Il processo delle pipeline di distribuzione
Il processo di distribuzione consente di clonare contenuto da una fase della pipeline a un'altra, in genere dallo sviluppo al test e dal test alla produzione.
Durante la distribuzione, Microsoft Fabric copia il contenuto dalla fase di origine a quella di destinazione. Durante il processo di copia le connessioni tra gli elementi copiati vengono mantenute. Inoltre, Fabric applica le regole di distribuzione configurate al contenuto aggiornato nella fase di destinazione. La distribuzione del contenuto può richiedere tempo, a seconda del numero di elementi da distribuire. Durante questo periodo, è possibile passare ad altre pagine del portale ma non è possibile usare il contenuto nella fase di destinazione.
È anche possibile distribuire il contenuto a livello di codice usando le API REST delle pipeline di distribuzione. Per ulteriori informazioni su questo processo, vedere Automatizzare la pipeline di distribuzione usando le API e DevOps.
Nota
La nuova interfaccia utente della pipeline di distribuzione è attualmente in anteprima . Per attivare o usare la nuova interfaccia utente, vedere Iniziare a usare la nuova interfaccia utente.
Esistono due parti principali del processo di pipeline di distribuzione:
Definire la struttura della pipeline di distribuzione
Quando viene creata una pipeline, è necessario definire il numero di fasi desiderate e come devono essere chiamate. È anche possibile rendere pubblica una o più fasi. Il numero di fasi e i relativi nomi sono permanenti e non possono essere modificati dopo la creazione della pipeline. Tuttavia, lo stato pubblico di una fase è modificabile in qualsiasi momento.
Per definire una pipeline, seguire le istruzioni in Creare una pipeline di distribuzione.
Aggiungere contenuto alle fasi
È possibile aggiungere contenuto a una fase della pipeline in due modi:
Assegnare un'area di lavoro a una fase vuota
Quando si distribuisce il contenuto in una fase vuota, viene creata una nuova area di lavoro sulla capacità per la fase in cui si esegue la distribuzione. Tutti i metadati nei report, nelle dashboard e nei modelli semantici dell'area di lavoro originale vengono copiati nella nuova area di lavoro nella fase in cui sta venendo eseguita la distribuzione.
Al termine della distribuzione, aggiornare i modelli semantici in modo da poter usare il contenuto appena copiato. L'aggiornamento dei modelli semantici è necessario perché i dati non vengono copiati da una fase all'altra. Per comprendere quali proprietà degli elementi vengono copiate durante il processo di distribuzione e quali non vengono copiate, vedere la sezione Proprietà degli elementi copiate durante la distribuzione.
Per istruzioni su come assegnare, o su come annullare l'assegnazione, delle aree di lavoro alle fasi della pipeline di distribuzione, vedere Assegnare un'area di lavoro a una pipeline di distribuzione di Microsoft Fabric.
Creare un'area di lavoro
La prima volta che un contenuto viene distribuito, le pipeline di distribuzione controllano se si dispone delle autorizzazioni.
Se queste sono presenti, il contenuto dell'area di lavoro viene copiato nella fase a cui sta venendo eseguita la distribuzione e viene creata una nuova area di lavoro per tale fase sulla capacità.
Se le autorizzazioni non sono presenti, l'area di lavoro viene creata ma il contenuto non viene copiato. È possibile chiedere a un amministratore della capacità di aggiungere l'area di lavoro a una capacità o richiedere autorizzazioni di assegnazione per la capacità. In seguito, quando l'area di lavoro viene assegnata a una capacità, è possibile distribuire contenuto in questa area di lavoro.
Se si usa Premium per utente (PPU) l'area di lavoro viene associata automaticamente alla licenza PPU. In questi casi, le autorizzazioni non sono necessarie. Tuttavia, se viene creata un'area di lavoro con una PPU, solo gli altri utenti PPU possono accedervi. Anche il contenuto creato in tali aree di lavoro può essere usato solo da utenti PPU.
Area di lavoro e proprietà del contenuto
L'utente che esegue la distribuzione diventa automaticamente il proprietario dei modelli semantici clonati e l'unico amministratore della nuova area di lavoro.
Distribuire il contenuto da una fase all'altra
Esistono diversi modi per distribuire contenuto da una fase a un'altra. È possibile distribuire tutto il contenuto oppure selezionare gli elementi di contenuto da distribuire.
È possibile distribuire il contenuto in qualsiasi fase adiacente, in entrambe le direzioni.
La distribuzione di contenuto di una pipeline di produzione di lavoro in una fase con un'area di lavoro esistente prevede quanto segue:
Distribuzione di nuovo contenuto in aggiunta al contenuto già presente.
Distribuzione del contenuto aggiornato per sostituire parte del contenuto già presente.
Processo di distribuzione
Quando il contenuto dalla fase di origine viene copiato nella fase di destinazione, Fabric identifica il contenuto esistente nella fase di destinazione e lo sovrascrive. Per identificare gli elementi di contenuto da sovrascrivere, le pipeline di distribuzione usano la connessione tra l'elemento padre e i relativi cloni. Questa connessione viene mantenuta quando viene creato nuovo contenuto. L'operazione di sovrascrittura sovrascrive soltanto il contenuto dell'elemento. L'ID, l'URL e le autorizzazioni dell'elemento rimangono invariati.
Nella fase di destinazione, le proprietà dell'elemento che non vengono copiate rimangono com'erano prima della distribuzione. Nuovo contenuto e nuovi elementi vengono copiati dalla fase originale alla fase di destinazione.
Associazione automatica
In Fabric, quando gli elementi sono connessi, ciascuno degli elementi dipende dall'altro. Ad esempio, un report dipenderà sempre dal modello semantico a cui è connesso. Un modello semantico può dipendere da un altro modello semantico e può anche essere connesso a diversi report che dipendono da esso. Se è presente una connessione tra due elementi, le pipeline di distribuzione tenteranno sempre di mantenere tale connessione.
Associazione automatica nella stessa area di lavoro
Durante la distribuzione, le pipeline di distribuzione verificano la presenza di dipendenze. La distribuzione ha esito positivo o negativo, a seconda del percorso dell'elemento che fornisce i dati da cui dipende l'elemento distribuito.
L'elemento collegato esiste nella fase di destinazione: le pipeline di distribuzione connettono automaticamente (associazione automatica) l'elemento distribuito all'elemento da cui dipende nella fase distribuita. Ad esempio, se viene distribuito un report impaginato dallo sviluppo al test e questo è connesso a un modello semantico distribuito in precedenza nella fase di test, questo si connette automaticamente allo stesso modello semantico nella fase di test.
L'elemento collegato non esiste nella fase di destinazione: la distribuzione ha esito negativo se un elemento ha una dipendenza da un altro elemento e l'elemento che fornisce i dati non viene distribuito e non risiede nella fase di destinazione. Ad esempio, se viene distribuito un report dallo sviluppo al test e la fase di test non contiene il modello semantico, la distribuzione ha esito negativo. Per evitare distribuzioni con esito negativo a causa di elementi dipendenti non distribuiti, usare il pulsante Seleziona elementi correlati. Seleziona elementi correlati seleziona automaticamente tutti gli elementi che forniscono dipendenze agli elementi da distribuire.
L'associazione automatica funziona solo con gli elementi supportati dalle pipeline di distribuzione e che risiedono in Fabric. Per visualizzare le dipendenze di un elemento, selezionare Visualizza derivazione dal menu Altre opzioni dell'elemento.
- Nuova interfaccia utente di Visualizza derivazione
- Interfaccia utente originaria di Visualizza derivazione
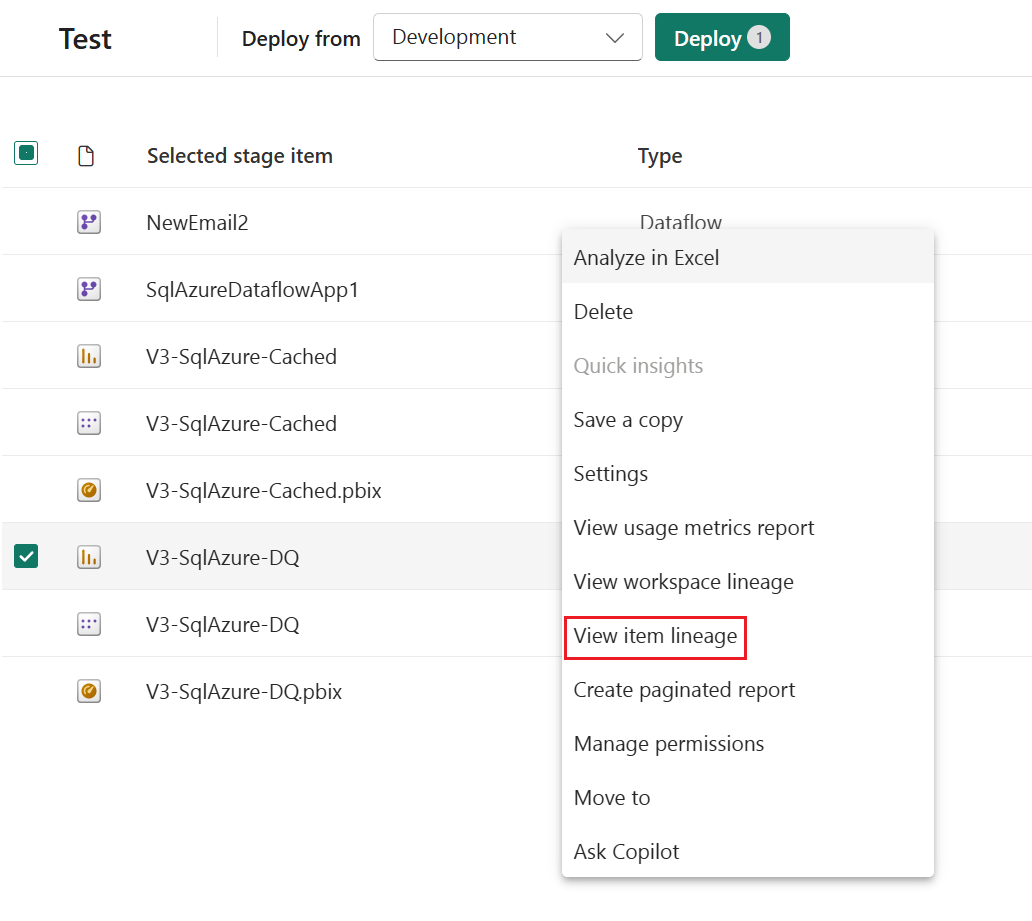
Associazione automatica tra aree di lavoro
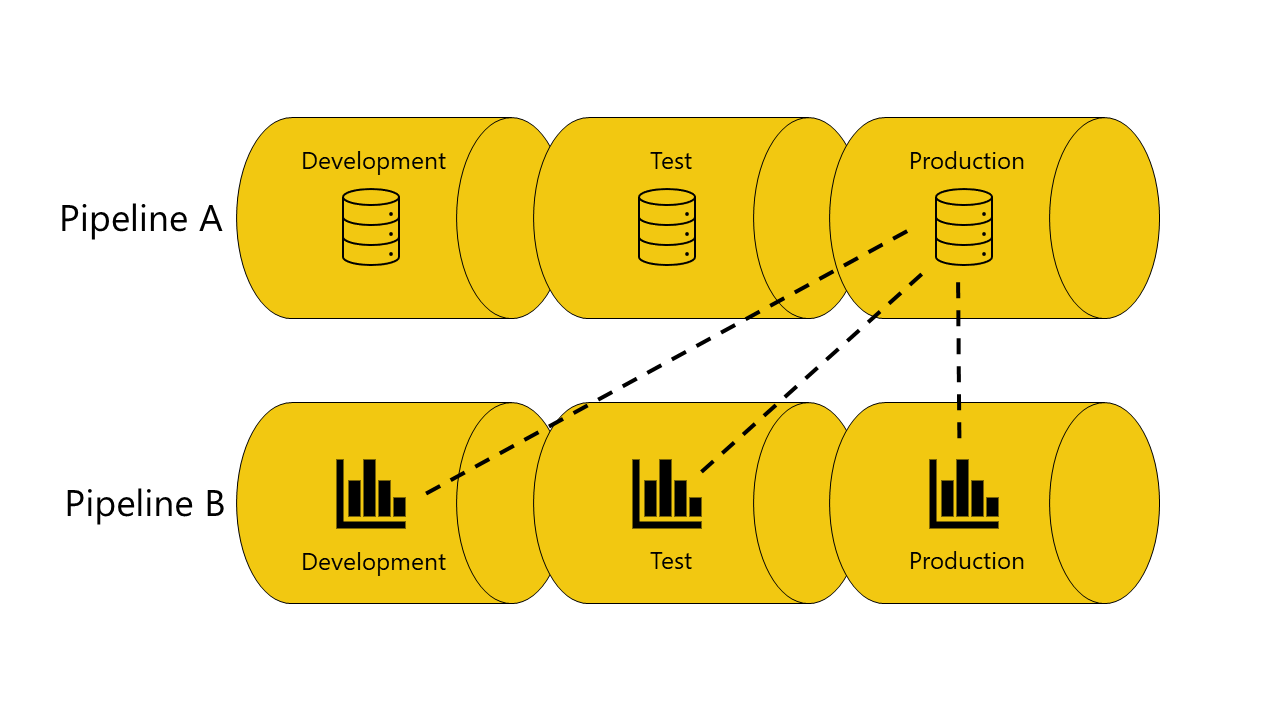
Le pipeline di distribuzione associano automaticamente gli elementi connessi tra le pipeline se si trovano nella stessa fase della pipeline. Quando si distribuiscono tali elementi, le pipeline di distribuzione tentano di stabilire una nuova connessione tra l'elemento distribuito e l'elemento a cui è collegato nell'altra pipeline. Ad esempio, se è presente un report nella fase di test della pipeline A collegato a un modello semantico nella fase di test della pipeline B, le pipeline di distribuzione riconoscono tale connessione.
Ecco un esempio con illustrazioni che mostrano il funzionamento dell'associazione automatica tra le pipeline:
Nella fase di sviluppo della pipeline A è presente un modello semantico.
È disponibile anche un report nella fase di sviluppo della pipeline B.
Il report nella pipeline B è connesso al modello semantico nella pipeline A. Il report dipende da questo modello semantico.
Il report viene distribuito nella pipeline B dalla fase di sviluppo alla fase di test.
La distribuzione ha esito positivo o negativo, a seconda che si disponga o meno di una copia del modello semantico da cui dipende nella fase di test della pipeline A:
È disponibile una copia del modello semantico da cui dipende il report nella fase di test della pipeline A:
La distribuzione ha esito positivo e le pipeline di distribuzione connettono (associazione automatica) il report nella fase di test della pipeline B al modello semantico nella fase di test della pipeline A.
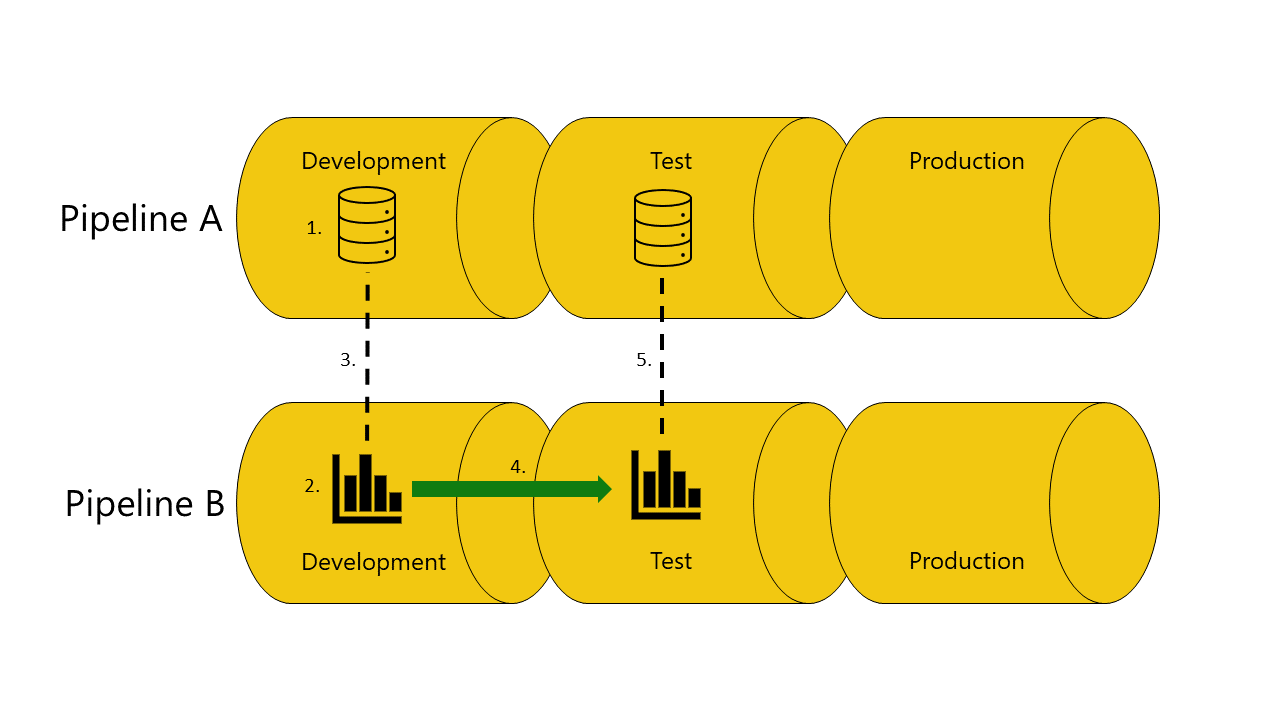
Non è disponibile una copia del modello semantico da cui dipende il report nella fase di test della pipeline A:
La distribuzione ha esito negativo perché le pipeline di distribuzione non possono collegare (associazione automatica) il report nella fase di test nella pipeline B al modello semantico da cui dipende nella fase di test della pipeline A.
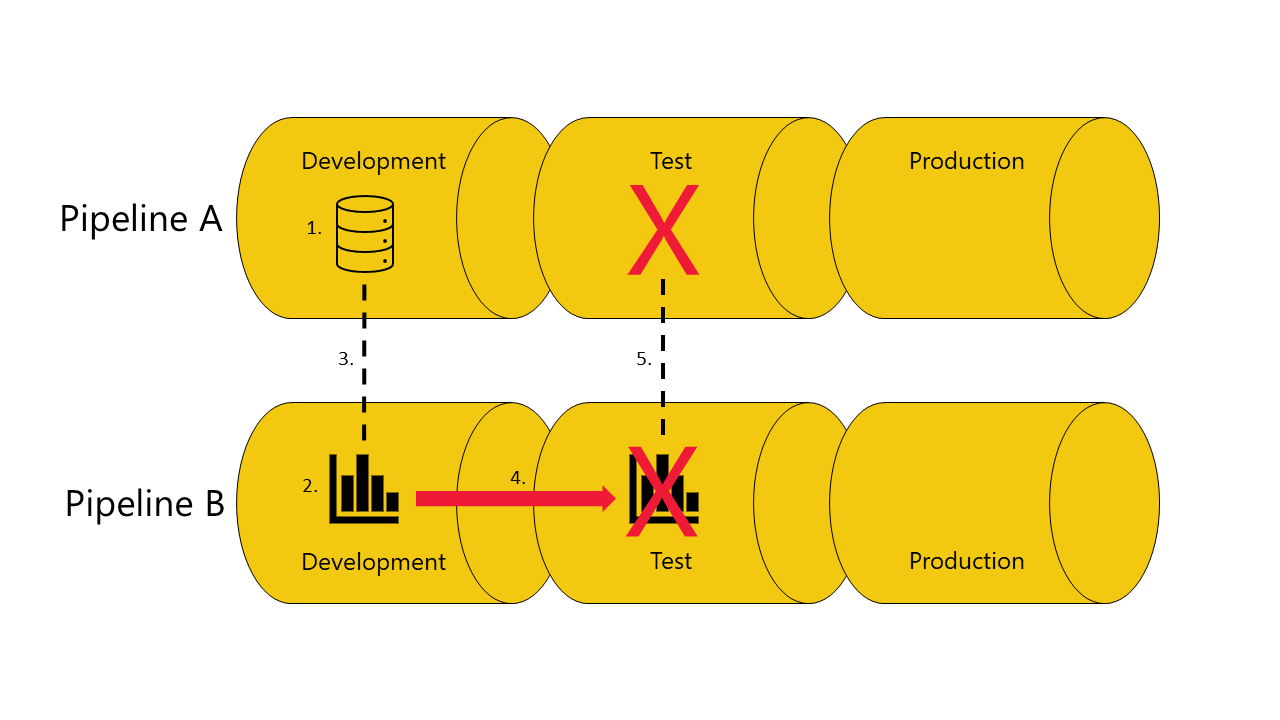
Evitare di usare l'associazione automatica
In alcuni casi, potrebbe non essere necessario usare l'associazione automatica. Ad esempio, se è disponibile una pipeline per lo sviluppo di modelli semantici dell'organizzazione e un'altra per la creazione di report. In questo caso, è possibile mantenere tutti i report sempre connessi ai modelli semantici nella fase di produzione della pipeline a cui appartengono. In questo caso, evitare di usare la funzionalità di associazione automatica.
Esistono tre metodi utilizzabili per evitare di usare l'associazione automatica:
Non connettere l'elemento alle fasi corrispondenti. Quando gli elementi non sono connessi nella stessa fase, le pipeline di distribuzione mantengono la connessione originale. Ad esempio, se si dispone di un report nella fase di sviluppo della pipeline B collegato a un modello semantico nella fase di produzione della pipeline A. Quando si distribuisce il report nella fase di test della pipeline B, questo rimane collegato al modello semantico nella fase di produzione della pipeline A.
Definire una regola dei parametri. Questa opzione non è disponibile per i report. È possibile usarlo solo con modelli semantici e flussi di dati.
Connettere report, dashboard e riquadri a un modello semantico proxy o a un flusso di dati non collegato a una pipeline.
Associazione automatica e parametri
I parametri possono essere usati per controllare le connessioni tra modelli semantici o flussi di dati e gli elementi da cui dipendono. Quando un parametro controlla la connessione, l'associazione automatica dopo la distribuzione non viene eseguita, neanche quando la connessione include un parametro applicabile all'ID del modello semantico o del flusso di dati o all'ID dell'area di lavoro. In questi casi, sarà necessario riassociare gli elementi dopo la distribuzione modificando il valore del parametro o usando le regole dei parametri.
Nota
Se si usano regole di parametro per riassociare gli elementi, i parametri devono essere di tipo Text.
Aggiornamento dei dati
I dati nell'elemento di destinazione, come ad esempio un modello semantico o un flusso di dati, vengono mantenuti quando possibile. Se non sono presenti modifiche a un elemento che contiene i dati, i dati vengono mantenuti come erano prima della distribuzione.
In molti casi, quando si ha una piccola modifica, come ad esempio l'aggiunta o la rimozione di una tabella, Fabric mantiene i dati originali. Le modifiche dello schema che causano un'interruzione o le modifiche del collegamento all'origine dei dati richiedono un aggiornamento completo.
Requisiti per la distribuzione in una fase con un'area di lavoro esistente
Un utente con una licenza, membro delle aree di lavoro di distribuzione di destinazione e di origine, può distribuire contenuto che risiede in una capacità in una fase con un'area di lavoro esistente. Per altre informazioni, vedere la sezione delle autorizzazioni.
Cartelle nelle pipeline di distribuzione (anteprima)
Le cartelle consentono agli utenti di organizzare e gestire in modo efficiente gli elementi dell'area di lavoro in modo familiare. Quando viene distribuito un contenuto che contiene cartelle in una fase diversa, la gerarchia di cartelle degli elementi applicati viene applicata automaticamente.
Rappresentazione delle cartelle
- Nuova interfaccia utente per la rappresentazione delle cartelle
- Interfaccia utente originaria per la rappresentazione delle cartelle
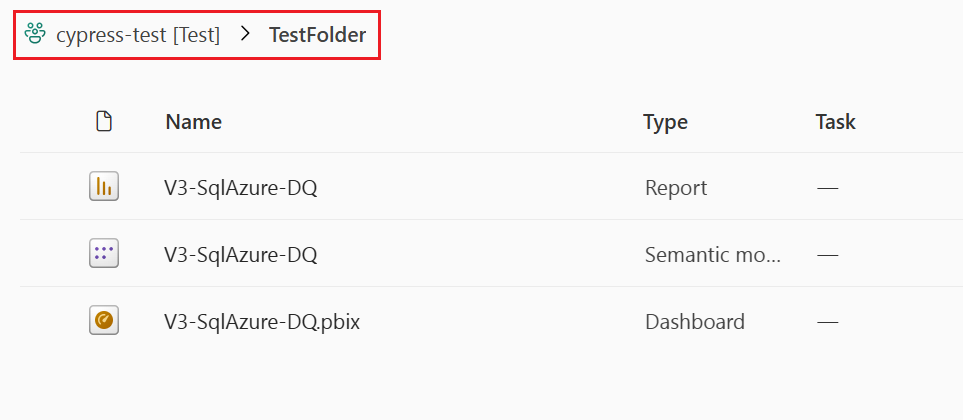
Il contenuto dell'area di lavoro viene visualizzato come strutturato nell'area di lavoro. Le cartelle sono elencate e, per visualizzare i relativi elementi, è necessario selezionare la cartella. Il percorso completo di un elemento viene visualizzato nella parte superiore dell'elenco elementi. Poiché una distribuzione è solo di elementi, è possibile selezionare solo una cartella che contiene elementi supportati. La selezione di una cartella per la distribuzione implica la selezione di tutti i relativi elementi e sottocartelle con i relativi elementi per una distribuzione.
Questa immagine mostra il contenuto di una cartella all'interno dell'area di lavoro. Il percorso completo della cartella viene visualizzato nella parte superiore dell'elenco.
In Pipeline di distribuzione le cartelle sono considerate parte del nome di un elemento (il nome di un elemento include il suo percorso completo). Quando viene distribuito un elemento, dopo che il suo percorso è stato modificato (ad esempio, spostandolo dalla cartella A alla cartella B), la pipeline di distribuzione applica questa modifica all'elemento associato durante la distribuzione: l'elemento associato verrà spostato anch'esso nella cartella B. Se la cartella B non esiste nella fase in cui si esegue la distribuzione, viene prima creata nell'area di lavoro corrispondente. Le cartelle possono essere visualizzate e gestite solo nella pagina dell'area di lavoro.
Distribuire elementi all'interno di una cartella da tale cartella. Non è possibile distribuire elementi da gerarchie diverse contemporaneamente.
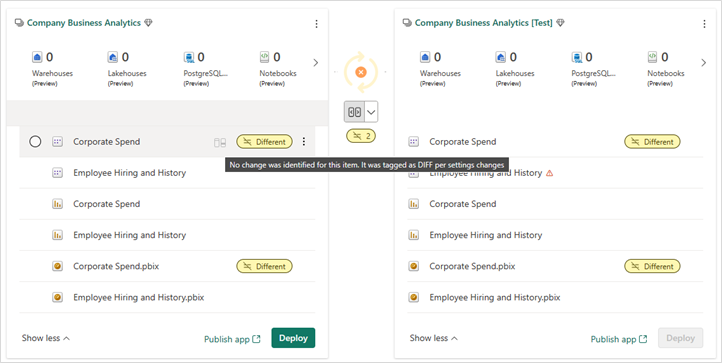
Identificare gli elementi spostati in cartelle diverse
Poiché le cartelle sono considerate parte del nome dell'elemento, gli elementi spostati in una cartella diversa nell'area di lavoro vengono identificati nella pagina Pipeline di distribuzione come Diverse quando viene effettuato un confronto. Questo elemento non viene visualizzato nella finestra di confronto perché non è una modifica dello schema, ma le impostazioni cambiano.
- Elemento di una cartella spostato nella nuova interfaccia utente
- Elemento di una cartella spostato nell'interfaccia utente originaria

Le singole cartelle non possono essere distribuite manualmente nelle pipeline di distribuzione. La loro distribuzione viene attivata automaticamente quando viene distribuito almeno uno dei relativi elementi.
La gerarchia di cartelle degli elementi associati viene aggiornata solo durante la distribuzione. Durante l'assegnazione, dopo il processo di associazione, la gerarchia degli elementi associati non viene ancora aggiornata.
Poiché una cartella viene distribuita solo se viene distribuito uno dei relativi elementi, non è possibile distribuire una cartella vuota.
La distribuzione di uno tra più elementi in una cartella aggiorna anche la struttura degli elementi non distribuiti nella fase di destinazione, anche se gli elementi stessi non vengono distribuiti.
Rappresentazione di elementi padre-figlio
Questi elementi vengono visualizzati solo nella nuova interfaccia utente. Ha lo stesso aspetto dell'area di lavoro. L'elemento figlio non viene distribuito ma ricreato nella fase di destinazione
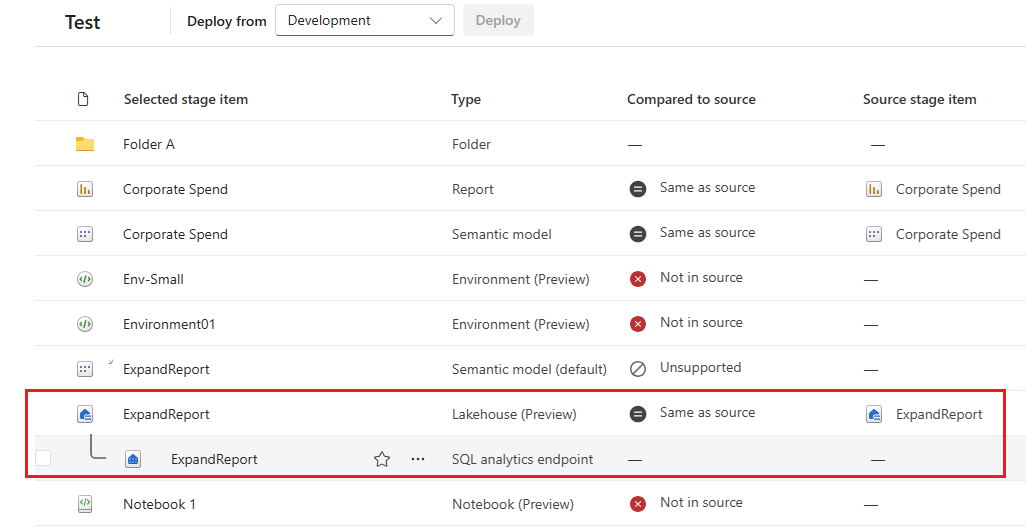
Proprietà degli elementi copiate durante la distribuzione
Per un elenco degli elementi supportati, vedere Elementi supportati delle pipeline di distribuzione.
Durante la distribuzione, le proprietà degli elementi seguenti vengono copiate e sovrascrivono le proprietà degli elementi nella fase di destinazione:
Origini dati (sono supportate le regole di distribuzione)
Parametri (sono supportate le regole di distribuzione)
Oggetti visivi del report
Pagine del report
Riquadri della dashboard
Metadati modello
Relazioni tra elementi
Le etichette di riservatezza vengono copiate solo quando viene soddisfatta una delle condizioni seguenti. Se queste condizioni non vengono soddisfatte, le etichette di riservatezza non vengono copiate durante la distribuzione.
Viene distribuito un nuovo elemento o un elemento esistente viene distribuito in una fase vuota.
Nota
Nei casi in cui l'etichettatura predefinita è abilitata nel tenant e l'etichetta predefinita è valida, se l'elemento distribuito è un modello semantico o un flusso di dati, l'etichetta viene copiata dall'elemento di origine solo se l'etichetta ha protezione. Se l'etichetta non è protetta, l'etichetta predefinita viene applicata al modello semantico di destinazione o al flusso di dati appena creato.
L'elemento di origine ha un'etichetta protetta e l'elemento di destinazione no. In questo caso viene visualizzata una finestra a comparsa che richiede il consenso per eseguire la sostituzione dell'etichetta di riservatezza di destinazione.
Proprietà degli elementi che non vengono copiate
Durante la distribuzione non vengono copiate le proprietà degli elementi seguenti:
Dati: i dati non sono copiati. Vengono copiati solo i metadati
URL
ID
Autorizzazioni: per un'area di lavoro o un elemento specifico
Impostazioni dell'area di lavoro: ogni fase ha una propria area di lavoro
Contenuto e impostazioni dell'app: per aggiornare le app, vedere Aggiornare il contenuto alle app di Power BI
Durante la distribuzione non vengono copiate neanche le proprietà dei modelli semantici seguenti:
Assegnazione di ruolo
Aggiorna pianificazione
Credenziali origine dati
Impostazioni di memorizzazione nella cache delle query (possono essere ereditate dalla capacità)
Impostazioni di approvazione
Funzionalità del modello semantico supportate
Le pipeline di distribuzione supportano molte funzionalità del modello semantico. In questa sezione vengono presentate due funzionalità del modello semantico che consentono di migliorare l'esperienza delle pipeline di distribuzione:
Aggiornamento incrementale
Le pipeline di distribuzione supportano l'aggiornamento incrementale, una funzionalità che consente di aggiornare in modo più rapido e affidabile modelli semantici di grandi dimensioni con un consumo ridotto.
Le pipeline di distribuzione consentono di applicare aggiornamenti a un modello semantico con l'aggiornamento incrementale, mantenendo nel contempo sia i dati sia le partizioni. Quando si distribuisce il modello semantico vengono distribuiti anche i criteri.
Per comprendere il comportamento dell'aggiornamento incrementale con i flussi di dati, vedere perché vengono visualizzate due origini dati connesse al flusso di dati dopo l'uso delle regole del flusso di dati?
Nota
Le impostazioni di aggiornamento incrementale non vengono copiate in Gen 1.
Attivazione dell'aggiornamento incrementale in una pipeline
Per abilitare l'aggiornamento incrementale, configurarlo in Power BI Desktop e poi pubblicare il modello semantico. Dopo la pubblicazione, i criteri di aggiornamento incrementale sono simili nell'intera pipeline e possono essere creati solo in Power BI Desktop.
Dopo aver configurato la pipeline con l'aggiornamento incrementale, è consigliabile usare il flusso seguente:
Apportare modifiche al file con estensione .pbix in Power BI Desktop. Per evitare tempi di attesa prolungati, è possibile apportare modifiche usando un campione dei dati.
Caricare il file con estensione .pbix nella prima fase (solitamente è quella di sviluppo).
Distribuire il contenuto nella fase successiva. Dopo la distribuzione, le modifiche apportate verranno applicate all'intero modello semantico in uso.
Esaminare le modifiche apportate in ogni fase e dopo averle verificate, eseguire la distribuzione nella fase successiva fino a raggiungere la fase finale.
Esempi di utilizzo
I seguenti sono esempi di come integrare l'aggiornamento incrementale con le pipeline di distribuzione.
Creare una nuova pipeline e connetterla a un'area di lavoro con un modello semantico in cui è abilitato l'aggiornamento incrementale.
Abilitare l'aggiornamento incrementale in un modello semantico già presente in un'area di lavoro di sviluppo.
Creare una pipeline da un'area di lavoro di produzione con un modello semantico che usa l'aggiornamento incrementale. Per esempio, è possibile assegnare l'area di lavoro alla fase di produzione di una nuova pipeline e usare la distribuzione nella fase precedente per eseguire la distribuzione nella fase di test e quindi nella fase di sviluppo.
Pubblicare un modello semantico che usa l'aggiornamento incrementale in un'area di lavoro che fa parte di una pipeline esistente.
Limitazioni dell'aggiornamento incrementale
Per l'aggiornamento incrementale, le pipeline di distribuzione supportano solo i modello semantico che usano i metadati di modelli semantici avanzati. Tutti i modelli semantici creati o modificati con Power BI Desktop implementano automaticamente metadati di modelli semantici avanzati.
Quando si ripubblica un modello semantico in una pipeline attiva con l'aggiornamento incrementale abilitato, le seguenti modifiche provocano un errore di distribuzione causato dalla possibile perdita di dati:
Ripubblicazione di un modello semantico che non usa l'aggiornamento incrementale per sostituirlo con uno in cui l'aggiornamento incrementale è abilitato.
Ridenominazione di una tabella in cui è abilitato l'aggiornamento incrementale.
Ridenominazione di colonne non calcolate in una tabella in cui è abilitato l'aggiornamento incrementale.
Altre modifiche sono consentite, ad esempio l'aggiunta di una colonna, la rimozione di una colonna e la ridenominazione di una colonna calcolata. Se tuttavia le modifiche hanno effetto sulla visualizzazione, è necessario aggiornare per rendere visibile la modifica.
Modelli compositi
I modelli compositi consentono di impostare un report con più connessioni dati.
È possibile usare la funzionalità dei modelli compositi per connettere un modello semantico di Fabric a un set di dati esterno, ad esempio Azure Analysis Services. Per altre informazioni, vedere Uso di DirectQuery per i modelli semantici di Fabric e Azure Analysis Services.
In una pipeline di distribuzione è possibile usare i modelli compositi per connettere un modello semantico a un altro modello semantico di Fabric esterno alla pipeline.
Aggregazioni automatiche
Le aggregazioni automatiche si basano sulle aggregazioni definite dall'utente e usano l'apprendimento automatico per ottimizzare continuamente i modelli semantici DirectQuery per ottenere prestazioni massime delle query del report.
Ogni modello semantico mantiene le aggregazioni automatiche dopo la distribuzione. Le pipeline di distribuzione non modificano l'aggregazione automatica di un modello semantico. Ciò significa che se si distribuisce un modello semantico con un'aggregazione automatica, l'aggregazione automatica nella fase di destinazione rimane invariata e non viene sovrascritta dall'aggregazione automatica distribuita dalla fase di origine.
Per abilitare le aggregazioni automatiche, seguire le istruzioni riportate in Configurare l'aggregazione automatica.
Tabelle ibride
Le tabelle ibride sono tabelle con aggiornamento incrementale che può avere partizioni di query dirette e di importazione. Durante una distribuzione pulita, vengono copiati sia i criteri di aggiornamento che le partizioni di tabella ibrida. Quando viene eseguita la distribuzione in una fase della pipeline che ha già partizioni di tabella ibride, vengono copiati solo i criteri di aggiornamento. Per aggiornare le partizioni, aggiornare la tabella.
Aggiornare il contenuto alle app Power BI
Le app Power BI rappresentano la modalità consigliata per la distribuzione di contenuto agli utenti che usano Fabric gratuitamente. È possibile aggiornare il contenuto delle app Power BI usando una pipeline di distribuzione, offrendo maggiore controllo e flessibilità in termini di ciclo di vita dell'app.
Creare un'app per ogni fase della pipeline di distribuzione, in modo da poter testare ogni aggiornamento dell'app dal punto di vista dell'utente finale. Usare il pulsante di pubblicazione o visualizzazione nella scheda dell'area di lavoro per pubblicare o visualizzare l'app in una fase specifica della pipeline.
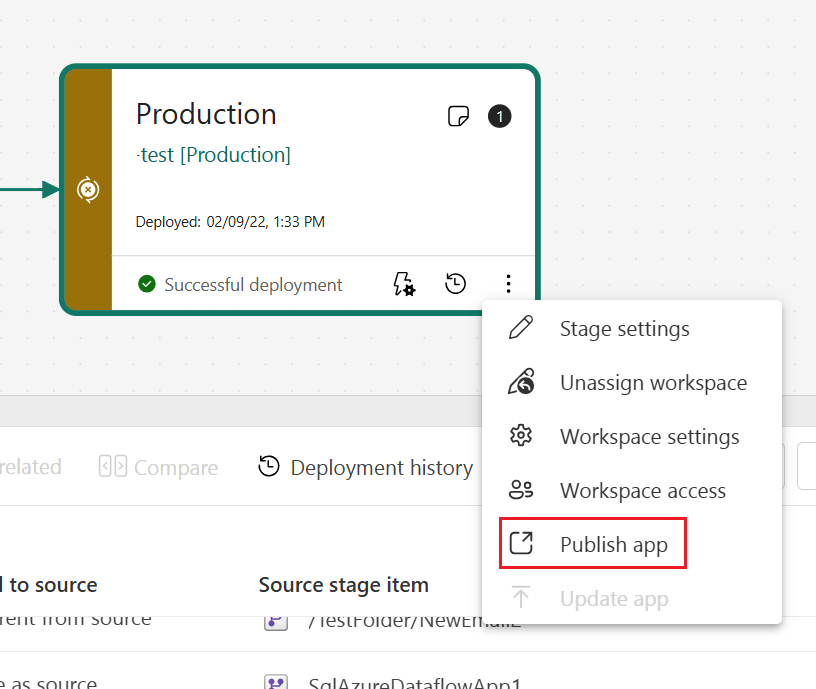

Nella fase di produzione è anche possibile aggiornare la pagina dell'app in Fabric, in modo che tutti gli aggiornamenti del contenuto diventino disponibili per gli utenti dell'app.
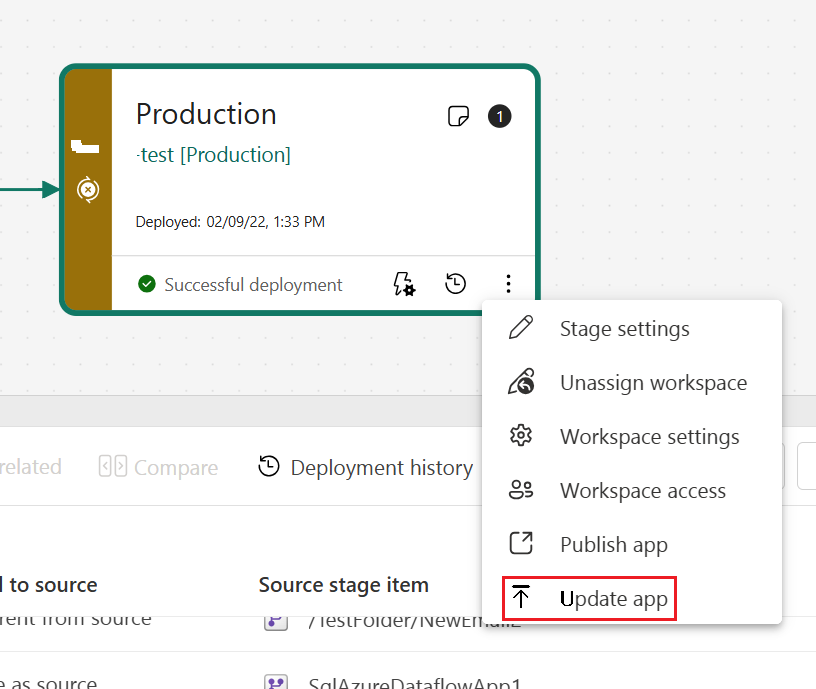

Importante
Il processo di distribuzione non include l'aggiornamento del contenuto o delle impostazioni dell'app. Per applicare le modifiche al contenuto o alle impostazioni, è necessario aggiornare manualmente l'app nella fase della pipeline richiesta.
Autorizzazioni
Le autorizzazioni sono necessarie per la pipeline e per le aree di lavoro assegnate. Le autorizzazioni della pipeline e quelle dell'area di lavoro vengono concesse e gestite separatamente.
Le pipeline dispongono di una sola autorizzazione, amministratore, necessaria per la condivisione, la modifica e l'eliminazione di una pipeline.
Le aree di lavoro hanno autorizzazioni diverse, dette anche ruoli. I ruoli dell'area di lavoro determinano il livello di accesso a un'area di lavoro in una pipeline.
Le pipeline di distribuzione non supportano i gruppi di Microsoft 365 come amministratori della pipeline.
Per eseguire la distribuzione da una fase a un'altra nella pipeline, è necessario essere amministratore della pipeline e anche collaboratore, membro o amministratore degli spazi di lavoro assegnati alle fasi coinvolte. Ad esempio, un amministratore della pipeline a cui non è assegnato un ruolo dell'area di lavoro può visualizzare la pipeline e condividerla con altri utenti. Tuttavia, questo utente non può visualizzare il contenuto dell'area di lavoro nella pipeline o nel servizio e non può eseguire distribuzioni.
Tabella autorizzazioni
Questa sezione descrive le autorizzazioni della pipeline di distribuzione. Le autorizzazioni elencate in questa sezione possono avere applicazioni diverse in altre funzionalità di Fabric.
L'autorizzazione della pipeline di distribuzione più bassa è l'amministratore della pipeline di pipeline ed è necessaria per tutte le operazioni della pipeline di distribuzione.
| User | Autorizzazioni della pipeline | Commenti |
|---|---|---|
| Amministratore della pipeline |
|
L'accesso alla pipeline non implica la concessione delle autorizzazioni per la visualizzazione o l'esecuzione di azioni sul contenuto dell'area di lavoro. |
|
Visualizzatore dell'area di lavoro (e amministratore della pipeline) |
|
I membri dell'area di lavoro assegnati al ruolo Spettatore senza autorizzazioni di compilazione, non possono accedere al modello semantico o modificare il contenuto dell'area di lavoro. |
|
Collaboratore dell'area di lavoro (e amministratore della pipeline) |
|
|
|
Membro dell'area di lavoro (e amministratore della pipeline) |
|
Se l'impostazione per bloccare la ripubblicazione e disabilitare l'aggiornamento del pacchetto, situata nella sezione sicurezza del modello semantico del tenant, è abilitata, solo i proprietari del modello semantico sono in grado di aggiornare i modelli semantici. |
|
Amministratore dell'area di lavoro (e amministratore della pipeline) |
|
Autorizzazioni concesse
Quando si distribuiscono elementi di Power BI, la proprietà dell'elemento distribuito potrebbe cambiare. Esaminare la tabella seguente per individuare chi può distribuire ogni elemento e come la distribuzione influisce sulla proprietà dell'elemento.
| Elemento di Fabric | Autorizzazione necessaria per la distribuzione di un elemento esistente | Proprietà dell'elemento dopo una prima distribuzione | Proprietà dell'elemento dopo la distribuzione in una fase con l'elemento |
|---|---|---|---|
| Modello semantico | Membro dell'area di lavoro | L'utente che ha effettuato la distribuzione diventa il proprietario | Unchanged |
| Flusso di dati | Proprietario del flusso di dati | L'utente che ha effettuato la distribuzione diventa il proprietario | Unchanged |
| Data mart | Proprietario data mart | L'utente che ha effettuato la distribuzione diventa il proprietario | Unchanged |
| Report impaginato | Membro dell'area di lavoro | L'utente che ha effettuato la distribuzione diventa il proprietario | L'utente che ha effettuato la distribuzione diventa il proprietario |
Autorizzazioni necessarie per le azioni più diffuse
La tabella seguente elenca le autorizzazioni necessarie per le azioni più diffuse della pipeline di distribuzione. Se non specificato diversamente, per ogni azione sono necessarie tutte le autorizzazioni elencate.
| Azione | Autorizzazioni necessarie |
|---|---|
| Visualizzare l'elenco delle pipeline nell'organizzazione | Nessuna licenza necessaria (utente gratuito) |
| Creare una pipeline | Un utente con una delle licenze seguenti:
|
| Eliminare una pipeline | Amministratore della pipeline |
| Aggiungere o rimuovere un utente della pipeline | Amministratore della pipeline |
| Assegnare un'area di lavoro a una fase |
|
| Annullare l'assegnazione di un'area di lavoro a una fase | Uno dei ruoli seguenti:
|
| Eseguire la distribuzione in uno stadio vuoto (vedere nota) |
|
| Distribuire gli elementi nella fase successiva (vedere la nota) |
|
| Visualizzare o impostare una regola |
|
| Gestire le impostazioni della pipeline | Amministratore della pipeline |
| Visualizzare una fase della pipeline |
|
| Visualizzare l'elenco di elementi in una fase | Amministratore della pipeline |
| Confrontare due fasi |
|
| Visualizza cronologia di distribuzione | Amministratore della pipeline |
Nota
Per distribuire il contenuto nell'ambiente GCC, è necessario essere almeno un membro dell'area di lavoro di origine e di destinazione. La distribuzione come collaboratore non è ancora supportata.
Considerazioni e limitazioni
Questa sezione elenca la maggior parte delle limitazioni delle pipeline di distribuzione.
- L'area di lavoro deve risiedere in una capacità Fabric.
- Attualmente, quando si distribuisce un'area di lavoro in un'area di destinazione esistente in un'area diversa, potrebbe non essere presente un avviso nella finestra di dialogo di distribuzione.
- Il numero massimo di elementi che si possono distribuire in una singola distribuzione è 300.
- Il download di un file con estensione .pbix dopo la distribuzione non è supportato.
- I gruppi di Microsoft 365 non sono supportati come amministratori della pipeline.
- Quando viene distribuito un elemento di Power BI per la prima volta, se un altro elemento nella fase di destinazione ha lo stesso tipo (ad esempio, se entrambi i file sono report) e nome, la distribuzione non va a buon fine.
- Per l'elenco delle limitazioni delle aree di lavoro, vedere le limitazioni all'assegnazione di aree di lavoro.
- Per un elenco di elementi supportati, vedere elementi supportati. Qualsiasi elemento non presente nell'elenco, non è supportato.
- La distribuzione ha esito negativo se uno degli elementi ha dipendenze circolari o autonome ( ad esempio, l'elemento A fa riferimento all'elemento B e l'elemento B fa riferimento all'elemento A).
- I report PBIR non sono supportati.
Limitazione del modello semantico
Non è possibile distribuire i set di dati che usano la connettività dei dati in tempo reale.
Non sono supportati modelli semantici con directQuery o modalità di connettività composita che usano varianti o tabelle di data/ora automatica. Per ulteriori informazioni, vedere Cosa è possibile fare con un set di dati con directQuery o modalità di connettività composita, che usa tabelle di variazione o calendario?.
Durante la distribuzione, se il modello semantico di destinazione usa una connessione dinamica, anche il modello semantico di origine deve usare questa modalità di connessione.
Dopo la distribuzione, il download di un modello semantico (dalla fase in cui è stato distribuito) non è supportato.
Per un elenco delle limitazioni delle regole di distribuzione, vedere Limitazioni delle regole di distribuzione.
Se è attivata l'associazione automatica, allora:
- La query nativa e DirectQuery insieme non sono supportate. Sono inclusi i set di dati proxy.
- La connessione all'origine dati deve essere il primo passaggio dell'espressione mashup.
Quando viene distribuito un modello semantico Direct Lake, questo non viene associato automaticamente agli elementi nella fase di destinazione. Ad esempio, se un LakeHouse è un'origine per un modello semantico DirectLake e vengono entrambi distribuiti nella fase successiva, il modello semantico DirectLake nella fase di destinazione sarà comunque associato a LakeHouse nella fase di origine. Usare le regole dell'origine dati per associarlo a un elemento nella fase di destinazione. Altri tipi di modelli semantici vengono associati automaticamente all'elemento associato nella fase di destinazione.
Limitazioni del flusso di dati
Le impostazioni di aggiornamento incrementale non vengono copiate in Gen 1.
Quando si distribuisce un flusso di dati in una fase vuota, le pipeline di distribuzione creano una nuova area di lavoro e impostano l'archiviazione del flusso di dati su un archivio blob di Fabric. L'archiviazione blob viene usata anche se l'area di lavoro di origine è configurata per l'uso di Azure data lake storage Gen2 (ADLS Gen2).
L'entità servizio non è supportata per i flussi di dati.
La distribuzione di common data model (CDM) non è supportata.
Per le limitazioni delle regole della pipeline di distribuzione che influiscono sui flussi di dati, vedere Limitazioni delle regole di distribuzione.
Se un flusso di dati viene aggiornato durante la distribuzione, la distribuzione ha esito negativo.
Quando si confrontano le fasi durante l'aggiornamento del flusso di dati, i risultati sono imprevedibili.
Limitazioni di data mart
Non è possibile distribuire un data mart con etichette di riservatezza.
Per distribuire un data mart, è necessario essere il proprietario del data mart.