Apache Sqoop は、Apache Hadoop クラスターとリレーショナル データベースの間でデータを転送するためツールです。 これにはコマンドライン インターフェイスがあります。
Sqoop を使用すると、MySQL、PostgreSQL、Oracle、SQL Server などのリレーショナル データベースから HDFS にデータをインポートし、HDFS のデータをそのようなデータベースにエクスポートできます。 Sqoop では、MapReduce と Apache Hive を使用して Hadoop 上のデータを変換できます。 高度な機能には、増分読み込み、SQL を使用した書式設定、データセットの更新などがあります。 Sqoop は並列で動作し、高速なデータ転送を実現します。
注意
Sqoop プロジェクトは廃止されました。 Sqoop は 2021 年 6 月に Apache Attic に移動されました。 Web サイト、ダウンロード、イシュー トラッカーは引き続きすべて使用できます。 詳細については、Apache Attic の Apache Sqoop を参照してください。
Apache®、Apache Spark®、Apache Hadoop®、Apache HBase、Apache Hive、Apache Ranger®、Apache Storm®、Apache Sqoop®、Apache Kafka®、および炎のロゴは、Apache Software Foundation の米国およびその他の国における登録商標または商標です。 これらのマークを使用することが、Apache Software Foundation による保証を意味するものではありません。
Sqoop のアーキテクチャとコンポーネント
Sqoop には、Sqoop1 と Sqoop2 の 2 つのバージョンがあります。 Sqoop1 は単純なクライアント ツールですが、Sqoop2 にはクライアント/サーバー アーキテクチャがあります。 これらは互いに互換性がないため、使用方法が異なります。 Sqoop2 は機能が完全ではなく、運用環境へのデプロイを目的としたものではありません。
Sqoop1 のアーキテクチャ

Sqoop1 のインポートとエクスポート
[インポート]
リレーショナル データベースからデータを読み取り、HDFS にデータを出力します。 リレーショナル データベースのテーブル内の各レコードは、HDFS に 1 行として出力されます。 HDFS に書き込むことができるファイル形式は、テキスト、SequenceFiles、Avro です。
エクスポート
HDFS からデータを読み取り、リレーショナル データベースに転送します。 ターゲット リレーショナル データベースでは、挿入と更新の両方がサポートされます。
Sqoop2 のアーキテクチャ

Sqoop サーバー
Sqoop クライアントのエントリ ポイントを提供します。
Sqoop クライアント
Sqoop サーバーとやり取りします。 クライアントは、サーバーと通信できれば、任意のノードに配置できます。 クライアントはサーバーとの通信のみを必要とするため、MapReduce と同様に設定する必要はありません。
オンプレミスの Sqoop の課題
オンプレミスの Sqoop デプロイの一般的な課題を次に示します。
- ハードウェアとデータセンターの容量によっては、スケーリングが困難な場合があります。
- 必要に応じて簡単にスケーリングすることはできません。
- 古くなったインフラストラクチャのサポートが終了すると、置き換えとアップグレードを強制される可能性があります。
- 提供されるネイティブ ツールがありません。
- コストの透明性
- 監視
- DevOps
- オートメーション
考慮事項
- Sqoop を Azure に移行し、データ ソースをオンプレミスに残す場合は、その接続性を考慮する必要があります。 Azure と既存のオンプレミス ネットワークの間でインターネット経由で VPN 接続を確立するか、Azure ExpressRoute を使用してプライベート接続を確立することができます。
- Sqoop を Azure HDInsight に移行する場合は、Sqoop のバージョンを考慮してください。 HDInsight では Sqoop1 のみがサポートされるため、オンプレミス環境で Sqoop2 を使用している場合は、HDInsight 上の Sqoop1 に置き換えるか、Sqoop2 を独立した状態にしておく必要があります。
- Sqoop を Azure Data Factory に移行する場合は、データ ファイルの形式を考慮する必要があります。 Data Factory では、SequenceFile 形式はサポートされません。 Sqoop の実装において SequenceFile 形式でデータをインポートする場合、サポートがないことが問題になる可能性があります。 詳細については、「ファイル形式」を参照してください。
移行のアプローチ
Azure には、Apache Sqoop のいくつかの移行ターゲットがあります。 要件と製品の機能に応じて、Azure IaaS 仮想マシン (VM)、Azure HDInsight、Azure Data Factory を選択できます。
移行ターゲットを選択するための決定チャートを次に示します。

以下のセクションでは、移行ターゲットについて説明します。
Azure IaaS へのリフト アンド シフト移行
オンプレミスの Sqoop の移行先として Azure IaaS VM を選択した場合は、リフト アンド シフト移行を実行できます。 完全に制御可能な環境を作成するには、同じバージョンの Sqoop を使用します。 このため、Sqoop ソフトウェアを変更する必要はありません。 Sqoop は Hadoop クラスターと連携して動作し、通常は Hadoop クラスターと共に移行されます。 次の記事は、Hadoop クラスターのリフト アンド シフト移行のガイドです。 移行するサービスに該当する記事を選択します。
移行の準備
移行の準備を行うには、移行を計画して、ネットワーク接続を確立します。
移行の計画
オンプレミスの Sqoop の移行を準備するために、次の情報を収集します。 この情報は、移行先の仮想マシンのサイズを決定し、ソフトウェア コンポーネントとネットワーク構成を計画するのに役立ちます。
| Item | バックグラウンド |
|---|---|
| 現在のホストのサイズ | Sqoop クライアントまたはサーバーが実行されているホストまたは仮想マシンの CPU、メモリ、ディスク、およびその他のコンポーネントに関する情報を取得します。 この情報は、Azure 仮想マシンに必要な基本サイズを推定するために使用します。 |
| ホストとアプリケーションのメトリック | Sqoop クライアントを実行するマシンのリソース使用状況情報 (CPU、メモリ、ディスク、およびその他のコンポーネント) を取得し、実際に使用されるリソースを見積もります。 ホストに割り当てられているリソースよりも少ないリソースが使用されている場合は、Azure への移行時にダウンサイズを検討してください。 必要なリソースの量を確認したら、「Azure の仮想マシンのサイズ」を参照して、移行する仮想マシンの種類を選択します。 |
| Sqoop のバージョン | オンプレミスの Sqoop のバージョンを確認して、Azure 仮想マシンにインストールする Sqoop のバージョンを決定します。 Cloudera や Hortonworks などのディストリビューションを使用している場合、コンポーネントのバージョンはそのディストリビューションのバージョンによって異なります。 |
| ジョブとスクリプトの実行 | Sqoop を実行するジョブと、それらをスケジュールする方法を確認します。 ジョブと方法は移行の候補です。 |
| 接続するデータベース | Sqoop ジョブのインポートおよびエクスポート コマンドで指定される、Sqoop が接続するデータベースを確認します。 それらを確認したら、Sqoop を Azure 仮想マシンに移行した後に、それらのデータベースに接続できるかどうかを確認する必要があります。 接続するデータベースの一部がまだオンプレミスにある場合は、オンプレミスと Azure の間のネットワーク接続が必要です。 詳細については、「ネットワーク接続の確立」セクションを参照してください。 |
| プラグイン | 使用する Sqoop プラグインを確認し、それらを移行できるかどうかを判断します。 |
| 高可用性、ビジネス継続性、ディザスター リカバリー | オンプレミスで使用しているトラブルシューティング手法を Azure で使用できるかどうかを判断します。 たとえば、2 つのノードにアクティブ/スタンバイ構成がある場合は、Sqoop クライアント用に同じ構成を持つ 2 つの Azure 仮想マシンを準備します。 ディザスター リカバリーを構成する場合も同様です。 |
ネットワーク接続の確立
接続するデータベースの一部をオンプレミスに残した場合は、オンプレミスと Azure の間のネットワーク接続が必要です。
オンプレミスとプライベート ネットワーク上の Azure を接続するには、主に次の 2 つのオプションがあります。
VPN Gateway
Azure VPN Gateway を使用すると、暗号化されたトラフィックを Azure 仮想ネットワークとオンプレミスの場所の間でパブリック インターネット経由で送信できます。 この手法は安価でセットアップが簡単です。 ただし、インターネット経由の暗号化された接続であるため、通信の帯域幅は保証されません。 帯域幅を保証する必要がある場合は、2 番目のオプションである ExpressRoute を選択する必要があります。 VPN オプションの詳細については、「VPN Gateway とは」と「VPN Gateway の設計」を参照してください。
ExpressRoute
ExpressRoute では、接続プロバイダーによって提供されるプライベート接続を使用して、オンプレミス ネットワークを Azure または Microsoft 365 に接続できます。 ExpressRoute はパブリック インターネットを経由しないため、インターネット経由の接続よりも安全で信頼性が高く、一貫した待機時間になります。 さらに、購入する回線の帯域幅オプションによって、安定した待機時間が保証されます。 詳細については、「Azure ExpressRoute とは」を参照してください。
これらのプライベート接続の方法でニーズが満たされない場合は、移行先として Azure Data Factory を検討してください。 Data Factory のセルフホステッド統合ランタイムを使用すると、プライベート ネットワークを構成しなくても、オンプレミスから Azure にデータを転送できます。
データと設定を移行する
オンプレミスの Sqoop を Azure 仮想マシンに移行する場合は、次のデータと設定を含めます。
Sqoop 構成ファイル: 環境によって異なりますが、多くの場合、次のファイルが含まれます。
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml、Oraoopを使用する場合
保存されたジョブ:
sqoop job --createコマンドを使用して Sqoop メタストアにジョブを保存した場合は、それらを移行する必要があります。 メタストアの保存先は、sqoop-site.xml で定義されます。 共有メタストアが設定されていない場合は、メタストアを実行するユーザーのホーム ディレクトリの .sqoop サブディレクトリで、保存されたジョブを探します。次のコマンドを使用すると、保存されたジョブに関する情報を表示できます。
保存されたジョブの一覧を取得する:
sqoop job --list保存されたジョブのパラメーターを表示する
sqoop job --show <job-id>
スクリプト: Sqoop を実行するスクリプト ファイルがある場合は、それらを移行する必要があります。
スケジューラ: Sqoop の実行をスケジュールする場合は、Linux の cron ジョブやジョブ管理ツールなど、そのスケジューラを確認する必要があります。 その後、スケジューラを Azure に移行できるかどうかを検討する必要があります。
プラグイン: Sqoop でカスタム プラグイン (外部データベースへのコネクタなど) を使用している場合は、それらを移行する必要があります。 パッチ ファイルを作成した場合は、移行された Sqoop にパッチを適用します。
HDInsight への移行
HDInsight では、Apache Hadoop コンポーネントと HDInsight プラットフォームが、クラスター上にデプロイされるパッケージにバンドルされます。 Sqoop 自体を Azure に移行する代わりに、HDInsight クラスターで Sqoop を実行する方が一般的です。 HDInsight を使用して Hadoop や Spark などのオープンソース フレームワークを実行する方法の詳細については、「Azure HDInsight とは」および Azure HDInsight へのビッグ データ ワークロードの移行ガイドに関する記事を参照してください。
HDInsight のコンポーネントのバージョンについては、次の記事を参照してください。
Data Factory への移行
Azure Data Factory は、フル マネージドのサーバーレス データ統合サービスです。 データの量などの要因に応じて、オンデマンドでスケーリングできます。 Python、.NET、Azure Resource Manager テンプレート (ARM テンプレート) を使用して直感的な編集と開発を行うための GUI があります。
データ ソースへの接続
標準の Sqoop コネクタの一覧については、該当する記事を参照してください。
Data Factory には多数のコネクタがあります。 詳細については、「Azure Data Factory と Azure Synapse Analytics のコネクタの概要」を参照してください。
次の表は、Sqoop1 バージョン 1.4.7 および Sqoop2 バージョン 1.99.7 で使用される Data Factory コネクタを示した例です。 サポートされるバージョンの一覧が変更される可能性があるため、必ず最新のドキュメントを参照してください。
| Sqoop1 - 1.4.7 | Sqoop2 - 1.99.7 | Data Factory | 考慮事項 |
|---|---|---|---|
| MySQL JDBC コネクタ | 汎用 JDBC コネクタ | MySQL、Azure Database for MySQL | |
| MySQL Direct Connector | 該当なし | 該当なし | Direct Connector では、mysqldump を使用して、JDBC を経由せずにデータの入出力を行います。 Data Factory では方法が異なりますが、代わりに MySQL コネクタを使用できます。 |
| Microsoft SQL コネクタ | 汎用 JDBC コネクタ | SQL Server、Azure SQL Database、Azure SQL Managed Instance | |
| PostgreSQL コネクタ | PostgreSQL、汎用 JDBC コネクタ | Azure Database for PostgreSQL | |
| PostgreSQL Direct Connector | 該当なし | 該当なし | Direct Connector では、JDBC を経由せず、COPY コマンドを使用してデータの入出力を行います。 Data Factory では方法が異なりますが、代わりに PostgreSQL コネクタを使用できます。 |
| pg_bulkload コネクタ | 該当なし | 該当なし | pg_bulkload を使用して PostgreSQL に読み込みます。 Data Factory では方法が異なりますが、代わりに PostgreSQL コネクタを使用できます。 |
| Netezza コネクタ | 汎用 JDBC コネクタ | Netteza | |
| Oracle および Hadoop 用のデータ コネクタ | 汎用 JDBC コネクタ | Oracle | |
| 該当なし | FTP コネクタ | FTP | |
| 該当なし | SFTP コネクタ | SFTP | |
| 該当なし | Kafka コネクタ | 該当なし | Data Factory は Kafka に直接接続できません。 Azure Databricks や HDInsight などの Spark ストリーミングを使用して Kafka に接続することを検討してください。 |
| 該当なし | Kite コネクタ | 該当なし | Data Factory は Kite に直接接続できません。 |
| HDFS | HDFS | HDFS | Data Factory では、HDFS はソースとしてサポートされますが、シンクとしてはサポートされません。 |
オンプレミスのデータベースに接続する
Sqoop を Data Factory に移行した後も、オンプレミス ネットワーク内のデータ ストアと Azure の間でデータをコピーする必要がある場合は、次の方法を使用することを検討してください。
セルフホステッド統合ランタイム
パブリック クラウド環境からの直接通信パスがないプライベート ネットワーク環境にデータを統合しようとしている場合は、次の操作を行ってセキュリティを強化できます。
- 内部ファイアウォールまたは仮想プライベート ネットワーク内のオンプレミス環境に、セルフホステッド統合ランタイムをインストールします。
- データ移動のための接続を確立するために、セルフホステッド統合ランタイムから Azure への HTTPS ベースの送信接続を確立します。
セルフホステッド統合ランタイムは、Windows でのみサポートされます。 また、複数のマシンにセルフホステッド統合ランタイムをインストールして関連付けることで、スケーラビリティと高可用性を実現することもできます。 セルフホステッド統合ランタイムは、オンプレミスまたは Azure 仮想ネットワークにないリソースにデータ変換アクティビティをディスパッチする役割も担います。
セルフホステッド統合ランタイムのセットアップ方法については、「セルフホステッド統合ランタイムの作成と構成」を参照してください。
プライベート エンドポイントを使用したマネージド仮想ネットワーク
オンプレミスと Azure の間にプライベート接続がある (ExpressRoute や VPN Gateway など) 場合は、Data Factory のマネージド仮想ネットワークとプライベート エンドポイントを使用して、オンプレミス データベースへのプライベート接続を確立できます。 次の図に示すように、仮想ネットワークを使用してオンプレミスのリソースにトラフィックを転送し、インターネットを経由せずにオンプレミスのリソースにアクセスできます。

このアーキテクチャの Visio ファイルをダウンロードします。
詳細については、「チュートリアル: プライベート エンドポイントを使用して Data Factory マネージド VNet からオンプレミスの SQL Server にアクセスする方法」を参照してください。
ネットワーク オプション
Data Factory には、次の 2 つのネットワーク オプションがあります。
どちらもプライベート ネットワークを構築し、データ統合のプロセスをセキュリティで保護するのに役立ちます。 これらは同時に使用できます。
マネージド仮想ネットワーク
統合ランタイム (Data Factory ランタイム) は、マネージド仮想ネットワーク内にデプロイできます。 マネージド仮想ネットワークに接続するデータ ストアなどのプライベート エンドポイントをデプロイすることで、閉域プライベート ネットワーク内のデータ統合の安全性を向上させることができます。

このアーキテクチャの Visio ファイルをダウンロードします。
詳細については、「Azure Data Factory のマネージド仮想ネットワーク」を参照してください。
プライベート リンク
Azure Data Factory 用の Azure Private Link を使用して Data Factory に接続できます。

このアーキテクチャの Visio ファイルをダウンロードします。
詳細については、「プライベート エンドポイントとは」と「Private Link のドキュメント」を参照してください。
データ コピーのパフォーマンス
Sqoop では、並列処理に MapReduce を使用することで、データ転送のパフォーマンスを向上させています。 Sqoop の移行後は、Data Factory によって、大規模なデータ移行を実行するシナリオのパフォーマンスとスケーラビリティを調整できます。
"データ統合ユニット" (DIU) は、Data Factory のパフォーマンスの単位です。 これは、CPU、メモリ、ネットワーク リソース割り当てを組み合わせたものです。 Data Factory では、Azure 統合ランタイムを使用するコピー アクティビティ用に最大 256 個の DIU を調整できます。 詳細については、「データ統合単位」を参照してください。
セルフホステッド統合ランタイムを使用する場合は、セルフホステッド統合ランタイムをホストするマシンをスケーリングすることで、パフォーマンスを向上させることができます。 最大のスケールアウトは 4 つのノードです。
目的のパフォーマンスを実現するための調整の詳細については、「コピー アクティビティのパフォーマンスとスケーラビリティに関するガイド」を参照してください。
SQL の適用
Sqoop では、次の例に示すように、SQL クエリの結果セットをインポートできます。
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
Data Factory では、データベースに対してクエリを実行し、結果セットをコピーすることもできます。
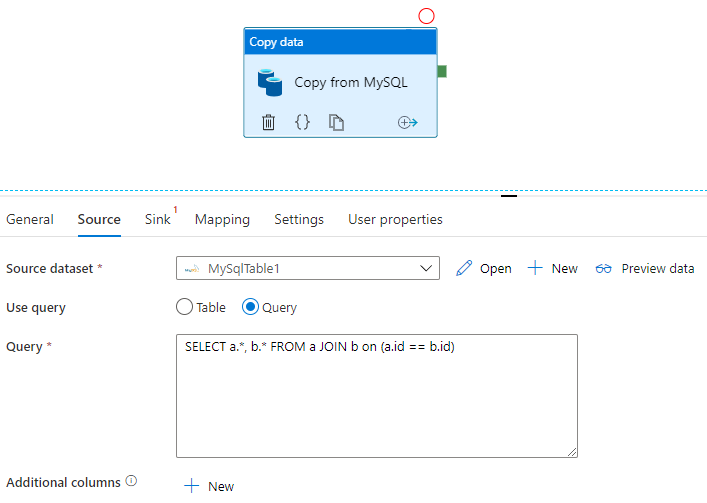
MySQL データベースに対するクエリの結果セットを取得する例については、「コピー アクティビティのプロパティ」を参照してください。
データの変換
Data Factory と HDInsight の両方で、さまざまなデータ変換アクティビティを実行できます。
Data Factory のアクティビティを使用してデータを変換する
Data Factory では、データ フローやデータ ラングリングなど、さまざまなデータ変換アクティビティを実行できます。 どちらの場合も、ビジュアル UI を使用して変換を定義します。 HDInsight、Databricks、ストアド プロシージャのさまざまな Hadoop コンポーネントのアクティビティとその他のカスタム アクティビティを使用することもできます。 Sqoop を移行し、そのプロセスにデータ変換を含める場合は、これらのアクティビティの使用を検討してください。 詳細については、Azure Data Factory でのデータの変換に関する記事を参照してください。
HDInsight アクティビティを使用してデータを変換する
Hive、Pig、MapReduce、Streaming、Spark など、Azure Data Factory パイプライン内のさまざまな HDInsight アクティビティでは、独自のクラスターまたはオンデマンド HDInsight クラスターでプログラムとクエリを実行できます。 Hadoop エコシステムのデータ変換ロジックを使用する Sqoop 実装を移行する場合は、変換を HDInsight アクティビティに簡単に移行できます。 詳細については、次の記事を参照してください。
- Azure Data Factory または Synapse Analytics で Hadoop Hive アクティビティを使用してデータを変換する
- Azure Data Factory または Synapse Analytics で Hadoop MapReduce アクティビティを使用してデータを変換する
- Azure Data Factory または Synapse Analytics で Hadoop Pig アクティビティを使用してデータを変換する
- Azure Data Factory と Synapse Analytics で Spark アクティビティを使用してデータを変換する
- Azure Data Factory または Synapse Analytics で Hadoop Streaming アクティビティを使用してデータを変換する
ファイル形式
Sqoop では、HDFS にデータをインポートするときに、テキスト、SequenceFile、Avro がファイル形式としてサポートされます。 Data Factory では、HDFS をデータ シンクとしてサポートしていませんが、ファイル ストレージとして Azure Data Lake Storage または Azure Blob Storage が使用されます。 HDFS の移行の詳細については、Apache HDFS の移行に関する記事を参照してください。
Data Factory でファイル ストレージに書き込む際にサポートされる形式は、テキスト、バイナリ、Avro、JSON、ORC、Parquet ですが、SequenceFile はサポートされません。 Spark などのアクティビティを使用し、saveAsSequenceFile を使用してファイルを SequenceFile に変換できます。
data.saveAsSequenceFile(<path>)
ジョブのスケジュール設定
Sqoop にはスケジューラ機能はありません。 スケジューラで Sqoop ジョブを実行している場合は、その機能を Data Factory に移行する必要があります。 Data Factory では、トリガーを使用して、データ パイプラインの実行をスケジュールできます。 既存のスケジュール構成に従って、Data Factory のトリガーを選択します。 トリガーの種類を次に示します。
- スケジュール トリガー: スケジュール トリガーでは、実時間のスケジュールでパイプラインが実行されます。
- タンブリング ウィンドウ トリガー: タンブリング ウィンドウ トリガーは、指定した開始時刻から定期的に実行され、その状態が維持されます。
- イベント ベースのトリガー: イベント ベースのトリガーでは、イベントに応答してパイプラインがトリガーされます。 イベントベースのトリガーには、2 つの種類があります。
- ストレージ イベント トリガー: ストレージ イベント トリガーでは、ファイルの作成、削除、書き込みなどのストレージ イベントに応答してパイプラインがトリガーされます。
- カスタム イベント トリガー: カスタム イベント トリガーでは、イベント グリッド内のカスタム トピックに送信されるイベントに応答してパイプラインがトリガーされます。 カスタム トピックの詳細については、「Azure Event Grid でのカスタム トピック」を参照してください。
トリガーの詳細については、「Azure Data Factory または Azure Synapse Analytics でのパイプラインの実行とトリガー」を参照してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Namrata Maheshwary | シニア クラウド ソリューション アーキテクト
- Raja N | ディレクター、カスタマー サクセス
- Hideo Takagi | クラウド ソリューション アーキテクト
- Ram Yerrabotu | シニア クラウド ソリューション アーキテクト
その他の共同作成者:
- Ram Baskaran | シニア クラウド ソリューション アーキテクト
- Jason Bouska | シニア ソフトウェア エンジニア
- Eugene Chung | シニア クラウド ソリューション アーキテクト
- Pawan Hosatti | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Daman Kaur | クラウド ソリューション アーキテクト
- Danny Liu | シニア クラウド ソリューション アーキテクト - エンジニアリング
- Jose Mendez | シニア クラウド ソリューション アーキテクト
- Ben Sadeghi | シニア スペシャリスト
- Sunil Sattiraju | シニア クラウド ソリューション アーキテクト
- Amanjeet Singh | プリンシパル プログラム マネージャー
- Nagaraj Seeplapudur Venkatesan | シニア クラウド ソリューション アーキテクト - エンジニアリング
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
Azure 製品の概要
- Azure Data Lake Storage Gen2 の概要
- Apache Spark とは - Azure HDInsight
- Azure HDInsight の Apache Hadoop の概要
- Azure HDInsight での Apache HBase の概要
- Azure HDInsight での Apache Kafka の概要
- Azure HDInsight のエンタープライズ セキュリティの概要
Azure 製品のリファレンス
- Microsoft Entra のドキュメント
- Azure Cosmos DB のドキュメント
- Azure Data Factory のドキュメント
- Azure Databricks のドキュメント
- Azure Event Hubs のドキュメント
- Azure Functions のドキュメント
- Azure HDInsight のドキュメント
- Microsoft Purview データ ガバナンスに関するドキュメント
- Azure Stream Analytics のドキュメント
- Azure Synapse Analytics
その他
- Azure HDInsight 用の Enterprise セキュリティ パッケージ
- HDInsight 上の Apache Hadoop 用の Java MapReduce プログラムを開発する
- HDInsight の Hadoop での Apache Sqoop の使用
- Apache Spark ストリーミングの概要
- 構造化ストリーミングのチュートリアル
- Apache Kafka アプリケーションから Azure Event Hubs を使用する