適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ ファクトリと Synapse パイプラインの Spark アクティビティでは、独自のまたはオンデマンドの HDInsight クラスターで Spark プログラムを実行します。 この記事は、データ変換とサポートされる変換アクティビティの概要を説明する、 データ変換アクティビティ に関する記事に基づいています。 オンデマンドの Spark のリンクされたサービスを使用すると、サービスは自動的に Spark クラスターを作成し、Just-In-Time でデータを処理し、処理が完了するとクラスターを削除します。
UI を使用したパイプラインへの Spark アクティビティの追加
パイプラインに Spark アクティビティを使用するには、次の手順を実行します。
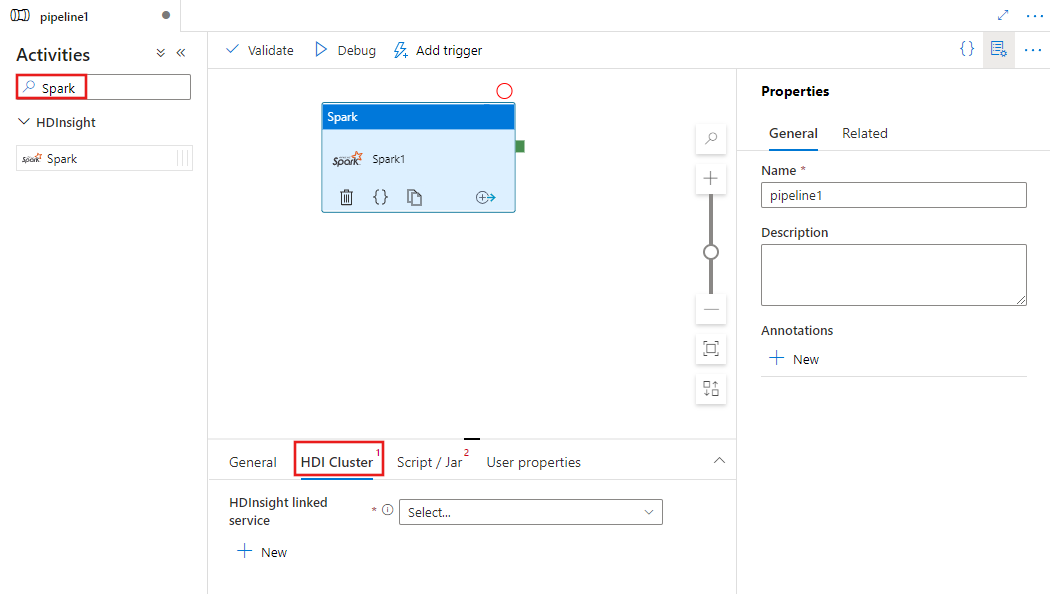
パイプラインの [アクティビティ] ペイン内で Spark を検索し、Spark アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい Spark アクティビティを選択します。
HDI Cluster タブを選択して、Spark アクティビティの実行に使用する HDInsight クラスターへのリンク サービスを選択または新規作成します。
Script/Jar タブを選択して、スクリプトをホストするAzure Storage アカウントにリンクされた新しいジョブ サービスを選択または作成します。 そこで実行するファイルへのパスを指定します。 また、プロキシユーザー、デバッグ設定、スクリプトに渡す引数や Spark 設定パラメーターなど、詳細な設定を行うことができます。
![Spark アクティビティの [スクリプト/Jar] タブの UI を示している。](media/transform-data-using-spark/spark-script-configuration.png)
Spark アクティビティのプロパティ
Spark アクティビティのサンプルの JSON 定義を次に示します。
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
次の表で、JSON 定義で使用される JSON プロパティについて説明します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| 名前 | パイプラインのアクティビティの名前。 | はい |
| 説明 | アクティビティの動作を説明するテキスト。 | いいえ |
| 型 | Spark アクティビティの場合、アクティビティの種類は HDInsightSpark です。 | はい |
| リンクサービス名 | Spark プログラムが実行されている HDInsight Spark のリンクされたサービスの名前。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| SparkJobLinkedService | Azure Storage にリンクされたサービスで、Spark ジョブ ファイル、依存関係、ログを保持します。 ここでは、Azure Blob Storage および ADLS Gen2 リンクされたサービスのみがサポートされています。 指定しない場合は、HDInsight クラスターに関連付けられているストレージが使用されます。 このプロパティの値には、Azure Storageリンクされたサービスのみを指定できます。 | いいえ |
| rootPath | Spark ファイルを含む Azure BLOB コンテナーとフォルダー。 ファイル名は大文字と小文字が区別されます。 このフォルダーの構造の詳細については、「フォルダー構造」(次のセクション) をご覧ください。 | はい |
| entryFilePath | Spark コード/パッケージのルート フォルダーへの相対パス。 エントリ ファイルは、Python ファイルまたは.jar ファイルである必要があります。 | はい |
| className | アプリケーションの Java/Spark メイン クラス | いいえ |
| 引数 | Spark プログラムのコマンドライン引数の一覧です。 | いいえ |
| proxyUser | 実行する Spark プログラムの代理として使用するユーザーアカウント | いいえ |
| sparkConfig | 「Spark Configuration - Application properties (Spark 構成 - アプリケーションのプロパティ)」と題するトピックに示されている Spark 構成プロパティの値を指定します。 | いいえ |
| getDebugInfo | SPARK ログ ファイルを、HDInsight クラスター (または sparkJobLinkedService で指定) によって使用されるAzure ストレージにコピーするタイミングを指定します。 使用できる値は以下の通りです。None、Always、または Failure。 既定値:[なし] : | いいえ |
フォルダー構造
Spark ジョブは、Pig/Hive ジョブよりも拡張性に優れています。 Spark ジョブの場合は、jar パッケージ (Java CLASSPATH に配置)、Python ファイル (PYTHONPATH に配置)、その他のファイルなど、複数の依存関係を提供できます。
HDInsight のリンクされたサービスによって参照されるAzure BLOB ストレージに、次のフォルダー構造を作成します。 その後、依存ファイルを、entryFilePath で表されるルート フォルダー内の適切なサブフォルダーにアップロードします。 たとえば、Pythonファイルを pyFiles サブフォルダーに、jar ファイルをルート フォルダーの jars サブフォルダーにアップロードします。 実行時に、サービスでは、Azure Blob Storage に次のフォルダー構造が必要です。
| パス | 内容 | 必須 | タイプ |
|---|---|---|---|
. (ルート) |
ストレージのリンクされたサービスにおける Spark ジョブのルート パス | はい | フォルダー |
| <ユーザー定義 > | Spark ジョブの入力ファイルを指定するパス | はい | ファイル |
| ./jars | このフォルダーのすべてのファイルがアップロードされ、クラスターの Java クラスパスに配置されます | いいえ | フォルダー |
| ./pyFiles | このフォルダーのすべてのファイルがアップロードされ、クラスターの PYTHONPATH に配置されます | いいえ | フォルダー |
| ./files | このフォルダーのすべてのファイルがアップロードされ、Executor 作業ディレクトリに配置されます | いいえ | フォルダー |
| ./archives | このフォルダーのファイルは圧縮されていません | いいえ | フォルダー |
| ./logs | Spark クラスターのログが格納されているフォルダー。 | いいえ | フォルダー |
HDInsight のリンクされたサービスによって参照されるAzure Blob Storageに 2 つの Spark ジョブ ファイルを含むストレージの例を次に示します。
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
関連するコンテンツ
別の手段でデータを変換する方法を説明している次の記事を参照してください。