Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Le immagini contengono spesso informazioni utili rilevanti negli scenari di ricerca. È possibile vettorializzare le immagini per rappresentare il contenuto visivo nell'indice di ricerca. In alternativa, è possibile usare gli arricchimenti e i set di competenze di intelligenza artificiale per creare ed estrarre testo ricercabile dalle immagini, tra cui:
- OCR per il riconoscimento ottico di caratteri di testo e cifre
- 'analisi delle immagini che descrive immagini tramite funzionalità visive
- Competenze personalizzate per richiamare qualsiasi elaborazione di immagine esterna che si desideri fornire
Usando OCR, è possibile estrarre testo e da foto o immagini, ad esempio la parola STOP in un segno di arresto. Tramite l'analisi delle immagini, è possibile generare una rappresentazione testuale di un'immagine, ad esempio il dente di leone per una foto di un dente di leone o il colore giallo. È possibile anche estrarre i metadati relativi all'immagine, ad esempio le dimensioni.
Questo articolo illustra i concetti fondamentali dell'uso delle immagini nei set di competenze e descrive anche diversi scenari comuni, ad esempio l'uso di immagini incorporate, competenze personalizzate e visualizzazioni sovrapposte alle immagini originali.
Per usare il contenuto delle immagini in un set di competenze, è necessario:
- File di origine che includano immagini
- Un indicizzatore di ricerca configurato per azioni con immagini
- Un set di competenze con competenze predefinite o personalizzate che richiamano OCR o analisi delle immagini
- Indice di ricerca con campi per ricevere l'output di testo analizzato, oltre ai mapping dei campi di output nell'indicizzatore che stabilisce l'associazione
Facoltativamente, è possibile definire proiezioni per accettare l'output analizzato dall'immagine in un archivio conoscenze per scenari di data mining.
Configurare file di origine
L'elaborazione delle immagini è basata sull'indicizzatore, il che significa che gli input non elaborati devono trovarsi in un'origine dati supportata.
- L'analisi delle immagini supporta JPEG, PNG, GIF e BMP
- OCR supporta JPEG, PNG, BMP e TIF
Le immagini sono file binari autonomi o incorporati in documenti, ad esempio pdf, RTF o file dell'applicazione Microsoft. È possibile estrarre un massimo di 1.000 immagini da un determinato documento. Se in un documento sono presenti più di 1.000 immagini, vengono estratti i primi 1.000 e viene generato un avviso.
Archiviazione BLOB di Azure è l'archiviazione usata più di frequente per l'elaborazione di immagini in Azure AI Search. Esistono tre attività principali correlate al recupero di immagini da un contenitore BLOB:
Abilitare l'accesso al contenuto nel contenitore. Se si usa una stringa di connessione ad accesso completo che include una chiave, la chiave concede l'autorizzazione per il contenuto. In alternativa, è possibile eseguire l'autenticazione usando Microsoft Entra ID o connettersi come servizio attendibile.
Creare un'origine dati di tipo azureblob che si connette al contenitore BLOB che archivia i file.
Rivedere i limiti del livello di servizio per assicurarsi che i dati di origine rientrino nei limiti di dimensioni e quantità massime per gli indicizzatori e l'arricchimento.
Configurare gli indicizzatori per l'elaborazione di immagini
Dopo aver configurato i file di origine, abilitare la normalizzazione delle immagini impostando il parametro imageAction nella configurazione dell'indicizzatore. La normalizzazione delle immagini consente di rendere le immagini più uniformi per l'elaborazione downstream. La normalizzazione delle immagini include le operazioni seguenti:
- Le immagini di grandi dimensioni vengono ridimensionate a un'altezza e una larghezza tali da renderle uniformi.
- Per le immagini con metadati che specificano l'orientamento, la rotazione delle immagini viene modificata per il caricamento verticale.
Si noti che abilitare imageAction (impostare questo parametro su un valore diverso da none) comporta un addebito aggiuntivo per l'estrazione di immagini in base ai prezzi di Azure AI Search.
Le modifiche a livello di metadati vengono acquisite in un tipo complesso creato per ogni immagine. Non è possibile rifiutare esplicitamente il requisito di normalizzazione dell'immagine. Le competenze che consentono di eseguire l'iterazione delle immagini, ad esempio OCR e analisi delle immagini, necessitano immagini normalizzate.
Creare o aggiornare un indicizzatore per impostare le proprietà di configurazione:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }Impostare
dataToExtractsucontentAndMetadata(obbligatorio).Verificare che sia
parsingModeimpostato su predefinito (obbligatorio).Questo parametro determina la granularità dei documenti di ricerca creati nell'indice. La modalità predefinita configura una corrispondenza uno-a-uno in modo che un BLOB restituisca un documento di ricerca. Se i documenti sono di grandi dimensioni o se le competenze richiedono blocchi di testo più piccoli, è possibile aggiungere la competenza Suddivisione testo che suddivide un documento in paging a scopo di elaborazione. Tuttavia, per scenari di ricerca in cui l’arricchimento include l’elaborazione delle immagini, è necessario un BLOB per ogni documento.
Impostare
imageActionper abilitare ilnormalized_imagesnodo in un albero di arricchimento (obbligatorio):generateNormalizedImagesper generare una matrice di immagini normalizzate come parte del cracking di documenti.generateNormalizedImagePerPage(si applica solo a PDF) per generare una matrice di immagini normalizzate in cui viene eseguito il rendering di ogni pagina del PDF in un'immagine di output. Per i file non PDF, il comportamento di questo parametro è simile a quellogenerateNormalizedImagesimpostato. Tuttavia, l'impostazionegenerateNormalizedImagePerPagepuò rendere l'operazione di indicizzazione meno efficiente in base alla progettazione (in particolare per documenti di grandi dimensioni) perché devono essere generate diverse immagini.
Facoltativamente, regolare la larghezza o l'altezza delle immagini normalizzate generate:
normalizedImageMaxWidthin pixel. Il valore predefinito è 2.000. Il valore massimo è 10.000.normalizedImageMaxHeightin pixel. Il valore predefinito è 2.000. Il valore massimo è 10.000.
Il valore predefinito di 2.000 pixel per la larghezza e l'altezza massime delle immagini normalizzate si basa sulle dimensioni massime supportate dalla competenza OCR e dalla competenza di analisi delle immagini. La competenza OCR supporta una larghezza e un'altezza massima di 4.200 per lingue non inglesi e 10.000 per l'inglese. Se si aumentano i limiti massimi, l'elaborazione potrebbe non riuscire per immagini di dimensioni maggiori a seconda della definizione del set di competenze e della lingua dei documenti.
Facoltativamente, impostare i criteri del tipo di file se il carico di lavoro è destinato a un tipo di file specifico. La configurazione dell'indicizzatore BLOB include le impostazioni di inclusione e esclusione di file. È possibile escludere i file non desiderati.
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Informazioni sulle immagini normalizzate
Quando imageAction è impostato su un valore diverso da nessuno, il nuovo normalized_images campo contiene una matrice di immagini. Ogni immagine è un tipo complesso che contiene i membri seguenti:
| Membro immagine | Descrizione |
|---|---|
| dati | Stringa con codifica Base64 dell'immagine normalizzata in formato JPEG. |
| Larghezza | Larghezza dell'immagine normalizzata in pixel. |
| altezza | Altezza dell'immagine normalizzata in pixel. |
| larghezzaOriginale | Larghezza originale dell'immagine prima della normalizzazione. |
| altezzaOriginale | Altezza originale dell'immagine prima della normalizzazione. |
| rotazione dall'originale | Rotazione in senso antiorario, espressa in gradi, effettuata per creare l'immagine normalizzata. Un valore compreso tra 0 e 360 gradi. Questo passaggio legge i metadati dall'immagine generata da una fotocamera o da uno scanner. In genere, è un multiplo di 90 gradi. |
| offset del contenuto | L'offset di carattere all'interno del campo di contenuto da cui è stata estratta l'immagine. Questo campo è applicabile solo ai file con immagini incorporate. L'oggetto contentOffset per le immagini estratte dai documenti PDF è sempre alla fine del testo nella pagina da cui è stato estratto nel documento. Ciò significa che le immagini vengono visualizzate dopo tutto il testo contenuto nella pagina, indipendentemente dalla posizione originale dell'immagine nella pagina. |
| numero di pagina | Se l'immagine è stata estratta o sottoposta a rendering da un PDF, questo campo contiene il numero di pagina nel PDF da cui è stata estratta o sottoposta a rendering, a partire da 1. Se l'immagine non proviene da un PDF, questo campo è 0. |
| boundingPolygon | Se l'immagine è stata estratta o sottoposta a rendering da un PDF, questo campo contiene le coordinate del poligono di delimitazione che racchiude l'immagine nella pagina. Il poligono è rappresentato come una matrice nidificata di punti, in cui ogni punto ha coordinate x e y normalizzate alle dimensioni della pagina. Questo vale solo per le immagini estratte usando imageAction: generateNormalizedImages. |
Valore di esempio di normalized_images:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
Nota
I dati di delimitazione dei poligoni sono rappresentati come una stringa contenente un array di poligoni con doppio annidamento e codificato in JSON. Ogni poligono è una matrice di punti, in cui ogni punto ha coordinate x e y. Le coordinate sono relative alla pagina PDF, con l'origine (0, 0) nell'angolo superiore sinistro.
Attualmente, le immagini estratte tramite imageAction: generateNormalizedImages produrranno sempre un singolo poligono, ma la struttura doppiamente annidata viene mantenuta per coerenza con la funzionalità Layout Documento, che supporta più poligoni.
Definire set di competenze per l'elaborazione di immagini
Questa sezione integra gli articoli di riferimento sulle competenze, fornendo il contesto per l'uso di input, output e modelli di competenze, in relazione all'elaborazione delle immagini.
Creare o aggiornare un set di competenze per aggiungere competenze.
Aggiungere modelli per OCR e Analisi immagini dalla portale di Azure oppure copiare le definizioni dalla documentazione di riferimento sulle competenze. Inserirli nella matrice di competenze della definizione del set di competenze.
Se necessario, includere una chiave multiservizio nella proprietà dei servizi di intelligenza artificiale di Azure del set di competenze. Azure AI Search effettua chiamate a una risorsa dei servizi di intelligenza artificiale di Azure, la quale è fatturabile per OCR e Analisi delle immagini per transazioni che superano il limite gratuito (20 per indicizzatore al giorno). I servizi di intelligenza artificiale di Azure devono trovarsi nella stessa area del servizio di ricerca.
Se le immagini originali sono incorporate in file PDF o di applicazioni come PPTX o DOCX, è necessario aggiungere una competenza Unione testo se si desidera l'output dell'immagine e l'output di testo insieme. L'uso di immagini incorporate è illustrato più avanti in questo articolo.
Dopo aver creato il framework di base del set di competenze e aver configurato i servizi di intelligenza artificiale di Azure, è possibile concentrarsi su ogni singola competenza di immagine, definendo input e contesto di origine e mappando gli output ai campi in un indice o in un archivio conoscenze.
Nota
Per un set di competenze di esempio che combina l'elaborazione di immagini con l'elaborazione del linguaggio naturale downstream, vedere Esercitazione REST: Usare REST e intelligenza artificiale per generare contenuto ricercabile dai BLOB di Azure. Illustra come inserire l'output dell'immagine delle competenze nel riconoscimento delle entità e nell'estrazione di frasi chiave.
Input per l'elaborazione di immagini
Come indicato, le immagini vengono estratte durante il cracking del documento e quindi normalizzate come passaggio preliminare. Le immagini normalizzate sono gli input di qualsiasi competenza di elaborazione delle immagini e sono sempre rappresentate in un albero del documento arricchito in uno dei due modi seguenti:
/document/normalized_images/*è per i documenti elaborati per intero./document/normalized_images/*/pagesè per i documenti elaborati in blocchi (pagine).
Che si usi OCR o l'analisi delle immagini, gli input hanno praticamente la stessa costruzione:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
Eseguire il mapping di output ai campi di ricerca
In un set di competenze, l'output delle competenze di Analisi immagini e OCR è sempre testo. Il testo di output è rappresentato come nodi in un albero del documento arricchito interno e ogni nodo deve essere mappato a campi in un indice di ricerca o a proiezioni in un archivio conoscenze per rendere disponibile il contenuto nell'app.
Nel set di competenze, esaminare la sezione
outputsdi ogni competenza per determinare quali nodi esistano nel documento arricchito:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }Creare o aggiornare un indice di ricerca per aggiungere campi per accettare gli output delle competenze.
Nell'esempio di raccolta di campi seguente il contenuto è contenuto BLOB. Metadata_storage_name contiene il nome del file (impostato su
retrievabletrue). Metadata_storage_path è il percorso univoco del BLOB ed è la chiave del documento predefinita. Merged_content viene restituito da Unisci testo (utile quando le immagini sono incorporate).Testo e layoutText sono output delle competenze OCR e devono essere una raccolta di stringhe per acquisire tutto l'output generato da OCR per l'intero documento.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],Aggiornare l'indicizzatore per eseguire il mapping dell'output del set di competenze (nodi in un albero di arricchimento) ai campi di indice.
I documenti arricchiti sono interni. Per esternalizzare i nodi in un albero del documento arricchito, configurare un mapping dei campi di output che specifici il campo indice che riceve il contenuto del nodo. I dati arricchiti sono accessibili dall'app tramite un campo indice. L'esempio seguente mostra un nodo di testo (output OCR) in un documento arricchito mappato a un campo di testo in un indice di ricerca.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]Eseguire l'indicizzatore per richiamare il recupero del documento di origine, l'elaborazione delle immagini e l'indicizzazione.
Verificare i risultati
Eseguire una query sull'indice per controllare i risultati dell'elaborazione delle immagini. Usare Esplora ricerche come client di ricerca, o qualsiasi strumento che invii richieste HTTP. La query seguente seleziona i campi che contengono l'output dell'elaborazione delle immagini.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR riconosce il testo nei file immagine. Ciò significa che i campi OCR (testo e layoutText) sono vuoti se i documenti di origine sono testo puro o immagini pure. Analogamente, i campi di analisi delle immagini (imageCaption e imageTags) sono vuoti se gli input del documento di origine sono rigorosamente di testo. Se gli input di imaging sono vuoti, l'esecuzione dell'indicizzatore genera avvisi. Tali avvisi sono da attendersi quando i nodi non sono popolati nel documento arricchito. Tenere presente che l'indicizzazione BLOB consente di includere o escludere tipi di file, nel caso in cui si volessero usare tipi di contenuto in isolamento. È possibile usare queste impostazioni per ridurre il rumore durante l'esecuzione dell'indicizzatore.
Una query alternativa per il controllo dei risultati può includere il contenuto e i campi merged_content . Notare che questi campi includono il contenuto per qualsiasi file BLOB, anche quelli in cui non è stata eseguita alcuna elaborazione delle immagini.
Informazioni sugli output delle competenze
Gli output delle competenze includono text (OCR), layoutText (OCR), merged_content, captions (analisi delle immagini), tags (analisi delle immagini):
textarchivia l'output generato da OCR. Questo nodo deve essere mappato al campo di tipoCollection(Edm.String). Esiste untextcampo per ogni documento di ricerca costituito da stringhe delimitate da virgole per i documenti che contengono più immagini. La figura seguente mostra l'output OCR per tre documenti. Il primo è un documento contenente un file senza immagini. Il secondo è un documento (file di immagine) contenente una parola, Microsoft. Il terzo è un documento contenente più immagini, alcune senza testo ("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutTextarchivia le informazioni generate da OCR sulla posizione del testo nella pagina, descritte in termini di rettangoli delimitatori e coordinate dell'immagine normalizzata. Questo nodo deve essere mappato al campo di tipoCollection(Edm.String). Esiste unlayoutTextcampo per ogni documento di ricerca costituito da stringhe delimitate da virgole.merged_contentarchivia l'output di una competenza Unione testo e deve essere un campo di grandi dimensioni di tipoEdm.Stringche contiene testo non elaborato dal documento di origine, con incorporatotextal posto di un'immagine. Se i file sono solo testo, l'analisi OCR e l'analisi delle immagini non hanno nulla a che fare emerged_contentsono ugualicontenta (una proprietà BLOB che contiene il contenuto del BLOB).imageCaptionacquisisce una descrizione di un'immagine come singoli tag e una descrizione di testo più lunga.imageTagsarchivia i tag relativi a un'immagine come raccolta di parole chiave, una raccolta per tutte le immagini nel documento di origine.
Lo screenshot seguente è un'illustrazione di un PDF che include testo e immagini incorporate. Il cracking del documento ha rilevato tre immagini incorporate: stormo di gabbiani, mappa, aquila. Altro testo contenuto nell'esempio (inclusi titoli, intestazioni e testo del corpo) è stato estratto come testo ed escluso dall'elaborazione delle immagini.
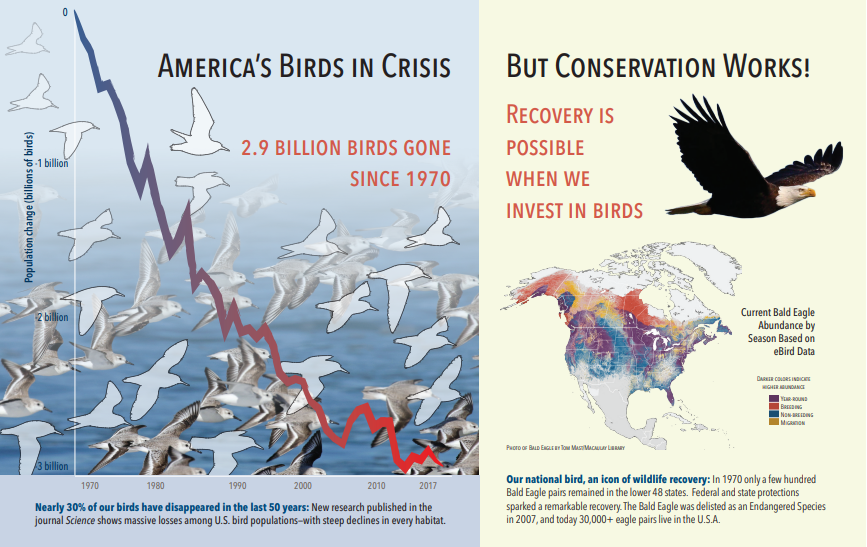
L'output dell'analisi delle immagini è illustrato nel codice JSON seguente (risultato della ricerca). La definizione della competenza consente di specificare quali funzionalità visive siano di interesse. Per questo esempio sono stati prodotti tag e descrizioni, ma sono disponibili più output tra cui scegliere.
imageCaptionoutput è una matrice di descrizioni, una per immagine, indicata datagssingole parole e frasi più lunghe che descrivono l'immagine. Si noti che i tag costituiti da un gregge di gabbiani nuotano nell'acqua o un vicino di un uccello.imageTagsoutput è una matrice di singoli tag, elencati nell'ordine di creazione. Si noti che i tag possono ripetersi. Non ci sono aggregazioni o raggruppamenti.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
Scenario: Immagini incorporate in PDF
Quando le immagini da elaborare vengono incorporate in altri file, ad esempio PDF o DOCX, la pipeline di arricchimento estrae solo le immagini e quindi le passa a OCR o all'analisi delle immagini per l'elaborazione. L'estrazione delle immagini viene eseguita durante la fase di cracking del documento e, una volta separate, le immagini rimangono separate, a meno che l'output elaborato non venga esplicitamente riunito al testo di origine.
Unisci testo viene usato per riportare l'output dell'elaborazione delle immagini nel documento. Anche se Unisci testo non è un requisito obbligatorio, viene spesso richiamato in modo che l'output dell'immagine (testo OCR, layout OCRText, tag di immagine, didascalie di immagine) possa essere reintrodotto nel documento. A seconda della competenza, l'output dell'immagine sostituisce un'immagine binaria incorporata con un equivalente di testo. L'output dell'analisi delle immagini può essere unito in corrispondenza della posizione dell'immagine. L'output OCR viene sempre visualizzato alla fine di ogni pagina.
Il flusso di lavoro seguente illustra il processo di estrazione, analisi e unione di immagini e come estendere la pipeline per eseguire il push dell'output elaborato dall'immagine in altre competenze basate su testo, ad esempio Riconoscimento di entità o Traduzione testuale.
Dopo la connessione all'origine dati, l'indicizzatore carica ed esegue il cracking dei documenti di origine, estrae immagini e testo e accoda ogni tipo di contenuto per l'elaborazione. Viene creato un documento arricchito costituito solo da un nodo radice (documento).
Le immagini nella coda vengono normalizzate e passate in documenti arricchiti come nodo di documento/normalized_images .
Gli arricchimenti delle immagini vengono eseguiti usando
"/document/normalized_images"come input.Gli output delle immagini vengono passati nell'albero dei documenti arricchiti, con ogni output come nodo separato. Gli output variano in base alla competenza (testo e layoutText per OCR; tag e didascalie per l'analisi delle immagini).
(Facoltativo ma consigliato se si desidera che i documenti di ricerca includano sia il testo che il testo di origine immagine) Unisci Testo viene eseguito, combinando la rappresentazione testuale delle immagini con il testo non elaborato estratto dal file. I blocchi di testo vengono consolidati in una singola stringa di grandi dimensioni, in cui il testo viene inserito prima nella stringa e quindi nell'output di testo OCR o tag di immagine e didascalie.
L'output di Unisci testo è ora il testo finale da analizzare per eventuali competenze downstream che eseguono l'elaborazione del testo. Ad esempio, se il set di competenze include sia OCR che Riconoscimento entità, l'input per Riconoscimento entità deve essere
"document/merged_text"(targetName dell'output della competenza Unisci testo).Una volta che tutte le competenze sono state eseguite, il documento arricchito è completo. Nell'ultimo passaggio, gli indicizzatori fanno riferimento ai mapping dei campi di output per inviare contenuto arricchito a singoli campi nell'indice di ricerca.
Il set di competenze di esempio seguente crea un campo merged_text contenente il testo originale del documento con testo OCRed incorporato al posto delle immagini incorporate. Include anche una competenza Riconoscimento entità che usa merged_text come input.
Sintassi del corpo della richiesta
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
Ora che si dispone di un merged_text campo, è possibile eseguirne il mapping come campo ricercabile nella definizione dell'indicizzatore. In questo modo sarà possibile eseguire ricerche su tutti i contenuti dei file, incluso il testo delle immagini.
Scenario: Visualizzare rettangoli di selezione
Un altro scenario comune è la visualizzazione delle informazioni di layout nei risultati della ricerca. All'interno dei risultati della ricerca, ad esempio, è possibile che si voglia evidenziare la posizione in cui è stata trovata una porzione di testo in un'immagine.
Poiché il passaggio OCR viene eseguito su immagini normalizzate, le coordinate del layout si trovano nello spazio dell’immagini normalizzato; tuttavia, se si necessita di visualizzare l'immagine originale, convertire i punti di coordinate nel layout nel sistema di coordinate dell'immagine originale.
L'algoritmo seguente illustra il modello:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
Scenario: competenze personalizzate per immagini
Le immagini possono anche essere passate in e restituite da competenze personalizzate. Un set di competenze base64 codifica l'immagine passata alla competenza personalizzata. Per usare l'immagine all'interno della competenza personalizzata, impostare "/document/normalized_images/*/data" come input per la competenza personalizzata. All'interno del codice di competenza personalizzato, la stringa viene decodificata in base64 prima di convertirla in un'immagine. Per restituire un'immagine al set di competenze, codificare l’immagine in base64 prima di restituirla al set di competenze.
L'immagine viene restituita come oggetto con le proprietà seguenti.
{
"$type": "file",
"data": "base64String"
}
Il repository di Campioni Python di Ricerca di Azure include un esempio completo implementato in Python di una competenza personalizzata per l’arricchimento di immagini.
Passare immagini a competenze personalizzate
Per gli scenari in cui si necessita di una competenza personalizzata per lavorare sulle immagini, è possibile passare immagini alla competenza personalizzata e restituirla come testo o immagini. Il set di competenze seguente proviene da un campione.
Il set di competenze seguente accetta l'immagine normalizzata (ottenuta durante il cracking del documento) e restituisce sezioni dell'immagine.
Set di competenze campione
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
Esempio di competenza personalizzata
La competenza personalizzata è esterna al set di competenze. In questo caso, si tratta di codice Python che esegue prima il ciclo del batch di record di richiesta nel formato di competenza personalizzato, quindi converte la stringa con codifica base64 in un'immagine.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
Analogamente, per restituire un'immagine, restituire una stringa con codifica Base64 all'interno di un oggetto JSON con una $type proprietà di file.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}
Contenuto correlato
- Create indexer (REST) (Creare un'indicizzatore - REST)
- Competenza di analisi di immagini
- OCR skill (Competenza OCR)
- Competenza Unione testo
- Come creare un set di competenze
- Eseguire il mapping dell'output arricchito ai campi