Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Applica a:![]() Azure SQL Database
Azure SQL Database
Questo articolo offre una panoramica della funzionalità di replica geografica attiva per Azure SQL Database, che consente di replicare continuamente i dati da un database primario a un database secondario leggibile. Il database secondario leggibile potrebbe trovarsi nella stessa area Azure primaria o, più comunemente, in un'area diversa. Questo tipo di database secondario leggibile è noto anche come geo-secondario o geo-replica.
La georeplicazione attiva è configurata per ogni database. Per eseguire il failover di gruppi di database o se l'applicazione richiede un endpoint di connessione stabile, considerare i gruppi di failover.
È anche possibile eseguire la migrazione del database SQL con la replica geografica attiva.
Panoramica
La replica geografica attiva è progettata come soluzione di continuità aziendale. La replica geografica attiva consente di eseguire un rapido ripristino di emergenza dei singoli database in caso di disastro regionale o di interruzione su larga scala. Dopo aver configurato la replica geografica, è possibile avviare un failover geografico in un'area secondaria geografica in una regione Azure diversa. Il failover geografico viene iniziato programmanticamente dall'applicazione oppure manualmente dall'utente.
Il seguente diagramma illustra una configurazione tipica di un'applicazione cloud con ridondanza geografica tramite la replica geografica attiva.
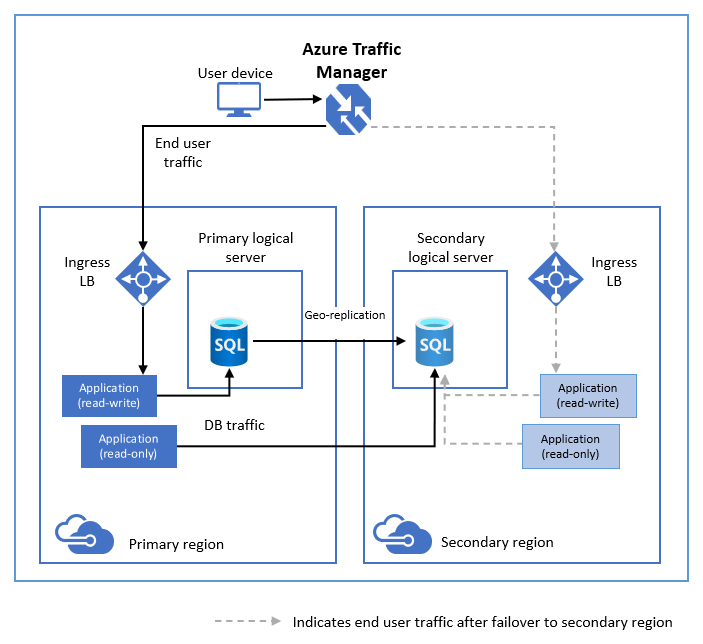
Se per qualsiasi motivo il database primario restituisce un errore, è possibile avviare il failover in uno dei database secondari. Quando un database secondario viene promosso a primario, tutti gli altri database secondari vengono automaticamente collegati al nuovo database primario.
È possibile gestire la replica geografica e avviare un failover geografico usando uno dei seguenti metodi:
- Portale Azure
- PowerShell: singolo database
- PowerShell: pool di risorse elastiche
- Transact-SQL: singolo database o pool elastico
- API REST: database singolo
La replica geografica attiva sfrutta la tecnologia del gruppo di disponibilità Always On per replicare in modo asincrono i log delle transazioni generati nella replica primaria in tutte le repliche geografiche. Anche se a un certo punto i dati del database secondario possono essere leggermente indietro rispetto al database primario, viene comunque garantita la coerenza transazionale per i dati nel database secondario. In altre parole, le modifiche apportate dalle transazioni di cui non è stato eseguito il commit non sono visibili.
Nota
La replica geografica attiva riproduce le modifiche tramite lo streaming del log delle transazioni del database dalla replica primaria alle repliche secondarie. Non è correlato alla replica transazionale, che replica le modifiche eseguendo comandi DML (INSERT, UPDATE, DELETE) nei sottoscrittori.
La replica geografica offre ridondanza a livello regionale. La ridondanza a livello di area consente alle applicazioni di eseguire rapidamente il ripristino da una perdita permanente di un'intera area Azure o da parti di un'area, causate da calamità naturali, errori umani irreversibili o atti dannosi. La replica geografica RPO è disponibile in Continuità aziendale in Azure SQL Database.
La figura seguente illustra un esempio di replica geografica attiva configurata con il database primario nell'area Stati Uniti occidentali 2 e il database geografico secondario nell'area Stati Uniti orientali.

Oltre al ripristino di emergenza, la replica geografica attiva può essere usata negli scenari seguenti:
- Migrazione di un database: è possibile usare la replica geografica attiva per eseguire la migrazione di un database da un server a un altro con un tempo di inattività minimo.
- Aggiornamenti dell'applicazione: È possibile creare un secondario aggiuntivo come copia di backup durante gli aggiornamenti dell'applicazione.
Per ottenere una continuità aziendale completa, l'aggiunta di ridondanza dei database a livello di area rappresenta solo una parte della soluzione. Per ripristinare un'applicazione (servizio) end-to-end dopo un problema grave, è necessario effettuare il ripristino di tutti i componenti del servizio e gli eventuali servizi dipendenti. Esempi di questi componenti includono il software client (ad esempio, un browser con JavaScript personalizzato), front-end Web, spazio di archiviazione e DNS. È di importanza cruciale che tutti i componenti siano resilienti agli stessi problemi e diventino disponibili entro l'obiettivo del tempo di ripristino (RTO) dell'applicazione. È perciò necessario identificare tutti i servizi dipendenti e comprendere quali garanzie e funzionalità vengono fornite. È quindi necessario intraprendere le azioni appropriate per assicurare il funzionamento del servizio durante il failover dei servizi da cui dipende. Per altre informazioni sulla progettazione di soluzioni per il ripristino di emergenza, vedere Progettazione di servizi disponibili globalmente tramite Azure SQL Database.
Terminologia e capacità
Replica asincrona automatica: è possibile creare solo un database secondario geografico per un database esistente. Il database geografico secondario può essere creato in qualsiasi server logico diverso dal server con il database primario. Dopo averlo creata, la replica geografica secondaria viene popolata con i dati copiati dal database primario. Questo processo è noto come seeding. Dopo aver creato ed eseguito il seeding del database geografico secondario, gli aggiornamenti al database primario vengono replicati automaticamente in modo asincrono nella replica geografica secondaria. Replica asincrona significa che le transazioni vengono sottoposte a commit nel database primario prima di essere replicate.
Repliche geo-secondarie leggibili: un'applicazione può accedere a una replica geografica secondaria per eseguire query di sola lettura usando le stesse o diverse entità di sicurezza usate per accedere al database primario. Per maggiori informazioni, vedere Utilizzare le repliche di sola lettura per distribuire i carichi di lavoro delle query in sola lettura.
Importante
È possibile usare la replica geografica per creare repliche secondarie nella stessa area del database primario. È possibile usare questi database secondari per soddisfare scenari di scalabilità orizzontale in lettura nella stessa area. Tuttavia, una replica secondaria nella stessa area non offre resilienza aggiuntiva a errori irreversibili o interruzioni su larga scala, pertanto non è una destinazione di failover adatta per scopi di ripristino di emergenza. Non garantisce inoltre l'isolamento della zona di disponibilità. Usare la configurazione con ridondanza della zona per i livelli di servizio business critical o premium oppure la configurazione con ridondanza della zona per il livello di servizio di utilizzo generico per ottenere l'isolamento della zona di disponibilità.
Failover (nessuna perdita di dati): quando viene avviato un failover (nessuna perdita di dati), viene completato un passaggio di sincronizzazione dei dati completo prima di cambiare i ruoli dei database primari e secondari geografici. In questo modo non si verifica alcuna perdita di dati. La durata del failover dipende dalle dimensioni del log delle transazioni nel database primario, che deve essere sincronizzato con la replica geografica secondaria. Il failover è progettato per i seguenti scenari:
- Eseguire esercitazioni di Disaster Recovery in produzione quando la perdita di dati non è accettabile
- Spostare il database in un'altra regione
- Restituire il database nella regione primaria dopo aver mitigato l'interruzione (failback).
Failover forzato (potenziale perdita di dati): il failover forzato passa immediatamente il database geografico secondario al ruolo primario senza attendere la sincronizzazione con il database primario. Le transazioni di cui è stato eseguito il commit al database primario, ma che non sono state ancora replicate nel database secondario, vengono perse. L'operazione è progettata come metodo di ripristino durante le interruzioni quando il database primario non è accessibile, ma la disponibilità del database deve essere ripristinata rapidamente. Quando il database primario originale è di nuovo online, viene riconnesso automaticamente, inviato di nuovo usando i dati correnti dal database primario e diventa il nuovo database geografico secondario.
Importante
Dopo il failover o il failover forzato, l'endpoint di connessione per il nuovo database primario cambia perché il nuovo database primario si trova ora in un server logico diverso.
- Più repliche secondarie geografiche leggibili: è possibile creare fino a quattro repliche secondarie geografiche per un database primario. Se è presente un solo database secondario e si verifica un errore, l'applicazione rimane esposta a maggiori rischi finché non viene creato un nuovo database secondario. Se sono presenti più database secondari, l'applicazione rimane protetta, anche se uno dei database secondari smette di funzionare. I database secondari aggiuntivi possono anche essere usati per espandere i carichi di lavoro di sola lettura.
Suggerimento
Se si utilizza la geo-replicazione attiva per sviluppare un'applicazione distribuita a livello globale ed è necessario fornire l'accesso in sola lettura ai dati in più di quattro aree, è possibile creare una secondaria di una secondaria (un processo noto come concatenamento) per creare ulteriori geo-repliche. Il ritardo di replica nelle repliche geografiche concatenate potrebbe essere superiore a quello delle repliche geografiche connesse direttamente al database primario. La configurazione di topologie di replica geografica concatenati è supportata solo a livello di codice e non dal portale di Azure.
Replica geografica dei database in un pool elastico: ogni replica geografica secondaria può essere un database singolo o un database in un pool elastico. La scelta del pool elastico per ogni database geografico secondario è separata e non dipende dalla configurazione di nessun'altra replica nella topologia (sia primaria che secondaria). Ogni pool elastico è contenuto all'interno di un singolo server logico. Poiché i nomi di database in un server logico devono essere univoci, più database secondari geografici dello stesso database primario non possono mai condividere un pool elastico.
Failover geografico controllato dall'utente e failback: un database secondario geografico che ha terminato il seeding iniziale può essere impostato in modo esplicito sul ruolo primario (failover) in qualsiasi momento dall'applicazione o dall'utente. Durante un'interruzione in cui il database primario è inaccessibile, è possibile usare solo il failover forzato, che promuove immediatamente un database geografico secondario a nuovo database primario. Quando l'interruzione è attenuata, il sistema rende automaticamente il database primario ripristinato un database geografico secondario e lo aggiorna con il nuovo database primario. A causa della natura asincrona della replica geografica, le transazioni recenti potrebbero andare perse durante i failover forzati qualora il database primario abbia esito negativo prima che queste transazioni vengano replicate in un database geografico secondario. Quando un database primario con più database geografici secondari esegue il failover, il sistema riconfigura automaticamente le relazioni di replica e collega i database geografici secondari rimanenti al nuovo database primario appena alzato di livello senza alcun intervento da parte dell'utente. Dopo aver risolto l'interruzione del servizio che ha causato il failover, è opportuno ripristinare il database nell'area originale. Per farlo, eseguire un failover manuale.
Replica standby: se la replica secondaria viene usata solo per il ripristino di emergenza e non dispone di carichi di lavoro di lettura o scrittura, è possibile designare la replica come standby per risparmiare sui costi di licenza.
Prepararsi al failover geografico
Per assicurarsi che l'applicazione possa accedere immediatamente al nuovo database primario dopo il failover geografico, verificare che l'autenticazione e l'accesso alla rete per il server secondario siano configurati correttamente. Per informazioni dettagliate, vedere Configurare e gestire la sicurezza di Azure SQL Database per il ripristino geografico o il failover. Verificare anche che i criteri di conservazione dei backup nel database secondario corrispondano a quello del database primario. L'impostazione non fa parte del database e non viene replicata dal database primario. Per impostazione predefinita, la geo-secondaria è configurata con un periodo di conservazione PITR predefinito di sette giorni. Per altre informazioni, vedere Backup automatici in Azure SQL Database.
Importante
Se il database è membro di un gruppo di failover, non è possibile avviarne il failover con il comando di failover di replica geografica. Usare il comando di failover per il gruppo. Se è necessario eseguire il failover di un singolo database, occorre rimuoverlo prima dal gruppo di failover. Vedere Panoramica dei gruppi difailover e procedure consigliate (Azure SQL Database) per informazioni dettagliate.
Configurare il database geografico secondario
I database primari e geografici secondari devono avere lo stesso livello di servizio. È vivamente consigliato che il sito secondario geografico sia configurato con la stessa ridondanza di archiviazione di backup, livello di calcolo (provisioning o serverless) e dimensioni di calcolo (DTU o vCore) del sito primario. Se il database primario riscontra un carico di lavoro a elevato utilizzo di scrittura, è possibile che un database secondario geografico con dimensioni di calcolo inferiori non riesca a restare al passo. Ciò causa il ritardo della replica nel database geografico secondario e potrebbe causarne l'indisponibilità. Per attenuare questi rischi, la replica geografica attiva riduce (limita) la frequenza del log delle transazioni del database primario, se necessario, per consentire ai database secondari di stare al passo con le modifiche.
Un'altra conseguenza di una configurazione geografica secondaria sbilanciata è che, dopo il failover, le prestazioni dell'applicazione possono ridursi a causa di una capacità di calcolo insufficiente del nuovo database primario. In tal caso, è necessario aumentare le prestazioni del database per avere risorse sufficienti, che potrebbero richiedere tempo significativo e un failover a disponibilità elevata alla fine del processo di aumento delle prestazioni, che può interrompere i carichi di lavoro dell'applicazione.
Suggerimento
Per indicazioni dettagliate sulla risoluzione dei problemi relativi al ritardo con la replica geografica, vedere Risolvere i problemi relativi al ritardo di replica geografica.
Se si decide di creare la replica geografica secondaria con una configurazione diversa, è necessario monitorare la frequenza di I/O del log nel tempo primario. In questo modo sarà possibile stimare le dimensioni minime di calcolo necessarie per il geo-secondario per supportare il carico di replica. Ad esempio, se il database primario è P6 (1000 DTU) e il relativo I/O di log è sostenuto a 50%, il database geografico secondario deve essere almeno P4 (500 DTU). Per recuperare i dati di I/O dei log cronologici, usare la visualizzazione sys.resource_stats . Per recuperare i dati di I/O del log recenti con una granularità più elevata che riflette meglio i picchi a breve termine, usare la visualizzazione sys.dm_db_resource_stats .
Suggerimento
La limitazione delle operazioni di I/O del log delle transazioni può verificarsi negli scenari seguenti:
- Se la replica geografica secondaria ha una dimensione di calcolo inferiore rispetto a quella primaria. Cercare il tipo di attesa nelle viste
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLOe sys.dm_os_wait_stats. - La limitazione può verificarsi anche per motivi non correlati alle dimensioni di calcolo, ad esempio nei carichi di lavoro pesanti per inserimenti massivi,
SELECT INTO, e costruzioni di indice. Per ulteriori informazioni sui tipi di attesa relativi a diverse modalità di limitazione dell'I/O dei log, vedere Gestione della frequenza del log delle transazioni.
Per impostazione predefinita, la ridondanza dell'archivio di backup del database geografico secondario è la stessa del database primario. È possibile scegliere di configurare un database geografico secondario con una ridondanza dell'archiviazione di backup diversa. I backup vengono eseguiti sempre nel database primario. Se il database secondario è configurato con una ridondanza dell'archiviazione di backup diversa, dopo un failover geografico, quando il database geografico secondario viene alzato di livello al database primario, i nuovi backup vengono archiviati e fatturati in base al tipo di archiviazione (RA-GRS, ZRS, LRS) selezionato nel nuovo database primario (secondario precedente).
Risparmiare sui costi con la replica standby
Se la replica secondaria viene usata solo per il ripristino di emergenza e non dispone di carichi di lavoro di lettura o scrittura, è possibile risparmiare sui costi di licenza designando il database per lo standby quando si configura una nuova relazione di replica geografica attiva.
Per maggiori informazioni, vedere replica standby senza licenza.
Replica geografica tra sottoscrizioni
È possibile usare il portale di Azure per configurare la replica geografica attiva tra sottoscrizioni, purché entrambe le sottoscrizioni si trovino nello stesso tenant Microsoft Entra.
- Per creare una replica geografica secondaria in una sottoscrizione different dalla sottoscrizione del database primario in un tenant Microsoft Entra diverso, usare l'autenticazione SQL e T-SQL. Autenticazione Microsoft Entra per Azure SQL per la replica geografica tra diverse sottoscrizioni non è supportata quando un server logico si trova in un diverso tenant di Azure
- Le operazioni di replica geografica tra sottoscrizioni, inclusa la configurazione e il failover geografico, sono supportate usando le API REST per la creazione e l’aggiornamento dei database.
La creazione di un'area geografica secondaria tra sottoscrizioni in un server logico, nello stesso o in un diverso tenant di Microsoft Entra, non è supportata quando l'autenticazione basata solo su Microsoft Entra con Azure SQL è abilitata nel server logico primario o secondario e la creazione viene tentata usando un utente ID di Microsoft Entra.
Per istruzioni dettagliate e metodi, vedere Tutorial: Configurare la replica geografica attiva e il failover (Azure SQL Database).
Endpoint privati
L’aggiunta di un database geografico secondario tramite T-SQL non è supportata durante la connessione al server primario tramite un endpoint privato.
Se è configurato un endpoint privato, ma è consentito l’accesso alla rete pubblica, l’aggiunta di un database secondario con replica geografica è supportata quando si è connessi al server primario da un indirizzo IP pubblico.
Dopo l’aggiunta di un database geografico secondario, è possibile negare l’accesso pubblico.
Mantenere sincronizzate le credenziali e le regole del firewall
Quando si usa l'accesso alla rete pubblica per la connessione al database, si consiglia di usare le regole del firewall IP a livello di database per i database con replica geografica. Queste regole vengono replicate con il database, il che garantisce che tutti i database secondari con replica geografica abbiano le stesse regole del firewall IP del database primario. Questo approccio consente di evitare la configurazione e la gestione di regole del firewall manualmente nei server che ospitano sia il database primario che i secondari. Analogamente, l'uso di utenti di database contenuti per l'accesso ai dati garantisce che i database primari e secondari abbiano sempre le stesse credenziali di autenticazione. In questo modo, dopo un failover geografico, non si verificano interruzioni dovute alla mancata corrispondenza delle credenziali di autenticazione. Se si usano login e utenti anziché utenti contenuti, è necessario eseguire passaggi aggiuntivi per assicurarsi che nel database secondario esistano gli stessi login. Per informazioni dettagliate sulla configurazione, vedere configurare e gestire la sicurezza di Azure SQL Database per il ripristino geografico o il failover.
Ridimensionare il database primario
È possibile ridimensionare un database primario a dimensioni di calcolo diverse (entro lo stesso livello di servizio) senza disconnettere eventuali database secondari. Quando si aumentano le prestazioni, è consigliabile aumentare prima quelle del database secondario geografico e quindi quelle del database primario. In caso di riduzione delle prestazioni, invertire l'ordine: prima ridurre le prestazioni del database primario e poi le prestazioni di quello secondario.
Per informazioni sui gruppi di failover, vedere Ridimensionare una replica in un gruppo di failover.
Evitare la perdita di dati critici
A causa della latenza elevata delle reti Wide Area Network, per la replica geografica viene usato un meccanismo di replica asincrona. La replica asincrona può comportare la perdita di dati nel caso in cui il database primario abbia esito negativo. Per proteggere le transazioni critiche dalla perdita di dati, uno sviluppatore di applicazioni può richiamare la stored procedure sp_wait_for_database_copy_sync immediatamente dopo aver effettuato il commit della transazione. La chiamata sp_wait_for_database_copy_sync blocca il thread chiamante finché l'ultima transazione sottoposta a commit non viene trasmessa e registrata nel log delle transazioni del database secondario. Attende inoltre che le transazioni trasmesse vengano riprodotte (riedotte) sul secondario. La procedura memorizzata del sistema sp_wait_for_database_copy_sync ha come ambito uno specifico collegamento di replica geografica. La procedura può essere chiamata da qualsiasi utente che abbia diritti di connessione al database primario.
Nota
sp_wait_for_database_copy_sync impedisce la perdita di dati dopo il failover geografico per transazioni specifiche, ma non garantisce la sincronizzazione completa per l'accesso in lettura. Il ritardo causato da una chiamata di procedura sp_wait_for_database_copy_sync può essere significativo e dipende dalle dimensioni del log delle transazioni non ancora trasmesso al database primario al momento della chiamata.
Monitorare il ritardo della replica geografica
Per monitorare il ritardo rispetto a RPO, usare la replication_lag_sec colonna di sys.dm_geo_replication_link_status nel database primario. Mostra il ritardo in secondi tra le transazioni effettuate sul primario e quelle scritturate nel log delle transazioni sul secondario. Ad esempio, se il ritardo è di un secondo, significa che se il database primario è interessato da un'interruzione in questo momento e viene avviato un failover geografico, le transazioni di cui è stato eseguito il commit nell'ultimo secondo andranno perse.
Per misurare il ritardo rispetto alle modifiche apportate al database primario che sono state consolidate nella replica geografica secondaria, confrontare l'ora di last_commit nella replica geografica secondaria con lo stesso valore nel database primario.
Suggerimento
Se replication_lag_sec nel primario è NULL, significa che il primario non sa attualmente quanto sia indietro un secondario geografico. Ciò si verifica in genere dopo il riavvio del processo e dovrebbe essere una condizione temporanea. Prendere in considerazione l'invio di un avviso se replication_lag_sec restituisce NULL per un periodo di tempo prolungato. Potrebbe indicare che il database geografico secondario non può comunicare con il database primario a causa di un errore di connettività.
Esistono anche condizioni che potrebbero causare la differenza tra last_commit il tempo nel database geografico secondario e il database primario diventano di grandi dimensioni. Se ad esempio un commit viene eseguito sul database primario dopo un lungo periodo di assenza di modifiche, la differenza passerà a un valore elevato prima di tornare rapidamente a zero. Valutare la possibilità di inviare un avviso se la differenza tra questi due valori resta elevata per molto tempo.
Gestione a livello di codice della replica geografica attiva
La replica geografica attiva può anche essere gestita a livello di codice tramite T-SQL, Azure PowerShell e API REST. Le tabelle seguenti descrivono il set di comandi disponibili. La replica geografica attiva include un set di API di Azure Resource Manager per la gestione, inclusi i cmdlet Azure SQL Database e Azure PowerShell. Queste API supportano il controllo degli accessi in base al ruolo di Azure (Azure RBAC). Per ulteriori informazioni su come implementare i ruoli di accesso, vedere controllo degli accessi in base ai ruoli di Azure (Azure RBAC).
Importante
Questi comandi T-SQL si applicano solo alla replica geografica attiva e non ai gruppi di failover.
| Comando | Descrizione |
|---|---|
| ALTER DATABASE | Usare l'argomento ADD SECONDARY ON SERVER per creare un database secondario per un database esistente e avviare la replica dei dati |
| ALTER DATABASE | Usare FAILOVER o FORCE_FAILOVER_ALLOW_DATA_LOSS per cambiare un database secondario come primario per avviare il failover |
| ALTER DATABASE | Usare REMOVE SECONDARY ON SERVER per terminare una replica di dati tra un database SQL e il database secondario specificato. |
| sys.geo_replication_links | Restituisce informazioni su tutti i collegamenti di replica esistenti per ogni database in un server. |
| sys.dm_geo_replication_link_status | Ottiene l'ultima ora di replica, l'ultimo intervallo di replica e altre informazioni sul collegamento di replica per un database specificato. |
| sys.dm_operation_status | Mostra lo stato per tutte le operazioni di database, inclusi i cambiamenti ai collegamenti di replica. |
| sys.sp_wait_for_database_copy_sync | Fa sì che l'applicazione attenda che tutte le transazioni di cui è stato eseguito il commit vengano sottoposte a protezione avanzata nel log delle transazioni di un database geografico secondario. |
Risoluzione dei problemi
Per altre informazioni sulla risoluzione dei problemi relativi al ritardo della replica geografica, vedere Risolvere i problemi di ritardo della replica geografica.
Contenuto correlato
Configurare la replica geografica attiva:
Altri contenuti di continuità aziendale: