Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive come la generazione aumentata tramite recupero consente ai modelli linguistici di grandi dimensioni (LLM) di trattare le fonti di dati come conoscenze senza bisogno di addestramento.
Gli LLM dispongono di una knowledge base ampia acquisita tramite il training. Per la maggior parte degli scenari, è possibile scegliere un LLM progettato per le proprie esigenze. Tuttavia, tali LLM richiedono un training aggiuntivo per comprendere i dati specifici. La generazione aumentata di recupero consente di rendere disponibili i dati per gli LLM senza doverne eseguire prima il training.
Funzionamento di RAG
Per eseguire la generazione aumentata di recupero, si creano incorporamenti per i dati insieme a domande comuni su di essi. È possibile eseguire questa operazione in tempo reale oppure creare e archiviare gli incorporamenti usando una soluzione di database vettoriale.
Quando un utente pone una domanda, l'LLM usa gli incorporamenti per confrontarla con i dati e trovare il contesto più pertinente. Il contesto e la domanda dell'utente vengono quindi inviati all'LLM tramite una richiesta, a cui l'LLM fornisce una risposta basata sui dati.
Processo RAG di base
Per eseguire la RAG, è necessario elaborare ogni origine dati che si vuole usare per l'estrazione. Il processo di base è il seguente:
- Suddividere i dati di grandi dimensioni in blocchi gestibili.
- Convertire i blocchi in un formato ricercabile.
- Archiviare i dati convertiti in una posizione che consenta un accesso efficiente. Inoltre, è importante archiviare i metadati pertinenti per citazioni o riferimenti quando l'LLM fornisce risposte.
- Fornisci i dati convertiti agli LLM nei prompt.
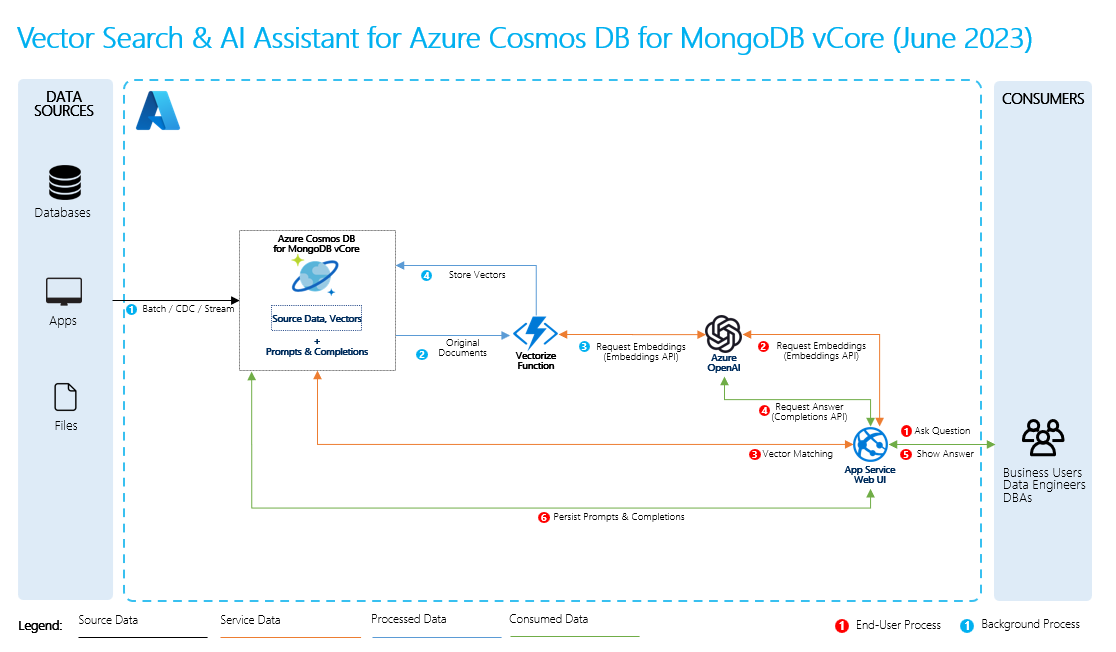
- Dati di origine: si tratta della posizione in cui sono presenti i dati. Potrebbe trattarsi di un file o una cartella nel computer, un file nell'archiviazione nel cloud, un asset di dati di Azure Machine Learning, un repository Git o un database SQL.
- Suddivisione in blocchi di dati: i dati nell'origine devono essere convertiti in testo normale. Ad esempio, i documenti di word o i PDF devono essere aperti e convertiti in testo. Il testo viene quindi suddiviso in blocchi più piccoli.
- Conversione del testo in vettori: si tratta di incorporamenti. I vettori sono rappresentazioni numeriche dei concetti convertiti in sequenze numeriche, che semplificano la comprensione delle relazioni tra tali concetti da parte dei computer.
- Collegamenti tra i dati di origine e gli incorporamenti: queste informazioni vengono archiviate come metadati nei blocchi creati, che vengono quindi usati per consentire agli LLM di generare citazioni durante la generazione di risposte.
Vedere anche
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.