このチュートリアルでは、Azure Data Factory を使用して Azure HDInsight で Apache Hadoop クラスター (オンデマンド) を作成する方法について説明します。 その後 Azure Data Factory でデータ パイプラインを使用して Hive ジョブを実行し、クラスターを削除します。 このチュートリアルを完了すると、クラスターの作成、ジョブの実行、クラスターの削除がスケジュールに従って実行されるビッグ データ ジョブの実行を operationalize する方法を習得できます。
このチュートリアルに含まれるタスクは次のとおりです。
- Azure のストレージ アカウントの作成
- Azure Data Factory のアクティビティを理解する
- Azure Portal を使用してデータ ファクトリを作成する
- リンクされたサービスを作成します
- パイプラインを作成する
- パイプラインをトリガーする
- パイプラインを監視する
- 出力を検証する
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
インストール済みの PowerShell Az モジュール。
Microsoft Entra サービス プリンシパル。 サービス プリンシパルを作成したら、リンク先の記事の手順に従って、アプリケーション ID と認証キーを必ず取得してください。 このチュートリアルで、後ほどこれらの値が必要になります。 また、サービス プリンシパルが、サブスクリプションまたはクラスターが作成されるリソース グループの共同作成者ロールのメンバーであることを確認してください。 必要な値を取得し、適切なロールを割り当てる手順については、「Microsoft Entra サービス プリンシパルを作成する」を参照してください。
予備の Azure オブジェクトを作成します。
このセクションでは、オンデマンドで作成する HDInsight クラスターに使用する各種オブジェクトを作成します。 作成されるストレージ アカウントには、クラスターで実行されるサンプル Apache Hive ジョブのシミュレートに使用するサンプル HiveQL スクリプトの partitionweblogs.hql が含まれます。
このセクションでは、Azure PowerShell スクリプトを使用してストレージ アカウントを作成し、ストレージ アカウント内の必要なファイルをコピーします。 このセクションの Azure PowerShell サンプル スクリプトでは、次のタスクを実行します。
- Azure へのサインイン
- Azure リソース グループを作成します。
- Azure Storage アカウントを作成します。
- ストレージ アカウントに BLOB コンテナーを作成します。
- サンプル HiveQL スクリプト (partitionweblogs.hql) を BLOB コンテナーにコピーします。 サンプル スクリプトは、別のパブリック BLOB コンテナーで既に使用できます。 下記の PowerShell スクリプトでは、作成された Azure ストレージ アカウントにこれらのファイルのコピーを作成します。
ストレージ アカウントを作成してファイルをコピーする
重要
スクリプトを使って作成する Azure リソース グループと Azure ストレージ アカウントの名前を指定します。 スクリプトによって出力されたリソース グループ名、ストレージ アカウント名、ストレージ アカウント キーを書き留めます。 これらは、次のセクションで必要になります。
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
ストレージ アカウントを確認する
- Azure Portal にサインオンします。
- 左側から、 [すべてのサービス]>[全般]>[リソース グループ] の順に移動します。
- PowerShell スクリプトで作成したリソース グループの名前を選択します。 一覧表示されるリソース グループが多すぎる場合は、フィルターを使用します。
- [概要] ビューには、リソース グループを他のプロジェクトと共有する場合を除き、リソースが 1 つだけ表示されています。 このリソースが、前の手順で指定した名前のストレージ アカウントです。 ストレージ アカウント名を選択します。
- [コンテナー] タイルを選択します。
- adfgetstarted コンテナーを選択します。
hivescriptsというフォルダーが表示されます。 - このフォルダーを開き、サンプル スクリプト ファイル (partitionweblogs.hql) があることを確認します。
Azure Data Factory のアクティビティを理解する
Azure Data Factory では、データの移動と変換を調整して自動化します。 Azure Data Factory を使用すると、入力データ スライスを処理するために HDInsight Hadoop クラスターをジャスト イン タイムで作成し、処理が完了したらクラスターを削除できます。
Azure Data Factory では、データ ファクトリに 1 つまたは複数のデータ パイプラインを設定できます。 データ パイプラインには、1 つ以上のアクティビティがあります。 次の 2 種類のアクティビティがあります。
- データ移動アクティビティ - データ移動アクティビティを使用して、ソース データ ストアから宛先データ ストアにデータを移動します。
- データ変換アクティビティ - データ変換アクティビティは、データを変換/処理するために使用します。 HDInsight Hive アクティビティは、Data Factory でサポートされるデータ変換アクティビティの 1 つです。 このチュートリアルでは、Hive 変換アクティビティを使用します。
この記事では、オンデマンドの HDInsight Hadoop クラスターを作成するように Hive アクティビティを構成します。 アクティビティを実行してデータ を処理するときには、次のことが行われます。
スライスを処理するために、HDInsight Hadoop クラスターが Just-In-Time 方式で自動的に作成されます。
クラスター上で HiveQL スクリプトを実行することによって入力データが処理されます。 このチュートリアルの Hive アクティビティに関連付けられた HiveQL スクリプトは、次のアクションを実行します。
- 既存のテーブル (hivesampletable) を使用して別のテーブル (HiveSampleOut) を作成します。
- HiveSampleOut テーブルに、元の hivesampletable の特定の列だけを設定します。
HDInsight Hadoop クラスターは、処理が完了し、(TimeToLive 設定で) 構成された時間アイドル状態になると、削除されます。 この TimeToLive アイドル時間内に次のデータ スライスを処理できる場合、スライスを処理するために同じクラスターが使用されます。
Data Factory の作成
Azure portal にサインインします。
左側のメニューで、
+ Create a resource>[分析]>[データ ファクトリ] の順に移動します。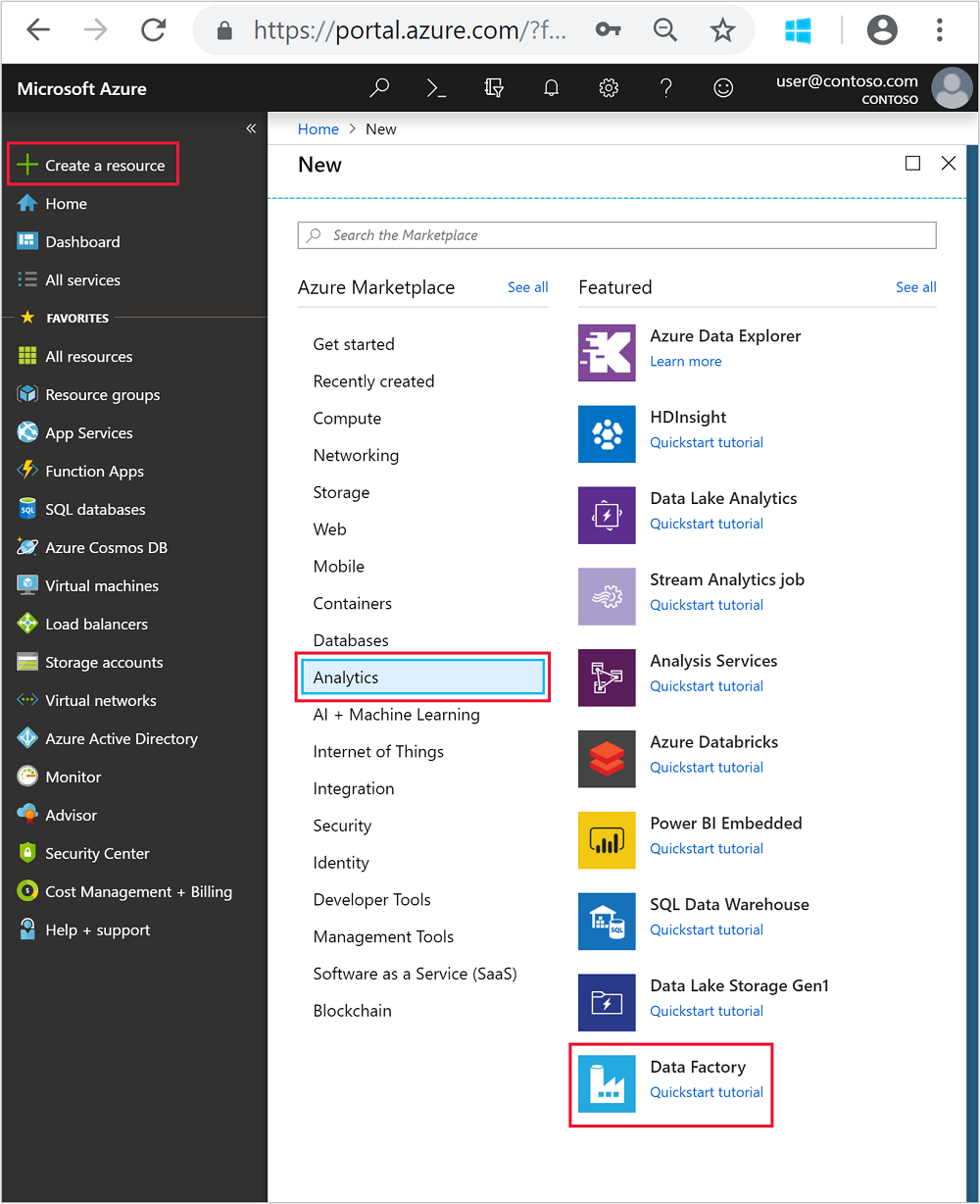
新しいデータ ファクトリタイルに以下の値を入力するか選択します。
プロパティ 値 名前 データ ファクトリの名前を入力します。 この名前はグローバルに一意である必要があります。 Version V2のままにします。 サブスクリプション Azure サブスクリプションを選択します。 Resource group PowerShell スクリプトを使用して作成したリソース グループを選択します。 場所 場所は、リソース グループの作成時に指定した場所に自動的に設定されます。 このチュートリアルでは、場所は [米国東部] に設定されます。 Enable GIT このボックスはオフにしてください。 
[作成] を選択します データ ファクトリの作成には、2 ~ 4 分ほどかかることがあります。
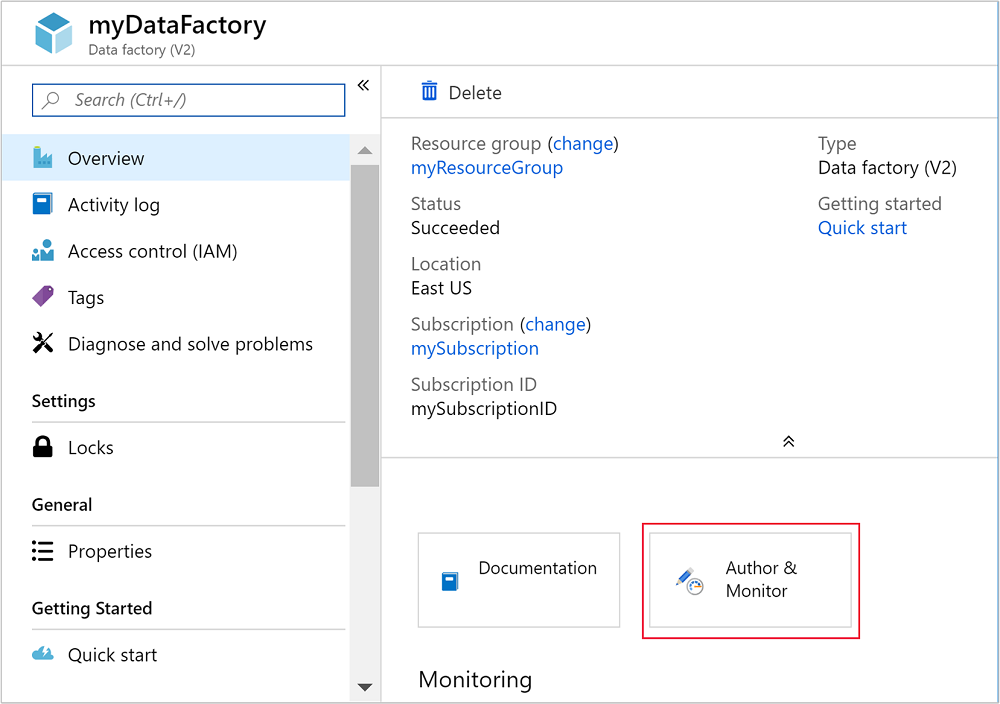
データ ファクトリが作成されると、 [リソースに移動] ボタンを含むデプロイ成功通知が届きます。 [リソースに移動] を選択して、Data Factory の既定のビューを開きます。
[作成と監視] を選択して、Azure Data Factory の作成および監視ポータルを起動します。
リンクされたサービスを作成します
このセクションでは、データ ファクトリ内に 2 つのリンクされたサービスを作成します。
- Azure ストレージ アカウントをデータ ファクトリにリンクする、Azure Storage のリンクされたサービス。 このストレージは、オンデマンドの HDInsight クラスターによって使用されます。 また、クラスター上で実行される Hive スクリプトも含まれています。
- オンデマンドの HDInsight のリンクされたサービス。 Azure Data Factory によって、HDInsight クラスターが自動的に作成され、Hive スクリプトが実行されます。 HDInsight クラスターは、事前に構成された時間だけアイドル状態になったら削除されます。
Azure Storage のリンクされたサービスを作成する
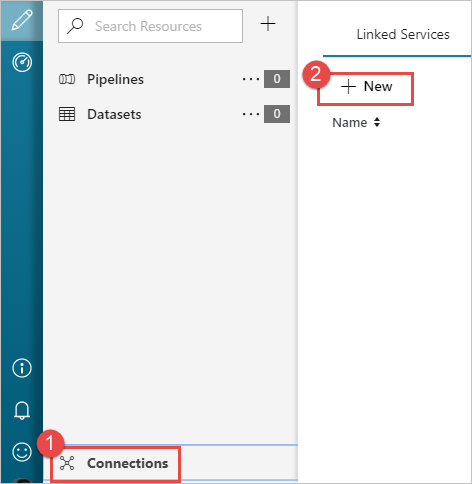
[始めましょう] ページの左側のウィンドウで、 [作成者] アイコンをクリックします。

ウィンドウの左下隅にある [接続] を選択し、 [+ 新規] を選択します。
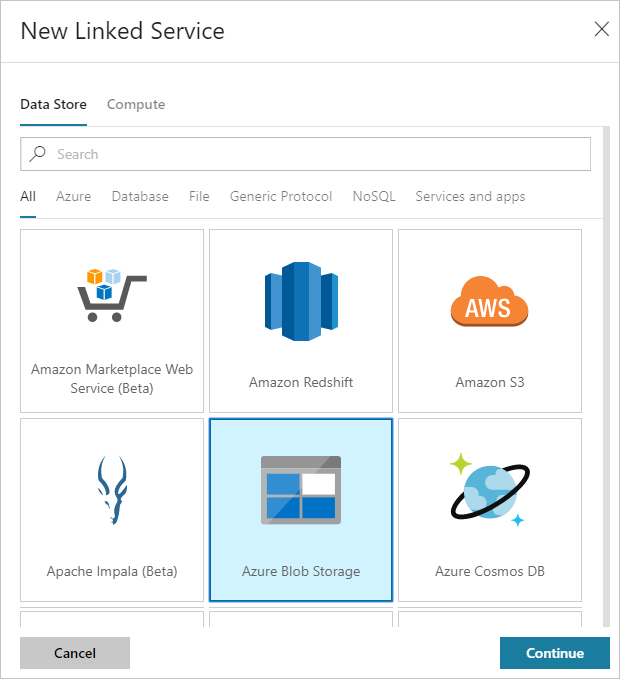
[New Linked Service](新しいリンクされたサービス) ダイアログ ボックスで [Azure Blob Storage] を選択し、 [続行] をクリックします。
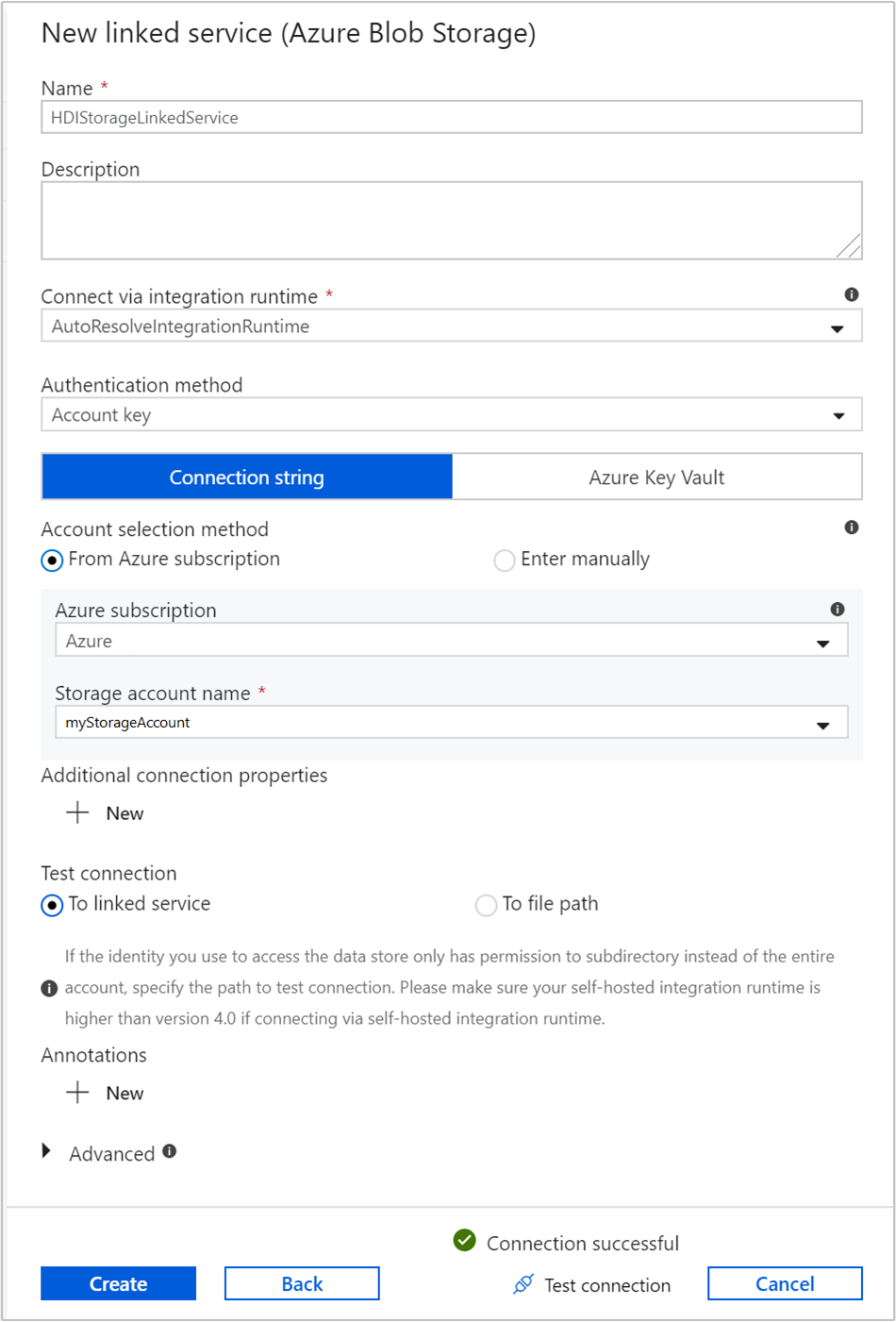
ストレージのリンク サービスに次の値を指定します。
プロパティ 値 名前 「 HDIStorageLinkedService」と入力します。Azure サブスクリプション ドロップダウン リストからサブスクリプションを選択します。 ストレージ アカウント名 PowerShell スクリプトの一部として作成した Azure Storage アカウントを選択します。 [テスト接続] を選択し、成功した場合は [作成] を選択します。
オンデマンドの HDInsight のリンクされたサービスを作成する
[+ 新規] ボタンをもう一度選択して、別のリンクされたサービスを作成します。
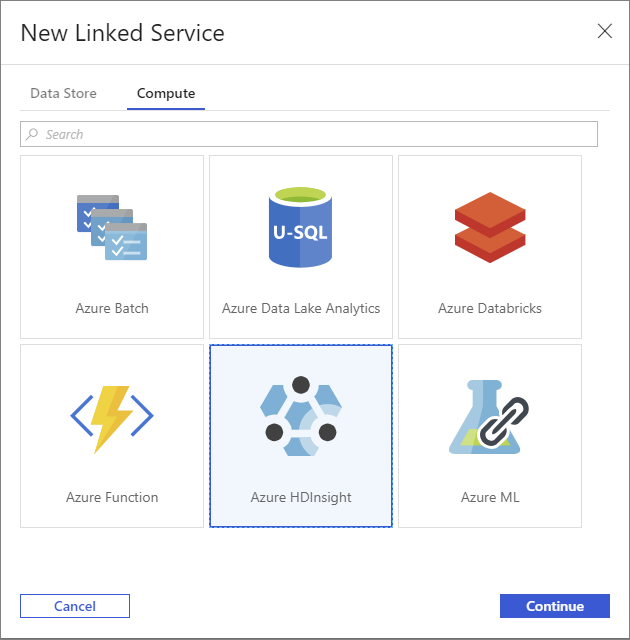
[New Linked Service](新しいリンクされたサービス) ウィンドウで、 [Compute] (計算) タブを選択します。
[Azure HDInsight] を選択し、 [続行] を選択します。
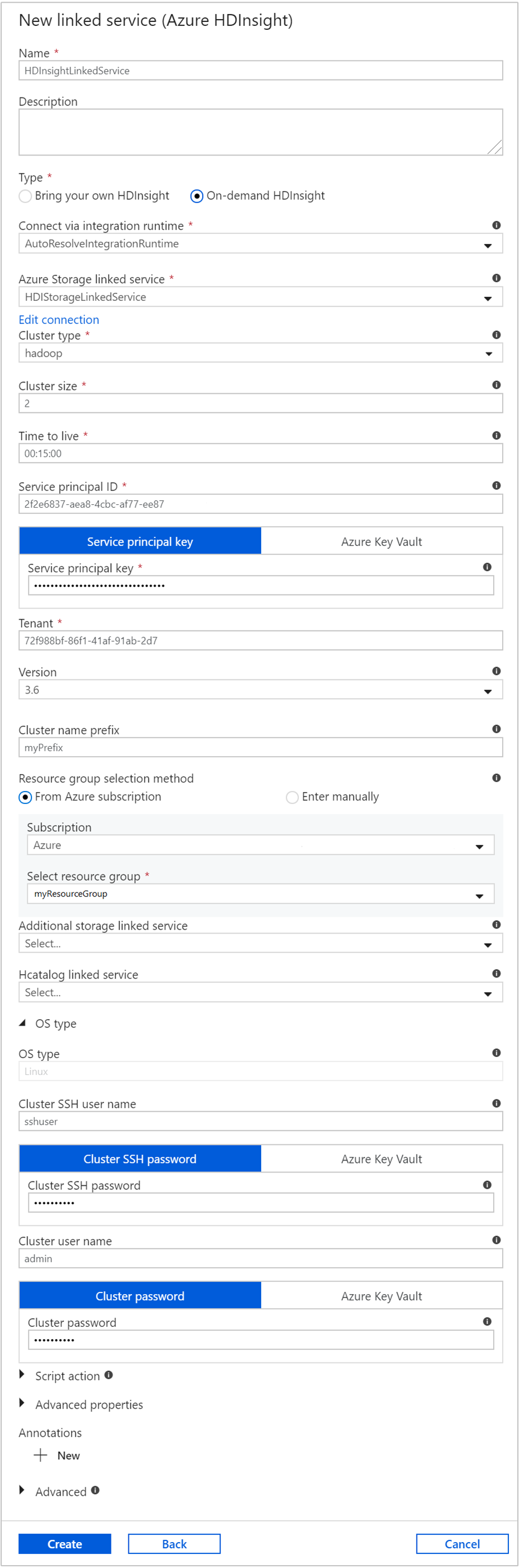
[New Linked Service] (新しいリンク サービス) ウィンドウで 次の値を入力し、残りは既定値のままにしておきます。
プロパティ 値 名前 「 HDInsightLinkedService」と入力します。Type [On-demand HDInsight](オンデマンド HDInsight) を選択します。 Azure Storage のリンクされたサービス [ HDIStorageLinkedService] を選択します。クラスターの種類 [hadoop] を選択します。 Time to Live HDInsight クラスターを使用できるようにしておく期間を指定します。この期間を過ぎると、クラスターは自動的に削除されます。 サービス プリンシパル ID 前提条件の一部として作成した Microsoft Entra サービス プリンシパルのアプリケーション ID を指定します。 サービス プリンシパル キー Microsoft Entra サービス プリンシパルの認証キーを指定します。 Cluster name prefix(クラスター名のプレフィックス) データ ファクトリによって作成されるすべてのクラスターの種類にプレフィックスとして追加する値を指定します。 サブスクリプション ドロップダウン リストからサブスクリプションを選択します。 リソース グループの選択 以前に使用した PowerShell スクリプトの一部として作成したリソース グループを選択します。 OS type/Cluster SSH ユーザー名 SSH ユーザー名 (通常は sshuser) を入力します。OS type/Cluster SSH パスワード SSH ユーザーのパスワードを指定します。 OS type/Cluster ユーザー名 クラスターのユーザー名 (通常は admin) を入力します。OS type/Cluster パスワード クラスター ユーザーのパスワードを指定します。 [作成] を選択します。
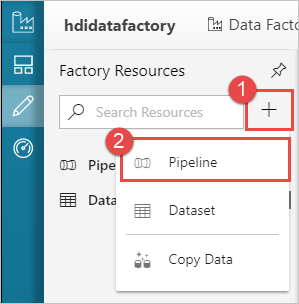
パイプラインを作成する
+ (正符号) ボタンを選択し、[パイプライン] を選択します。
[アクティビティ] ツールボックスで [HDInsight] を展開し、パイプライン デザイナー画面に Hive アクティビティをドラッグします。 [全般] タブで、アクティビティの名前を指定します。
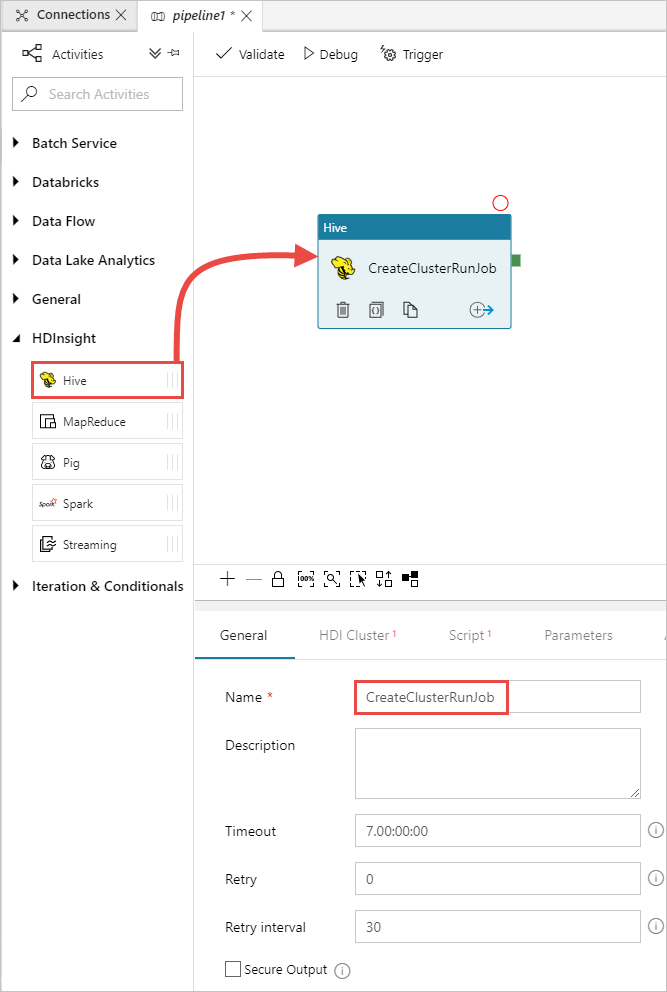
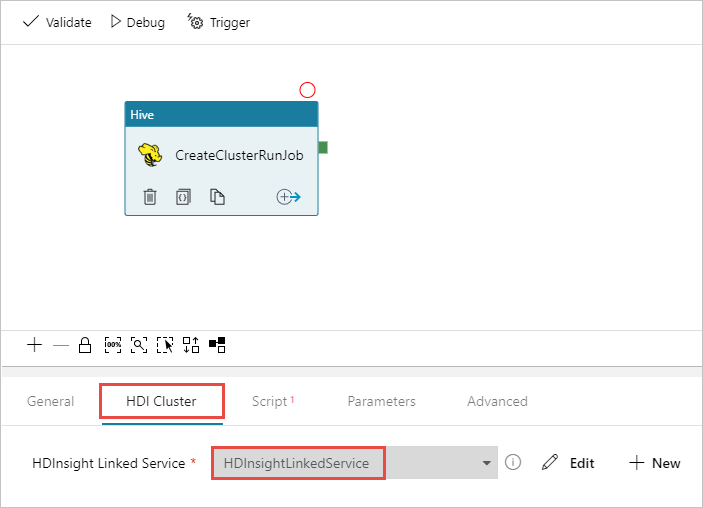
Hive アクティビティが選択されていることを確認し、 [HDI Cluster](HDI クラスター) タブを選択します。 [HDInsight Linked Service](HDInsight のリンクされたサービス) ドロップダウン リストで、HDInsight 用に以前に作成したリンク サービスの HDInsightLinkedService を選択します。
[スクリプト] タブを選択し、次の手順を実行します。
[スクリプトにリンクされたサービス] でドロップダウン リストから [HDIStorageLinkedService] を選択します。 この値は、以前に作成したストレージのリンクされたサービスです。
[ファイル パス] で [ストレージを参照] を選択し、サンプル Hive スクリプトがある場所に移動します。 以前に PowerShell スクリプトを実行した場合、この場所は
adfgetstarted/hivescripts/partitionweblogs.hqlになります。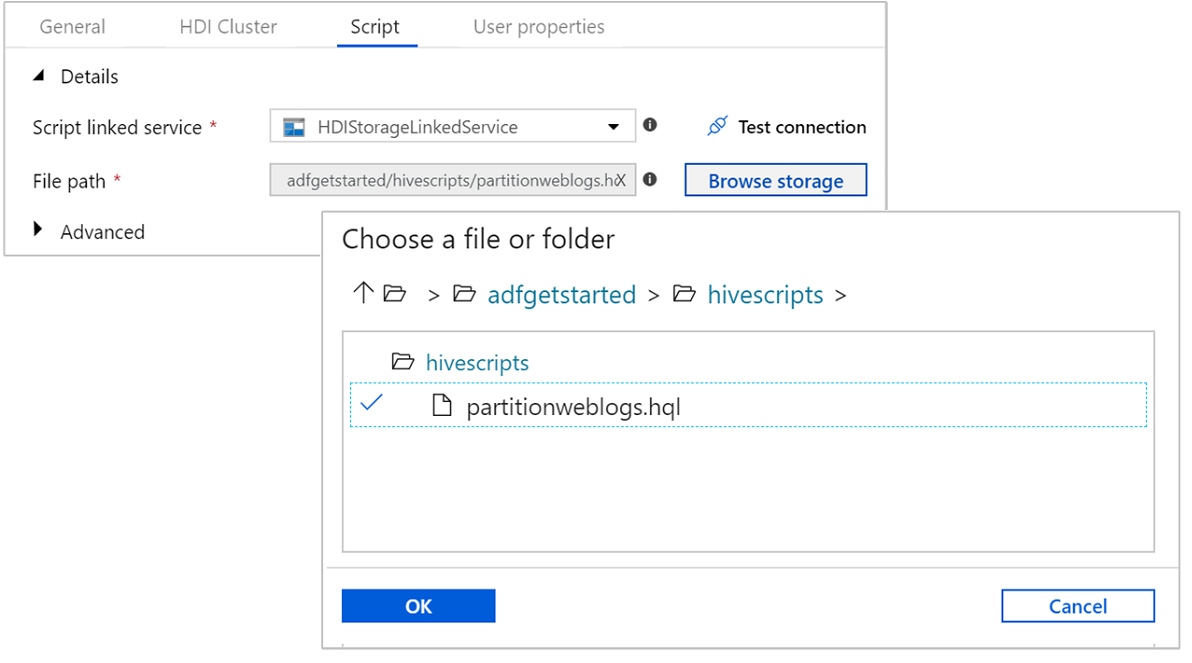
[詳細設定]>[パラメーター] で、[
Auto-fill from script] を選択します。 このオプションを選択すると、実行時に値を必要とする、Hive スクリプトのパラメーターが検索されます。[値] ボックスに、
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/形式で既存のフォルダーを追加します。 パスの大文字と小文字は区別されます。 このパスにスクリプトの出力が保存されます。 ストレージ アカウントではセキュリティで保護された転送が既定で有効であることが必要になったため、wasbsスキーマが不可欠です。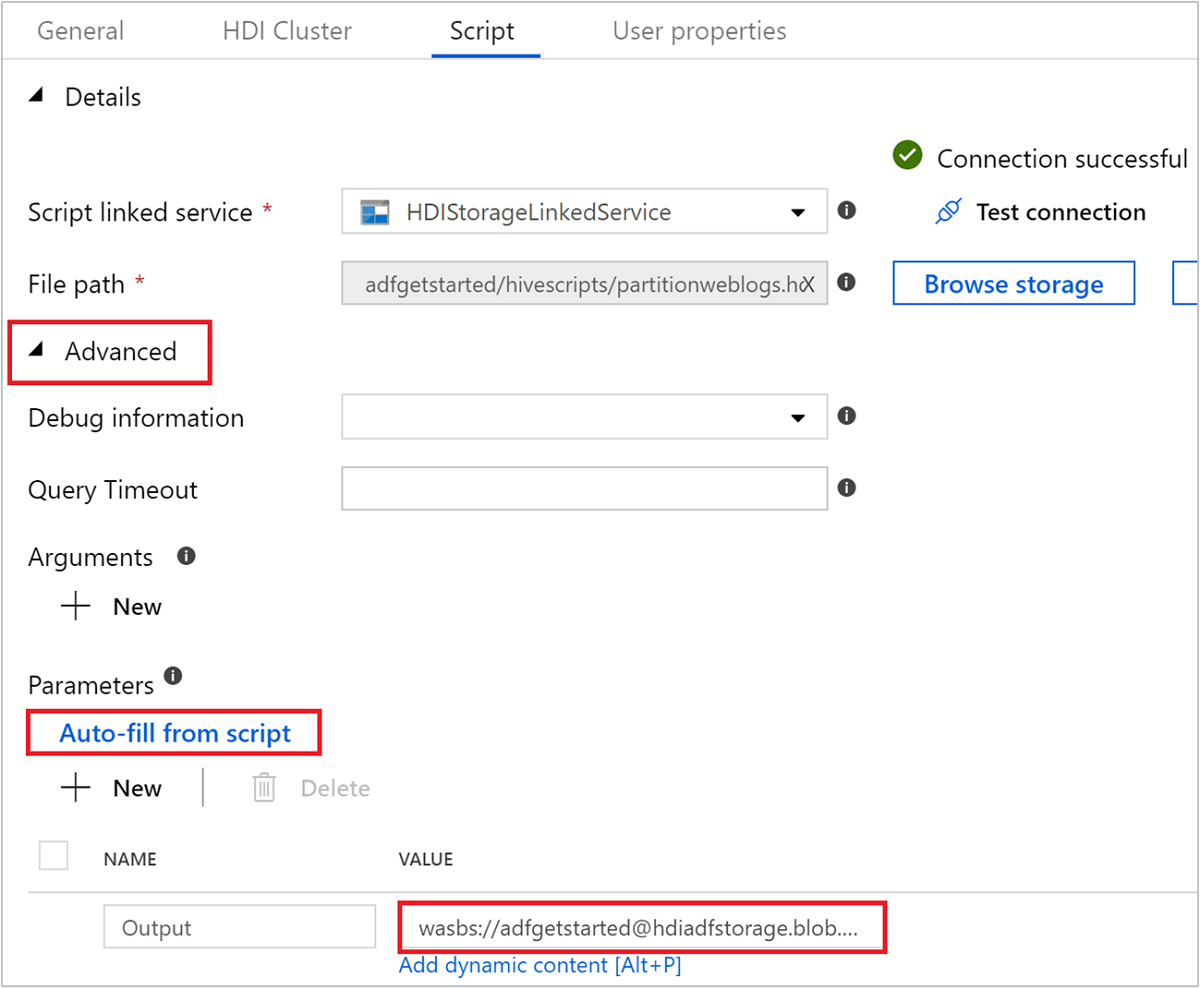
[検証] を選択してパイプラインを検証します。 >> (右矢印) ボタンを選択して、検証ウィンドウを閉じます。
最後に、 [すべて発行] を選択して、成果物を Azure Data Factory に発行します。
パイプラインをトリガーする
デザイナー画面のツール バーで、 [Add trigger] (トリガーを追加)>[Trigger Now](今すぐトリガー) を選択します。
ポップアップ サイド バーで [OK] を選択します。
パイプラインを監視する
左側で [監視] タブに切り替えます。 [Pipeline Runs](パイプラインの実行) の一覧にパイプライン実行が表示されます。 [状態] 列で実行の状態を確認します。
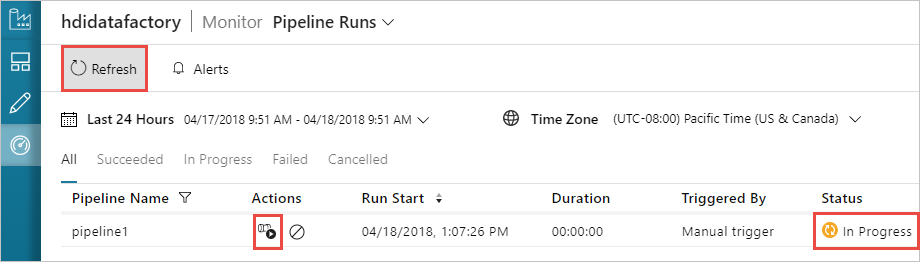
[最新の情報に更新] を選択して、状態を更新します。
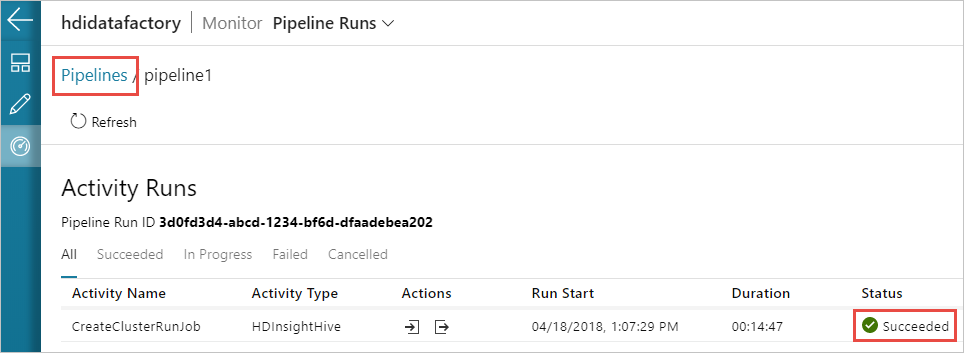
[View Activity Runs](アクティビティの実行の表示) アイコンをクリックして、パイプラインに関連付けられているアクティビティの実行を表示することもできます。 作成したパイプラインにはアクティビティが 1 つしかないため、次のスクリーンショットでは、アクティビティの実行が 1 つしか表示されていません。 前のビューに戻るには、ページの上部にある [パイプライン] を選択します。
出力を検証する
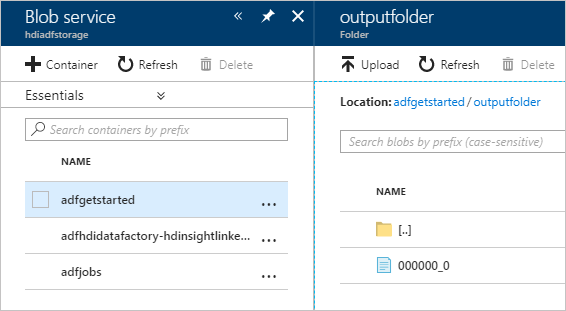
出力を検証するには、Azure Portal 上で、このチュートリアルで使用したストレージ アカウントに移動します。 次のフォルダーまたはコンテナーが表示されます。
パイプラインの一部として実行された Hive スクリプトの出力が含まれた adfgerstarted/outputfolder が表示されます。
adfhdidatafactory-<リンクされたサービスの名前>-<タイムスタンプ> コンテナーが表示されます。 このコンテナーは、パイプライン実行の一環として作成された HDInsight クラスターの既定のストレージの場所です。
Azure Data Factory のジョブ ログがある adfjobs コンテナーが表示されます。
リソースをクリーンアップする
オンデマンドの HDInsight クラスターを作成した場合、HDInsight クラスターを明示的に削除する必要はありません。 クラスターは、パイプラインの作成時に指定した構成に基づいて削除されます。 クラスターを削除した後も、クラスターに関連付けられているストレージ アカウントは引き続き存在します。 データをそのまま保持できるように、この動作は仕様です。 データを保持する必要がない場合は、作成したストレージ アカウントを削除してかまいません。
また、このチュートリアルで作成したリソース グループ全体を削除することもできます。 このプロセスにより、作成したストレージ アカウントと Azure Data Factory が削除されます。
リソース グループを削除します
Azure Portal にサインオンします。
左側のウィンドウの [リソース グループ] を選択します。
PowerShell スクリプトで作成したリソース グループの名前を選択します。 一覧表示されるリソース グループが多すぎる場合は、フィルターを使用します。 リソース グループが開きます。
[リソース] タイルには、リソース グループを他のプロジェクトと共有する場合を除き、既定のストレージ アカウントとデータ ファクトリが表示されます。
[リソース グループの削除] を選択します。 この操作を実行すると、ストレージ アカウントと、そのストレージ アカウントに格納されているデータが削除されます。
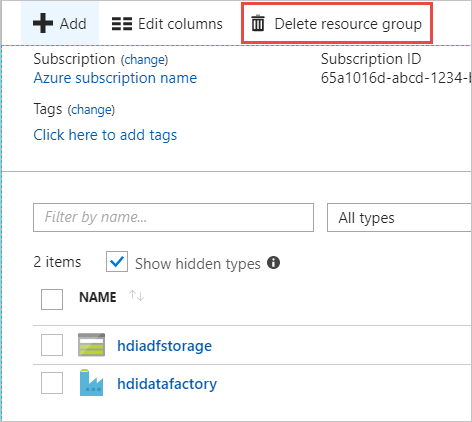
リソース グループ名を入力して削除を確認し、 [削除] をクリックします。
次のステップ
この記事では、Azure Data Factory を使用してオンデマンドの HDInsight クラスターを作成し、Apache Hive ジョブを実行する方法を説明しました。 次の記事に進み、HDInsight クラスターをカスタム構成で作成する方法を確認してください。