Azure OpenAI On Your Data
この記事では、開発者がパーソナライズされた Copilot (プレビュー) を迅速に作成するために、企業データを接続、取り込み、グラウンディングすることを容易にする Azure OpenAI On Your Data について説明します。 ユーザーの理解度を高め、タスクの完了を早め、業務効率を向上させ、意思決定を支援します。
Azure OpenAI On Your Data とは
Azure OpenAI On Your Data では、モデルのトレーニングや微調整をすることなく、GPT-35-Turbo や GPT-4 などの高度な AI モデルを独自のエンタープライズ データ上で実行できます。 より正確にデータをチャットして分析することができます。 指定したデータ ソースで使用可能な最新情報に基づいて、回答をサポートするソースを指定できます。 Azure OpenAI On Your Data には、REST API、SDK、または Azure OpenAI Studio の Web ベースのインターフェイスを使用してアクセスできます。 また、データに接続して拡張チャット ソリューションを有効にする Web アプリを作成したり、Copilot Studio (プレビュー) で Copilot として直接デプロイしたりすることもできます。
データに対する Azure OpenAI を使用した開発
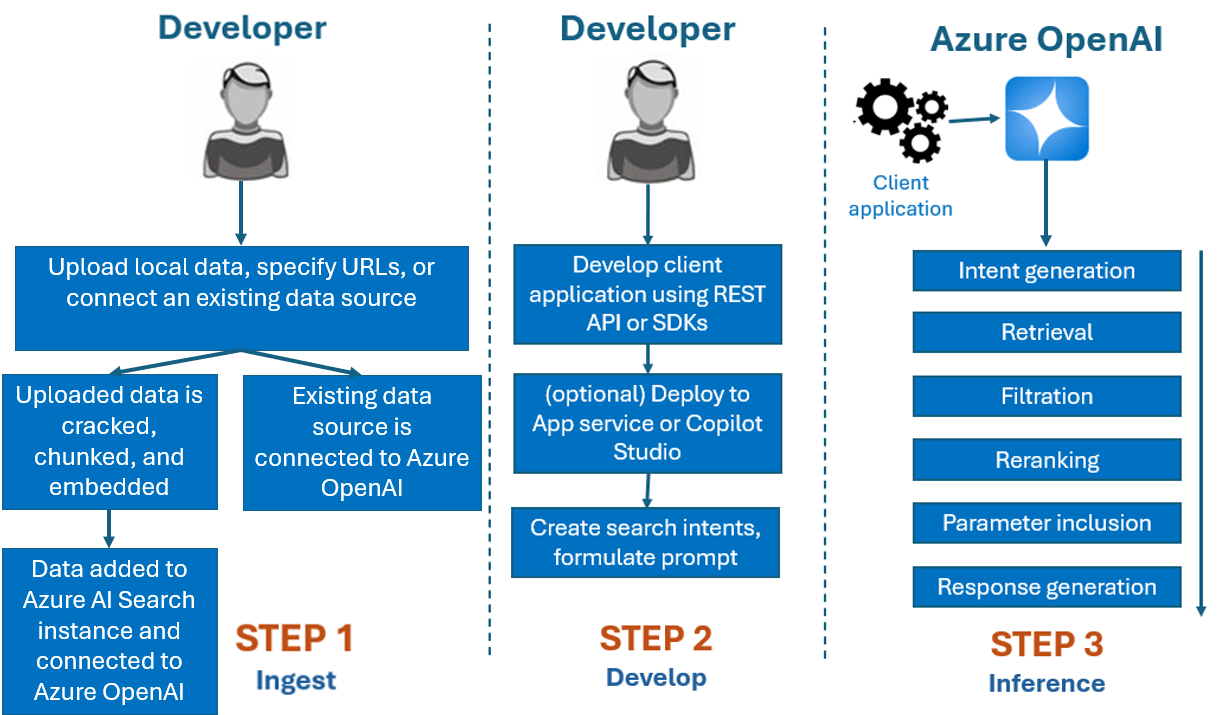
通常、Azure OpenAI On Your Data で使用する開発プロセスは次のとおりです。
取り込み: Azure OpenAI Studio またはインジェスト API を使用してファイルをアップロードします。 こうすると、データを分割し、チャンク化して、Azure Open AI モデルで使用できる Azure AI 検索インスタンスに埋め込むことができるようになります。 既存のサポートされているデータ ソースがある場合は、直接接続することもできます。
開発: Azure OpenAI On Your Data を試した後、複数の言語で使用できる REST API と SDK を使用してアプリケーションの開発を始めます。 これにより、Azure OpenAI サービスに渡すプロンプトと検索意図が作成されます。
推論: アプリケーションを好みの環境にデプロイすると、Azure OpenAI にプロンプトが送信され、応答が返される前にいくつかの手順が実行されます。
意図の生成: サービスにより、ユーザーのプロンプトの意図が判断され、適切な応答が決まります。
取得: サービスにより、接続されたデータ ソースに対してクエリが実行され、使用できるデータの関連チャンクが取得されます。 たとえば、セマンティックまたはベクトル検索が使用されます。 厳密さや取得するドキュメント数などの [パラメーター] は、取得に影響を与えるために利用されます。
フィルター処理と再ランク付け: データをランク付けおよびフィルター処理して関連性を絞り込むことで、取得手順の検索結果が改善されます。
応答の生成: 結果のデータは、システム メッセージなどの他の情報と共に大規模言語モデル (LLM) に送信され、応答がアプリケーションに返されます。
まず、Azure OpenAI Studio を使用してデータ ソースに接続し、データに関する質問やチャットを開始します。
データ ソースを追加するための Azure ロールベースのアクセス制御 (Azure RBAC)
Azure OpenAI On Your Data を完全に使用するには、1 つ以上の Azure RBAC ロールを設定する必要があります。 詳細については、「Azure OpenAI On Your Data を安全に使用する」を参照してください。
データ形式とファイルの種類
Azure OpenAI On Your Data では、次のファイルの種類がサポートされています。
.txt.md.html.docx.pptx.pdf
アップロードの制限があります。また、ドキュメント構造と、それがモデルからの応答の品質に与える可能性がある影響については、いくつかの注意事項があります。
サポートされていない形式からサポートされている形式にデータを変換する場合は、変換による次のことを確認してモデルの応答の品質を最適化します。
- 重大なデータ損失が発生していないこと。
- データに予期しないノイズが追加されていないこと。
ファイルにテーブルや列、箇条書きなどの特別な書式設定がある場合は、GitHub で使用できるデータ準備スクリプトを使用してデータを準備します。
長いテキストを含むドキュメントとデータセットの場合は、使用可能なデータ準備スクリプトを使用します。 スクリプトは、モデルの応答がより正確になるようにデータをチャンクします。 このスクリプトでは、スキャンされた PDF ファイルと画像もサポートされます。
サポートされるデータ ソース
データをアップロードするには、データ ソースに接続する必要があります。 データを使用して Azure OpenAI モデルとチャットする場合、ユーザーのクエリに基づいて関連するデータを見つけることができるように、データは検索インデックスにチャンクされます。
仮想コアベースの Azure Cosmos DB for MongoDB の統合ベクター データベースは、Azure OpenAI On Your Data との統合をネイティブにサポートします。
ローカル コンピューターからのファイルのアップロード (プレビュー) や BLOB ストレージ アカウントに含まれるデータ (プレビュー) などの一部のデータ ソースでは、Azure AI Search が使用されます。 次のデータ ソースを選択すると、データが Azure AI Search インデックスに取り込まれます。
| Azure AI Search を使用して取り込まれたデータ | 説明 |
|---|---|
| Azure AI Search | Azure OpenAI On Your Data で既存の Azure AI Search インデックスを使用します。 |
| ファイルのアップロード (プレビュー) | ローカル コンピューターからファイルをアップロードして、Azure Blob Storage データベースに格納し、Azure AI Search に取り込みます。 |
| URL/Web アドレス (プレビュー) | URL からの Web コンテンツは、Azure Blob Storage に格納されます。 |
| Azure Blob Storage (プレビュー) | Azure Blob Storage からファイルをアップロードして、Azure AI Search インデックスに取り込みます。 |

- Azure AI Search
- Azure Cosmos DB for MongoDB のベクター データベース
- Azure Blob Storage (プレビュー)
- ファイルのアップロード (プレビュー)
- URL/Web アドレス (プレビュー)
- Elasticsearch (プレビュー)
次のいずれかの操作を行う場合は、Azure AI Search インデックスの使用を検討することをお勧めします。
- インデックス作成プロセスをカスタマイズします。
- 他のデータ ソースからデータを取り込むことで、以前に作成したインデックスを再利用します。
Note
- 既存のインデックスを使用するには、少なくとも 1 つの検索可能なフィールドが必要です。
- CORS の [配信元の種類を許可する] オプションを
allに、[許可された配信元] オプションを*に設定します。
種類の検索
Azure OpenAI On Your Data には、データ ソースを追加するときに使用できる次の検索の種類が用意されています。
Ada 埋め込みモデルを使用したベクトル検索であり、選択したリージョンで利用できます
ベクトル検索を有効にするには、Azure OpenAI リソースにデプロイされた既存の埋め込みモデルが必要です。 データを接続するときに埋め込みデプロイを選択し、[データ管理] で、いずれかのベクトル検索の種類を選択します。 データ ソースとして Azure AI Search を使用している場合は、インデックスにベクトル列があることを確認してください。
独自のインデックスを使用している場合は、データ ソースを追加するときにフィールド マッピングをカスタマイズして、質問に回答するときにマッピングされるフィールドを定義できます。 フィールド マッピングをカスタマイズするには、データ ソースの追加時に [データ ソース] ページで [カスタム フィールド マッピングを使用する] を選択 します。
重要
| 検索オプション | 取得の種類 | 追加価格は? | メリット |
|---|---|---|---|
| keyword | キーワード検索 | 追加価格はありません。 | 演算子の有無にかかわらず、サポートされている任意の言語の用語または語句を使用して、検索可能なフィールドに対して高速で柔軟なクエリ解析と照合を実行します。 |
| "セマンティック" | セマンティック検索 | セマンティック検索の使用に対する追加価格。 | リランカー (AI モデルを使用) を使用して、最初の検索ランカーによって返されるクエリ用語とドキュメントの意味を理解することで、検索結果の精度と関連性を向上させます |
| vector | ベクター検索 | 埋め込みモデルの呼び出しによる Azure OpenAI アカウントの追加価格。 | コンテンツのベクター埋め込みに基づいて、特定のクエリ入力に似たドキュメントを検索できます。 |
| ハイブリッド (ベクトル + キーワード) | ベクトル検索とキーワード検索のハイブリッド | 埋め込みモデルの呼び出しによる Azure OpenAI アカウントの追加価格。 | ベクトル埋め込みを使用してベクトル フィールドに対して類似性検索を実行すると同時に、用語クエリを使用した英数字フィールドに対する柔軟なクエリ解析とフルテキスト検索もサポートします。 |
| ハイブリッド (ベクトル + キーワード) + セマンティック | ベクトル検索、セマンティック検索、キーワード検索のハイブリッド。 | 埋め込みモデルの呼び出しによる Azure OpenAI アカウントの追加価格とセマンティック検索の使用に対する追加価格。 | ベクトル埋め込み、言語理解、柔軟なクエリ解析を使用して、複雑で多様な情報取得シナリオを処理できる豊富な検索エクスペリエンスと生成 AI アプリを作成します。 |
インテリジェント検索
Azure OpenAI On Your Data では、データに対してインテリジェント検索が有効になっています。 セマンティック検索とキーワード検索の両方がある場合、セマンティック検索が既定で有効になります。 埋め込みモデルがある場合、インテリジェント検索は既定でハイブリッド + セマンティック検索になります。
ドキュメント レベルのアクセス制御
Note
データ ソースとして Azure AI Search を選択すると、ドキュメント レベルのアクセス制御がサポートされます。
データ上で Azure OpenAI を使用すると、Azure AI Search セキュリティ フィルターを使用するさまざまなユーザーの応答で使用できるドキュメントを制限できます。 ドキュメント レベルのアクセスを有効にすると、Azure AI Search から返されて応答の生成に使用された検索結果は、ユーザーの Microsoft Entra グループ メンバーシップに基づいてトリミングされます。 既存の Azure AI Search インデックスに対してのみドキュメント レベルのアクセスを有効にできます。詳細については、「Azure OpenAI On Your Data を安全に使用する」を参照してください。
インデックス フィールド マッピング
独自のインデックスを使用している場合は、データ ソースを追加するときに、質問に回答するためにマップするフィールドを定義するように Azure OpenAI Studio で求められます。 [コンテンツ データ] には複数のフィールドを指定でき、ユース ケースに関連するテキストを含むすべてのフィールドを含める必要があります。

この例では、[コンテンツ データ] と [タイトル] にマップされたフィールドは、質問に回答するための情報をモデルに提供します。 [タイトル] は、引用テキストにタイトルを付けるためにも使用されます。 [ファイル名] にマップされたフィールドは、応答で引用名を生成します。
これらのフィールドを正しくマップすることで、モデルの応答と引用品質を向上させることができます。 API では、fieldsMapping パラメーターを使用してそれを追加構成できます。
検索フィルター (API)
クエリの実行に対して値ベースの条件を追加で実装したい場合は、REST API で filter パラメーターを使って検索フィルターを設定できます。
Azure AI 検索にデータを取り込む方法
Azure AI 検索へのデータ取り込みは、次のプロセスで行われます。
インジェスト資産が Azure AI Search リソースと Azure ストレージ アカウントに作成されます。 現在、これらの資産は、インデクサー、インデックス、データ ソース、検索リソース内のカスタム スキル、Azure ストレージ アカウント内のコンテナー (後でチャンク コンテナーと呼ばれます) です。 入力 Azure ストレージ コンテナーは、Azure OpenAI Studio またはインジェスト API (プレビュー) を使用して指定できます。 既定では、テキストは UTF-8 エンコードを使用すると想定されます。 別のエンコードを指定するには、エンコード構成プロパティを使用します。 サポートされているエンコードの一覧については、.NET のドキュメントを参照してください。
データが入力コンテナーから読み取られ、コンテンツが開かれ、それぞれ最大 1,024 個のトークンを持つ小さなチャンクにチャンクされます。 ベクトル検索が有効な場合、サービスは各チャンクの埋め込みを表すベクトルを計算します。 この手順の出力 ("前処理済み" または "チャンクされた" データと呼ばれます) は、前の手順で作成したチャンク コンテナーに保存されます。
前処理されたデータがチャンク コンテナーから読み込まれ、Azure AI Search インデックスにインデックスが作成されます。
データ接続
Azure OpenAI、Azure AI 検索、Azure Blob Storage から接続を認証する方法を選択する必要があります。 "システム割り当てマネージド ID" または "API キー" を選択できます。 認証の種類として [API キー] を選択すると、システムによって API キーが自動的に設定され、Azure AI 検索、Azure OpenAI、Azure Blob Storage のリソースに接続できるようになります。 [システム割り当てマネージド ID] を選択すると、認証は自分の "ロールの割り当て" に基づいて行われます。 セキュリティのために、[システム割り当てマネージド ID] が既定で選択されています。

[次へ] ボタンを選択すると、選択した認証方法を使用するようにセットアップが自動的に検証されます。 エラーが発生した場合は、ロールの割り当てに関する記事を参照して、セットアップを更新してください。
セットアップを修正したら、もう一度 [次へ] を選択して検証し、続行します。 API ユーザーは、割り当てられたマネージド ID と API キーを使用して認証を構成することもできます。


![Azure portal の [インデクサー] タブのスクリーンショット。](../media/use-your-data/indexers-azure-portal.png#lightbox)
![個々のインデクサーの [設定] ページのスクリーンショット。](../media/use-your-data/indexer-schedule-azure-portal.png#lightbox)


Copilot (プレビュー)、Teams アプリ (プレビュー)、または Web アプリにデプロイする
Azure OpenAI をデータに接続したら、Azure OpenAI Studio の [デプロイ] ボタンを使用してデプロイできます。
![Azure OpenAI Studio の [モデルのデプロイ] ボタンを示すスクリーンショット。](../media/use-your-data/deploy-model.png#lightbox)
これにより、ソリューションをデプロイするための複数のオプションが提供されます。
Azure OpenAI Studio から直接 Copilot Studio (プレビュー) の Copilot にデプロイできます。これにより、Microsoft Teams、Web サイト、Dynamics 365、その他の Azure Bot Service チャネルなど、さまざまなチャネルに会話エクスペリエンスを提供できます。 Azure OpenAI サービスと Copilot Studio (プレビュー) で使用されるテナントは同じである必要があります。 詳細については、「Azure OpenAI On Your Data への接続を使用する」を参照してください。
Note
Copilot Studio (プレビュー) の Copilot にデプロイできるのは、米国リージョンのみです。
Azure OpenAI On Your Data を安全に使用する
Microsoft Entra ID のロールベースのアクセス制御、仮想ネットワーク、プライベート エンドポイントを使用してデータとリソースを保護することで、Azure OpenAI On Your Data を安全に使用できます。 また、Azure AI Search セキュリティ フィルターを使用してさまざまなユーザーの応答で使用できるドキュメントを制限することもできます。 「Azure OpenAI On Your Data を安全に使用する」を参照してください。
ベスト プラクティス
次のセクションでモデルによって提供される回答の品質を向上させる方法について説明します。
インジェスト パラメーター
データが Azure AI 検索に取り込まれるとき、Studio またはインジェスト API で次の追加設定を変更できます。
チャンク サイズ (プレビュー)
Azure OpenAI On Your Data は、取り込む前にチャンクに分割することでドキュメントを処理します。 チャンク サイズとは、検索インデックス内の任意のチャンクのトークン数についての最大サイズです。 チャンク サイズと取得するドキュメントの数によって、モデルに送信されるプロンプトに含まれる情報 (トークン) の量が制御されます。 一般に、チャンク サイズに、取得するドキュメントの数を乗算した値が、モデルに送信されるトークンの合計数です。
ユース ケースのチャンク サイズの設定
既定のチャンク サイズは 1024 トークンです。 ただし、データが一意であることを考慮すると、異なるチャンク サイズ (256、512、1,536 トークンなど) の方がより効果的な場合があります。
チャンク サイズを調整すると、チャット ボットのパフォーマンスが向上する可能性があります。 最適なチャンク サイズを見つけるには試行錯誤が必要ですが、まずデータセットの性質を検討することから始めてください。 一般に、直接的な事実があり、コンテキストが少ないデータセットには、チャンク サイズが小さい方が適しています。一方、より多くのコンテキスト情報には、大きいチャンク サイズの方が便利です。ただし、取得のパフォーマンスに影響を与える可能性があります。
256 のような小さなチャンク サイズでは、より細かいチャンクが生成されます。 また、このサイズは、出力を生成するためにモデルによって使用されるトークンの数が少なくなることを意味し (取得するドキュメントの数が非常に多い場合を除き)、コストが低くなる可能性があります。 また、チャンクが小さい場合は、モデルがテキストの長いセクションを処理して解釈する必要がなくなることを意味し、ノイズや混乱要因が少なくなります。 ただし、この粒度とフォーカスによって潜在的な問題が引き起こされる可能性があります。 特に、取得するドキュメントの数が 3 のような低い値に設定されている場合は、重要な情報が上位の取得チャンクに含まれていない可能性があります。
ヒント
チャンク サイズを変更するには、ドキュメントを再取り込みする必要があるため、最初に厳密度や取得されるドキュメントの数などの実行時パラメーターを調整すると便利です。 必要な結果が得られない場合は、チャンク サイズを変更することを検討してください。
- ドキュメントに含まれているはずの回答を含む質問に対して "わかりません" などの多数の応答が発生する場合は、粒度を向上させるためにチャンク サイズを 256 または 512 に減らすことを検討してください。
- チャットボットが正しい詳細を指定しているが、他の情報が欠落している場合 (引用文献で明らかになります)、チャンク サイズを 1,536 に増やすと、より多くのコンテキスト情報を取り込むのに役立つ可能性があります。
ランタイム パラメーター
次の追加設定は、Azure OpenAI Studio の [データ パラメーター] セクションと API で変更できます。 これらのパラメーターを更新するときに、データを再取り込みする必要はありません。
| パラメーター名 | 説明 |
|---|---|
| 独自のデータに応答を制限する | このフラグは、データ ソースに関係のないクエリや、検索ドキュメントが完全な回答には不十分な場合を処理するチャットボットのアプローチを構成します。 この設定を無効にすると、モデルはユーザーのドキュメントに加えてモデル独自の知識で応答を補足します。 この設定を有効にすると、モデルは応答にユーザーのドキュメントのみを利用しようとします。 これは API の inScope パラメーターで、既定で true に設定されます。 |
| 取得したドキュメント | このパラメーターは、3、5、10、または 20 に設定できる整数であり、最終的な応答を作成するために大規模言語モデルに提供されるドキュメント チャンクの数を制御します。 既定では、5 に設定されます。 検索プロセスはノイズが多く、チャンクが原因で、関連情報が検索インデックス内の複数のチャンクに分散される場合があります。 上位 K の数値 (5 など) を選択すると、検索とチャンクの固有の制限にもかかわらず、モデルが関連情報を抽出できるようになります。 ただし、数値を大きくしすぎると、モデルが混乱する可能性があります。 さらに、効果的に使用できるドキュメントの最大数は、モデルのバージョンによって異なります。ドキュメントを処理するためのコンテキスト サイズと容量はそれぞれ異なるためです。 応答に重要なコンテキストがない場合は、このパラメーターの値を増やしてみてください。 これは API の topNDocuments パラメーターで、既定は 5 です。 |
| 厳密度 | 類似性スコアに基づいて検索ドキュメントをフィルター処理する際のシステムの強度を判断します。 システムは、Azure Search またはその他のドキュメント ストアに対してクエリを実行し、ChatGPT などの大規模言語モデルに提供するドキュメントを決定します。 無関係なドキュメントを除外すると、エンド ツー エンドのチャットボットのパフォーマンスが大幅に向上する可能性があります。 一部のドキュメントは、類似性スコアが低い場合、モデルに転送する前に上位 K の結果から除外されます。 これは、1 から 5 までの整数値によって制御されます。 この値を 1 に設定すると、ユーザー クエリとの検索の類似性に基づいて、システムによってドキュメントが最小限にフィルター処理されます。 逆に、5 に設定すると、システムがドキュメントを積極的に除外し、非常に高い類似性のしきい値を適用することを示します。 チャットボットが関連情報を省略していることが分かる場合は、フィルターの厳格さを下げて (値を 1 に近い値に設定)、より多くのドキュメントを含めます。 逆に、無関係なドキュメントにより応答が混乱している場合は、しきい値を増やします (値を 5 に近い値に設定します)。 これは API の strictness パラメーターで、既定で 3 に設定されます。 |
引用されていない文献
データ ソースから取得されるが引用文献に含まれていないドキュメントについては、API で "TYPE":CONTENT ではなく、"TYPE":"UNCITED_REFERENCE" がモデルによって返される可能性があります。 これはデバッグに役立ちます。また、上記の [厳密度] と [取得するドキュメント] ランタイム パラメーターを変更することで、この動作を制御できます。
システム メッセージ
Azure OpenAI On Your Data を使用するときに、モデルの応答を誘導するシステム メッセージを定義できます。 このメッセージを使用すると、Azure OpenAI On Your Data で使用される取得拡張生成 (RAG) パターンに基づいて応答をカスタマイズできます。 システム メッセージは、エクスペリエンスを提供するための内部ベース プロンプトに加えて使用されます。 これをサポートするために、特定の数のトークンの後にシステム メッセージを切り捨てて、モデルがデータを使用して質問に回答できるようにします。 既定のエクスペリエンスに基づいて追加の動作を定義する場合は、システム プロンプトを詳細に記述し、期待されるカスタマイズを正確に説明するようにしてください。
データセットの追加を選択したら、Azure OpenAI Studio の [システム メッセージ] セクション、または role_information API のパラメーターを使用できます。

潜在的な使用パターン
ロールの定義
アシスタントに求める役割を定義できます。 たとえば、サポート ボットを構築する場合は、"ユーザーが新しい問題を解決するのに役立つ専門家のインシデント サポート アシスタントです" などと追加できます。
取得するデータの種類の定義
アシスタントに提供するデータの性質を追加することもできます。
- "財務レポート"、"学術論文"、"インシデント レポート" など、データセットのトピックまたはスコープを定義します。たとえば、テクニカル サポートの場合は、"取得したドキュメント内の類似したインシデントからの情報を使用してクエリに回答する" などと追加できます。
- データに特定の特性がある場合は、これらの詳細をシステム メッセージに追加できます。 たとえば、ドキュメントが日本語の場合は、"日本語のドキュメントを取得し、それを日本語で注意深く読み、日本語で回答する必要があります。" などと追加できます。
- 財務レポートのテーブルなどの構造化データがドキュメントに含まれている場合は、このファクトをシステム プロンプトに追加することもできます。 たとえば、データにテーブルがある場合は、"財務結果に関連するテーブルの形式でデータが与えられているので、テーブルを一行ずつ読んで計算を行い、ユーザーの質問に答えてください" などと追加できます。
出力シンクの定義
システム メッセージを定義することで、モデルの出力を変更することもできます。 たとえば、アシスタントの回答がフランス語であることを確認する場合は、 "あなたは、フランス語の検索情報を理解するユーザーを支援する AI アシスタントです。ユーザーの質問は、英語でもフランス語でもかまいません。取得したドキュメントをよく読んで、フランス語で回答してください。すべての回答がフランス語であることを確認するには、ドキュメントからの知識をフランス語に翻訳してください。" のようなプロンプトを追加できます。
重要な動作の再確認
Azure OpenAI On Your Data は、データを使用してユーザー クエリに回答するためのプロンプトの形式で大規模言語モデルに命令を送信することによって機能します。 アプリケーションにとって重要な特定の動作がある場合は、システム メッセージでその動作を繰り返すことで、精度を高めることができます。 たとえば、ドキュメントからのみ回答するようにモデル誘導するには、"取得したドキュメントのみを使用して、あなたの知識を使用せずに回答してください。回答内のすべての主張に対して、取得したドキュメントへの引用を生成してください。取得したドキュメントを使用してユーザーの質問に回答できない場合は、ドキュメントがユーザー クエリに関連する理由を説明してください。いずれの場合も、あなたの知識を使用して回答しないでください。" などと追加できます。
プロンプト エンジニアリングのテクニック
プロンプト エンジニアリングには、出力の改善を試みることができるテクニックがたくさんあります。 一例として、"取得したドキュメントに含まれる情報について段階的に考え、ユーザー クエリに回答してください。ドキュメントからユーザー クエリに関連する知識を段階的に抽出し、関連するドキュメントから抽出された情報から回答をボトムアップします。" という思考の連鎖を促すプロンプトを追加できます。
Note
システム メッセージは、取得したドキュメントに基づいて GPT アシスタントがユーザーの質問に応答する方法を変更するために使用されます。 この機能は取得プロセスには影響しません。 取得プロセスの手順を指定する場合は、質問に含めることをお勧めします。 システム メッセージはガイダンスに過ぎません。 モデルは、客観的であること、物議を醸すような表現を避けることなど、特定のふるまいをするよう事前に設定されているため、指定されたすべての指示には準拠していない可能性があります。 システム メッセージがこれらの動作と矛盾する場合、予期しない動作が発生する可能性があります。
最大応答数
モデルの応答あたりのトークン数に制限を設定します。 Azure OpenAI On Your Data の上限は 1,500 です。 これは、API での max_tokens パラメーターの設定と同じです。
独自のデータに応答を制限する
このオプションは、モデルが独自のデータのみを使用して応答することを促進します。これは、既定で選択されます。 このオプションの選択を解除すると、モデルは内部ナレッジをより迅速に適用して応答する可能性があります。 ユース ケースとシナリオに基づいて適切な選択を決定してください。
モデルとの対話
モデルとのチャットで最良の結果を得るには、次のプラクティスを使用してください。
会話履歴
- 新しい会話を開始する (または前の会話とは関係のない質問をする) 前に、チャット履歴をクリアします。
- 会話履歴によってモデルの現在の状態が変化するため、最初の会話ターンとそれ以降のターンで、同じ質問に対して異なる回答を得られることが期待できます。 適切ではない回答を受け取った場合は、品質のバグとして報告してください。
モデルの応答
特定の質問に対するモデルの応答に満足できない場合は、質問をより具体的にするか、より一般的にしてみてモデルがどのように応答するかを確認し、それに応じて質問を再構築します。
思考の連鎖プロンプティングは、複雑な質問/タスクに対する望ましい出力をモデルに生成させるのに効果的であることが示されています。
質問の長さ
長い質問は避け、可能であれば複数の質問に分割します。 GPT モデルには、受け入れられるトークンの数に制限があります。 トークンの制限は、ユーザーの質問、システム メッセージ、取得された検索ドキュメント (チャンク)、内部プロンプト、会話履歴 (存在する場合)、および応答に対してカウントされます。 質問がトークンの制限を超えると、切り捨てられます。
多言語のサポート
現在のところ、Azure OpenAI On Your Data のキーワード検索とセマンティック検索では、インデントのデータと同じ言語でのデータ クエリがサポートされています。 たとえば、データが日本語の場合、入力クエリも日本語にする必要があります。 多言語ドキュメントを取得する場合、ベクトル検索を有効にしてインデックスを作成することをお勧めします。
情報取得とモデル応答の品質を向上させるために、英語、フランス語、スペイン語、ポルトガル語、イタリア語、ドイツ語、中国語 (Zh)、日本語、韓国語、ロシア語、アラビア語のセマンティック検索を有効にすることをお勧めします。
システム メッセージを使用して、データが別の言語であることをモデルに通知することをお勧めします。 次に例を示します。
*"*ユーザーが取得した日本語ドキュメントから情報を抽出できるように設計された AI アシスタントです。回答を作成する前に、日本の文書を慎重に調べてください。ユーザーのクエリは日本語になり、日本語でも応答する必要があります。"
複数の言語のドキュメントがある場合は、言語ごとに新しいインデックスを作成し、それらを個別に Azure OpenAI に接続することをお勧めします。
ストリーミング データ
stream パラメーターを使用してストリーミング要求を送信すると、API 応答全体を待たずに、データを段階的に送受信できるようになります。 これにより、特に大規模または動的なデータの場合、パフォーマンスとユーザー エクスペリエンスが向上する可能性があります。
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
会話履歴で結果を向上させる
モデルのチャットでは、チャットの履歴を提供すると、モデルから返される結果の品質を高めやすくなります。 応答品質を向上させるために、API 要求にアシスタント メッセージの context プロパティを含める必要はありません。 例については「API リファレンス ドキュメント」を参照してください。
関数呼び出し
一部の Azure OpenAI モデルでは、関数呼び出しを有効にするために、tools と tool_choice パラメーターを定義できます。 REST API /chat/completions を使用して関数呼び出しを設定できます。 tools とデータ ソースの両方が要求内にある場合は、次のポリシーが適用されます。
tool_choiceがnoneの場合、ツールは無視され、回答の生成に使用されるのはデータ ソースだけです。- それ以外の場合で、
tool_choiceが指定されていない場合、またはautoまたはオブジェクトとして指定されている場合は、データ ソースが無視され、選択した関数名と引数 (存在する場合) が応答に含まれます。 モデルで関数が選択されていないと判断された場合でも、データ ソースは無視されます。
上記のポリシーがニーズを満たしていない場合は、他のオプションを検討してください。例: プロンプト フローまたは Assistants API。
Azure OpenAI On Your Data のトークン使用量の見積もり
Azure OpenAI On Your Data の取得拡張生成 (RAG) サービスは、検索サービス (Azure AI 検索など) と生成 (Azure OpenAI モデル) の両方を活用して、提供されたデータに基づいてユーザーが質問に対する回答を取得できるようにするサービスです。
この RAG パイプラインの一部として、高レベルの 3 つの手順があります。
ユーザー クエリを再編成して、検索インテントのリストにします。 これは、指示、ユーザーの質問、会話履歴を含むプロンプトを使用してモデルに対する呼び出しを行うことによって行われます。 これをインテント プロンプトを呼ぶことにします。
インテントごとに複数のドキュメント チャンクが検索サービスから取得されます。 ユーザーが指定した厳密度のしきい値に基づいて無関係なチャンクをフィルターで除外し、内部ロジックに基づいてチャンクを再ランク付け/集計した後、ユーザーが指定した数のドキュメント チャンクが選択されます。
これらのドキュメント チャンクは、ユーザーの質問、会話履歴、ロール情報、指示と共にモデルに送信され、最終的なモデル応答が生成されます。 これを生成プロンプトと呼ぶことにします。
モデルに対して合計 2 つの呼び出しが行われます。
インテントの処理: インテント プロンプトのトークン推定には、ユーザーの質問、会話履歴、インテント生成のためにモデルに送信される指示のトークンが含まれます。
応答の生成: 生成プロンプトのトークン推定には、ユーザーの質問、会話履歴、取得されるドキュメント チャンクのリスト、ロール情報、生成のために送信される指示のトークンが含まれます。
合計トークン推定では、モデルが生成した出力トークン数 (インテントと応答の両方) を考慮する必要があります。 以下の 4 つの列をすべて合計すると、応答の生成に使用される合計トークン数の平均が得られます。
| モデル | 生成プロンプトのトークン数 | インテント プロンプトのトークン数 | 応答トークン数 | インテント トークン数 |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4-1106-preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
上記の数は、次のデータ セットでのテストに基づいています。
- 191 回の会話
- 250 回の質問
- 質問ごとに平均 10 個のトークン
- 会話ごとに平均 4 回の会話ターン
パラメーターは次のとおりです。
| 設定 | Value |
|---|---|
| 取得されるドキュメントの数 | 5 |
| 厳密度 | 3 |
| チャンク サイズ | 1024 |
| 応答は取り込まれたデータに限定されるか? | True |
これらの推定値は、上記のパラメーターに設定された値によって変化します。 たとえば、取得されるドキュメントの数が 10、厳密度が 1 に設定されていると、トークン数は多くなります。 返される応答が取り込まれたデータに限定されなければ、モデルに与えられる指示の数が減り、トークン数が少なくなります。
推定値は、ドキュメントと投げかけられる質問の性質にも依存します。 たとえば、質問が自由回答形式の場合は、応答が長くなる可能性があります。 同様に、システム メッセージが長いほど、プロンプトが長くなって、より多くのトークンが消費され、会話履歴が長ければ、プロンプトが長くなります。
| モデル | システム メッセージの最大トークン数 |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
上記の表は、システム メッセージに対して使用できるトークンの最大数を示しています。 モデル応答の最大トークン数を確認するには、モデルに関する記事を参照してください。 さらに、次のコードもトークンを使用します:
メタ プロンプト: モデルからの応答をグラウンド データ コンテンツ (API の
inScope=True) に限定すると、トークンの最大数が増加します。 それ以外の場合 (たとえば、inScope=Falseの場合)、最大値は減少します。 この数は、ユーザーの質問と会話履歴のトークンの長さに応じて可変です。 この見積もりには、ベース プロンプトと、取得のためのクエリ書き換えプロンプトが含まれます。ユーザーの質問と履歴: 変数ですが、上限は 2,000 トークンです。
取得されたドキュメント (チャンク): 取得されたドキュメント チャンクによって使用されるトークンの数は、複数の要因によって異なります。 この上限は、取得されたドキュメント チャンクの数にチャンク サイズを乗算した値です。 ただし、残りのフィールドをカウントした後、使用されている特定のモデルで使用可能なトークンに基づいて、切り捨てられます。
使用可能なトークンの 20% がモデル応答用に予約されています。 使用可能なトークンの残りの 80% には、メタ プロンプト、ユーザーの質問と会話の履歴、およびシステム メッセージが含まれます。 残りのトークン予算は、取得したドキュメント チャンクによって使用されます。
入力 (質問、システム メッセージ/ロール情報など) によって消費されるトークン数を計算するには、次のコード サンプルを使用します。
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
トラブルシューティング
失敗した操作のトラブルシューティングを行うには、API 応答または Azure OpenAI Studio で特定されたエラーまたは警告を必ずご確認ください。 一般的なエラーと警告のいくつかを次に示します。
失敗したインジェスト ジョブ
クォータ制限の問題
サービス Y に X という名前のインデックスを作成できませんでした。 このサービスのインデックス クォータを超えました。 先に未使用のインデックスを削除して、インデックス作成要求間に遅延を追加するか、サービスをアップグレードして上限を引き上げる必要があります。
このサービスでは、X の標準インデクサー クォータを超えました。 現在、X 個の標準インデクサーがあります。 先に未使用のインデクサーを削除して、インデクサー 'executionMode' を変更するか、サービスをアップグレードして上限を引き上げる必要があります。
解決策:
より高い価格レベルにアップグレードするか、未使用の資産を削除します。
タイムアウトの問題を前処理する
Web API 要求が失敗したため、スキルを実行できませんでした
Web API のスキルの応答が無効であるため、スキルを実行できませんでした
解決策:
入力ドキュメントを小さなドキュメントに分割して、もう一度お試しください。
アクセス許可の問題
この要求では、この操作の実行は許可されません
解決策:
これは、指定された資格情報を使用してストレージ アカウントにアクセスできないことを意味しています。 この場合、API に渡されたストレージ アカウントの資格情報を確認し、ストレージ アカウントがプライベート エンドポイントの背後に隠されていないことをご確認ください (プライベート エンドポイントがこのリソース用に構成されていない場合)。
Azure AI 検索を使用してクエリを送信するときの 503 エラー
各ユーザー メッセージは複数の検索クエリに変換でき、そのすべてが検索リソースに並列で送信されます。 これにより、検索レプリカとパーティションの数が少ない場合に調整動作が発生する可能性があります。 1 つのパーティションと 1 つのレプリカでサポートできる 1 秒あたりのクエリの最大数では不十分な場合があります。 この場合は、レプリカとパーティションを増やすか、アプリケーションにスリープ/再試行ロジックを追加することを検討してください。 詳細については、Azure AI 検索のドキュメントを参照してください。
リージョン別の可用性とモデル サポート
| リージョン | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| オーストラリア東部 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| カナダ東部 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 米国東部 | ✅ | ✅ | ✅ | |||||
| 米国東部 2 | ✅ | ✅ | ✅ | ✅ | ||||
| フランス中部 | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| 東日本 | ✅ | |||||||
| 米国中北部 | ✅ | ✅ | ✅ | |||||
| ノルウェー東部 | ✅ | ✅ | ||||||
| 米国中南部 | ✅ | ✅ | ||||||
| インド南部 | ✅ | ✅ | ||||||
| スウェーデン中部 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| スイス北部 | ✅ | ✅ | ✅ | |||||
| 英国南部 | ✅ | ✅ | ✅ | ✅ | ||||
| 米国西部 | ✅ | ✅ | ✅ |
**これはテキストのみの実装です
Azure OpenAI リソースが別のリージョンにある場合、Azure OpenAI On Your Data を使用することはできません。