Procedure consigliate per la configurazione HADR (SQL Server nelle macchine virtuali di Azure)
Si applica a:![]() SQL Server su VM Azure
SQL Server su VM Azure
Un cluster di failover di Windows Server viene usato per la disponibilità elevata e il ripristino di emergenza con SQL Server in Macchine virtuali (VM) di Azure.
Questo articolo illustra le procedure consigliate per la configurazione del cluster sia per le istanze del cluster di failover che per i gruppi di disponibilità quando vengono usati con SQL Server in Macchine virtuali di Azure.
Per altre informazioni, vedere gli altri articoli di questa serie: Elenco di controllo, Dimensioni della macchina virtuale, Archiviazione, Sicurezza, Configurazione HADR, Raccolta di base.
Elenco di controllo
Esaminare l'elenco di controllo seguente per una breve panoramica delle procedure consigliate di HADR, illustrate nel resto dell'articolo in modo più dettagliato.
Funzionalità di disponibilità elevata e ripristino di emergenza (HADR), ad esempio il gruppo di disponibilità Always On e l'istanza del cluster di failover si basano sulla tecnologia del cluster di failover di Windows Server sottostante. Esaminare le procedure consigliate per modificare le impostazioni HADR per supportare al meglio l'ambiente cloud.
Per il cluster Windows, prendere in considerazione le seguenti procedure consigliate:
- Distribuire le VM di SQL Server in più subnet, quando possibile, per evitare la dipendenza da un'istanza di Azure Load Balancer o da un nome di rete distribuita (DNN) per instradare il traffico alla soluzione HADR.
- Modificare il cluster in parametri meno aggressivi per evitare interruzioni impreviste derivanti da errori di rete temporanei o manutenzione della piattaforma Azure. Per ulteriori informazioni, consultare Impostazioni heartbeat e soglia. Per Windows Server 2012 e versioni successive, usare i valori consigliati:
- SameSubnetDelay: 1 secondo
- SameSubnetThreshold: 40 heartbeat
- CrossSubnetDelay: 1 secondo
- CrossSubnetThreshold: 40 heartbeat
- Collocare le macchine virtuali in un set di disponibilità o in zone di disponibilità diverse. Per ulteriori informazioni, consultare Impostazioni di disponibilità delle VM.
- Usare una singola scheda di interfaccia di rete per ogni nodo del cluster.
- Configurare la votazione quorum del cluster per l'uso di 3 o più voti in numero dispari. Non assegnare voti alle aree di ripristino di emergenza.
- Monitorare attentamente i limiti delle risorse per evitare riavvii imprevisti o failover a causa di vincoli di risorse.
- Assicurarsi che il sistema operativo, i driver e SQL Server siano nelle build più recenti.
- Ottimizzare le prestazioni per SQL Server in VM di Azure. Per ulteriori informazioni, consultare le altre sezioni di questo articolo.
- Ridurre o distribuire il carico di lavoro per evitare limiti di risorse.
- Passare a una VM o a un disco con limiti più elevati per evitare vincoli.
Per il gruppo di disponibilità di SQL Server o l'istanza del cluster di failover, prendere in considerazione le seguenti procedure consigliate:
- Se si verificano con frequenza errori imprevisti, seguire le procedure consigliate per le prestazioni descritte nel resto di questo articolo.
- Se l'ottimizzazione delle prestazioni delle macchine virtuali di SQL Server non risolve i failover imprevisti, è consigliabile ridurre il monitoraggio per il gruppo di disponibilità o l'istanza del cluster di failover. Tuttavia, questa operazione potrebbe non risolvere l'origine sottostante del problema e potrebbe mascherare i sintomi riducendo la probabilità di errore. Potrebbe essere comunque necessario analizzare e risolvere la causa radice sottostante. Per Windows Server 2012 e versioni successive, usare i valori consigliati seguenti:
- Timeout del lease: usare questa equazione per calcolare il valore massimo di timeout del lease:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Iniziare con 40 secondi. Se si usano i valori più flessibiliSameSubnetThresholdeSameSubnetDelayconsigliati in precedenza, non superare 80 secondi per il valore di timeout del lease. - Numero massimo di errori in un periodo specificato: impostare questo valore su 6.
- Timeout del lease: usare questa equazione per calcolare il valore massimo di timeout del lease:
- Quando si usano il nome di rete virtuale (VNN) e Azure Load Balancer per connettersi alla soluzione HADR, specificare
MultiSubnetFailover = truenella stringa di connessione, anche se il cluster si estende solo su una subnet.- Se il client non supporta
MultiSubnetFailover = True, potrebbe essere necessario impostareRegisterAllProvidersIP = 0eHostRecordTTL = 300per memorizzare nella cache le credenziali del client per durate più brevi. Tuttavia, questa operazione può causare query aggiuntive al server DNS.
- Se il client non supporta
- Per connettersi alla soluzione HADR usando il nome di rete distribuita (DNN), tenere presente quanto segue:
- È necessario usare un driver del client che supporta
MultiSubnetFailover = Truee questo parametro deve trovarsi nella stringa di connessione. - Usare una porta DNN univoca nella stringa di connessione durante la connessione al listener DNN per un gruppo di disponibilità.
- È necessario usare un driver del client che supporta
- Usare una stringa di connessione di mirroring del database per un gruppo di disponibilità di base per ignorare la necessità di un servizio di bilanciamento del carico o DNN.
- Convalidare le dimensioni del settore dei dischi rigidi virtuali prima di distribuire la soluzione a disponibilità elevata per evitare operazioni di I/O non allineate. Per ulteriori informazioni, consultare KB3009974.
- Se il motore del database di SQL Server, il listener del gruppo di disponibilità Always On o il probe di integrità dell'istanza del cluster di failover sono configurati per usare una porta compresa tra 49.152 e 65.536 (intervallo di porte dinamiche predefinito per TCP/IP), aggiungere un'esclusione per ogni porta. In questo modo, gli altri sistemi non possono essere assegnati dinamicamente alla stessa porta. L'esempio seguente crea un'esclusione per la porta 59.999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Per confrontare l'elenco di controllo HADR con le altre procedure consigliate, vedere Elenco di controllo delle procedure consigliate per le prestazioni.
Set di disponibilità della macchina virtuale
Per ridurre l'effetto del tempo inattivo, prendere in considerazione le seguenti migliori impostazioni di disponibilità della macchina virtuale:
- Usare i gruppi di posizionamento di prossimità insieme alla rete accelerata per ottenere la latenza più bassa.
- Posizionare i nodi del cluster di macchine virtuali in zone di disponibilità separate per proteggere da errori a livello di data center o in un singolo set di disponibilità per la ridondanza a bassa latenza all'interno dello stesso data center.
- Usare un sistema operativo e dischi gestiti Premium per le macchine virtuali in un set di disponibilità.
- Configurare ogni livello applicazione in set di disponibilità separati.
Quorum
Anche se un cluster a due nodi funziona senza una risorsa quorum, i clienti sono strettamente tenuti a usare una risorsa quorum per avere il supporto di produzione. La convalida del cluster non passa alcun cluster senza una risorsa quorum.
Tecnicamente, un cluster a tre nodi può sopravvivere a una perdita di un singolo nodo (passando a due nodi) senza una risorsa quorum, ma dopo che il cluster è passato a due nodi, se si verifica un altro errore di comunicazione o un'altra perdita di nodo, è possibile che le risorse cluster vadano offline per evitare uno scenario split brain. La configurazione di una risorsa quorum consente al cluster di continuare online con un solo nodo online.
Il disco di controllo è l'opzione quorum più resiliente, ma per usare un disco di controllo su SQL Server in una macchina virtuale Azure, è necessario usare un disco condiviso di Azure, che impone alcune limitazioni per la soluzione a disponibilità elevata. Di conseguenza, è consigliabile usare un disco di controllo quando si configura l'istanza del cluster di failover con Dischi condivisi di Azure, altrimenti usare un cloud di controllo quando possibile.
La tabella seguente elenca le opzioni quorum disponibili per SQL Server nelle macchine virtuali di Azure:
| Cloud di controllo | Disco di controllo | Condivisione file di controllo | |
|---|---|---|---|
| Sistema operativo supportato | Windows Server 2016+ | Tutte le date | Tutte le date |
- Il cloud di controllo è ideale per le distribuzioni in più siti, più zone e più aree. Usare un cloud di controllo quando possibile, a meno che non si usi una soluzione cluster di archiviazione condivisa.
- Il disco di controllo è l'opzione quorum più resiliente ed è preferibile per qualsiasi cluster che usa Dischi condivisi di Azure (o qualsiasi soluzione di dischi condivisi, ad esempio SCSI condiviso, iSCSI o SAN Fibre Channel). Un volume condiviso cluster non può essere usato come disco di controllo.
- Il fileshare di controllo è adatto quando il disco di controllo e il cloud di controllo non sono disponibili.
Per iniziare, vedere Configurare il quorum del cluster.
Votazione quorum
È possibile modificare la votazione quorum di un nodo che partecipa a un cluster di failover di Windows Server.
Quando si modificano le impostazioni della votazione del nodo, seguire queste linee guida:
| Linee guida per la votazione quorum |
|---|
| Iniziare con ogni nodo senza votazione per impostazione predefinita. Ogni nodo deve avere solo una votazione con giustificazione esplicita. |
| Abilitare le votazioni per i nodi del cluster che ospitano la replica primaria di un gruppo di disponibilità o i proprietari preferiti di un'istanza del cluster di failover. |
| Abilitare le votazioni per i proprietari di failover automatici. Ogni nodo che potrebbe ospitare una replica primaria o un'istanza del cluster di failover in seguito a un failover automatico dovrebbe disporre di una votazione. |
| Se un gruppo di disponibilità dispone di più repliche secondarie, abilitare solo le votazioni per le repliche con failover automatico. |
| Disabilitare le votazioni per i nodi presenti nei siti di ripristino di emergenza secondari. Non è consigliabile fare in modo che i nodi nel sito secondario contribuiscano a una decisione che comporti l'impostazione offline del cluster quando non vi sono problemi con il sito primario. |
| Assicurarsi di avere un numero dispari di votazioni, con un minimo di tre votazioni quorum. Aggiungere un quorum di controllo per una votazione aggiuntiva, se necessario in un cluster a due nodi. |
| Valutare nuovamente le assegnazioni delle votazioni dopo il failover. Non è consigliabile eseguire il failover in una configurazione del cluster che non supporta un quorum integro. |
Connettività
Per replicare l'esperienza locale di connessione al listener del gruppo di disponibilità o all'istanza del cluster di failover, distribuire le macchine virtuali di SQL Server in più subnet all'interno della stessa rete virtuale. La presenza di più subnet annulla la necessità di una dipendenza aggiuntiva su Azure Load Balancer o da un nome di rete distribuita per instradare il traffico al listener.
Per semplificare la soluzione HADR, distribuire le macchine virtuali di SQL Server in più subnet quando possibile. Per altre informazioni, vedere Gruppo di disponibilità su più subnet e Istanza del cluster di failover su più subnet.
Se le macchine virtuali di SQL Server si trovano in una singola subnet, è possibile configurare un nome di rete virtuale (VNN) e Azure Load Balancer o un nome di rete distribuita (DNN) per le istanze del cluster di failover e i listener del gruppo di disponibilità.
Il nome della rete distribuita è l'opzione di connettività consigliata, se disponibile:
- La soluzione end-to-end è più affidabile perché non rende più necessario gestire la risorsa del servizio di bilanciamento del carico.
- L'eliminazione dei probe di bilanciamento del carico riduce al minimo la durata del failover.
- Il nome di rete distribuita semplifica il provisioning e la gestione dell'istanza del cluster di failover o del listener del gruppo di disponibilità con SQL Server in Macchine virtuali di Azure.
Tenere presente le limitazioni seguenti:
- Il driver client deve supportare il parametro
MultiSubnetFailover=True. - La funzionalità del nome di rete distribuita è disponibile a partire da SQL Server 2016 SP3, SQL Server 2017 CU25 e SQL Server 2019 CU8 in Windows Server 2016 e versioni successive.
Per altre informazioni sul quorum, vedere la panoramica del cluster di failover di Windows Server.
Per configurare la connettività, vedere gli articoli seguenti:
- Gruppo di disponibilità: Configurare il nome di rete distribuita, Configurare il nome di rete virtuale.
- Istanza del cluster di failover: Configurare il nome di rete distribuita, Configurare il nome di rete virtuale.
Quando si usa il nome di rete distribuita, la maggior parte delle funzionalità di SQL Server funziona in modo trasparente con l'istanza del cluster di failover e i gruppi di disponibilità, ma esistono alcune funzionalità che possono richiedere particolari considerazioni. Per altre informazioni, vedere Interoperabilità tra istanza del cluster di failover e nome di rete distribuita e Interoperabilità tra gruppo di disponibilità e nome di rete distribuita.
Suggerimento
Impostare il parametro MultiSubnetFailover = true nella stringa di connessione anche per le soluzioni HADR che si estendono su una singola subnet per supportare l'estensione futura delle subnet senza dover aggiornare le stringa di connessione.
Heartbeat e soglia
Modificare le impostazioni di heartbeat e soglia del cluster in impostazioni di riduzione. Le impostazioni predefinite del cluster heartbeat e soglia sono progettate per reti locali altamente ottimizzate e non considerano la possibilità di aumentare la latenza in un ambiente cloud. La rete heartbeat viene mantenuta con UDP 3343, che tradizionalmente è molto meno affidabile di TCP e più soggetta a conversazioni incomplete.
Pertanto, quando si eseguono nodi del cluster per SQL Server in soluzioni a disponibilità elevata delle macchine virtuali di Azure, è consigliabile modificare le impostazioni del cluster su uno stato di monitoraggio meno restrittivo per evitare errori temporanei a causa della maggiore possibilità di latenza o errore di rete, manutenzione di Azure o colli di bottiglia delle risorse.
Le impostazioni di ritardo e soglia hanno un effetto cumulativo sul rilevamento totale dell'integrità. Ad esempio, impostando CrossSubnetDelay per inviare un heartbeat ogni 2 secondi e impostando CrossSubnetThreshold su 10 heartbeat persi prima di eseguire il ripristino, il cluster può avere una tolleranza di rete totale di 20 secondi prima dell'esecuzione dell'azione di ripristino. In generale, è preferibile continuare a inviare heartbeat frequenti, ma con soglie maggiori.
Per garantire il ripristino durante interruzioni legittime, garantendo una maggiore tolleranza per i problemi temporanei, ridurre le impostazioni di ritardo e soglia ai valori consigliati descritti nella tabella seguente:
| Impostazione | Windows Server 2012 o versioni successive | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 secondo | 2 secondi |
| SameSubnetThreshold | 40 heartbeat | 10 heartbeat (max) |
| CrossSubnetDelay | 1 secondo | 2 secondi |
| CrossSubnetThreshold | 40 heartbeat | 20 heartbeat (max) |
Usare PowerShell per modificare i parametri del cluster:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Usare PowerShell per verificare le modifiche:
get-cluster | fl *subnet*
Considerare quanto segue:
- Questa modifica è immediata. Il riavvio del cluster o delle risorse non è necessario.
- I valori nella stessa subnet non devono essere maggiori dei valori tra subnet.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Scegliere valori flessibili in base al tempo inattivo tollerabile e a quanto tempo deve trascorrere prima che si verifichi un'azione correttiva a seconda dell'applicazione, delle esigenze aziendali e dell'ambiente. Se non è possibile superare i valori predefiniti di Windows Server 2019, provare almeno a pareggiarli, se possibile:
Per riferimento, nella tabella seguente vengono indicati i valori predefiniti:
| Impostazione | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 secondo | 1 secondo | 1 secondo |
| SameSubnetThreshold | 20 heartbeat | 10 heartbeat | 5 heartbeat |
| CrossSubnetDelay | 1 secondo | 1 secondo | 1 secondo |
| CrossSubnetThreshold | 20 heartbeat | 10 heartbeat | 5 heartbeat |
Per altre informazioni, vedere Ottimizzazione delle soglie di rete del cluster di failover.
Monitoraggio meno restrittivo
Se eseguire l'ottimizzazione delle impostazioni di heartbeat e soglia del cluster come consigliato non è sufficiente e si riscontrano ancora failover dovuti a problemi temporanei anziché a vere interruzioni, è possibile configurare il monitoraggio del gruppo di disponibilità o dell'istanza del cluster di failover in modo che sia meno restrittivo. In alcuni scenari, può essere utile ridurre temporaneamente il monitoraggio per un periodo di tempo in base al livello di attività. Ad esempio, è possibile ridurre il monitoraggio quando si eseguono carichi di lavoro con utilizzo intensivo di I/O, ad esempio backup del database, manutenzione degli indici, DBCC CHECKDB e così via. Una volta completata l'attività, impostare il monitoraggio su valori più restrittivi.
Avviso
La modifica di queste impostazioni può mascherare un problema sottostante e deve essere usata come soluzione temporanea per ridurre, invece di eliminare, la probabilità di errore. I problemi sottostanti devono comunque essere esaminati e risolti.
Per iniziare, aumentare i valori predefiniti dei parametri seguenti per un monitoraggio meno restrittivo, quindi regolare in base alle esigenze:
| Parametro | Valore predefinito | Valore meno restrittivo | Descrizione |
|---|---|---|---|
| Timeout controllo integrità | 30000 | 60000 | Determina l'integrità della replica o del nodo primario. La DLL della risorsa cluster sp_server_diagnostics restituisce i risultati a un intervallo uguale a 1/3 della soglia di timeout del controllo integrità. Se sp_server_diagnostics è lenta o non restituisce informazioni, la DLL della risorsa attende l'intervallo completo della soglia di timeout del controllo integrità prima di determinare che la risorsa non risponde e avviare un failover automatico, se configurato. |
| Livello delle condizioni di errore | 3 | 2 | Condizioni che attivano un failover automatico. I livelli delle condizioni di errore sono 5 e vanno dal livello meno restrittivo (livello 1), al livello più restrittivo (livello 5). |
Usare Transact-SQL (T-SQL) per modificare il controllo di integrità e le condizioni di errore sia per i gruppi di disponibilità che per le istanze del cluster di failover.
Per i gruppi di disponibilità:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Perle istanze del cluster di failover:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Nel caso specifico dei gruppi di disponibilità, iniziare con i parametri consigliati seguenti e modificare in base alle esigenze:
| Parametro | Valore predefinito | Valore meno restrittivo | Descrizione |
|---|---|---|---|
| Timeout lease | 20000 | 40000 | Previene lo "split brain". |
| Timeout sessione | 10000 | 20000 | Controlla i problemi di comunicazione tra le repliche. Il periodo di timeout della sessione è una proprietà della replica che determina i secondi di attesa di una replica di disponibilità per una risposta del ping da una replica connessa prima di considerare la connessione non riuscita. Per impostazione predefinita, l'attesa di una replica è di 10 secondi per una risposta del ping. Questa proprietà della replica si applica solo alla connessione tra una determinata replica secondaria e la replica primaria del gruppo di disponibilità. |
| Numero massimo di errori nel periodo specificato | 2 | 6 | Usato per evitare lo spostamento indefinito di una risorsa cluster all'interno di più errori del nodo. Un valore troppo basso può causare un errore nel gruppo di disponibilità. Aumentare il valore per evitare brevi interruzioni dovute a problemi di prestazioni, perché un valore troppo basso può causare un errore del gruppo di disponibilità. |
Prima di apportare modifiche, considerare quanto segue:
- Non ridurre i valori di timeout al di sotto dei valori predefiniti.
- Usare questa equazione per calcolare il valore massimo di timeout del lease:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Iniziare con 40 secondi. Se si usano i valori più flessibiliSameSubnetThresholdeSameSubnetDelayconsigliati in precedenza, non superare 80 secondi per il valore di timeout del lease. - Per le repliche con commit sincrono, la modifica del timeout della sessione a un valore elevato può aumentare il tempo di attesa di HADR_sync_commit.
Timeout lease
Usare Gestione cluster di failover per modificare le impostazioni di timeout del lease per il gruppo di disponibilità. Per informazioni dettagliate, vedere la documentazione relativa al controllo di integrità del lease del gruppo di disponibilità di SQL Server.
Timeout sessione
Usare Transact-SQL (T-SQL) per modificare il timeout della sessione per un gruppo di disponibilità:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Numero massimo di errori nel periodo specificato
Usare Gestione cluster di failover per modificare il valore Numero massimo di errori nel periodo specificato:
- Nel riquadro di spostamento selezionare Ruoli.
- In Ruoli fare clic con il pulsante destro del mouse sulla risorsa cluster e scegliere Proprietà.
- Selezionare la scheda Failover e aumentare il valore Numero massimo di errori nel periodo specificato in base alle esigenze.
Limiti delle risorse
I limiti delle macchine virtuali o dei dischi possono comportare un collo di bottiglia della risorsa che influisce sull'integrità del cluster e impedisce il controllo di integrità. Se si verificano problemi con i limiti delle risorse, tenere presente quanto segue:
- Assicurarsi che il sistema operativo, i driver e SQL Server siano nelle build più recenti.
- Ottimizzare SQL Server nell'ambiente di macchine virtuali di Azure come descritto nelle linee guida relative alle prestazioni per SQL Server in Macchine virtuali di Azure
- Ridurre o distribuire il carico di lavoro per ridurre l'utilizzo senza superare i limiti delle risorse
- Ottimizzare il carico di lavoro di SQL Server se è disponibile un'opportunità, ad esempio:
- Aggiungere/ottimizzare gli indici
- Aggiornare le statistiche se necessario e, se possibile, con Analisi completa
- Usare funzionalità come Resource Governor (a partire da SQL Server 2014, solo enterprise) per limitare l'utilizzo delle risorse durante carichi di lavoro specifici, ad esempio i backup o la manutenzione degli indici.
- Passare a una macchina virtuale o a un disco con limiti più elevati per soddisfare o superare le richieste del carico di lavoro.
Rete
Distribuire le VM di SQL Server in più subnet, quando possibile, per evitare la dipendenza da un'istanza di Azure Load Balancer o da un nome di rete distribuita (DNN) per instradare il traffico alla soluzione HADR.
Usare una singola scheda di interfaccia di rete per server (nodo del cluster). La ridondanza fisica della rete di Azure rende superfluo l'uso di altre schede di interfaccia di rete e subnet in un cluster guest di macchine virtuali di Azure. Il report di convalida del cluster informa che i nodi sono raggiungibili solo in una singola rete. È possibile ignorare questo avviso nei cluster di failover guest di macchine virtuali di Azure.
I limiti di larghezza di banda per una determinata macchina virtuale vengono condivisi tra schede di interfaccia di rete e l'aggiunta di una scheda di interfaccia di rete non migliora le prestazioni del gruppo di disponibilità per SQL Server in Macchine virtuali di Azure. Di conseguenza, non è necessario aggiungere una seconda scheda di interfaccia di rete.
Il servizio DHCP non conforme a RFC in Azure può causare l'esito negativo della creazione di determinate configurazioni del cluster di failover. Questo errore si verifica perché al nome della rete del cluster viene assegnato un indirizzo IP duplicato, ad esempio lo stesso indirizzo IP di uno dei nodi del cluster. Ciò costituisce un problema quando si usano i gruppi di disponibilità, che dipendono dalla funzionalità del cluster di failover di Windows.
Si consideri uno scenario in cui viene creato e portato online un cluster a due nodi:
- Il cluster è online e NODE1 richiede un indirizzo IP assegnato in modo dinamico per il nome di rete del cluster.
- Il servizio DHCP non assegna un indirizzo IP diverso da quello dello stesso NODE1, poiché il servizio DHCP riconosce che la richiesta proviene da NODE1.
- Windows rileva l'assegnazione di un indirizzo duplicato a NODE1 e al nome di rete del cluster di failover e il gruppo cluster predefinito non può essere portato online.
- Il gruppo di cluster predefinito passa a NODE2. NODE2 tratta l'indirizzo IP di NODE1 come l'indirizzo IP del cluster e porta online il gruppo cluster predefinito.
- Quando NODE2 tenta di stabilire la connessione con NODE1, i pacchetti indirizzati a NODE1 non lasciano mai NODE2 perché l'indirizzo IP di NODE1 viene risolto in se stesso. NODE2 non è in grado di stabilire la connessione con NODE1, quindi perde il quorum e arresta il cluster.
- NODE1 può inviare i pacchetti a NODE2, ma NODE2 non può rispondere. NODE1 perde il quorum e arresta il cluster.
È possibile evitare questo scenario assegnando un indirizzo IP statico inutilizzato al nome di rete del cluster per portare online il nome di rete del cluster e aggiungere l'indirizzo IP ad Azure Load Balancer.
Se il motore di database di SQL Server, il listener del gruppo di disponibilità Always On o il probe di integrità dell'istanza del cluster di failover, l'endpoint di mirroring del database, la risorsa IP principale del cluster o qualunque altra risorsa SQL sono configurati per usare una porta compresa tra 49.152 e 65.536 (intervallo di porte dinamiche predefinito per TCP/IP), aggiungere un'esclusione per ogni porta. In questo modo si impedisce l'assegnazione dinamica della stessa porta ad altri processi di sistema. L'esempio seguente crea un'esclusione per la porta 59.999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
È importante configurare l'esclusione della porta quando la porta non è in uso; in caso contrario, il comando non riesce con un messaggio simile a "Impossibile accedere al file perché è utilizzato da un altro processo".
Per verificare che le esclusioni siano state configurate correttamente, usare il comando seguente: netsh int ipv4 show excludedportrange tcp.
L'impostazione di questa esclusione per la porta probe IP del ruolo del gruppo di disponibilità deve impedire eventi come ID evento: 1069 con stato 10048. Questo evento può essere visualizzato negli eventi del cluster di failover di Windows con il messaggio seguente:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Ciò può essere causato da un processo interno che accetta la stessa porta definita come porta probe. Tenere presente che la porta probe viene usata per controllare lo stato di un'istanza del pool di back-end da Azure Load Balancer.
Se il probe di integrità non riesce a ottenere una risposta da un'istanza di back-end, non verranno inviate nuove connessioni a tale istanza back-end finché il probe di integrità non riesce di nuovo.
Problemi noti
Esaminare le risoluzioni di alcuni problemi ed errori comuni.
La contesa delle risorse (in particolare I/O) provoca il failover
L'esaurimento della capacità di I/O o CPU per la macchina virtuale può causare il failover del gruppo di disponibilità. Identificare la contesa esattamente prima del failover è la soluzione più affidabile per identificare la causa di un failover automatico. Monitorare Macchine Virtuali di Azure per esaminare le metriche di utilizzo di I/O di archiviazione e analizzare la latenza a livello di macchina virtuale o disco.
Seguire questa procedura per esaminare l'evento di esaurimento complessivo di I/O della macchina virtuale di Azure:
Passare alla macchina virtuale nel portale di Azure, non alle macchine virtuali di SQL.
Selezionare Metriche in Monitoraggio per aprire la pagina Metriche.
Selezionare Ora locale per specificare l'intervallo di tempo desiderato e il fuso orario locale della macchina virtuale o UTC/GMT.
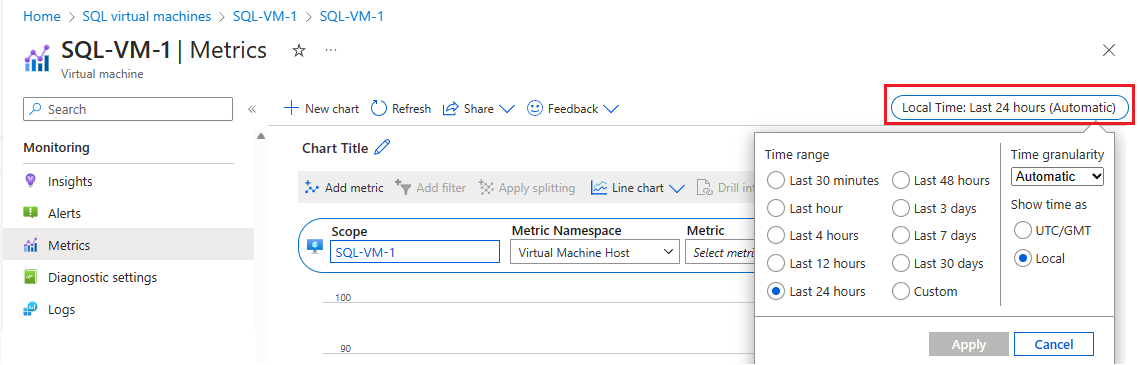
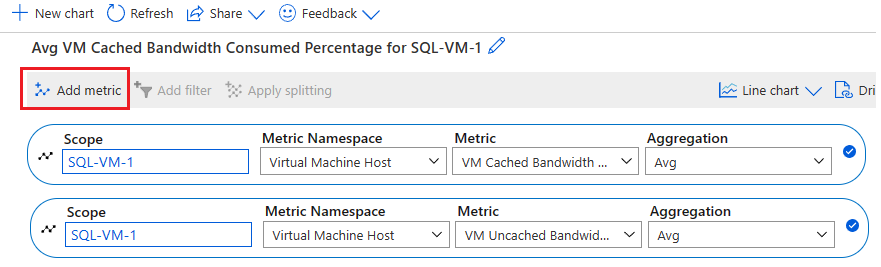
Selezionare Aggiungi metrica per aggiungere le due metriche seguenti e visualizzare il grafico:
- Percentuale di utilizzo larghezza di banda della cache della macchina virtuale
- Percentuale di utilizzo larghezza di banda non della cache della macchina virtuale
Gli eventi HostEvent delle macchine virtuali di Azure causano il failover
È possibile che un evento HostEvent della macchina virtuale di Azure causi il failover del gruppo di disponibilità. Se si ritiene che un evento HostEvent della macchina virtuale di Azure abbia causato un failover, è possibile controllare il log attività di Monitoraggio di Azure e la panoramica Integrità risorse della macchina virtuale di Azure.
Il log attività di Monitoraggio di Azure è un log della piattaforma presente in Azure che contiene informazioni sugli eventi a livello di sottoscrizione. Il log attività include informazioni relative, ad esempio, alla modifica di una risorsa o all'avvio di una macchina virtuale. È possibile visualizzare il log attività nel portale di Azure o recuperarne le voci con PowerShell e l'interfaccia della riga di comando di Azure.
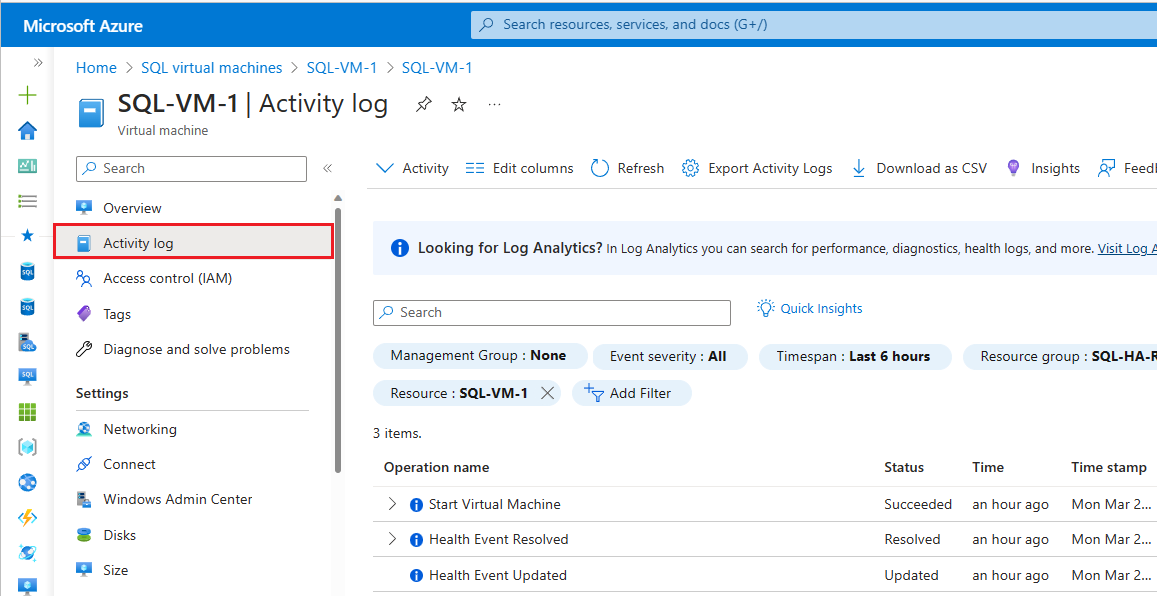
Per controllare il log attività di Monitoraggio di Azure, seguire questa procedura:
Passare alla macchina virtuale nel portale di Azure
Selezionare Log attività nel riquadro Macchina virtuale.
Selezionare Intervallo di tempo e quindi scegliere l'intervallo di tempo in cui è stato eseguito il failover del gruppo di disponibilità. Selezionare Applica.
Se Azure dispone di altre informazioni sulla causa radice di una mancata disponibilità avviata dalla piattaforma, tali informazioni possono essere pubblicate in Macchina virtuale di Azure - Panoramica di Integrità risorse fino a 72 ore dopo la mancata disponibilità iniziale. Queste informazioni sono attualmente disponibili solo per le macchine virtuali.
- Passare alla macchina virtuale nel portale di Azure.
- Selezionare Integrità risorse nel riquadro Integrità.
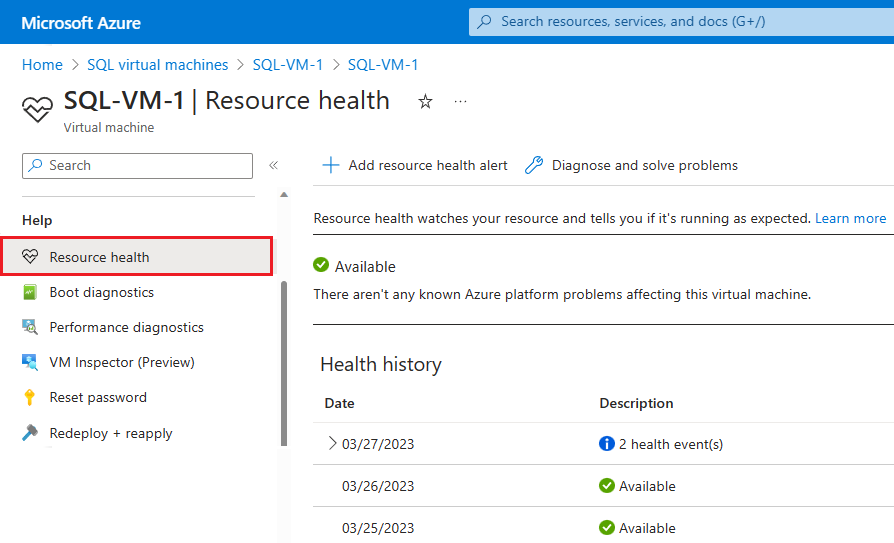
È anche possibile configurare avvisi in base agli eventi di integrità di questa pagina.
Nodo del cluster rimosso dall'appartenenza
Se le impostazioni di heartbeat e soglia del cluster di Windows sono troppo aggressive per l'ambiente in uso, è possibile che venga visualizzato di frequente il messaggio seguente nel registro eventi di sistema.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Per altre informazioni, esaminare Risoluzione dei problemi relativi all'ID evento 1135.
Lease scaduto/Lease non più valido
Se il monitoraggio è troppo aggressivo per l'ambiente, è possibile che si verifichino frequenti riavvii, errori o failover del gruppo di disponibilità o dell'istanza del cluster di failover. Inoltre, per i gruppi di disponibilità, è possibile che vengano visualizzati i messaggi seguenti nel log degli errori di SQL Server:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Connection timeout
Se il timeout della sessione è troppo aggressivo per l'ambiente del gruppo di disponibilità, è possibile che vengano visualizzati di frequente i messaggi seguenti:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Failover del gruppo non riuscito
Se il valore Numero massimo di errori nel periodo specificato è troppo basso e si verificano errori intermittenti a causa di problemi temporanei, il gruppo di disponibilità potrebbe ritrovarsi in uno stato di errore. Aumentare questo valore per tollerare più errori temporanei.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Event 1196 - Network name resource failed registration of associated DNS name (Evento 1196 - la risorsa del nome di rete non è riuscita a registrare uno dei nomi DNS associati)
- Controllare le impostazioni della scheda di interfaccia di rete per ogni nodo del cluster per verificare che non siano presenti record DNS esterni
- Verificare che nei server DNS interni sia presente il record A per il cluster. In caso contrario, creare un nuovo manuale di record A nel server DNS per l'oggetto Controllo di accesso del cluster e selezionare Allow any authenticated users to update DNS Records with the same owner name (Consenti a tutti gli utenti autenticati di aggiornare i record DNS con lo stesso nome del proprietario).
- Portare offline il nome cluster della risorsa con la risorsa dell'indirizzo IP e correggerlo.
Event 157 - Disk has been surprised removed (Evento 157 - il disco è stato rimosso in modo imprevisto)
Questo problema può verificarsi se la proprietà AutomaticClusteringEnabled di Spazi di archiviazione è impostata su True per un ambiente del gruppo di disponibilità. Sostituirlo con False. Inoltre, l'esecuzione di un report di convalida con l'opzione Archiviazione può attivare l'evento di reimpostazione o rimozione imprevista del disco. La limitazione delle richieste del sistema di archiviazione può anche attivare l'evento di rimozione improvvisa.
Event 1206 - Cluster network name resource cannot be brought online (Evento 1206 - impossibile portare online la risorsa del nome di rete cluster)
Non è possibile aggiornare nel dominio l'oggetto del computer associato a una risorsa. Assicurarsi di disporre delle autorizzazioni appropriate per il dominio.
Errori di clustering di Windows
Se non ci sono porte del servizio cluster aperte per la comunicazione, potrebbero verificarsi problemi durante la configurazione di un cluster di failover di Windows o della relativa connettività.
Se si usa Windows Server 2019 e non viene visualizzato un IP del cluster Windows, significa che è stato configurato un nome di rete distribuita, che è supportato solo in SQL Server 2019. Se si dispone di versioni precedenti di SQL Server, è possibile rimuovere e ricreare il cluster usando il nome di rete.
Esaminare gli altri errori degli eventi di clustering di failover di Windows e le relative soluzioni qui.
Passaggi successivi
Per altre informazioni, vedere:
- Impostazioni HADR per SQL Server su VM di Azure
- Cluster di failover di Windows Server con SQL Server
- Gruppi di disponibilità Always On in SQL Server su VM di Azure
- Cluster di failover di Windows Server con SQL Server
- Istanze del cluster di failover con SQL Server in VM di Azure
- Panoramica dell'istanza del cluster di failover
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per