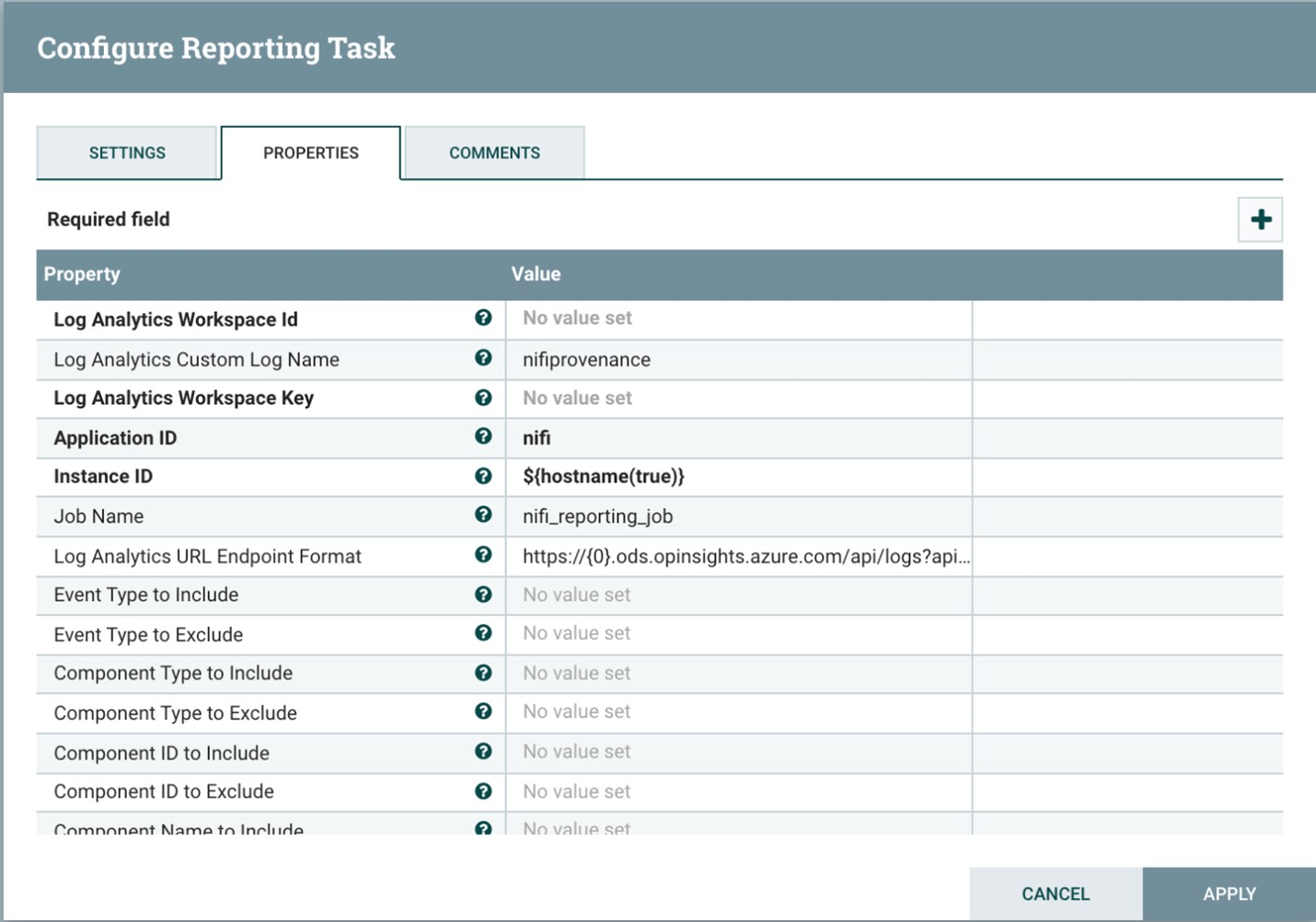
Due proprietà sono obbligatorie:
- L'ID area di lavoro Azure Log Analytics
- La chiave dell'area di lavoro Log Analytics
È possibile trovare questi valori nel portale di Azure passando all'area di lavoro Log Analytics.
Sono disponibili anche altre opzioni per personalizzare e filtrare gli eventi di provenienza inviati dal sistema.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
È possibile proteggere NiFi dal punto di vista dell'autenticazione e dell'autorizzazione. È anche possibile proteggere NiFi per tutte le comunicazioni di rete, tra cui:
- All'interno del cluster.
- Tra il cluster e ZooKeeper.
Per le istruzioni su come attivare le opzioni seguenti, vedere la Guida dell'amministratore di Apache NiFi:
- Kerberos
- Lightweight Directory Access Protocol (LDAP)
- Autenticazione e autorizzazione basate su certificato
- SSL (Secure Sockets Layer) bidirezionale per le comunicazioni del cluster
Se si attiva l'accesso client protetto di ZooKeeper, configurare NiFi aggiungendo le proprietà correlate al relativo file di configurazione bootstrap.conf. Le voci di configurazione seguenti forniscono un esempio:
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
Per raccomandazioni generali, vedere la baseline di sicurezza di Linux.
Sicurezza della rete
Quando si implementa questa soluzione, tenere presente quanto segue sulla sicurezza di rete:
Gruppi di sicurezza di rete
In Azure è possibile usare i gruppi di sicurezza di rete per limitare il traffico di rete.
È consigliabile usare un jumpbox per la connessione al cluster NiFi per le attività amministrative. Usare questa macchina virtuale con protezione avanzata con accesso JIT (Just-In-Time) o Azure Bastion. Configurare i gruppi di sicurezza di rete per controllare come concedere l'accesso al jumpbox o ad Azure Bastion. È possibile ottenere l'isolamento e il controllo della rete usando i gruppi di sicurezza di rete in modo accurato nelle varie subnet dell'architettura.
Lo screenshot seguente mostra i componenti di una tipica rete virtuale. Contiene una subnet comune per il jumpbox, il set di scalabilità di macchine virtuali e le macchine virtuali ZooKeeper. Questa topologia di rete semplificata raggruppa i componenti in un'unica subnet. Seguire le linee guida dell'organizzazione per la separazione dei compiti e la progettazione della rete.
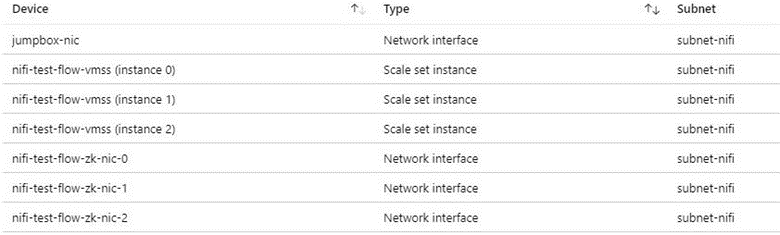
Considerazioni per l'accesso a Internet in uscita
L'esecuzione di NiFi in Azure non richiede l'accesso alla rete Internet pubblica. Se il flusso di dati non richiede l'accesso a Internet per il recupero dei dati, migliorare la sicurezza del cluster seguendo questa procedura per disabilitare l'accesso a Internet in uscita:
Creare un'ulteriore regola del gruppo di sicurezza di rete nella rete virtuale.
Usare queste impostazioni:
- Fonte:
Any - Destinazione:
Internet - Azione:
Deny
- Fonte:

Dopo aver configurato questa regola, è comunque possibile accedere ad alcuni servizi di Azure dal flusso di dati se si configura un endpoint privato nella rete virtuale. A questo scopo, usare il collegamento privato di Azure. Questo servizio consente il flusso del traffico sulla rete backbone Microsoft senza richiedere altri accessi esterni alla rete. NiFi supporta attualmente il collegamento privato per i processori di Archiviazione BLOB e Data Lake Storage. Se un server NTP (Network Time Protocol) non è disponibile nella rete privata, consentire l'accesso in uscita a NTP. Per informazioni dettagliate, vedere Sincronizzazione dell'ora per le macchine virtuali Linux in Azure.
Protezione dei dati
È possibile usare NiFi senza protezione e senza crittografia in transito, gestione delle identità e degli accessi (IAM) o crittografia dei dati. È tuttavia consigliabile proteggere le distribuzioni nell'ambiente di produzione e nel cloud pubblico adottando queste misure:
- Crittografia delle comunicazioni con TLS (Transport Layer Security)
- Uso di un meccanismo di autenticazione e autorizzazione supportato
- Crittografia dei dati inattivi
Archiviazione di Azure prevede la funzionalità Transparent Data Encryption sul lato server. Tuttavia, a partire dalla versione 1.13.2, NiFi non configura la crittografia in transito o IAM per impostazione predefinita. Questo comportamento potrebbe cambiare nelle versioni future.
Le sezioni seguenti illustrano come proteggere le distribuzioni in questi modi:
- Abilitare la crittografia in transito con TLS
- Configurare l'autenticazione basata su certificati o ID Microsoft Entra
- Gestire l'archiviazione crittografata in Azure
Crittografia del disco
Per migliorare la sicurezza, usare Crittografia dischi di Azure. Per la procedura dettagliata, vedere Crittografare il disco del sistema operativo e i dischi dati collegati in un set di scalabilità di macchine virtuali con l'interfaccia della riga di comando di Azure. Questo documento contiene anche le istruzioni su come fornire la propria chiave di crittografia. La procedura seguente illustra un esempio di base per NiFi che funziona per la maggior parte delle distribuzioni:
Per attivare la crittografia del disco in un'istanza di Key Vault esistente, usare il comando seguente dell'interfaccia della riga di comando di Azure:
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryptionAttivare la crittografia dei dischi dati del set di scalabilità di macchine virtuali con il comando seguente:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATAFacoltativamente, è possibile usare una chiave di crittografia della chiave (KEK). Usare il comando seguente dell'interfaccia della riga di comando di Azure per crittografare con una chiave KEK:
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Nota
Se il set di scalabilità di macchine virtuali è stato configurato per la modalità di aggiornamento manuale, eseguire il comando update-instances. Includere la versione della chiave di crittografia archiviata in Key Vault.
Crittografia dei dati in transito
NiFi supporta TLS 1.2 per la crittografia in transito. Questo protocollo offre protezione per l'accesso degli utenti all'interfaccia utente. Con i cluster, il protocollo protegge la comunicazione tra i nodi NiFi. Può anche proteggere la comunicazione con ZooKeeper. Quando si abilita TLS, NiFi usa il protocollo mTLS (mutual TLS) per l'autenticazione reciproca per:
- Autenticazione client basata su certificato, se è stato configurato questo tipo di autenticazione.
- Tutte le comunicazioni all'interno del cluster.
Per abilitare TLS, seguire questa procedura:
Creare un archivio chiavi e un truststore per la comunicazione e l'autenticazione tra client e server e all'interno del cluster.
Configurare
$NIFI_HOME/conf/nifi.properties. Imposta i valori seguenti:- Nomi host
- Porti
- Proprietà dell'archivio chiavi
- Proprietà del truststore
- Proprietà di sicurezza del cluster e di ZooKeeper, se applicabile
Configurare l'autenticazione in
$NIFI_HOME/conf/authorizers.xml, in genere con un utente iniziale con autenticazione basata su certificato o un'altra opzione.Facoltativamente, configurare mTLS e un criterio di lettura proxy tra NiFi ed eventuali proxy, servizi di bilanciamento del carico o endpoint esterni.
Per una procedura dettagliata completa, vedere la sezione relativa alla protezione di NiFi con TLS nella documentazione del progetto Apache.
Nota
A partire dalla versione 1.13.2:
- NiFi non abilita TLS per impostazione predefinita.
- Non è disponibile alcun supporto predefinito per l'accesso anonimo e utente singolo per le istanze di NiFi abilitate per TLS.
Per abilitare TLS per la crittografia in transito, configurare un gruppo di utenti e un provider di criteri per l'autenticazione e l'autorizzazione in $NIFI_HOME/conf/authorizers.xml. Per altre informazioni, vedere Controllo di identità e accesso più avanti in questo articolo.
Certificati, chiavi e archivi chiavi
Per supportare TLS, generare i certificati, archiviarli in Java KeyStore e TrustStore e distribuirli in un cluster NiFi. Sono disponibili due opzioni generali per i certificati:
- Certificati autofirmati
- Certificati firmati da autorità di certificazione (CA)
Con i certificati firmati dall'autorità di certificazione, è consigliabile usare una CA intermedia per generare i certificati per i nodi del cluster.
KeyStore e TrustStore sono i contenitori di chiavi e certificati nella piattaforma Java. KeyStore archivia la chiave privata e il certificato di un nodo nel cluster. TrustStore archivia uno dei tipi di certificati seguenti:
- Tutti i certificati attendibili, per i certificati autofirmati in KeyStore
- Un certificato di un'autorità di certificazione, per i certificati firmati da CA in KeyStore
Quando si sceglie un contenitore, tenere presente la scalabilità del cluster NiFi. Ad esempio, potrebbe essere necessario aumentare o ridurre il numero di nodi di un cluster in futuro. In questo caso, scegliere i certificati firmati da CA in KeyStore e uno o più certificati di una CA in TrustStore. Con questa opzione non è necessario aggiornare il truststore esistente nei nodi esistenti del cluster. Un truststore esistente considera attendibili e accetta i certificati da questi tipi di nodi:
- Nodi aggiunti al cluster
- Nodi che sostituiscono altri nodi nel cluster
Configurazione di NiFi
Per abilitare TLS per NiFi, usare $NIFI_HOME/conf/nifi.properties per configurare le proprietà in questa tabella. Assicurarsi che le proprietà seguenti includano il nome host usato per accedere a NiFi:
nifi.web.https.hostoppurenifi.web.proxy.host- Il nome designato del certificato host o nomi alternativi del soggetto
In caso contrario, potrebbe verificarsi un errore di verifica del nome host o un errore di verifica dell'intestazione HOST HTTP, negando l'accesso.
| Nome proprietà | Descrizione | Valori di esempio |
|---|---|---|
nifi.web.https.host |
Nome host o indirizzo IP da usare per l'interfaccia utente e l'API REST. Questo valore deve essere risolvibile internamente. È consigliabile non usare un nome accessibile pubblicamente. | nifi.internal.cloudapp.net |
nifi.web.https.port |
Porta HTTPS da usare per l'interfaccia utente e l'API REST. | 9443 (predefinito) |
nifi.web.proxy.host |
Elenco di nomi host alternativi delimitati da virgole che i client usano per accedere all'interfaccia utente e all'API REST. Questo elenco include in genere qualsiasi nome host specificato come nome alternativo del soggetto nel certificato del server. L'elenco può includere anche qualsiasi nome host e porta usati da un servizio di bilanciamento del carico, un proxy o un controller in ingresso Kubernetes. | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
Il percorso di un archivio chiavi JKS o PKCS12 che contiene la chiave privata del certificato. | ./conf/keystore.jks |
nifi.security.keystoreType |
Il tipo di archivio chiavi. | JKS oppure PKCS12 |
nifi.security.keystorePasswd |
La password dell'archivio chiavi. | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
(Facoltativo) La password della chiave privata. | |
nifi.security.truststore |
Il percorso di un truststore JKS o PKCS12 che contiene i certificati o i certificati della CA che autenticano gli utenti attendibili e i nodi del cluster. | ./conf/truststore.jks |
nifi.security.truststoreType |
Il tipo di truststore. | JKS oppure PKCS12 |
nifi.security.truststorePasswd |
La password del truststore. | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
Lo stato di TLS per la comunicazione all'interno del cluster. Se nifi.cluster.is.node è true, impostare questo valore su true per abilitare TLS del cluster. |
true |
nifi.remote.input.secure |
Lo stato di TLS per la comunicazione da sito a sito. | true |
L'esempio seguente illustra come vengono visualizzate queste proprietà in $NIFI_HOME/conf/nifi.properties. Si noti che i valori di nifi.web.http.host e nifi.web.http.port sono vuoti.
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
Configurazione di ZooKeeper
Per le istruzioni su come abilitare TLS in Apache ZooKeeper per le comunicazioni in quorum e l'accesso client, vedere la Guida dell'amministratore di ZooKeeper. Solo le versioni 3.5.5 o successive supportano questa funzionalità.
NiFi usa ZooKeeper per il clustering senza leader e il coordinamento dei cluster. A partire dalla versione 1.13.0, NiFi supporta l'accesso client sicuro alle istanze di ZooKeeper abilitate per TLS. ZooKeeper archivia l'appartenenza al cluster e lo stato del processore con ambito cluster in testo normale. È quindi importante usare l'accesso client sicuro a ZooKeeper per autenticare le richieste client di ZooKeeper. Crittografare anche i valori sensibili in transito.
Per abilitare TLS per l'accesso client NiFi a ZooKeeper, impostare le proprietà seguenti in $NIFI_HOME/conf/nifi.properties. Se si impostano nifi.zookeeper.client.secure true senza configurare nifi.zookeeper.security le proprietà, NiFi esegue il fallback all'archivio chiavi e all'archivio trust specificato in nifi.securityproperties.
| Nome proprietà | Descrizione | Valori di esempio |
|---|---|---|
nifi.zookeeper.client.secure |
Lo stato di TLS client durante la connessione a ZooKeeper. | true |
nifi.zookeeper.security.keystore |
Il percorso di un archivio chiavi JKS, PKCS12 o PEM che contiene la chiave privata del certificato presentato a ZooKeeper per l'autenticazione. | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
Il tipo di archivio chiavi. | JKS, PKCS12, PEM o rilevamento automatico per estensione |
nifi.zookeeper.security.keystorePasswd |
La password dell'archivio chiavi. | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
(Facoltativo) La password della chiave privata. | |
nifi.zookeeper.security.truststore |
Il percorso di un truststore JKS, PKCS12 o PEM che contiene i certificati o i certificati della CA usati per autenticare ZooKeeper. | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
Il tipo di truststore. | JKS, PKCS12, PEM o rilevamento automatico per estensione |
nifi.zookeeper.security.truststorePasswd |
La password del truststore. | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
La stringa di connessione all'host o al quorum ZooKeeper. Questa stringa è un elenco di valori host:port delimitati da virgole. In genere il valore di secureClientPort non è uguale al valore di clientPort. Per il valore corretto, vedere la configurazione di ZooKeeper. |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
L'esempio seguente illustra come vengono visualizzate queste proprietà in $NIFI_HOME/conf/nifi.properties:
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
Per altre informazioni sulla protezione di ZooKeeper con TLS, vedere la Guida all'amministrazione di Apache NiFi.
Identità e controllo di accesso
In NiFi il controllo di identità e accesso si ottiene tramite autenticazione e autorizzazione degli utenti. Per l'autenticazione utente, NiFi offre più opzioni tra cui scegliere: utente singolo, LDAP, Kerberos, SAML (Security Assertion Markup Language) e OIDC (OpenID Connect). Se non si configura un'opzione, NiFi usa i certificati client per autenticare gli utenti tramite HTTPS.
Se si sta valutando l'autenticazione a più fattori, è consigliabile combinare Microsoft Entra ID e OIDC. Microsoft Entra ID supporta l'accesso Single Sign-On (SSO) nativo del cloud con OIDC. Con questa combinazione, gli utenti possono sfruttare molte funzionalità di sicurezza aziendali:
- Registrazione e generazione di avvisi su attività sospette degli account utente
- Monitoraggio dei tentativi di accesso a credenziali disattivate
- Generazione di avvisi su comportamenti di accesso insoliti
Per l'autorizzazione, NiFi fornisce l'imposizione basata su criteri di accesso, gruppo e utente. NiFi fornisce questa imposizione tramite UserGroupProviders e AccessPolicyProviders. Per impostazione predefinita, i provider includono File, LDAP, Shell e UserGroupProvider basati su Azure Graph. Con AzureGraphUserGroupProvider è possibile usare gruppi di utenti di origine da Microsoft Entra ID. È quindi possibile assegnare criteri a questi gruppi. Per le istruzioni di configurazione, vedere la Guida all'amministrazione di Apache NiFi.
Per la gestione e l'archiviazione di criteri utente e di gruppo, sono attualmente disponibili AccessPolicyProvider basati su file e Apache Ranger. Per informazioni dettagliate, vedere la documentazione di Apache NiFi e la documentazione di Apache Ranger.
Gateway applicazione
Un gateway applicazione fornisce un servizio di bilanciamento del carico di livello 7 gestito per l'interfaccia NiFi. Configurare il gateway applicazione per usare il set di scalabilità di macchine virtuali dei nodi NiFi come pool back-end.
Per la maggior parte delle installazioni NiFi, è consigliabile usare la configurazione seguente del gateway applicazione:
- Piano: Standard.
- Dimensioni SKU: medie
- Numero di istanze: almeno due
Usare un probe di integrità per monitorare l'integrità del server Web in ogni nodo. Rimuovere i nodi non integri dalla rotazione del servizio di bilanciamento del carico. Questo approccio semplifica la visualizzazione dell'interfaccia utente quando il cluster complessivo non è integro. Il browser indirizza l'utente solo ai nodi attualmente integri e che rispondono alle richieste.
Sono disponibili due probe di integrità principali da considerare. Insieme forniscono un heartbeat regolare sull'integrità complessiva di ogni nodo del cluster. Configurare il primo probe di integrità in modo che punti al percorso /NiFi. Questo probe determina l'integrità dell'interfaccia utente NiFi in ogni nodo. Configurare un secondo probe di integrità per il percorso /nifi-api/controller/cluster. Questo probe indica se ogni nodo è attualmente integro e aggiunto al cluster complessivo.
Sono disponibili due opzioni per la configurazione dell'indirizzo IP front-end del gateway applicazione:
- Con un indirizzo IP pubblico
- Con un indirizzo IP di subnet privato
Includere un indirizzo IP pubblico solo se gli utenti devono poter accedere all'interfaccia utente tramite rete Internet pubblica. Se l'accesso alla rete Internet pubblica non è necessario per gli utenti, accedere al front-end del servizio di bilanciamento del carico da un jumpbox nella rete virtuale o tramite peering alla rete privata. Se si configura il gateway applicazione con un indirizzo IP pubblico, è consigliabile abilitare l'autenticazione del certificato client per NiFi e TLS per l'interfaccia utente NiFi. È anche possibile usare un gruppo di sicurezza di rete nella subnet del gateway applicazione delegata per limitare gli indirizzi IP di origine.
Diagnostica e monitoraggio dello stato
Nelle impostazioni di diagnostica del gateway applicazione è disponibile un'opzione di configurazione per l'invio di metriche e log di accesso. Usando questa opzione, è possibile inviare queste informazioni dal servizio di bilanciamento del carico a varie destinazioni:
- Un account di archiviazione
- Hub eventi di
- Un'area di lavoro Log Analytics
L'attivazione di questa impostazione è utile per il debug dei problemi di bilanciamento del carico e per ottenere informazioni dettagliate sull'integrità dei nodi del cluster.
La query di Log Analytics seguente mostra l'integrità dei nodi del cluster nel tempo dal punto di vista del gateway applicazione. È possibile usare una query simile per generare avvisi o azioni automatizzate di correzione per i nodi non integri.
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
Il grafico seguente dei risultati della query mostra una visualizzazione temporale dell'integrità del cluster:

Disponibilità
Quando si implementa questa soluzione, tenere presente quanto segue sulla disponibilità:
Bilanciamento del carico
Usare un servizio di bilanciamento del carico per aumentare la disponibilità dell'interfaccia utente durante il tempo di inattività del nodo.
Separare le VM
Per aumentare la disponibilità, distribuire il cluster ZooKeeper in macchine virtuali distinte da quelle del cluster NiFi. Per altre informazioni sulla configurazione di ZooKeeper, vedere la sezione relativa alla gestione dello stato nella Guida dell'amministratore di sistema di Apache NiFi.
Zone di disponibilità
Distribuire sia il set di scalabilità di macchine virtuali NiFi che il cluster ZooKeeper in una configurazione tra zone per ottimizzare la disponibilità. Quando la comunicazione tra i nodi del cluster attraversa le zone di disponibilità, introduce una piccola quantità di latenza. Tuttavia, questa latenza ha in genere un effetto complessivo minimo sulla velocità effettiva del cluster.
set di scalabilità di macchine virtuali
È consigliabile distribuire i nodi NiFi in un singolo set di scalabilità di macchine virtuali che si estende su zone di disponibilità, se disponibili. Per informazioni dettagliate sull'uso dei set di scalabilità in questo modo, vedere Creare un set di scalabilità di macchine virtuali che usa le zone di disponibilità.
Monitoraggio
Per monitorare l'integrità e le prestazioni di un cluster NiFi, usare le attività di creazione di report.
Monitoraggio basato su attività di creazione report
Per il monitoraggio, è possibile usare un'attività di creazione report configurata ed eseguita in NiFi. Come illustrato in Diagnostica e monitoraggio dello stato, Log Analytics offre un'attività di creazione report nel bundle NiFi di Azure. È possibile usare tale attività di creazione report per integrare il monitoraggio con Log Analytics e i sistemi di monitoraggio o registrazione esistenti.
Query di Log Analytics
Le query di esempio delle sezioni seguenti possono risultare utili per iniziare. Per una panoramica su come eseguire query sui dati di Log Analytics, vedere Query sui log di Monitoraggio di Azure.
Le query di log in Monitoraggio e Log Analytics usano una versione del Linguaggio di query Kusto. Esistono tuttavia differenze tra le query sui log e le query Kusto. Per altre informazioni, vedere Panoramica delle query Kusto.
Per un apprendimento più strutturato, vedere queste esercitazioni:
- Introduzione alle query su log in Monitoraggio di Azure
- Introduzione a Log Analytics in Monitoraggio di Azure
Attività di creazione report di Log Analytics
Per impostazione predefinita, NiFi invia i dati delle metriche alla tabella nifimetrics. È tuttavia possibile configurare una destinazione diversa nelle proprietà dell'attività di creazione report. L'attività di creazione report acquisisce le metriche NiFi seguenti:
| Tipo di metrica | Nome metrica |
|---|---|
| Metriche di NiFi | FlowFilesReceived |
| Metriche di NiFi | FlowFilesSent |
| Metriche di NiFi | FlowFilesQueued |
| Metriche di NiFi | BytesReceived |
| Metriche di NiFi | BytesWritten |
| Metriche di NiFi | BytesRead |
| Metriche di NiFi | BytesSent |
| Metriche di NiFi | BytesQueued |
| Metriche sullo stato delle porte | InputCount |
| Metriche sullo stato delle porte | InputBytes |
| Metriche sullo stato della connessione | QueuedCount |
| Metriche sullo stato della connessione | QueuedBytes |
| Metriche sullo stato delle porte | OutputCount |
| Metriche sullo stato delle porte | OutputBytes |
| Metriche della macchina virtuale Java (JVM) | jvm.uptime |
| Metriche di JVM | jvm.heap_used |
| Metriche di JVM | jvm.heap_usage |
| Metriche di JVM | jvm.non_heap_usage |
| Metriche di JVM | jvm.thread_states.runnable |
| Metriche di JVM | jvm.thread_states.blocked |
| Metriche di JVM | jvm.thread_states.timed_waiting |
| Metriche di JVM | jvm.thread_states.terminated |
| Metriche di JVM | jvm.thread_count |
| Metriche di JVM | jvm.daemon_thread_count |
| Metriche di JVM | jvm.file_descriptor_usage |
| Metriche di JVM | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| Metriche di JVM | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| Metriche di JVM | jvm.buff_pool_direct_capacity |
| Metriche di JVM | jvm.buff_pool_direct_count |
| Metriche di JVM | jvm.buff_pool_direct_mem_used |
| Metriche di JVM | jvm.buff_pool_mapped_capacity |
| Metriche di JVM | jvm.buff_pool_mapped_count |
| Metriche di JVM | jvm.buff_pool_mapped_mem_used |
| Metriche di JVM | jvm.mem_pool_code_cache |
| Metriche di JVM | jvm.mem_pool_compressed_class_space |
| Metriche di JVM | jvm.mem_pool_g1_eden_space |
| Metriche di JVM | jvm.mem_pool_g1_old_gen |
| Metriche di JVM | jvm.mem_pool_g1_survivor_space |
| Metriche di JVM | jvm.mem_pool_metaspace |
| Metriche di JVM | jvm.thread_states.new |
| Metriche di JVM | jvm.thread_states.waiting |
| Metriche a livello di processore | BytesRead |
| Metriche a livello di processore | BytesWritten |
| Metriche a livello di processore | FlowFilesReceived |
| Metriche a livello di processore | FlowFilesSent |
Ecco una query di esempio per la metrica BytesQueued di un cluster:
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
La query produce un grafico simile a quello illustrato in questo screenshot:

Nota
Quando si esegue NiFi in Azure, non ci si limita all'attività di creazione report di Log Analytics. NiFi supporta attività di creazione report per molte tecnologie di monitoraggio di terze parti. Per un elenco delle attività di creazione report supportate, vedere la sezione relativa alle attività di creazione report nell'indice della documentazione di Apache NiFi.
Monitoraggio dell'infrastruttura di NiFi
Oltre all'attività di creazione report, installare l'estensione della macchina virtuale Log Analytics nei nodi NiFi e ZooKeeper. Questa estensione raccoglie log, metriche aggiuntive a livello di macchina virtuale e metriche di ZooKeeper.
Log personalizzati per l'app NiFi, l'utente, il bootstrap e ZooKeeper
Per acquisire altri log, seguire questa procedura:
Nel portale di Azure selezionare Aree di lavoro di Log Analytics e quindi selezionare l'area di lavoro personale.
In Impostazioni selezionare Log personalizzati.
Selezionare Aggiungi log personalizzato.
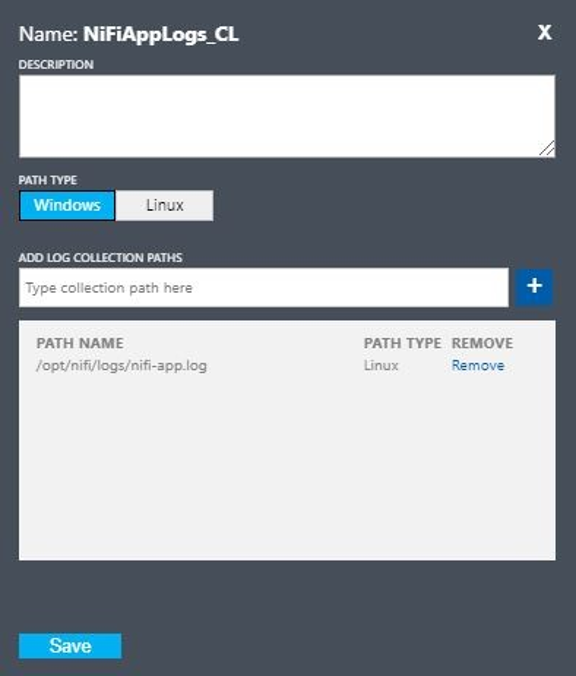
Configurare un log personalizzato con i valori seguenti:
- Nome:
NiFiAppLogs - Tipo di percorso:
Linux - Nome percorso:
/opt/nifi/logs/nifi-app.log
- Nome:
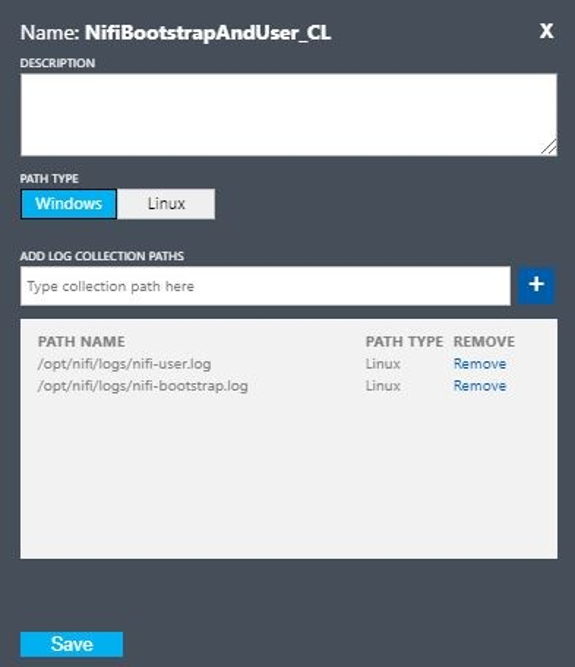
Configurare un log personalizzato con i valori seguenti:
- Nome:
NiFiBootstrapAndUser - Tipo del primo percorso:
Linux - Nome del primo percorso:
/opt/nifi/logs/nifi-user.log - Tipo del secondo percorso:
Linux - Nome del secondo percorso:
/opt/nifi/logs/nifi-bootstrap.log
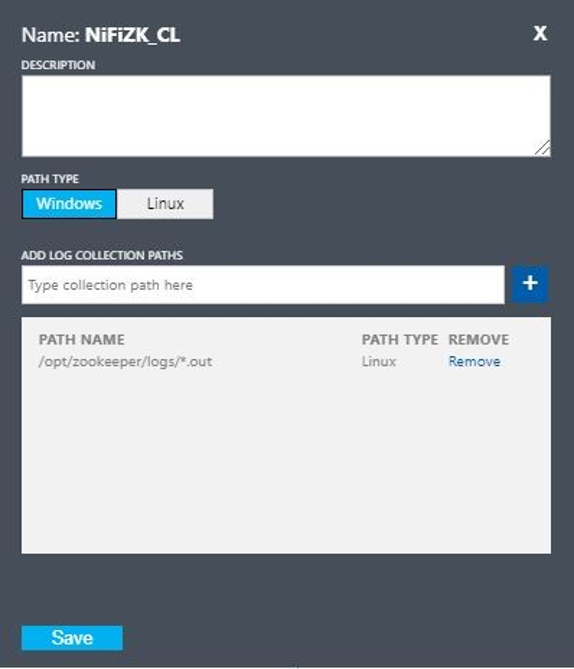
- Nome:
Configurare un log personalizzato con i valori seguenti:
- Nome:
NiFiZK - Tipo di percorso:
Linux - Nome percorso:
/opt/zookeeper/logs/*.out
- Nome:
Ecco una query di esempio della tabella NiFiAppLogs personalizzata creata nel primo esempio:
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
La query produce risultati simili ai seguenti:

Configurazione dei log dell'infrastruttura
È possibile usare Monitoraggio per monitorare e gestire macchine virtuali o computer fisici. Queste risorse possono trovarsi nel data center locale o in un altro ambiente cloud. Per configurare questo monitoraggio, distribuire l'agente di Log Analytics. Configurare l'agente per la creazione di report in un'area di lavoro Log Analytics. Per altre informazioni, vedere Panoramica dell'agente di Log Analytics.
Lo screenshot seguente mostra una configurazione dell'agente di esempio per le macchine virtuali NiFi. La tabella Perf archivia i dati raccolti.

Ecco una query di esempio per i log Perf dell'app NiFi:
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
La query produce un report simile a quello illustrato in questo screenshot:

Avvisi
Usare Monitoraggio per creare avvisi sull'integrità e sulle prestazioni del cluster NiFi. Gli avvisi di esempio includono:
- Il numero totale di code che ha superato una soglia.
- Il valore di
BytesWrittenè al di sotto di una soglia prevista. - Il valore di
FlowFilesReceivedè al di sotto di una soglia. - Il cluster non è integro.
Per altre informazioni sulla configurazione degli avvisi in Monitoraggio, vedere Panoramica degli avvisi in Microsoft Azure.
Parametri di configurazione
Le sezioni seguenti illustrano le configurazioni consigliate e non predefinite per NiFi e le relative dipendenze, tra cui ZooKeeper e Java. Queste impostazioni sono adatte per dimensioni del cluster che sono possibili nel cloud. Impostare le proprietà nei file di configurazione seguenti:
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
Per informazioni dettagliate sulle proprietà e i file di configurazione disponibili, vedere la Guida dell'amministratore di sistema di Apache NiFi e la Guida dell'amministratore di ZooKeeper.
NiFi
Per una distribuzione di Azure, è consigliabile modificare le proprietà in $NIFI_HOME/conf/nifi.properties. La tabella seguente elenca le proprietà più importanti. Per altre raccomandazioni e informazioni dettagliate, vedere le liste di distribuzione di Apache NiFi.
| Parametro | Descrizione | Default | Elemento consigliato |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
Tempo di attesa durante l'apertura di una connessione ad altri nodi del cluster. | 5 secondi | 60 secondi |
nifi.cluster.node.read.timeout |
Tempo di attesa di una risposta quando si effettua una richiesta ad altri nodi del cluster. | 5 secondi | 60 secondi |
nifi.cluster.protocol.heartbeat.interval |
Frequenza con cui inviare gli heartbeat al coordinatore del cluster. | 5 secondi | 60 secondi |
nifi.cluster.node.max.concurrent.requests |
Livello di parallelismo da usare per la replica di chiamate HTTP come chiamate API REST ad altri nodi del cluster. | 100 | 500 |
nifi.cluster.node.protocol.threads |
Dimensioni iniziali del pool di thread per le comunicazioni tra cluster/replicate. | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
Numero massimo di thread da usare per le comunicazioni tra cluster/replicate. | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
Numero di nodi da usare per decidere qual è il flusso corrente. Questo valore consente di aggirare il voto in corrispondenza del numero specificato. | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
Tempo di attesa dei nodi prima di decidere qual è il flusso corrente. | 5 minuti | 5 minuti |
Comportamento del cluster
Quando si configurano i cluster, tenere presente quanto segue.
Timeout
Per garantire l'integrità complessiva di un cluster e dei relativi nodi, può essere utile aumentare i timeout. Questa procedura consente di garantire che non vengano generati errori a causa di problemi temporanei o carichi elevati della rete.
In un sistema distribuito le prestazioni dei singoli sistemi variano. Questa variazione include le comunicazioni di rete e la latenza, che in genere influisce sulla comunicazione tra nodi e tra cluster. La variazione può essere causata dall'infrastruttura di rete o dal sistema stesso. Di conseguenza, la probabilità che si verifichi una variazione è molto alta in cluster di sistemi di grandi dimensioni. Nelle applicazioni Java in condizioni di carico, anche le pause in Garbage Collection (GC) nella macchina virtuale Java (JVM) possono influire sui tempi di risposta alle richieste.
Usare le proprietà illustrate nelle sezioni seguenti per configurare i timeout in base alle esigenze del sistema:
nifi.cluster.node.connection.timeout e nifi.cluster.node.read.timeout
La proprietà nifi.cluster.node.connection.timeout specifica il tempo di attesa all'apertura di una connessione. La proprietà nifi.cluster.node.read.timeout specifica il tempo di attesa durante la ricezione di dati tra le richieste. Il valore predefinito per ogni proprietà è cinque secondi. Queste proprietà si applicano alle richieste da nodo a nodo. Aumentando questi valori è possibile alleviare diversi problemi correlati:
- Disconnessione dal coordinatore del cluster a causa di interruzioni di heartbeat
- Mancato recupero del flusso dal coordinatore durante l'aggiunta al cluster
- Definizione delle comunicazioni da sito a sito e di bilanciamento del carico
A meno che il cluster non abbia un set di scalabilità molto piccolo, ad esempio non più di tre nodi, usare valori maggiori rispetto a quelli predefiniti.
nifi.cluster.protocol.heartbeat.interval
Come parte della strategia di clustering NiFi, ogni nodo genera un heartbeat per comunicare lo stato di integrità. Per impostazione predefinita, i nodi inviano heartbeat ogni cinque secondi. Se il coordinatore del cluster rileva che otto heartbeat di fila generati da un nodo non sono riusciti, disconnette il nodo. Aumentare l'intervallo impostato nella proprietà nifi.cluster.protocol.heartbeat.interval per supportare heartbeat lenti e impedire al cluster di disconnettere inutilmente i nodi.
Concorrenza
Usare le proprietà illustrate nelle sezioni seguenti per configurare le impostazioni di concorrenza:
nifi.cluster.node.protocol.threads e nifi.cluster.node.protocol.max.threads
La proprietà nifi.cluster.node.protocol.max.threads specifica il numero massimo di thread da usare per le comunicazioni di tutto il cluster, ad esempio il bilanciamento del carico da sito a sito e l'aggregazione dell'interfaccia utente. Il valore predefinito per questa proprietà è 50 thread. Per i cluster di grandi dimensioni, aumentare questo valore per tenere conto del numero maggiore di richieste necessarie per queste operazioni.
La proprietà nifi.cluster.node.protocol.threads determina le dimensioni iniziali del pool di thread. Il valore predefinito è 10 thread. Questo è il valore minimo. Aumenta in base alle esigenze fino al valore massimo impostato in nifi.cluster.node.protocol.max.threads. Aumentare il valore di nifi.cluster.node.protocol.threads per i cluster che usano un set di scalabilità di grandi dimensioni all'avvio.
nifi.cluster.node.max.concurrent.requests
Molte richieste HTTP, ad esempio le chiamate API REST e le chiamate all'interfaccia utente, devono essere replicate in altri nodi del cluster. Man mano che aumentano le dimensioni del cluster, viene replicato un numero crescente di richieste. La proprietà nifi.cluster.node.max.concurrent.requests limita il numero di richieste in sospeso. Il valore deve essere superiore alle dimensioni previste del cluster. Il valore predefinito è 100 richieste simultanee. A meno che non si esegua un piccolo cluster con non più di tre nodi, aumentare questo valore per evitare richieste non riuscite.
Selezione del flusso
Usare le proprietà illustrate nelle sezioni seguenti per configurare le impostazioni di selezione del flusso:
nifi.cluster.flow.election.max.candidates
NiFi usa il clustering senza leader, il che significa che non esiste un nodo autorevole specifico. Di conseguenza, i nodi votano quale definizione di flusso viene considerata corretta. Votano anche per decidere quali nodi aggiungere al cluster.
Per impostazione predefinita, la proprietà nifi.cluster.flow.election.max.candidates indica il tempo di attesa massimo specificato dalla proprietà nifi.cluster.flow.election.max.wait.time. Se questo valore è troppo elevato, l'avvio può essere lento. Il valore predefinito per nifi.cluster.flow.election.max.wait.time è cinque minuti. Impostare il numero massimo di candidati su un valore non vuoto, ad esempio 1 o superiore, per assicurarsi che l'attesa non sia più lunga del necessario. Se si imposta questa proprietà, assegnare un valore corrispondente alle dimensioni del cluster o a una frazione di maggioranza delle dimensioni previste del cluster. Per piccoli cluster statici con non più di 10 nodi, impostare questo valore sul numero di nodi del cluster.
nifi.cluster.flow.election.max.wait.time
In un ambiente cloud elastico, il tempo di provisioning degli host influisce sul tempo di avvio dell'applicazione. La proprietà nifi.cluster.flow.election.max.wait.time determina il tempo di attesa di NiFi di decidere un flusso. Assicurarsi che questo valore sia commisurato al tempo di avvio generale del cluster in corrispondenza delle dimensioni iniziali. Nei test iniziali, cinque minuti sono più che adeguati in tutte le aree di Azure con i tipi di istanza consigliati. È tuttavia possibile aumentare questo valore se il tempo di provisioning supera regolarmente il valore predefinito.
Java
È consigliabile usare una versione LTS di Java. Di queste versioni, Java 11 è leggermente preferibile a Java 8 perché supporta un'implementazione di Garbage Collection più veloce. Tuttavia, è possibile avere una distribuzione NiFi a elevate prestazioni usando una delle due versioni.
Le sezioni seguenti illustrano le configurazioni comuni di JVM da usare durante l'esecuzione di NiFi. Impostare i parametri di JVM nel file di configurazione bootstrap in $NIFI_HOME/conf/bootstrap.conf.
Garbage Collector
Se si esegue Java 11, è consigliabile usare il Garbage Collector G1 (G1GC) nella maggior parte delle situazioni. G1GC offre prestazioni superiori rispetto a ParallelGC perché riduce la lunghezza delle pause di GC. G1GC è l'impostazione predefinita in Java 11, ma è possibile configurarlo esplicitamente impostando il valore seguente in bootstrap.conf:
java.arg.13=-XX:+UseG1GC
Se si esegue Java 8, non usare G1GC. Usare invece ParallelGC. Esistono problemi nell'implementazione Java 8 di G1GC che impediscono di usarlo con le implementazioni del repository consigliate. ParallelGC è più lento di G1GC. Con ParallelGC, tuttavia, è comunque possibile avere una distribuzione NiFi a elevate prestazioni con Java 8.
Heap
Un set di proprietà nel file bootstrap.conf determina la configurazione dell'heap JVM NiFi. Per un flusso standard, configurare un heap da 32 GB usando queste impostazioni:
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
Per scegliere le dimensioni ottimali dell'heap da applicare al processo JVM, considerare due fattori:
- Le caratteristiche del flusso di dati
- Il modo in cui NiFi usa la memoria nell'elaborazione
Per la documentazione dettagliata, vedere Apache NiFi in Depth.
Impostare le dimensioni dell'heap necessarie per soddisfare i requisiti di elaborazione. Questo approccio riduce al minimo la durata delle pause di GC. Per considerazioni generali su Garbage Collection per Java, vedere la guida all'ottimizzazione di Garbage Collection per la versione di Java in uso.
Quando si modificano le impostazioni della memoria della JVM, considerare questi fattori importanti:
Il numero di FlowFile, ovvero record di dati NiFi, attivi in un determinato periodo. Questo numero include i FlowFile in coda o in contropressione.
Il numero di attributi definiti nei FlowFile.
La quantità di memoria necessaria a un processore per elaborare una particolare parte di contenuto.
Il modo in cui un processore elabora i dati:
- Streaming di dati
- Uso di processori orientati ai record
- Conservazione di tutti i dati in memoria contemporaneamente
Questi dettagli sono importanti. Durante l'elaborazione, NiFi contiene riferimenti e attributi per ogni FlowFile in memoria. Alle massime prestazioni, la quantità di memoria usata dal sistema è proporzionale al numero di FlowFile attivi e di tutti gli attributi che contengono. Questo numero include i FlowFile in coda. NiFi può eseguire lo swapping su disco. Tuttavia, evitare questa opzione perché influisce negativamente sulle prestazioni.
Tenere anche presente l'utilizzo di memoria degli oggetti di base. In particolare, rendere l'heap sufficientemente grande da contenere gli oggetti in memoria. Considerare questi suggerimenti per configurare le impostazioni di memoria:
- Eseguire il flusso con dati rappresentativi e contropressione minima iniziando con l'impostazione
-Xmx4Ge quindi aumentando la memoria gradualmente in base alle esigenze. - Eseguire il flusso con dati rappresentativi e contropressione di picco iniziando con l'impostazione
-Xmx4Ge quindi aumentando le dimensioni del cluster gradualmente in base alle esigenze. - Profilare l'applicazione mentre il flusso è in esecuzione usando strumenti come VisualVM e YourKit.
- Se gli aumenti graduali nell'heap non migliorano in modo significativo le prestazioni, è consigliabile riprogettare i flussi, i processori e altri aspetti del sistema.
Parametri di JVM aggiuntivi
La tabella seguente elenca ulteriori opzioni della JVM. Fornisce anche i valori che si sono rivelati ottimali nei test iniziali. I test hanno comportato l'osservazione dell'attività di GC e l'utilizzo della memoria ed è stata usata un'attenta profilatura.
| Parametro | Descrizione | Valore predefinito di JVM | Elemento consigliato |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
La quantità di heap in uso prima dell'attivazione di un ciclo di contrassegni. | 45 | 35 |
ParallelGCThreads |
Il numero di thread usati da GC. Questo valore è limitato per ridurre l'effetto complessivo sul sistema. | 5/8 del numero di vCPU | 8 |
ConcGCThreads |
Il numero di thread di GC da eseguire in parallelo. Questo valore viene aumentato per tenere conto dei ParallelGCThreads limitati. | 1/4 del valore di ParallelGCThreads |
4 |
G1ReservePercent |
La percentuale di memoria di riserva da mantenere libera. Questo valore viene aumentato per evitare l'esaurimento dello spazio, evitando così l'esecuzione completa di GC. | 10 | 20 |
UseStringDeduplication |
Indica se provare a identificare e deduplicare i riferimenti a stringhe identiche. L'attivazione di questa funzionalità può comportare un risparmio di memoria. | - | present |
Configurare queste impostazioni aggiungendo le voci seguenti a bootstrap.conf di NiFi:
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
Per una migliore tolleranza di errore, eseguire ZooKeeper come cluster. Adottare questo approccio anche se la maggior parte delle distribuzioni di NiFi impone un carico relativamente contenuto su ZooKeeper. Attivare il clustering per ZooKeeper in modo esplicito. Per impostazione predefinita, ZooKeeper viene eseguito in modalità server singolo. Per informazioni dettagliate, vedere la sezione relativa alla configurazione in cluster (multiserver) nella Guida dell'amministratore di ZooKeeper.
Ad eccezione delle impostazioni di clustering, usare i valori predefiniti per la configurazione di ZooKeeper.
Se si dispone di un cluster NiFi di grandi dimensioni, potrebbe essere necessario usare un numero maggiore di server ZooKeeper. Per i cluster di dimensioni inferiori, sono sufficienti VM di dimensioni ridotte e dischi gestiti SSD Standard.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Muazma Zahid | Principal PM Manager
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
Il materiale e le raccomandazioni di questo documento provengono da diverse fonti:
- Sperimentazione
- Procedure consigliate per Azure
- Conoscenze, procedure consigliate e documentazione della community NiFi
Per ulteriori informazioni, vedi le seguenti risorse:
- Guida dell'amministratore di sistema di Apache NiFi
- Liste di distribuzione di Apache NiFi
- Procedure consigliate di Cloudera per la configurazione di un'installazione di NiFi a elevate prestazioni
- Archiviazione Premium di Azure: progettata per prestazioni elevate
- Risolvere i problemi relativi alle prestazioni delle macchine virtuali di Azure in Linux o Windows
Risorse correlate
- Distribuzioni basate su Helm per Apache NiFi
- Monitoraggio di Azure Esplora dati
- [Estrazione ibrida, trasformazione, caricamento (ETL) con Azure Data Factory] [ETL ibrido con Azure Data Factory]
- [DataOps per il data warehouse moderno] [DataOps per il data warehouse moderno]
- Data warehousing e analisi