適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
Data Factory in Microsoft Fabric は、よりシンプルなアーキテクチャ、組み込みの AI、および新機能を備えた次世代のAzure Data Factoryです。 データ統合を初めて使用する場合は、Fabric Data Factory から始めます。 既存の ADF ワークロードをFabricにアップグレードして、データ サイエンス、リアルタイム分析、レポートの新機能にアクセスできます。
データ フローは、Azure Data Factory パイプラインとAzure Synapse Analytics パイプラインの両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、入門記事「 マッピング データ フローを使用したデータの変換」を参照してください。
ヒント
Dataflow Gen2 の同等の変換 (データの取得) については、データ フロー ユーザーのマッピングに関する Dataflow Gen2 のガイドを参照してください。
ソース変換は、データ フローのデータ ソースを構成します。 データ フローを設計する際、最初の手順では、常にソース変換を構成します。 ソースを追加するには、データ フローのキャンバスにある [Add Source](ソースの追加) ボックスを選択します。
各データ フローには少なくとも 1 つのソース変換が必要ですが、データ変換を完了するために必要な数だけソースを追加できます。 これらのソースは、結合、参照、または和集合変換を使用して結合できます。
各ソース変換が関連付けられるデータセットまたはリンクされたサービスは 1 つだけです。 データセットは、書き込みまたは読み取りを行うデータの形状と場所を定義します。 ファイルベースのデータセットを使用する場合、ソース内でワイルドカードやファイル リストを使用すると、一度に複数のファイルを操作できます。
インライン データセット
ソース変換を作成するときに最初に行う決定は、ソース情報がデータセット オブジェクト内またはソース変換内で定義されるかどうかです。 ほとんどの形式はどちらか一方しかありません。 特定のコネクタの使用方法については、該当するコネクタ ドキュメントを参照してください。
形式がインラインとデータセット オブジェクトの両方でサポートされているとき、両方に利点があります。 データセット オブジェクトは、他のデータ フローと、コピーなどのアクティビティとで使用できる再利用可能なエンティティです。 これらの再利用可能なエンティティは、強化されたスキーマを使用する場合に特に役立ちます。 データセットは Spark を基盤としていません。 場合によっては、ソース変換で特定の設定またはスキーマ プロジェクションをオーバーライドすることが必要になります。
インライン データセットは、柔軟なスキーマ、1 回限りのソース インスタンス、またはパラメーター化されたソースの使用時に推奨されます。 ソースが大きくパラメーター化されている場合、インライン データセットでは、"ダミー" オブジェクトを作成しなくて済みます。 インライン データセットは Spark を基盤とし、それらのプロパティはデータ フローにネイティブです。
インライン データセットを使用するには、 [Source Type](ソースの種類) セレクターで目的の形式を選択します。 ソース データセットを選択せず、接続先にするリンクされたサービスを選択します。
スキーマ オプション
インライン データセットはデータ フロー内で定義されているため、インライン データセットには定義されたスキーマは関連付けられません。 [プロジェクション] タブで、ソース データ スキーマをインポートし、そのスキーマをソース プロジェクションとして格納できます。 このタブには、ADF のスキーマ検出サービスの動作を定義できる、[スキーマ オプション] ボタンがあります。
- [プロジェクション スキーマを使用する]: このオプションは、ADF でソースとしてスキャンされるソース ファイルが多数ある場合に便利です。 ADF の既定の動作として、すべてのソース ファイルのスキーマが検出されます。 ただし、事前に定義されたプロジェクションがソース変換に既に格納されている場合は、これを true に設定すると、ADF ですべてのスキーマの自動検出がスキップされます。 このオプションをオンにすると、ソース変換で、事前に定義されたスキーマがすべてのファイルに適用され、すべてのファイルをはるかに高速で読み取ることができます。
- [スキーマ ドリフトを許可]: ソース スキーマでまだ定義されていない新しい列がデータ フローで許可されるように、スキーマ ドリフトを有効にします。
- [スキーマの検証]: このオプションを設定すると、プロジェクションに定義されたいずれかの列と型がソース データの検出されたスキーマと一致しない場合、データ フローが失敗します。
- [誤差のある列の型を推論]: ADF によって新しい誤差のある列が特定されると、それらの新しい列は、ADF の自動的な型の推定を使用して適切なデータ型に強制型変換されます。
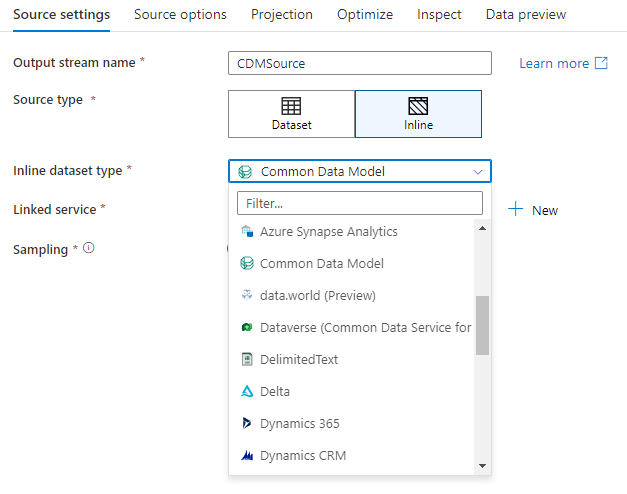
ワークスペース DB (Synapse ワークスペースのみ)
Azure Synapse ワークスペースでは、Workspace DB と呼ばれるデータ フロー ソース変換に追加のオプションがあります。 このオプションでは、利用できるあらゆる種類のワークスペース データベースをソース データとして直接選択できます。追加のリンク サービスやデータセットは必要ありません。 ワークスペース DB を選択すると、Azure Synapse データベース テンプレートを使用して作成されたデータベースにもアクセスできます。
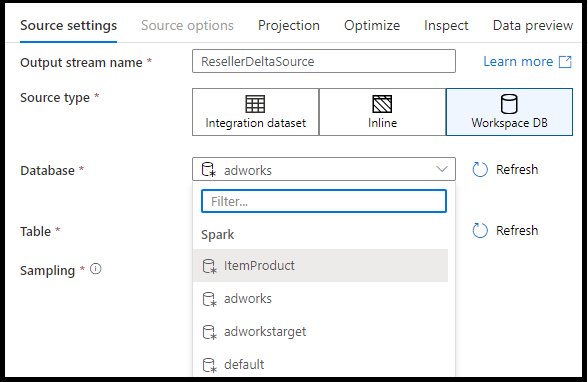
サポートされるソースの種類
マッピング データ フローは、抽出、読み込み、変換 (ELT) アプローチに従い、Azure内にある taging データセットで動作します。 現在は、次のデータセットをソース変換で使用できます。
| コネクタ | 形式 | データセット、インライン |
|---|---|---|
| アマゾンS3 |
Avro 区切りテキスト Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Appfigures (プレビュー) | -/✓ | |
| Asana (プレビュー) | -/✓ | |
| Azure Blob Storage |
Avro 区切りテキスト Delta Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Azure Data Lake Storage Gen1 |
Avro 区切りテキスト Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Data Lake Storage Gen2 |
Avro 共通データモデル 区切りテキスト Delta Excel JSON ORC Parquet XML |
✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL データベース | ✓/✓ | |
| Azure SQL Managed Instance | ✓/✓ | |
| Azure Synapse Analytics | ✓/✓ | |
| data.world (プレビュー) | -/✓ | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Google スプレッドシート (プレビュー) | -/✓ | |
| Hive | -/✓ | |
| Quickbase (プレビュー) | -/✓ | |
| SFTP |
Avro 区切りテキスト Excel JSON ORC Parquet XML |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Smartsheet (プレビュー) | -/✓ | |
| Snowflake | ✓/✓ | |
| SQL Server | ✓/✓ | |
| REST | ✓/✓ | |
| TeamDesk (プレビュー) | -/✓ | |
| Twilio (プレビュー) | -/✓ | |
| Zendesk (プレビュー) | -/✓ |
これらのコネクタに固有の設定は、 [Source options](ソース オプション) タブにあります。これらの設定に関する情報とデータ フロー スクリプトの例は、コネクタのドキュメントに記載されています。
Azure Data Factoryおよび Synapse パイプラインは、90 を超えるネイティブ コネクタにアクセスできます。 それらの他のソースからのデータをデータ フローに含めるには、コピー アクティビティを使用して、サポートされているステージング領域のいずれかにそのデータを読み込みます。
ソースの設定
ソースを追加したら、 [ソースの設定] タブを使用して構成します。ここでは、ソースが指すデータセットを選択または作成できます。 また、データのスキーマとサンプリング オプションも選択できます。
データセット パラメーターの開発値は、デバッグの設定で構成できます (デバッグ モードをオンにする必要があります)。
![[ソースの設定] タブを示すスクリーンショット。](media/data-flow/source-1.png)
[出力ストリーム名] : ソース変換の名前です。
[ソースの種類] : インライン データセットまたは既存のデータセット オブジェクトのどちらを使用するかを選択します。
[テスト接続] : ソース データセットで使用されているリンクされたサービスにデータ フローの Spark サービスが正常に接続できるかどうかをテストします。 この機能を有効にするにはデバッグ モードをオンにする必要があります。
[スキーマの誤差] : [スキーマの誤差] は、データ フロー内の柔軟なスキーマをネイティブに処理するこのサービスの機能であり、列の変更を明示的に定義する必要はありません。
ソース列が頻繁に変更される場合は、[スキーマ ドリフトを許可] チェック ボックスをオンにします。 この設定により、すべての受信ソース フィールドが変換を通してシンクに流れることができます。
変動した列の型を推論 を選択すると、サービスが新しく検出された各列のデータ型を検出し、定義します。 この機能が無効になっている場合、すべてのドリフトした列は文字列型になります。
[スキーマの検証]: [スキーマの検証] を選択した場合、受信したソース データがデータセットの定義済みスキーマと一致しなければ、データ フローの実行は失敗します。
[Skip line count](スキップ行数) : この [Skip line count](スキップ行数) フィールドでは、データセットの先頭で無視する行数を指定します。
サンプリング:ソースからの行数を制限するには、サンプリングを有効にします。 デバッグの目的でソースのデータをテストまたはサンプリングする場合は、この設定を使用します。 これは、パイプラインからデバッグ モードでデータ フローを実行する場合に非常に便利です。
ソースが正しく構成されていることを確認するには、デバッグ モードを有効にし、データ プレビューを取り込みます。 詳細については、デバッグ モードに関するページを参照してください。
注
デバッグ モードを有効にすると、データ プレビュー時に、デバッグの設定での行数上限の構成によってソースのサンプリング設定が上書きされます。
ソース オプション
[Source options](ソース オプション) タブには、選択したコネクタおよび形式に固有の設定が含まれています。 詳細と例については、関連するコネクタのドキュメントを参照してください。 これには、それをサポートするデータ ソースの分離レベル (オンプレミスの SQL Server、Azure SQL データベース、Azure SQL マネージド インスタンスなど) や、その他のデータ ソース固有の設定などの詳細が含まれます。
プロジェクション
データセット内のスキーマと同様に、ソース内のプロジェクションでは、ソース データのデータの列、型、および形式が定義されます。 SQL や Parquet など、ほとんどのデータセットの種類では、ソースでのプロジェクションはデータセットで定義されているスキーマを反映するように固定されており、それはソースによって異なります。 ソース ファイルが厳密に型指定されていない場合 (たとえば、Parquet ファイルでなくフラットな .csv ファイル)、このソース変換では各フィールドのデータ型を定義できます。 次の図はプロジェクションの例を示したものです。
![[プロジェクション] タブの設定を示すスクリーンショット。](media/data-flow/source-3.png)
テキスト ファイルが定義済みのスキーマを含まない場合は、サービスがデータ型をサンプリングして推論するように、[データ型の検出] を選択します。 [Define default format](既定の形式の定義) を選択して、既定のデータ形式を自動検出します。
スキーマをリセットすると、参照されているデータベースにある定義にプロジェクションがリセットされます。
スキーマを上書きすると、ソースの予想データ型をここで変更し、スキーマ定義のデータ型を上書きできます。 あるいは、列のデータ型は、下流の派生列変換で変更できます。 選択変換を使用して、列の名前を変更します。
スキーマをインポート
[プロジェクション] タブの [スキーマのインポート] ボタンを選択すると、アクティブなデバッグ クラスターを使用し、スキーマ プロジェクションを作成できます。 あらゆるソースの種類で利用できます。 スキーマをここでインポートすると、データセットに定義されているプロジェクションがオーバーライドされます。 データセット オブジェクトは変更されません。
スキーマのインポートは、データセット内にスキーマ定義を存在させる必要のない複雑なデータ構造をサポートする Avro や Azure Cosmos DB などのデータセットで役立ちます。 インライン データセットの場合、スキーマのインポートは、スキーマの誤差なしで列のメタデータを参照する唯一の方法です。
ソース変換を最適化する
[Optimize](最適化) タブでは、各変換手順でパーティション情報を編集できます。 ほとんどの場合、[現在のパーティション分割を使用] を選択すると、ソースの理想的なパーティション構造に最適化されます。
Azure SQL Database のソースから読み取る場合、Source のカスタムパーティション分割を使用することで、最も速くデータを読み取ることができる可能性があります。 サービスは、データベースへの接続を並列で行うことによって、大規模なクエリを読み取ります。 このソース パーティション分割は、列に対して、またはクエリを使用して行うことができます。
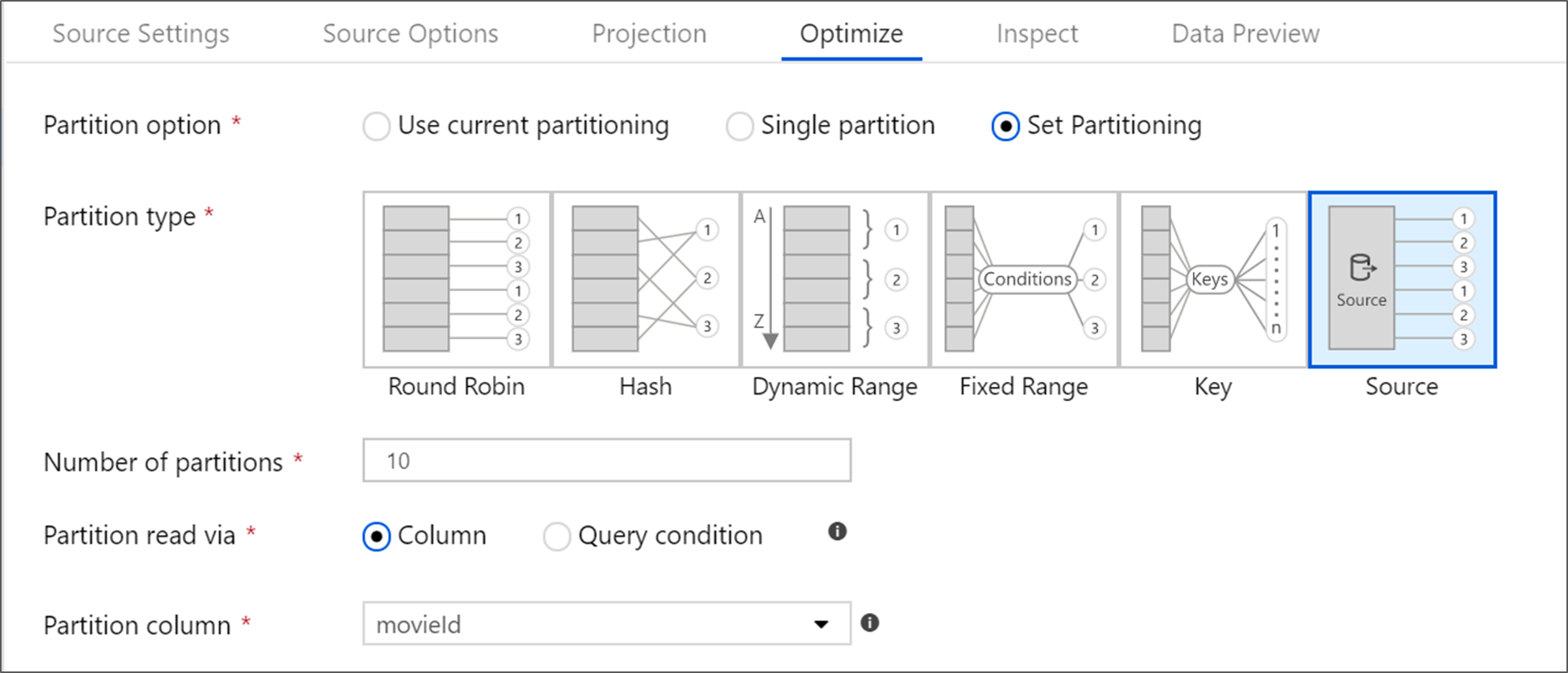
マッピング データ フロー内での最適化の詳細については、[Optimize] タブに関する説明を参照してください。