Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2019 (15.x) e versioni successive
SQL Server 2019 (15.x) e versioni successive
Il 28 febbraio 2025, i cluster Big Data di SQL Server 2019 sono stati ritirati. Per altre informazioni, vedere il post di blog dell'annuncio.
Modifiche al supporto per PolyBase in SQL Server
Correlate al ritiro dei cluster Big Data di SQL Server 2019 vi sono alcune funzionalità relative alle query con scalabilità orizzontale.
È stata ritirata la funzionalità dei gruppi con scalabilità orizzontale PolyBase di Microsoft SQL Server. La funzionalità gruppi con scalabilità orizzontale è stata rimossa dal prodotto in SQL Server 2022 (16.x). Le versioni di SQL Server 2019, 2017 e 2016 già presenti sul mercato continueranno a supportare la funzionalità fino alla fine del proprio ciclo di vita. La virtualizzazione dei dati PolyBase continua a essere completamente supportata come funzionalità di scalabilità in SQL Server.
Anche le origini dati esterne Cloudera (CDP) e Hortonworks (HDP) Hadoop verranno ritirate per tutte le versioni di SQL Server già presenti sul mercato e non sono incluse in SQL Server 2022. Il supporto per origini dati esterne è limitato alle versioni di prodotto attualmente nel supporto ordinario da parte del rispettivo fornitore. È consigliabile usare la nuova integrazione con l'archiviazione di oggetti disponibile in SQL Server 2022 (16.x).
In SQL Server 2022 (16.x) e versioni successive, gli utenti devono configurare le loro origini dati esterne per utilizzare i nuovi connettori quando si connettono ad Azure Storage. Nella tabella seguente vengono riassunte le modifiche:
| Origine dati esterna | From | To |
|---|---|---|
| Archiviazione BLOB di Azure | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
Note
Azure Blob Storage (abs) richiederà l'uso della firma di accesso condiviso (SAS) per l'elemento SEGRETO nella credenziale con ambito nel database. In SQL Server 2019 e versioni precedenti, il connettore wasb[s] utilizzava la chiave dell'account di archiviazione insieme alle credenziali con ambito di database per l'autenticazione all'account di archiviazione di Azure.
Informazioni sull'architettura dei cluster Big Data per la scelta delle opzioni di sostituzione e migrazione
Per creare la soluzione sostitutiva per un sistema di archiviazione ed elaborazione Big Data, è importante comprendere quali cluster Big Data di SQL Server 2019 hanno fornito e l'architettura può aiutare a fornire informazioni sulle scelte. L'architettura di un cluster Big Data è stata:

Il seguente mapping delle funzionalità è stato fornito da questa architettura:
| Component | Benefit |
|---|---|
| Kubernetes | Agente di orchestrazione open source per la distribuzione e la gestione su larga scala di applicazioni basate su contenitori. Fornisce un metodo dichiarativo per creare e controllare resilienza, ridondanza e portabilità per l'intero ambiente con scalabilità elastica. |
| Big Data Cluster Controller | Fornisce la gestione e la sicurezza per il cluster. Contiene il servizio di controllo, l'archivio di configurazione e altri servizi a livello di cluster, tra cui Kibana, Grafana ed ElasticSearch. |
| Pool di calcolo | Fornisce risorse di calcolo al cluster. Contiene nodi che eseguono SQL Server in pod Linux. I Pod nel pool di calcolo sono divisi in istanze di calcolo SQL per attività di elaborazione specifiche. Questo componente fornisce anche la virtualizzazione dei dati tramite PolyBase per eseguire query su origini dati esterne senza spostare o copiare i dati. |
| Pool di dati | Fornisce la persistenza dei dati per il cluster. Il pool di dati è costituito da uno o più pod che eseguono SQL Server in Linux. Viene usato per inserire dati da query SQL o processi Spark. |
| Pool di archiviazione | Il pool di archiviazione è composto da pod costituiti da SQL Server su Linux, Spark e HDFS. Tutti i nodi di archiviazione in un cluster Big Data sono membri di un cluster HDFS. |
| App Pool | Consente la distribuzione di applicazioni in un cluster Big Data fornendo le interfacce per creare, gestire ed eseguire le applicazioni. |
Per altre informazioni su queste funzioni, vedere Introduzione ai cluster Big Data di SQL Server.
Opzioni di sostituzione delle funzionalità per Big Data e SQL Server
La funzione per i dati operativi resa possibile da SQL Server all'interno di cluster Big Data può essere sostituita da SQL Server in locale in una configurazione ibrida o tramite la piattaforma Microsoft Azure. Microsoft Azure consente di scegliere tra diversi database relazionali, NoSQL e in memoria completamente gestiti, che includono motori proprietari e open source, per soddisfare le esigenze degli sviluppatori di app moderne. La gestione dell'infrastruttura, incluse scalabilità, disponibilità e sicurezza, è automatizzata, consentendo di risparmiare tempo e denaro e di concentrarsi sulla creazione di applicazioni, mentre i database gestiti di Azure semplificano le attività attraverso il rilevamento di dati analitici sulle prestazioni tramite intelligenza integrata, scalabilità senza limiti e gestione delle minacce alla sicurezza. Per altre informazioni, vedere Database di Azure.
La decisione successiva riguarda le posizioni delle risorse di calcolo e di archiviazione dei dati per l'analisi. Le due opzioni per l'architettura consistono nella distribuzione nel cloud o ibrida. È possibile eseguire la migrazione della maggior parte dei carichi di lavoro di analisi nella piattaforma Microsoft Azure. I dati "nati nel cloud" (provenienti da applicazioni basate sul cloud) sono i principali candidati per queste tecnologie e i servizi di spostamento dati possono eseguire la migrazione dei dati locali su larga scala in modo rapido e sicuro. Per altre informazioni sulle opzioni di spostamento dati, vedere Soluzioni di trasferimento dei dati.
Microsoft Azure include sistemi e certificazioni che consentono dati ed elaborazione dei dati sicuri per diversi strumenti. Per altre informazioni su queste certificazioni, vedere il Centro protezione.
Note
La piattaforma Microsoft Azure offre un livello molto elevato di sicurezza e più certificazioni per vari settori e rispetta la sovranità dei dati per i requisiti degli enti pubblici. Microsoft Azure offre anche una piattaforma cloud dedicata per i carichi di lavoro degli enti pubblici. La sicurezza in se stessa non deve essere il principale motivo per cui scegliere sistemi locali. È consigliabile valutare attentamente il livello di sicurezza fornito da Microsoft Azure prima di decidere se mantenere le soluzioni per Big Data in locale.
Nell'opzione con architettura nel cloud tutti i componenti risiedono in Microsoft Azure. La responsabilità dell'utente riguarda i dati e il codice creati per l'archiviazione e l'elaborazione dei carichi di lavoro. Queste opzioni vengono trattate in modo più dettagliato in questo articolo.
- Questa architettura è ottimale per un'ampia gamma di componenti per l'archiviazione e l'elaborazione dei dati e quando ci si vuole concentrare sui costrutti di dati e di elaborazione anziché sull'infrastruttura.
Nelle opzioni con architettura ibrida alcuni componenti vengono mantenuti in locale e altri vengono affidati a un provider di servizi cloud. La connettività tra i due è progettata per ottenere il migliore approccio di elaborazione rispetto ai dati.
- Questa opzione è ideale quando vi è un investimento significativo in tecnologie e architetture locali, ma si vuole usare le offerte di Microsoft Azure o quando sono presenti destinazioni di elaborazione o applicazioni che risiedono in locale o sono rivolte a un pubblico mondiale.
Per altre informazioni sulla creazione di architetture scalabili, vedere Creare un sistema scalabile per dati di grandi dimensioni.
In-cloud
Azure SQL con Azure Machine Learning
È possibile sostituire la funzionalità dei cluster Big Data di SQL Server usando una o più opzioni di database SQL di Azure per i dati operativi e Microsoft Azure Machine Learning per i carichi di lavoro predittivi.
Azure Machine Learning è un servizio basato sul cloud che può essere usato per qualsiasi tipo di Machine Learning, da quello classico al Deep Learning, fino all'apprendimento con e senza supervisione. Che si preferisca scrivere codice Python o R con l'SDK oppure usare opzioni senza codice o con poco codice nello Studio, è possibile creare, eseguire il training e monitorare modelli di Machine Learning e Deep Learning in un'area di lavoro di Azure Machine Learning. Grazie ad Azure Machine Learning, puoi iniziare l'addestramento sulla tua macchina locale e poi scalare nel cloud. Il servizio interagisce anche con gli strumenti open source più diffusi di Deep Learning e apprendimento per rinforzo, ad esempio PyTorch, TensorFlow, scikit-learn e Ray RLlib.
Usare Microsoft Azure Machine Learning come opzione sostitutiva per i cluster Big Data di SQL Server 2019 quando è necessario quanto segue:
- Un ambiente Web basato su finestra di progettazione per Machine Learning, per trascinare moduli per la creazione degli esperimenti e quindi distribuire pipeline in un ambiente con poco codice.
- Jupyter notebook: usare i notebook di esempio forniti o creare notebook personalizzati per sfruttare gli esempi dell'SDK per Python per l’apprendimento automatico.
- Script o notebook R in cui utilizzare l'SDK per R per scrivere codice personalizzato o usare i moduli R nel designer.
- Solution Accelerator per più modelli, basato su Azure Machine Learning e che consente di eseguire e gestire centinaia o addirittura migliaia di modelli di Machine Learning e di eseguirne il training.
- Estensioni di Machine Learning per Visual Studio Code (anteprima), che offrono un ambiente di sviluppo completo per la creazione e la gestione dei progetti di Machine Learning.
- Un'interfaccia della riga di comando per Machine Learning. Azure Machine Learning include un'estensione per l'interfaccia della riga di comando di Azure che fornisce comandi per la gestione con risorse di Azure Machine Learning dalla riga di comando.
- Integrazione con framework open source come PyTorch, TensorFlow e scikit-learn e molti altri ancora per il training, la distribuzione e la gestione del processo di Machine Learning end-to-end.
- Apprendimento per rinforzo con Ray RLlib.
- MLflow per tenere traccia delle metriche e distribuire modelli oppure Kubeflow per creare pipeline di flussi di lavoro end-to-end.
L'architettura di una distribuzione di Microsoft Azure Machine Learning è la seguente:

Per altre informazioni su Microsoft Azure Machine Learning, vedere Funzionamento di Azure Machine Learning.
Azure SQL da Databricks
È possibile sostituire la funzionalità dei cluster Big Data di SQL Server usando una o più opzioni di database SQL di Azure per i dati operativi e Microsoft Azure Databricks per i carichi di lavoro di analisi.
Azure Databricks è una piattaforma di analisi dei dati ottimizzata per la piattaforma di servizi cloud di Microsoft Azure. Azure Databricks offre due ambienti per lo sviluppo di applicazioni a elevato utilizzo di dati: Azure Databricks SQL Analytics e l’area di lavoro di Azure Databricks.
Analisi SQL di Azure Databricks offre agli analisti una piattaforma intuitiva per eseguire query SQL sui loro data lake, creare più tipi di visualizzazioni per esplorare i risultati delle query da prospettive diverse, nonché creare e condividere dashboard.
L'area di lavoro di Azure Databricks è uno spazio interattivo che favorisce la collaborazione tra ingegneri dei dati, scienziati dei dati e ingegneri di Machine Learning. Nel caso di una pipeline di Big Data, i dati (non elaborati o strutturati) vengono inseriti in Azure tramite Azure Data Factory in batch o trasmessi quasi in tempo reale con Apache Kafka, Hub eventi o l'hub IoT. I dati vengono archiviati in un data lake per un'archiviazione permanente a lungo termine, in Archiviazione BLOB di Azure o in Azure Data Lake Storage. Come parte del flusso di lavoro di analisi, usare Azure Databricks per leggere dati da più origini e trasformarli in informazioni rivoluzionarie tramite Spark.
Usare Microsoft Azure Databricks come opzione sostitutiva per i cluster Big Data di SQL Server 2019 quando è necessario quanto segue:
- Cluster Spark completamente gestiti con Spark SQL e DataFrames.
- Elaborazione e analisi dei dati in tempo reale per applicazioni analitiche e interattive, integrandosi con HDFS, Flume e Kafka.
- Accedere alla libreria MLlib costituita da utilità e algoritmi di apprendimento comuni, tra cui classificazione, regressione, clustering, filtri per la collaborazione, riduzione della dimensionalità e primitive di ottimizzazione sottostanti.
- Documentazione del tuo stato di avanzamento nei notebook in R, Python, Scala o SQL.
- Visualizzazione dei dati in pochi passaggi, usando strumenti familiari come Matplotlib, ggplot o d3.
- Dashboard interattivi per creare report dinamici.
- GraphX per grafi e calcolo dei grafi per casi d'uso di più ampio respiro, dall'analisi cognitiva all'esplorazione dei dati.
- Creazione di cluster in pochi secondi, con cluster con scalabilità automatica dinamica condivisi tra team.
- Accesso a cluster a livello di codice tramite API REST.
- Accesso istantaneo alle funzionalità di Apache Spark più recenti con ogni versione.
- Un'API Core Spark: include il supporto per R, SQL, Python, Scala e Java.
- Un'area di lavoro interattiva per l'esplorazione e la visualizzazione.
- Endpoint SQL completamente gestiti nel cloud.
- Query SQL in esecuzione su endpoint SQL completamente gestiti, dimensionati in base alla latenza delle query e al numero di utenti simultanei.
- Integrazione con Microsoft Entra ID (in precedenza Azure Active Directory).
- Accesso in base al ruolo per autorizzazioni utente a livello granulare per notebook, cluster, processi e dati.
- SLA di livello aziendale.
- Dashboard per la condivisione di informazioni dettagliate, per la combinazione di visualizzazioni e testo per condividere i dati analitici ricavati dalle query.
- Avvisi che semplificano il monitoraggio e l'integrazione e notifiche quando un campo restituito da una query soddisfa una soglia. Usare gli avvisi per monitorare l'attività aziendale o integrarli con strumenti per avviare flussi di lavoro come l'onboarding dell'utente o i ticket di supporto.
- Sicurezza di livello Enterprise, tra cui integrazione di Microsoft Entra ID, controlli in base al ruolo e contratti di servizio per proteggere i dati e l'azienda.
- Integrazione con servizi, database e archivi di Azure, tra cui Synapse Analytics, Cosmos DB, Data Lake Store e Archiviazione BLOB.
- Integrazione con Power BI e altri strumenti di business intelligence, ad esempio Tableau Software.
L'architettura di una distribuzione di Microsoft Azure Databricks è la seguente:
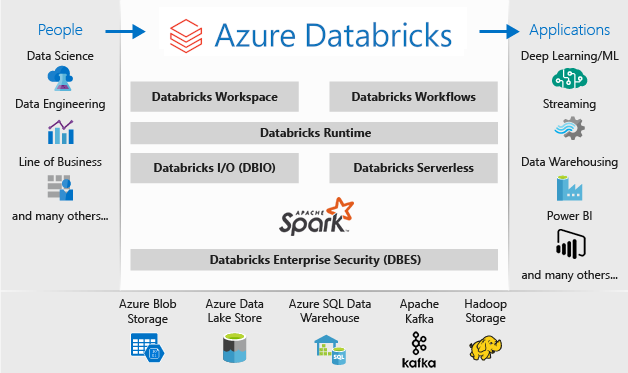
Per altre informazioni su Microsoft Azure Databricks, vedere Che cos'è Databricks Data Science & Engineering?
Hybrid
Rispecchiamento in Microsoft Fabric
Come esperienza di replica dei dati, il mirroring del database in Fabric è una soluzione a basso costo e a bassa latenza per riunire i dati da vari sistemi in una singola piattaforma di analisi. È possibile replicare continuamente il patrimonio di dati esistente direttamente in OneLake di Fabric, inclusi i dati di SQL Server 2016+, database SQL di Azure, Istanza gestita di SQL di Azure, Oracle, Snowflake, Cosmos DB e altro ancora.
Con i dati più aggiornati in un formato interrogabile in OneLake, è ora possibile usare tutti i diversi servizi in Fabric, ad esempio l'esecuzione di analisi con Spark, l'esecuzione di notebook, l'ingegneria dei dati, la visualizzazione tramite report di Power BI e altro ancora.
Il mirroring in Fabric offre un'esperienza semplice per accelerare il time-to-value delle informazioni dettagliate e delle decisioni e per suddividere i silos di dati tra soluzioni tecnologiche, senza sviluppare costosi processi di estrazione, trasformazione e caricamento (ETL) per spostare i dati.
Con il mirroring in Fabric, non è necessario unire servizi diversi da più fornitori. Invece, è possibile usufruire di un prodotto end-to-end altamente integrato e facile da usare, progettato per semplificare le esigenze di analisi e creato per l'apertura e la collaborazione tra soluzioni tecnologiche in grado di leggere il formato di tabella Delta Lake open source.
Per altre informazioni, vedi:
- Database con mirroring di Microsoft Fabric
- Monitoraggio dei database con mirroring di Microsoft Fabric
- Esplorare i dati nel database mirror con Microsoft Fabric
- Che cos'è Microsoft Fabric?
- Modellare i dati nel modello semantico di Power BI predefinito in Microsoft Fabric
- Che cos'è l'endpoint di analisi SQL per un Lakehouse?
- Direct Lake
Microsoft SQL Server su Windows, Apache Spark e archiviazione di oggetti in locale
È possibile installare SQL Server su Windows o Linux e aumentare le prestazioni dell'architettura hardware utilizzando la funzionalità di query di archiviazione oggetti di SQL Server 2022 (16.x) e la funzionalità PolyBase per consentire query su tutti i dati nel sistema.
L'installazione e la configurazione di una piattaforma con scalabilità orizzontale, come Apache Hadoop o Apache Spark, consentono di eseguire query su dati non relazionali su larga scala. L'uso di un set centrale di sistemi di archiviazione di oggetti che supporta l'API S3 consente sia a SQL Server 2022 (16.x) sia a Spark di accedere allo stesso set di dati tra tutti i sistemi.
È anche possibile usare il sistema di orchestrazione dei contenitori Kubernetes per la distribuzione. In questo modo, si ottiene un'architettura dichiarativa che può essere eseguita in locale o in qualsiasi cloud che supporta Kubernetes o la piattaforma Red Hat OpenShift. Per altre informazioni sulla distribuzione di SQL Server in un ambiente Kubernetes, vedere Distribuire un cluster contenitore di SQL Server in Azure oppure guardare Distribuzione di SQL Server 2019 in Kubernetes.
Usare SQL Server e Hadoop/Spark in locale come opzione sostitutiva per i cluster Big Data di SQL Server 2019 quando è necessario:
- Mantenere l'intera soluzione in locale
- Usare hardware dedicato per tutte le parti della soluzione
- Accedere a dati relazionali e non relazionali dalla stessa architettura, in entrambe le direzioni
- Condividere un singolo set di dati non relazionali tra SQL Server e il sistema non relazionale con scalabilità orizzontale
Eseguire la migrazione
Dopo aver selezionato un ambiente (cloud o ibrido) per la migrazione, è necessario soppesare i vettori di inattività e costi per determinare se eseguire un nuovo sistema e spostare i dati dal sistema precedente a quello nuovo in tempo reale (migrazione affiancata) o un backup e ripristino oppure se eseguire un nuovo avvio del sistema da origini dati esistenti (migrazione sul posto).
La decisione successiva riguarda se riscrivere la funzionalità corrente nel sistema usando la nuova architettura scelta o se spostare quanto più codice possibile nel nuovo sistema. Benché la prima opzione possa richiedere più tempo, consente di utilizzare i nuovi metodi, concetti e vantaggi offerti dalla nuova architettura. In questo caso, le mappe dell'accesso ai dati e delle funzionalità sono le attività di pianificazione principali su cui concentrarsi.
Se si prevede di eseguire la migrazione del sistema corrente con il minor numero possibile di modifiche al codice, la compatibilità con il linguaggio è l'aspetto principale su cui concentrarsi per la pianificazione.
Migrazione del codice
Il passaggio successivo consiste nel controllare il codice usato dal sistema corrente e le modifiche che devono essere apportate nel nuovo ambiente.
È necessario valutare due principali vettori per la migrazione del codice:
- Origini e destinazioni
- Migrazione delle funzionalità
Origini e destinazioni
La prima attività nella migrazione del codice consiste nell'identificare i metodi, le stringhe o le API di connessione all'origine dati usati dal codice per accedere ai dati importati, al relativo percorso e alla destinazione finale. Documentare queste origini e creare una mappa alle posizioni della nuova architettura.
- Se la soluzione corrente sta utilizzando un sistema di pipeline per spostare i dati nel sistema, eseguire la mappatura delle origini, dei passaggi e delle destinazioni della nuova architettura ai componenti della pipeline.
- Se la nuova soluzione sostituisce anche l'architettura di pipeline, considerare il sistema una nuova installazione per scopi di pianificazione, anche se si riutilizza la piattaforma hardware o cloud come opzione sostitutiva.
Migrazione delle funzionalità
L'attività più complessa necessaria in una migrazione è la consultazione, l'aggiornamento o la creazione della documentazione delle funzionalità del sistema corrente. Se si prevede un aggiornamento sul posto e si tenta di ridurre il più possibile la quantità di codice da riscrivere, questo passaggio richiede il tempo maggiore.
Tuttavia, una migrazione da una tecnologia precedente è spesso un momento ottimale per aggiornarsi sugli ultimi progressi tecnologici e trarre vantaggio dai costrutti forniti. Spesso è possibile ottenere sicurezza, prestazioni, scelte di funzionalità e ottimizzazioni dei costi migliori anche da una riscrittura del sistema corrente.
In entrambi i casi, la migrazione include due fattori principali: il codice e i linguaggi supportati dal nuovo sistema e le scelte riguardo allo spostamento dati. In genere, è possibile modificare le stringhe di connessione dal cluster Big Data corrente all'istanza di SQL Server e all'ambiente Spark. Le informazioni sui dati di connessione e il passaggio del codice dovrebbero essere ridotti al minimo.
Se si prevede una riscrittura della funzionalità corrente, eseguire il mapping di nuovi pacchetti, librerie e DLL all'architettura scelta per la migrazione. Un elenco di tutti i linguaggi, le librerie e le funzioni offerti da ogni soluzione sono disponibili nei riferimenti alla documentazione mostrati nelle sezioni precedenti. Effettuare una mappatura di qualsiasi linguaggio sospetto o non supportato e pianificare la sostituzione con l'architettura selezionata.
Opzioni di migrazione dei dati
Esistono due approcci comuni per lo spostamento dati in un sistema di analisi su larga scala. Il primo consiste nel creare un processo di "cutover" in cui il sistema originale continua a elaborare i dati e i dati vengono accumulati in un set di dati aggregati per i report. Il nuovo sistema inizia quindi con dati aggiornati e viene usato dalla data di migrazione in poi.
In alcuni casi, tutti i dati devono passare dal sistema legacy al nuovo sistema. In questo caso, è possibile montare gli archivi file originali dai cluster Big Data di SQL Server se il nuovo sistema supporta questo approccio e quindi copiare i dati poco per volta nel nuovo sistema. In alternativa, è possibile creare uno spostamento fisico.
La migrazione dei dati correnti da cluster Big Data di SQL Server 2019 a un altro sistema dipende molto da due fattori: la posizione dei dati correnti e il fatto che la destinazione sia locale o nel cloud.
Migrazione dei dati in locale
Per migrazioni tra ambienti locali, è possibile eseguire la migrazione dei dati di SQL Server con una strategia di backup e ripristino oppure configurare la replica per spostare alcuni o tutti i dati relazionali. È possibile usare SQL Server Integration Services per copiare dati da SQL Server a un'altra posizione. Per altre informazioni sullo spostamento dati con SSIS, vedere SQL Server Integration Services.
Per i dati HDFS nell'ambiente di cluster Big Data di SQL Server corrente, l'approccio standard consiste nel montare i dati in un cluster Spark autonomo e usare il processo di archiviazione di oggetti per spostare i dati in modo che un'istanza di SQL Server 2022 (16.x) possa accedervi o lasciarli così come sono e continuare a elaborarli con processi Spark.
Migrazione dei dati nel cloud
Per i dati presenti in risorse di archiviazione cloud o locali, è possibile usare Azure Data Factory, che include oltre 90 connettori per una pipeline di trasferimento completa, con pianificazione, monitoraggio, generazione di avvisi e altri servizi. Per altre informazioni su Azure Data Factory, vedere Che cos'è Azure Data Factory?
Se si vogliono spostare grandi quantità di dati in modo sicuro e rapido dal patrimonio di dati locale a Microsoft Azure, è possibile usare il servizio Importazione/Esportazione di Azure. Il servizio Importazione/Esportazione di Azure viene usato per importare in modo sicuro grandi quantità di dati nell'archiviazione BLOB di Azure e in File di Azure tramite la spedizione di unità disco a un data center di Azure. È anche possibile usare questo servizio per trasferire i dati dall'archivio BLOB di Azure a unità disco per la spedizione al sito locale. È possibile importare dati da uno o più dischi nell'Archivio Blob di Azure o in File di Azure. Per quantità di dati estremamente elevate, l'uso di questo servizio può offrire il percorso più veloce.
Per trasferire i dati usando i dischi forniti da Microsoft, è possibile usare Azure Data Box Disk per importare dati in Azure. Per altre informazioni, vedere Che cos'è il servizio Importazione/Esportazione di Azure?
Per altre informazioni su queste scelte e sulle decisioni che le accompagnano, vedere Uso di Azure Data Lake Storage Gen1 per i requisiti dei Big Data.