Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Microsoft Fabric offre diversi modi per inserire i dati nell'ambiente di analisi. Sia che sia necessario elaborare eventi di streaming in tempo reale, replicare database operativi, orchestrare pipeline batch o accedere ai dati senza copiarli, Fabric offre funzionalità predefinite per supportare ogni scenario.
Questo articolo descrive le opzioni principali per l'inserimento dati e lo spostamento dei dati in Fabric. Si tratta di:
- Inserimento in tempo reale con Eventstreams e Eventhouse
- Orchestrazione batch con pipeline di Data Factory e processo di copia
- Replica quasi in tempo reale con modalità di mirroring
- Virtualizzazione dei dati con scorciatoie di OneLake
Usare questa panoramica per comprendere il funzionamento di ogni approccio e scegliere la strategia più adatta ai requisiti del carico di lavoro per latenza, trasformazione e complessità operativa.
Inserimento dati in tempo reale
Gli elementi Eventstream e Eventhouse nel carico di lavoro di Real-Time Intelligence supportano scenari di dati di streaming. I flussi di eventi inseriscono ed elaborano eventi in tempo reale e i depositi di eventi archiviano ed eseguono query su larga scala. In genere si usa un flusso di eventi per acquisire e instradare i dati a una eventhouse. È anche possibile usare ogni funzionalità in modo indipendente in base ai requisiti. Il diagramma seguente illustra il flusso dei set di dati in tempo reale a Eventstream e Eventhouse in Fabric:
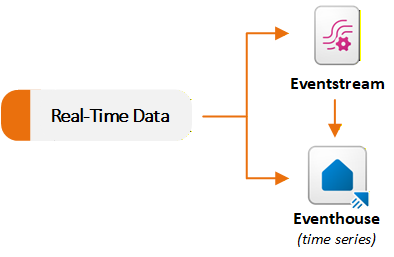
Inserire e instradare eventi con Eventstream
Eventstream offre un'esperienza senza codice per inserire eventi in Fabric, applicare trasformazioni in flusso e instradare i dati a più destinazioni. Un Eventstream funge da pipeline di inserimento in tempo reale. Si crea un eventstream e si aggiungono uno o più connettori di origine. Fabric supporta molte origini di streaming, tra cui eventi interni di Fabric come eventi della workspace di Fabric, eventi di file OneLake ed eventi di processo del pipeline.
Dopo l'avvio del flusso degli eventi, è possibile applicare in tempo reale trasformazioni facoltative tramite un editor trascina e rilascia. Ad esempio, è possibile filtrare gli eventi, le aggregazioni della finestra temporale di calcolo, unire più flussi o rimodellare i campi senza scrivere codice.
È possibile inviare il flusso elaborato a una o più destinazioni supportate. I flussi di eventi possono esporre endpoint Apache Kafka tramite origini e destinazioni endpoint personalizzate. Questa funzionalità consente ai producer Kafka di trasmettere gli eventi nel Fabric e ai consumer Kafka di utilizzare eventi dal Fabric.
I flussi di eventi non archiviano i dati in modo permanente. Trasmette gli eventi attraverso la memoria e li inoltra alle destinazioni configurate. Questa progettazione rende i flussi di eventi adatti per scenari di estrazione, trasformazione, caricamento (ETL) in tempo reale e per la distribuzione dei dati di streaming in più destinazioni. Ad esempio, è possibile inserire dati di telemetria da sensori Internet delle cose (IoT), filtrare e aggregare i dati in tempo reale, inviare il flusso perfezionato a un eventhouse per l'analisi e instradare gli eventi di anomalia a Activator per l'invio di avvisi.
Inserire i dati direttamente in Eventhouse
Eventhouses possono acquisire dati direttamente da più origini. Fabric include un'esperienza integrata di recupero dei dati all'interno di Eventhouse. La procedura guidata si connette a fonti come file locali, Archiviazione di Azure, Amazon S3, Hub eventi di Azure e OneLake. È possibile caricare i dati in una tabella di database KQL (Kusto Query Language) in tempo reale o in modalità batch usando l'interfaccia utente eventhouse.
È anche possibile selezionare un eventstream esistente in Fabric come origine. Ad esempio, se si usa un flusso di eventi che inserisce dati dall'hub IoT o Da Kafka, è possibile indirizzarne l'output direttamente a una tabella di database KQL senza alcuna configurazione aggiuntiva.
Inserimento dati a blocchi
Data Factory offre l'esperienza principale per le pipeline di estrazione, trasformazione, caricamento (ETL) e estrazione, caricamento, trasformazione (ELT) tradizionali. Include una libreria di connettori di grandi dimensioni. Fabric Data Factory fornisce un elenco di connettori nativi per archivi dati locali e cloud, inclusi database, applicazioni SaaS (Software as a Service) e sistemi basati su file. Questi connettori consentono di connettersi a quasi tutti i sistemi di origine.
Orchestrare lo spostamento dei dati con le pipeline
È possibile compilare pipeline che usano questi connettori per copiare o spostare i dati in archivi onelake o analitici. Questo approccio supporta:
- Set di dati non strutturati, ad esempio immagini, video e audio
- Set di dati semistrutturati, ad esempio JSON, CSV e XML
- Set di dati strutturati da sistemi di database relazionali supportati
In una pipeline si combinano più componenti di orchestrazione, tra cui:
- Attività di spostamento dei dati, ad esempio Copia dati e Copia attività
- Attività di trasformazione dei dati, ad esempio Dataflow Gen2, Elimina dati, Notebook di Fabric e script SQL
- Attività del flusso di controllo, ad esempio ForEach, Lookup, Set Variable e Webhook
È possibile eseguire una pipeline su richiesta, in base a una pianificazione o in risposta agli eventi. Ad esempio, è possibile pianificare l'esecuzione di una pipeline ogni due ore durante i giorni feriali o attivarla quando viene creato un nuovo file in OneLake.
Semplificare lo spostamento dei dati con il processo di copia
Attività di copia supporta più modelli di trasferimento dei dati, tra cui la copia bulk, la copia incrementale e la replica CDC (Change Data Capture). È possibile usare Copia attività per spostare i dati da un'origine a OneLake senza la necessità di creare una pipeline, continuando ad accedere alle opzioni di configurazione avanzate. Il processo di copia supporta molte origini e destinazioni. Offre un maggiore controllo rispetto al mirroring e meno complessità operativa rispetto alla gestione delle pipeline che usano l'attività di copia.
Replica dei dati tramite mirroring
Il mirroring replica i dati da sistemi esterni in Fabric quasi in tempo reale mediante la configurazione automatizzata. Ci si connette a un sistema esterno, ad esempio database SQL di Azure, SQL Server, Oracle, SAP o Snowflake. Fabric replica automaticamente dati o metadati in OneLake. Il mirroring supporta tre tipi:
- Il mirroring del database replica interi database e tabelle.
- Il mirroring dei metadati sincronizza i metadati, ad esempio nomi di catalogo, schemi e tabelle anziché spostare fisicamente i dati. Questo approccio usa i tasti di scelta rapida in modo che i dati rimangano nel sistema di origine pur essendo ancora accessibili in Fabric.
- Il mirroring aperto utilizza il formato della tabella aperta di Delta Lake. Gli sviluppatori possono scrivere le modifiche dell'applicazione direttamente in un elemento di database con mirroring in OneLake usando le API pubbliche.
Fabric è in ascolto delle modifiche del sistema di origine (tramite Change Data Capture o metodi simili) e applica tali modifiche quasi in tempo reale alla copia speculare. Il risultato è un set di dati live e queryable che rimane sincronizzato con bassa latenza, senza pipeline ETL complesse.
Il mirroring supporta attualmente varie origini, tra cui database SQL di Azure, Istanza gestita di SQL, Azure Cosmos DB, Database di Azure per PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake e SQL Server. Supporta anche origini dati da soluzioni partner che hanno implementato l'API Open Mirroring. I dati con mirroring vengono archiviati in OneLake come tabelle Delta aggiornate. Fabric gestisce automaticamente queste tabelle in modo che sia possibile usarle per l'analisi in tempo reale o combinarle con altri dati di Fabric. Questa funzionalità supporta scenari ibridi di elaborazione transazionale e analitica, in cui i dati operativi passano continuamente alla piattaforma di analisi.
Il mirroring elimina la necessità di compilare manualmente pipeline di caricamento incrementali. Dal punto di vista dei costi del mirroring, le operazioni di calcolo che mantengono i database mirrorati sincronizzati non utilizzano le unità di capacità (CU) dalla capacità della tua infrastruttura Fabric. L'archiviazione dei dati con mirroring in OneLake è gratuita fino al limite di terabyte dello SKU di Fabric (ad esempio, F64 include 64 TB di archiviazione di database con mirroring gratuita).
Accedere ai dati esterni con scorciatoie
Fabric fornisce collegamenti per abilitare la virtualizzazione dei dati. Un collegamento in OneLake fa riferimento ai dati archiviati in un sistema esterno, ad esempio Azure Data Lake Storage Gen2, Amazon S3 o SharePoint. Anziché copiare i dati, i collegamenti consentono a OneLake di fare riferimento a file esterni come parte del data lake unificato. È possibile eseguire query o unire dati esterni con dati locali senza eseguire una migrazione iniziale. Questo approccio di inserimento senza copia è utile quando i requisiti di residenza dei dati o la duplicazione impediscono lo spostamento dei dati. Il diagramma seguente mostra come i collegamenti connettono i sistemi di archiviazione esterni agli elementi di Fabric senza copiare i dati:
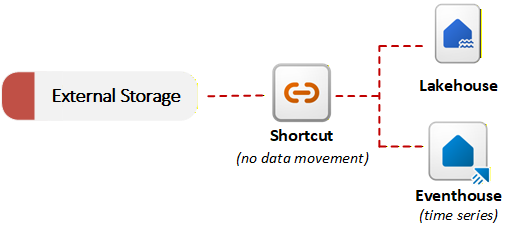
OneLake può rilevare il tipo di dati a cui fa riferimento un collegamento e applicare trasformazioni di file o trasformazioni di intelligenza artificiale senza richiedere una pipeline o codice personalizzato. OneLake mantiene automaticamente la tabella Delta risultante sincronizzata con l'origine. Ad esempio, è possibile convertire .csv i file in tabelle Delta o applicare l'analisi del sentiment basata su intelligenza artificiale ai .txt file in una cartella.
In combinazione con il mirroring, i tasti di scelta rapida offrono modelli di accesso ai dati flessibili. È possibile mantenere i dati sul posto usando le scorciatoie, oppure replicare i dati usando il mirroring, come alternativa. In entrambi i casi, i dati sono pronti per gli strumenti di analisi Fabric senza ETL complessi.
Guida decisionale: Scegliere una strategia di spostamento dei dati
Microsoft Fabric offre diverse opzioni per l'inserimento dei dati in Fabric, inclusi i flussi di eventi per l'elaborazione in tempo reale, il mirroring, le pipeline con attività di copia, le attività di processi di copia e le scorciatoie. Ogni opzione offre un equilibrio diverso tra controllo, automazione e complessità operativa.
Per indicazioni sulla selezione dell'approccio appropriato per lo scenario, vedere Guida alle decisioni di Microsoft Fabric: Scegliere una strategia di spostamento dei dati.