In un tipico caso di frode online, il ladro effettua più transazioni, causando una perdita di migliaia di dollari. Ecco perché il rilevamento delle frodi deve avvenire quasi in tempo reale. Più di 800 milioni di persone usano app per dispositivi mobili. Con l'aumentare del numero, aumenta anche la frode della banca mobile. L'industria finanziaria sta riscontrando un aumento del 100% dell'anno in perdite causate dall'accesso da piattaforme mobili. Ma c'è una mitigazione. Questo articolo presenta una soluzione che usa la tecnologia Di Azure per stimare una transazione fraudolenta della banca mobile entro due secondi. L'architettura presentata qui si basa su una soluzione reale.
Sfide: rari casi di frode e regole rigide
La maggior parte delle frodi mobili si verifica quando un attacco di scambio SIM viene usato per compromettere un numero di cellulare. Il numero di telefono viene clonato e il criminale riceve le notifiche SMS e le chiamate inviate al dispositivo mobile della vittima. Il criminale ottiene quindi le credenziali di accesso usando social engineering, phishing, vishing (usando un telefono per il phish) o un'app scaricata infetti. Con queste informazioni, il criminale può rappresentare un cliente bancario, registrarsi per l'accesso mobile e generare immediatamente trasferimenti di fondi e prelievi.
Le frodi mobili sono difficili da rilevare e costose per i consumatori e le banche. La prima sfida è che è raro. Meno del 1% di tutte le transazioni sono fraudolente, quindi può richiedere tempo per un team di gestione di frodi o casi per analizzare le transazioni potenzialmente fraudolente per identificare quelle fraudolente. Una seconda sfida è che molte soluzioni di monitoraggio delle frodi si basano su motori basati su regole. Tradizionalmente, i motori basati su regole sono efficaci per rilevare modelli stabiliti di transazioni simili a frodi generate da indirizzi IP rischiosi o più transazioni generate entro un breve periodo in un nuovo account. Ma i motori basati su regole presentano una limitazione significativa: le regole non si adattano rapidamente a tipi di attacchi nuovi o in continua evoluzione. Sono vincolati nei modi seguenti:
- Il rilevamento non è in tempo reale, quindi le frodi vengono rilevate dopo che si verifica una perdita finanziaria.
- Le regole sono binarie e limitate. Non supportano la complessità e le combinazioni di variabili di input che possono essere valutate. Questa limitazione comporta un numero elevato di falsi positivi.
- Le regole sono hardcoded nella logica di business. La cura delle regole, l'incorporamento di nuove origini dati o l'aggiunta di nuovi modelli di frode richiedono in genere modifiche alle applicazioni che influiscono su un processo aziendale. La propagazione delle modifiche in un processo aziendale può essere complessa e costosa.
I modelli di intelligenza artificiale possono migliorare notevolmente i tassi di rilevamento delle frodi e i tempi di rilevamento. Le banche usano questi modelli insieme ad altri approcci per ridurre le perdite. Il processo descritto di seguito si basa su tre elementi:
- Un modello di intelligenza artificiale che agisce su un set derivato di caratteristiche comportamentali
- Metodologia per l'apprendimento automatico
- Un processo di valutazione del modello simile a quello usato da un responsabile delle frodi per valutare un portfolio
Contesto operativo
Per la banca su cui si basa questa soluzione, poiché i clienti hanno aumentato l'uso dei servizi digitali, si è verificato un picco di frode nel canale mobile. È stato il momento per la banca di riconsiderare il suo approccio al rilevamento e alla prevenzione delle frodi. Questa soluzione ha iniziato con domande che hanno interessato il processo di frode e le decisioni:
- Quali attività o transazioni sono probabilmente fraudolente?
- Quali account vengono compromessi?
- Quali attività richiedono ulteriori indagini e gestione dei casi?
Affinché la soluzione fornisca valore, è necessario comprendere chiaramente in che modo le frodi bancarie mobili diventano evidenti nell'ambiente operativo:
- Quali tipi di frode vengono perpetuati sulla piattaforma?
- Come viene eseguito il commit?
- Quali sono i modelli nelle attività fraudolente e nelle transazioni?
Le risposte a queste domande hanno portato a una comprensione dei tipi di comportamento che possono segnalare frodi. Gli attributi dei dati sono stati mappati ai messaggi, raccolti dai gateway applicazione per dispositivi mobili, correlati ai comportamenti identificati. Il comportamento dell'account più rilevante per determinare le frodi è stato quindi profilato.
La tabella seguente identifica i tipi di compromissione, gli attributi dei dati che potrebbero segnalare frodi e comportamenti rilevanti per la banca:
| Compromissioni delle credenziali* | Compromissioni dei dispositivi | Compromessi finanziari | Compromessi non transazionali | |
|---|---|---|---|---|
| Metodi utilizzati | Phishing, vishing. | Scambio SIM, vishing, malware, jailbreaking, emulatori di dispositivo. | Uso delle credenziali dell'account e degli identificatori digitali dell'utente e del dispositivo (ad esempio indirizzi di posta elettronica e fisici). | Aggiunta di nuovi utenti all'account, all'aumento dei limiti di carte o account, alla modifica dei dettagli dell'account e delle informazioni o della password del profilo del cliente. |
| Dati | Indirizzo di posta elettronica o password, numeri di carta di credito o di debito, PIN selezionati dal cliente o monouso. | ID dispositivo, numero di scheda SIM, georilevazione e IP. | Importi delle transazioni, trasferimento, prelievo o beneficiari dei pagamenti. | Dettagli dell'account. |
| Criteri | Nuovo cliente digitale (non registrato in precedenza) con una carta e un PIN esistenti. Accessi non riusciti per gli utenti che non esistono o sono sconosciuti. Accessi durante gli intervalli di tempo insoliti per l'account. Più tentativi di modificare le password di accesso. |
Irregolarità geografiche (accesso da una posizione insolita). Accesso da più dispositivi in un breve periodo di tempo. |
Modelli nelle transazioni. Ad esempio, molte piccole transazioni registrate per lo stesso conto in breve tempo, a volte seguite da un prelievo di grandi dimensioni. Oppure pagamenti, prelievi o trasferimenti effettuati per gli importi massimi consentiti. Frequenza insolita delle transazioni. |
Modelli negli accessi e nella sequenza di attività. Ad esempio, più accessi entro un breve periodo di tempo, più tentativi di modificare le informazioni di contatto o l'aggiunta di dispositivi durante un intervallo di tempo insolito. |
* L'indicatore più comune di compromissione. Precede compromessi finanziari e non finanziari.
La dimensione comportamentale è fondamentale per rilevare le frodi mobili. I profili basati sul comportamento possono aiutare a stabilire modelli di comportamento tipici per un account. L'analisi può indicare un'attività che sembra non rientrare nella norma. Di seguito sono riportati alcuni esempi di tipi di comportamento che possono essere profilati:
- Quanti account sono associati al dispositivo?
- Quanti dispositivi sono associati all'account? Con quale frequenza vengono eliminati o aggiunti?
- Con quale frequenza viene eseguito l'accesso al dispositivo o al cliente?
- Con quale frequenza il cliente modifica le password?
- Qual è l'importo medio del trasferimento monetario o del prelievo dal conto?
- Con quale frequenza vengono effettuati prelievi dal conto?
La soluzione usa un approccio basato su:
- Progettazione di funzionalità per creare profili comportamentali per clienti e account.
- Azure Machine Learning per creare un modello di classificazione delle frodi per un comportamento sospetto o incoerente dell'account.
- Servizi di Azure per l'elaborazione di eventi in tempo reale e il flusso di lavoro end-to-end.
Architettura di alto livello

Scaricare un file di Visio di questa architettura.
Flusso di dati
In questa architettura sono disponibili tre flussi di lavoro:
Una pipeline guidata dagli eventi inserisce ed elabora i dati di log, crea e gestisce profili di account comportamentali, incorpora un modello di classificazione delle frodi e produce un punteggio predittivo. La maggior parte dei passaggi di questa pipeline inizia con una funzione di Azure. Le funzioni di Azure vengono usate perché sono serverless, con scalabilità orizzontale e pianificate. Questo carico di lavoro richiede l'elaborazione di milioni di transazioni mobili in ingresso e la valutazione di frodi quasi in tempo reale.
Un flusso di lavoro di training del modello combina i dati cronologici delle frodi locali e i dati di log inseriti. Questo carico di lavoro è orientato al batch e usato per il training del modello e la ripetizione del training. Azure Data Factory orchestra i passaggi di elaborazione, tra cui:
- Caricamento di dati cronologici di illeciti cronologici etichettati da origini locali.
- Archivio di set di funzionalità di dati e cronologia dei punteggi per tutte le transazioni.
- Estrazione di eventi e messaggi in un formato strutturato per la ripetizione e la ripetizione del training dei modelli e della progettazione delle funzionalità.
- Training e ripetizione del training di un modello di frode tramite Azure Machine Learning.
Il terzo flusso di lavoro si integra con i processi aziendali back-end. È possibile usare App per la logica di Azure per connettersi e sincronizzarsi con un sistema locale per creare un caso di gestione delle frodi, sospendere l'accesso all'account o generare un contatto telefonico.
L'architettura è fondamentale per la pipeline di dati e il modello di intelligenza artificiale, illustrati più avanti in questo articolo.
La soluzione si integra con l'ambiente locale della banca usando un bus di servizio aziendale (ESB) e una connessione di rete efficiente.
Pipeline di dati e automazione
Quando un criminale ha accesso a un conto bancario tramite un'app per dispositivi mobili, la perdita finanziaria può verificarsi in pochi minuti. Un rilevamento efficace dell'attività di frode deve verificarsi mentre il criminale interagisce con l'applicazione mobile e prima che si verifichi una transazione monetaria. Il tempo necessario per reagire a una transazione fraudolenta influisce direttamente sulla quantità di perdita finanziaria che può essere impedita. Prima si verifica il rilevamento, meno la perdita finanziaria.
Meno di due secondi, e idealmente molto meno, è la quantità massima di tempo dopo l'inoltro di un'attività di mobile banking per l'elaborazione che deve essere valutata per frode. Questo è ciò che deve accadere durante questi due secondi:
- Raccogliere un evento JSON complesso.
- Convalidare, autenticare, analizzare e trasformare il codice JSON.
- Creare funzionalità dell'account dagli attributi dei dati.
- Inviare la transazione per l'inferenza.
- Recuperare il punteggio delle frodi.
- Eseguire la sincronizzazione con un sistema di gestione dei casi back-end.
La latenza e i tempi di risposta sono fondamentali in una soluzione di rilevamento delle frodi. L'infrastruttura per supportarla deve essere veloce e scalabile.
Elaborazione di eventi
Gli eventi di telemetria dei gateway applicazione per dispositivi mobili e Internet della banca vengono formattati come file JSON con uno schema definito in modo libero. Questi eventi vengono trasmessi come dati di telemetria dell'applicazione a Hub eventi di Azure, in cui una funzione di Azure in un ambiente del servizio app dedicato orchestra l'elaborazione.
Il diagramma seguente illustra le interazioni fondamentali per una funzione di Azure all'interno di questa infrastruttura:
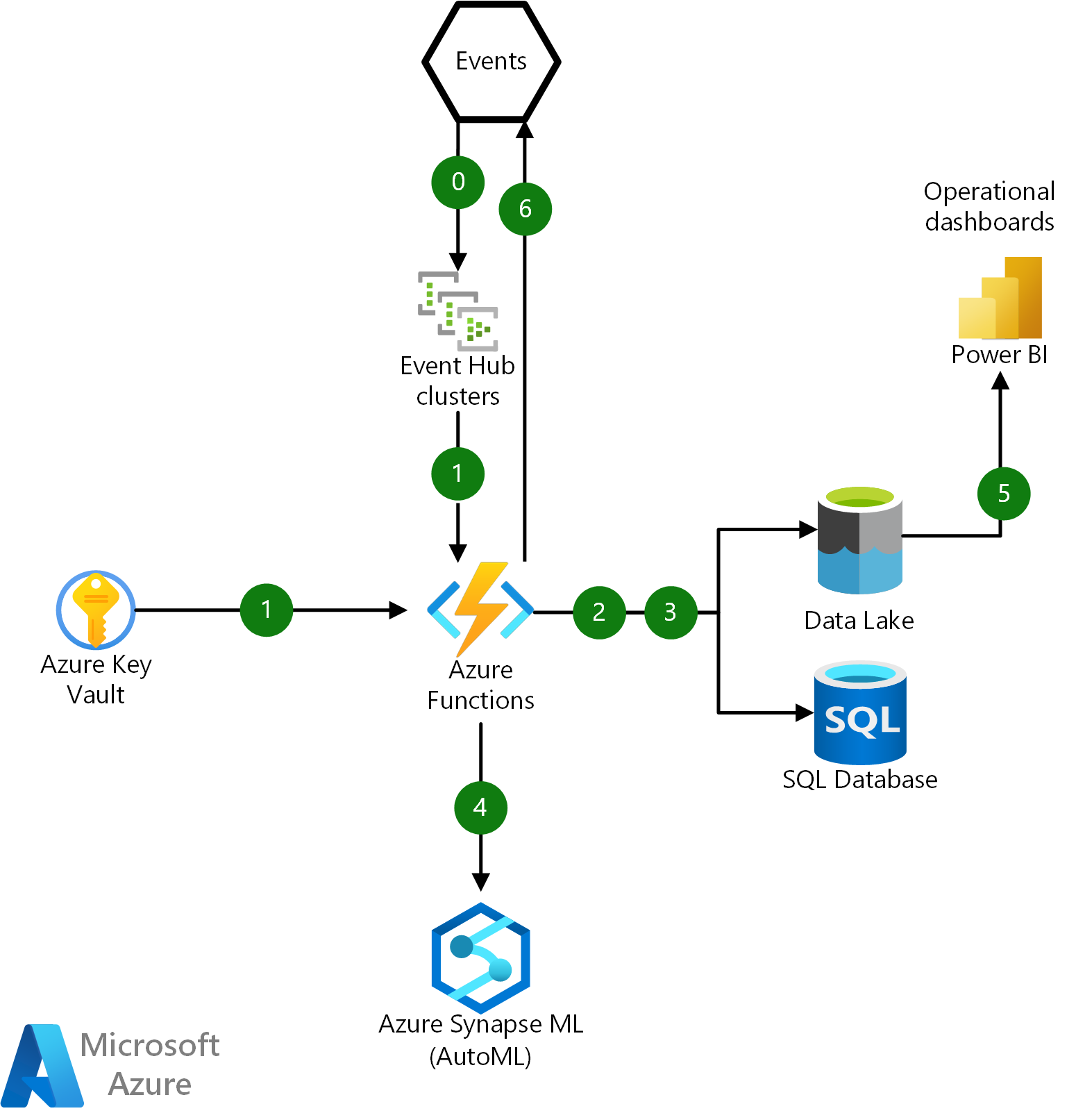
Scaricare un file di Visio di questa architettura.
Flusso di dati
- Inserire il payload dell'evento JSON non elaborato da Hub eventi ed eseguire l'autenticazione usando un certificato SSL recuperato da Azure Key Vault.
- Coordinare la deserializzazione, l'analisi, l'archiviazione e la registrazione dei messaggi JSON non elaborati in Azure Data Lake e nella cronologia delle transazioni finanziarie degli utenti in database SQL di Azure.
- Aggiornare e recuperare i profili utente e dispositivo da database SQL e Data Lake.
- Chiamare un endpoint di Azure Machine Learning per eseguire un modello predittivo e ottenere un punteggio di frode. Rendere persistente il risultato dell'inferenza in un data lake per l'analisi operativa.
- Connessione Power BI a Data Lake tramite Azure Synapse Analytics per un dashboard di analisi operativa in tempo reale.
- Pubblicare i risultati con punteggio come evento in un sistema locale per ulteriori indagini e attività di gestione delle frodi.
Pre-elaborazione dei dati e trasformazione JSON
Nello scenario reale su cui si basa questa soluzione, la pre-elaborazione dei dati è un passaggio integrale nella formattazione dei dati per lo sviluppo e il training dei modelli di Machine Learning. Ci sono stati anni di eventi storici per dispositivi mobili e internet banking, inclusi i dati delle transazioni dai dati di telemetria del gateway applicazione in formato JSON. Erano presenti centinaia di migliaia di file che contengono più eventi che dovevano essere deserializzati e appiattiti e puliti per il training del modello di Machine Learning.
Ogni gateway applicazione produce dati di telemetria dall'interazione di un utente, acquisendo informazioni come il sistema operativo, i metadati del dispositivo mobile, i dati dell'account e le richieste e le risposte delle transazioni. C'era una variazione tra i file JSON e gli attributi e i tipi di dati erano diversi e incoerenti. Un'altra complicazione con i file JSON è che gli attributi e i tipi di dati potrebbero cambiare in modo imprevisto man mano che gli aggiornamenti dell'applicazione sono stati inseriti nei gateway e le funzionalità sono stati rimossi, modificati o aggiunti. I problemi di trasformazione dei dati con gli schemi includono quanto segue:
- Un file JSON può includere una o più interazioni tramite telefono cellulare. Ogni interazione deve essere estratta come messaggio separato.
- I campi possono essere denominati o rappresentati in modo diverso.
- I caratteri come le nuove righe o i ritorni a capo sono incorporati in modo incoerente nei messaggi.
- Gli attributi come gli indirizzi di posta elettronica potrebbero essere mancanti o parzialmente formattati.
- Potrebbero esserci proprietà e valori annidati complessi.
Un pool di Spark viene usato come parte del percorso a freddo per elaborare i file JSON cronologici e per deserializzare, appiattire ed estrarre attributi di dispositivo e transazione. Ogni file JSON viene convalidato e analizzato e gli attributi della transazione vengono estratti e salvati in modo permanente in un data lake e partizionati in base alla data della transazione.
Questi attributi vengono usati in un secondo momento per creare funzionalità per il classificatore di frodi. La potenza di questa soluzione si basa sulla possibilità di standardizzare, unire e aggregare dati JSON con dati cronologici per creare profili di comportamento.
Elaborazione dei dati quasi in tempo reale e definizione delle caratteristiche con database SQL
In questa soluzione, gli eventi vengono generati da più origini, inclusi record di autenticazione, informazioni sui clienti e dati demografici, record delle transazioni e dati di log e attività dai dispositivi mobili. database SQL viene usato per eseguire l'analisi dei dati in tempo reale, la pre-elaborazione e la definizione delle funzionalità perché SQL ha familiarità con molti sviluppatori.
La funzionalità HTAP è necessaria per recuperare la cronologia del comportamento dell'account utente per un determinato dispositivo nei sette giorni precedenti per calcolare le funzionalità quasi in tempo reale con bassa latenza. In database SQL vengono usate le funzionalità HTAP (Hybrid Transaction/Analytical Processing):
- Le tabelle ottimizzate per la memoria archiviano i profili account. Le tabelle ottimizzate per la memoria presentano vantaggi rispetto alle tabelle SQL tradizionali perché vengono create e accessibili nella memoria principale. Viene evitata la latenza e il sovraccarico dell'accesso al disco. Il requisito per questa soluzione consiste nell'elaborare 300 messaggi JSON al secondo. Le tabelle ottimizzate per la memoria forniscono questo livello di velocità effettiva.
- Le tabelle ottimizzate per la memoria sono accessibili in modo più efficiente dalle stored procedure compilate in modo nativo. A differenza delle stored procedure interpretate, le stored procedure compilate in modo nativo vengono compilate quando vengono create per la prima volta.
- Una tabella temporale è una tabella che mantiene automaticamente la cronologia delle modifiche. Quando una riga viene aggiunta o aggiornata, la versione viene scritta nella tabella di cronologia. In questa soluzione i profili account vengono archiviati in una tabella temporale con criteri di conservazione di 7 giorni, quindi le righe vengono rimosse automaticamente dopo il periodo di conservazione.
Questo approccio offre anche questi vantaggi:
- Accesso ai dati archiviati per l'analisi operativa, la ripetizione del training del modello di Machine Learning e la convalida delle frodi
- Archiviazione dei dati semplificata nell'archiviazione a lungo termine
- Scalabilità tramite partizionamento orizzontale dei dati e uso di un database elastico
Gestione dello schema di eventi
L'automazione della gestione dello schema è un'altra sfida da risolvere per questa soluzione. JSON è un formato di file flessibile e portabile, in parte perché uno schema non viene archiviato con i dati. Quando i file JSON devono essere analizzati, deserializzati ed elaborati, uno schema che rappresenta la struttura del codice JSON deve essere codificato in un punto qualsiasi per convalidare le proprietà dei dati e i tipi di dati. Se lo schema non è sincronizzato con il messaggio JSON in ingresso, la convalida JSON ha esito negativo e i dati non vengono estratti.
La sfida si verifica quando la struttura dei messaggi JSON cambia a causa della nuova funzionalità dell'applicazione. Nella soluzione originale, la banca per cui questa soluzione è stata creata ha distribuito più gateway applicazione, ognuno con la propria interfaccia utente, funzionalità, dati di telemetria e struttura di messaggi JSON. Quando lo schema non è sincronizzato con i dati JSON in ingresso, le incoerenze hanno creato ritardi di perdita ed elaborazione dei dati per il rilevamento delle frodi.
La banca non ha definito uno schema formale per questi eventi e le costanti fluttuazioni nella struttura dei file JSON hanno creato un debito tecnico a ogni iterazione della soluzione. Questa soluzione risolve il problema stabilendo uno schema per questi eventi e usando Registro schemi di Azure. Registro schemi di Azure offre un repository centrale di schemi per eventi e flessibilità per i produttori e le applicazioni consumer per lo scambio di dati senza dover gestire e condividere lo schema. Il semplice framework di governance introdotto per gli schemi riutilizzabili e la relazione che definisce tra gli schemi tramite i costrutti di raggruppamento (gruppi di schemi) può eliminare un notevole debito tecnico, applicare la conformità e garantire la compatibilità con le versioni precedenti tra gli schemi che cambiano.
Progettazione di funzionalità per Machine Learning
Le funzionalità consentono di profilare il comportamento dell'account aggregando le attività su diverse scale temporali. Vengono creati dai dati nei log applicazioni che rappresentano il comportamento transazionale, non transazionale e del dispositivo. Il comportamento transazionale include attività monetarie come pagamenti e prelievi. Il comportamento non transazionale include azioni utente come tentativi di accesso e modifiche della password. Il comportamento del dispositivo include attività che coinvolgono un dispositivo mobile, ad esempio l'aggiunta o la rimozione di un dispositivo. Le funzionalità vengono usate per rappresentare il comportamento dell'account corrente e passato, tra cui:
- Nuovi tentativi di registrazione utente da un dispositivo specifico.
- Tentativi di accesso riusciti e non riusciti.
- Richieste di aggiunta di beneficiari o beneficiari di terzi.
- Richieste di aumento dei limiti dell'account o della carta di credito.
- Modifiche della password.
Una tabella del profilo account contiene attributi delle transazioni JSON, ad esempio l'ID messaggio, il tipo di transazione, l'importo del pagamento, il giorno della settimana e l'ora del giorno. Le attività vengono aggregate in più intervalli di tempo, ad esempio un'ora, un giorno e sette giorni e archiviate come cronologia dei comportamenti per ogni account. Ogni riga della tabella rappresenta un singolo account. Ecco alcune delle funzionalità seguenti:
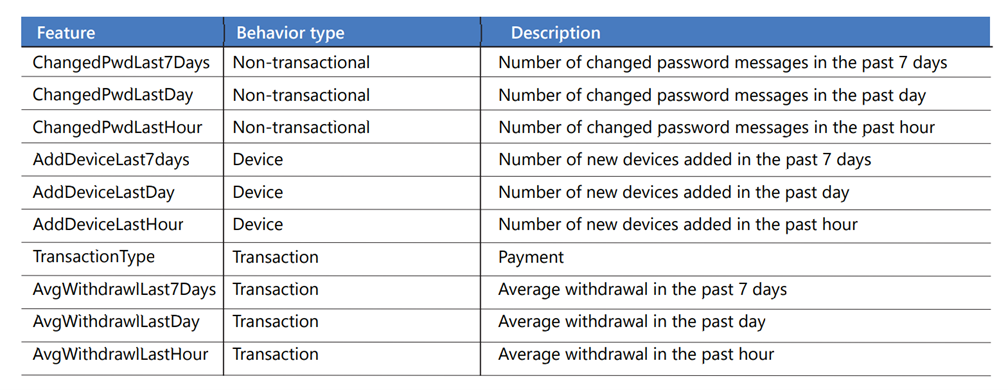
Dopo aver calcolato le funzionalità dell'account e aver aggiornato il profilo, una funzione di Azure chiama il modello di Machine Learning per l'assegnazione dei punteggi tramite un'API REST per rispondere a questa domanda: Qual è la probabilità che questo account si trovi in uno stato di frode, in base al comportamento riscontrato?
AutoML
AutoML viene usato nella soluzione perché è veloce e facile da usare. AutoML può essere un punto di partenza utile per l'individuazione rapida e l'apprendimento perché non richiede conoscenze o configurazioni specializzate. Automatizza le attività iterative e dispendiose in termini di tempo dello sviluppo di modelli di Machine Learning. I data scientist, gli analisti e gli sviluppatori possono usarli per creare modelli di Machine Learning con scalabilità elevata, efficienza e produttività, mantenendo al contempo la qualità del modello.
AutoML può eseguire le attività seguenti in un processo di Machine Learning:
- Suddividere i dati in set di dati di training e convalida
- Ottimizzare il training in base a una metrica scelta
- Eseguire la convalida incrociata
- Generare funzionalità
- Attribuire i valori mancanti
- Eseguire la codifica one-hot e vari scaler
Squilibrio dei dati
La classificazione delle frodi è complessa a causa dello squilibrio di classe grave. In un set di dati di frodi sono presenti molte più transazioni non fraudolente rispetto alle transazioni fraudolente. In genere, meno del 1% di un set di dati contiene transazioni fraudolente. Se non viene risolto, questo squilibrio può causare un problema di credibilità nel modello perché tutte le transazioni potrebbero finire classificate come non fraudolente. Il modello potrebbe perdere completamente tutte le transazioni fraudolente e ottenere comunque un tasso di accuratezza del 99%.
AutoML consente di ridistribuire i dati e di creare un migliore equilibrio tra transazioni fraudolente e non fraudolente:
- AutoML supporta l'aggiunta di una colonna di pesi come input, causando l'aumento o la riduzione delle righe nei dati, che possono rendere una classe meno importante. Gli algoritmi usati da AutoML rilevano uno squilibrio quando il numero di campioni nella classe di minoranza è uguale o inferiore al 20% del numero di campioni nella classe di maggioranza. Successivamente, AutoML esegue l'esperimento con dati sottocampionati per verificare se l'uso dei pesi della classe risolve questo problema e migliora le prestazioni. Se determina che le prestazioni sono migliori a causa dell'esperimento, viene applicato il rimedio.
- È possibile usare una metrica di misurazione delle prestazioni che gestisce meglio i dati sbilanciati. Ad esempio, se il modello deve essere sensibile ai falsi negativi, usare
recall. Quando il modello deve essere sensibile ai falsi positivi, usareprecision. È anche possibile usare un punteggio F1. Questo punteggio è la media armonica traprecisionerecall, quindi non è influenzato da un numero elevato di veri positivi o veri negativi. Potrebbe essere necessario calcolare manualmente alcune metriche durante la fase di test.
In alternativa, per aumentare il numero di transazioni classificate come fraudolente, è possibile usare manualmente una tecnica denominata Tecnica di sovracampionamento delle minoranze sintetiche (SMOTE). SMOTE è una tecnica statistica che usa bootstrapping e k-nearest neighbor (KNN) per produrre istanze della classe di minoranza.
Training del modello
Per il training del modello, Python SDK prevede dati in formato dataframe pandas o come set di dati tabulare di Azure Machine Learning. Il valore da stimare deve trovarsi nel set di dati. La colonna y viene passata come parametro quando si crea il processo di training.
Ecco un esempio di codice, con commenti:
data = https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.7)
label_column_name = "Class"
automl_settings = {
"n_cross_validations": 3, # Number of cross validation splits.
"primary_metric": "average_precision_score_weighted", # This is the metric that you want to optimize.
"experiment_timeout_hours": 0.25, # Percentage of an hour you want this to run.
"verbosity": logging.INFO, # Logging info level, debug, info, warning, error, critical.
"enable_stack_ensemble": False, # VotingEnsembled is enabled by default.
}
automl_config = AutoMLConfig(
task="classification",
debug_log="automl_errors.log",
training_data=training_data,
label_column_name=label_column_name,
**automl_settings,
)
local_run = experiment.submit(automl_config, show_output=True)
Nel codice:
- Caricare il set di dati in un set di dati tabulare di Azure Machine Learning o in un dataframe pandas.
- Suddividere il set di dati in training del 70% e convalida del 30%.
- Creare una variabile per la colonna da stimare.
- Iniziare a creare i parametri AutoML.
- Configurare
AutoMLConfig.taskè il tipo di Machine Learning da eseguire:classificationoregression. In questo caso, usareclassification.debug_logè il percorso in cui sono scritte le informazioni di debug.training_dataè il dataframe o l'oggetto tabulare in cui vengono caricati i dati di training.label_column_nameè la colonna che si vuole stimare.
- Eseguire il processo di Machine Learning.
Valutazione del modello
Un buon modello produce risultati realistici e interattivi. Questa è una delle sfide con un modello di rilevamento delle frodi. La maggior parte dei modelli di rilevamento delle frodi produce una decisione binaria per determinare se una transazione è fraudolenta. La decisione si basa su due fattori:
- Punteggio di probabilità compreso tra 0 e 100 restituito dall'algoritmo di classificazione
- Soglia di probabilità stabilita dall'azienda. Al di sopra della soglia viene considerata fraudolenta e al di sotto della soglia viene considerata non fraudolenta.
Probabilità è una metrica standard per qualsiasi modello di classificazione. Ma in genere non è sufficiente in uno scenario di frode per decidere se bloccare un account per evitare ulteriori perdite.
In questa soluzione, le metriche a livello di account vengono create e inserite nella decisione di decidere se l'azienda deve agire per bloccare un account. Le metriche a livello di account sono definite in base a queste metriche standard del settore:
| Problema del responsabile delle frodi | Metrico | Descrizione |
|---|---|---|
| Sto rilevando frodi? | Tasso di rilevamento degli account illeciti (ADR) | Percentuale di account illeciti rilevati in tutti gli account illeciti. |
| Quanto denaro sto risparmiando (prevenzione della perdita)? Quanto ritarderà la reazione a un costo di avviso? | Frequenza di rilevamento dei valori (VDR) | La percentuale di risparmi monetari, presupponendo che la transazione di frode corrente attivi un'azione di blocco sulle transazioni successive, su tutte le perdite di frodi. |
| Quanti clienti sono inconvenienza? | Rapporto di falsi positivi dell'account | Numero di account non fraudolenti che vengono contrassegnati per ogni frode reale rilevata (al giorno). Rapporto degli account falsi positivi rilevati rispetto agli account fraudolenti rilevati. |
Queste metriche sono punti dati importanti per un responsabile delle frodi. Il manager li usa per ottenere un quadro più completo del rischio dell'account e decidere la correzione.
Operazionalizzazione e ripetizione del training del modello
I modelli predittivi devono essere aggiornati periodicamente. Nel corso del tempo e, man mano che diventano disponibili dati nuovi e diversi, è necessario ripetere il training di un modello predittivo. Ciò vale soprattutto per i modelli di rilevamento delle frodi in cui sono frequenti nuovi modelli di attività criminale. Diventa inoltre necessario quando i dati di telemetria dai log dell'applicazione per dispositivi mobili cambiano a causa di modifiche di cui è stato eseguito il push nel gateway applicazione. Per fornire la ripetizione del training in questa soluzione, vengono registrate tutte le transazioni inviate per l'analisi e le metriche di valutazione del modello corrispondenti. Nel corso del tempo, le prestazioni del modello sono monitorate. Quando sembra degradare, viene attivato un flusso di lavoro di ripetizione del training. Diversi servizi di Azure vengono usati nel flusso di lavoro di ripetizione del training:
È possibile usare Azure Synapse Analytics o Azure Data Lake per archiviare i dati cronologici dei clienti. È possibile usare questi servizi per archiviare le transazioni fraudolente note caricate da origini locali e dati archiviati dal servizio Web di Azure Machine Learning, incluse transazioni, stime e metriche di valutazione del modello. I dati necessari per la ripetizione del training vengono archiviati in questo archivio dati.
È possibile usare le pipeline di Data Factory o Azure Synapse per orchestrare il flusso di dati e il processo per la ripetizione del training, tra cui:
- Estrazione di dati cronologici e file di log dai sistemi locali.
- Processo di deserializzazione JSON.
- Logica di pre-elaborazione dei dati.
Per informazioni dettagliate, vedere Ripetere il training e aggiornare i modelli di Azure Machine Learning con Azure Data Factory.
È possibile usare distribuzioni blu-verde in Azure Machine Learning. Per informazioni sulla distribuzione di un nuovo modello con tempi di inattività minimi, vedere Cassaforte'implementazione per gli endpoint online.
Componenti
- Funzioni di Azure fornisce funzioni di codice serverless basate su eventi e un'esperienza di sviluppo end-to-end.
- Hub eventi è un servizio di inserimento dati completamente gestito in tempo reale. È possibile usarlo per trasmettere milioni di eventi al secondo da qualsiasi origine.
- Key Vault crittografa le chiavi crittografiche e altri segreti usati da app e servizi cloud.
- Azure Machine Learning è un servizio di livello aziendale per il ciclo di vita di Machine Learning end-to-end.
- AutoML è un processo per automatizzare le attività iterative e dispendiose in termini di tempo dello sviluppo di modelli di Machine Learning.
- database SQL di Azure è un servizio di database relazionale completamente gestito e sempre aggiornato creato per il cloud.
- Azure Synapse Analytics è un servizio di analisi illimitato che riunisce l'integrazione dei dati, il data warehousing aziendale e l'analisi dei Big Data.
Considerazioni tecniche
Per selezionare i componenti tecnologici corretti per un'infrastruttura basata sul cloud in modo continuo per il rilevamento delle frodi, è necessario comprendere i requisiti correnti e talvolta vaghi. Le scelte tecnologiche per questa soluzione sono basate su considerazioni che potrebbero aiutare a prendere decisioni simili.
Competenze
Prendere in considerazione i set di competenze tecnologici correnti dei team che progettano, implementano e mantengono la soluzione. Le tecnologie cloud e di intelligenza artificiale espandono le scelte disponibili per l'implementazione di una soluzione. Ad esempio, se il team ha competenze di base per l'analisi scientifica dei dati, Azure Machine Learning è una scelta ottimale per la creazione e l'endpoint del modello. La decisione di usare Hub eventi è un altro esempio. Hub eventi è un servizio gestito facile da configurare e gestire. Esistono vantaggi tecnici per l'uso di un'alternativa come Kafka, ma questa operazione potrebbe richiedere formazione.
Ambiente operativo ibrido
La distribuzione per questa soluzione si estende su un ambiente locale e sull'ambiente Azure. I servizi, le reti, le applicazioni e le comunicazioni devono funzionare in modo efficace in entrambe le infrastrutture per supportare il carico di lavoro. Le decisioni relative alla tecnologia includono:
- Come sono integrati gli ambienti?
- Quali sono i requisiti di connettività di rete tra il data center di Azure e l'infrastruttura locale? Azure ExpressRoute viene usato perché fornisce due righe, ridondanza e failover. La VPN da sito a sito non fornisce la sicurezza o la qualità del servizio (QoS) necessaria per il carico di lavoro.
- In che modo i punteggi di rilevamento delle frodi si integrano con i sistemi back-end? Le risposte di assegnazione dei punteggi devono essere integrate con flussi di lavoro di frode back-end per automatizzare la verifica delle transazioni con i clienti o altre attività di gestione dei casi. È possibile usare Funzioni di Azure o App per la logica per integrare i servizi di Azure con i sistemi locali.
Sicurezza
L'hosting di una soluzione nel cloud crea nuove responsabilità di sicurezza. Nel cloud la sicurezza è una responsabilità condivisa tra un fornitore del cloud e un tenant del cliente. Le responsabilità del carico di lavoro variano a seconda che il carico di lavoro sia un servizio SaaS, PaaS o IaaS. Per altre informazioni, vedere Responsabilità condivisa nel cloud.
Sia che si stia passando a un approccio Zero Trust o si stia lavorando per applicare i requisiti di conformità alle normative, la protezione di una soluzione end-to-end richiede un'attenta pianificazione e considerazione. Per la progettazione e la distribuzione, è consigliabile adottare principi di sicurezza coerenti con un approccio Zero Trust. L'adozione di principi come verificare in modo esplicito, usare l'accesso con privilegi minimi e presupporre che la violazione rafforza la sicurezza del carico di lavoro.
Verificare in modo esplicito è il processo di analisi e valutazione di vari aspetti di una richiesta di accesso. Ecco alcuni dei principi seguenti:
- Usare una piattaforma di identità avanzata come Microsoft Entra ID.
- Comprendere il modello di sicurezza per ogni servizio cloud e come vengono protetti i dati e l'accesso.
- Quando possibile, usare l'identità gestita e le entità servizio per controllare l'accesso ai servizi cloud.
- Archiviare chiavi, segreti, certificati ed artefatti dell'applicazione, ad esempio stringhe di database, URL di endpoint REST e chiavi API in Key Vault.
L'accesso con privilegi minimi consente di garantire che le autorizzazioni vengano concesse solo per soddisfare specifiche esigenze aziendali da un ambiente appropriato a un client appropriato. Ecco alcuni dei principi seguenti:
- Compartimentare i carichi di lavoro limitando la quantità di accesso a un componente o a una risorsa tramite assegnazioni di ruolo o accesso alla rete.
- Non consentire l'accesso pubblico a endpoint e servizi. Usare gli endpoint privati per proteggere i servizi, a meno che il servizio non richieda l'accesso pubblico.
- Usare le regole del firewall per proteggere gli endpoint di servizio o isolare i carichi di lavoro usando le reti virtuali.
Si supponga che la violazione sia una strategia per guidare le decisioni di progettazione e distribuzione. La strategia consiste nel presupporre che una soluzione sia stata compromessa. Si tratta di un approccio per creare resilienza in un carico di lavoro pianificando il rilevamento, la risposta e la correzione di una minaccia per la sicurezza. Per le decisioni relative alla progettazione e alla distribuzione, implica che:
- I componenti del carico di lavoro sono isolati e segmentati in modo che una compromissione di un componente riduca al minimo l'impatto sui componenti upstream o downstream.
- I dati di telemetria vengono acquisiti e analizzati in modo proattivo per identificare anomalie e potenziali minacce.
- L'automazione è in grado di rilevare, rispondere e correggere una minaccia.
Ecco alcune linee guida da considerare:
- Crittografare i dati inattivi e in transito.
- Abilitare il controllo per i servizi.
- Acquisire e centralizzare i log di controllo e i dati di telemetria in un'unica area di lavoro log per facilitare l'analisi e la correlazione.
- Abilitare Microsoft Defender per il cloud per cercare configurazioni potenzialmente vulnerabili e fornire un avviso anticipato dei potenziali problemi di sicurezza.
La rete è uno dei fattori di sicurezza più importanti. Per impostazione predefinita, gli endpoint dell'area di lavoro di Azure Synapse sono endpoint pubblici. Ciò significa che è possibile accedervi da qualsiasi rete pubblica, pertanto è consigliabile disabilitare l'accesso pubblico all'area di lavoro. Valutare la possibilità di distribuire Azure Synapse con la funzionalità managed Rete virtuale abilitata per aggiungere un livello di isolamento tra l'area di lavoro e altri servizi di Azure. Per altre informazioni sui Rete virtuale gestiti e altri fattori di sicurezza, vedere il white paper sulla sicurezza di Azure Synapse Analytics: Sicurezza di rete.

Scaricare un file di Visio di questa architettura.
Nella tabella seguente sono incluse indicazioni sulla sicurezza specifiche di ogni componente della soluzione della banca. Per un buon punto di partenza, vedere Azure Security Benchmark, che include le baseline di sicurezza per ognuno dei singoli servizi di Azure. Le raccomandazioni della baseline di sicurezza consentono di selezionare le impostazioni di configurazione della sicurezza per ogni servizio.
Per altre informazioni, vedere Zero Trust Guidance Center.
Scalabilità
La soluzione deve eseguire tempi di punta end-to-end. Un flusso di lavoro di streaming per la gestione di milioni di eventi in arrivo continuamente richiede una velocità effettiva elevata. Pianificare la creazione di un sistema di test che simula il volume e la concorrenza per assicurarsi che i componenti tecnologici siano configurati e ottimizzati per soddisfare le latenze necessarie. I test di scalabilità sono particolarmente importanti per questi componenti:
- Inserimento dati per gestire flussi di dati simultanei. In questa architettura, Hub eventi viene usato perché è possibile distribuire e assegnare più istanze a gruppi di consumer diversi. Un approccio con scalabilità orizzontale è un'opzione migliore perché la scalabilità verticale può causare il blocco. Un approccio con scalabilità orizzontale è anche più adatto se si prevede di espandere il rilevamento delle frodi da mobile banking per includere un canale di internet banking.
- Framework per gestire e pianificare il flusso del processo. Funzioni di Azure viene usato per orchestrare il flusso di lavoro. Per migliorare la velocità effettiva, i messaggi vengono raggruppati in micro batch ed elaborati tramite una singola funzione di Azure anziché elaborare un messaggio per ogni chiamata di funzione.
- Processo di dati a bassa latenza per gestire l'analisi, la pre-elaborazione, le aggregazioni e l'archiviazione. Nella soluzione reale su cui si basa questo articolo, le funzionalità delle funzioni SQL ottimizzate per la memoria soddisfano i requisiti di scalabilità e concorrenza.
- Assegnazione dei punteggi del modello per gestire le richieste simultanee. Con i servizi Web di Azure Machine Learning sono disponibili due opzioni per il ridimensionamento:
- Selezionare un livello Web di produzione per supportare il carico di lavoro di concorrenza dell'API.
- Aggiungere più endpoint a un servizio Web se è necessario supportare più di 200 richieste simultanee.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autori principali:
- Kate Baroni | Principal Customer Engineer
- Michael Hlobil | Principal Customer Engineering Manager
- Cedric Labuschagne | Technical Program Manager
- Frank Garofalo | Principal Customer Engineer
- Shep Sheppard | Senior Service Engineer
Altro collaboratore:
- Mick Alberts | Writer tecnico
Passaggi successivi
- Una pipeline di Big Data veloce, serverless e basata su una singola funzione di Azure
- Prendere in considerazione Funzioni di Azure per uno scenario di streaming di dati serverless
- Considerazioni sulla rete per l'ambiente del servizio app
- Hub eventi
- Insieme di credenziali delle chiavi di
- Azure Machine Learning