Arricchimento tramite intelligenza artificiale in Ricerca di intelligenza artificiale di Azure
In Ricerca di intelligenza artificiale di Azure l'arricchimento tramite intelligenza artificiale si riferisce all'integrazione con i servizi di intelligenza artificiale di Azure per elaborare il contenuto che non è ricercabile nel formato non elaborato. Tramite l'arricchimento, l'analisi e l'inferenza vengono usate per creare contenuto ricercabile e struttura in cui non esistevano in precedenza.
Poiché Azure AI Search viene usato per le query di testo e vettoriali, lo scopo dell'arricchimento tramite intelligenza artificiale è quello di migliorare l'utilità del contenuto negli scenari correlati alla ricerca. Il contenuto non elaborato deve essere di testo o immagini (non è possibile arricchire i vettori), ma il contenuto creato da una pipeline di arricchimento può essere vettorializzato e indicizzato in un indice vettoriale usando competenze come la competenza divisione del testo per la suddivisione in blocchi e la competenza AzureOpenAIEmbedding per la codifica. Per altre informazioni sull'uso delle competenze negli scenari vettoriali, vedere Suddivisione in blocchi e incorporamento dei dati integrati.
L'arricchimento tramite intelligenza artificiale si basa sulle competenze.
Le competenze predefinite toccano i servizi di intelligenza artificiale di Azure. Applicano le trasformazioni e l'elaborazione seguenti al contenuto non elaborato:
- Rilevamento di traduzione e lingua per la ricerca multilingue
- Riconoscimento delle entità per estrarre nomi, posizioni e altre entità da blocchi di testo di grandi dimensioni
- Estrazione di frasi chiave per identificare e restituire termini importanti
- Riconoscimento ottico dei caratteri (OCR) per riconoscere testo stampato e scritto a mano nei file binari
- Analisi delle immagini per descrivere il contenuto dell'immagine e restituire le descrizioni come campi di testo ricercabili
Le competenze personalizzate eseguono il codice esterno. Le competenze personalizzate possono essere usate per qualsiasi elaborazione personalizzata da includere nella pipeline.
L'arricchimento tramite intelligenza artificiale è un'estensione di una pipeline dell'indicizzatore che si connette alle origini dati di Azure. Una pipeline di arricchimento include tutti i componenti di una pipeline dell'indicizzatore (indicizzatore, origine dati, indice), oltre a un set di competenze che specifica i passaggi di arricchimento atomico.
Il diagramma seguente illustra la progressione dell'arricchimento tramite intelligenza artificiale:
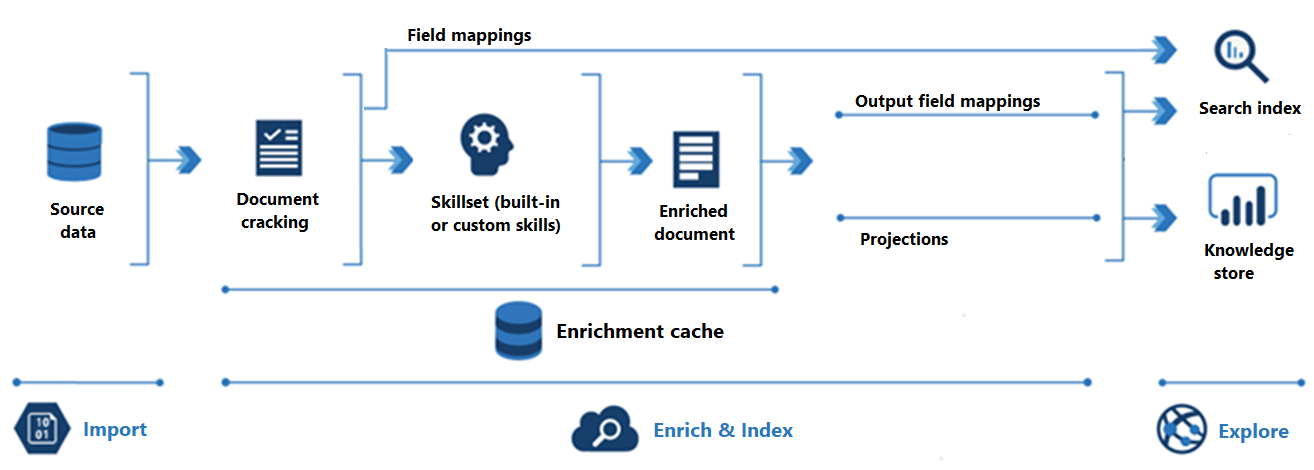
L'importazione è il primo passaggio. In questo caso, l'indicizzatore si connette a un'origine dati ed esegue il pull del contenuto (documenti) nel servizio di ricerca. L’Archiviazione BLOB di Azure è la risorsa più comune usata negli scenari di arricchimento tramite intelligenza artificiale, ma qualsiasi origine dati supportata può fornire contenuto.
Arricchisci e indicizza copre la maggior parte della pipeline di arricchimento tramite intelligenza artificiale:
L'arricchimento inizia quando l'indicizzatore "viola i documenti" ed estrae immagini e testo. Il tipo di elaborazione che si verifica successivamente dipende dai dati e dalle competenze aggiunte a un set di competenze. Se si dispone di immagini, possono essere inoltrate alle competenze che eseguono l'elaborazione delle immagini. Il contenuto del testo viene accodato per l'elaborazione del testo e del linguaggio naturale. Internamente, le competenze creano un "documento arricchito" che raccoglie le trasformazioni man mano che si verificano.
Il contenuto arricchito viene generato durante l'esecuzione del set di competenze ed è temporaneo, a meno che non venga salvato. È possibile abilitare una cache di arricchimento per rendere persistenti i documenti e gli output delle competenze interrotti per il riutilizzo successivo durante le esecuzioni future del set di competenze.
Per ottenere contenuto in un indice di ricerca, l'indicizzatore deve disporre di informazioni di mapping per l'invio di contenuto arricchito al campo di destinazione. I mapping dei campi (esplicito o implicito) impostano il percorso dati dai dati di origine a un indice di ricerca. I mapping dei campi di output impostano il percorso dei dati da documenti arricchiti a un indice.
L'indicizzazione è il processo in cui il contenuto non elaborato e arricchito viene inserito nelle strutture di dati fisiche di un indice di ricerca (relativi file e cartelle). L'analisi lessicale e la tokenizzazione si verificano in questo passaggio.
L’esplorazione è l'ultimo passaggio. L'output è sempre un indice di ricerca su cui è possibile eseguire query da un'app client. L'output può essere facoltativamente un archivio conoscenze costituito da BLOB e tabelle in Archiviazione di Azure a cui si accede tramite strumenti di esplorazione dei dati o processi downstream. Se si sta creando un archivio conoscenze, le proiezioni determinano il percorso dei dati per il contenuto arricchito. Lo stesso contenuto arricchito può essere visualizzato sia negli indici che negli archivi conoscenze.
Quando usare l'arricchimento tramite intelligenza artificiale
L'arricchimento è utile se il contenuto non elaborato è testo non strutturato, contenuto immagine o contenuto che richiede il rilevamento e la traduzione della lingua. L'applicazione dell'intelligenza artificiale tramite le competenze predefinite può sbloccare questo contenuto per le applicazioni di ricerca full-text e data science.
È anche possibile creare competenze personalizzate per fornire l'elaborazione esterna. Il codice open source, di terze parti o di prima parte può essere integrato nella pipeline come competenza personalizzata. I modelli di classificazione che identificano le caratteristiche salienti di vari tipi di documento rientrano in questa categoria, ma è possibile usare qualsiasi pacchetto esterno che aggiunge valore al contenuto.
Casi d'uso per competenze predefinite
Le competenze predefinite si basano sulle API dei servizi di intelligenza artificiale di Azure: Visione artificiale e servizio di linguaggio di Azure per intelligenza artificiale. A meno che l'input del contenuto non sia ridotto, aspettarsi di collegare una risorsa dei servizi di intelligenza artificiale di Azure fatturabile per eseguire carichi di lavoro più grandi.
Un set di competenze assemblato usando competenze predefinite è particolarmente indicato per gli scenari di applicazione seguenti:
Le competenze di elaborazione delle immagini includono il riconoscimento ottico dei caratteri (OCR) e l'identificazione delle caratteristiche visive, ad esempio il rilevamento del viso, l'interpretazione delle immagini o il loro riconoscimento (persone o luoghi famosi) o attributi come l’orientamento dell’immagine. Queste competenze creano rappresentazioni testuali del contenuto dell'immagine per la ricerca full-text in Ricerca di intelligenza artificiale di Azure.
La traduzione automatica viene fornita dalla competenza Traduzione testuale, spesso abbinata al rilevamento della lingua per soluzioni multilingue .
L'elaborazione del linguaggio naturale analizza blocchi di testo. Le competenze in questa categoria includono Riconoscimento delle entità, Rilevamento sentiment (incluso l’opinion mining) e Rilevamento delle informazioni personali. Con queste competenze, viene eseguito il mapping del testo come campi ricercabili e filtrabili in un indice.
Casi d'uso per competenze personalizzate
Le competenze personalizzate eseguono codice esterno fornito e ne eseguono il wrapping nell'interfaccia Web della competenza personalizzata. Sono disponibili diversi esempi di competenze personalizzate nel repository GitHub azure-search-power-skills.
Le competenze personalizzate non sono sempre complesse. Ad esempio, se si dispone di un pacchetto esistente che fornisce criteri di ricerca o un modello di classificazione dei documenti, è possibile eseguirne il wrapping in una competenza personalizzata.
Archiviazione dell'output
In Ricerca di intelligenza artificiale di Azure un indicizzatore salva l'output creato. Una singola esecuzione dell'indicizzatore può creare fino a tre strutture di dati contenenti output arricchiti e indicizzati.
| Archivio dati | Richiesto | Ufficio | Descrizione |
|---|---|---|---|
| indice ricercabile | Richiesto | Servizio di ricerca | Utilizzato per la ricerca full-text e altri moduli di query. Specificare un indice è un requisito dell'indicizzatore. Il contenuto dell'indice viene popolato dagli output delle competenze, oltre a tutti i campi di origine mappati direttamente ai campi nell'indice. |
| archivio conoscenze | Facoltativo | Archiviazione di Azure | Usato per app downstream come knowledge mining o data science. Un archivio conoscenze è definito nell'ambito di un set di competenze. La definizione determina se i documenti arricchiti vengono proiettati come tabelle o oggetti (file o BLOB) in Archiviazione di Azure. |
| cache di arricchimento | Facoltativo | Archiviazione di Azure | Usato per memorizzare nella cache gli arricchimenti per il riutilizzo nelle esecuzioni successive del set di competenze. La cache archivia il contenuto importato e non elaborato (documenti di cui è stata violata la sicurezza). Archivia anche i documenti arricchiti creati durante l'esecuzione del set di competenze. La memorizzazione nella cache è utile se si usa l'analisi delle immagini o OCR e si vuole evitare il tempo e le spese per la rielaborazione dei file di immagine. |
Gli indici e gli archivi conoscenze sono completamente indipendenti l'uno dall'altro. Sebbene sia necessario allegare un indice per soddisfare i requisiti dell'indicizzatore, se l'unico obiettivo è un archivio di conoscenze, è possibile ignorare l'indice dopo il popolamento.
Esplorazione del contenuto
Dopo aver definito e caricato un indice di ricerca o un archivio conoscenze, è possibile esplorarne i dati.
Eseguire query su un indice di ricerca
Eseguire query per accedere al contenuto arricchito generato dalla pipeline. L'indice è simile a qualsiasi altro che è possibile creare per Ricerca di intelligenza artificiale di Azure: è possibile integrare l'analisi del testo con degli analizzatori personalizzati, richiamare query di ricerca fuzzy, aggiungere filtri o sperimentare profili di punteggio per ottimizzare la pertinenza della ricerca.
Usare gli strumenti di esplorazione dei dati in un archivio conoscenze
In Archiviazione di Azure un archivio conoscenze può assumere i formati seguenti: un contenitore BLOB di documenti JSON, un contenitore BLOB di oggetti immagine o tabelle in Archiviazione tabelle. È possibile usare Storage Explorer, Power BI o qualsiasi app che si connette ad Archiviazione di Azure per accedere al contenuto.
Un contenitore BLOB acquisisce i documenti arricchiti nel loro insieme, utile se si crea un feed in altri processi.
Una tabella è utile se sono necessarie delle sezioni di documenti arricchiti, o se si desidera includere o escludere delle parti specifiche dell'output. Per l'analisi in Power BI, le tabelle sono l'origine dati consigliata per l'esplorazione e la visualizzazione dei dati in Power BI.
Disponibilità e prezzi
L'arricchimento è disponibile nelle aree con servizi di intelligenza artificiale di Azure. È possibile controllare la disponibilità dell'arricchimento nella pagina dell'elenco delle aree.
La fatturazione segue un modello di prezzi con pagamento in base al consumo. I costi dell'uso delle competenze predefinite vengono addebitati quando viene specificata una chiave dei servizi di intelligenza artificiale di Azure in più aree nel set di competenze. Sono inoltre previsti dei costi associati all'estrazione di immagini, come rilevato da Ricerca di intelligenza artificiale di Azure. Le competenze di estrazione del testo e utilità, tuttavia, non sono fatturabili. Per altre informazioni, vedere Come vengono addebitati i costi per Ricerca di intelligenza artificiale di Azure.
Elenco di controllo: un flusso di lavoro tipico
Una pipeline di arricchimento è costituita da indicizzatori con set di competenze. Dopo l'indicizzazione, è possibile eseguire query su un indice per convalidare i risultati.
Iniziare con un subset di dati in un'origine dati supportata. La progettazione dell'indicizzatore e del set di competenze è un processo iterativo. Il lavoro va più veloce con un piccolo set di dati rappresentativo.
Creare un'origine dati che specifica una connessione ai dati.
Creare un set di competenze. A meno che il progetto non sia di piccole dimensioni, è necessario collegare una risorsa multiservizio di Intelligenza artificiale di Azure. Se si sta creando un archivio conoscenze, definirlo all'interno del set di competenze.
Creare uno schema di indice che definisce un indice di ricerca.
Creare ed eseguire l'indicizzatore per riunire tutti i componenti precedenti. Questo passaggio recupera i dati, esegue il set di competenze e carica l'indice.
Un indicizzatore è anche il percorso in cui si specificano mapping dei campi e mapping dei campi di output che configurano il percorso dei dati in un indice di ricerca.
Facoltativamente, abilitare la memorizzazione nella cache di arricchimento nella configurazione dell'indicizzatore. Questo passaggio consente di riutilizzare gli arricchimenti esistenti in un secondo momento.
Eseguire query per valutare i risultati o avviare una sessione di debug per risolvere eventuali problemi del set di competenze.
Per ripetere uno dei passaggi precedenti, reimpostare l'indicizzatore prima di eseguirlo. In alternativa, eliminare e ricreare gli oggetti in ogni esecuzione (consigliato se si usa il livello gratuito). Se è stata abilitata la memorizzazione nella cache, l'indicizzatore esegue il pull dalla cache se i dati sono invariati nell'origine e se le modifiche apportate alla pipeline non invalidano la cache.
Passaggi successivi
- Guida introduttiva: Creare un set di competenze per l'arricchimento tramite intelligenza artificiale
- Esercitazione: Informazioni sulle API REST di arricchimento tramite intelligenza artificiale
- Concetti relativi al set di competenze
- Concetti relativi all'archivio conoscenze
- Creare un set di competenze
- Creare un archivio conoscenze